«Достань словарь и посмотри, что такое «катарсис». Если это то, чем он хочет нас замочить, я хочу знать, что это такое.» (с) Анализируй это!
Поздним вечером, когда проектирование базы данных на 64 таблицы было почти завершено, а интерфейс для их заполнения еще даже не начинался, встал вопрос о том, как их все-таки заполнить данными.
Заполнить в ручную — идея была откинута в сторону сразу.
«Надо что-то накодить!» — кричала душа.
«Надо что-то скачать!» — настаивал разум!
В результате прошвырнувшись по Интернету и найдя с десяток разного рода решений как устанавливаемых, так и SaaS, как платных, так и бесплатных — нашел я его — databene-benerator- генератор связанных данных (фикстур) для баз данных. И статью на русском, с описанием возможностей и синтаксиса (1), а так же ее, но на английском (2). Я понял — это то, что нужно! Но откуда его взять? Как его использовать под Windows? Удобно? С поддержкой русских символов?
И так «катарсис» (3) — понятие в античной философии; термин для обозначения процесса и результата облегчающего, очищающего и облагораживающего воздействия на человека различных факторов.
Как это связано с темой публикации? Вы поймете, если прочтете это. Приглашаю под cut!
То, что было описано в вышеупомянутых статьях о «бенераторе» мне не совсем подходило.
Если хоть что-то из перечисленного выше для вас подходит, то значит у нас с вами другой путь, точнее другой вход на этот путь!
Для начала нам нужно получить сам бенератор, для этого необходимо заполнить форму по адресу:
bergmann-it.de/download/download_benerator?lang=en
и нажать «Download».
На момент публикации доступна 0.9.8, я же использовал 0.9.7, по сути, разницу вы, скорее всего не заметите, так как самый свежий мануал, который я смог найти это — вот этот (4) для версии 0.8.1.
Наткнулся я на него совершенно случайно, сравнив версию в мануале (http://databene.org/download/databene-benerator-manual-0.7.6.pdf) на сайте и версию бенератора. Я стал подбирать версию в адресе мануала, и каково же было удивление найдя 0.8.1!!! Дальнейшие поиски не увенчались успехом...
И так вы справились! У нас в руках, т.е. на кончиках пальцев архив «databene-benerator-0.9.7» (у вас свежее). Теперь, что с этим делать.
Распаковываем в «D:\databene-benerator-0.9.7».
А дальше пошло чистой воды шаманство: на форумах упоминается maven — кто это за зверь я не знаю, но скажу что работает и без него!
Путем не хитрых операцию смотрю что есть в архиве. Есть батнички (или sh-скрипты к слову тоже есть), которые что-то запускают… benerator.bat запускает benerator_common.bat, тот запускает java.exe. В параметрах у первого benerator.xml. Во втором пути к папке lib, а там *.jar.…
На тот момент я пробовал работать только в двух IDE для разработки на Java — Netbeans и Eclipse. Задал гуглу вопрос «databene Benerator eclipse» и в выдаче получил ответ «databene.org/databene-benerator/115-my-first-ide-based-benerator-project.html» — но ссылки со страниц официального сайта на эту страницу — нет!
Теперь нам нужен Eclipse, скачиваем и распаковываем, если его еще нет. Подойдет любая версия. Я слегка знаком с PHP, поэтому мой выбор вы угадаете. Кстати и расположение рабочих окон Eclipse (так называемая перспектива) для работы с бенератором — удобнее PHP (можно выбрать в правом верхнем углу).
И так запускаем Eclipse, создаем проект:
Выбираем «File->New->Project…»

Затем выбираем «Java Project», жмем «Next->».
В появившемся окне вводим название проекта «generatedb», и выбираем Project layout как «Use project folder as root for sources and class files», жмем «Next->».
Переключаемся на вкладку Libraries, жмем «Add External JARs…». В открывшемся окошке идем в «D:\databene-benerator-0.9.7\lib» и выбираем все файлы, которые там есть.
Жмем «Finish». Проект создан.
Однако для запуска бенератора нужно настроить «запускатор»!
Выбираем «Run->Run Configurations…».
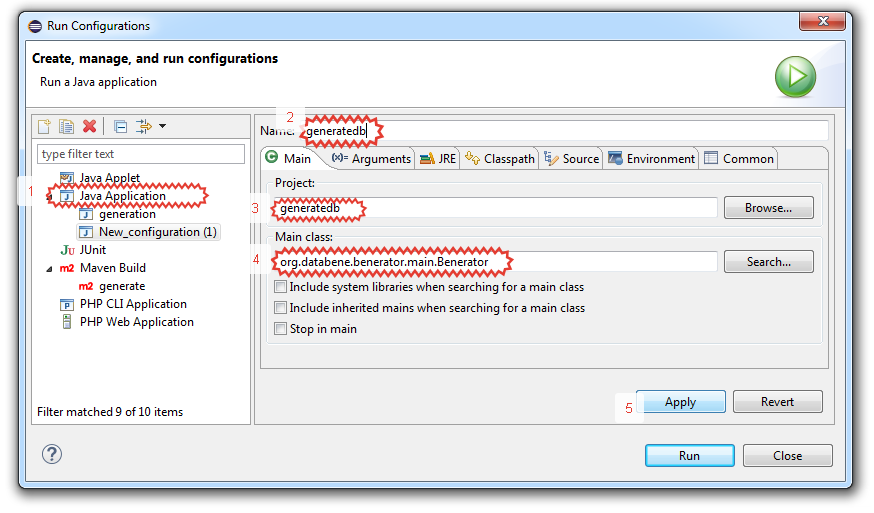
В появившемся окне:
1. На «Java Aplication» делаем ПКМ и выбираем «New».
2. Затем «Name» указываем название нашей конфигурации для запуска.
3. Далее «Project» оставляем без изменения.
4. А в «Main class» вводим «org.databene.benerator.main.Benerator».
5. Жмем «Apply».
Если вы все-таки нажали «Run», то во вкладку «Console» будет выдано большое количество строк разных ругательств, все не по-русски. Это потому, что мы не сделали самого главного. Так чего мы ждем?
В наш проект пора добавить файлы «benerator.xml» и «log4j.xml», на отсутствие которых ругался benerator.
ПКМ на проекте в обозревателе проектов и выбираем «New->XML File», вводим название файла, затем «Finish».
benerator.xml – главный файл проекта, именно в нем описывается все, что вы сделаете со своими таблицами.
log4j.xml – файл конфигурации инструмента для логов, от его конфигурации зависит что и в каком объеме бенератор выплюнет в консоль (служебную информацию).
Содержимое «log4j.xml» приводим к виду:
Содержимое «benerator.xml» приводим к виду:
Остановимся на некоторых моментах «benerator.xml», более подробно он рассмотрен в первой русскоязычной статье и в руководстве к версии 0.8.1.
Здесь же отмечу, что волшебная строчка «characterEncoding=UTF-8» в параметре url – решает проблему с переносом русских символов в базу данных (и не только русских).
Упомянуть об этом разработчики на сайте тоже забыли. Ну да это не их забота. Строка конфигурации драйвера jdbc универсальна для Java приложений, в результате нашел это где-то на не относящемся к области поиска ресурсе.
Очистка таблиц базы данных перед повторным генерированием
Для начала подготавливаем файл «truncate_tables.mysql.sql» (текстовый)
Первая и последние строчки – отключение и включение проверки консистентности таблицы. Иначе может возникнуть ситуация когда одна таблица блокирует удаление записей другой (ссылочная целостность).
Строчки – команды очистки конкретных таблиц БД. Их желательно группировать по следующему принципу:
1. Отдельная группа справочники (не связаны ни с какими другими)
2. Далее группы каскадно могут завязываться на уже заполненные таблицы.
Очистка – либо целиком группу, либо по одной, но следить за зависимостями.
Комментирование по таблично удобно для того, что бы можно было гибко выполнять повторную генерацию данных.
В benerator.xml после определения memstore добавляем строки:
Будьте бдительны! После запуска бенератора — не закомментированные таблицы очистятся!
Удаление таблиц и создание базы данных – вносить такие манипуляции сюда, на мой взгляд, не стоит. Для этого есть удобные инструменты для синхронизации модели и базы данных. Я пользуюсь MySQL Workbench (5).
Встраивание в бенератор скриптов на… JavaScript!? Да, да на нем!
В benerator.xml после определения execute добавляем строки:
Создаем файл «script.js» (текстовый)
Первая функция выполняет транслитерацию русских символов на английские (взято с (5), с небольшими переработками).
Вторая – вырезает кусочек строки.
Пример использования JavaScript в коде:
Основная идея: все что в параметре script, внутри {js: } – суть JavaScript. Переменные передаются прозрачно, в прочем это видно из примеров использования.
Уже обратили внимание на сокращенную запись условного оператора if?
Распределение таблиц БД по отдельным файлам для удобства генерации
Мне было удобно выделять каждую таблицу, или группу из 2-3 взаимосвязанных таблиц, генерация которых не может быть выполнена независимо – в отдельный файл «*.ben.xml». Каждый файл комментируется отдельно для удобства его отдельной генерации.
Обратите внимание: эти файлы должны иметь расширение именно «*.ben.xml».
В основном файле это выглядит так:
Пример файла «table.s_organization.ben.xml» (XML)
Обратите внимание – структура схожа с «benerator.xml», однако не нужно описывать соединение с БД и подключение общих модулей, т.к. все это уже выполнено в основном файле конфигурации.
Теперь, то почему я испытал «катарсис» – после стольких мучений все работало:
1. databene-benerator запускался и заполнял таблички данными, всего 2-3 ночи и вуаля удобный инструмент для решения насущной задачи!
2. Оказывается, русские символы, он понимает, и это мой косяк, что я мало знаком с синтаксисом обращения к jdbc-драйверу в Java-проектах (синтаксис универсальный) – еще 3 ночи и тоже все ровно!
3. Пошли алгоритмы заполнения таблиц один за другим, они сдавались под моим напором каждый вечер. И все 64 таблицы удалось заполнить еще за 6 вечеров.
Да есть еще много вопросов, но основные из них раскрыты, задача выполнена, знания получены, опыт приобретен. Для изменения количества и качества записей в таблицах мне не нужно их «лопатить» руками. Бенератор за несколько минут сделает свое дело.
В статье не рассмотрены:
1. генерация взаимосвязанных таблиц,
2. работа с датой и временем,
3. генерация вещественных чисел.
Однако эта информация есть в постах, на которые есть ссылки, а так же в документации. Так что после такого ускорения, читателю не составить много труда освоить и эти вопросы.
Специально для статьи зарегистрировался на github и выложил исходники, которые могут помочь разобраться с примерами. Для их использования достаточно скачать в виде *.zip архива, распаковать его. Создать новый проект и выполнить импорт в него «File->Import->General->FileSystem». Отметить весь проект и нажать «Finish». Не забудьте добавить «запускатор» и библиотеки бенератора.
Спасибо за внимание!
1. habrahabr.ru/post/169713. [В Интернете]
2. sysmagazine.com/posts/169713. [В Интернете]
3. ru.wikipedia.org/wiki/Катарсис. [В Интернете]
4. databene.org/download/databene-benerator-manual-0.8.1.pdf. [В Интернете]
5. dev.mysql.com/downloads/workbench. [В Интернете]
6. ajaxs.ru/lesson/javascript/137-transliteracija_stroki_na_javascript.html. [В Интернете]
Введение
Поздним вечером, когда проектирование базы данных на 64 таблицы было почти завершено, а интерфейс для их заполнения еще даже не начинался, встал вопрос о том, как их все-таки заполнить данными.
Заполнить в ручную — идея была откинута в сторону сразу.
«Надо что-то накодить!» — кричала душа.
«Надо что-то скачать!» — настаивал разум!
В результате прошвырнувшись по Интернету и найдя с десяток разного рода решений как устанавливаемых, так и SaaS, как платных, так и бесплатных — нашел я его — databene-benerator- генератор связанных данных (фикстур) для баз данных. И статью на русском, с описанием возможностей и синтаксиса (1), а так же ее, но на английском (2). Я понял — это то, что нужно! Но откуда его взять? Как его использовать под Windows? Удобно? С поддержкой русских символов?
И так «катарсис» (3) — понятие в античной философии; термин для обозначения процесса и результата облегчающего, очищающего и облагораживающего воздействия на человека различных факторов.
Как это связано с темой публикации? Вы поймете, если прочтете это. Приглашаю под cut!
Создание проекта в Eclipse
То, что было описано в вышеупомянутых статьях о «бенераторе» мне не совсем подходило.
- использую для работы Windows;
- люблю GUI (такая слабость, как котики… Ну вы поняли).
- умею работать с MySQL, но не с PostgreSQL.
- мне нужны данные еще и на русском.
Если хоть что-то из перечисленного выше для вас подходит, то значит у нас с вами другой путь, точнее другой вход на этот путь!
Для начала нам нужно получить сам бенератор, для этого необходимо заполнить форму по адресу:
bergmann-it.de/download/download_benerator?lang=en
и нажать «Download».
На момент публикации доступна 0.9.8, я же использовал 0.9.7, по сути, разницу вы, скорее всего не заметите, так как самый свежий мануал, который я смог найти это — вот этот (4) для версии 0.8.1.
Наткнулся я на него совершенно случайно, сравнив версию в мануале (http://databene.org/download/databene-benerator-manual-0.7.6.pdf) на сайте и версию бенератора. Я стал подбирать версию в адресе мануала, и каково же было удивление найдя 0.8.1!!! Дальнейшие поиски не увенчались успехом...
И так вы справились! У нас в руках, т.е. на кончиках пальцев архив «databene-benerator-0.9.7» (у вас свежее). Теперь, что с этим делать.
Распаковываем в «D:\databene-benerator-0.9.7».
А дальше пошло чистой воды шаманство: на форумах упоминается maven — кто это за зверь я не знаю, но скажу что работает и без него!
Путем не хитрых операцию смотрю что есть в архиве. Есть батнички (или sh-скрипты к слову тоже есть), которые что-то запускают… benerator.bat запускает benerator_common.bat, тот запускает java.exe. В параметрах у первого benerator.xml. Во втором пути к папке lib, а там *.jar.…
На тот момент я пробовал работать только в двух IDE для разработки на Java — Netbeans и Eclipse. Задал гуглу вопрос «databene Benerator eclipse» и в выдаче получил ответ «databene.org/databene-benerator/115-my-first-ide-based-benerator-project.html» — но ссылки со страниц официального сайта на эту страницу — нет!
Теперь нам нужен Eclipse, скачиваем и распаковываем, если его еще нет. Подойдет любая версия. Я слегка знаком с PHP, поэтому мой выбор вы угадаете. Кстати и расположение рабочих окон Eclipse (так называемая перспектива) для работы с бенератором — удобнее PHP (можно выбрать в правом верхнем углу).
И так запускаем Eclipse, создаем проект:
Выбираем «File->New->Project…»

Затем выбираем «Java Project», жмем «Next->».
В появившемся окне вводим название проекта «generatedb», и выбираем Project layout как «Use project folder as root for sources and class files», жмем «Next->».
Переключаемся на вкладку Libraries, жмем «Add External JARs…». В открывшемся окошке идем в «D:\databene-benerator-0.9.7\lib» и выбираем все файлы, которые там есть.
Жмем «Finish». Проект создан.
Однако для запуска бенератора нужно настроить «запускатор»!
Выбираем «Run->Run Configurations…».

В появившемся окне:
1. На «Java Aplication» делаем ПКМ и выбираем «New».
2. Затем «Name» указываем название нашей конфигурации для запуска.
3. Далее «Project» оставляем без изменения.
4. А в «Main class» вводим «org.databene.benerator.main.Benerator».
5. Жмем «Apply».
Если вы все-таки нажали «Run», то во вкладку «Console» будет выдано большое количество строк разных ругательств, все не по-русски. Это потому, что мы не сделали самого главного. Так чего мы ждем?
Структура проекта
В наш проект пора добавить файлы «benerator.xml» и «log4j.xml», на отсутствие которых ругался benerator.
ПКМ на проекте в обозревателе проектов и выбираем «New->XML File», вводим название файла, затем «Finish».
benerator.xml – главный файл проекта, именно в нем описывается все, что вы сделаете со своими таблицами.
log4j.xml – файл конфигурации инструмента для логов, от его конфигурации зависит что и в каком объеме бенератор выплюнет в консоль (служебную информацию).
Содержимое «log4j.xml» приводим к виду:
log4j.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/" debug="false">
<!-- Append messages to the console -->
<appender name="CONSOLE" class="org.apache.log4j.ConsoleAppender">
<param name="Target" value="System.out"/>
<param name="Threshold" value="debug"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{ABSOLUTE} %-5p (%t) [%c{1}] %m%n"/>
</layout>
</appender>
<!-- Limit categories -->
<category name="org.apache">
<priority value="warn"/>
</category>
<category name="org.databene">
<priority value="info"/>
</category>
<!-- <category name="org.databene.commons">
<priority value="debug"/>
</category> -->
<category name="org.databene.COMMENT">
<priority value="debug"/>
</category>
<category name="org.databene.benerator.STATE">
<priority value="info"/>
</category>
<category name="org.databene.domain">
<priority value="info"/>
</category>
<category name="org.databene.SQL">
<priority value="debug"/>
</category>
<!-- ======================= -->
<!-- Setup the Root category -->
<!-- ======================= -->
<root>
<priority value="info"/>
<appender-ref ref="CONSOLE"/>
</root>
</log4j:configuration>
Содержимое «benerator.xml» приводим к виду:
benerator.xml
<?xml version="1.0" encoding="UTF-8"?>
<setup xmlns="http://databene.org/benerator/0.9.7"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.9.7 benerator-0.9.7.xsd"
defaultEncoding="UTF-8"
defaultDataset="RU"
defaultLocale="ru"
defaultLineSeparator="\r\n"
defaultSeparator=";">
<import platforms="db,csv" />
<import defaults="true" domains="organization,address,person,net" />
<import class="org.databene.benerator.distribution.function.*,
org.databene.benerator.primitive.*,org.databene.platform.db.*"/>
<import class="org.databene.commons.TimeUtil"/>
<database id="db"
url="jdbc:mysql://localhost:3306/qs?characterEncoding=UTF-8"
driver="com.mysql.jdbc.Driver"
user="root"
password=""
catalog="qs"/>
<memstore id="memstore"/>
</setup>
Основной сценарий и некоторые рабочие решения
Остановимся на некоторых моментах «benerator.xml», более подробно он рассмотрен в первой русскоязычной статье и в руководстве к версии 0.8.1.
Здесь же отмечу, что волшебная строчка «characterEncoding=UTF-8» в параметре url – решает проблему с переносом русских символов в базу данных (и не только русских).
Упомянуть об этом разработчики на сайте тоже забыли. Ну да это не их забота. Строка конфигурации драйвера jdbc универсальна для Java приложений, в результате нашел это где-то на не относящемся к области поиска ресурсе.
Очистка таблиц базы данных перед повторным генерированием
Для начала подготавливаем файл «truncate_tables.mysql.sql» (текстовый)
truncate_tables.mysql.sql
SET foreign_key_checks = 0;
--truncate table s_person;
--truncate table s_job_title;
--truncate table s_organization;
--truncate table s_department;
--truncate table t_orgstructure;
--truncate table s_type_project;
--truncate table s_direction_project;
--truncate table s_norm_labor;
--truncate table s_timetable;
SET foreign_key_checks = 1;
Первая и последние строчки – отключение и включение проверки консистентности таблицы. Иначе может возникнуть ситуация когда одна таблица блокирует удаление записей другой (ссылочная целостность).
Строчки – команды очистки конкретных таблиц БД. Их желательно группировать по следующему принципу:
1. Отдельная группа справочники (не связаны ни с какими другими)
2. Далее группы каскадно могут завязываться на уже заполненные таблицы.
Очистка – либо целиком группу, либо по одной, но следить за зависимостями.
Комментирование по таблично удобно для того, что бы можно было гибко выполнять повторную генерацию данных.
В benerator.xml после определения memstore добавляем строки:
<comment>Подготавливаем базу данных</comment>
<execute uri="truncate_tables.mysql.sql" target="db" />
Будьте бдительны! После запуска бенератора — не закомментированные таблицы очистятся!
Удаление таблиц и создание базы данных – вносить такие манипуляции сюда, на мой взгляд, не стоит. Для этого есть удобные инструменты для синхронизации модели и базы данных. Я пользуюсь MySQL Workbench (5).
Встраивание в бенератор скриптов на… JavaScript!? Да, да на нем!
В benerator.xml после определения execute добавляем строки:
<comment>Подготавливаем внешние скрипты</comment>
<execute uri="script.js" type="js"/>
Создаем файл «script.js» (текстовый)
script.js
function toLink (str) {
var space = '';
str = str.toLowerCase();
var transl = {
'а': 'a', 'б': 'b', 'в': 'v', 'г': 'g', 'д': 'd', 'е': 'e', 'ё': 'e', 'ж': 'zh',
'з': 'z', 'и': 'i', 'й': 'j', 'к': 'k', 'л': 'l', 'м': 'm', 'н': 'n',
'о': 'o', 'п': 'p', 'р': 'r','с': 's', 'т': 't', 'у': 'u', 'ф': 'f', 'х': 'h',
'ц': 'c', 'ч': 'ch', 'ш': 'sh', 'щ': 'sh','ъ': space, 'ы': 'y', 'ь': space, 'э': 'e', 'ю': 'yu', 'я': 'ya'
}
var link = '';
for (var i = 0; i < str.length; i++) {
if(/[а-яё]/.test(str.charAt(i))) { //если текущий символ - русская буква, то меняем его
link += transl[str.charAt(i)];
} else if (/[a-z0-9]/.test(str.charAt(i))) {
link += str.charAt(i); //если текущий символ - английская буква или цифра, то оставляем как есть
} else {
if (link.slice(-1) !== space) link += space; // если не то и не другое то вставляем space
}
}
return link;
}
function cut(str, cutStart, cutEnd){
return str.substr(cutStart,cutEnd);
}
Первая функция выполняет транслитерацию русских символов на английские (взято с (5), с небольшими переработками).
Вторая – вырезает кусочек строки.
Пример использования JavaScript в коде:
<generate type="s_organization" count="20" consumer="db,ConsoleExporter">
…
<variable name="sgn" script="{js: (p.gender.name()=='MALE') ? sgnMALE : sgnFEMALE}"/>
<attribute name="email" type='string' script="{js:toLink(p.givenName+p.familyName)+'@'+d}" converter="ToLowerCaseConverter, UniqueStringConverter"/>
<variable name="theme_tmp" type='string' generator="new SeedSentenceGenerator('csv/notes.txt',3)" />
<attribute name="theme" maxLength="45" script="{js:cut(theme_tmp,0,44)+'.'}"/>
…
</generate>
Основная идея: все что в параметре script, внутри {js: } – суть JavaScript. Переменные передаются прозрачно, в прочем это видно из примеров использования.
Уже обратили внимание на сокращенную запись условного оператора if?
Распределение таблиц БД по отдельным файлам для удобства генерации
Мне было удобно выделять каждую таблицу, или группу из 2-3 взаимосвязанных таблиц, генерация которых не может быть выполнена независимо – в отдельный файл «*.ben.xml». Каждый файл комментируется отдельно для удобства его отдельной генерации.
Обратите внимание: эти файлы должны иметь расширение именно «*.ben.xml».
В основном файле это выглядит так:
<!-- <include uri="table.s_organization.ben.xml" /> -->
<!-- <include uri="table.s_job_title.ben.xml" /> -->
<!-- <include uri="table.s_type_doc.ben.xml" />-->
Пример файла «table.s_organization.ben.xml» (XML)
table.s_organization.ben.xml
<?xml version="1.0" encoding="UTF-8"?>
<setup xmlns="http://databene.org/benerator/0.9.7"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.9.7 benerator-0.9.7.xsd"
defaultEncoding="UTF-8"
defaultDataset="RU"
defaultLocale="ru"
defaultLineSeparator="\r\n"
defaultSeparator=";"
>
<comment>[[POPULATE TABLE s_organization]] Processed...</comment>
<generate type="s_organization" count="20" consumer="db,ConsoleExporter">
<attribute name="bik" type='string' pattern='[0-9]{9}'/>
<variable name="c" generator="CompanyNameGenerator" dataset="US" locale="us"/>
<attribute name="caption" type='string' script="c.fullName" />
<attribute name="short_caption" type='string' script="c.shortName" />
<attribute name="form_sobs" type='string' script="c.legalForm" />
<variable name="a" generator="AddressGenerator" dataset="US" locale="us"/>
<attribute name="ur_strana" type='string' script="a.country" />
<attribute name="ur_index" type='string' pattern="[0-9]{6}"/>
<attribute name="ur_nas_punkt" type='string' script="a.city" />
<attribute name="ur_ulica" type='string' script="a.street" />
<attribute name='ur_dom' type='int' min='1' max='150' />
<attribute name='ur_office' type='int' min='1' max='100' />
<attribute name="telefon" type="string" script="a.officePhone" unique="true" />
<attribute name="faks" type="string" script="a.fax" unique="true" />
<variable name="d" generator="DomainGenerator" dataset="US" locale="us"/>
<variable name="p" generator="PersonGenerator" dataset="RU" locale="ru"/>
<variable name="tag1" source="memstore" type="sgnMALE" distribution="random"/>
<variable name="tag2" source="memstore" type="sgnFEMALE" distribution="random"/>
<variable name="sgn" script="{js: (p.gender.name()=='MALE') ? sgnMALE : sgnFEMALE}"/>
<attribute name="email" type='string' script="{js:toLink(p.givenName+p.familyName)+'@'+d}" converter="ToLowerCaseConverter, UniqueStringConverter"/>
<attribute name="webpage" type='string' script="d" converter="ToLowerCaseConverter, UniqueStringConverter"/>
<attribute name="fio_ruk" type='string' script="p.familyName +' '+ p.givenName +' '+ sgn.secondgiven"/>
<attribute name="rschet" type='string' pattern="[0-9]{20}"/>
<attribute name="kschet" type='string' pattern="[0-9]{20}"/>
<attribute name="INN" type='string' pattern="[0-9]{10}"/>
<attribute name="KPP" type='string' pattern="[0-9]{9}"/>
<attribute name="date_update" type="datetime" generator="dtGen"/>
<attribute name="note" type='string' generator="new SeedSentenceGenerator('csv/notes.txt',3)" maxLength="255"/>
</generate>
<comment>[[POPULATE TABLE s_organization]] End. OK!</comment>
</setup>
Обратите внимание – структура схожа с «benerator.xml», однако не нужно описывать соединение с БД и подключение общих модулей, т.к. все это уже выполнено в основном файле конфигурации.
Заключение
Теперь, то почему я испытал «катарсис» – после стольких мучений все работало:
1. databene-benerator запускался и заполнял таблички данными, всего 2-3 ночи и вуаля удобный инструмент для решения насущной задачи!
2. Оказывается, русские символы, он понимает, и это мой косяк, что я мало знаком с синтаксисом обращения к jdbc-драйверу в Java-проектах (синтаксис универсальный) – еще 3 ночи и тоже все ровно!
3. Пошли алгоритмы заполнения таблиц один за другим, они сдавались под моим напором каждый вечер. И все 64 таблицы удалось заполнить еще за 6 вечеров.
Да есть еще много вопросов, но основные из них раскрыты, задача выполнена, знания получены, опыт приобретен. Для изменения количества и качества записей в таблицах мне не нужно их «лопатить» руками. Бенератор за несколько минут сделает свое дело.
В статье не рассмотрены:
1. генерация взаимосвязанных таблиц,
2. работа с датой и временем,
3. генерация вещественных чисел.
Однако эта информация есть в постах, на которые есть ссылки, а так же в документации. Так что после такого ускорения, читателю не составить много труда освоить и эти вопросы.
Специально для статьи зарегистрировался на github и выложил исходники, которые могут помочь разобраться с примерами. Для их использования достаточно скачать в виде *.zip архива, распаковать его. Создать новый проект и выполнить импорт в него «File->Import->General->FileSystem». Отметить весь проект и нажать «Finish». Не забудьте добавить «запускатор» и библиотеки бенератора.
Спасибо за внимание!
Используемые материалы
1. habrahabr.ru/post/169713. [В Интернете]
2. sysmagazine.com/posts/169713. [В Интернете]
3. ru.wikipedia.org/wiki/Катарсис. [В Интернете]
4. databene.org/download/databene-benerator-manual-0.8.1.pdf. [В Интернете]
5. dev.mysql.com/downloads/workbench. [В Интернете]
6. ajaxs.ru/lesson/javascript/137-transliteracija_stroki_na_javascript.html. [В Интернете]
