Примечание переводчика 1. Я наткнулся на этот блог в одном из обзоров материалов по машинному обучению. Если вы хорошо разбираетесь в машинном обучении, то в этой статье вы не найдете для себя ничего интересного. Она достаточно поверхностная и затрагивает только основы. Если же вы, как и я, только начинаете интересоваться данной темой, то добро пожаловать под кат.
Примечание переводчика 2. Кода будет мало, а тот что есть написан на языке R, но не стоит отчаиваться, если вы его до сих пор никогда в глаза не видели. До этой статьи я тоже ничего о нем не знал, поэтому я специально отдельно написал «шпору» по языку, включив туда все, что вам встретится в статье. Если хотите сами разобраться, то начать рекомендую c маленького курса на CodeSchool. На хабре тоже есть интересная информация и полезные ссылки. И наконец вот тут есть большая шпаргалка.
Примечание переводчика 3. Статья из двух частей, однако самое интересное начинается только во второй части, поэтому я позволил себе объединить их в одну статью.

В этой серии статей, я собираюсь шаг за шагом построить и оттестировать простую стратегию управления активом, основанную на машинном обучении. Первая часть будет посвящена базовым концепциям машинного обучения и их применению к финансовым рынкам.
Машинное обучение является одним из наиболее многообещающих направлений в финансовой математике, в последние годы получившее репутацию изощренного и сложного инструмента. В действительности все не так сложно.
Цель машинного обучения в построении точной модели на основе исторических данных и затем использования этой модели для предсказаний в будущем. В финансовой математике с помощью машинного обучения решаются следующие задачи:
Рассмотрим простой пример. Давайте попытаемся предсказать движение стоимости акций Google на один день вперед. В следующей части мы будем использовать несколько индикаторов, но сейчас, для изучения основ, мы будем использовать только один показатель: день недели. Итак, давайте попробуем предсказать движение цены на основе дня недели.
Ниже отображен график акций Google и картинка экспортированных данных из Yahoo Finance.
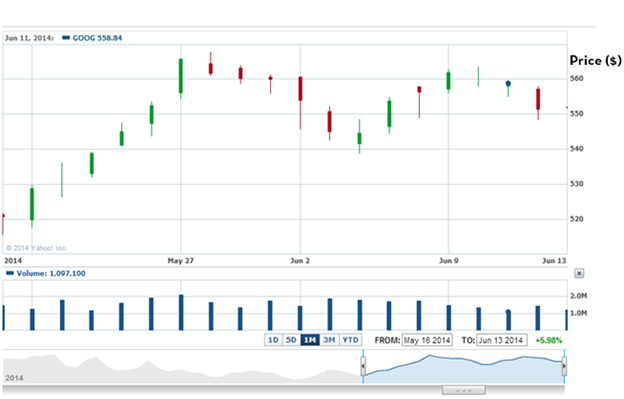

Я добавил колонку день недели и колонку цена закрытия минус цена открытия. Так же, я добавил колонку направления цены, где пишу «UP», если разница между ценой закрытия и открытия больше 0 и «DOWN» если меньше:

В машинном обучении этот набор данных будет называться тренировочным, потому что алгоритм обучается на них. Другими словами алгоритм просматривает весь набор данных и устанавливает зависимость между днем недели и направлением изменения стоимости акции. Заметьте, что наш набор маленький — здесь всего 23 строки. В следующей части, мы будем использовать сотни строк для построения модели. В действительности, чем больше данных, тем лучше.
Теперь давайте выберем алгоритм. Есть целый ряд алгоритмов, которые вы можете использовать, включая скрытые Марковские Модели, искусственные нейронные сети, наивный байесовский классификатор, метод опорных векторов, дерева решений, дисперсионный анализ и множество других. Здесь хороший список, где вы можете разобраться в каждом алгоритме и понять когда и какой из них применять. Для начала я рекомендую использовать один из наиболее часто используемых алгоритмов, например метод опорных векторов или наивный байесовский классификатор. Не тратьте много времени на выбор, наиболее важные части вашего анализа — индикаторы которые вы используете и величина, которую прогнозируете.
Теперь, когда мы разобрались с базовой концепцией использования алгоритмов машинного обучения в вашей стратегии, мы изучим простой пример использования наивного байесовского классификатора для предсказания направления акций Apple. Сначала мы разберемся с тем, как работает этот классификатор, затем мы рассмотрим очень простой пример использования дня недели для предсказания движения цены, а в конце мы усложним модель, добавив технический индикатор.
Формула Байеса позволяет найти вероятность того, что событие А случится, если известно, что событие В уже произошло. Обычно обозначается как: P (A | B).
В нашем примере, мы спрашиваем: «Какова вероятность, что сегодняшняя цена повысится, если известно, что сегодня среда?». Метод учитывает как вероятность того, что сегодняшняя цена вырастет исходя из общего количества дней во время которых наблюдался рост, так и исходя из того, что сегодня среда, т. е. сколько раз цена росла в среду.
У нас появляется возможность сравнить вероятность того, что сегодняшняя цена вырастет и вероятность того, что она упадет, и использовать наибольшее значение как прогноз.
До сих пор мы обсуждали только один индикатор, но как только их становится несколько, вся математика быстро усложняется. Чтобы это предотвратить используется наивный байесовский классификатор (вот тут хорошая статья). Он обрабатывает каждый индикатор, как независимый, или не коррелированный (отсюда термин наивный). Поэтому важно использовать индикаторы связанные слабо или не связанные вовсе.
Это очень упрощенное описание наивного байесовского классификатора, если вам интересно узнать о нем подробнее, а так же о других алгоритмах машинного обучения, посмотрите тут
Теперь разберем очень простой пример на R. Мы будем использовать день недели, для прогнозирования движения цены акций Apple вверх или вниз.
Для начала давайте убедимся, что у нас есть все библиотеки которые нам нужны:
Теперь давайте получим данные, которые нам нужны:
Теперь, когда у нас есть все необходимые данные, давайте получим наш индикатор «день недели»:
То, что мы собираемся спрогнозировать, т.е. движение цены вверх или вниз, и создание финального набора данных:
Теперь мы готовы применить наивный байесовский классификатор:
Поздравляю! Мы применили алгоритм машинного обучения для анализа акций Apple. Теперь давайте разберемся в результатах.

Здесь отображена вероятность повышения или понижения цены на основе исходного набора данных ( известного как предыдущие вероятности). Мы можем видеть небольшой медвежий уклон.

Здесь отображены условные вероятности (указывается вероятность роста или падения цены для каждого дня недели).
Видно, что модель не очень хороша, т. к. она не возвращает высоких вероятностей. Тем не менее заметно, что открывать длинные позиции лучше в начале недели, а шортить ближе к концу.
Очевидно вам захочется использовать более сложную стратегию, нежели просто ориентирование на день недели. Давайте добавим пересечение со скользящей средней в нашу модель (вы можете получить больше информации о добавлении различных индикаторов к вашей модели здесь)
Я предпочитаю использовать экспоненциальные скользящие средние, поэтому давайте рассмотрим 5-ти дневные и 10-дневные экспоненциальные скользящие средние (EMA).
Для начала нам необходимо рассчитать EMA:
Затем рассчитываем пересечение:
Теперь округляем значения до 2-х знаков после запятой. Это важно, поскольку если попадется значение, которое наивный классификатор байеса не видел во время обучения, он автоматически рассчитает вероятность в 0%. Например, если мы смотрим на пересечение EMA с точностью до 6-ти знаков, и была найдена высокая вероятность движения цены вниз, когда разница была $2.349181, а затем была представлена новая точка данных, которая имела разницу $2.349182, будет рассчитана 0% вероятность повышения или понижения цены. Окрулив до 2-х знаков после запятой, мы снижаем риск столкнуться с неизвестным для модели значением (при условии, что для обучения использовался достаточно большой набор данных, в котором скорее всего встретятся все значения индикатора). Это важное ограничение, о котором нужно помнить, при построении собственных моделей.
Давайте создадим новый dataset и разделим данные на тренировочный и тестовый набор. Таким образом, мы сможем понять, насколько хорошо работает наша модель на новых данных.
Теперь построим модель:

Условная вероятность пересечения скользящих средних – число, которое показывает среднее значение для каждого случая ([,1]) и для стандартного отклонения ([,2]). Мы можем видеть, что в среднем разница между 5-дневной EMA и 10-ти дневной EMА для длинных и коротких торгов была $0.54 и -$0.24 соответственно.
Теперь протестируем на новых данных:

Всего в тестовой выборке 164 дня. При этом предсказания нашей модели совпали с реальными данными 79 раз или в 48% случаев.
Этот результат нельзя назвать хорошим, но он должен дать вам представление о том, как построить свою собственную стратегию, основанную на машинном обучении. В следующей части, мы посмотрим, как можно использовать эту модель для улучшения вашей стратегии.
Примечание переводчика 5. На сегодняшний день есть еще 2 статьи из этого цикла: про дерево решений и про нейронные сети. Статьи в таком же стиле, т.е. не глубокие, а только дающие общее представление о вопросе. Если интересно — я продолжу переводить. Обо всех замечаниях, неточностях и прочих ошибках пишите в личку.
Примечание переводчика 2. Кода будет мало, а тот что есть написан на языке R, но не стоит отчаиваться, если вы его до сих пор никогда в глаза не видели. До этой статьи я тоже ничего о нем не знал, поэтому я специально отдельно написал «шпору» по языку, включив туда все, что вам встретится в статье. Если хотите сами разобраться, то начать рекомендую c маленького курса на CodeSchool. На хабре тоже есть интересная информация и полезные ссылки. И наконец вот тут есть большая шпаргалка.
Примечание переводчика 3. Статья из двух частей, однако самое интересное начинается только во второй части, поэтому я позволил себе объединить их в одну статью.

Часть 1
В этой серии статей, я собираюсь шаг за шагом построить и оттестировать простую стратегию управления активом, основанную на машинном обучении. Первая часть будет посвящена базовым концепциям машинного обучения и их применению к финансовым рынкам.
Машинное обучение является одним из наиболее многообещающих направлений в финансовой математике, в последние годы получившее репутацию изощренного и сложного инструмента. В действительности все не так сложно.
Цель машинного обучения в построении точной модели на основе исторических данных и затем использования этой модели для предсказаний в будущем. В финансовой математике с помощью машинного обучения решаются следующие задачи:
- Регрессия. Используется для прогнозирования направления и значения величины. Например рост на $7.00 стоимости акций Google за день.
- Классификация. Используется для прогнозирования категорий, например направление стоимости акций Google за день.
Рассмотрим простой пример. Давайте попытаемся предсказать движение стоимости акций Google на один день вперед. В следующей части мы будем использовать несколько индикаторов, но сейчас, для изучения основ, мы будем использовать только один показатель: день недели. Итак, давайте попробуем предсказать движение цены на основе дня недели.
Ниже отображен график акций Google и картинка экспортированных данных из Yahoo Finance.


Я добавил колонку день недели и колонку цена закрытия минус цена открытия. Так же, я добавил колонку направления цены, где пишу «UP», если разница между ценой закрытия и открытия больше 0 и «DOWN» если меньше:
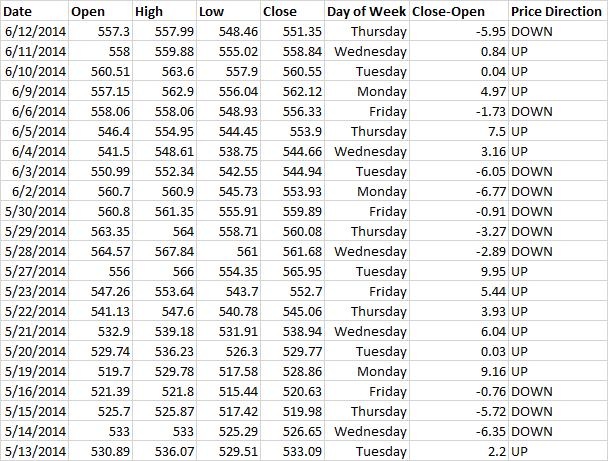
В машинном обучении этот набор данных будет называться тренировочным, потому что алгоритм обучается на них. Другими словами алгоритм просматривает весь набор данных и устанавливает зависимость между днем недели и направлением изменения стоимости акции. Заметьте, что наш набор маленький — здесь всего 23 строки. В следующей части, мы будем использовать сотни строк для построения модели. В действительности, чем больше данных, тем лучше.
Теперь давайте выберем алгоритм. Есть целый ряд алгоритмов, которые вы можете использовать, включая скрытые Марковские Модели, искусственные нейронные сети, наивный байесовский классификатор, метод опорных векторов, дерева решений, дисперсионный анализ и множество других. Здесь хороший список, где вы можете разобраться в каждом алгоритме и понять когда и какой из них применять. Для начала я рекомендую использовать один из наиболее часто используемых алгоритмов, например метод опорных векторов или наивный байесовский классификатор. Не тратьте много времени на выбор, наиболее важные части вашего анализа — индикаторы которые вы используете и величина, которую прогнозируете.
Часть 2
Теперь, когда мы разобрались с базовой концепцией использования алгоритмов машинного обучения в вашей стратегии, мы изучим простой пример использования наивного байесовского классификатора для предсказания направления акций Apple. Сначала мы разберемся с тем, как работает этот классификатор, затем мы рассмотрим очень простой пример использования дня недели для предсказания движения цены, а в конце мы усложним модель, добавив технический индикатор.
Что такое наивный байесовский классификатор?
Формула Байеса позволяет найти вероятность того, что событие А случится, если известно, что событие В уже произошло. Обычно обозначается как: P (A | B).
В нашем примере, мы спрашиваем: «Какова вероятность, что сегодняшняя цена повысится, если известно, что сегодня среда?». Метод учитывает как вероятность того, что сегодняшняя цена вырастет исходя из общего количества дней во время которых наблюдался рост, так и исходя из того, что сегодня среда, т. е. сколько раз цена росла в среду.
У нас появляется возможность сравнить вероятность того, что сегодняшняя цена вырастет и вероятность того, что она упадет, и использовать наибольшее значение как прогноз.
До сих пор мы обсуждали только один индикатор, но как только их становится несколько, вся математика быстро усложняется. Чтобы это предотвратить используется наивный байесовский классификатор (вот тут хорошая статья). Он обрабатывает каждый индикатор, как независимый, или не коррелированный (отсюда термин наивный). Поэтому важно использовать индикаторы связанные слабо или не связанные вовсе.
Это очень упрощенное описание наивного байесовского классификатора, если вам интересно узнать о нем подробнее, а так же о других алгоритмах машинного обучения, посмотрите тут
Пошаговый пример на R
Шпора по R
Для работы вам понадобится:
Сам по себе язык очень простой. Файлы скриптов можно не создавать – все пишется прямо в консоли.
Теперь по порядку, все что встретится:
В языке не строгая типизация, объявлять переменные нет необходимости. Для присвоения значения используется знак «<-»
Например:
Вектор присваивается так:
Есть особый тип – data frame. Визуально его легче всего представить в виде таблицы. Например(взято с CodeSchool):
Можно указывать диапазон строк\столбцов. К примеру чтобы вывести с 1 по 4 строку все столбцы, надо написать:
Чтобы вывести все строки и только второй столбец:
В самом языке изначально не так много функций, поэтому для работы необходимо будет подключить некоторые библиотеки. Для этого прописывается:
При вызове функций, дополнительные параметры прописываются так: имя_параметра = значение. Например:
Конкретно эта функция выгружает с yahoo данные о стоимости акций. Подробней о ней в мануале: www.quantmod.com/documentation/getSymbols.html
С остальным думаю вопросов не возникнет.
- Интерпретатор языка R.
- В качестве IDE я использовал RStudio.
Сам по себе язык очень простой. Файлы скриптов можно не создавать – все пишется прямо в консоли.
Теперь по порядку, все что встретится:
В языке не строгая типизация, объявлять переменные нет необходимости. Для присвоения значения используется знак «<-»
Например:
a <- 1.
Вектор присваивается так:
a <- c(1,2,3)
Есть особый тип – data frame. Визуально его легче всего представить в виде таблицы. Например(взято с CodeSchool):
> weights <- c(300, 200, 100, 250, 150)
> prices <- c(9000, 5000, 12000, 7500, 18000)
> types <- c(1, 2, 3, 2, 3)
> treasure <- data.frame(weights, prices, types)
> print(treasure)
weights prices types
1 300 9000 1
2 200 5000 2
3 100 12000 3
4 250 7500 2
5 150 18000 3
Можно указывать диапазон строк\столбцов. К примеру чтобы вывести с 1 по 4 строку все столбцы, надо написать:
treasure[1:4,]
Чтобы вывести все строки и только второй столбец:
treasure[,2]
В самом языке изначально не так много функций, поэтому для работы необходимо будет подключить некоторые библиотеки. Для этого прописывается:
install.packages("lib_name")
library("lib_name")
При вызове функций, дополнительные параметры прописываются так: имя_параметра = значение. Например:
getSymbols("AAPL", src = "yahoo", from = startDate, to = endDate)
Конкретно эта функция выгружает с yahoo данные о стоимости акций. Подробней о ней в мануале: www.quantmod.com/documentation/getSymbols.html
С остальным думаю вопросов не возникнет.
Теперь разберем очень простой пример на R. Мы будем использовать день недели, для прогнозирования движения цены акций Apple вверх или вниз.
Для начала давайте убедимся, что у нас есть все библиотеки которые нам нужны:
install.packages("quantmod")
library("quantmod")
#Позволяет импортировать данные
install.packages("lubridate")
library("lubridate")
#Упрощает работу с датами
install.packages("e1071")
library("e1071")
#Дает доступ к алгоритму наивного байесовского классификатора
Теперь давайте получим данные, которые нам нужны:
startDate = as.Date("2012-01-01")
#Начало рассматриваемого промежутка
endDate = as.Date("2014-01-01")
#Конец рассматриваемого промежутка
getSymbols("AAPL", src = "yahoo", from = startDate, to = endDate)
#Получаем дневное OHLCV акций Apple с Yahoo FinanceТеперь, когда у нас есть все необходимые данные, давайте получим наш индикатор «день недели»:
DayofWeek<-wday(AAPL, label=TRUE)
#Находим день неделиТо, что мы собираемся спрогнозировать, т.е. движение цены вверх или вниз, и создание финального набора данных:
PriceChange<- Cl(AAPL) - Op(AAPL)
#Находим разницу между ценой закрытия и ценой открытия.
Class<-ifelse(PriceChange>0, "UP","DOWN")
#Конвертируем в двоичную классификацию. (В наших данных не встречаются дни, когда цена открытия была равна цене закрытия, т. е. изменение было равно нулю, поэтому для упрощения мы не рассматриваем этот случай)
DataSet<-data.frame(DayofWeek,Class)
#Создаем наш набор данных
Теперь мы готовы применить наивный байесовский классификатор:
MyModel<-naiveBayes(DataSet[,1],DataSet[,2])
#Входное значение, или независимая переменная (DataSet[,1]), и то, что мы собираемся предсказывать, зависимая переменная (DataSet[,2]).Поздравляю! Мы применили алгоритм машинного обучения для анализа акций Apple. Теперь давайте разберемся в результатах.
Здесь отображена вероятность повышения или понижения цены на основе исходного набора данных ( известного как предыдущие вероятности). Мы можем видеть небольшой медвежий уклон.
Здесь отображены условные вероятности (указывается вероятность роста или падения цены для каждого дня недели).
Видно, что модель не очень хороша, т. к. она не возвращает высоких вероятностей. Тем не менее заметно, что открывать длинные позиции лучше в начале недели, а шортить ближе к концу.
Улучшаем модель
Очевидно вам захочется использовать более сложную стратегию, нежели просто ориентирование на день недели. Давайте добавим пересечение со скользящей средней в нашу модель (вы можете получить больше информации о добавлении различных индикаторов к вашей модели здесь)
Я предпочитаю использовать экспоненциальные скользящие средние, поэтому давайте рассмотрим 5-ти дневные и 10-дневные экспоненциальные скользящие средние (EMA).
Для начала нам необходимо рассчитать EMA:
EMA5<-EMA(Op(AAPL),n = 5)
#Мы рассчитываем 5-периодную EMA по цене открытия
EMA10<-EMA(Op(AAPL),n = 10)
#Затем 10-ти периодную EMA, так же по цене открытия
Затем рассчитываем пересечение:
EMACross <- EMA5 - EMA10
#Положительные значения будут означать что EMA5 расположена на графике выше EMA10Теперь округляем значения до 2-х знаков после запятой. Это важно, поскольку если попадется значение, которое наивный классификатор байеса не видел во время обучения, он автоматически рассчитает вероятность в 0%. Например, если мы смотрим на пересечение EMA с точностью до 6-ти знаков, и была найдена высокая вероятность движения цены вниз, когда разница была $2.349181, а затем была представлена новая точка данных, которая имела разницу $2.349182, будет рассчитана 0% вероятность повышения или понижения цены. Окрулив до 2-х знаков после запятой, мы снижаем риск столкнуться с неизвестным для модели значением (при условии, что для обучения использовался достаточно большой набор данных, в котором скорее всего встретятся все значения индикатора). Это важное ограничение, о котором нужно помнить, при построении собственных моделей.
EMACross<-round(EMACross,2)Давайте создадим новый dataset и разделим данные на тренировочный и тестовый набор. Таким образом, мы сможем понять, насколько хорошо работает наша модель на новых данных.
DataSet2<-data.frame(DayofWeek,EMACross, Class)
DataSet2<-DataSet2[-c(1:10),]
#Нам нужно удалить значения, в которых 10-периодная скользящая средняя все еще не рассчитана
TrainingSet<-DataSet2[1:328,]
#Мы используем 2/3 данных для обучения модели
TestSet<-DataSet2[329:492,]
#И 1/3 для тестирования моделиТеперь построим модель:
EMACrossModel<-naiveBayes(TrainingSet[,1:2],TrainingSet[,3])Условная вероятность пересечения скользящих средних – число, которое показывает среднее значение для каждого случая ([,1]) и для стандартного отклонения ([,2]). Мы можем видеть, что в среднем разница между 5-дневной EMA и 10-ти дневной EMА для длинных и коротких торгов была $0.54 и -$0.24 соответственно.
Теперь протестируем на новых данных:
table(predict(EMACrossModel,TestSet),TestSet[,3],dnn=list('predicted','actual'))Примечание переводчика 4
Я почему-то долго не мог понять как читать эту таблицу. Для тех, у кого тоже был тяжелый день: числа на пересечениях down-down и up-up это количество дней, в которых предсказание совпало с реальными данными. Соответственно если смотреть на столбец down и строку up – это количество дней, в которых наша модель предсказала движение вверх, а реально было движение вниз.
Всего в тестовой выборке 164 дня. При этом предсказания нашей модели совпали с реальными данными 79 раз или в 48% случаев.
Этот результат нельзя назвать хорошим, но он должен дать вам представление о том, как построить свою собственную стратегию, основанную на машинном обучении. В следующей части, мы посмотрим, как можно использовать эту модель для улучшения вашей стратегии.
Примечание переводчика 5. На сегодняшний день есть еще 2 статьи из этого цикла: про дерево решений и про нейронные сети. Статьи в таком же стиле, т.е. не глубокие, а только дающие общее представление о вопросе. Если интересно — я продолжу переводить. Обо всех замечаниях, неточностях и прочих ошибках пишите в личку.
