
PostgreSQL это современная, динамично развивающаяся СУБД с очень большим набором возможностей которые позволяют решать самый широкий спектр задач. Использование PostgreSQL как правило относится к очень критичному сегменту ИТ инфраструктуры который связан с обработкой и хранением данных. Учитывая особое место СУБД в инфраструктуре и степень критичности возложенных на нее задач, возникает вопрос мониторинга и надлежащего контроля за работой СУБД. В этом плане PostgreSQL обладает широкими внутренними средствами сбора и хранения статистики. Собираемая статистика позволяет получить довольно подробную картину о том что происходит под капотом в процессе функционирования СУБД. Эта статистика хранится в специальных системных таблицах-представлениях и постоянно обновляется. Выполняя обычные SQL запросы в эти таблицы можно получать разнообразные данные о базах, таблицах, индексах и других подсистемах СУБД.
Ниже я описываю способ и средства для мониторинга PostgreSQL в системе мониторинга Zabbix. Мне нравится эта система мониторинга поскольку предоставляет широкие возможности для реализации самого кастомного мониторинга самых разных систем и процессов.
Мониторинг будет строиться на основе SQL запросов к таблицам статистики. Сами запросы оформлены в виде дополнительного конфигурационного файла к zabbix агенту, в котором SQL запросы обернуты в т.н. UserParameters — пользовательские параметры мониторинга. Пользовательский параметр в Zabbix это отличный способ который позволяет настраивать мониторинг для нестандартных вещей, такими вещами в нашем случае будут параметры работы PostgreSQL. Каждый пользовательский параметр состоит из двух элементов: Название ключа и Команда. Название ключа представляет собой уникальное имя которое не пересекается с другими именами ключей. Команда — это собственно команда-действие которое должен выполнить агент zabbix. В расширенном варианте этой команде могут быть переданы различные параметры. В конфигурации заббикса, это выглядит так:
UserParameter=custom.simple.key,/usr/local/bin/simple-script
UserParameter=custom.ext.key[*],/usr/local/bin/ext-script $1 $2
Таким образом, все запросы к статистике PostgreSQL представляют собой запросы клиента psql обернутые в пользовательские параметры.
Сильные стороны:
- минимальные требования к конфигурированию наблюдаемого узла — в самом простом случае добавляем конфиг и перезапускаем zabbix агент (сложный случай предполагает донастройку прав доступа к PostgreSQL);
- настройка параметров подключения к PostgreSQL, как и пороговые значения для триггеров выполняются через переменные-макросы в веб-интерфейсе — таким образом не нужно залазить в триггеры и плодить шаблон на случай разных пороговых значений для разных хостов (макросы можно назначить на хост);
- широкий спектр собираемых данных (соединения, время транзакций, статистика по базам и таблицам, потоковая репликация и пр.);
- низкоуровневое обнаружение для баз данных, таблиц и серверов stand-by.
Слабые стороны:
- очень много наблюдаемых параметров, возможно кто-то захочет что-то отключить.
- в зависимости от версии PostgreSQL какие-то вещи не будут работать. В частности, это касается мониторинга репликации, т.к. некоторых функций попросту нет в старых версиях. Писалось с оглядкой на версии 9.2 и выше.
- также для некоторых вещей требуется наличие установленных расширений pg_stat_statements и pg_buffercache — если расширения не установлены часть параметров будет недоступна для наблюдения.
Возможности мониторинга:
- информация по объему выделяемых и записываемых буферах, чекпоинтах и времени записи в процессе чекпойинтов — pg_stat_bgwriter
- общая информация по shared buffers — здесь требуется расширение pg_buffercache. Также хочу отметить что запросы к этой статистике являются ресурсозатратными, что отражено в документации к расширению, поэтому в зависимости от потребностей можно либо увеличить интервал опроса, либо выключить параметры совсем.
- общая информация по сервису — аптайм, время ответа, cache hit ratio, среднее время запроса.
- информация по клиентским соединениям и времени выполнения запросов/транзакций — pg_stat_activity.
- размер баз данных и суммарная статистика по всем базам (коммиты/роллбэки, чтение/запись, временные файлы) — pg_stat_database
- потабличная статистика (чтение/запись, кол-во служебных задач такие как vacuum/analyze) — pg_stat_user_tables, pg_statio_user_tables.
- информация по потоковой репликации (статус сервера, количество реплик, лаг с ними) — pg_stat_replication
- прочие штуки (кол-во строк в таблице, существование триггера, параметры конфигурации, WAL журналы)
Дополнительно стоит отметить, что для сбора статистических данных необходимо включить следующие параметры в postgresql.conf:
track_activities — включает трекинг команд (queries/statements) всеми клиентскими процессами;
track_counts — включает сбор статистики по таблицам и индексам;
Установка и настройка.
Все необходимое для настройки находится в Github репозитории.
# git clone https://github.com/lesovsky/zabbix-extensions/
# cp zabbix-extensions/files/postgresql/postgresql.conf /etc/zabbix/zabbix_agentd.d/
Дальше следует отметить что для выполнения запросов со стороны агента, необходимо чтобы в pg_hba конфигурации был определен соответствующий доступ — агент должен иметь возможность устаналивать соединения с postgres сервисом в целевую базу и исполнять запросы. В самом простом случае нужно добавить следующую строку в pg_hba.conf (для разных дистрибутив расположение файла может отличаться) — разрешаем подключения от имени postgres к базе mydb с localhost.
host mydb postgres 127.0.0.1/32 trust
Незабываем, что после изменения pg_hba.conf сервису postgresql нужно сделать reload (pg_ctl reload). Однако это самый простой вариант и не совсем безопасный, поэтому если вы хотите использовать парольную или более сложную схему доступа, то еще раз внимательно ознакомьтесь с pg_hba и .pgpass.
Итак файл конфигурации скопирован, осталось подгрузить его в основную конфигурацию, убедитесь что в основном файле конфигурации агента, есть строка Include c указанным там путем где размещены дополнительные файлы конфигурации. Теперь перезапускаем агента, после чего можем проверить работу выполнением самой простой проверки — используем pgsql.ping и в квадратных скобках указываем опции подключения к postgres, которые будет переданы psql клиенту.
# systemctl restart zabbix-agent.service
# zabbix-get -s 127.0.0.1 -k pgsql.ping['-h 127.0.0.1 -p 5432 -U postgres -d mydb']
Если вы правильно прописали доступ, то вам вернется время ответа сервиса в милисекундах. Если вернулась пустая строка, то тут проблема с доступом в pg_hba. Если вернулась строка ZBX_NOTSUPPORTED — конфигурация не подгрузилась, проверяйте конфиг агента, пути в Include и выставленные на конфиг права.
Когда команда проверки возвращает правильный ответ, остается скачать шаблон и загрузить его в веб интерфейс и назначить на целевой хост. Скачать шаблон можно также из репозитория (postgresql-extended-template.xml). После импорта нужно перейти на вкладку настройки макросов шаблона и настроить их.

Ниже список и краткое описание:
- PG_CONNINFO — это параметры подключения который будут переданы клиенту psql при выполнении запроса. Это самый важный макрос т.к. определяет параметры подключения к postgres сервису. Строка указанная по умолчанию является более-менее универсальной для любых случаев, однако если у вас несколько серверов и у каждого сервера отличные от других настройки, то у хостов в заббиксе можно определить макрос с таким же именем и задать ему индивидуальное значение. При выполнении проверки макрос хоста имеет приоритет перед макросом шаблона.
- PG_CONNINFO_STANDBY — это параметры подключения который будут переданы утилите psql при выполнении запроса на stanby сервера (определение лага репликации).
- PG_CACHE_HIT_RATIO — это пороговое значение для триггера на процент успешного попадания в кэш; сработает триггер если процент попадания будет ниже этой отметки;
- PG_CHECKPOINTS_REQ_THRESHOLD — пороговое значение для чекпойнтов по требованию
- PG_CONFLICTS_THRESHOLD — пороговое значение для конфликтов возникших при выполнении запросов на серверах standby;
- PG_CONN_IDLE_IN_TRANSACTION — пороговое значение для соединений которые открыли транзакцию и ничего при этом не делают (плохие транзакции);
- PG_CONN_TOTAL_PCT — пороговое значение для процента открытых соединений к максимально возможному числу соединений (если 100%, то всё, коннекты кончились);
- PG_CONN_WAITING — пороговое значение для заблокированных запросов которые ждут завершения других запросов;
- PG_DATABASE_SIZE_THRESHOLD — пороговое значение для размера БД;
- PG_DEADLOCKS_THRESHOLD — пороговое значение для дедлоков (к счастью они разрешаются автоматически, но об их наличии желательно быть в курсе, т.к. это прямое свидетельство некачественно написанного кода);
- PG_LONG_QUERY_THRESHOLD — пороговое значение для времени выполнения запросов; сработает триггер если будут запросы чье время выполнения больше этой отметки;
- PG_PING_THRESHOLD_MS — пороговое значение для времени ответа сервиса;
- PG_SR_LAG_BYTE — пороговое значение для лага репликации в байтах;
- PG_SR_LAG_SEC — пороговое значение для лага репликации в секундах;
- PG_UPTIME_THRESHOLD — пороговое значение аптайма, если аптайм ниже отметки значит сервис перезапустили;
Из текста триггеров должно стать понятно для чего нужны эти пороговые значения:
- PostgreSQL active transaction to long — зафиксирована длинная транзакция или запрос;
- PostgreSQL cache hit ratio too low — слишком низкий процент попадания в кэш;
- PostgreSQL deadlock occured — зафиксирован дедлок;
- PostgreSQL idle in transaction connections to high — много коннектов в состоянии idle in transaction;
- PostgreSQL idle transaction to long — зафиксирована длинная транзакция в состоянии idel in transaction;
- PostgreSQL number of waiting connections to high — зафиксированн запрос или транзакция в состоянии ожидания;
- PostgreSQL recovery conflict occured — обнаружен конфликт при восстановлении на реплике;
- PostgreSQL required checkpoints occurs to frequently — чекпоинты случаются слишком часто;
- PostgreSQL response to long — долгое время ответа;
- PostgreSQL service not running — сервис не запущен;
- PostgreSQL service was restarted — сервис перезапустился;
- PostgreSQL total number of connections to high — общее число коннектов слишком большое и приближается к max_connections;
- PostgreSQL waiting transaction to long — зафиксирована слишком длинный запрос или транзакция в состоянии ожидания;
- PostgreSQL database {#DBNAME} to large — размер БД слишком большой;
- PostgreSQL streaming lag between {HOSTNAME} and {#HOTSTANDBY} to high — лаг репликации между серверами слишком большой.
Правила низкоуровневого обнаружения
- PostgreSQL databases discovery — обнаружение имеющихся БД с возможностью фильтрации по регулярным выражениям. При обнаружении добавляется график о размерах;
- PostgreSQL database tables discovery — обнаружение имеющихся таблиц в наблюдаемой базе с возможностью фильтрации по регулярным выражениям. Будьте внимательны с фильтром и добавляйте только те таблицы что вам реально интересны, т.к. это правило порождает 21 параметр на каждую найденную таблицу. При обнаружении добавляются графики о размерах, сканированиях, изменении строк и статистике по чтению.
- PostgreSQL streaming stand-by discovery — обнаружение подключенных реплик. При обнаружении добавляется график с лагом репликации.
Доступные графики, если говорить про графики, то я постарался сгруппировать наблюдаемые параметры, при этом не перегружая графики чрезмерно большим количеством парамтеров. Так информация из pg_stat_user_tables разнесена на 4 графика.
- PostgreSQL bgwriter — общая информация о том что происходит с буфферами (сколько выделено, сколько и каким образом записано).
- PostgreSQL buffers — общая информация по состоянию shared buffers (сколько буфферов, сколько используется, сколько «грязных» буфферов).
- PostgreSQL checkpoints — информация по происходящим чекпоинтам.
- PostgreSQL connections — информация по клиентским соединениям.
- PostgreSQL service responce — время ответа сервиса и среднее время выполнения запросов.
- PostgreSQL summary db stats: block hit/read — чтение из кэша и с диска.
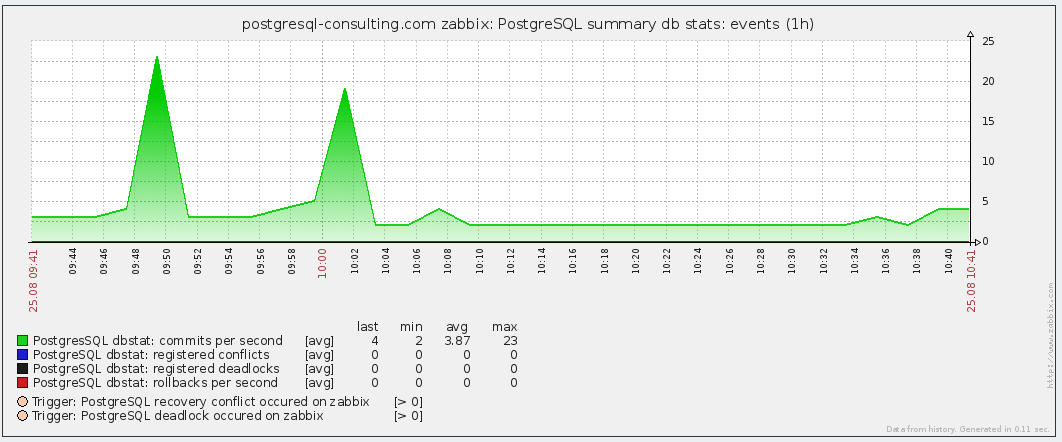
- PostgreSQL summary db stats: events — события в базе (дедлоки, конфликты, коммиты, роллбэки).
- PostgreSQL summary db stats: temp files — информация по временным файлам.
- PostgreSQL summary db stats: tuples — общая информация по изменениям строк.
- PostgreSQL transactions — время выполнения запросов.
- PostgreSQL uptime — аптайм и процент попадания в кэш.
- PostgreSQL write-ahead log — информация по WAL журналу (объем записи и кол-во файлов).
- PostgreSQL: database {#DBNAME} size — информация по изменению размера БД.
- PostgreSQL table {#TABLENAME} maintenance — операции обслуживания таблицы (autovacuum, autoanalyze, vacuum, analyze).
- PostgreSQL table {#TABLENAME} read stats — статистика по чтению из кэша, диска.
- PostgreSQL table {#TABLENAME} rows — изменение в строках.
- PostgreSQL table {#TABLENAME} scans — информация по сканирования (sequential/index scans).
- PostgreSQL table {#TABLENAME} size — информация по размерам таблиц и их индексов.
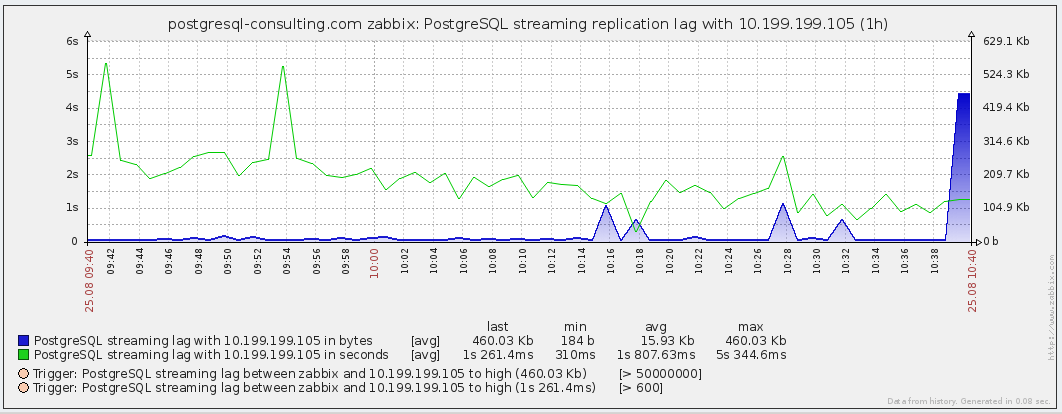
- PostgreSQL streaming replication lag with {#HOTSTANDBY} — размер лага репликации с серверами-репликами.
В заключении, немного графиков-примеров:
Здесь как мы видим, в базе регулярно создаются временные файлы, следует поискать виновника в логе и пересмотреть work_mem.

Здесь события происходящие в базе — коммиты/роллбэки и конфликты/дедлоки — вцелом все хорошо здесь.
Здесь состояние потоковой репликации с одним из серверов — время отставания в секундах и байтах.
И заключительный график — время отклика службы и среднее время запроса.

Вот и все, всем спасибо за внимание!
