Недавно тут была статья, в которой рассказывалось о попытке обхитрить биткоин, используя нейросеть. Я пошел другим путем, и у меня из этого практически-полезного результата не получилось, но несмотря на это, свой опыт я не считаю полной неудачей. Во-первых, не считаю потому, что глупо надеяться просто взять и взломать биткоин, а во-вторых потому, что ожидаемый результат был получен, а значит можно утверждать, что кое-каких успехов я все же добился. И поэтому, я решил поделиться наработками с читателями хабра.
Считается, что некоторые функции, в обратную сторону не работают. Википедия в статье оперирует таким понятием, как «вычислительная невозможность». В одном из каментов приводили как пример функцию
X = A MOD B
Кто-то может скажет, что эта функция в обратную сторону нерешаема. Я считаю, что это функция очень даже решаема, просто в обратную сторону она выдает бесконечное множество пар (A,B), если нам известно «В», то решением будет бесконечное множество возможных чисел «А». Не совсем то, что нам хотелось бы, но ведь мы и не думали, что попали в сказку? Это чем-то похоже на вырывание одного уравнения из системы уравнений — каждое уравнение в системе дает множество, но в системе пересечение этих множеств дает небольшое количество решений. Поэтому, точно так же, как мы не решаем отдельно каждое уравнение в системе уравнений, нет смысла рассматривать такие функции в отрыве от других функций, из который состоит криптоалгоритм. Поэтому на элементарные операции криптоалгоритма нельзя смотреть по отдельности, а если на них смотреть как на систему уравнений, то теоретически ее можно решить. И получается, что по аналогии можно посчитать sha256 в обратную сторону, достаточно только перенести ту же идею работы со списками на побитовые операции. Но начнем мы, конечно, не с sha-256, а с тривиальных примеров.
Пусть у нас есть битовые переменные a, b, c. Пусть так же мы знаем, что в результате взятия a&b мы получили 0, а бит «c» не участвовал в формуле. Попытаемся «проиграть» эту формулу в обратную сторону. Мы знаем, что операция И дает нам в итоге ноль, если хотя бы один из операндов поступающих на ее вход равен нулю. Таким образом, возможные значения abc, как они видятся операнду «а» можно представить списком из одного регэспа 0**. Где звездочка означает 0 или 1. Возможные значения переменных abc, как они видятся операнду «b» можно представить списком из регэкспа *0*. Список нам нужен потому, что в больших выражениях одного регэкспа нам мало. Под регэкспом я понимаю не традиционное регулярное выражение, а урезанный его вариант, в котором звездочка означает любое значение соответствующего бита.
Когда мы берем логическое «И» над приходящими на входы списками, нам надо скомбинировать каждый входящий регэксп на правый вход с каждым входящим на левый. В данной задаче нам просто — входит только по одному регэкспу, вот их и комбинируем. Для «И», если на выходе надо получить 0 — левый список просто дополняем правым. Схематически я это показал на картинке в виде графа:

Пояснение. Результат f подается снизу, на выход, и поднимается в противоположную стрелкам сторону — вверх, раздваиваясь на узлах, до тех пор, пока не приходит в конечную переменную. Конечная переменная формирует список возможных значений переменных (тот который видится с позиции этой переменной), необходимых для достижения пришедшего результата. Для переменной «а» это 0**, для переменной «b» это *0*. Фактически, это все звездочки, но только одна из них, в позиции переменной, заменена на пришедшее f. Далее этот список спускается вниз по стрелкам, комбинируясь в узлах с другими такими же списками. Переменную «с» я добавил специально, чтобы показать, что неучаствующие в выражении переменные не мешают нам, а спускаются вниз в исходном виде. На выходе мы получили список, состоящий из двух регэкспов. Каждый регэксп определяет набор возможных значений, которые при желании мы легко можем сгенерировать из этого регэкспа. Это и есть ответ.
Разумеется, если в списке много элементов, мы должны как-то объединять непротиворечащие регэкспы и исключать дубликаты, этот момент важный, но — оптимизационный, и потому сейчас несущественен для понимания идеи. Про него будет ниже.
Теперь то же самое, но только для f=1. Получаем а=1**, b=*1*. Правило объединения, если для «И» нам на выходе надо получить 1 — сложнее. Мы должны объединить с правой и левой части непротиворечивые регэкспы, построив при этом список новых регэкспов. У меня получились следующие итоговые правила:
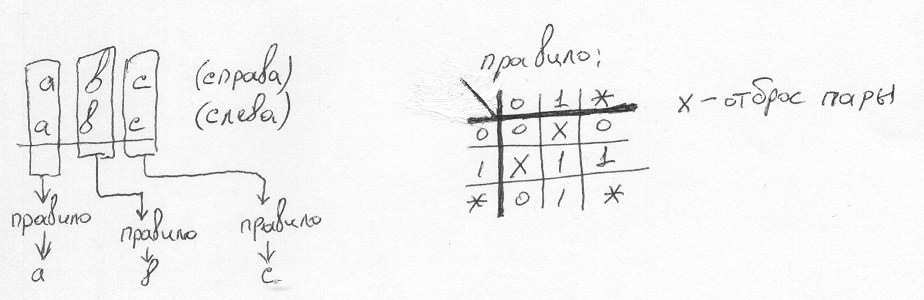
Регэкспы просматриваются побитово. В зависимости от значений бита справа и слева, выбираем наиболее конкретное значение, или отбрасываем данную пару регэкспов, если встретили биты, которые противоречат друг другу.
Обработав входы по этому правилу, получим:

Думаю, идея ясна. Для «ИЛИ» и «НЕ» можно построить аналогичные правила:

Тут еще показано, что для лог «НЕ» мы оперируем не со списками регэкспов, а с самой f, инвертируя ее. Списки регэкспов через «НЕ» проходят без изменений и без инверсий.
Таким образом, для sha256 мы можем построить граф, разбить наш message digest на биты, подать эти биты на выходы и нам вернется список возможных значений переменных прообраза.
Целей максимально оптимизировать алгоритм не ставилось. Понятно, что работать с битами через символы — расточительно, и можно сильно повысить скорость алгоритма, если переложить его на си и ассемблер с побитовыми операциями. Однако, есть еще один путь оптимизации — минимизация размеров списков, которыми мы оперируем. При объединении списков часто возникают дубликаты и непротиворечащие регекспы, которые надо откидывать. Кроме того, иногда, два регэкспа могут быть объединены в один новый, который в свою очередь можно подвергнуть дальнейшей оптимизации. Например, 000100 и 001100 можно объединить в 00*100, правило такого объединения относительно легко выводится — допустимо только изменение одного бита, важно только чтобы вновь созданный регэксп не представлял никаких лишних значений переменных. Поэтому *0 нельзя объединить с 0*, получив при этом **, потому что ** представляет 11, чего не допускал ни первый ни второй регэксп.
Кроме этого, в узлах списки мы будем кэшировать — считаем их однократно для каждого f которое пришло снизу.
Я сделал следующие предположения
— исходное сообщение короче 56 байт (для биткоина можно было бы считать что это так, на самом деле от этого упрощения отказаться не сложно);
— нам известно все исходное сообщение, кроме первых 8 бит.
Конечно, это не фонтан, я понимаю, что 8 неизвестных бит — это достаточно мало, чтобы подобрать их прямым перебором, но целью эксперимента была именно проверка способа. У меня получилось этим способом найти букву T, зная sha-256 от фразы «The quick brown fox jumps over the lazy dog», и зная все буквы этой фразы, кроме самой буквы T. Программа должна сработать и для больших неизвестных, просто будет работать дольше, и потребует больше памяти. По этой причине, невозможно считать все буквы неизвестными — не хватит вычислительных ресурсов, а значит практического применения нет. Вычисление буквы T занимает 82сек на 3ггц Phenom. Конечно, прямой перебор всех неизвестных бит (256 значений) занял бы доли секунды, так что в этом смысле тоже практической пользы от программы нет.
Как мне кажется, есть возможный путь оптимизации, который заключается в придумывании компактной записи множеств, но все равно способ будет работать не быстрей прямого перебора.
Ссылка на проект, который находит букву T: https://github.com/chabapok/sha256unroll
Идея
Считается, что некоторые функции, в обратную сторону не работают. Википедия в статье оперирует таким понятием, как «вычислительная невозможность». В одном из каментов приводили как пример функцию
X = A MOD B
Кто-то может скажет, что эта функция в обратную сторону нерешаема. Я считаю, что это функция очень даже решаема, просто в обратную сторону она выдает бесконечное множество пар (A,B), если нам известно «В», то решением будет бесконечное множество возможных чисел «А». Не совсем то, что нам хотелось бы, но ведь мы и не думали, что попали в сказку? Это чем-то похоже на вырывание одного уравнения из системы уравнений — каждое уравнение в системе дает множество, но в системе пересечение этих множеств дает небольшое количество решений. Поэтому, точно так же, как мы не решаем отдельно каждое уравнение в системе уравнений, нет смысла рассматривать такие функции в отрыве от других функций, из который состоит криптоалгоритм. Поэтому на элементарные операции криптоалгоритма нельзя смотреть по отдельности, а если на них смотреть как на систему уравнений, то теоретически ее можно решить. И получается, что по аналогии можно посчитать sha256 в обратную сторону, достаточно только перенести ту же идею работы со списками на побитовые операции. Но начнем мы, конечно, не с sha-256, а с тривиальных примеров.
Пусть у нас есть битовые переменные a, b, c. Пусть так же мы знаем, что в результате взятия a&b мы получили 0, а бит «c» не участвовал в формуле. Попытаемся «проиграть» эту формулу в обратную сторону. Мы знаем, что операция И дает нам в итоге ноль, если хотя бы один из операндов поступающих на ее вход равен нулю. Таким образом, возможные значения abc, как они видятся операнду «а» можно представить списком из одного регэспа 0**. Где звездочка означает 0 или 1. Возможные значения переменных abc, как они видятся операнду «b» можно представить списком из регэкспа *0*. Список нам нужен потому, что в больших выражениях одного регэкспа нам мало. Под регэкспом я понимаю не традиционное регулярное выражение, а урезанный его вариант, в котором звездочка означает любое значение соответствующего бита.
Когда мы берем логическое «И» над приходящими на входы списками, нам надо скомбинировать каждый входящий регэксп на правый вход с каждым входящим на левый. В данной задаче нам просто — входит только по одному регэкспу, вот их и комбинируем. Для «И», если на выходе надо получить 0 — левый список просто дополняем правым. Схематически я это показал на картинке в виде графа:
Пояснение. Результат f подается снизу, на выход, и поднимается в противоположную стрелкам сторону — вверх, раздваиваясь на узлах, до тех пор, пока не приходит в конечную переменную. Конечная переменная формирует список возможных значений переменных (тот который видится с позиции этой переменной), необходимых для достижения пришедшего результата. Для переменной «а» это 0**, для переменной «b» это *0*. Фактически, это все звездочки, но только одна из них, в позиции переменной, заменена на пришедшее f. Далее этот список спускается вниз по стрелкам, комбинируясь в узлах с другими такими же списками. Переменную «с» я добавил специально, чтобы показать, что неучаствующие в выражении переменные не мешают нам, а спускаются вниз в исходном виде. На выходе мы получили список, состоящий из двух регэкспов. Каждый регэксп определяет набор возможных значений, которые при желании мы легко можем сгенерировать из этого регэкспа. Это и есть ответ.
Разумеется, если в списке много элементов, мы должны как-то объединять непротиворечащие регэкспы и исключать дубликаты, этот момент важный, но — оптимизационный, и потому сейчас несущественен для понимания идеи. Про него будет ниже.
Теперь то же самое, но только для f=1. Получаем а=1**, b=*1*. Правило объединения, если для «И» нам на выходе надо получить 1 — сложнее. Мы должны объединить с правой и левой части непротиворечивые регэкспы, построив при этом список новых регэкспов. У меня получились следующие итоговые правила:
Регэкспы просматриваются побитово. В зависимости от значений бита справа и слева, выбираем наиболее конкретное значение, или отбрасываем данную пару регэкспов, если встретили биты, которые противоречат друг другу.
Обработав входы по этому правилу, получим:
Думаю, идея ясна. Для «ИЛИ» и «НЕ» можно построить аналогичные правила:
Тут еще показано, что для лог «НЕ» мы оперируем не со списками регэкспов, а с самой f, инвертируя ее. Списки регэкспов через «НЕ» проходят без изменений и без инверсий.
Таким образом, для sha256 мы можем построить граф, разбить наш message digest на биты, подать эти биты на выходы и нам вернется список возможных значений переменных прообраза.
Оптимизация
Целей максимально оптимизировать алгоритм не ставилось. Понятно, что работать с битами через символы — расточительно, и можно сильно повысить скорость алгоритма, если переложить его на си и ассемблер с побитовыми операциями. Однако, есть еще один путь оптимизации — минимизация размеров списков, которыми мы оперируем. При объединении списков часто возникают дубликаты и непротиворечащие регекспы, которые надо откидывать. Кроме того, иногда, два регэкспа могут быть объединены в один новый, который в свою очередь можно подвергнуть дальнейшей оптимизации. Например, 000100 и 001100 можно объединить в 00*100, правило такого объединения относительно легко выводится — допустимо только изменение одного бита, важно только чтобы вновь созданный регэксп не представлял никаких лишних значений переменных. Поэтому *0 нельзя объединить с 0*, получив при этом **, потому что ** представляет 11, чего не допускал ни первый ни второй регэксп.
Кроме этого, в узлах списки мы будем кэшировать — считаем их однократно для каждого f которое пришло снизу.
Эксперимент
Я сделал следующие предположения
— исходное сообщение короче 56 байт (для биткоина можно было бы считать что это так, на самом деле от этого упрощения отказаться не сложно);
— нам известно все исходное сообщение, кроме первых 8 бит.
Конечно, это не фонтан, я понимаю, что 8 неизвестных бит — это достаточно мало, чтобы подобрать их прямым перебором, но целью эксперимента была именно проверка способа. У меня получилось этим способом найти букву T, зная sha-256 от фразы «The quick brown fox jumps over the lazy dog», и зная все буквы этой фразы, кроме самой буквы T. Программа должна сработать и для больших неизвестных, просто будет работать дольше, и потребует больше памяти. По этой причине, невозможно считать все буквы неизвестными — не хватит вычислительных ресурсов, а значит практического применения нет. Вычисление буквы T занимает 82сек на 3ггц Phenom. Конечно, прямой перебор всех неизвестных бит (256 значений) занял бы доли секунды, так что в этом смысле тоже практической пользы от программы нет.
Как мне кажется, есть возможный путь оптимизации, который заключается в придумывании компактной записи множеств, но все равно способ будет работать не быстрей прямого перебора.
Ссылка на проект, который находит букву T: https://github.com/chabapok/sha256unroll
