Входе одного проекта мне пришлось создать сверхбыструю русскую морфологию. Около 50.000 слов в секунду на довольно слабом ноутбуке, что всего в 2-3 раза медленнее чем стемминг (обрезка окончаний по правилам), но значительно его точнее. Это данные по обычному диску, на SSD или виртуальном диске поиск происходит значительно быстрее.
Первоначальная версия была на MySQL, но перевод ее на файлы мне удалось добиться стократного увеличения производительности. О том когда и почему файлы быстрее MySQL я и расскажу в статье.
Но для начала, чтобы не томить тех кому интересна моя реализация. Вот ссылка на нее в GitHub. Там исходник для PHP. Для других языков написать аналог довольно легко, будет не более 100 строк кода. Основная проблема конвертировать базу в приемлемый для поиска вид мною уже выполнена. Вам просто нужно портировать поиск на свой язык.
Задача
Все кто хоть немного в теме контекстной рекламы используют Яндекс.WordStat. Это сервис для подбора ключевых слов. Однако, он содержит много шума.
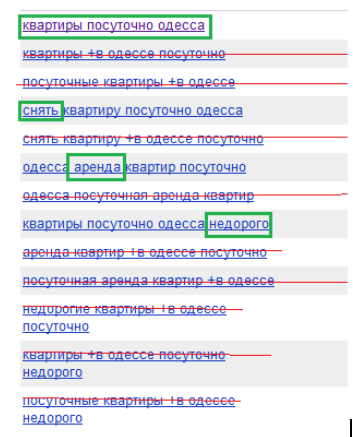
На скриншоте вычеркнуты все запросы, которые дублируют прошлые. Зеленым выделена разница между основным запросом и уточнением. Т.е. все эти 60 слов со скриншота можно записать 6тью:
квартиры посуточно одесса снять аренда недорого
Т.е. 90% информации в WordStat — шум. Но основная проблема в том, что нужно копировать данные, вставлять их в блокнот и редактировать. Для пользователей было удобнее использовать галочки. Вот, например, сравнение WordStat тем, что получилось у меня в итоге:
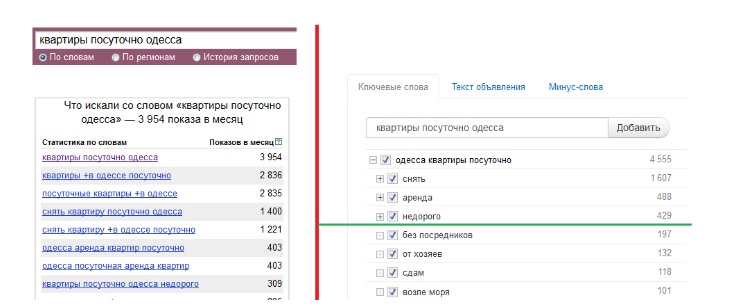
На скриншоте Яндекс.Вордстат и HTraffic. Данные одни, разная визуализация.
В общем, это позволяет в 10-20 раз ускорить подбор ключевых слов. Однако, все это требует морфологии. При этом вордстат по API может выдать до 200 запросов, в каждом из них в среднем 5 слов. Это уже 1000 слов. К тому-же, вместе с запросом мы пробиваем еще и его синонимы, их может быть до 10ти. Т.е. 10.000 слов вполне реальная ситуация.
Конечно можно использовать кеширование и запоминать ранее найденные словоформы. Тогда число поисков сократиться раз в 10. Но это не полностью избавляет от проблем со скоростью.
Омонимия и нормализация
Скорость не единственная наша проблема. Русский язык слишком велик и могуч. В нем огромное число словоформ (написаний слова в другом падеже, роде и тп). И иногда разные словоформы разных слов пишутся одинаково. Это называется омонимией. Например, система встретив в тексте слово-строку “дели” не знает к какому слову ее отнести:
- Дели. “Дели — столица Индии”.
- Делить. “Смело дели на два”.
- Деть. “Куда вы дели мои носки?”
Такая многозначность нам сильно мешает. Намного было удобнее, если бы каждая слово-строка имела бы не более одной интерпретации. В этом случае кода у нас было бы намного меньше и возросла бы скорость работы.
Но научить разрешать омонимию машину сложная задача. Она требует много времени на реализацию, а также может негативно сказаться на производительности.
Решение этой проблемы я скопировал у Яндекс.Директ. Он объединяет слова имеющие омонимию в одно. Т.е. они получают один ID. Иногда это приводит к глюкам, когда по запросу находиться не искомое слово, а склеенное с ним, но это происходит довольно редко. В противном случае Директ не использовал бы подобное решение.
База AOT.ru
В рунете есть только одна свободная база русской морфологии — Aot.ru. В ней около 200 тысяч слов, у каждого в среднем где-то по 15 словоформ. Документация по ней сильно запутана и имеет неточности. Поэтому я потрачу пару абзацев, чтобы ее описать.
База выглядит так: в ней есть наборы окончаний, приставки и слова. Слово имеет псевдооснову (грубо говоря корень слова), номер приставки (если она есть), номер набора окончаний. Чтобы сгенерировать все варианты слова нужно в цикле перебрать окончания, и спереди к каждому из них прибавить приставку и псевдооснову.
Есть несколько моментов:
- Псевдоосновы может не быть. Например: идти, шел. В этом случае в базе вместо пслевдоосновы пишется “#”.
- Иногда в таблице окончаний есть приставки. Такое происходит в превосходной степени прилагательных (лучший -> наилучший). Приставка из окончания должна идти перед основной приставкой.
Вид базы когда окончания отделены от слов называется сжатым. В этом случае, база весит мало, но поиск по ней крайне медленный. Поэтому словарь нужно “разжать” — записать каждую словоформу отдельно. Но словоформ в базе несколько миллионов, поэтому на это требуется несколько десятков мегабайт. Первый делом я посмотрел в сторону баз данных.
MySQL
Я записал все словоформы в одну таблицу с двумя столбцами, текст и id слова. Добавил индекс по тексту словоформы, но скорость оказалась крайне низкой. Запуск процедур оптимизации таблицы не помог.
Чтобы разобраться в чем-же причина, я стал искать сразу по 10 слов, через IN. Скорость увеличилась незначительно, следовательно,. дело было не в парсинге SQL и NO-SQL бы мне не помог.
Игры с типом индекса и хранилищем тоже почти ничего не дали.
Также я изучил несколько тестов производительности сравнивающие MySQL с другими движками, например, с Mongo. Однако, заметного превосходства скорости чтения перед MySQL в них не демонстрирует ни один движок.
CRC32
Я решил уменьшить длину индекса. Текст словоформы заменил на его контрольную сумму (crc32).
Поскольку словоформ около 2уъ миллионов, а 2^32 = 4 млрд, мы получаем вероятность коллизии 0.05%. Всего по известным словам около 1.000 коллизий, исключить их можно просто указав все в ассоциативном массиве с их настоящими id:
if(isset($Collisions[$wordStr])) return $Collisions[$wordStr];Но это не исключает ложноположительного срабатывания, если словоформы нет в базе, то в 1 из 2000 случаев возвращается левый id. Но это критично только для поиску по огромным разнотематическим массивам данных (вроде википедии).
Словарный запас человека крайне редко выше 10.000 слов. Например, у Льва Толстого 20.000. Слов в базе 200.000, если организовать поиск по полному собранию сочинений Толстого, то вероятность того, что из-за коллизии он найдет что-то лишнее, будет 1 к 10 * 2000. Т.е. 1 к 20.000.
Другими словами, вероятность глюков из-за использования crc32 крайне мала. И это с лихвой компенсируется увеличением производительности и уменьшением объема данных.
Однако, это мало помогло. Скорость была около 500 слов в секунду. Я начал смотреть в сторону файлов.
Файлы
Когда все способы оптимизации MySQL были испробованы, я решил записать морфологический словарь в файл и искать по нему бинарным поиском. Результаты превзошли мои ожидания. Скорость возросла где-то втрое.
Для меня эта цифра была неожиданной, поскольку я писал на PHP, а скриптовые языки несут свои накладные расходы (вроде маршалинга). При этом MySQL и моя реализация использует аналогичные алгоритмы — бинарные деревья и быстрый поиск.
В обоих случаях сложность log(n). Т.е. происходит log2(2.000.000) ~ 21 операция считывания из файла. PHP должно 21 раз строку из сишного вида преобразовать в свой внутренний. В MySQL подобного не происходит. В теории, PHP должен заметно проигрывать в скорость.
Чтобы разобраться в чем-же дело я добавил блокирование файлов на чтение. Сама блокировка здесь не нужна, ведь чтение с чтением не конфликтует, да и тестировал я в один поток. Были интересны накладные расходы. Скорость упала раза в 1.5. Вероятно, что одна из основных причин в том, что MySQL предотвращает конфликты записи в несколько потоков, а в нашей задаче это не нужно.
Но это не объясняет и половины разницы в скорости. Откуда взялись остальные тормоза, мне не понятно. Хотя деревья и драйвер могут нести свои накладные расходы, но не такие большие. Интересно ваше мнение в комментариях.
Хеширование
Деревья не оптимальная структура для поиска данных. Хеш намного быстрее. У Хеша константное время. В нашем случае вместо 21 операции мы потратим 1-2. При этом чтение будет происходить последовательно, т.е. лучше будет работать кеш диска и считывающей головке не придется туда-сюда прыгать.
Хеш используется, например, в PHP для реализации асоциативных массивов. В БД используются бинарные деревья, поскольку они позволяют организовать сортировку и операторы больше и меньше. Но когда нужно выбрать элементы равные какому-то значению, то здесь деревья проигрывают хешу на больших таблицах в десятки раз.
Таким образом мне удалось ускорить библиотеку в 10-15 раз. Но на этом я не остановился, я начал хранить CRC и id слова в разных файлах. Таким образом чтение стало полностью последовательным. Также я стал сохранять файловый указатель открытым между несколькими запусками поиска.
Итоговый выигрыш в производительности перед MySQL составил 80-100 раз. Разброс оценки обусловлен тем, что я тестировал на разном соотношении ошибок и правильных словоформ.
Выводы
Я не призываю заменять БД на файлы всегда и везде. БД имеет намного больше функций. Но есть несколько случаев, когда эта замена будет оправдана. Например, это статические базы (города по IP, морфология). В этом случае переход на файлы, кроме всего прочего, облегчит жизнь, для установки на другой сервер достаточно будет простого копирования файлов.
Основная фишка БД это избавления от конфликтов между потоками. Такое довольно сложно организовать при работе с файлами. БД блокируют чтение, когда идет запись. Но на больших нагрузках это рождает свои проблемы.
Сколько у вас не было серверов и потоков, все они блокируются, когда один из них пишет данные в базу. Здесь все зависит от типа хранилища, некоторые ставят блокировку на уровне строк, но и это не всегда помогает.
Поэтому часто разделяют базы. Одна используется для чтения, вторая для записи. Они синхронизируются время от времени, например ночью. Если, в большинстве запросов чтения у вас выборка происходит оператором “=”, то вы можете многократно увеличить скорость, делая копии таблиц в файлах и используя хеш.
Если тормозит база записи, то, в некоторых случаях, быстрее будет записывать что-то вроде лога с изменениями, а при синхронизации переводить этот лог в нормальную базу. Но такой вариант помогает далеко не всегда.
