
[ Первая часть ]
В этом посте будет то, что не поместилось в первую часть. Это некоторые операторы, которые есть в
aggregation framework и достаточно вольный перевод трех статей из раздела экоситема на сайте со справкой к MongoDB, описывающих некоторые случаи применения для интернет-коммерции.Случаи использования разделены там на восемь статей, которые условно можно разделить на три группы. Мне показались самыми интересными для перевода три материала, связанные с
e-commerce.- Операторы в aggregation framework
- Каталог продуктов
- Корзина и управления остатками на складе
- Иерархия категорий
Операторы в aggregation framework
Как правило в
aggregation framework есть основные операторы например $project или $group из которых формируются цепочки pipeline.Но есть и такие операторы как
$cond, которые всегда находятся внутри основных операторов. $cond примерный аналог обычного if
Появился с версии
2.6 и у него есть две формы записи:{ $cond: { if: <boolean-expression>, then: <true-case>, else: <false-case-> } }
или
{ $cond: [ <boolean-expression>, <true-case>, <false-case> ] }
Пример, есть следующие документы:
{ "_id" : 1, "item" : "abc1", qty: 300 }
{ "_id" : 2, "item" : "abc2", qty: 200 }
{ "_id" : 3, "item" : "xyz1", qty: 250 }
Установим
discount равным 30, если поле qty больше или равно 250, иначе discount будет равен 20db.test.aggregate( [ {
$project:{
item: 1,
discount: { $cond: { if: { $gte: [ "$qty", 250 ] }, then: 30, else: 20 } }
}
} ] )
Полученный результат:
{ "_id" : 1, "item" : "abc1", "discount" : 30 }
{ "_id" : 2, "item" : "abc2", "discount" : 20 }
{ "_id" : 3, "item" : "xyz1", "discount" : 30 }
$ifNull проверяет что поле существует и не равно null
Если поля нет, то заменяет его нужным значением.
{ "_id" : 1, "item" : "abc1", description: "product 1", qty: 300 }
{ "_id" : 2, "item" : "abc2", description: null, qty: 200 }
{ "_id" : 3, "item" : "xyz1", qty: 250 }
Unspecified если поля description не существует или оно равно null.db.test.aggregate( [ {
$project: { item: 1, description: { $ifNull: [ "$description", "Unspecified" ]}}
} ] )
{ "_id" : 1, "item" : "abc1", "description" : "product 1" }
{ "_id" : 2, "item" : "abc2", "description" : "Unspecified" }
{ "_id" : 3, "item" : "xyz1", "description" : "Unspecified" }
$let создает переменные
Оператор
$let может создавать переменные и потом проводить с ними какие то операции. В примере создаем две переменные,
total присваиваем значение сумы двух полей price, tax. А переменной discounted результат, который возвращает логический оператор cond. После этого перемножаем переменные
total и discounted и возвращаем их произведение.{ _id: 1, price: 10, tax: 0.50, applyDiscount: true }
{ _id: 2, price: 10, tax: 0.25, applyDiscount: false }
db.test.aggregate( [ {
$project: {
finalTotal: {
$let: {
vars: {
total: { $add: [ '$price', '$tax' ] },
discounted: { $cond: { if: '$applyDiscount', then: 0.9, else: 1 } }
},
in: { $multiply: [ "$$total", "$$discounted" ] }
}
}
}
}] )
{ "_id" : 1, "finalTotal" : 9.450000000000001 }
{ "_id" : 2, "finalTotal" : 10.25 }
$map применяет определенное выражения к каждому элементу
Применяет какое либо выражение к каждому элементу, в данном примере каждому элементу массива прибавляется
+2.{ _id: 1, quizzes: [ 5, 6, 7 ] }
{ _id: 2, quizzes: [ ] }
db.grades.aggregate([{
$project:{
adjustedGrades: {$map: {input: "$quizzes", as: "grade", in: { $add: [ "$$grade", 2 ] } } }
}
}])
{ "_id" : 1, "adjustedGrades" : [ 7, 8, 9 ] }
{ "_id" : 2, "adjustedGrades" : [ ] }
$setEquals сравнивает массивы
Сравнивает два и более массивов и возвращает
true если они имеют похожие элементы.| Пример | Результат |
| { $setEquals: [ [ «a», «b», «a» ], [ «b», «a» ] ] } | true |
| { $setEquals: [ [ «a», «b» ], [ [ «a», «b» ] ] ] } | false |
$setIntersection возвращает совпавшие элементы
Принимает два или более массивов и возвращает массив, содержащий элементы, которые присутствуют в каждом из входных массивов. Если один из массивов пустой или содержит вложенные массивы, то возвращает пустой массив.
| Пример | Результат |
| { $setIntersection: [ [ «a», «b», «a» ], [ «b», «a» ] ] } | [ «b», «a» ] |
| { $setIntersection: [ [ «a», «b» ], [ [ «a», «b» ] ] ] } | [ ] |
$setUnion возвращает элементы, присутствующие в любом из входных параметров.
Принимает два или более массивов и возвращает массив, содержащий элементы, которые появляются в любом входном массиве.
| Пример | Результат |
| { $setUnion: [ [ «a», «b», «a» ], [ «b», «a» ] ] } | [ «b», «a» ] |
| { $setUnion: [ [ «a», «b» ], [ [ «a», «b» ] ] ] } | [ [ «a», «b» ], «b», «a» ] |
$setDifference тоже что setUnion но наоборот
| Пример | Результат |
| { $setDifference: [ [ «a», «b», «a» ], [ «b», «a» ] ] } | [ ] |
| { $setDifference: [ [ «a», «b» ], [ [ «a», «b» ] ] ] } | [ «a», «b» ] |
$setIsSubset проверяет на подмножество
Принимает два массива и возвращает True, если первый массив подмножество второго, в том числе когда первый массив равен второму, и false если наоборот.
| Пример | Результат |
| { $setIsSubset: [ [ «a», «b», «a» ], [ «b», «a» ] ] } | true |
| { $setIsSubset: [ [ «a», «b» ], [ [ «a», «b» ] ] ] } | false |
$anyElementTrue
Оценивает массив в виде набора элементов и возвращает True, если любой из элементов True и false если наоборот. Пустой массив возвращает false. Принимает один аргумент.
| Пример | Результат |
| { $anyElementTrue: [ [ true, false ] ] } | |
| { $anyElementTrue: [ [ [ false ] ] ] } | |
| { $anyElementTrue: [ [ null, false, 0 ] ] } | |
| { $anyElementTrue: [ [ ] ] } |
$allElementsTrue
Проверяет массив и возвращает True, если не один элемент массива не равен false. В противном случае, возвращает false. Пустой массив возвращает True.
| Пример | Результат |
| { $allElementsTrue: [ [ true, 1, «someString» ] ] } | |
| { $allElementsTrue: [ [ [ false ] ] ] } | |
| { $allElementsTrue: [ [ ] ] } | |
| { $allElementsTrue: [ [ null, false, 0 ] ] } |
$cmp — сравнивает два элемента
Сравнивает два элемента и возвращает:
- -1, если первое значение меньше второго.
- 1, если первое значение больше второго.
- 0, если оба значения равны.
{ "_id" : 1, "item" : "abc1", description: "product 1", qty: 300 }
{ "_id" : 2, "item" : "abc2", description: "product 2", qty: 200 }
{ "_id" : 3, "item" : "xyz1", description: "product 3", qty: 250 }
C помощью
$cmp сравниваем значение поля qty с 250:db.test.aggregate( [ {
$project:{ _id: 0, item: 1,qty: 1, cmpTo250: { $cmp: [ "$qty", 250 ] } }
} ] )
Результат:
{ "item" : "abc1", "qty" : 300, "cmpTo250" : 1 }
{ "item" : "abc2", "qty" : 200, "cmpTo250" : -1 }
{ "item" : "xyz1", "qty" : 250, "cmpTo250" : 0 }
$add прибавляет
{ "_id" : 1, "item" : "abc", "price" : 10, "fee" : 2 }
{ "_id" : 2, "item" : "jkl", "price" : 20, "fee" : 1 }
db.test.aggregate([ { $project: { item: 1, total: { $add: [ "$price", "$fee" ] } } } ])
{ "_id" : 1, "item" : "abc", "total" : 12 }
{ "_id" : 2, "item" : "jkl", "total" : 21 }
$subtract вычитает
Может возвращать разницу дат в милисекундах.
{ "_id" : 1, "item" : "abc", "price" : 10, "fee" : 2, "discount" : 5 }
{ "_id" : 2, "item" : "jkl", "price" : 20, "fee" : 1, "discount" : 2 }
db.test.aggregate( [ {
$project: { item: 1, total: { $subtract: [ { $add: [ "$price", "$fee" ] }, "$discount" ] } }
} ] )
{ "_id" : 1, "item" : "abc", "total" : 7 }
{ "_id" : 2, "item" : "jkl", "total" : 19 }
$multiply умножает
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity": 2 }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity": 1 }
db.test.aggregate([ { $project: { item: 1, total: { $multiply: [ "$price", "$quantity" ] } } } ])
{ "_id" : 1, "item" : "abc", "total" : 20 }
{ "_id" : 2, "item" : "jkl", "total" : 20 }
$divide оператор деления
{ "_id" : 1, "name" : "A", "hours" : 80, "resources" : 7 },
{ "_id" : 2, "name" : "B", "hours" : 40, "resources" : 4 }
db.test.aggregate([ { $project: { name: 1, workdays: { $divide: [ "$hours", 8 ] } } } ])
{ "_id" : 1, "name" : "A", "workdays" : 10 }
{ "_id" : 2, "name" : "B", "workdays" : 5 }
$concat — конкатенация строк
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" }
db.test.aggregate([ { $project: { itemDescription: { $concat: [ "$item", " - ", "$description" ] } } } ])
{ "_id" : 1, "itemDescription" : "ABC1 - product 1" }
$substr возвращает подстроку
Получает индекс начала и количество символов от начала. Индекс начинается с нуля.
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" }
{ "_id" : 2, "item" : "ABC2", quarter: "13Q4", "description" : "product 2" }
db.inventory.aggregate([{
$project:{
item: 1,
yearSubstring: { $substr: [ "$quarter", 0, 2 ] },
quarterSubtring: { $substr: [ "$quarter", 2, -1 ] }
}
}])
{ "_id" : 1, "item" : "ABC1", "yearSubstring" : "13", "quarterSubtring" : "Q1" }
{ "_id" : 2, "item" : "ABC2", "yearSubstring" : "13", "quarterSubtring" : "Q4" }
$toLower — преобразует в нижний регистр
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "PRODUCT 1" }
db.test.aggregate([{
$project:{ item: { $toLower: "$item" }, description: { $toLower: "$description" }}
}])
{ "_id" : 1, "item" : "abc1", "description" : "product 1" }
$toUpper преобразует в верхний регистр
{ "_id" : 2, "item" : "abc2", quarter: "13Q4", "description" : "Product 2" }
db.inventory.aggregate( [ {
$project:{ item: { $toUpper: "$item" }, description: { $toUpper: "$description" } }
} ] )
{ "_id" : 2, "item" : "ABC2", "description" : "PRODUCT 2" }
$strcasecmp сравнивает строки
Сравнивает две строки и возвращает:
- 1, если первая строка “больше” второй строки.
- 0, если две строки равны.
- -1, если первая строка “меньше” второй строки.
Оператор не чувствителен к регистру.
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" }
{ "_id" : 2, "item" : "ABC2", quarter: "13Q4", "description" : "product 2" }
{ "_id" : 3, "item" : "XYZ1", quarter: "14Q2", "description" : null }
db.inventory.aggregate([{
$project:{ item: 1, comparisonResult: { $strcasecmp: [ "$quarter", "13q4" ] } }
}])
{ "_id" : 1, "item" : "ABC1", "comparisonResult" : -1 }
{ "_id" : 2, "item" : "ABC2", "comparisonResult" : 0 }
{ "_id" : 3, "item" : "XYZ1", "comparisonResult" : 1 }
Работа с датами
$dayOfYear день в году по счету
$dayOfMonth день в месяце по счету
$dayOfWeek возвращает день недели по счету, 1 (суббота) — 7 (воскресенье).
$year возвращает год
$month возвращает месяц по счету
$week возвращает номер недели в году как число от 0 до 53
$hour возвращает час как число между 0 и 23
$minute возвращает минуту как число между 0 и 59
$second возвращает секунды как число между 0 и 23
$millisecond возвращает милисекунды как число между 0 и 999
Возвращает день года для даты в виде числа между 1 и 366.
Например для 1 января вернет 1.
{ "_id": 1, "item": "abc", "date" : ISODate("2014-01-01T08:15:39.736Z") }
db.sales.aggregate( [ {
$project: {
year: { $year: "$date" },
month: { $month: "$date" },
day: { $dayOfMonth: "$date" },
hour: { $hour: "$date" },
minutes: { $minute: "$date" },
seconds: { $second: "$date" },
milliseconds: { $millisecond: "$date" },
dayOfYear: { $dayOfYear: "$date" },
dayOfWeek: { $dayOfWeek: "$date" },
week: { $week: "$date" }
}
} ] )
{
"_id" : 1,
"year" : 2014,
"month" : 1,
"day" : 1,
"hour" : 8,
"minutes" : 15,
"seconds" : 39,
"milliseconds" : 736,
"dayOfYear" : 1,
"dayOfWeek" : 4,
"week" : 0
}
$dateToString преобразует в строку
Преобразует объект date в строку в соответствии с заданным форматом.
{
"_id" : 1,
"item" : "abc",
"price" : 10,
"quantity" : 2,
"date" : ISODate("2014-01-01T08:15:39.736Z")
}
db.test.aggregate( [ {
$project: {
yearMonthDay: { $dateToString: { format: "%Y-%m-%d", date: "$date" } },
time: { $dateToString: { format: "%H:%M:%S:%L", date: "$date" } }
}
} ] )
{ "_id" : 1, "yearMonthDay" : "2014-01-01", "time" : "08:15:39:736" }
Каталог продуктов
Эта глава описывает основные принципы проектирования каталога товаров в системе электронной коммерции, с использованием
MongoDB.Каталог товаров должен уметь хранить различные виды объектов, у каждого из которых должен быть свой список характеристик.
Для реляционных баз данных существуют несколько решений подобных задач, отличающихся в том числе по производительности. Мы рассмотрим некоторые из этих вариантов, а затем посмотрим как это будет решаться в
MongoDB.SQL и реляционная модель данных
Concrete Table Inheritance (Наследование с таблицами конечных классов)
Первый вариант в реляционной модели — это создание своей таблицы для каждой категории товаров:
CREATE TABLE `product_audio_album` (
`sku` char(8) NOT NULL,
...
`artist` varchar(255) DEFAULT NULL,
`genre_0` varchar(255) DEFAULT NULL,
`genre_1` varchar(255) DEFAULT NULL,
...,
PRIMARY KEY(`sku`))
...
CREATE TABLE `product_film` (
`sku` char(8) NOT NULL,
...
`title` varchar(255) DEFAULT NULL,
`rating` char(8) DEFAULT NULL,
...,
PRIMARY KEY(`sku`))
...
У этого подходя есть два основных ограничения связанных с гибкостью.
- Собственно создание каждый раз новой таблицы для каждой новой категории продуктов.
- Явная адаптация запросов для конкретного типа продуктов.
Single Table Inheritance (Наследование с единой таблицей)
Второй вариант в реляционной модели состоит в использовании одной таблицы для всех категорий товаров. И добавляя новые колонки в любое время нужно сохранять данные о типах товаров:
CREATE TABLE `product` (
`sku` char(8) NOT NULL,
...
`artist` varchar(255) DEFAULT NULL,
`genre_0` varchar(255) DEFAULT NULL,
`genre_1` varchar(255) DEFAULT NULL,
...
`title` varchar(255) DEFAULT NULL,
`rating` char(8) DEFAULT NULL,
...,
PRIMARY KEY(`sku`))
Этот подход является более гибким и он позволяет делать одиночные запросы с учетом различных типов продуктов.
Multiple Table Inheritance (множественное наследование таблиц)
Также в реляционной модели можно использовать «множественное наследование таблиц», паттерн, при котором общие для всех категорий товаров атрибуты, находятся в основной таблице
product и в отдельных таблицах (для каждой категории своя) будут содержаться различающиеся атрибуты.Рассмотрим следующий
SQL пример:CREATE TABLE `product` (
`sku` char(8) NOT NULL,
`title` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
`price`, ...
PRIMARY KEY(`sku`))
CREATE TABLE `product_audio_album` (
`sku` char(8) NOT NULL,
...
`artist` varchar(255) DEFAULT NULL,
`genre_0` varchar(255) DEFAULT NULL,
`genre_1` varchar(255) DEFAULT NULL,
...,
PRIMARY KEY(`sku`),
FOREIGN KEY(`sku`) REFERENCES `product`(`sku`))
...
CREATE TABLE `product_film` (
`sku` char(8) NOT NULL,
...
`title` varchar(255) DEFAULT NULL,
`rating` char(8) DEFAULT NULL,
...,
PRIMARY KEY(`sku`),
FOREIGN KEY(`sku`) REFERENCES `product`(`sku`))
...
Этот вариант является более эффективным чем наследование одной таблицы и чуть более гибким чем создание таблицы для каждой категории. Этот вариант требует применения «дорогостоящего»
JOIN для получения всех атрибутов относящихся к конкретному товару.Значения атрибутов для каждой сущности
И последний паттерн в реляционной модели — это схема
entity-attribute-value. В соответствии с этой схемой у нас будет таблица с тремя столбцами например entity_id, attribute_id, value с помощью которых будет описываться каждый продукт.Рассмотрим пример с хранением аудио записей:
| Entity | Attribute | Value |
| sku_00e8da9b | type | Audio Album |
| sku_00e8da9b | title | A Love Supreme |
| sku_00e8da9b | ... | ... |
| sku_00e8da9b | artist | John Coltrane |
| sku_00e8da9b | genre | Jazz |
| sku_00e8da9b | genre | General |
| ... | ... | ... |
Эта схема достаточно гибкая:
Любой товар может иметь любой набор атрибутов. Новые категории продуктов не требуют внесения изменений в базу.
Недостатком этого варианта является то, что потребуются много запросов, содержащих
JOIN, что в свою очередь не очень хорошо для производительности.Кроме того, некоторые решения для
e-commerce с реляционными системами баз данных сериализуют эти данные в колонке BLOB. И атрибуты товаров становятся труднодоступными для поиска и сортировки.Не реляционная модель данных
Поскольку
mongodb не являет реляционной базой данных, то для создания каталога продукции у нас появляются дополнительные возможности в плане гибкости.Самый лучший вариант — использовать одну коллекцию для хранения всех видов документов. И поскольку для каждого документа схема может быть любой, то можно хранить все имеющиеся у товара характеристики (атрибуты) в одном документе.
В корне документа должна находится общая информация о продукте, чтобы облегчить поиск по всему каталогу. А уже в субдокументах должны находиться поля, которые у каждого документа уникальны. Рассмотрим пример:
{
sku: "00e8da9b",
type: "Audio Album",
title: "A Love Supreme",
description: "by John Coltrane",
asin: "B0000A118M",
shipping: {
weight: 6,
dimensions: {
width: 10,
height: 10,
depth: 1
},
},
pricing: {
list: 1200,
retail: 1100,
savings: 100,
pct_savings: 8
},
details: {
title: "A Love Supreme [Original Recording Reissued]",
artist: "John Coltrane",
genre: [ "Jazz", "General" ],
...
tracks: [
"A Love Supreme Part I: Acknowledgement",
"A Love Supreme Part II - Resolution",
"A Love Supreme, Part III: Pursuance",
"A Love Supreme, Part IV-Psalm"
],
},
}
Для документов в которых хранится информация о фильмах
{ type: "Film" } Основные поля цена, доставка и т.д. остаются такими же. А вот содержание субдокумента будет отличатся. Например:{
sku: "00e8da9d",
type: "Film",
...,
asin: "B000P0J0AQ",
shipping: { ... },
pricing: { ... },
details: {
title: "The Matrix",
director: [ "Andy Wachowski", "Larry Wachowski" ],
writer: [ "Andy Wachowski", "Larry Wachowski" ],
...,
aspect_ratio: "1.66:1"
},
}
В большинстве случаев основные операции для каталога товаров — это поиск. Ниже мы увидим различные типы запросов, которые могут пригодиться. Все примеры будут на
Python/PyMongo.Найти альбомы по жанру и отсортировать по году выпуска
Этот запрос возвращает документы с товарами соотвествующими конкретному жанру и отсортированные в обратном хронологическом порядке:
query = db.products.find({'type':'Audio Album', 'details.genre': 'jazz'}).sort([('details.issue_date', -1)])
Для этого запроса необходим индекс, для полей, используемых в запросе и в сортировке:
db.products.ensure_index([ ('type', 1), ('details.genre', 1), ('details.issue_date', -1)])
Найти товары, отсортированные по проценту скидки в порядке убывания.
В то время как большинство запросов будет для определённого типа продукта (например альбомы, фильмы и т.д.), часто нам может понадобится вернуть все товары в определенном ценовом диапазоне.
Найдем товары у которых хорошая скидка, для поиска будем использовать поле с ценами, которое есть во всех документах.
query = db.products.find( { 'pricing.pct_savings': {'$gt': 25 }).sort([('pricing.pct_savings', -1)])
Для этого запроса создадим индекс по полю
pricing.pct_savings:db.products.ensure_index('pricing.pct_savings')
MongoDB может прочитать индексы как в порядке возрастания так и убывания.Найти все фильмы в которых играли известные актеры
Находим документы у которых тип документа
"Film" и в атрибутах документа есть значение { 'actor': 'Keanu Reeves' }. Результат отсортируем по дате в порядке убывания.query = db.products.find({'type': 'Film', 'details.actor': 'Keanu Reeves'}).sort([('details.issue_date', -1)])
Для этого запроса создадим следующий индекс:
db.products.ensure_index([ ('type', 1), ('details.actor', 1), ('details.issue_date', -1)])
Индекс начинается с поля
type которое есть во всех документах и дальше уже идет по полю details.actor этим мы как бы сужаем область поиска. Таким образом, индекс будет максимально эффективен.Найдем все фильмы у которых есть определённое слово в названии
Для того, чтобы выполнить запрос поиска по словам независимо от типа базы данных, база должна будет просканировать какую-то часть документов, чтоб получить результат.
Mongodb поддерживает в запросах регулярные выражения. В Python можно использовать модуль re для конструирования регулярных выражений.import re
re_hacker = re.compile(r'.*hacker.*', re.IGNORECASE)
query = db.products.find({'type': 'Film', 'title': re_hacker}).sort([('details.issue_date', -1)])
Mongodb предоставляет специальный синтаксис для регулярных выражений, поэтому для запросов можно обходится без модуля
re. Рассмотрим следующий пример, альтернативный предыдущему.query = db.products.find({ 'type': 'Film', 'title': {'$regex': '.*hacker.*', '$options':'i'}}).sort([('details.issue_date', -1)])
$options специальный оператор, в данном случае он указывает, что искомое слово не зависит от регистра.Создадим индекс:
db.products.ensure_index([ ('type', 1), ('details.issue_date', -1), ('title', 1) ])
Этот индекс позволяет избежать сканирования целых документов, благодаря индексу сканироваться будет только поле
title.Масштабирование ( Sharding )
Производительность базы данных при масштабировании зависит от индексов. Можно использовать шардинг для повышения производительности, тогда большие индексы будут влезать в оперативную память.
В конфигурации шардов выбираем
shard key, это позволит mongos маршрутизировать запросы непосредственно нужного нам шарда или небольшой группы шардов.Поскольку в большинстве запросов присутствует поле
type, его можно включить в shard key. Для остальной части shard key нужно учитывать:details.issue_dateмы не будем включать вshard key, потому что это поле не присутствует в запросах а только в сортировке.- Нужно включить одно или несколько полей которые содержатся в
detailи являются часто запрашиваемыми.
В следующем примере предположим что поле
details.genre является вторым по важности полем после type. Инициализируем шардирование с помощью Python/PyMongo>>> db.command('shardCollection', 'product', { key : { 'type': 1, 'details.genre' : 1, 'sku':1 } } )
{ "collectionsharded" : "details.genre", "ok" : 1 }
Даже если мы составим неудачный
shard key, то все равно от шардинга будет польза:- Шардинг даст большой объем оперативной памяти, доступный для хранения индексов.
MongoDBбудет распараллеливать запросы по шардам, уменьшая задержку.
Чтение
Хотя шардинг это хороший способ масштабирования, некоторые наборы данных невозможно разделить таким образом, чтобы
mongos направлял запросы к нужным шардам.В таком случае
mongos отправляет запросы сразу ко всем шардам, а затем с полученным результатом уже возвращается к клиенту.Мы можем немного увеличить производительность за счет того, что явно укажем с какого шарда предпочтительнее читать.
Свойство
SECONDARY в следующем примере, позволяет читать из вторичного узла (а также первичного) для всего соединения.conn = pymongo.MongoClient(read_preference=pymongo.SECONDARY)
SECONDARY_ONLY означает что клиент будет читать только из вторичного члена.conn = pymongo.MongoClient(read_preference=pymongo.SECONDARY_ONLY)
Можно также указать
read_preference для конкретных запросов, например:results = db.product.find(..., read_preference=pymongo.SECONDARY)
или
results = db.product.find(..., read_preference=pymongo.SECONDARY_ONLY)
Корзина и управления остатками на складе
Пользователи интернет-магазинов регулярно добавляют и удаляют элементы из своей «корзины», и поэтому количество товара на складе может постоянно меняться в течении покупки несколько раз, к тому же пользователь магазина может отказаться от покупок в любой момент, а иногда могут возникнуть другие непредвиденные проблемы для решения которых потребуется отменить заказ.
Все это может немного затруднять учет наличествующих на складе товаров, и нам нужно убедиться что пользователи не смогут «купить» те товары которых уже зарезервированы.
Поэтому у корзины будет время в течении которого, если она была неактивна, то зарезервированные товары снова станут доступны всем остальным и корзина будет очищена.
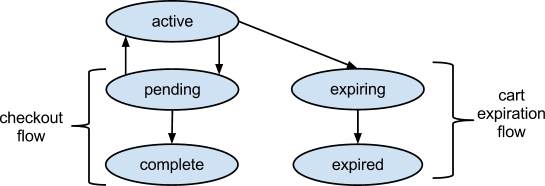
В коллекцию
Inventory должны сохранятся документы, содержащие текущее количество запасов по каждой единицы складского учета ( SKU; или item), а также список корзин с количеством товаров в каждой. Тогда мы можем вернуть доступные остатки, если они находились в корзине, но клиент не пользовался корзиной какое-то время.В следующем примере
_id поле хранящее SKU# В этом документе содержится _id:SKU, также мы видим, что количество товаров в наличии 16 штук, 1 шт. в # корзине с id 42, и 2 шт. в корзине c id 43. Это оставляет в общей сложности 19 не проданных единиц товара.
{
_id: '00e8da9b',
qty: 16,
carted: [
{ qty: 1, cart_id: 42, timestamp: ISODate("2012-03-09T20:55:36Z") },
{ qty: 2, cart_id: 43, timestamp: ISODate("2012-03-09T21:55:36Z") },
]
}
В данном примере используется простая схема, в продакшене мы можем объединить эту схему с каталогом товаров описанным во второй главе.
Для нормального моделирования корзины мы нуждаемся в SKU,
quantity полях, а также в каких то уточняющих полях, находящихся в item_details# Поле item_details в каждом документе позволяет приложению отображать детали содержимого корзины
# пользователя, не делая второй запрос для выборки этих деталей из каталога товаров.
{
_id: 42,
last_modified: ISODate("2012-03-09T20:55:36Z"),
status: 'active',
items: [
{ sku: '00e8da9b', qty: 1, item_details: {...} },
{ sku: '0ab42f88', qty: 4, item_details: {...} }
]
}
ОперацииДобавление элемента в корзину
Основным моментом в работе с корзиной является перемещение товара из имеющихся запасов на складе в корзину.
Важно не поместить в корзину уже зарезервированный товар. Реализуем это с помощью функции add_item_to_cart.
def add_item_to_cart(cart_id, sku, qty, details):
now = datetime.utcnow()
# Убедимся, что корзина по прежнему активна и добавим товар
result = db.cart.update(
{'_id': cart_id, 'status': 'active' },
{'$set': {'last_modified':now}, '$push': {'items': {'sku':sku, 'qty':qty, 'details':details}}},
w=1
)
if not result['updatedExisting']:
raise CartInactive()
# Обновляем остатки
result = db.inventory.update(
{'_id':sku, 'qty': {'$gte': qty}},
{'$inc': {'qty':-qty}, '$push': {'carted': {'qty':qty, 'cart_id':cart_id, 'timestamp':now}}},
w=1
)
if not result['updatedExisting']:
# Если обновить остатки не получилось, то откатываем состояние корзины, удаляем из нее товар.
db.cart.update( {'_id': cart_id }, { '$pull': { 'items': {'sku': sku } } })
raise InadequateInventory()
Для этой функции не будет индексов, поскольку на поле _id индекс устанавливается автоматически.
Первая операция в этой функции — это проверка, что корзина активна и только после этого туда добавляется товар. Тогда мы проверяем доступность нужного количества остатков на складе и если да, то уменьшаем их.
Если же на складе нет нужного количества товаров то обновляем корзину, удаляя из неё товар.
Изменение количества в корзине
Приложение должно проверять, что когда пользователь увеличивает количество товаров в корзине, они есть в наличии на складе.
def update_quantity(cart_id, sku, old_qty, new_qty):
# индекс не нужен так как для поля _id создается по умолчанию.
now = datetime.utcnow()
delta_qty = new_qty - old_qty
# Убедимся, что корзина по прежнему активна и после этого добавляем товарную позицию.
result = db.cart.update(
{'_id': cart_id, 'status': 'active', 'items.sku': sku },
{'$set': { 'last_modified': now, 'items.$.qty': new_qty } },
w=1
)
if not result['updatedExisting']:
raise CartInactive()
# Обновление остатков
result = db.inventory.update(
{'_id':sku, 'carted.cart_id': cart_id, 'qty': {'$gte': delta_qty} },
{'$inc': {'qty': -delta_qty },'$set': { 'carted.$.qty': new_qty, 'timestamp': now } },
w=1
)
if not result['updatedExisting']:
# Если обновление остатков не произошло то возвращаем старое количество товаров
db.cart.update( {'_id': cart_id, 'items.sku': sku }, {'$set': { 'items.$.qty': old_qty } } )
raise InadequateInventory()
Окончание сделки
В конце нужно проверить способ оплаты и, если оплата прошла, успешно очистить корзину.
def checkout(cart_id):
now = datetime.utcnow()
# Проверяем что состояние корзины <code>active</code> и устанавливаем состояние <code>pending</code>.
# также получаем детали корзины чтобы мы могли сформировать окончательный чек
cart = db.cart.find_and_modify(
{'_id': cart_id, 'status': 'active' },
update={'$set': { 'status': 'pending','last_modified': now } }
)
if cart is None:
raise CartInactive()
# Проверяем детали оплаты; коллекция payment
try:
collect_payment(cart)
db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'complete' } } )
db.inventory.update( {'carted.cart_id': cart_id}, {'$pull': {'cart_id': cart_id} }, multi=True)
except:
db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'active' } } )
raise
Начинаем с блокирования корзины, установив состояние pending. Тогда система обновит корзину и автоматически вернет детали, содержащие платежную информацию.
- Если оплата прошла успешно, то приложение удалит
cart_id из документов в коллекции inventory. И установит состояние корзины complete.
- Если платеж был отклонен, приложение разблокирует корзину, установив его статус на активный и сообщит об ошибке оплаты.
Возвращение товаров на склад.
Периодически приложение должно обнулять неактивные корзины и возвращать товары обратно на склад.
Переменная timeout содержит в себе время истечения активности корзины.
def expire_carts(timeout):
now = datetime.utcnow()
threshold = now - timedelta(seconds=timeout)
# Блокирование и нахождение всех бездействующих корзин
db.cart.update(
{'status': 'active', 'last_modified': { '$lt': threshold } },
{'$set': { 'status': 'expiring' } },
multi=True
)
# Идем по бездействующим корзинам
for cart in db.cart.find({'status': 'expiring'}):
# Возвращаем все товары на склад
for item in cart['items']:
db.inventory.update(
{ '_id': item['sku'], 'carted.cart_id': cart['id'], 'carted.qty': item['qty'] },
{'$inc': { 'qty': item['qty'] }, '$pull': { 'carted': { 'cart_id': cart['id'] } } }
)
db.cart.update( {'_id': cart['id'] }, {'$set': { 'status': 'expired' })
Эта функция:
- Находит все корзины, которые старше заданного времени.
- Для каждой неактивной корзины, все товары возвращает в доступные остатки на складе.
- Как только все товары будут возвращены на склад, установим состояние корзины
expired.
Создадим индекс содержащий поля status и last_modified.
db.cart.ensure_index([('status', 1), ('last_modified', 1)])
Обработка ошибок.
Вышеописанные операции не учитывают одну возможную проблему: если исключение произойдет после обновления корзины, но перед обновлением документов в коллекции inventory, то в результате это может привести к тому, что время корзины уже истекло, а товары не возвратились на склад.
Чтоб учесть этот случай, приложение нуждается в периодической очистке найденных в inventory товаров которые имеют carted и не забыть проверить что они точно есть в корзине и сделать их доступными на складе.
def cleanup_inventory(timeout):
now = datetime.utcnow()
threshold = now - timedelta(seconds=timeout)
# Находим все элементы с истекшим сроком
for item in db.inventory.find( {'carted.timestamp': {'$lt': threshold }}):
carted = dict(
(carted_item['cart_id'], carted_item) for carted_item in item['carted'] if carted_item['timestamp'] < threshold
)
# Первый проход: Находим любые активные корзины и обновим carted, которые находятся в коллекции inventory
for cart in db.cart.find( { '_id': {'$in': carted.keys() }, 'status':'active'}):
cart = carted[cart['_id']]
db.inventory.update(
{'_id': item['_id'], 'carted.cart_id':cart['_id'] },
{ '$set': {'carted.$.timestamp':now }}
)
del carted[cart['_id']]
# Второй проход: Все carted присуствующие в словаре должны быть возвращены на склад.
for cart_id, carted_item in carted.items():
db.inventory.update(
{ '_id': item['_id'], 'carted.cart_id': cart_id, 'carted.qty': carted_item['qty'] },
{ '$inc': { 'qty': carted_item['qty'] }, '$pull': { 'carted': { 'cart_id': cart_id } } }
)
В итоге эта функция находит все «carted» элементы, которые имеют временные метки старше, чем константа timeout. И затем два раза проходим по этим пунктам:
- Из элементов с метками времени старше
timeout, если корзина по-прежнему активна, сбрасываем время.
- И товары, которые которые остаются в неактивной корзине, функция возвращает на склад.
Шардинг
Если мы решим шардировать эту систему, то идеальным вариантом для shard key будет _id, потому что большинство операций обновления используют поле _id.
Это позволит mongos маршрутизировать все обновления которые выбраны по _id в одном процессе mongod.
Но есть два недостатка в использовании _id в качестве shard key.
Если _id в коллекции cart будет инкрементом, то все новые документы будут на одном шарде.
Мы можем уменьшить этот эффект, выбирая случайное значение после создания корзины, такие как хэш (например MD5 или SHA-1) из идентификатора ObjectID, как _id.
Этот процесс показан ниже:
import hashlib
import bson
cart_id = bson.ObjectId()
cart_id_hash = hashlib.md5(str(cart_id)).hexdigest()
cart = { "_id": cart_id, "cart_hash": cart_id_hash }
db.cart.insert(cart)
Время истечения корзины и регулирование операций, требующих обновления и широковещательных запросов ко всем шардам, используют _id в качестве shard key.
Это может быть не очень актуальным, истечение функции запуска относительно нечасто, и их можно искусственно замедлить (умеренно используя функции Sleep ()), чтобы минимизировать нагрузку на сервер.
Для шардинга с помощью Python/PyMongo используем следующие команды:
>>> db.command('shardCollection', 'inventory', 'key': { '_id': 1 } )
{ "collectionsharded" : "inventory", "ok" : 1 }
>>> db.command('shardCollection', 'cart', 'key': { '_id': 1 } )
{ "collectionsharded" : "cart", "ok" : 1 }
Иерархия категорий
Будем моделировать дерево категорий с товарами. Каждая категория будет сохранятся в своём документе у которого будет список предков или список родителей.
Для примера будем использовать список жанров:

Поскольку эти виды категорий изменяются не часто, наше моделирование будет фокусироваться на операциях необходимых для поддержания иерархии, а не производительности операций обновления.
Эта схема имеет следующие свойства:
- Каждую категорию в дереве представляет один документ
Objectid идентифицирует каждый документ категории для внутренних перекрестных ссылок.- Каждый документ с категорией имеет удобочитаемое имя и поле с нормальным URL-адресом.
- Схема хранит список предков для каждой категории, чтобы упростить получение всех предков используя только один запрос.
Рассмотрим следующий прототип:
{ "_id" : ObjectId("4f5ec858eb03303a11000002"),
"name" : "Modal Jazz",
"parent" : ObjectId("4f5ec858eb03303a11000001"),
"slug" : "modal-jazz",
"ancestors" : [
{ "_id" : ObjectId("4f5ec858eb03303a11000001"), "slug" : "bop", "name" : "Bop" },
{ "_id" : ObjectId("4f5ec858eb03303a11000000"), "slug" : "ragtime", "name" : "Ragtime" }
]
}
В этом разделе будут описываться операции манипуляции с деревом категорий, которые могут понадобится в E-Commerce решениях. Все примеры будут использовать Python/PyMongo
Чтение и показ категорий
Запрос.
Используем следующие опции для чтения и показа дерева категорий. В этом запросе будем использовать поле slug и возвращать информацию о категории “bread crumb”
category = db.categories.find({'slug':slug}, {'_id':0, 'name':1, 'ancestors.slug':1, 'ancestors.name':1 })
Создадим уникальный индекс по полю slug.
>>> db.categories.ensure_index('slug', unique=True)
Добавление категории
Чтобы добавить категорию, необходимо сначала определить её предков. Добавим новую категорию -Swing в виде потомка категории Ragtime, как показано на схеме:

Операция добавления категории довольно проста, за исключением предков. Чтобы добавить предков в массив, рассмотрим следующую функцию:
def build_ancestors(_id, parent_id):
parent = db.categories.find_one({'_id': parent_id}, {'name': 1, 'slug': 1, 'ancestors':1})
parent_ancestors = parent.pop('ancestors')
ancestors = [ parent ] + parent_ancestors
db.categories.update({'_id': _id}, {'$set': { 'ancestors': ancestors } })
Нужно попасть на один уровень вверх в дереве и получить список предков для Ragtime, которые можно использовать для создания списка предков Swing.
Тогда создадим документ и установим ему следующие значения:
doc = dict(name='Swing', slug='swing', parent=ragtime_id)
swing_id = db.categories.insert(doc)
build_ancestors(swing_id, ragtime_id)
Для операций добавления новой категории нам хватит индекса по умолчанию на _id
Изменение предков у категории
В этом разделе рассмотрим процесс изменения дерева, поставим категорию bop над категорией swing.

Обновим документ bop чтобы изменить значения родителя:
db.categories.update({'_id':bop_id}, {'$set': { 'parent': swing_id } } )
Следующая функция перестроит поле где хранятся предки.
def build_ancestors_full(_id, parent_id):
ancestors = []
while parent_id is not None:
parent = db.categories.find_one({'_id': parent_id}, {'parent': 1, 'name': 1, 'slug': 1, 'ancestors':1})
parent_id = parent.pop('parent')
ancestors.append(parent)
db.categories.update({'_id': _id}, {'$set': { 'ancestors': ancestors } })
Можно использовать следующий цикл для реконструирования всех потомков bop
for cat in db.categories.find({'ancestors._id': bop_id}, {'parent': 1}):
build_ancestors_full(cat['_id'], cat['parent'])
Создадим индекс для поля ancestors._id который нужен для операций обновления.
db.categories.ensure_index('ancestors._id')
Переименование категории
Для переименования категории нужно обновить как саму категорию так и всех потомков.
Рассмотрим переименования категории “Bop” в “BeBop” это изображено на следующей диаграме:

Первое что нужно — это изменить имя категории:
db.categories.update({'_id':bop_id}, {'$set': { 'name': 'BeBop' } })
Далее нужно обновить у каждого потомка список предков:
db.categories.update({'ancestors._id': bop_id}, {'$set': { 'ancestors.$.name': 'BeBop' } }, multi=True)
Эта операция использует:
- Позиционный оператор $ чтобы найти нужного предка не зная точно его
_id.
- Опцию
multi которая указывает что нужно обновить все документы подпадающие под условие.
Для этого обновления у нас уже есть индекс ancestors._id.
Шардинг
Для большинства случаев шардинг этой коллекции имеет ограниченную ценность, потому что эта коллекция будет очень маленькой. Если нужен шард то для shard key подойдет поле _id.
>>> db.command('shardCollection', 'categories', { 'key': {'_id': 1} })
{ "collectionsharded" : "categories", "ok" : 1 }
P.S. Просьба о грамматических ошибках и ошибках перевода писать в личку.
Используемые материалы:
Эко система MongoDB
Справка по операторам в aggregation framework
Статья про шардинг на хабре
Справочник «Паттерны проектирования» (ru)
Основным моментом в работе с корзиной является перемещение товара из имеющихся запасов на складе в корзину.
Важно не поместить в корзину уже зарезервированный товар. Реализуем это с помощью функции
add_item_to_cart.def add_item_to_cart(cart_id, sku, qty, details):
now = datetime.utcnow()
# Убедимся, что корзина по прежнему активна и добавим товар
result = db.cart.update(
{'_id': cart_id, 'status': 'active' },
{'$set': {'last_modified':now}, '$push': {'items': {'sku':sku, 'qty':qty, 'details':details}}},
w=1
)
if not result['updatedExisting']:
raise CartInactive()
# Обновляем остатки
result = db.inventory.update(
{'_id':sku, 'qty': {'$gte': qty}},
{'$inc': {'qty':-qty}, '$push': {'carted': {'qty':qty, 'cart_id':cart_id, 'timestamp':now}}},
w=1
)
if not result['updatedExisting']:
# Если обновить остатки не получилось, то откатываем состояние корзины, удаляем из нее товар.
db.cart.update( {'_id': cart_id }, { '$pull': { 'items': {'sku': sku } } })
raise InadequateInventory()
Для этой функции не будет индексов, поскольку на поле
_id индекс устанавливается автоматически.Первая операция в этой функции — это проверка, что корзина активна и только после этого туда добавляется товар. Тогда мы проверяем доступность нужного количества остатков на складе и если да, то уменьшаем их.
Если же на складе нет нужного количества товаров то обновляем корзину, удаляя из неё товар.
Изменение количества в корзине
Приложение должно проверять, что когда пользователь увеличивает количество товаров в корзине, они есть в наличии на складе.
def update_quantity(cart_id, sku, old_qty, new_qty):
# индекс не нужен так как для поля _id создается по умолчанию.
now = datetime.utcnow()
delta_qty = new_qty - old_qty
# Убедимся, что корзина по прежнему активна и после этого добавляем товарную позицию.
result = db.cart.update(
{'_id': cart_id, 'status': 'active', 'items.sku': sku },
{'$set': { 'last_modified': now, 'items.$.qty': new_qty } },
w=1
)
if not result['updatedExisting']:
raise CartInactive()
# Обновление остатков
result = db.inventory.update(
{'_id':sku, 'carted.cart_id': cart_id, 'qty': {'$gte': delta_qty} },
{'$inc': {'qty': -delta_qty },'$set': { 'carted.$.qty': new_qty, 'timestamp': now } },
w=1
)
if not result['updatedExisting']:
# Если обновление остатков не произошло то возвращаем старое количество товаров
db.cart.update( {'_id': cart_id, 'items.sku': sku }, {'$set': { 'items.$.qty': old_qty } } )
raise InadequateInventory()
Окончание сделки
В конце нужно проверить способ оплаты и, если оплата прошла, успешно очистить корзину.
def checkout(cart_id):
now = datetime.utcnow()
# Проверяем что состояние корзины <code>active</code> и устанавливаем состояние <code>pending</code>.
# также получаем детали корзины чтобы мы могли сформировать окончательный чек
cart = db.cart.find_and_modify(
{'_id': cart_id, 'status': 'active' },
update={'$set': { 'status': 'pending','last_modified': now } }
)
if cart is None:
raise CartInactive()
# Проверяем детали оплаты; коллекция payment
try:
collect_payment(cart)
db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'complete' } } )
db.inventory.update( {'carted.cart_id': cart_id}, {'$pull': {'cart_id': cart_id} }, multi=True)
except:
db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'active' } } )
raise
Начинаем с блокирования корзины, установив состояние
pending. Тогда система обновит корзину и автоматически вернет детали, содержащие платежную информацию.- Если оплата прошла успешно, то приложение удалит
cart_idиз документов в коллекцииinventory. И установит состояние корзиныcomplete. - Если платеж был отклонен, приложение разблокирует корзину, установив его статус на активный и сообщит об ошибке оплаты.
Возвращение товаров на склад.
Периодически приложение должно обнулять неактивные корзины и возвращать товары обратно на склад.
Переменная
timeout содержит в себе время истечения активности корзины.def expire_carts(timeout):
now = datetime.utcnow()
threshold = now - timedelta(seconds=timeout)
# Блокирование и нахождение всех бездействующих корзин
db.cart.update(
{'status': 'active', 'last_modified': { '$lt': threshold } },
{'$set': { 'status': 'expiring' } },
multi=True
)
# Идем по бездействующим корзинам
for cart in db.cart.find({'status': 'expiring'}):
# Возвращаем все товары на склад
for item in cart['items']:
db.inventory.update(
{ '_id': item['sku'], 'carted.cart_id': cart['id'], 'carted.qty': item['qty'] },
{'$inc': { 'qty': item['qty'] }, '$pull': { 'carted': { 'cart_id': cart['id'] } } }
)
db.cart.update( {'_id': cart['id'] }, {'$set': { 'status': 'expired' })
Эта функция:
- Находит все корзины, которые старше заданного времени.
- Для каждой неактивной корзины, все товары возвращает в доступные остатки на складе.
- Как только все товары будут возвращены на склад, установим состояние корзины
expired.
Создадим индекс содержащий поля
status и last_modified.db.cart.ensure_index([('status', 1), ('last_modified', 1)])
Обработка ошибок.
Вышеописанные операции не учитывают одну возможную проблему: если исключение произойдет после обновления корзины, но перед обновлением документов в коллекции
inventory, то в результате это может привести к тому, что время корзины уже истекло, а товары не возвратились на склад.Чтоб учесть этот случай, приложение нуждается в периодической очистке найденных в
inventory товаров которые имеют carted и не забыть проверить что они точно есть в корзине и сделать их доступными на складе.def cleanup_inventory(timeout):
now = datetime.utcnow()
threshold = now - timedelta(seconds=timeout)
# Находим все элементы с истекшим сроком
for item in db.inventory.find( {'carted.timestamp': {'$lt': threshold }}):
carted = dict(
(carted_item['cart_id'], carted_item) for carted_item in item['carted'] if carted_item['timestamp'] < threshold
)
# Первый проход: Находим любые активные корзины и обновим carted, которые находятся в коллекции inventory
for cart in db.cart.find( { '_id': {'$in': carted.keys() }, 'status':'active'}):
cart = carted[cart['_id']]
db.inventory.update(
{'_id': item['_id'], 'carted.cart_id':cart['_id'] },
{ '$set': {'carted.$.timestamp':now }}
)
del carted[cart['_id']]
# Второй проход: Все carted присуствующие в словаре должны быть возвращены на склад.
for cart_id, carted_item in carted.items():
db.inventory.update(
{ '_id': item['_id'], 'carted.cart_id': cart_id, 'carted.qty': carted_item['qty'] },
{ '$inc': { 'qty': carted_item['qty'] }, '$pull': { 'carted': { 'cart_id': cart_id } } }
)
В итоге эта функция находит все «carted» элементы, которые имеют временные метки старше, чем константа
timeout. И затем два раза проходим по этим пунктам:- Из элементов с метками времени старше
timeout, если корзина по-прежнему активна, сбрасываем время. - И товары, которые которые остаются в неактивной корзине, функция возвращает на склад.
Шардинг
Если мы решим шардировать эту систему, то идеальным вариантом для
shard key будет _id, потому что большинство операций обновления используют поле _id.Это позволит
mongos маршрутизировать все обновления которые выбраны по _id в одном процессе mongod.Но есть два недостатка в использовании
_id в качестве shard key.Если
_id в коллекции cart будет инкрементом, то все новые документы будут на одном шарде.Мы можем уменьшить этот эффект, выбирая случайное значение после создания корзины, такие как хэш (например MD5 или SHA-1) из идентификатора ObjectID, как _id.
Этот процесс показан ниже:
import hashlib
import bson
cart_id = bson.ObjectId()
cart_id_hash = hashlib.md5(str(cart_id)).hexdigest()
cart = { "_id": cart_id, "cart_hash": cart_id_hash }
db.cart.insert(cart)
Время истечения корзины и регулирование операций, требующих обновления и широковещательных запросов ко всем шардам, используют
_id в качестве shard key.Это может быть не очень актуальным, истечение функции запуска относительно нечасто, и их можно искусственно замедлить (умеренно используя функции
Sleep ()), чтобы минимизировать нагрузку на сервер. Для шардинга с помощью Python/PyMongo используем следующие команды:
>>> db.command('shardCollection', 'inventory', 'key': { '_id': 1 } )
{ "collectionsharded" : "inventory", "ok" : 1 }
>>> db.command('shardCollection', 'cart', 'key': { '_id': 1 } )
{ "collectionsharded" : "cart", "ok" : 1 }
Иерархия категорий
Будем моделировать дерево категорий с товарами. Каждая категория будет сохранятся в своём документе у которого будет список предков или список родителей.
Для примера будем использовать список жанров:
Поскольку эти виды категорий изменяются не часто, наше моделирование будет фокусироваться на операциях необходимых для поддержания иерархии, а не производительности операций обновления.
Эта схема имеет следующие свойства:
- Каждую категорию в дереве представляет один документ
Objectidидентифицирует каждый документ категории для внутренних перекрестных ссылок.- Каждый документ с категорией имеет удобочитаемое имя и поле с нормальным URL-адресом.
- Схема хранит список предков для каждой категории, чтобы упростить получение всех предков используя только один запрос.
Рассмотрим следующий прототип:
{ "_id" : ObjectId("4f5ec858eb03303a11000002"),
"name" : "Modal Jazz",
"parent" : ObjectId("4f5ec858eb03303a11000001"),
"slug" : "modal-jazz",
"ancestors" : [
{ "_id" : ObjectId("4f5ec858eb03303a11000001"), "slug" : "bop", "name" : "Bop" },
{ "_id" : ObjectId("4f5ec858eb03303a11000000"), "slug" : "ragtime", "name" : "Ragtime" }
]
}
В этом разделе будут описываться операции манипуляции с деревом категорий, которые могут понадобится в E-Commerce решениях. Все примеры будут использовать
Python/PyMongoЧтение и показ категорий
Запрос.
Используем следующие опции для чтения и показа дерева категорий. В этом запросе будем использовать поле
slug и возвращать информацию о категории “bread crumb”category = db.categories.find({'slug':slug}, {'_id':0, 'name':1, 'ancestors.slug':1, 'ancestors.name':1 })
Создадим уникальный индекс по полю
slug.>>> db.categories.ensure_index('slug', unique=True)
Добавление категории
Чтобы добавить категорию, необходимо сначала определить её предков. Добавим новую категорию -
Swing в виде потомка категории Ragtime, как показано на схеме:Операция добавления категории довольно проста, за исключением предков. Чтобы добавить предков в массив, рассмотрим следующую функцию:
def build_ancestors(_id, parent_id):
parent = db.categories.find_one({'_id': parent_id}, {'name': 1, 'slug': 1, 'ancestors':1})
parent_ancestors = parent.pop('ancestors')
ancestors = [ parent ] + parent_ancestors
db.categories.update({'_id': _id}, {'$set': { 'ancestors': ancestors } })
Нужно попасть на один уровень вверх в дереве и получить список предков для
Ragtime, которые можно использовать для создания списка предков Swing.Тогда создадим документ и установим ему следующие значения:
doc = dict(name='Swing', slug='swing', parent=ragtime_id)
swing_id = db.categories.insert(doc)
build_ancestors(swing_id, ragtime_id)
Для операций добавления новой категории нам хватит индекса по умолчанию на
_idИзменение предков у категории
В этом разделе рассмотрим процесс изменения дерева, поставим категорию
bop над категорией swing. Обновим документ
bop чтобы изменить значения родителя:db.categories.update({'_id':bop_id}, {'$set': { 'parent': swing_id } } )
Следующая функция перестроит поле где хранятся предки.
def build_ancestors_full(_id, parent_id):
ancestors = []
while parent_id is not None:
parent = db.categories.find_one({'_id': parent_id}, {'parent': 1, 'name': 1, 'slug': 1, 'ancestors':1})
parent_id = parent.pop('parent')
ancestors.append(parent)
db.categories.update({'_id': _id}, {'$set': { 'ancestors': ancestors } })
Можно использовать следующий цикл для реконструирования всех потомков
bopfor cat in db.categories.find({'ancestors._id': bop_id}, {'parent': 1}):
build_ancestors_full(cat['_id'], cat['parent'])
Создадим индекс для поля
ancestors._id который нужен для операций обновления.db.categories.ensure_index('ancestors._id')
Переименование категории
Для переименования категории нужно обновить как саму категорию так и всех потомков.
Рассмотрим переименования категории “Bop” в “BeBop” это изображено на следующей диаграме:
Первое что нужно — это изменить имя категории:
db.categories.update({'_id':bop_id}, {'$set': { 'name': 'BeBop' } })
Далее нужно обновить у каждого потомка список предков:
db.categories.update({'ancestors._id': bop_id}, {'$set': { 'ancestors.$.name': 'BeBop' } }, multi=True)
Эта операция использует:
- Позиционный оператор $ чтобы найти нужного предка не зная точно его
_id. - Опцию
multiкоторая указывает что нужно обновить все документы подпадающие под условие.
Для этого обновления у нас уже есть индекс
ancestors._id.Шардинг
Для большинства случаев шардинг этой коллекции имеет ограниченную ценность, потому что эта коллекция будет очень маленькой. Если нужен шард то для
shard key подойдет поле _id.>>> db.command('shardCollection', 'categories', { 'key': {'_id': 1} })
{ "collectionsharded" : "categories", "ok" : 1 }
P.S. Просьба о грамматических ошибках и ошибках перевода писать в личку.
Используемые материалы:
Эко система MongoDB
Справка по операторам в aggregation framework
Статья про шардинг на хабре
Справочник «Паттерны проектирования» (ru)
