Занимались мы как-то обработкой аудио на Java с помощью сложных алгоритмов. Каждый кусочек аудио должен был пройти длинную цепочку обработки (20-50 алгоритмов разной степени сложности). Потоки аудио поступали параллельно, алгоритмы работали параллельно, и завершались в разные моменты. Некоторые алгоритмы нуждались в разной степени буферизации. Из кусочков аудио извлекалась информация повышающегося уровня абстракции, то есть начиная с какого-то уровня уже шло не аудио, а извлечённая информация об этом аудио.
Всё хозяйство должно было работать в рамках одного экземпляра приложения, но при этом должно было быть несколько вложенных почти независимых очень похожих контейнеров для клиентского кода (типа Bean'ов).
С самого начала мы не ставили задачу всеобщей унификации, и решали в каждой части системы по своему. Где-то использовали потоки для длительных задач, где-то создавали цепочки вызовов, где-то — модель подписки. Так как система была довольно большой, то практически все известные способы декомпозиции и обработки были задействованы в той или иной степени. Потом мы обнаруживали общность и реализовывали похожие решения в разных частях системы. А потом изобрели первую версию того, что сейчас мы называем система контактов или SynapseGrid.
Так как мы решали не отдельную прикладную задачу из серии «сделал — забыл», а реализовывали инструментарий, позволяющий решать семейство задач, то одним из принципов разработки был принцип модульности. То есть мы создавали отдельные повторно-используемые компоненты, которые должны были комбинироваться почти произвольным образом, чтобы строить системы для решения любой задачи из семейства.
Когда мы только начинали, мы не очень хорошо понимали, как моделировать аудио-поток. Начали мы с того, что представляли его в форме AudioInputStream. Оказалось, что такое представление не позволяет обеспечить модульности. Т.е. один-то модуль может легко читать из байт-потока с блокировками, и выполнять свою обработку. Но как он передаст данные дальше? Если соединять модули pipe'ом, то придётся каждый малюсенький модуль помещать в отдельный поток выполнения, который будет блокироваться, пока не поступит порция новых данных. Это, понятное дело, было крайне неэффективно.
Потом мы обнаружили, что если аудио-поток разбить на фреймы (кусочки фиксированной длины, по 10-40 мс), то модули гораздо проще соединить. Кусочки аудио могли быть помещены в обычную очередь и очередь можно было проверить без блокировки.
Первичная обработка аудио во многих задачах оказывалась почти линейной. Т.е. модули выстраивались в цепочку, в которой выход предыдущего модуля соединялся со входом последующего модуля. Такую структуру обычно называют pipeline'ом.
Организовать передачу данных можно тремя способами:
1. pull
2. push
3. functional aggregation
В случае pull, данные «вытягиваются» из последнего компонента, причём цепочка предшествующих компонентов ненаблюдаема и может произойти блокировка из-за нехватки данных в каком-то буфере. При возникновении любого исключения происходит схлопывание всего стека, что приводит к невозможности продолжить работу.
В случае push, данные «вталкиваются» в первый компонент и дальнейшая их судьба остаётся неизвестной. При нехватке данных для буферизации на выходе цепочки ничего не появляется. При возникновении исключения стек снова схлопывается и исключение появляется в самом начале цепочки, где с ним снова непонятно, что можно сделать. Продолжение работы также невозможно. Кроме того, реализация модулей в режиме push довольно неудобна/непривычна для программиста. И обязательно требует наличия side-effect'ов.
Когда мы стали использовать functional-подход, оказалось, что он обладает преимуществами перед pull и push. Во-первых, вся цепочка компонентов видна как на ладони, и может быть легко прослежена. Во-вторых, при возникновении исключения в любом компоненте его легко перехватить, и, что немаловажно, исключение затрагивает только один компонент, и обработку можно продолжить с минимальными проблемами.
Т.к. разработка в то время шла на Java, мы сделали интерфейс для функционального подхода, который должны были реализовывать все модули. Оказалось, что модули принципиально разделились на два вида — те, что всегда обязательно на каждый входной элемент выдавали ровно один выходной элемент, и другие модули, которые могли выдать 0..n элементов на выходе. Модули первого типа (типа
Модули второго типа (
Для «прокачки» данных через pipeline можно было использовать две стратегии — depth first или width first.
При depth first каждый элемент прослеживался до конца цепочки, а потом обрабатывался следующий входной элемент. При width first все элементы проходили первый этап, потом все полученные проходили второй этап и т.д.
Наиболее общим интерфейсом является 1 -> 0..n (flatMap), поэтому этот интерфейс был взят за основу разработки. Оказалось, что модули, имеющие такой интерфейс, очень легко объединять по принципу функциональной агрегации в более крупные модули, имеющие точно такой же интерфейс. Для линейного pipeline'а получилось, что ничего другого и не требуется.
В некоторый момент обработка разветвлялась. Одни и те же данные надо было передавать нескольким модулям. Схема, которая хорошо работала для pipeline, здесь создавала проблемы. Во-первых, чтобы данные передавать в несколько мест, надо было иметь алгоритм, в котором явно были прописаны оба продолжения. Во-вторых, при агрегировании цепочки с двумя концами невозможно было обеспечить тот же интерфейс с одним входом и одним выходом.
Мы довольно быстро придумали схему с подпиской на события. Создавался объект Event[T], в который можно было с одной стороны помещать данные, а с другой стороны подписываться на новые данные. Это позволяло обеспечить decoupling модулей. Event был сделан асинхронным и потокобезопасным. Созданная схема очень напоминает библиотеку RxJava (там событие называется Observable[T]).
Модель с подпиской была довольно неплохой и позволяла довольно просто организовать работу в нескольких независимых потоках. Одним из отличий от Observable в нашей схеме было то, что на вход Event'а данные могли поступать из нескольких источников.
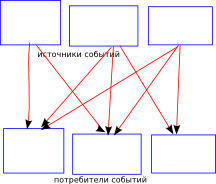
Рис.1 Многие-ко-многим, напрямую
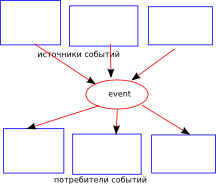
Рис.2 Многие-ко-многим по схеме «звезда»
По мере развития проекта количество event'ов возросло и обнаружились ограничения этой схемы.
1. Неизвестно, генерирует ли кто-нибудь данное событие.
2. Неизвестно, подписан ли кто-нибудь на событие.
3. Потоки данных текут ненаблюдаемо — одно событие, обработчик, скрытая внутренняя генерация(?) другого события, другой обработчик и т.д.
4. Если подписка синхронная, т.е. обработчик выполняется в вызывающем потоке, то непонятно, что делать с исключением.
Если подписку обработчика на событие отследить ещё можно, и даже можно нарисовать схему event-подписчики, то связь генератор-событие являлась потусторонней и невозможно было понять, генерирует ли кто-то это событие и при каких условиях.
К этому моменту Akka у нас уже использовалась для remoting'а и выглядела многообещающе. По-крайней мере, можно было надеяться переложить на Akka многопоточность и решить некоторые проблемы с event'ами.
Акка предлагает легковесного Actor'а, который работает в условно-отдельном потоке, но не потребляет много ресурсов. Условно-отдельный поток означает, что если эктор занят обработкой какого-то сообщения, то никакой другой поток параллельно не будет задействован для обработки других сообщений этим же эктором. Т.е. отдельный эктор обрабатывает сообщения строго последовательно, но при большом количестве экторов оказывается, что все радостно работают параллельно и друг другу не мешают.
Оказалось, что в подходе с экторами связи вообще никак не продуманы и не наблюдаются. Т.е. связи между экторами лежат целиком на совести разработчика и могут расползаться по программе как угодно. Более того, хотя мы теоретически можем отследить судьбу одной ссылки на эктор, однако в Akka предусмотрен способ получения ссылки по текстовому url эктора. Т.е. мы принципиально не можем отследить и ограничить расползание связей в системе.
К чему это приводит? В многопоточной системе с большим количеством похожих экторов и огромным количеством ненаблюдаемых связей периодически возникают малоизученные явления. Например, бесконечный цикл трёх видов: расходящийся, когда в каждой итерации число сообщений увеличивается, монотонный, который просто живёт своей жизнью, отъедает ресурсы процессора, но не приводит к катастрофе, и затухающий, когда количество сообщений медленно убывает. Отладить такую систему is next to impossible. Весьма сложно. В ряде критичных мест нам пришлось пользоваться подходом Model Checking. И всё равно не было полной уверенности, что где-то не циркулируют какие-нибудь сообщения.
В Ubuntu некоторое время тому назад появилась система загрузки, основанная на событийной модели (Upstart). Система очень примечательна своим подходом к событиям. Каждое событие имеет имя и может иметь параметры. Обработчики (task'и) могут подписаться на комбинацию событий (с boolean-условиями на параметры) и будут вызваны, если всё сложится. Также обработчики декларативно описывают те события, которые они генерируют (хотя можно любое событие сгенерировать и потусторонним способом).
Эта система описывает так называемую «решётку», или направленный граф (диграф). Узлами решётки являются события, а ветвями — обработчики. В силу встроенного в граф параллелизма upstart позволяет запускать обработчики гораздо раньше, чем это делает система System V, основанная на фиксированных разделяющих слоях (runlevels 0..6). Независимые обработчики спокойно работают параллельно.
Идеи Upstart повлияли на дальнейшую разработку системы контактов.
До тех пор, пока мы рассматриваем картину звезды с одним event'ом (приведённую на рисунке выше), нам не удастся придумать хорошего механизма для организации многопоточной системы. Но если построить направленный граф, то уже прорисовываются интересные перспективы.
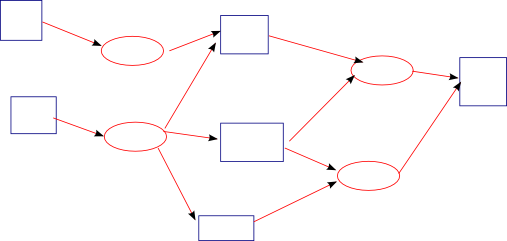
Рис.3 Решётка событий и обработчиков
По схеме очень напоминает upstart. Если потребовать, чтобы связи объявлялись декларативно и запретить/исключить неявное создание связей, то весь граф, описывающий работу всей системы, оказывается как на ладони и доступен для статического анализа. Просто наблюдая такой граф, можно обнаружить нежелательные циклы, отсутствующие связи, висящие отдельно Event'ы или обработчики.
В первой версии мы просто несколько обобщили и адаптировали Event[T], но сохранили распределённый («размазанный») механизм передачи сообщений. Наличие графа обработки уже само по себе позволяло понять работу системы и решить текущие проблемы. Но такой «размазанный» механизм передачи сообщений с обязательной буферизацией и защищённо-потокобезопасный, не подходил для решения аналогичных задач в других частях системы. Там требовалось что-то похожее, но более легковесное.
Здесь требуется небольшое отступление о механизме легковесных экторов, который имеет много сходных черт с архитектурой SynapseGrid.
Рассмотрим такой код:
Когда мы отправляем сообщение «Hello» эктору, создаётся обёртка вокруг нашего сообщения:
И это сообщение помещается в очередь. Где-то параллельно работают 16 потоков, которые из этой большой очереди читают сообщения. И есть ещё некий диспетчер, который следит за тем, чтобы с одним эктором не работали два потока одновременно. Поток хватает сообщение, находит эктора и просто выполняет функцию этого эктора на нашем сообщении («Hello»).
Такая схема позволяет существовать миллионам экторов, которые не потребляют ресурсы (кроме чуточки памяти), пока спят. А расход процессорного времени происходит только в 16 потоках и исключительно на обработку реальных данных.
Если посмотреть на пользовательскую модель, то у каждого эктора — своя очередь сообщения и мы командой
В этой схеме actorRef играет роль handle или тега, или метки. Т.е. мы наши данные снабжаем меткой, которая показывает расположение сообщения «Hello» в виртуальном пространстве виртуальных очередей экторов.
Виртуально на миллион экторов мы имеем миллион очередей. Представляете массив из 1000000 очередей, который надо просматривать? В этой виртуальной пользовательской модели всё будет не очень эффективно. А реализуется эта же самая структура с помощью меток, что позволяет получить одну большую очередь, но с метками-тегами. И работать эта очередь будет весьма эффективно.
Ещё одна аналогия, которая приходит на ум, это использование HashMap для хранения огромных разреженных массивов. Как нам для нескольких точек в трёхмерном пространстве сохранить какие-то данные? Пусть размер нашего трёхмерного пространства — 1000х1000х1000. Если хранить массивами, то потребуется 10e9 ячеек. А если использовать метку (x,y,z), то потребуется гораздо меньше памяти. Здесь как раз и работает
В схеме с размазанным механизмом передачи сообщений связи непосредственно хранились в Event'ах. Это похоже на то, как если бы миллион очередей к экторам сделать на самом деле. А вот если сделать единую коллекцию, где будут находится события и связи, то можно обеспечить эффективный централизованный механизм распределения сообщений.
Итак, для представления событий, на которые можно подписаться, мы вводим понятие контакта,
а для представления сообщений, связанных с этим контактом, — сигнал.
Как можно видеть, контакт похож на ActorRef, а сигнал — на Message. Отличие заключается в том, что с контактом не связано ни состояние, ни поведение. Это просто некий идентификатор. Если вспомнить аналогию с виртуальной «очередью», то контакт идентифицирует эту очередь.
Т.к. в контакте нет ни данных, ни поведения, то передать в него сообщение просто так невозможно. Это приводит к невозможности создания потусторонних связей, которые обычно возникают внутри обработчиков/хэндлеров. Связи могут быть только декларативными.
Как уже говорилось выше, моделью целой системы является направленный граф. Если внимательно присмотреться, то можно заметить, что это двудольный граф. Но в подавляющем большинстве случаев элементарные обработчики представляют собой map или flatMap компоненты, имеющие один вход и один выход. Поэтому в основу SynapseGrid мы положили более простой граф, узлы которого соответствуют контактам, а дуги связаны с компонентами, осуществляющими обработку данных. Т.е. граф задан совокупностью троек (контакт1, контакт2, обработчик):
(здесь мы пользуемся тем, что map-компонеты являются частным случаем flatMap-компонентов).
При появлении данных (сигналов) на каком-либо контакте, мы легко можем определить все обработчики, которые хотели бы обработать эти данные, можем спланировать вызов этих обработчиков в одном или нескольких потоках. Результаты работы, полученные каждым обработчиком, становятся сигналами на выходных контактах, к которым привязаны обработчики, и снова попадают в общую очередь на обработку.
Описанный механизм работы предполагает наличие неизменного (immutable) графа, заданного совокупностью троек. Такой граф было бы не очень удобно создавать сразу в одном выражении. Вместо этого оказывается удобно использовать концепцию билдеров, позволяющих шаг за шагом, добавляя отдельные дуги, конструировать граф системы.
Для системы контактов мы разработали DSL
Использование стандартных названий методов map, flatMap, filter позволяет воспользоваться Scala-sugar — for-comprehension:
Больше примеров использования DSL — в описании SynapseGrid.
Одной из особенностей Akka и других подходов на основе экторов является то обстоятельство, что порядок обработки сообщений разными акторами не определён и отдан на волю случая. Скорее всего, это приводит к выигрышу в производительности, но также отрицательно сказывается на предсказуемости работы системы.
Поскольку непредсказуемость для нас гораздо хуже, чем недоиспользование потенциала процессора, мы решили в основных режимах работы обеспечивать гарантии детерминированности последовательности сигналов. (А более производительный, но менее детерминированный режим работы использовать только для оптимизации в редких случаях.)
Все сигналы погружаются в дискретное время и упорядочиваются внутри каждого временного слота. В начальный момент времени имеется один сигнал на входном контакте. Переход от одного момента времени к другому происходит только тогда, когда все сигналы текущего момента времени обработаны. Порождаемые сигналы упорядочиваются так, как если бы обработчики вызывались строго последовательно (в однопоточном режиме так оно и есть, а в многопоточном сигналы упорядочиваются принудительно).
Если посмотреть на совокупность сигналов в каждый момент времени, то получающаяся картинка называется треллис и применяется, например, в алгоритме Витерби.
Поскольку вся обработка происходит централизованно, никто не мешает нам такую картинку нарисовать и проанализировать прохождение сигналов.
Если граф разветвляется, то можно довольно просто гарантировать синхронность появления сигналов на заданных контактах. Если альтернативные цепочки имеют разную длину, то синхронность обеспечивается очень просто — добавлением нескольких пустых стрелочек («линий задержки»).
Созданная система контактов замечательно заменяла pipeline и подписки на события. И постепенно на эту систему были переведены многие компоненты системы. Однако для объединения нескольких систем, необходимо было предусмотреть возможность существования компонентов с несколькими входами и несколькими выходами. В отличие от компонентов-двухполюсников, аналогами которых являются обычные функции, аналогов для многоконтактных компонентов мы не нашли.
Выход был найден в использовании всё тех же меток для различения входов между собой и выходов между собой. Компонент, представляющий подсистему, получил такую сигнатуру:
Т.е. данные, которые мы хотим отправить на вход in1, оборачиваются в Signal и помечаются контактом in1. Данные, появляющиеся на выходе out1 представляются
С точки зрения треллиса родительской системы вся обработка в дочерней подсистеме происходит за один временной шаг. Внутри подсистемы создаётся свой треллис.
Подсистема оказалась хорошим претендентом на выполнение в отдельном потоке и мы первым делом реализовали механизм, позволяющий любую подсистему выделить в отдельный Akka-эктор.
Такая схема позволила закрыть 90% всех потребностей в многопоточности. Akka гарантирует, что в пределах одного эктора всё происходящее можно считать однопоточным. А SynapseGrid позволил объединять любое количество экторов в связанную систему с наблюдаемыми связями. У экторов, построенных на основе подсистем, отсутствует прямая возможность создания потусторонней связи с другой подсистемой. Картина мира становится гораздо прозрачней.
Однако остались ещё 10% потребностей в многопоточности, которые не давали нам покоя. А именно, если нам требовалось обеспечить параллельную обработку массы однотипных данных с помощью одного компонента, экторы на основе подсистем буксовали. Они обрабатывали данные строго последовательно.
Тогда было решено сделать свой планировщик, который будет загружать работой 16 потоков ExecutorContext'а согласно семантике SynapseGrid. Библиотека synapse-grid-concurrent позволяет полностью выполнять систему произвольной вложенности на пуле потоков и при этом гарантирует детерминизм однопоточного варианта.
SynapseGrid позволяет строить модульные системы, выполняющие срочную (ASAP) обработку данных без лишней буферизации. В основе библиотеки лежит функциональный подход, внешнее связывание и декларативный подход. Система собирается с помощью развитого API Builder'а в режиме конструирования. А в режиме исполнения система является немодифицируемой (immutable).
Выполнение логики обработки данных может осуществляться в одном или в нескольких потоках с гарантией получения идентичных результатов. SynapseGrid расширяет возможности Akka путём добавления строго типизированных входов, выходов и связей между экторами.
Библиотека опубликована на GitHub'е под свободной лицензией (BSD-like).
Как показал опыт эксплуатации SynapseGrid, библиотека позволяет легко конструировать эффективные системы потоковой обработки данных в режиме реального времени.
Всё хозяйство должно было работать в рамках одного экземпляра приложения, но при этом должно было быть несколько вложенных почти независимых очень похожих контейнеров для клиентского кода (типа Bean'ов).
С самого начала мы не ставили задачу всеобщей унификации, и решали в каждой части системы по своему. Где-то использовали потоки для длительных задач, где-то создавали цепочки вызовов, где-то — модель подписки. Так как система была довольно большой, то практически все известные способы декомпозиции и обработки были задействованы в той или иной степени. Потом мы обнаруживали общность и реализовывали похожие решения в разных частях системы. А потом изобрели первую версию того, что сейчас мы называем система контактов или SynapseGrid.
Модульность
Так как мы решали не отдельную прикладную задачу из серии «сделал — забыл», а реализовывали инструментарий, позволяющий решать семейство задач, то одним из принципов разработки был принцип модульности. То есть мы создавали отдельные повторно-используемые компоненты, которые должны были комбинироваться почти произвольным образом, чтобы строить системы для решения любой задачи из семейства.
Потоковая обработка аудио
Когда мы только начинали, мы не очень хорошо понимали, как моделировать аудио-поток. Начали мы с того, что представляли его в форме AudioInputStream. Оказалось, что такое представление не позволяет обеспечить модульности. Т.е. один-то модуль может легко читать из байт-потока с блокировками, и выполнять свою обработку. Но как он передаст данные дальше? Если соединять модули pipe'ом, то придётся каждый малюсенький модуль помещать в отдельный поток выполнения, который будет блокироваться, пока не поступит порция новых данных. Это, понятное дело, было крайне неэффективно.
Потом мы обнаружили, что если аудио-поток разбить на фреймы (кусочки фиксированной длины, по 10-40 мс), то модули гораздо проще соединить. Кусочки аудио могли быть помещены в обычную очередь и очередь можно было проверить без блокировки.
Первичная обработка аудио во многих задачах оказывалась почти линейной. Т.е. модули выстраивались в цепочку, в которой выход предыдущего модуля соединялся со входом последующего модуля. Такую структуру обычно называют pipeline'ом.
Организовать передачу данных можно тремя способами:
1. pull
def getData =
process(previousModule.getData)
2. push
def pushData(d:data) {
val res = process(d)
nextModule.pushData(res)
}
3. functional aggregation
def f(d:data) = {
val r1 = module1.f(d)
val r2 = module2.f(r1)
r2
}
В случае pull, данные «вытягиваются» из последнего компонента, причём цепочка предшествующих компонентов ненаблюдаема и может произойти блокировка из-за нехватки данных в каком-то буфере. При возникновении любого исключения происходит схлопывание всего стека, что приводит к невозможности продолжить работу.
В случае push, данные «вталкиваются» в первый компонент и дальнейшая их судьба остаётся неизвестной. При нехватке данных для буферизации на выходе цепочки ничего не появляется. При возникновении исключения стек снова схлопывается и исключение появляется в самом начале цепочки, где с ним снова непонятно, что можно сделать. Продолжение работы также невозможно. Кроме того, реализация модулей в режиме push довольно неудобна/непривычна для программиста. И обязательно требует наличия side-effect'ов.
Когда мы стали использовать functional-подход, оказалось, что он обладает преимуществами перед pull и push. Во-первых, вся цепочка компонентов видна как на ладони, и может быть легко прослежена. Во-вторых, при возникновении исключения в любом компоненте его легко перехватить, и, что немаловажно, исключение затрагивает только один компонент, и обработку можно продолжить с минимальными проблемами.
Т.к. разработка в то время шла на Java, мы сделали интерфейс для функционального подхода, который должны были реализовывать все модули. Оказалось, что модули принципиально разделились на два вида — те, что всегда обязательно на каждый входной элемент выдавали ровно один выходной элемент, и другие модули, которые могли выдать 0..n элементов на выходе. Модули первого типа (типа
map) хотя и были частным случаем второго типа, но они встречались довольно часто и их интерфейс был проще:trait MapModule[TIn, TOut] {
def f(data:TIn):TOut
}
Модули второго типа (
flatMap) содержали внутреннюю буферизацию, специфичную для модуля, и имели на выходе коллекцию, содержащую 0..n элементов:trait FlatMapModule[TIn, TOut] {
def f(data:TIn):Collection[TOut]
}
Для «прокачки» данных через pipeline можно было использовать две стратегии — depth first или width first.
def widthFirst(d:Data) = {
val r1:Collection[...] = module1.f(d)
val r2 =
for(d1 <- r1; d2 <- module2.f(d1))
yield d2
val r3 =
for(d2 <- r2; d3 <- module3.f(d2))
yield d3
r3
}
def depthFirst(d:Data) = {
for(d1 <- module1.f(d);
d2 <- module2.f(r1);
d3 <- module3.f(d2)
)
yield d3
}
При depth first каждый элемент прослеживался до конца цепочки, а потом обрабатывался следующий входной элемент. При width first все элементы проходили первый этап, потом все полученные проходили второй этап и т.д.
Наиболее общим интерфейсом является 1 -> 0..n (flatMap), поэтому этот интерфейс был взят за основу разработки. Оказалось, что модули, имеющие такой интерфейс, очень легко объединять по принципу функциональной агрегации в более крупные модули, имеющие точно такой же интерфейс. Для линейного pipeline'а получилось, что ничего другого и не требуется.
Модель подписки
В некоторый момент обработка разветвлялась. Одни и те же данные надо было передавать нескольким модулям. Схема, которая хорошо работала для pipeline, здесь создавала проблемы. Во-первых, чтобы данные передавать в несколько мест, надо было иметь алгоритм, в котором явно были прописаны оба продолжения. Во-вторых, при агрегировании цепочки с двумя концами невозможно было обеспечить тот же интерфейс с одним входом и одним выходом.
Мы довольно быстро придумали схему с подпиской на события. Создавался объект Event[T], в который можно было с одной стороны помещать данные, а с другой стороны подписываться на новые данные. Это позволяло обеспечить decoupling модулей. Event был сделан асинхронным и потокобезопасным. Созданная схема очень напоминает библиотеку RxJava (там событие называется Observable[T]).
Модель с подпиской была довольно неплохой и позволяла довольно просто организовать работу в нескольких независимых потоках. Одним из отличий от Observable в нашей схеме было то, что на вход Event'а данные могли поступать из нескольких источников.

Рис.1 Многие-ко-многим, напрямую

Рис.2 Многие-ко-многим по схеме «звезда»
По мере развития проекта количество event'ов возросло и обнаружились ограничения этой схемы.
1. Неизвестно, генерирует ли кто-нибудь данное событие.
2. Неизвестно, подписан ли кто-нибудь на событие.
3. Потоки данных текут ненаблюдаемо — одно событие, обработчик, скрытая внутренняя генерация(?) другого события, другой обработчик и т.д.
4. Если подписка синхронная, т.е. обработчик выполняется в вызывающем потоке, то непонятно, что делать с исключением.
Если подписку обработчика на событие отследить ещё можно, и даже можно нарисовать схему event-подписчики, то связь генератор-событие являлась потусторонней и невозможно было понять, генерирует ли кто-то это событие и при каких условиях.
Akka
К этому моменту Akka у нас уже использовалась для remoting'а и выглядела многообещающе. По-крайней мере, можно было надеяться переложить на Akka многопоточность и решить некоторые проблемы с event'ами.
Акка предлагает легковесного Actor'а, который работает в условно-отдельном потоке, но не потребляет много ресурсов. Условно-отдельный поток означает, что если эктор занят обработкой какого-то сообщения, то никакой другой поток параллельно не будет задействован для обработки других сообщений этим же эктором. Т.е. отдельный эктор обрабатывает сообщения строго последовательно, но при большом количестве экторов оказывается, что все радостно работают параллельно и друг другу не мешают.
Оказалось, что в подходе с экторами связи вообще никак не продуманы и не наблюдаются. Т.е. связи между экторами лежат целиком на совести разработчика и могут расползаться по программе как угодно. Более того, хотя мы теоретически можем отследить судьбу одной ссылки на эктор, однако в Akka предусмотрен способ получения ссылки по текстовому url эктора. Т.е. мы принципиально не можем отследить и ограничить расползание связей в системе.
К чему это приводит? В многопоточной системе с большим количеством похожих экторов и огромным количеством ненаблюдаемых связей периодически возникают малоизученные явления. Например, бесконечный цикл трёх видов: расходящийся, когда в каждой итерации число сообщений увеличивается, монотонный, который просто живёт своей жизнью, отъедает ресурсы процессора, но не приводит к катастрофе, и затухающий, когда количество сообщений медленно убывает. Отладить такую систему is next to impossible. Весьма сложно. В ряде критичных мест нам пришлось пользоваться подходом Model Checking. И всё равно не было полной уверенности, что где-то не циркулируют какие-нибудь сообщения.
Upstart
В Ubuntu некоторое время тому назад появилась система загрузки, основанная на событийной модели (Upstart). Система очень примечательна своим подходом к событиям. Каждое событие имеет имя и может иметь параметры. Обработчики (task'и) могут подписаться на комбинацию событий (с boolean-условиями на параметры) и будут вызваны, если всё сложится. Также обработчики декларативно описывают те события, которые они генерируют (хотя можно любое событие сгенерировать и потусторонним способом).
Эта система описывает так называемую «решётку», или направленный граф (диграф). Узлами решётки являются события, а ветвями — обработчики. В силу встроенного в граф параллелизма upstart позволяет запускать обработчики гораздо раньше, чем это делает система System V, основанная на фиксированных разделяющих слоях (runlevels 0..6). Независимые обработчики спокойно работают параллельно.
Идеи Upstart повлияли на дальнейшую разработку системы контактов.
Система контактов 1-й версии
До тех пор, пока мы рассматриваем картину звезды с одним event'ом (приведённую на рисунке выше), нам не удастся придумать хорошего механизма для организации многопоточной системы. Но если построить направленный граф, то уже прорисовываются интересные перспективы.

Рис.3 Решётка событий и обработчиков
По схеме очень напоминает upstart. Если потребовать, чтобы связи объявлялись декларативно и запретить/исключить неявное создание связей, то весь граф, описывающий работу всей системы, оказывается как на ладони и доступен для статического анализа. Просто наблюдая такой граф, можно обнаружить нежелательные циклы, отсутствующие связи, висящие отдельно Event'ы или обработчики.
В первой версии мы просто несколько обобщили и адаптировали Event[T], но сохранили распределённый («размазанный») механизм передачи сообщений. Наличие графа обработки уже само по себе позволяло понять работу системы и решить текущие проблемы. Но такой «размазанный» механизм передачи сообщений с обязательной буферизацией и защищённо-потокобезопасный, не подходил для решения аналогичных задач в других частях системы. Там требовалось что-то похожее, но более легковесное.
Механизм работы легковесных экторов в Akka
Здесь требуется небольшое отступление о механизме легковесных экторов, который имеет много сходных черт с архитектурой SynapseGrid.
Рассмотрим такой код:
val helloActorRef = actor(new Act {
become {
case "hello" ⇒ sender ! "hi"
}
})
helloActorRef ! "Hello"
Когда мы отправляем сообщение «Hello» эктору, создаётся обёртка вокруг нашего сообщения:
Message(helloActorRef, "Hello")
И это сообщение помещается в очередь. Где-то параллельно работают 16 потоков, которые из этой большой очереди читают сообщения. И есть ещё некий диспетчер, который следит за тем, чтобы с одним эктором не работали два потока одновременно. Поток хватает сообщение, находит эктора и просто выполняет функцию этого эктора на нашем сообщении («Hello»).
Такая схема позволяет существовать миллионам экторов, которые не потребляют ресурсы (кроме чуточки памяти), пока спят. А расход процессорного времени происходит только в 16 потоках и исключительно на обработку реальных данных.
Если посмотреть на пользовательскую модель, то у каждого эктора — своя очередь сообщения и мы командой
! отправляем в эту очередь наше сообщение. То есть выглядит так, будто имеется миллион очередей. А реализуется эта пользовательская модель в форме глобальной очереди и глобальных потоков. Происходит своего рода виртуализация пользовательского представления с помощью эффективного системного представления.В этой схеме actorRef играет роль handle или тега, или метки. Т.е. мы наши данные снабжаем меткой, которая показывает расположение сообщения «Hello» в виртуальном пространстве виртуальных очередей экторов.
Виртуально на миллион экторов мы имеем миллион очередей. Представляете массив из 1000000 очередей, который надо просматривать? В этой виртуальной пользовательской модели всё будет не очень эффективно. А реализуется эта же самая структура с помощью меток, что позволяет получить одну большую очередь, но с метками-тегами. И работать эта очередь будет весьма эффективно.
Ещё одна аналогия, которая приходит на ум, это использование HashMap для хранения огромных разреженных массивов. Как нам для нескольких точек в трёхмерном пространстве сохранить какие-то данные? Пусть размер нашего трёхмерного пространства — 1000х1000х1000. Если хранить массивами, то потребуется 10e9 ячеек. А если использовать метку (x,y,z), то потребуется гораздо меньше памяти. Здесь как раз и работает
HashMap[(x,y,z), data].Система контактов 2-й версии или SynapseGrid
В схеме с размазанным механизмом передачи сообщений связи непосредственно хранились в Event'ах. Это похоже на то, как если бы миллион очередей к экторам сделать на самом деле. А вот если сделать единую коллекцию, где будут находится события и связи, то можно обеспечить эффективный централизованный механизм распределения сообщений.
Итак, для представления событий, на которые можно подписаться, мы вводим понятие контакта,
val contact1 = Contact[T]("Событие1")
а для представления сообщений, связанных с этим контактом, — сигнал.
Signal[T](contact1, data:T)
Как можно видеть, контакт похож на ActorRef, а сигнал — на Message. Отличие заключается в том, что с контактом не связано ни состояние, ни поведение. Это просто некий идентификатор. Если вспомнить аналогию с виртуальной «очередью», то контакт идентифицирует эту очередь.
Т.к. в контакте нет ни данных, ни поведения, то передать в него сообщение просто так невозможно. Это приводит к невозможности создания потусторонних связей, которые обычно возникают внутри обработчиков/хэндлеров. Связи могут быть только декларативными.
Внешнее связывание
В использовании контактов и сигналов, ActorRef и Message мы наблюдаем общий паттерн, который, по-видимому, довольно часто встречается в функциональном программировании. Я называю этот паттерн «внешним связыванием». Идея заключается в том, чтобы не хранить данные в объекте, который используется для адресации этих данных. Вместо этого адрес (ссылка, идентификатор) является immutable структурой, похожей на индекс. А значение хранится где-то ещё или вообще нигде постоянно не хранится. Для получения доступа к данным мы пользуемся какой-нибудьмонадойсистемой, которая управляет нашими данными.
Например, сигнал — это временный объект, который на короткий срок сообщает, что на таком-то контакте находятся такие-то данные. Можно было бы с тем же успехом вместо списка сигналов использовать HashMap или другую структуру, которая нам показалась бы удобной.
Благодаря тому, что в самом контакте данные не хранятся, мы можем, например, оперировать историей «состояния» переменной. Достаточно иметь список сигналов, относящихся к одному контакту. А обработка сигналов для всей системы позволяет построить развёртку во времени всех её «состояний».
Как уже говорилось выше, моделью целой системы является направленный граф. Если внимательно присмотреться, то можно заметить, что это двудольный граф. Но в подавляющем большинстве случаев элементарные обработчики представляют собой map или flatMap компоненты, имеющие один вход и один выход. Поэтому в основу SynapseGrid мы положили более простой граф, узлы которого соответствуют контактам, а дуги связаны с компонентами, осуществляющими обработку данных. Т.е. граф задан совокупностью троек (контакт1, контакт2, обработчик):
Link[TIn, TOut](from:Contact[TIn], to:Contact[TOut],function: TIn=>Collection[TOut])
(здесь мы пользуемся тем, что map-компонеты являются частным случаем flatMap-компонентов).
В описании SynapseGrid приведена интересная метафора макетной платы, хорошо иллюстрирующая идею SynapseGrid.
При появлении данных (сигналов) на каком-либо контакте, мы легко можем определить все обработчики, которые хотели бы обработать эти данные, можем спланировать вызов этих обработчиков в одном или нескольких потоках. Результаты работы, полученные каждым обработчиком, становятся сигналами на выходных контактах, к которым привязаны обработчики, и снова попадают в общую очередь на обработку.
Buider'ы и DSL
Описанный механизм работы предполагает наличие неизменного (immutable) графа, заданного совокупностью троек. Такой граф было бы не очень удобно создавать сразу в одном выражении. Вместо этого оказывается удобно использовать концепцию билдеров, позволяющих шаг за шагом, добавляя отдельные дуги, конструировать граф системы.
Для системы контактов мы разработали DSL
SystemBuilder, который содержит множество методов на все случаи жизни, позволяющих конструировать систему шаг за шагом. val in = input[Int]("in") // input - создаёт контакт и отмечает, что он служит входным контактом подсистемы
val c = contact[Int]("c")
(in -> c).map(_ * 2) // создаёт связь Link между контактами in и c. Связь содержит map-операцию, созданную из функции умножения на 2
val c2 = in.map(_ * 2) // создаёт новый вспомогательный контакт и связь map. Возвращает созданный контакт
Использование стандартных названий методов map, flatMap, filter позволяет воспользоваться Scala-sugar — for-comprehension:
val c2 = for(i <- in) yield i * 2 // делает ровно тоже самое, что и вышеприведённый код для in.map
val c3 = for(i <- in; j <- 0 until i) yield j * 2 //
/* что эквивалентно такой записи:
val temp = in.flatMap(i => 0 until i)
val c3 = cc.map(j => j * 2)
*/
Больше примеров использования DSL — в описании SynapseGrid.
Метаморфозы системы
В SynapseGrid чётко выделяются две фазы — фаза конструирования системы и фаза времени выполнения (runtime). Причём обычно эти фазы не пересекаются. В работающую систему невозможно просто так добавить новые элементы. Похожее явление происходит, например, в Guice — модули создаются сначала, а потом по описанию, содержащемуся в модулях, конструируется работающая система.
Код, который конструирует систему, пользуется API Builder'а. А код, который работает в реальной системе, ничего не знает о контактах и сигналах. Он просто обрабатывает приходящие данные и возвращает результат выполнения.
Треллис, дискретное время, синхронизм и детерминизм
Одной из особенностей Akka и других подходов на основе экторов является то обстоятельство, что порядок обработки сообщений разными акторами не определён и отдан на волю случая. Скорее всего, это приводит к выигрышу в производительности, но также отрицательно сказывается на предсказуемости работы системы.
Поскольку непредсказуемость для нас гораздо хуже, чем недоиспользование потенциала процессора, мы решили в основных режимах работы обеспечивать гарантии детерминированности последовательности сигналов. (А более производительный, но менее детерминированный режим работы использовать только для оптимизации в редких случаях.)
Все сигналы погружаются в дискретное время и упорядочиваются внутри каждого временного слота. В начальный момент времени имеется один сигнал на входном контакте. Переход от одного момента времени к другому происходит только тогда, когда все сигналы текущего момента времени обработаны. Порождаемые сигналы упорядочиваются так, как если бы обработчики вызывались строго последовательно (в однопоточном режиме так оно и есть, а в многопоточном сигналы упорядочиваются принудительно).
Если посмотреть на совокупность сигналов в каждый момент времени, то получающаяся картинка называется треллис и применяется, например, в алгоритме Витерби.
Поскольку вся обработка происходит централизованно, никто не мешает нам такую картинку нарисовать и проанализировать прохождение сигналов.
Если граф разветвляется, то можно довольно просто гарантировать синхронность появления сигналов на заданных контактах. Если альтернативные цепочки имеют разную длину, то синхронность обеспечивается очень просто — добавлением нескольких пустых стрелочек («линий задержки»).
Подсистемы
Созданная система контактов замечательно заменяла pipeline и подписки на события. И постепенно на эту систему были переведены многие компоненты системы. Однако для объединения нескольких систем, необходимо было предусмотреть возможность существования компонентов с несколькими входами и несколькими выходами. В отличие от компонентов-двухполюсников, аналогами которых являются обычные функции, аналогов для многоконтактных компонентов мы не нашли.
Выход был найден в использовании всё тех же меток для различения входов между собой и выходов между собой. Компонент, представляющий подсистему, получил такую сигнатуру:
type Component = Signal => Collection[Signal]
Т.е. данные, которые мы хотим отправить на вход in1, оборачиваются в Signal и помечаются контактом in1. Данные, появляющиеся на выходе out1 представляются
Signal(out1, data).С точки зрения треллиса родительской системы вся обработка в дочерней подсистеме происходит за один временной шаг. Внутри подсистемы создаётся свой треллис.
Параллелизм
Подсистема оказалась хорошим претендентом на выполнение в отдельном потоке и мы первым делом реализовали механизм, позволяющий любую подсистему выделить в отдельный Akka-эктор.
Такая схема позволила закрыть 90% всех потребностей в многопоточности. Akka гарантирует, что в пределах одного эктора всё происходящее можно считать однопоточным. А SynapseGrid позволил объединять любое количество экторов в связанную систему с наблюдаемыми связями. У экторов, построенных на основе подсистем, отсутствует прямая возможность создания потусторонней связи с другой подсистемой. Картина мира становится гораздо прозрачней.
Преимущества системы экторов на SynapseGrid
Экторы, которые создаются в SynapseGrid, обладают определёнными преимуществами по сравнению с обычными структурами экторов, которые создаются в Akka вручную. А именно:
1. Строго-типизированный обмен данными. Верификация на стадии компиляции (конструирования).
2. Наличие нескольких строготипизированных входов и выходов.
3. Наличие явных выходных связей и возможность отследить, куда передаются выходные сообщения эктора.
4. Возможность отрисовки полной картины системы, состоящей из большого числа экторов и связей между ними.
Однако остались ещё 10% потребностей в многопоточности, которые не давали нам покоя. А именно, если нам требовалось обеспечить параллельную обработку массы однотипных данных с помощью одного компонента, экторы на основе подсистем буксовали. Они обрабатывали данные строго последовательно.
Тогда было решено сделать свой планировщик, который будет загружать работой 16 потоков ExecutorContext'а согласно семантике SynapseGrid. Библиотека synapse-grid-concurrent позволяет полностью выполнять систему произвольной вложенности на пуле потоков и при этом гарантирует детерминизм однопоточного варианта.
Заключение
SynapseGrid позволяет строить модульные системы, выполняющие срочную (ASAP) обработку данных без лишней буферизации. В основе библиотеки лежит функциональный подход, внешнее связывание и декларативный подход. Система собирается с помощью развитого API Builder'а в режиме конструирования. А в режиме исполнения система является немодифицируемой (immutable).
Выполнение логики обработки данных может осуществляться в одном или в нескольких потоках с гарантией получения идентичных результатов. SynapseGrid расширяет возможности Akka путём добавления строго типизированных входов, выходов и связей между экторами.
Библиотека опубликована на GitHub'е под свободной лицензией (BSD-like).
Как показал опыт эксплуатации SynapseGrid, библиотека позволяет легко конструировать эффективные системы потоковой обработки данных в режиме реального времени.
