В одной из прошлых статей мы кратко рассказали, как грид контролы работают с удаленным сервером, используя OData протокол. Большинство современных грид контролов позволяют удобно группировать данные по нескольким колонками. Рассмотрим подробнее, как формулируются запросы к REST серверу, в случае, когда грид производит автоматическую группировку данных.
Грид контролы, позволяющие группировать записи по нескольким колонкам, существенно упрощают жизнь как программисту, так и конечному пользователю. Очень удобно иметь возможность сгруппировать, например, список задач, выделить задачи, требующие помощи, разделить их по приоритетам, и т.д.
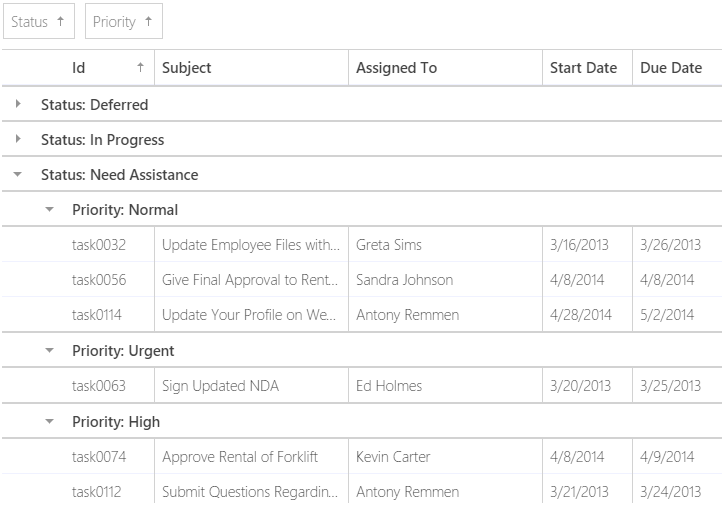
Потом можно сгруппировать их по сотрудникам и просмотреть все задачи для выбранного сотрудника, также сгруппированные по статусу и приоритету.
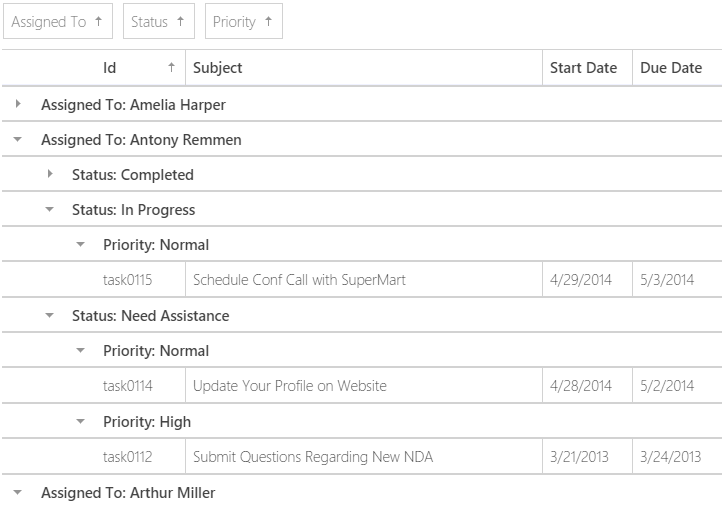
Особенно приятно для разработчиков то, что для создания такого комфортного интерфейса достаточно лишь нескольких строк кода.
Мы подготовили пример списка задач
databoom.space/samples_devexpress_grouping.html
Для этого примера мы использовали dxDataGrid компании Devexpress (этот грид входит в набор компонентов DevExtreme Web)
Для того чтобы включить в гриде группировку, достаточно указать свойство
groupPanel: {visible: true}
После этого грид позволяет группировать данные перетаскивая заголовки колонок на панель группировки.
Чтобы при первом показе грид сгруппировал данные по каким-либо колонкам, необходимо в описании колонок указать:
groupIndex: 0 (для первой колонки, по содержимому которой группируются данные)
groupIndex: 1 (для второй колонки, и т.д.)
Всего пара настроек, и пользователи будут Вам благодарны :)
Мы указали гриду URL по которому он может получить список задач
samples.databoom.space/api1/sampledb/collections
Далее грид автоматически формирует запрос к серверу добавляя к URL различные условия запроса.
Первый запрос, который грид шлет на сервер, для показа списка задач, сгруппированных по статусу и приоритету:
https://samples.databoom.space/api1/sampledb/collections/tasks?$orderby=Task_Status,Task_Priority,id&$top=21&$inlinecount=allpages
Поскольку данные отсортированы, то в качестве группы он берет значения полей «Task_Status» и «Task_Priority» для первой записи. Далее идут несколько записей с повторяющимися значениями этих полей. Далее идет несколько записей у которых сменился приоритет. То есть в данном случае достаточно простого запроса для получения отсортированных данных.
Если мы будем скролировать грид вниз, чтобы посмотреть остальные записи, грид попросит у сервера следующие записи, например:
https://samples.databoom.space/api1/sampledb/collections/tasks?$orderby=Task_Status,Task_Priority,id&$skip=29&$top=32&$inlinecount=allpages
В данном случае добавился еще один параметр запроса:
Перечисленные выше запросы ничем не отличаются от простых запросов, которые грид слал бы серверу для показа списка задач, отсортированных по статусу и приоритету.
Теперь попробуем схлопнуть группу записей со статусом «Completed». Грид шлёт на сервер 2 запроса:
Первый запрос
Этот запрос нужен для того, чтобы узнать количество записей со статусом «Completed» (те что мы схлопываем)
Второй запрос
Если мы схлопываем следующую группу, то первый из этих двух запросов также просит количество записей для схлопываемой группы, а вот следующий запрос теперь уже включает исключения из записей в двух схлопнутых группах:
Таким образом, грид вполне успешно обходится простыми запросами, с ипользованием сортировки, простой фильтрации и условий постраничного вывода.
В случае большого количества групп запросы с фильтрацией всех схлопнутых групп, с большим количеством условий на неравенство ($filter=… and … and … and … and … ) становятся слишком большими и недостаточно эффективными.
Можно было бы просто получить список групп, а далее просить записи по равенству полей (все записи, принадлежащие определенной группе), с запросом на сортировку по этим полям. Такой запрос при наличии необходимых индексов быстро получает небольшое количество записей внутри одной группы и потом сортирует это небольшое количество.
Но для работы таким способом необходимо было бы иметь возможность стандартизованного выполнения запросов на агрегирование данных.
Возможность выполнения запросов на агрегирование данных появилась в стандарте OData версии 4.0, и производители грид контролов собираются реализовать поддержку этих возможностей в новых версиях продуктов.
Удобство (зачем это нужно)
Грид контролы, позволяющие группировать записи по нескольким колонкам, существенно упрощают жизнь как программисту, так и конечному пользователю. Очень удобно иметь возможность сгруппировать, например, список задач, выделить задачи, требующие помощи, разделить их по приоритетам, и т.д.

Потом можно сгруппировать их по сотрудникам и просмотреть все задачи для выбранного сотрудника, также сгруппированные по статусу и приоритету.

Особенно приятно для разработчиков то, что для создания такого комфортного интерфейса достаточно лишь нескольких строк кода.
Как это сделать
Мы подготовили пример списка задач
databoom.space/samples_devexpress_grouping.html
Для этого примера мы использовали dxDataGrid компании Devexpress (этот грид входит в набор компонентов DevExtreme Web)
Подробнее можно посмотреть в документации dxDataGrid:
js.devexpress.com/Documentation/ApiReference/UI_Widgets/dxDataGrid
посмотреть примеры:
js.devexpress.com/Demos/WidgetsGallery/#demo/datagridgridpagingandscrollingpager/generic/light/default
простой пример работы грида без группировки с сервером databoom:
databoom.space/samples_devexpress_grid.html
Для того чтобы грид работал с databoom достаточно указать URL со списком данных для показа в гриде, например, список людей:
samples.databoom.space/api1/sampledb/collections/persons
Для того чтобы включить в гриде группировку, достаточно указать свойство
groupPanel: {visible: true}
После этого грид позволяет группировать данные перетаскивая заголовки колонок на панель группировки.
Чтобы при первом показе грид сгруппировал данные по каким-либо колонкам, необходимо в описании колонок указать:
groupIndex: 0 (для первой колонки, по содержимому которой группируются данные)
groupIndex: 1 (для второй колонки, и т.д.)
Всего пара настроек, и пользователи будут Вам благодарны :)
Как это работает
Мы указали гриду URL по которому он может получить список задач
samples.databoom.space/api1/sampledb/collections
Далее грид автоматически формирует запрос к серверу добавляя к URL различные условия запроса.
Первый запрос, который грид шлет на сервер, для показа списка задач, сгруппированных по статусу и приоритету:
https://samples.databoom.space/api1/sampledb/collections/tasks?$orderby=Task_Status,Task_Priority,id&$top=21&$inlinecount=allpages
- $orderby=Task_Status,Task_Priority – отсортировать записи по статусу и приоритету
- $top=31 – грид просит ограничить результат и выслать 31 запись
- $inlinecount=allpages – грид просит вернуть общее количество записей в коллекции
Поскольку данные отсортированы, то в качестве группы он берет значения полей «Task_Status» и «Task_Priority» для первой записи. Далее идут несколько записей с повторяющимися значениями этих полей. Далее идет несколько записей у которых сменился приоритет. То есть в данном случае достаточно простого запроса для получения отсортированных данных.
Если мы будем скролировать грид вниз, чтобы посмотреть остальные записи, грид попросит у сервера следующие записи, например:
https://samples.databoom.space/api1/sampledb/collections/tasks?$orderby=Task_Status,Task_Priority,id&$skip=29&$top=32&$inlinecount=allpages
В данном случае добавился еще один параметр запроса:
- $skip=29 –пропустить указанное количество записей
Перечисленные выше запросы ничем не отличаются от простых запросов, которые грид слал бы серверу для показа списка задач, отсортированных по статусу и приоритету.
Теперь попробуем схлопнуть группу записей со статусом «Completed». Грид шлёт на сервер 2 запроса:
- https://samples.databoom.space/api1/sampledb/collections/tasks?$top=1&$filter=(Task_Status eq 'Completed')&$inlinecount=allpages
- https://samples.databoom.space/api1/sampledb/collections/tasks?$orderby=Task_Status,Task_Priority,id&$top=31&$filter=((Task_Status ne 'Completed'))&$inlinecount=allpages
Первый запрос
- $filter=(Task_Status eq 'Completed') – отобрать все записи со статусом «Completed» (те что мы схлопываем)
- $top=1 – грид просит только одну запись
- $inlinecount=allpages – грид просит вернуть общее количество записей с данным статусом
Этот запрос нужен для того, чтобы узнать количество записей со статусом «Completed» (те что мы схлопываем)
Второй запрос
- $orderby=Task_Status,Task_Priority – отсортировать данные по указанным полям
- $filter=(Task_Status ne 'Completed') – отобрать все записи со статусом отличным от «Completed» (те записи, что идут после схлопнутых со статусом «Completed»)
- $top=31 – грид просит 31 запись
- $inlinecount=allpages – грид просит вернуть общее количество записей с данным статусом
Если мы схлопываем следующую группу, то первый из этих двух запросов также просит количество записей для схлопываемой группы, а вот следующий запрос теперь уже включает исключения из записей в двух схлопнутых группах:
- $filter=(Task_Status ne 'Completed') and (Task_Status ne 'Deferred')
Таким образом, грид вполне успешно обходится простыми запросами, с ипользованием сортировки, простой фильтрации и условий постраничного вывода.
Замечания (как могло бы работать)
В случае большого количества групп запросы с фильтрацией всех схлопнутых групп, с большим количеством условий на неравенство ($filter=… and … and … and … and … ) становятся слишком большими и недостаточно эффективными.
Можно было бы просто получить список групп, а далее просить записи по равенству полей (все записи, принадлежащие определенной группе), с запросом на сортировку по этим полям. Такой запрос при наличии необходимых индексов быстро получает небольшое количество записей внутри одной группы и потом сортирует это небольшое количество.
Но для работы таким способом необходимо было бы иметь возможность стандартизованного выполнения запросов на агрегирование данных.
Возможность выполнения запросов на агрегирование данных появилась в стандарте OData версии 4.0, и производители грид контролов собираются реализовать поддержку этих возможностей в новых версиях продуктов.
