Доброго времени суток, хабр!
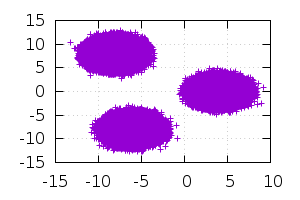
Моим основным ЯП является D. Всегда понимал, что он будет проигрывать C++ из-за сборщика, каких-то высокоуровневых плюшек и т.д. Но никогда не доходили руки проверить насколько. Решил написать простенький классификатор (даже не помню метод как называется) и проверить. Результат меня приятно удивил: версия C++ отработала за 5.47 сек, версия D — за 5.55 сек. «0.08 сек при обработке файла в 74Мб это не так уж и много» — подумал я. Но, на всякий случай, решил попробовать собрать код на D с помощью gdc (dmd как frontend, gnu backend) и тут уже в душу закрались сомнения, что я всё сделал правильно: код отработал за 4.01 сек, что более чем на 20% быстрее версии на С++. Решил собрать с помощью ldc2 (dmd frontend, llvm backend): 2.92(!!) сек. Тут я решил разобраться.
Первым делом запустил valgrind --tool=callgrind для C++ версии. Как и следовало ожидать на чтение файла уходит бОльшая часть времени.
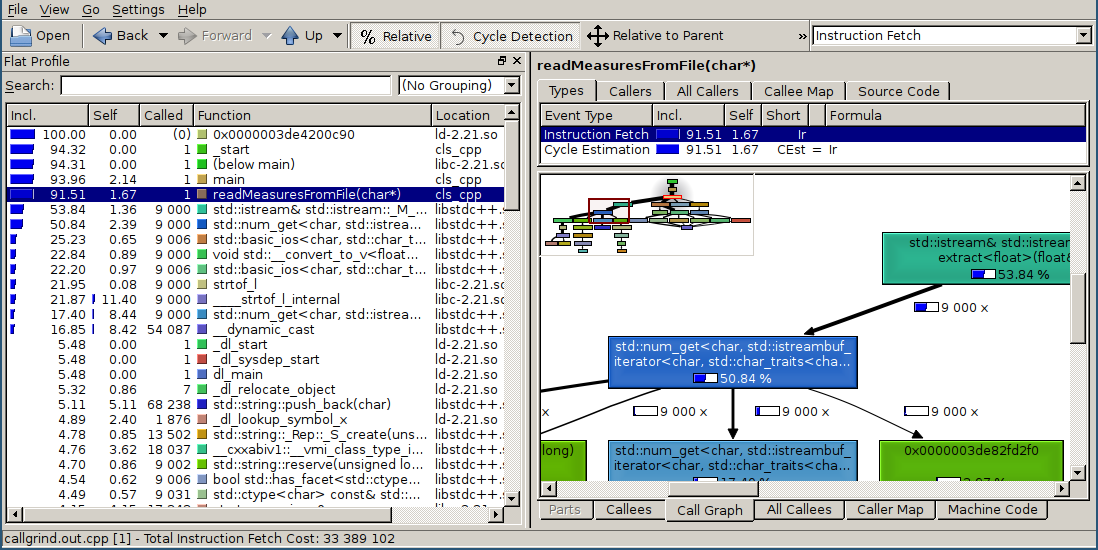
К сожалению, для версии dmd valgrind не смог отработать и завершился ошибкой illegal hardware instruction, видимо ребята из DigitalMars наколдовали с асемблером сильно, но для gdc и ldc2 всё сработало, как для версии С++.

Хоть и valgrind не demangle'ит имена D функций, зато есть маленький хак: callgrind.out.NNN пропускаем через этот инструмент и получаем нормальные имена (не все, но большую часть). И прошу прощения за gdb, версия 7.9.1-13.fc22 полностью поддерживает demangle D кода.
Осознал я, что рано радоваться, нужно выяснить время выполнения непосредственно алгоритма. И раз уж на то пошло, попробовать различные варианты алгоритма:
Пара слов по поводу алгоритма: я не ставил задачи написать хороший классификатор и правильно его настроить, просто тестовый код.
Результаты в секундах, в скобочках отношение к С++ коду:
Второй вариант алгоритма активней использует сборщик мусора (который я никак не настраивал). Лучший результат выдал, конечно же, ldc2 — в полтора раза медленей С++ при активной сборке мусора, что, в итоге, не так уж и плохо. И даже очень хорошо, если сравнивать полное время выполнения программы: 5.4 сек (с учётом правки тов. roman_kashitsyn 3.4 сек) для C++ против 2.9 сек для D на ldc2.
Естественно, для чистоты эксперимента, код я никак специально не оптимизировал и сделал максимально эквивалентным.
PS. В языках Rust и Go не силён, если кто-нибудь захочет написать эквивалентный код (для полноты эксперимента) буду рад вставить результаты сюда.
UPD: спасибо тов. I_AM_FAKE за код на Rust
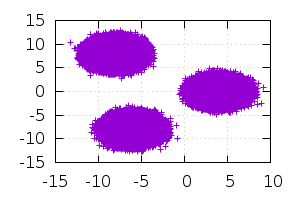
Моим основным ЯП является D. Всегда понимал, что он будет проигрывать C++ из-за сборщика, каких-то высокоуровневых плюшек и т.д. Но никогда не доходили руки проверить насколько. Решил написать простенький классификатор (даже не помню метод как называется) и проверить. Результат меня приятно удивил: версия C++ отработала за 5.47 сек, версия D — за 5.55 сек. «0.08 сек при обработке файла в 74Мб это не так уж и много» — подумал я. Но, на всякий случай, решил попробовать собрать код на D с помощью gdc (dmd как frontend, gnu backend) и тут уже в душу закрались сомнения, что я всё сделал правильно: код отработал за 4.01 сек, что более чем на 20% быстрее версии на С++. Решил собрать с помощью ldc2 (dmd frontend, llvm backend): 2.92(!!) сек. Тут я решил разобраться.
Первым делом запустил valgrind --tool=callgrind для C++ версии. Как и следовало ожидать на чтение файла уходит бОльшая часть времени.
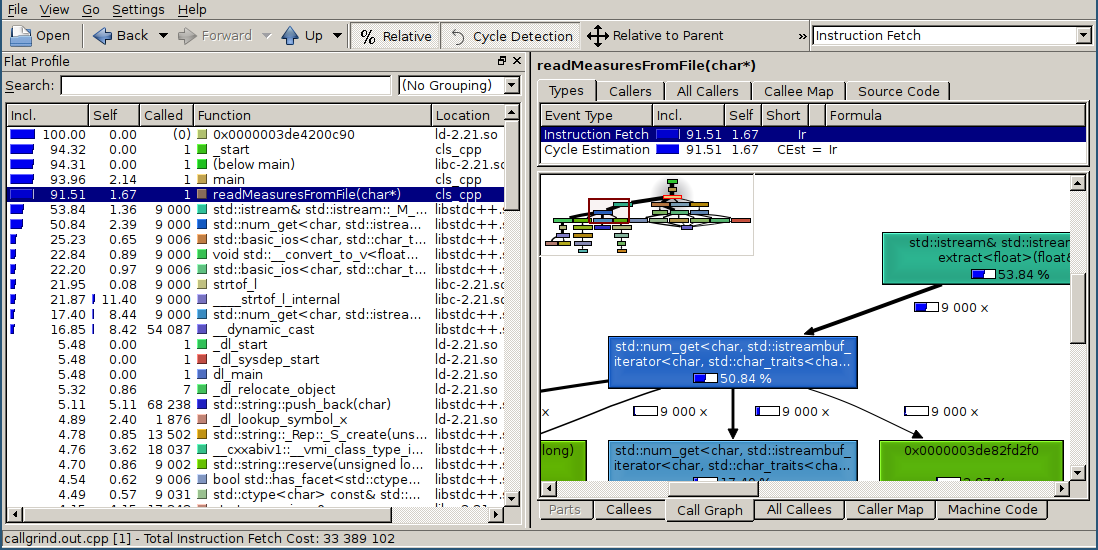
К сожалению, для версии dmd valgrind не смог отработать и завершился ошибкой illegal hardware instruction, видимо ребята из DigitalMars наколдовали с асемблером сильно, но для gdc и ldc2 всё сработало, как для версии С++.

Хоть и valgrind не demangle'ит имена D функций, зато есть маленький хак: callgrind.out.NNN пропускаем через этот инструмент и получаем нормальные имена (не все, но большую часть). И прошу прощения за gdb, версия 7.9.1-13.fc22 полностью поддерживает demangle D кода.
Осознал я, что рано радоваться, нужно выяснить время выполнения непосредственно алгоритма. И раз уж на то пошло, попробовать различные варианты алгоритма:
- минимальный — создаются классификаторы, точки в классах не сохраняются
- с сохранением точек и слиянием классов (изначальный алгоритм с изначальной настройкой плодил много классов)
Пара слов по поводу алгоритма: я не ставил задачи написать хороший классификатор и правильно его настроить, просто тестовый код.
Результаты в секундах, в скобочках отношение к С++ коду:
| c++ g++ | d dmd | d gdc | d ldc2 | rust rustc | |
|---|---|---|---|---|---|
| 1 | 0.577 | 1.797 (3.11) | 0.999 (1.73) | 0.583 (1.01) | 0.546 (0.933) |
| 2 | 0.628 | 2.272 (3.617) | 1.217 (1.937) | 0.898 (1.429) | 0.52 (0.935) |
Второй вариант алгоритма активней использует сборщик мусора (который я никак не настраивал). Лучший результат выдал, конечно же, ldc2 — в полтора раза медленей С++ при активной сборке мусора, что, в итоге, не так уж и плохо. И даже очень хорошо, если сравнивать полное время выполнения программы: 5.4 сек (с учётом правки тов. roman_kashitsyn 3.4 сек) для C++ против 2.9 сек для D на ldc2.
Естественно, для чистоты эксперимента, код я никак специально не оптимизировал и сделал максимально эквивалентным.
Код на D
import std.stdio;
import std.math;
import std.format;
import std.datetime;
//version=COLLECT_MEASURES;
//version=MERGE_CLASSES;
struct Measure
{
float x=0, y=0;
auto opBinary(string op)( auto ref const Measure m ) const
if( op == "+" || op == "-" )
{ mixin( "return Measure( x " ~ op ~ " m.x, y " ~ op ~ " m.y );" ); }
auto opBinary(string op)( float m ) const
if( op == "*" || op == "/" )
{ mixin( "return Measure( x " ~ op ~ " m, y " ~ op ~ " m );" ); }
}
unittest
{
auto a = Measure(1,3);
auto b = Measure(4,5);
auto add = a + b;
assert( add.x == 5 && add.y == 8 );
auto dif = a - b;
assert( dif.x == -3 && dif.y == -2 );
auto mlt = a * 3;
assert( mlt.x == 3 && mlt.y == 9 );
auto div = b / 2;
assert( div.x == 2 && div.y == 2.5 );
}
float sqr( float v ) { return v * v; }
float dist( ref const Measure a, ref const Measure b )
{ return sqrt( sqr(a.x - b.x) + sqr(a.y - b.y) ); }
class Class
{
Measure mean;
size_t N;
version(COLLECT_MEASURES)
Measure[] measures;
this( in Measure m )
{
mean = m;
N = 1;
version(COLLECT_MEASURES)
measures ~= m;
}
void append( in Measure m )
{
mean = ( mean * N + m ) / ( N + 1 );
N++;
version(COLLECT_MEASURES)
measures ~= m;
}
void merge( const Class m )
{
mean = ( mean * N + m.mean * m.N ) / ( N + m.N );
N += m.N;
version(COLLECT_MEASURES)
measures ~= m.measures;
}
}
unittest
{
auto cls = new Class( Measure(1,2) );
assert( cls.mean.x == 1 && cls.mean.y == 2 );
assert( cls.N == 1 );
cls.append( Measure(3,4) );
assert( cls.mean.x == 2 && cls.mean.y == 3 );
assert( cls.N == 2 );
}
class Classifier
{
public:
Class[] list;
float ncls_dist;
this( float mdist ) { ncls_dist = mdist; }
void classificate( ref const Measure m )
{
float min_dist = float.max;
Class near_cls;
foreach( i; list )
{
float d = dist( m, i.mean );
if( d < min_dist )
{
min_dist = d;
near_cls = i;
}
}
if( min_dist < ncls_dist ) near_cls.append(m);
else list ~= new Class(m);
}
void mergeClasses()
{
Class[] uniq;
l: foreach( cls; list )
{
foreach( trg; uniq )
if( dist( cls.mean, trg.mean ) < ncls_dist )
{
trg.merge( cls );
continue l;
}
uniq ~= cls;
}
list = uniq;
}
}
Measure[] readMeasuresFromFile( string name )
{
auto file = File( name, "r" );
Measure[] list;
foreach( line; file.byLine() )
{
Measure tmp;
formattedRead( line, "%f %f", &tmp.x, &tmp.y );
list ~= tmp;
}
return list;
}
void main( string[] args )
{
auto measures = readMeasuresFromFile( args[1] );
StopWatch sw;
sw.start();
auto clsf = new Classifier(3);
foreach( m; measures )
clsf.classificate(m);
version(MERGE_CLASSES)
clsf.mergeClasses();
sw.stop();
writeln( "work time: ", sw.peek.nsecs / 1_000_000_000.0f );
foreach( cls; clsf.list )
writefln( "[%f, %f]: %d", cls.mean.x, cls.mean.y, cls.N );
}
Код на Rust
#![feature(duration)]
#![feature(duration_span)]
#![feature(append)]
use std::ops::*;
use std::borrow::Borrow;
use std::f32;
use std::cell::RefCell;
use std::fs::File;
use std::io::BufReader;
use std::io::BufRead;
use std::time::Duration;
use std::env;
#[derive(Clone,Copy)]
struct Measure
{
x : f32,
y : f32
}
impl Measure{
#[allow(non_snake_case)]
pub fn new(X:f32,Y:f32) -> Measure{
Measure{
x:X,
y:Y
}
}
}
impl Add for Measure{
type Output = Measure;
fn add(self, rhs:Measure) -> Measure {
Measure{
x: self.x + rhs.x,
y: self.y + rhs.y,
}
}
}
impl Sub for Measure{
type Output = Measure;
fn sub(self, rhs: Measure) -> Measure {
Measure{
x: self.x - rhs.x,
y: self.y - rhs.y
}
}
}
impl Div<f32> for Measure {
type Output = Measure;
fn div(self, rhs: f32) -> Measure {
Measure{
x: self.x / rhs,
y: self.y / rhs
}
}
}
impl Mul<f32> for Measure {
type Output = Measure;
fn mul(self, rhs: f32) -> Measure {
Measure{
x: self.x * rhs,
y: self.y * rhs
}
}
}
#[inline]
fn sqr(v:f32)->f32
{
v * v
}
fn dist (a: & Measure, b: & Measure) -> f32
{
(sqr(a.x - b.x) + sqr(a.y - b.y)).sqrt()
}
#[derive(Clone)]
struct Class
{
mean: Measure,
count: usize,
#[cfg(collect_measures)]
measures: Vec<Measure>
}
impl Class{
#[cfg(collect_measures)]
pub fn new( m: Measure ) -> Class
{
Class{
mean: m,
count: 1,
measures: vec![m.clone()]
}
}
#[cfg(not(collect_measures))]
pub fn new( m: Measure ) -> Class
{
Class{
mean: m,
count: 1,
}
}
#[cfg(collect_measures)]
pub fn append(&mut self, m: Measure){
self.mean = ( self.mean * self.count as f32 + m ) /( self.count + 1)as f32;
self.measures.push(m.clone());
self.count += 1;
}
#[cfg(not(collect_measures))]
pub fn append(&mut self, m: Measure){
self.mean = ( self.mean * self.count as f32 + m ) /( self.count + 1)as f32;
self.count += 1;
}
#[cfg(collect_measures)]
pub fn merge(&mut self, m: &mut Class)
{
self.mean = ( self.mean * self.count as f32 + ((m.mean) * m.count as f32 )) / ( self.count + m.count) as f32;
self.count += m.count;
self.measures.append(&mut m.measures);
}
#[cfg(not(collect_measures))]
pub fn merge(&mut self, m: &mut Class)
{
self.mean = ( self.mean * self.count as f32 + ((m.mean) * m.count as f32 )) / ( self.count + m.count) as f32;
self.count += m.count;
}
}
#[test]
fn test_Measure()
{
let a = Measure::new(1f32,3f32);
let b = Measure::new(4f32,5f32);
let add = a + b;
assert!( add.x == 5f32 && add.y == 8f32 );
let dif = a - b;
assert!( dif.x == -3f32 && dif.y == -2f32 );
let mlt = &a * 3f32;
assert!( mlt.x == 3f32 && mlt.y == 9f32 );
let div = &b / 2f32;
assert!( div.x == 2f32 && div.y == 2.5f32 );
}
#[test]
fn test_Class()
{
let mut cls = Class::new( Measure::new(1f32,2f32) );
assert!( cls.mean.x == 1f32 && cls.mean.y == 2f32 );
assert!( cls.count == 1 );
cls.append( Measure::new(3f32,4f32) );
assert!( cls.mean.x == 2f32 && cls.mean.y == 3f32 );
assert!( cls.count == 2 );
}
struct Classifier
{
list:Vec<RefCell<Class>>,
ncls_dist:f32
}
impl Classifier{
pub fn new(mdist:f32) -> Classifier{
Classifier{
list:Vec::new(),
ncls_dist:mdist
}
}
pub fn classificate(&mut self, m: Measure){
let mut min_dist:f32 = f32::MAX;
let mut near_cls = 0;
let mut index:usize = 0;
for i in self.list.iter()
{
let d = dist( &m, & i.borrow().mean);
if d < min_dist
{
min_dist = d;
near_cls = index;
}
index+=1;
}
if min_dist < self.ncls_dist{
self.list[near_cls].borrow_mut().append(m);
}
else {
self.list.push(RefCell::new( Class::new(m)));
}
}
#[allow(dead_code)]
pub fn merge_classes(&mut self)
{
let mut uniq: Vec<RefCell<Class>>= Vec::new();
for cls in self.list.iter(){
let mut is_uniq = true;
for trg in uniq.iter(){
if dist( &cls.borrow().mean, &trg.borrow().mean) < self.ncls_dist
{
trg.borrow_mut().merge(&mut *cls.borrow_mut());
is_uniq = false;
break;
}
}
if is_uniq
{
uniq.push(RefCell::new(cls.borrow_mut().clone()));
}
}
self.list = uniq;
}
}
fn read_measures_from_file( name: String ) -> Vec<Measure>
{
let mut list:Vec<Measure> = Vec::new();
let f = File::open(name).unwrap();
let mut reader = BufReader::new(&f);
let mut ret_string = String::new();
while let Ok(size ) = reader.read_line( &mut ret_string){
if size > 0
{
let len = ret_string.len() - 1;
ret_string.truncate(len);
let buffer:Vec<&str> = ret_string.split(' ').collect();
let var:f32 = (buffer[0]).parse::<f32>().unwrap();
let var2:f32 = (buffer[1]).parse::<f32>().unwrap();
list.push(Measure::new(var,var2));
}
else{
break;
}
ret_string.clear();
}
return list;
}
fn main()
{
let measures = read_measures_from_file(env::args().skip(1).next().unwrap());
let mut clsf = Classifier::new(3f32);
let d = Duration::span(||{
for i in measures{
clsf. classificate(i);
}
if cfg!(merge_classes){
clsf.merge_classes();
}
});
println!("work time: {}", d.secs() as f64 + d.extra_nanos()as f64 / 1000000000.0f64);
for i in clsf.list{
let i = i.borrow();
println!("[{}, {}]: {}",i.mean.x,i.mean.y, i.count);
}
}
Код на С++
#include <vector>
#include <cmath>
#include <cfloat>
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <cassert>
#include <ctime>
using namespace std;
//#define COLLECT_MEASURES
//#define MERGE_CLASSES
class Measure
{
public:
float x, y;
Measure(): x(0), y(0) {}
Measure( float X, float Y ): x(X), y(Y) {}
Measure( const Measure& m ): x(m.x), y(m.y) {}
Measure operator+( const Measure& m ) const
{ return Measure( x + m.x, y + m.y ); }
Measure operator-( const Measure& m ) const
{ return Measure( x - m.x, y - m.y ); }
Measure operator*( float v ) const
{ return Measure( x * v, y * v ); }
Measure operator/( float v ) const
{ return Measure( x / v, y / v ); }
};
void test_Measure()
{
Measure a(1,3);
Measure b(4,5);
auto add = a + b;
assert( add.x == 5 && add.y == 8 );
auto dif = a - b;
assert( dif.x == -3 && dif.y == -2 );
auto mlt = a * 3;
assert( mlt.x == 3 && mlt.y == 9 );
auto div = b / 2;
assert( div.x == 2 && div.y == 2.5 );
}
inline float sqr( float v ) { return v * v; }
float dist( const Measure& a, const Measure& b )
{ return sqrt( sqr(a.x - b.x) + sqr(a.y - b.y) ); }
class Class
{
public:
Measure mean;
size_t N;
#ifdef COLLECT_MEASURES
vector<Measure> measures;
#endif
Class( const Measure& m ): mean(m)
{
N = 1;
#ifdef COLLECT_MEASURES
measures.push_back(m);
#endif
}
void append( const Measure& m )
{
mean = ( mean * N + m ) / ( N + 1 );
N++;
#ifdef COLLECT_MEASURES
measures.push_back(m);
#endif
}
void merge( const Class& m )
{
mean = ( mean * N + m.mean * m.N ) / ( N + m.N );
N += m.N;
#ifdef COLLECT_MEASURES
measures.insert(measures.end(), m.measures.begin(), m.measures.end());
#endif
}
};
void test_Class()
{
auto cls = Class( Measure(1,2) );
assert( cls.mean.x == 1 && cls.mean.y == 2 );
assert( cls.N == 1 );
cls.append( Measure(3,4) );
assert( cls.mean.x == 2 && cls.mean.y == 3 );
assert( cls.N == 2 );
}
class Classifier
{
public:
vector<Class*> list;
float ncls_dist;
Classifier( float mdist ): ncls_dist(mdist) {}
void classificate( const Measure& m )
{
float min_dist = FLT_MAX;
Class* near_cls;
for( auto i = list.begin(); i != list.end(); ++i )
{
float d = dist( m, (*i)->mean );
if( d < min_dist )
{
min_dist = d;
near_cls = *i;
}
}
if( min_dist < ncls_dist ) near_cls->append(m);
else list.push_back( new Class(m) );
}
void mergeClasses()
{
vector<Class*> uniq;
l: for( auto cls = list.begin(); cls != list.end(); ++cls )
{
bool is_uniq = true;
for( auto trg = uniq.begin(); trg != uniq.end(); ++trg )
{
if( dist( (*cls)->mean, (*trg)->mean ) < ncls_dist )
{
(*trg)->merge( **cls );
delete (*cls);
is_uniq = false;
}
if( !is_uniq ) break;
}
if( is_uniq ) uniq.push_back( *cls );
}
list = uniq;
}
~Classifier()
{
for( auto i = list.begin(); i != list.end(); ++i )
delete *i;
}
};
vector<Measure> readMeasuresFromFile( char* name )
{
ifstream file( name );
vector<Measure> list;
for( string line; getline(file, line); )
{
istringstream in( line );
Measure tmp;
in >> tmp.x >> tmp.y;
list.push_back( tmp );
}
return list;
}
void runTests()
{
test_Measure();
test_Class();
}
int main( int argc, char* args[] )
{
//runTests();
auto measures = readMeasuresFromFile( args[1] );
clock_t start = clock();
auto clsf = new Classifier(3);
for( auto i = measures.begin(); i != measures.end(); ++i )
clsf->classificate( *i );
#ifdef MERGE_CLASSES
clsf->mergeClasses();
#endif
clock_t end = clock();
cout << "work time: " << double(end - start) / CLOCKS_PER_SEC << endl;
for( auto i = clsf->list.begin(); i != clsf->list.end(); ++i )
cout << "[" << (*i)->mean.x << ", " << (*i)->mean.y << "]: " << (*i)->N << endl;
delete clsf;
}
Код генератора выборки
import std.stdio;
import std.string;
import std.exception;
import std.random;
import std.math;
double normal( double mu=0.0, double sigma=1.0 )
{
static bool deviate = false;
static float stored;
if( !deviate )
{
double max = cast(double)(ulong.max - 1);
double dist = sqrt( -2.0 * log( uniform( 0, max ) / max ) );
double angle = 2.0 * PI * ( uniform( 0, max ) / max );
stored = dist * cos( angle );
deviate = true;
return dist * sin( angle ) * sigma + mu;
}
else
{
deviate = false;
return stored * sigma + mu;
}
}
struct vec { float x, y; }
vec randomVec( in vec m, in vec s ) { return vec( normal(m.x, s.x), normal(m.y, s.y) ); }
auto generate( size_t[vec] classes )
{
vec[] ret;
foreach( pnt, count; classes )
{
auto tmp = new vec[]( count );
foreach( i, ref t; tmp )
t = randomVec( pnt, vec(1,1) );
ret ~= tmp;
}
return ret;
}
import std.getopt;
void main( string[] args )
{
uint k;
getopt( args,
"count-multiplier|c", &k
);
enforce( args.length == 2, format( "wrong number of arguments: use %s <output_file>", args[0] ) );
auto f = File( args[1], "w" );
scope(exit) f.close();
auto vs = generate( [ vec(-8,8): 20 * k, vec(4,0) : 10 * k, vec(-6,-8) : 15 * k ] );
foreach( v; vs.randomSample(vs.length) )
f.writeln( v.x, " ", v.y );
}
Сборка
Тест 1
Тест 2
g++ -O2 -std=c++11 cls.cpp -o cls_cpp && echo "c++ g++ builded"
dmd -O -release cls.d -ofcls_d_dmd && echo "d dmd builded"
ldc2 -O2 -release cls.d -ofcls_d_ldc2 && echo "d ldc2 builded"
gdc -O2 cls.d -o cls_d_gdc && echo "d gdc builded"
rustc -O cls.rs -o cls_rs && echo "rust rustc builded"
Тест 2
g++ -O2 -D COLLECT_MEASURES -D MERGE_CLASSES -std=c++11 cls.cpp -o cls_cpp && echo "c++ g++ builded"
dmd -O -version=COLLECT_MEASURES -version=MERGE_CLASSES -release cls.d -ofcls_d_dmd && echo "d dmd builded"
ldc2 -O2 -d-version COLLECT_MEASURES -d-version MERGE_CLASSES -release cls.d -ofcls_d_ldc2 && echo "d ldc2 builded"
gdc -O2 -fversion=COLLECT_MEASURES -fversion=MERGE_CLASSES cls.d -o cls_d_gdc && echo "d gdc builded"
rustc -O --cfg collect_measures --cfg merge_classes cls.rs -o cls_rs && echo "rust rustc builded"
Версии компиляторов
g++ (GCC) 5.1.1 20150612 (Red Hat 5.1.1-3)
DMD64 D Compiler v2.067.1
GNU gdb (GDB) Fedora 7.9.1-13.fc22
LDC — the LLVM D compiler (0.15.2-beta1)
rustc 1.3.0-nightly (cb7d06215 2015-06-26)
DMD64 D Compiler v2.067.1
GNU gdb (GDB) Fedora 7.9.1-13.fc22
LDC — the LLVM D compiler (0.15.2-beta1)
rustc 1.3.0-nightly (cb7d06215 2015-06-26)
PS. В языках Rust и Go не силён, если кто-нибудь захочет написать эквивалентный код (для полноты эксперимента) буду рад вставить результаты сюда.
UPD: спасибо тов. I_AM_FAKE за код на Rust
