 Не знаю, как вы, я лично обожаю заниматься оптимизацией производительности программ. Я люблю, когда программы не тормозят, а сайты открываются быстро. В этой статье я бы хотел привести некоторые (базовые) подходы к улучшению производительности. В основном, они относятся к веб-приложениям, но некоторые вещи справедливы и для «обычных» программ. Я затрону такие темы, как профилирование, пакетная обработка, асинхронная обработка запросов и др. Этот топик можно считать продолжением «Стратегии оптимизации веб-приложений с использованием MySQL.
Не знаю, как вы, я лично обожаю заниматься оптимизацией производительности программ. Я люблю, когда программы не тормозят, а сайты открываются быстро. В этой статье я бы хотел привести некоторые (базовые) подходы к улучшению производительности. В основном, они относятся к веб-приложениям, но некоторые вещи справедливы и для «обычных» программ. Я затрону такие темы, как профилирование, пакетная обработка, асинхронная обработка запросов и др. Этот топик можно считать продолжением «Стратегии оптимизации веб-приложений с использованием MySQL.Когда следует оптимизировать?
Самый первый вопрос, который нужно себе задавать перед тем, как заняться оптимизацией чего-либо — устраивает ли вас текущая производительность? Например, если вы разрабатываете игру, каков минимальный FPS на «среднем» железе и «средних» настройках? Если он опускается ниже, скажем, 30, то игроки это заметят. Даже если средняя частота кадров составляет 60 FPS, именно минимальное значение FPS определяет ощущения от игры — «тормозит» или «работает плавно». Если это веб-сайт, сколько времени открываются страницы для пользователей? Если это время составляет доли секунды, пользователи будут более активны и будут получать удовлетворение от работы с вашим сайтом.
Допустим, вы поняли, что вас (или ваше начальство, хехехе) не устраивает текущая производительность приложения. Что делать?
1. Измеряйте
Любая оптимизация должна начинаться с цифр. Если у вас нет времен исполнения отдельных фрагментов приложения, вы не можете заниматься оптимизацией эффективно. Вы можете долго оптимизировать фрагменты, которые вам проще оптимизировать, чем те, которые действительно тормозят, потому что у вас нет полной картины происходящего.
При разработке зачастую бывает удобно использовать профайлинг для выявления узких мест. Для PHP, к примеру, есть хороший профайлер под названием xhprof от компании Facebook (про него здесь неоднократно писали). Если у вас есть большой и незнакомый для вас проект, то профайлер — это практически единственная возможность быстро найти узкие места в коде, если такие там есть. Однако, «обычный» профайлер во время повседневной разработки редко применяется, сразу по нескольким причинам:
— даже самые «хорошие» профайлеры существенно замедляют работу приложения
— за результатами нужно идти в отдельное место или запускать отдельные просмотрщики
— сами результаты нужно где-то хранить (данные профилирования обычно занимают ощутимое количество места).
По этим (и, возможно, некоторым другим) причинам в качестве замены отдельной утилите для профилирования при веб-разработке встраивают так называемые «дебаг-панели» в development-версии сайта (пример), в которых приводится сводка (с возможностью посмотреть детали) различных метрик, которые встроены прямо в код. Обычно это количество и время исполнения SQL-запросов, реже встречается количества и времена исполнения запросов к другим сервисам (например, к memcache). Почти всегда измеряется также общее время исполнения, размер ответа с сервера, количество потребляемой памяти.
В большинстве игр можно включить «отладочную консоль», в которой, как правило, можно видеть количество FPS, количество объектов на сцене и т.д. До относительно недавнего времени в minecraft содержалась диаграмма с распределением времени для каждого кадра: одним цветом рисовалось время, затраченное на «физику», другим — рендеринг.
Можно измерять очень много различных вещей, но для веб-проектов обычно основное время занимает база данных или обращения к другим сервисам. Если вы не используете какой-то готовый фреймворк, или в ваш любимый фреймворк не входит дебаг-панель, достаточно даже такого кода для того, чтобы с чего-то начать:
<?php
function sql_query($query) {
$start = microtime(true);
$result = mysql_query($query);
$GLOBALS['SQL_TIME'] += microtime(true) - $start;
return $result;
}2. Я сказал, измеряйте!
Вы молодец, всё обвесили таймерами, в development-окружении всё чудесно, но на production всё по-другому? Значит, вы измеряете неправильно или, что более вероятно, не всё… Как насчёт того, чтобы измерять производительность на production? Если вы пишете, к примеру, на PHP, существует замечательный инструмент для измерения производительности в production-окружении, работающий по протоколу UDP, под названием Pinba. На основании этого инструмента можно оставить debug-панель при разработке и в дополнение получить realtime-статистику по вашим таймерам в «боевом» окружении. Если вы никогда не измеряли производительность таким способом, вы скорее всего узнаете очень много интересного о том, как на самом деле работает ваш сайт.
Время отдачи страницы с сервера — 100 мс, но вам всё равно жалуются, что страницы открываются долго? Измеряйте размер отдаваемых данных и показатели встроенных в браузер счётчиков производительности. Возможно, вашему сайту нужен CDN для отдачи статических данных, возможно нужно просто сменить хостинг-провайдера. Пока вы не измерите, где бутылочное горлышко, вы можете лишь гадать.
3. Будьте ленивы
Часто можно обнаружить, что в коде на каждый чих происходит инициализация чего-нибудь большого и ненужного на этой странице. Например, какой-нибудь большой init-метод, который на каждый веб-запрос лезет за прогнозом погоды на другой сайт или выполняется «git pull origin master» в корне проекта, как средство автоматического деплоя. В процессе анализа производительности вы обязательно натолкнетесь на много вещей, которые можно просто выкинуть из кода, или «завернуть в if», и включать нужный кусок только тогда, когда он действительно требуется.
Очень часто встречается, что большые фрагменты страницы остаются практически неизменными (например, «шапка» и «подвал» страницы). Если это так, то очевидным решением является либо заранее сгенерировать содержимое, либо поместить его в кеш и не рисовать его каждый раз по новой.
Будьте ленивы в своем коде и в реальной жизни. Не делайте одну и ту же (никому не нужную) работу постоянно, делайте только то, что действительно нужно для ответа на запрос пользователя, а остальное либо не делайте, либо делегируйте кому-нибудь (например, можно «тяжелые», но не очень чувствительные к задержкам, вещи поручить cron'у вместо того, чтобы исполнять это в вебе).
4. Используйте (асинхронную) пакетную обработку
В самых разных проектах можно встретить одну и ту же тривиальную ошибку проектирования: обработку десятков, сотен записей, по одной, вместо того, чтобы обрабатывать всё вместе, единым запросом. Например, если на странице вам нужно показать данные по 30 товарах, сделайте один запрос вида «SELECT … FROM table WHERE id IN(...)» вместо 30 запросов вида «SELECT … FROM table WHERE id = ...». Для большинства баз данных разницы в скорости между одним запросом с результатом на 30 строк и одним (!) запросом с результатом на 1 строку не будет вообще. Как правило, нужно совсем небольшое количество изменений в коде для того, чтобы добавить пакетную обработку, а взамен вы получите прирост скорости в разы, иногда в сотни раз. Это касается не только SQL-запросов, но и любых обращений к внешним или внутренним сервисам. Обращение по сети куда-либо всегда вносит существенную задержку в обработку запроса, поэтому количество запросов крайне желательно уменьшать до минимума в условиях веба.
Ещё одна возможность ускорить пакетную обработку — это асинхронность. Если ваш язык это позволяет и вы можете сгруппировать запросы к разным сервисам в один и выполнить их асинхронно, то вы тоже получите ощутимое уменьшение времени ответа, причём чем больше сервисов, тем больше выигрыш. Это слабо применимо к MySQL, но хорошо применимо при работе, скажем, с медленным Google Datastore API.
5. Упрощайте сложное, распутывайте запутанное
Приведу пример: у вас есть здоровенный SQL-запрос, который что-то делает, и делает это (возможно) правильно, но ооочень медленно, сканируя при этом миллионы строк. Чтобы оптимизировать сложный SQL-запрос, для начала нужно его упростить, выкинуть оттуда всё лишнее, возможно, целые таблицы или вложенные выборки. Лишь после того, как вы убрали всё лишнее, можно начать проводить осмысленную оптимизацию. В противном случае, вы можете потратить много времени впустую, оптимизируя фрагмент, который никак не влияет на конечный результат. Часто, особенно при работе с MySQL, в качестве удовлетворительного решения может быть разбиение запроса на несколько более простых, каждый из которых работает намного быстрее исходного.
В системах, которые разрабатываются большим количеством людей, часто можно увидеть «наслоения костылей» вместо четкого и хорошо проектированного кода. Такое происходит не только при низкой квалификации программистов, но и при обычной, итеративной разработке, при условии отсутствия постоянного рефакторинга. Если вы обнаружили, что проблема таится в одном из таких мест, для начала нужно провести небольшой рефакторинг кода, чтобы, во-первых, разобраться в том, как оно работает, а во-вторых, возможно сразу оптимизировать или выкинуть некоторые очевидно лишние вещи. Часто бывает так, что, после простого приведения кода в порядок, производительность кода становится удовлетворительной и соответствующий фрагмент перестает требовать оптимизации.
6. «Дорогие» фичи
Вполне возможна ситуация, когда вы обнаружите, что есть фичи, которыми пользуется 0,1% пользователей, но которые при этом занимают половину времени ответа на сервере. Если это так, то вы можете либо попробовать переосмыслить эту функциональность и предложить какое-то другое, более «дешевое» решение взамен, либо сделать эту фичу опциональной и отключенной по умолчанию. Если пользователю она нужна, он её включит обратно.
7. Кеширование
Если вообще больше ничего не помогает, или у вас есть данные, которые не меняются со временем, кешируйте их. Почему я утверждаю, что стоит использовать кеш только тогда, когда все другие опции израсходованы? Дело в том, что как только вы начинаете класть в кеш изменяемые данные, вы должны будете следить за актуальностью кеша, что является очень сложной инженерной задачей.
Пример: вы кешируете отдельные записи в таблице table по первичному ключу id. Одна запись — один ключ в кеше вида «table_<id>». Представьте теперь, что вам нужно обновить несколько записей по определенному условию («update table where <condition>»). Как правильно сбросить кеш в этом случае? Одно из простых, но очень трудоёмких решений — это делать предварительную выборку по этому условию, сбрасывать все записи в кеше по id и потом делать update. А что, если между select, сбросом кеша и update «вклинится» другой запрос? Примерно вот так:
| Первый запрос: 1. select id from table where <condition> 2. memcache delete ids 6. update table set … where <condition> |
Второй параллельный запрос: 3. memcache get «table_N» — пусто, кеш уже сброшен 4. select … from table where id = N 5. memcache set «table_N» — устанавливаем старые данные в кеш |
Наличие двух источников данных вместо одного без очень аккуратно написанного кода неизбежно приводит к их рассинхронизации и, в случае кеша, к неприятным артефактам на сайте в виде несогласованных между собой или устаревших данных, «битых» счётчиков и т.д.
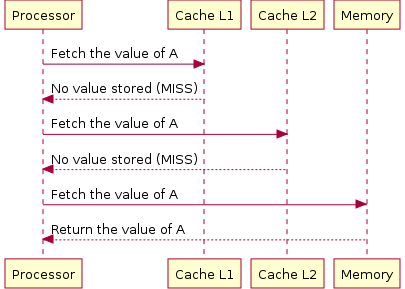 Безусловно, есть большое количество примеров, когда кеширование успешно применяется для увеличения производительности, но, опять же, после рассмотрения всех остальных возможностей. В операционных системах операции по работе с медленными носителями кешируются (чтение просто кешируется, запись буферизуется, что иногда приводит к порче данных или структуры файловой системы). Это дает ощутимый вклад в скорость работы, но, если вы когда-нибудь сравнивали user experience от работы с SSD и с жестким диском, вы никогда больше не захотите пользоваться последним, несмотря на кеширование :). В процессорах используется много уровней кеша, поскольку память различного объема отличается по скорости работы на порядки (сравните время доступа порядка 1 нс к регистровой памяти и 10 мс для жесткого диска — разница в 10 млн раз!), поэтому значительное усложнение архитектуры всё равно оправдано (иллюстрация взята из википедии).
Безусловно, есть большое количество примеров, когда кеширование успешно применяется для увеличения производительности, но, опять же, после рассмотрения всех остальных возможностей. В операционных системах операции по работе с медленными носителями кешируются (чтение просто кешируется, запись буферизуется, что иногда приводит к порче данных или структуры файловой системы). Это дает ощутимый вклад в скорость работы, но, если вы когда-нибудь сравнивали user experience от работы с SSD и с жестким диском, вы никогда больше не захотите пользоваться последним, несмотря на кеширование :). В процессорах используется много уровней кеша, поскольку память различного объема отличается по скорости работы на порядки (сравните время доступа порядка 1 нс к регистровой памяти и 10 мс для жесткого диска — разница в 10 млн раз!), поэтому значительное усложнение архитектуры всё равно оправдано (иллюстрация взята из википедии).Заключение
Итак, мы рассмотрели базовые способы повышения производительности (веб-)приложений, в основном рассматривая связку PHP+MySQL, как наиболее распространенную. Я лично использую приведенные выше подходы при оптимизации, и пока что мне удавалось без особых усилий ускорять проекты во много раз, иногда в десятки раз, потратив буквально несколько дней для самого большого из них :). Надеюсь, статья если не научит вас оптимизации, то по крайней мере подтолкнет вас (и ваших коллег) в правильном направлении, и мир станет чуточку лучше.
* Первая иллюстрация взята с этой страницы (по мнению гугла)
