
Connection establishment…
Просматривая результаты (довольно таки неутешительные) очередного экзамена на INTUIT-e, я в сотый раз задался вопросом «Ну почему опять этот вопрос не верно?! Ведь на 100% был уверен в ответе…». Проявив толику малодушия, я решил поискать правильные ответы на тесты и был сильно удивлен их отсутствием в открытом доступе. Кое что безусловно было, но это в основном была замануха вида «10 случайных ответов бесплатно, а за остальное будьте добры перечислить нам денежку». Деньги там не большие, но платить за ответы не хотелось и я решил пойти другим путем.
Первой шальной мыслью было попробовать поискать баги на сайте, но я быстро от нее отказался, потому что пришла следующая. Я вспомнил, что в былые времена INTUIT продавал диски с локальной версией своего сайта, которая позволяла проходить обучение без подключения к интернету и в т.ч. сдавать экзамены. Результаты потом можно было синхронизировать при подключении. Далее в мозгу возникла логическая цепочка «Можно проходить тесты offline => проверка производится тоже в offline => где-то там лежит файл с ответами».
Какие-то 4.5Гб отделяли меня от моего счастья и решения всех моих дилемм! Диск был найден довольно быстро на каком-то трекере и поставлен на закачку. От скуки начал читать комментарии. Среди россыпи благодарностей кто-то спрашивал: «а там же можно ответы посмотреть?». Ему так и не ответили, но меня тогда это совершенно не насторожило. И вот образ скачан и установлен (ставился он довольно долго). Посмотрим что тут у нас.
Погружение
Внутренняя структура корневого каталога выглядела следующим образом:
html
lib
local_web_server
intu32.ico
INTUIT.exe
intuit.ini
trayicon.ico
uninstall.exe
Как-то сразу меня потянуло в папку lib. И верно потянуло. Куча *.pm файлов и пара каталогов с интересными названиями «course» и «test». Заглянув в папку test и изучив ее содержимое я понял, что я ничего не понял. В ней лежало 3 .pm файла, которые, как вы уже наверное догадались, оказались perl-пакетами. Надо сказать, что я совершенно не гуру перла. Писал на нем что-то когда-то для экспериментов, но то дела давно минувших дней. Система же, которая попала ко мне в руки, была полностью написана на перле. Но это не повод сдаваться и раскопки были продолжены.
В директории course оказалось много файлов с названиями очень похожими на сокращенные называния курсов. Как же найти тот, который мне был нужен? Пора, видимо, запустить ярлык с рабочего стола и посмотреть, что нам там предлагают. Через некоторое время после запуска стартовал браузер по умолчанию и загрузил страницу по адресу localhost:3232. Занятно. Значит где-то внутри этого вигвама все таки обитает полноценный апач или на худой конец какой-нибудь денвер. Но об этом позднее.
Залогинившись под admin:admin я решил попробовать сдать экзамен по нужному мне курсу что бы посмотреть как вообще вся эта система работает. Отметив ответы на вопросы и нажав на кнопку отправки формы я увидел следующий текст: «Вы набрали {n}% баллов. Правильно решили {m} задач из {k}.» И тут взгляд упал на строку браузера в которой был указан путь к курсу, но не в каталог lib, а в каталог html. Там же было сокращенное название курса. Кажется похожий файл я уже видел… Бегом в каталог lib/courses, открываю oopbase.pm и вижу несколько процедур, какой-то хеш массив %lecture, а вот ниже картина гораздо интересней! Вот он красавец! Хеш массив %test со всеми вопросами, а так же вариантами ответов. «Все задача решена!» подумал я в тот момент, но по ходу изучения этого хеша, красивая розовая птица Обломинго все более навязчиво стучалась мне в окно… Ответов не было. Хеш очень большой, поэтому привожу его кусок, который представляет интерес:
830 =>
['830','50','5',"16ab48786a5d520fe6eeea7f1a6e140b",
[['5708','830','1','10',"7ce21606425e2b20e566f422696b92de",
[['16692','5708','1','1',"Корректность программы – это понятие","e9b0b5d2f98bf71489891a48f80cb868",
"387b3b67d9c1248131c136eae3e6cab9",
[['349301','16692','1',"неформальное",],
['349302','16692','2',"которое можно определить, используя только термины самой программы",],
['349303','16692','3',"которое можно формализовать триадой Хоара",],
['349304','16692','4',"для формализации которого необходимо задание спецификации",],],],
Ключ 830 это как раз то значение, которое ставилось в соответствие ключу из хеша %lecture. Заодно привожу и его часть:
my %lecture = (
11 => 830,
7 => 826,
17 => 836,
2 => 821,
1 => 820,
…
);
Теперь становиться понятным, что вопросы которые соответствуют ключу 830, относятся к 11-й лекции. И это единственное, что стало понятным на тот момент. Поскольку больше умных мыслей про этот файл у меня не было, было решено пойти в обход, как делают все нормальные герои. Путь мой лежал к дальнейшему изучению файловой структуры, авось найдется та самая таблица ответов. Я даже придумал как она могла бы выглядеть. Таблица найдена не была, зато внимательное изучение каталога lib привело меня по цепочке test.pm => etest.pm к довольно занятному файлу ext.pm который содержал процедуры:
sub check_answer_exam
sub check_answer_exam_extern
sub check_answer
Которые в свою очередь вызывали одноименные процедуры из пакета “er”. Пакет был довольно быстро найден и анализ его содержимого показал, что он через XSLoader подгружает библиотеку er.dll, которая лежала недалеко (а рядом лежала точно такая же, но под *nix c расширением .so). Картина начала вырисовываться, и я пошел смотреть таблицу экспорта этой библиотеки.
We need to go deeper!

Таблица экспорта убила во мне все чувство прекрасного. Там содержалась одна функция boot_er. А как же check_answer и прочие плюшки… Дело начинало пахнуть керосином и требовало контрмер: хорошего чая и IDA Pro!
Оказалось, библиотека не так проста как кажется и содержит в себе целую кучу всяких процедур, да и еще вдобавок имеет интересную таблицу импорта. Помимо вполне привычных импортов из KERNEL32 и msvcrt, я увидел целую кучу функций из библиотеки perl58.dll и все бы, наверное, было не так занятно, если бы эти функции легко находились в гугле. Но они не находились.
Может, это все от недостатка перлового опыта и я не знаю как искать подобные функции, но исчерпывающего описания я нигде не нашел. Только обрывки информации на форумах. Идем дальше. Смелое нажатие Shift+F12 показало много потенциально интересных вещей.
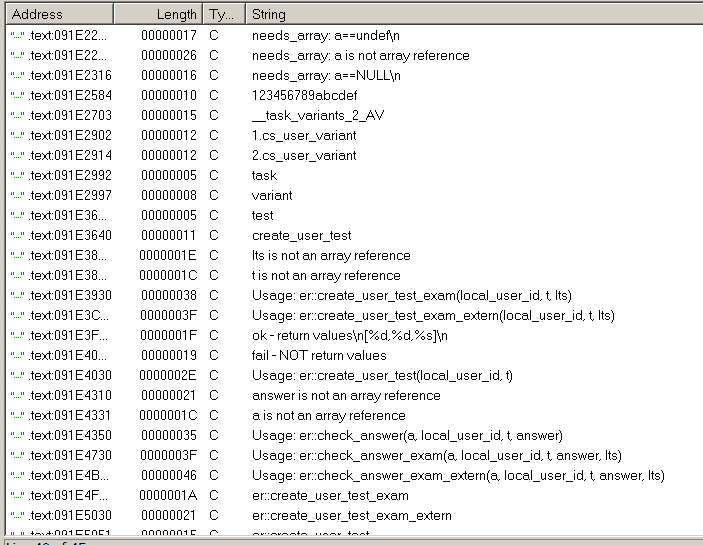
В частности, строка Usage: er::check_answer(a, local_user_id, t, answer) натолкнула меня на мысль о вызове этой библиотеки из собственного perl-скрипта. Единственная загвоздка была в формате входных данных. Поковырявшись в скриптах, с помощью которых осуществлялось тестирование, я увидел несколько вызовов print, которые меня заинтересовали. Выводились значения не в какой-то лог-файл, а прямо на консоль. Логично предположить, что это консоль web-сервера и дело оставалось за малым: найти эту консоль.
Осмотр каталога «local_web_server» показал, что никаким апачем и даже денвером там никогда не пахло. Сервер был написан на perl и предоставлялся в двух вариантах «server_unix.pl» и «server_win32.pl», а главный запускной файл «intuit.exe» который лежит каталогом выше, как раз и запускал все это хозяйство на что указывали следующие строки полученные с помощью IDA из этого файла
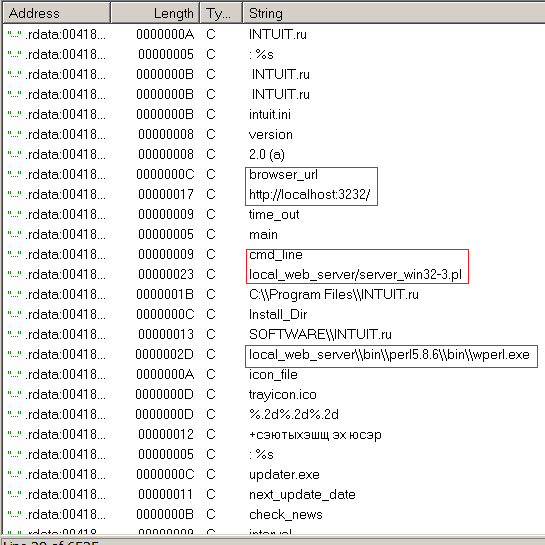
Отлично, значит можно все это запустить вручную и посмотреть, что там пишется в STDOUT. Выбрав первый тест в нужном мне курсе и отметив правильные ответы, я нажал на кнопку отправки и увидел следующий консольный вывод.

А вот и первые печеньки! Разберем значения, которые представляют практический интерес:
- 820 – идентификатор теста, который соответствует первой лекции (исходя из хеш массива %lecture)
- tasks => 4 – это количество верно решенных задач.
- answer => [348966, 349080, 63232, 63234, 53240] – массив отмеченных мною вариантов ответов.
Числа в массиве answer это идентификаторы ответов которые были рассмотрены ранее в массиве %test.
Осталось получить параметры вызова функции er::check_answer(). В файл etest.pm был добавлен вызов функции print, в которой с помощью Data::Dumper в файл записывалось содержимое массива param, который и передавался в функцию. Привожу кусок кода:
if($type eq 'lecture') {
open(F, ">>D:\param.txt");
print F Dumper(@param);
close(F);
($mtime,$csa,$tasks,$points,$mark) = test::ext::check_answer(@param);
}
Далее на основании полученных данных я набросал скрипт следующего содержания:
#!/usr/bin/perl -w
require test::ext;
@var1 = [
1388075531,
'8647ee8932669c9e0a00827bb82957d2',
[
[
5658,
16542
]
# тут еще 4 таких же массива как выше, но с другими идентификаторами разделов и вопросов.
];
$var2 = '57d0c0e0304de48376b064b86cd36bc1';
@var3 = [ … ]; # Все варианты вопросов и ответов к этой лекции
$var4 = ['348973', '348975'];
my @param = (@var1, $var2, @var3, $var4);
my ($mtime,$csa,$tasks,$points,$mark);
($mtime,$csa,$tasks,$points,$mark) = test::ext::check_answer(@param);
print "Tasks: " . $tasks;
Разберем что тут происходит. В var1 содержатся те вопросы которые были заданы в текущем тесте всего там 5 массивов вида [int id раздела, int id вопроса]. Переменная $var2 содержит хеш-идентификатор пользователя, который проходит тест. Нужен скорее всего для сохранения результатов теста. Хеш @var3 содержит точную копию значения из массива %test, которое можно получить по ключу-идентификатору лекции. И наконец, массив $var4 содержит выбранные мною варианты ответов. В приведенном выше скрипте я оставил только ответы на первый вопрос, чтобы было проще тестировать.
Запуск скрипта порадовал строкой «Tasks: 1», а это означало, что я на верном пути. Сразу возникла мысль по написанию простейшего брутфорса, который бы формировал различные варианты массива $var4 и проверял бы $task на равенство единице. Так бы и закончилась эта история, если бы не переполнявший меня интерес и желание узнать насколько же все таки глубока кроличья нора.
Wake up, Neo… The Matrix has you…
Изучив еще раз таблицу импорта в IDA, было решено начать с функции strncmp. Запустив под отладчиком свой тестовый скрипт (код которого приведен выше) и оттрассировав программу до загрузки библиотеки er.dll, я открыл список используемых ею функций и поставил точку останова на импорт strncmp. После перезапуска скрипта, отладчик радостно сообщил «Break point at msvcrt.strncmp», а в стеке лежали сравниваемые строки:

Это был хеш из массива var1 и я решил посмотреть, откуда вызывается эта функция. Нажав Ctrl+F9, а потом F8, я начал трассировать программу дальше. По ходу трассировки я опять оказался внутри strncmp, которой передавались две строки вида «57f260a2606af344753ffc00ad834581». Этот хеш мне был смутно знаком и, посмотрев код скрипта, я убедился, что это хеш, относящийся к одному из вопросов. А вот это было уже теплее! Нажав F9 и опять попав в функцию сравнения, я был немного озадачен теми параметрами, которые увидел в стеке:

Строка «e8c178abd4f1114837d00771871b6379» была хешем относящимся к другому вопросу теста, а вторая мне была не знакома. Продолжив запуски, я составил список из 6-ти вызовов функции сравнения. Вот они:
| Вызов | Хеш #1 | Хеш #2 |
|---|---|---|
| 1 | 8647ee8932669c9e0a00827bb82957d2 | 8647ee8932669c9e0a00827bb82957d2 |
| 2 | 57f260a2606af344753ffc00ad834581 | 57f260a2606af344753ffc00ad834581 |
| 3 | e8c178abd4f1114837d00771871b6379 | 0f4632529bff4a4ebab04b5794c1518a |
| 4 | 9ffcabf80ad0aea2ec7b8c7b89051c29 | 46916f5f972e01efa665f6cf2245f071 |
| 5 | 3f2fd6dc285372ee847ee9837718f0df | a95478bfb5af215aa268d21b498b493c |
| 6 | 7f29edf5e4fad4e5782ffd36512cc6b7 | a2401e9ad6086aa57ea59b61ec0d55d2 |
Вызовы со 2-го по 6й содержали в качестве первой строки хеши, которые я на тот момент обозвал «идентификаторами вопроса». При этом в том вопросе, на который я ответил верно, хеши совпадали. Значит, тут была какая-то зависимость. Изменив в скрипте массив $var4, я окончательно в этом убедился, увидев вместо «57f260a2606af344753ffc00ad834581» совершенно другой хеш: «859c6288692d7037035a011ba54597aa». Теперь предстояло понять, откуда же берутся эти хеши.
Перейдя к вызову функции, я поставил точку останова на начало передачи параметров и, убрав все остальные точки, я перезапустил скрипт.

Как видно из кода, адрес, по которому лежит хеш, хранится в EAX, что подтверждал дамп памяти.

Дело за малым — выяснить кто его туда положил.
Дальнейшее изучение алгоритма показало, что для каждого вопроса формируются строки вида
asdc*a*<id_вопроса>*a*<id_варианта_ответа_1>…*a*<id_варианта_ответа_N>, которые хешируются алгоритмом md5 и сверяются с тем хешем, который ранее я ошибочно назвал «идетификатором вопроса». На самом деле это оказался хеш-идентификатор правильного ответа. Шах!
И мат!
Оказалось, что идея с написанием брутфорса ответов была не такой плохой, как мне показалось вначале. И хотя я все равно к этому пришел снова, этот брутфорс уже совершенно другого качества. Я не буду приводить полный код, рассмотрю лишь основные его моменты.
Дабы не оскорблять чувства верующих в perl (я думаю им хватило моего чудо-скрипта), реализовывать брутфорс я буду на C#, который, как известно, все стерпит. Разбор файлов с курсами было решено проводить с помощью регулярных выражений. Критикам этого подхода я хочу сразу сказать: Можете сделать лучше? Делайте. А мне удобнее так.
Интерес в файле курса представляют следующие блоки данных:
- хеш-массив номеров лекций и их идентификаторов
- списки вопросов к каждой лекции
- варианты ответов к вопросам
Первый хеш массив можно получить достаточно простым регулярным выражением:
(?<lnum>\d+)\s=>\s(?<lid>\d+)
Далее разберем получение вопросов из курса. Для этого я применил следующее регулярное выражение:
\['(?<tid>\d+)','\d+'(?:,'\d'){2},"(?<ttext>.*?)","(?<ahash>[a-f0-9]*)","[a-f0-9]*",(?<avars>\[{2}.*?(?:,\]){2})
Оно может показаться сложным на первый взгляд, но на самом деле в нем тоже нет ничего сверхъестественного. Именованные группы содержат:
- tid — идентификатор вопроса
- ttext — текст вопроса
- ahash — хеш правильного ответа
- avars — варианты ответов в необработанном виде
Парсинг необработанных вариантов ответов осуществляется следующим выражением:
'(?<aid>\d+)'.*?"(?<atext>.*?)"
Именованные группы содержат:
- aid — идентификатор варианта ответа
- atext — текст вопроса
Непосредственно брутфорс ответов в данном случае является комбинаторной задачей о нахождении всех подмножеств заданного множества. Генерация подмножеств была осуществлена с помощью двоичного кода, что демонстрирует следующий алгоритм:
int SetPower = (int)Math.Pow(2, answers.Count);
for (int i = 1; i < SetPower; i++)
{
string aStr = "";
answers.ForEach(x => x.Valid = false);
for (int j = 0; j < answers.Count; j++)
{
if ((i & (1 << j)) != 0)
{
aStr += "*a*" + answers[j].AID;
answers[j].Valid = true;
}
}
string answerString = "asdc*a*" + task.TID + aStr;
if (GetMD5Hash(answerString) == task.TrueAnswerHash)
{
return answers.Where(w => w.Valid == true).ToList();
}
}
На каждом проходе алгоритма формируется подмножество вариантов ответов, из которых собирается строка для хеширования. После получения хеша она сравнивается с эталонным, и в случае совпадения возвращается множество правильных ответов.
Connection terminated…
Так и закончилась эта история о борьбе за знания. Знания это та вещь которая добывается только трудом и любые знания полученные бесплатно (в широком смысле этого слова) не стоят ровным счетом ничего. Благодарю НОУ «ИНТУИТ» за их ресурс в целом и за те приятные моменты, которые они мне доставили своей магической библиотекой er.dll в частности.
Дополнительные материалы к статье
Perl-cкрипт использованный мной для отладки
Консольный брутфорсер ответов
