Хотелось бы сказать, что Stack Overflow — масштабный проект, но это не так. Я имею ввиду мы добились многого, но я не могу назвать наш проект “большим”, ещё рано. Давайте я приведу в пример некоторые цифры — с какой нагрузкой мы имеем дело сейчас. Срез статистики за 24 часа от 12 ноября 2013 года. Это обычный будний день. Отмечу, что здесь представлена информация только по нашим собственным вычислительным мощностям, без CDN.

Мне обязательно нужно будет написать пост о том, как мы эти цифры получаем, но данная статистика (кроме трафика) рассчитана только благодаря HTTP логам. Как получилось так много часов за день? Мы называем это магией. Большинство людей называют это “несколько серверов с многоядерными процессорами”, но мы всё списываем на магию. Stack Exchange работает на следующем оборудовании:
Как вся эта красота выглядит можно посмотреть на первой фотографии (выше).
Мы не просто занимаемся хостингом своих сайтов. Ближайшая стойка — это сервера для виртулизации (vmware) и вспомогательной инфраструктуры, которая не влияет на работу сервиса непосредственно, например машинки для деплоя, контроллеры домена, мониторинг, дополнительная база данных для администраторов и прочее. 2 SQL сервера из списка выше были резервными серверами до недавнего времени — сейчас они используются для read-only запросов, так что мы можем продолжать масштабироваться, не задумываясь о нагрузке на базы данных еще долго. 2 веб-сервера из того списка предназначены для разработки и перифирийных задач, по-этому они потребляют мало трафика.
Если мы на момент представим, что что-то произошло и вся избыточность инфраструктуры пропала, то весь Stack Exchange может работать на следующем оборудовании без потери в производительности:
Нам надо будет попробовать отключить часть серверов специально чтобы проверить на деле. :)
Ниже — средняя конфигурация оборудования:
Кажется, что 20Гбит/с — слишком много? Да, например SQL сервера в пик не загружают сеть больше, чем на 100-200 Мбит/с, но не забывайте про резервное копирование, перестроение топологии — это пожет понадобиться в любой момент и тогда сеть будет использована на полную. Такое количество памяти и SSD смогут загрузить этот канал полностью.
В данный момент у нас примерно 2 ТБ данных в SQL (1.06/1.16 ТБ на первом кластере из 18 SSD и 0.889/1.45 ТБ на втором, состоящем из 4 SSD). Возможно, стоило бы задуматься об облаках, но сейчас мы используем SSD и время записи в базу равно буквально 0 миллисекундам. С базой данных в памяти и двумя уровнями кеша перед ней, Stack Overflow имеет соотношение чтения к записи 40 к 60. Да, всё верно, 60% времени работы базы данных она пишет.
На веб-серверах используются SSD диски на 320 ГБ в RAID1.
Сервера ElasticSearch тоже снабжаются SSD дисками на 300 ГБ. Это важно, так как там часто выполняется перезапись и индексация.
Мы так же не упомянули о SAN. Это DELL Equal Logic PS6110X с 24 SAS 10K дисками и подключением 2х10 Гбит/с. Используется он как хранилище для виртуальных серверов VmWare как облако и не связан с самим сайтом. Если этот сервер упадёт, сайты некоторое время даже не будут знать об этом.
Что мы будем с этим делать? Мы хотим большей производительности — это очень важно для нас. 12-го ноября страница загружалась в среднем 28 миллисекунд. Мы стараемся поддерживать скорость загрузки не дольше 50 миллисекунд. Вот средняя статистика загрузки популярных страниц в этот день:
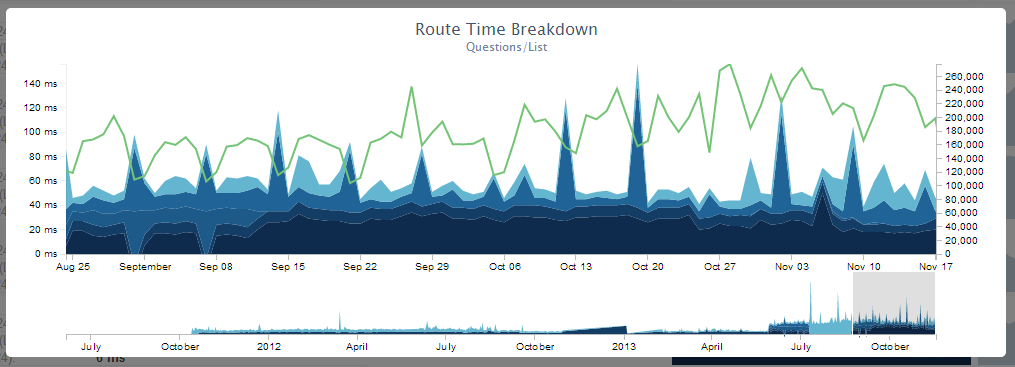
Мы мониторим скорость загрузки путём записи таймингов. Благодаря этому, мы можем составить очень наглядный график:

Очевидно, что все сервисы сейчас работают на низкой нагрузке. Веб-сервера потребляют в среднем 5-15% процессора, 15,5 ГБ ОЗУ, и 20-40 МБит/c полосы сети. Средняя загрузка процессора сервера базы данных — 5-10%, 365 ГБ ОЗУ и 100-200 МБит/с полосы сети. Благодаря этому мы можем полноценно развиваться и, что очень важно, мы страхуемся от падения на случай повышения нагрузки — ошибка в коде или любой другой сбой.
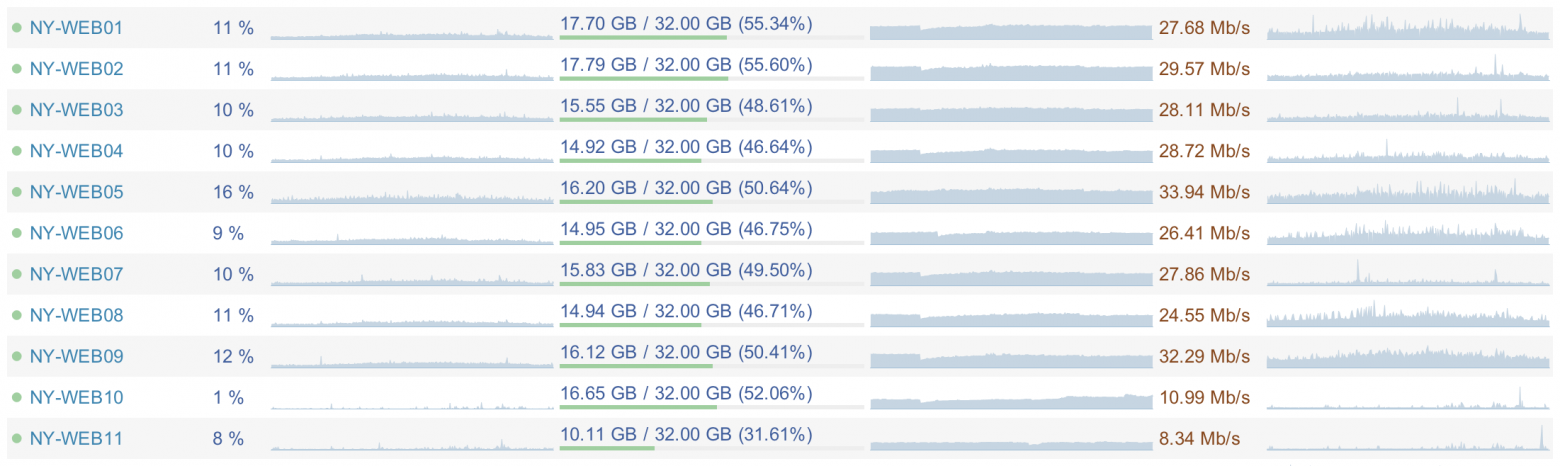
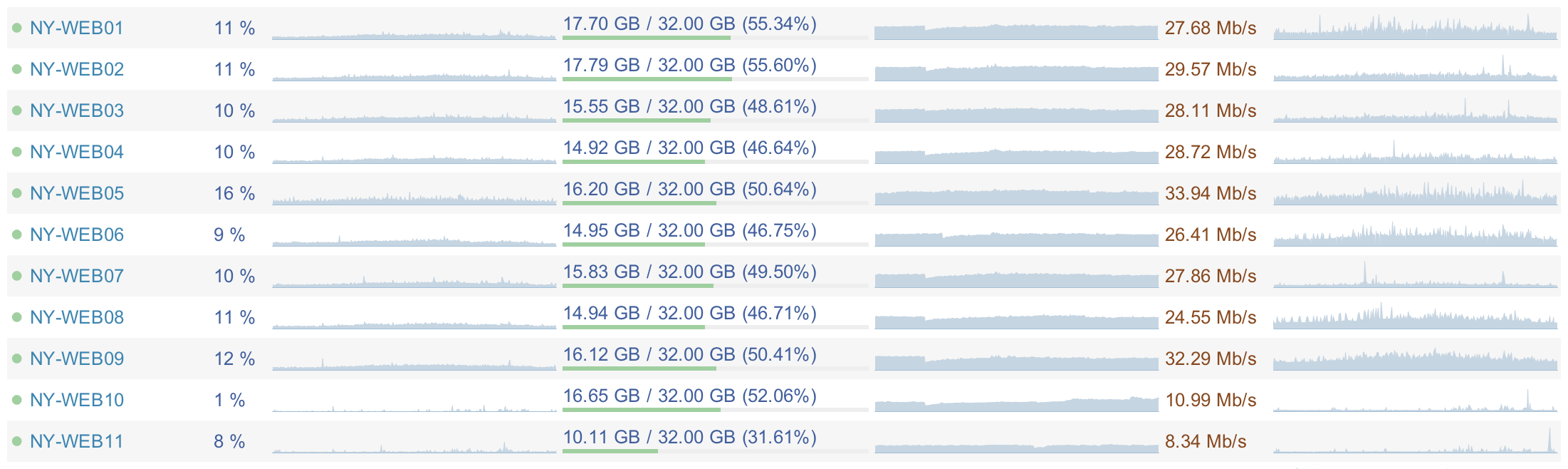
Вот скриншот из Opserver:
Главная причина того, что нагрузка настолько низкая, заключается в эффективности кода. Пусть пост и посвящен другому, но эффективный код — критическое место для масштабирования вашего железа в будущем. Все, что вы сделали, но не должны были делать, будет вам стоить дороже, чем если бы вы этого не сделали вовсе — аналогичное правило касается и неэффективного кода. Под стоимостью понимается следующее: энергопотребление, стоимость железа (потому что вам нужно больше серверов, или они должны быть мощнее), разработчики, занятые попытками осознать более сложный код (хотя, честно говоря, оптимизированный код не обязательно становится проще) и скорее всего медленный рендер страниц — что выражается в реакции пользователя, который не станет ждать загрузки еще одной страницы… а то и вовсе больше не зайдет к вам. Цена неэффективного кода может оказаться гораздо выше, чем вам кажется.
Итак, сегодня мы познакомились с тем, как работает Stack Overflow на нынешнем железе. В следующий раз мы узнаем о том, почему мы не спешим переезжать в облака.

Статистика
- 148,084,883 HTTP запросов к нашему балансировщику нагрузки
- 36,095,312 из них — настоящие загрузки страниц
- 833,992,982,627 байт (776 ГБ) HTTP трафика отправлено
- 286,574,644,032 байт (267 ГБ) трафика получено
- 1,125,992,557,312 байт (1,048 ГБ) трафика отправлено
- 334,572,103 SQL запроса по HTTP запросам
- 412,865,051 запрос до Redis серверов
- 3,603,418 запросов до обработчика тэгов (отдельный сервис)
- 558,224,585 мс (155 часов) было затрачено на обработку SQL запросов
- 99,346,916 мс (27 часов) потребовалось на ожидание ответа от серверов Redis
- 132,384,059 мс (36 часов) прошло на обработку запросов по тэгам
- 2,728,177,045 мс (757 часов) работали скрипты ASP.Net
Мне обязательно нужно будет написать пост о том, как мы эти цифры получаем, но данная статистика (кроме трафика) рассчитана только благодаря HTTP логам. Как получилось так много часов за день? Мы называем это магией. Большинство людей называют это “несколько серверов с многоядерными процессорами”, но мы всё списываем на магию. Stack Exchange работает на следующем оборудовании:
- 4 MS SQL сервера
- 11 IIS Веб-серверов
- 2 сервера Redis
- 3 сервера, занимающиеся обработкой тэгов (абсолютно всё, что касается тегов, например запрос /questions/tagged/c++)
- 3 сервера ElasticSearch
- 2 балансировщика нагрузки (реализация HAProxy)
- 2 свитча (каждый на базе Nexus 5596 + Fabric Extenders)
- 2 Файервол Cisco 5525-X ASAs
- 2 Маршрутизатора Cisco 3945
Как вся эта красота выглядит можно посмотреть на первой фотографии (выше).
Мы не просто занимаемся хостингом своих сайтов. Ближайшая стойка — это сервера для виртулизации (vmware) и вспомогательной инфраструктуры, которая не влияет на работу сервиса непосредственно, например машинки для деплоя, контроллеры домена, мониторинг, дополнительная база данных для администраторов и прочее. 2 SQL сервера из списка выше были резервными серверами до недавнего времени — сейчас они используются для read-only запросов, так что мы можем продолжать масштабироваться, не задумываясь о нагрузке на базы данных еще долго. 2 веб-сервера из того списка предназначены для разработки и перифирийных задач, по-этому они потребляют мало трафика.
Об оборудовании
Если мы на момент представим, что что-то произошло и вся избыточность инфраструктуры пропала, то весь Stack Exchange может работать на следующем оборудовании без потери в производительности:
- 2 SQL сервера (Stack Overflow на одной машинке, всё остальное на другой, хотя мы уверены, что они смогут работать на одном сервере)
- 2 Веб-сервера (возможно три, но я верю, что будет достаточно и двух)
- 1 сервер Redis
- 1 сервер для обработки тэгов
- 1 сервер ElasticSearch
- 1 балансировщик нагрузки
- 1 свитч
- 1 ASA брендмауэр
- 1 Маршрутизатор
Нам надо будет попробовать отключить часть серверов специально чтобы проверить на деле. :)
Ниже — средняя конфигурация оборудования:
- SQL сервера работают на 384 ГБ ОЗУ с файловым хранилищем в 1.8ТБ (SSD)
- Сервера Redis запускаются на машинках с 96 ГБ ОЗУ
- Сервера ElasticSearch — 196 ГБ ОЗУ
- Сервера для обработки тегов требуют самых быстрых процессоров, что мы можем приобрести.
- Свитчи — 10 ГБит на каждый порт.
- Веб-сервера ничем особым не отличаются — 32 ГБ ОЗУ, 2 четырёхъядерных процессора и 300 ГБ SSD хранилища на каждый.
- Сервера, у которых нет сети 2х10Гбит/с (например SQL) подключаются четырьмя соединениями по 1 Гбит/с.
Кажется, что 20Гбит/с — слишком много? Да, например SQL сервера в пик не загружают сеть больше, чем на 100-200 Мбит/с, но не забывайте про резервное копирование, перестроение топологии — это пожет понадобиться в любой момент и тогда сеть будет использована на полную. Такое количество памяти и SSD смогут загрузить этот канал полностью.
Хранилище
В данный момент у нас примерно 2 ТБ данных в SQL (1.06/1.16 ТБ на первом кластере из 18 SSD и 0.889/1.45 ТБ на втором, состоящем из 4 SSD). Возможно, стоило бы задуматься об облаках, но сейчас мы используем SSD и время записи в базу равно буквально 0 миллисекундам. С базой данных в памяти и двумя уровнями кеша перед ней, Stack Overflow имеет соотношение чтения к записи 40 к 60. Да, всё верно, 60% времени работы базы данных она пишет.
На веб-серверах используются SSD диски на 320 ГБ в RAID1.
Сервера ElasticSearch тоже снабжаются SSD дисками на 300 ГБ. Это важно, так как там часто выполняется перезапись и индексация.
Мы так же не упомянули о SAN. Это DELL Equal Logic PS6110X с 24 SAS 10K дисками и подключением 2х10 Гбит/с. Используется он как хранилище для виртуальных серверов VmWare как облако и не связан с самим сайтом. Если этот сервер упадёт, сайты некоторое время даже не будут знать об этом.
Что дальше?
Что мы будем с этим делать? Мы хотим большей производительности — это очень важно для нас. 12-го ноября страница загружалась в среднем 28 миллисекунд. Мы стараемся поддерживать скорость загрузки не дольше 50 миллисекунд. Вот средняя статистика загрузки популярных страниц в этот день:
- Страницы вопросов с ответами — 28 миллисекунд (29.7 млн. запросов)
- Профили пользователей — 39 миллисекунд (1.7 мил. запросов)
- Список вопросов — 78 миллисекунд (1.1 млн. запросов)
- Домашняя страница — 65 миллисекунд (1 млн. запросов), что очень медленно. Мы исправим это в ближайшее время.
Мы мониторим скорость загрузки путём записи таймингов. Благодаря этому, мы можем составить очень наглядный график:
Масштабируемость в будущем
Очевидно, что все сервисы сейчас работают на низкой нагрузке. Веб-сервера потребляют в среднем 5-15% процессора, 15,5 ГБ ОЗУ, и 20-40 МБит/c полосы сети. Средняя загрузка процессора сервера базы данных — 5-10%, 365 ГБ ОЗУ и 100-200 МБит/с полосы сети. Благодаря этому мы можем полноценно развиваться и, что очень важно, мы страхуемся от падения на случай повышения нагрузки — ошибка в коде или любой другой сбой.
Вот скриншот из Opserver:
Главная причина того, что нагрузка настолько низкая, заключается в эффективности кода. Пусть пост и посвящен другому, но эффективный код — критическое место для масштабирования вашего железа в будущем. Все, что вы сделали, но не должны были делать, будет вам стоить дороже, чем если бы вы этого не сделали вовсе — аналогичное правило касается и неэффективного кода. Под стоимостью понимается следующее: энергопотребление, стоимость железа (потому что вам нужно больше серверов, или они должны быть мощнее), разработчики, занятые попытками осознать более сложный код (хотя, честно говоря, оптимизированный код не обязательно становится проще) и скорее всего медленный рендер страниц — что выражается в реакции пользователя, который не станет ждать загрузки еще одной страницы… а то и вовсе больше не зайдет к вам. Цена неэффективного кода может оказаться гораздо выше, чем вам кажется.
Итак, сегодня мы познакомились с тем, как работает Stack Overflow на нынешнем железе. В следующий раз мы узнаем о том, почему мы не спешим переезжать в облака.
