Содержание
Общая теория распознавания
Мы, наконец, дошли до самой интересной темы – распознавания символа. Но для начала давайте немного разберемся с теорией, чтобы было понятнее, что именно и почему мы делаем. Общая задача автоматического распознавания или машинного обучения выглядит следующим образом.
Есть некоторый набор классов C и пространство объектов R. Есть некая внешняя «экспертная» система, с помощью которой для произвольного объекта можно определить, к какому классу он относится.
Задача автоматического распознавания – построить такую систему, которая на основе переданной ей ограниченной выборки заранее классифицированных объектов выдавала бы для любого нового переданного ей объекта соответствующий ему класс. При этом суммарная разница в классификации между «экспертной» системой и системой автоматического распознавания должна быть минимальной.
Система классов может быть дискретной или непрерывной, множество объектов может быть какой угодно структуры, экспертная система может быть произвольной, начиная с обычных человеческих экспертов, оценка точности может производиться только на некоторой выборке объектов. Но в своей основе практически любая задача автоматического распознавания (от ранжирования результатов поиска до медицинской диагностики) сводится именно к построению связки между объектами из заданного пространства и набором классов.

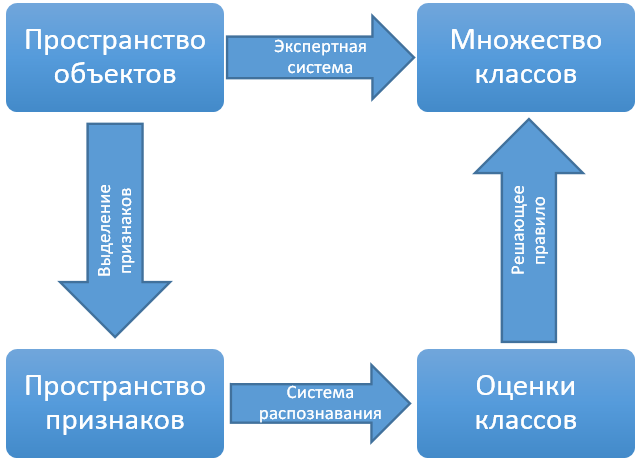
Но в такой постановке задача фактически бессмысленная, потому что совершенно непонятно, что у нас за объекты и как с ними вообще работать.
Поэтому обычно применяется следующая схема: строится некоторое пространство признаков, в котором мы хотя бы можем определять расстояние между объектами в каком-либо виде. Строится преобразование из пространства объектов в пространство признаков. Главное требование строящегося преобразования – стараться соблюдать «гипотезу компактности»: объекты, которые в пространстве признаков находятся рядом, должны иметь одинаковые или близкие классы.
Таким образом, исходная задача делится на следующие шаги:
- Построить преобразование из пространства объектов в пространство признаков с учетом «гипотезы компактности»
- Разметить пространство признаков на основе имеющейся размеченной выборки объектов, так чтобы каждой точке соответствовал набор оценок принадлежности этой точки различным классам.
- Сделать решающее правило, которое по набору оценок принимало бы итоговое решение какому классу принадлежит объект.
Про третий шаг алгоритма я скажу всего несколько слов, потому что это одно из редких мест в системе, где идея проста и реализация тоже проста. Есть несколько систем распознавания символов, каждая из этих систем выдает список вариантов распознавания с какой-то уверенностью. Задача решающего правила – слить списки вариантов распознавания от всех систем в один общий список и объединить качество распознавания от нескольких систем в одно интегральное качество. Делается объединение качества с помощью формулы, специально подобранной под наши классификаторы.
И еще одно замечание про классы распознавания – в статье я употребляю слово «символы», потому что оно всем понятно и известно. Но это сделано только для упрощения текста, на самом деле мы распознаем не символы, а графемы. Графема – это конкретный способ графического представления символа. Отношение между символами и графемами достаточно сложное – одной графеме может соответствовать несколько символов (маленькая «с» и большая «С» в латинице и кириллице – это все одна графема), а одному символу может соответствовать несколько графем (буква «a» в разных шрифтах может быть разными графемами). Стандартного списка графем не существует, мы его составляли сами и для каждой графемы задан список символов, которым она может соответствовать. Преобразование из графем в символы происходит уже после распознавания символов на этапе генерации вариантов распознавания слов.


Пример двух разных графем буквы «a».
Пара фактов про нашу оценку качества работы классификаторов:
- Мы используем несколько классификаторов, которые дополняют друг друга. То есть нормальной оценкой качества в любом случае является только оценка интегрированного списка вариантов, полученного уже после применения решающего правила.
- На этапе перебора вариантов слов используется очень много контекстной информации, которой просто нет в пределах одного символа. Поэтому от классификаторов не требуется всегда ставить нужный вариант распознавания на первое место – вместо этого нужно, чтобы правильный вариант был в первых двух-трех вариантах распознавания.
Система распознавания
В нашей программе используется несколько различных классификаторов, которые в основном отличаются используемыми признаками, но при этом имеют практический одинаковую структуру самой системы распознавания.
Требования, которые у нас есть к системе распознавания символов, достаточно простые:
- Система должна одинаково работать на любом исходном множестве возможных символов. Потому что мы никогда заранее не знаем, какой язык или сочетание языков выберет пользователь для распознавания. Тем более что у пользователя обычно есть возможность создать свой язык с вообще произвольным алфавитом.
- Ограничение возможных символов для распознавания должно увеличивать качество и ускорять работу классификаторов. Если пользователь подбирает язык распознавания под свой документ, он должен замечать улучшения.
В связи с этими двумя требованиями у нас не очень распространено использование сложных и интеллектуальных систем распознавания. Часто задают вопрос про нейронные сети, поэтому лучше напишу здесь сразу – нет, мы их не используем по многим причинам. Основная проблема с ними – жестоко фиксированное множество распознаваемых классов и излишняя внутренняя сложность, чрезвычайно осложняющая точную донастройку классификатора. Дальнейшее обсуждение нейронных сетей – тема для большого холивара, так что лучше расскажу про то, что мы используем.
А используем мы разновидности байесовского классификатора. Идея его в следующем:
Нам нужно для конкретной точки в пространстве признаков (x) оценить вероятность ее принадлежности разным классам (C1, C2, …, Cn)
Если написать формально, то нам нужно посчитать вероятность что класс объекта равен Ci при условии что объект описывается в пространстве признаков точкой x — P( Ci | x ).
Применяем формулу Баейса из базового курса теории вероятности:
P( Ci | x ) = P( Ci ) * P( x | Ci ) / P( x );
Мы в итоге сравниваем вероятности для разных классов, чтобы определить ответ для символа, поэтому знаменатель из формулы выкидываем, он для всех классов общий. Нам нужно будет сравнивать набор значений P( Ci ) * P( x | Ci) для разных классов и выбрать из них наибольшее значение.
P( Ci ) – это априорная вероятность класса. Она не зависит от распознаваемого объекта, ее можно посчитать заранее. Для любого набора возможных классов (возможных алфавитов) ее можно высчитать заранее по частоте встречаемости букв в указанном языке. А практика показывает, что иногда даже лучше брать одинаковые априорные вероятности всех символов.
P( x | Ci ) – это вероятность для определенного класса Ci получить объект с описанием x. Эту вероятность мы можем определить заранее на этапе обучения классификатора. Тут работают совершенно стандартные методы из математической статистики – делаем предположение о форме распределения (нормальное, равномерное, …) для класса в пространстве признаков, берем большую выборку объектов этого класса, и по этой выборке определяем необходимые параметры для выбранного распределения.

Совсем небольшой фрагмент нашей базы изображений для обучения классификаторов.
Что нам дает использование байесовского классификатора? Эта система совсем не зависит от алфавита распознавания. Вероятностное распределение для каждого класса считается по выборке абсолютно независимо. Априорные вероятности для классов на практике лучше вообще не использовать. Итоговая оценка для каждого класса – это вероятность, а, следовательно, для любого класса она находится в одинаковом диапазоне.
Таким образом мы получаем систему, которая может работать без всяких дополнительных настроек как на изображении бинарного кода из ноликов и единичек, так и на тексте из разговорника на 4-5 языках. Дополнительным плюсом является то, что вероятностные модели очень легко интерпретировать и можно независимо дообучать отдельные символы, если возникает такая потребность.
Пространство признаков
Как я говорил раньше, классификаторов символов у нас в системе используется несколько и основное различие у этих классификаторов как раз в пространстве признаков.
Пространство признаков для наших классификаторов построено на сочетании двух идей:
- Байесовскому классификатору очень просто работать, если пространство признаков состоит из числовых векторов фиксированной длины – для числовых векторов очень легко считать математическое ожидание, дисперсию и прочие характеристики которые необходимы для восстановления параметров распределения.
- Если на изображении посчитать базовые характеристики, типа количества черного в определенном фрагменте изображения, то каждая такая характеристика в отдельности ничего не скажет о принадлежности изображения конкретному символу. Но если собрать много таких характеристик в один вектор, то эти вектора в сумме будут уже заметно различаться у разных классов.
Так что у нас есть несколько классификаторов, построенных следующим образом: выбираем много (порядка сотни) базовых признаков, собираем из них вектор, объявляем такие вектора нашим пространством признаков и строим на них байесовский классификатор.
Как упрощенный пример – мы делим изображение на несколько вертикальных и горизонтальных полос, а для каждой полосы считаем отношение черных и белых пикселей. При этом считаем, что у нас распределение получившихся векторов нормальное. Для нормального распределения нам нужно посчитать математическое ожидание и дисперсию чтобы узнать параметры распределения. Сделать это на векторах, при достаточно большой выборке элементарно. Таким образом мы из очень простых признаков и с помощью простой математики получаем классификатор, который на практике обладает достаточно высоким качеством.
Это был упрощённый пример, а какие именно признаки и в каких именно сочетаниях на самом деле используются – это как раз результат накопленного опыта и долгих исследований, так что подробного их описания я здесь приводить не буду.
Растровый классификатор
Отдельно нужно написать про растровый классификатор. Самое простое пространство признаков, которое можно придумать для распознавания символов – это само изображение. Мы выбираем некоторый (небольшой) размер, любое изображение приводим к этому размеру и получаем фактически вектор значений фиксированный длины. Как складывать и усреднять вектора всем известно, так что у нас получается совершенно нормальное пространство признаков.
Это самый базовый классификатор – растровый. Мы приводим все изображения одной графемы из обучающей базы к одному размеру, а затем усредняем их. В итоге получается серое изображение где цвет каждой точки отвечает вероятности того, что это точка должна быть белой или черной для данного символа. Растровый классификатор при желании можно интерпретировать как байесовский и считать некоторую вероятность что данное изображении появилось при данном эталоне для символа. Но для этого классификатора такой подход только все усложняет, поэтому мы используем обычное расстояние между черно-белым изображением и серым эталоном для оценки принадлежности изображения заданному классу.
Плюсом растрового классификатора является его простота и скорость. А минусом – невысокая точность, в основном из-за того, что при приведении к одному размеру мы теряем всю информацию о геометрии символов – скажем точка и буква “I” в этом классификаторе приводятся к одинаковому черному квадрату. В итоге этот классификатор является идеальным механизмом для генерации первоначального списка вариантов распознавания, который уже потом можно уточнять с помощью более сложных классификаторов.
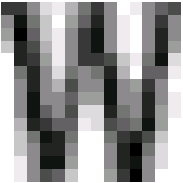


Несколько примеров растровых эталонов для одной буквы.
Структурный классификатор
Кроме печатного текста наша система умеет еще распознавать рукописный текст. А проблема рукописного текста в том, что его вариативность очень большая, даже если человек старается писать печатными буквами.
Поэтому для рукописного текста все стандартные классификаторы не могут дать достаточного качества. Так что для этой задачи у нас в системе есть еще один шаг – структурный классификатор.
Его идея в следующем – у каждого символа есть на самом деле четко определенная структура. Но если мы попробуем просто выделить эту структуру на изображении – ничего не получится, вариативность очень большая и нам еще нужно будет как-то сравнивать найденную структуру с структурой каждого возможного символа. Но у нас есть базовые классификаторы – они неточные, но в 99,9% случаев правильный вариант распознавания будет все-таки в списке, скажем, 10 лучших вариантов.
Так что пойдем с обратного конца:
- Для каждого символа опишем его структуру через базовые элементы – линия, дуга, кольцо, … Описание придется делать вручную, это большая проблема, но пока еще никто не смог придумать автоматического выделения топологии с приемлемым для нас качеством.
- Для структурного описания символа отдельно опишем, как именно его искать на изображении – с каких элементов начинать и в каком порядке идти.
- При распознавании символа получим небольшой список возможных вариантов распознавания, используя базовые классификаторы.
- Для каждого варианта распознавания попробуем найти на изображении соответствующее ему структурное описание.
- Если описание подошло – оцениваем его качество. Не подошло – значит, вариант распознавания совсем не подходит.
Так как в таком подходе мы проверяем конкретные гипотезы, то мы всегда точно знаем, что именно и в каком порядке искать на изображении – так алгоритм выделения структуры сильно упрощается.

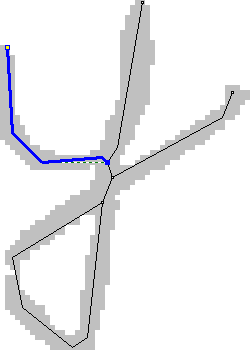


Пример выделенных структурных элементов на изображении символа
Дифференциальный классификатор
В качестве надстройки над набором классификаторов у нас еще есть дифференциальный классификатор. Причина его появления в следующем – есть пары символов, которые очень похожи друг на друга, за исключением каких-то небольших очень специфических особенностей. Причем для каждой пары символов эти особенности отличаются. Если знания об этих особенностях пытаться встраивать в общий классификатор, то общий классификатор будет перегружен признаками, каждый из которых не будет приносить пользы подавляющем большинстве случаев. С другой стороны, после работы обычных классификаторов у нас уже есть список гипотез распознавания, и мы точно знаем какие варианты нам нужно сравнивать между собой.
Поэтому для похожих пар символов находим специальные признаки, которые различают именно эти два класса и построим классификатор на основе этих признаков только для этих двух классов. Если у нас в вариантах распознавания есть два похожих варианта с близкими оценками, такой классификатор может точно сказать, какой из этих двух вариантов предпочтительней.
В нашей системе дифференциальные классификаторы используются после работы всех основных классификаторов, чтобы дополнительно пересортировать список вариантов распознавания символа. Для определения похожих пар символов используется автоматическая система, которая смотрит какие символы путались с какими чаще всего при использовании только базовых классификаторов. Затем для каждой подозрительной пары вручную выбираются дополнительные признаки и обучается дифференциальный классификатор.
Практика показывает, что для обычных языков пар близких символов не очень много. При этом добавление каждого нового дифференциального классификатора очень заметно улучшает распознавание.
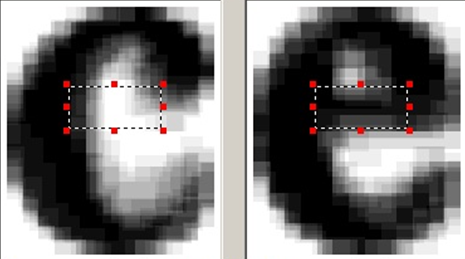
Пример области для выделения дополнительных признаков для пары похожих символов.
В качестве заключения
Эта статья ни в коем случае не претендует на точное описание тех механизмов, которые используются внутри FineReader и других наших продуктов для распознавания. Это описание лишь базовых принципов, которые использовались при создании технологий. Реальная система слишком большая и сложная, чтобы ее можно было описать в двух-трех статьях на Хабре. Если вам реально интересно, как там все в действительности устроено, – лучше
