
Как и во многих других приложениях, нам в мобильном ICQ приходится хранить достаточно много информации: сообщения, контакты и тому подобное. Когда количество запросов к этим данным достигает какого-то критического значения, приложение начинает тормозить. Долгий запуск, медленное открытие чата, медленная отправка сообщений, постоянные спиннеры — все это жутко напрягает. Чаще всего причиной тормозов является неудачная работа с данными. В статье я хочу поделиться нашим опытом рефакторинга структуры данных, оптимизации запросов и некоторыми удобными приемами для миграции.
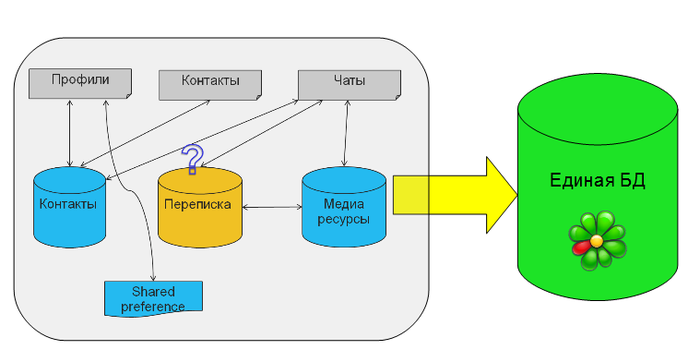
Несколько слов об исходной задаче. Основная сущность у нас — профиль ICQ, у которого есть список контактов, а у тех есть сообщения. Наше приложение существует уже много лет, разрабатывалось разными людьми с разными подходами, номер версии основной БД уверенно приближался к 30. Кроме того, количество фич в продукте невозможно предсказать заранее, это тоже повлияло на архитектуру. В общем, модель данных изначально была примерно такой:

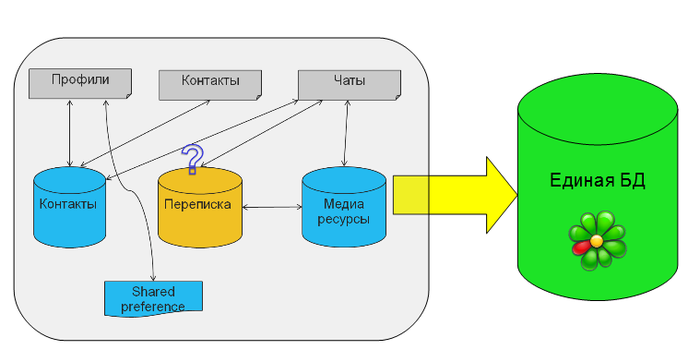
У нас было несколько файлов, где мы хранили в бинарном виде профили, контакты и список активных чатов. Переписка изначально хранилась в базе данных отдельно, для каждого профиля она была своя. В какой-то момент данные о контактах были перенесены в новую БД. Потом в приложение добавили поддержку медиа-сообщений: файлов, картинок и видео. [irony]Логично[/irony], для них создали отдельную БД. Кроме того, мы использовали кусочек shared preferences, где хранили критичные данные о нашем доступе к сети, чтобы не привязывать их к основным базам данных. Постепенно работа с файлами стала сильно напрягать. Представьте, у вас изменился один контакт, но вам все равно приходится сериализовывать и записывать в файл все контакты! Однажды мы решили, что в этой структуре больше невозможно разбираться и развивать ее, стали появляться проблемы синхронизации, например, когда нужно атомарно записать и в файл, и в базу (а транзакции недоступны!). Хотелось все данные поместить в единую БД и наслаждаться преимуществами реляционной структуры и СУБД. Для всех данных, кроме истории переписки, вопросов с хранением не было.
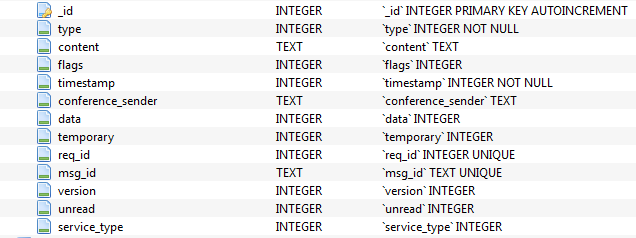
Это наша примерная таблица с сообщениями, отметим, что здесь два ключевых поля — text и integer:

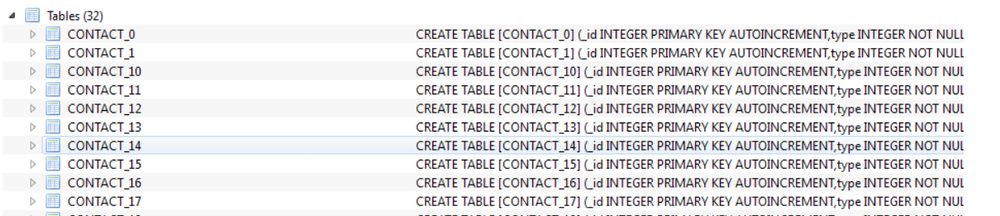
Мы выбирали между двумя вариантами хранения истории: для каждого контакта создавалась отдельная таблица со структурой выше, либо вся история велась в одной таблице, а информация о контакте была в отдельном ключевом поле. Соответственно, в первом варианте id контакта содержалось в имени таблицы. Примерно так:
Первый вариант довольно быстр, если мы много работаем с одним чатом, т.е. когда нужно читать и записывать сообщения для одного контакта. Однако приложение содержало много кода, который определяет, в какую именно таблицу нужно писать, какие индексы использовать, и поэтому показалось логичным перенести все это в одну большую таблицу. Но волновала проблема с производительностью. Если искать ответ на вопрос в интернете, как в таких ситуациях лучше хранить данные, то чаще всего ответы будут примерно такими: «Если у вас количество таблиц невелико и заранее известно, то лучше их разбить. Если вы часто обращаетесь к данным из разных таблиц, то лучше их объединить». Чтобы точно понять, какая структура лучше, мы написали небольшое тестовое приложение и сравнили скорость работы запросов. Рассмотрим пример из жизни. У пользователя 30 контактов, всего хранится 20000 сообщений. Активный пользователь отправляет в среднем около 30 сообщений в день и получает примерно в два раза больше. Итого 100 сообщений в день, то есть 20 тысяч — это примерно полугодовая переписка.
Создадим две базы данных: в одной данные раскиданы по разным таблицам, во второй — все хранится в одной таблице. Сразу после создания файлов мы увидим, что в первом случае размер нашей базы данных составляет почти 400 Кб, а во втором — всего 32 килобайта. Почему так происходит? Размер файла с базой данных всегда кратен некоторой величине — размеру странички. База данных хранит внутри себя данные постранично. Размер страницы может быть настроен в системе командой Pragma page_size, в Android по умолчанию это 4 килобайта. Мы экспериментировали с этим параметром, пытались его увеличивать и уменьшать. Максимальный размер странички согласно документации сейчас 64 килобайта, минимальный — 512 байт. Любые изменения этого параметра приводили к ухудшениям в каких-либо тестах. На самом деле, размер странички в каждой операционной системе оптимизирован под дисковые операции. Известно, что данные читаются по секторам, и такой размер странички лучше всего заточен под работу с диском. Более подробно о формате файла — в официальной документации.
После добавления тестовых данных размеры наших файлов в страницах подравнялись, но подход с кучей таблиц ожидаемо проигрывает.

Давайте рассмотрим варианты инсертов. Самый грубый вариант: сообщения добавляются в цикле безо всяких транзакций, в обоих случаях это займет неприличные 5,5 минут. Если же в нашем примере сгруппировать по 1000 записей в одну транзакцию, то затрачиваемое время существенно сократится. Что еще можно сделать, кроме транзакций? Когда вызываем метод insert() из класса SQLiteDatabase, то он внутри БД каждый раз создает prepared statement — скомпилированное SQL-выражение — и исполняет этот statement на каждый запрос. Это довольно накладно с точки зрения производительности. Поэтому SQL Statement, который мы используем для вставок, можно вынести наружу. Каждый раз нам нужно только наполнять его новыми данными. Если мы применим этот подход, то выиграем еще около 20%.
Чтобы получить еще больший прирост производительности, нам нужно немного повозиться с настройками БД. Небольшое техническое отступление на тему транзакций. Транзакция в БД должна обладать следующими свойствами: атомарность, консистентность, независимость, надежность (https://ru.wikipedia.org/wiki/ACID). Для поддержания всех этих свойств база данных не может записывать транзакции сразу непосредственно в файл с базой данных, на диск. Ей необходимо вести отдельную структуру — журнал транзакций. Это довольно мощный инструмент, который позволяет поддерживать указанные выше свойства транзакций.
В SQLite есть много интересных режимов ведения журнала транзакций, например, in-memory. В этом режиме журнал транзакций ведется непосредственно в памяти, и достигается колоссальная производительность базы данных. Но если случайно выключится питание, то данные будут потеряны. Более подробно о журналах транзакций.
Нам будут интересны два режима работы, при которых данные надежно сохраняются. Первый — режим по умолчанию в Android — journal_mode rollback. Если его настраивать через «pragma», то он задается как «journal_mode=delete». В этом случае база данных создает специальный файл db-journal. В него пишутся данные, необходимые для отката транзакции, если что-то пошло не так. А данные транзакции пишутся в основной файл БД. Если транзакция успешно завершена, то файл journal помечается специальным флагом, что он не используется. Нам важно, что в этом режиме база данных пишет сразу в два файла: файл отката и основной файл БД.
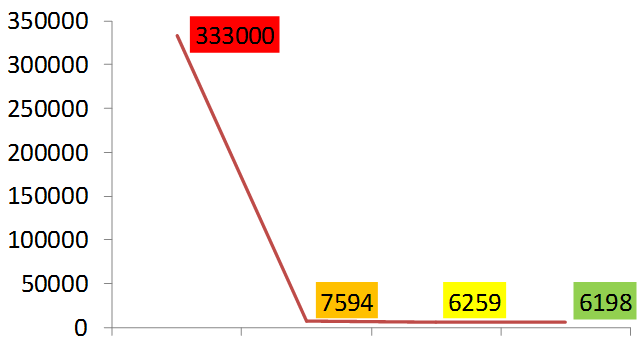
В SQLite версии 3.7 (это Android API 16) появился новый режим журнала транзакций, Write Ahead Logging. В этом режиме данные пишутся не в основной файл базы, а во временный, который называется db-wal. А чтобы приложение могло работать с ним так же, как с основной базой данных, создается файл с индексами — db-shm. Работает это примерно так. Данные транзакций пишутся во временный файл WAL, который имеет такую же страничную структуру. Когда количество страниц достигает какого-то порогового значения, данные из файла WAL переносятся в основную базу данных. Если в этот момент отключится питание, и данные не будут перенесены, то при следующем старте SQLite найдет этот файл и восстановит структуру. Что касается нашего теста, то при включении данного режима производительность еще вырастет. Здесь мы выигрываем немного, потому что у нас всего 20 транзакций. Но если их много, то в разных тестах ускорение может достигать 40%. Поэтому использование wal на новых моделях гаджетов будет хорошим решением.
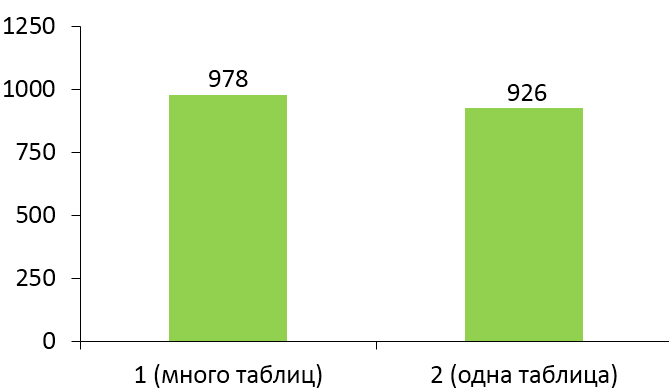
На графике ниже показано, насколько мы ускорили вставки записей.
Давайте рассмотрим выборку данных. Для нашего приложения это, пожалуй, важнее, поскольку приложения чаще всего именно читает данные. Здесь я расскажу довольно очевидные вещи, которые наверняка использует большинство из вас. Тем не менее, для многих приложений это все еще актуально. Во-первых, необходимо использовать индексы. Это специальная структура, хранящаяся отдельно от таблицы, сопоставляющая данные по некоторому ключу с записью в основной таблице. При использовании индекса СУБД вместо полного сканирования всей таблицы сперва ищет id искомых записей в индексе по ключевому полю за O(log N), а потом точечно читает нужные данные из таблицы.
Однако даже при использовании индексов еще много чего можно ускорить. Рассмотрим такой пример: при запуске приложения нужно прочитать для каждого контакта по одному сообщению, чтобы отобразить чаты. Если просто считывать в цикле каждое сообщение, то, к примеру, при 100 итерациях общее время чтения составит примерно 5-6 секунд. Вместо отдельных запросов лучше сгруппировать искомые ключи в один запрос. Например, мы можем использовать конструкцию where in и передавать список id. Однако самый эффективный вариант — это чтение данных из самого индекса. В индексах можно хранить не одно поле, а несколько. Такие индексы называются составными. Это несколько замедляет вставки, но зато при выборке полей, из которых состоит индекс, БД будет читать не две структуры — индекс и основной файл, — а лишь индекс. Если доставать данные по ID, которые уже лежат в индексе, то можно получить существенное ускорение.
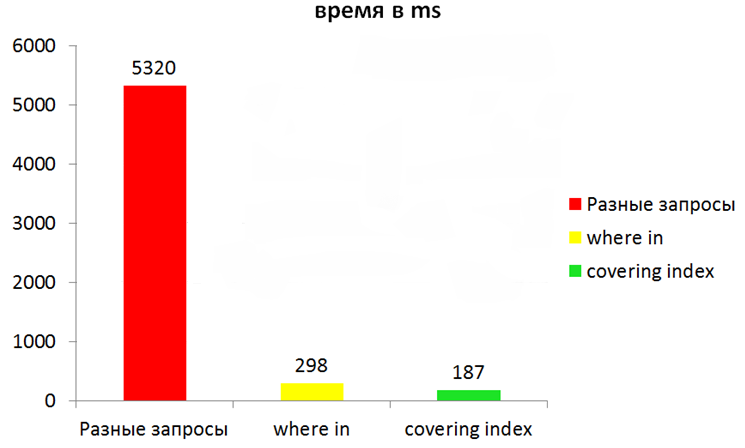
Казалось бы, хороший результат, но если включить wal, то при определенных условиях можно еще больше ускорить приложение. Причина в том, что в этом режиме задействуются отдельные каналы данных для записи и чтения (запись не блокирует чтение: www.sqlite.org/wal.html).
Нельзя не упомянуть про очень удобный инструмент для отладки запросов. В SQLite есть команда «explain query plan». Рассмотрим пример этой команды.

При исполнении данного запроса DB Browser показывает, что именно делает СУБД при выполнении SQL-запроса. В данном случае мы видим, что SQLite производит поиск по индексу (using covering index). Эта команда может вернуть нам четыре разных результата:
Повторюсь: каждый запрос, который вы хотите оптимизировать, желательно прогонять с помощью «explain query plan» и смотреть, что именно делает база данных. Перейдем теперь к миграции: необходимо перенести громоздкую структуру в единую базу так, чтобы не потерять данные.
Вероятно, многие пользуются классом SQLiteOpenHelper, который позволяет отследить изменение версии базы данных и в методе onUpgrade выполнить код, меняющий вашу структуру. Надо сказать, что этот метод вызывается внутри одной транзакции. Если вы попытаетесь в методе onUpgrade копировать данные или выполнять какие-либо сложные действия, которые могут кинуть исключения, вы рискуете не обновить ничего. Рекомендую использовать этот метод только для изменения структуры. А для переноса самих данных лучше вызывать отдельный метод.
Кстати, в одном из апгрейдов у нас была досадная ошибка. Мы использовали константы в SQL-коде, и в какой-то момент константы поменялись. А версии приложения, с которых мы попытались апгрейдить структуру, естественно, работали со старыми именами таблиц и полей. При этом у нас в коде все работало в текущем апгрейде с прошлой версии, а в апгрейде с позапрошлой версии — нет, ведь мы поменяли константу, и было совершенно неочевидно, где искать ошибку. Поэтому мы решили больше вообще не использовать константы в SQL-запросах.
После того как мы обновили структуру БД, нам необходимо было скопировать кучу записей из разных старых баз. Самое простое решение — прочитать все старые данные в курсор, распарсить каждую запись и добавить в новую базу, но это жутко медленно. Если у нас большая история переписки, десятки тысяч сообщений, то этот процесс занимает несколько секунд. Пользователь начнет скучать, может подумать, что приложение повисло и, в худшем случае, откажется от него совсем. Поэтому нам важно было ускорить эту процедуру. Оказалось, что в SQLite есть очень удобная команда «Attach database», которая позволяет подключать к вашей базе сторонние БД. Чтобы обратиться к таблицам из присоединенных баз, нужно всего лишь дописать имя базы к имени таблицы. Таким образом, можно для миграции без всякого парсинга использовать средства SQLite.
У этого подхода есть некоторые ограничения. Сама команда Attach database, которая является расширением SQLite, не работает внутри транзакции, поэтому в рамках метода onUpgrade вызвать ее не получится. Кроме того, транзакции в рамках Attach database работают только при запросах к одной БД. В нашем варианте, когда нужно было несколько баз данных слить в одну, приходилось работу с каждой базой выносить в транзакцию. Но зато это работает существенно быстрее курсоров, мы могли аккуратно перенести все данные меньше чем за секунду!
Также после апгрейда самое время задуматься о том, чтобы включить эффективные режимы работы с базой данных, WAL, например. Если ваше приложение поддерживает старый API, то нужно проверить, что текущий API выше версии 16.
Еще полезно будет провести некоторую дефрагментацию данных внутри базы. В SQLite есть очень удобная команда Vacuum, она позволяет удалить все неиспользуемые страницы и дефрагментировать данные. Не секрет, что если просто выполнить команду delete, то физически данные с диска не удалятся, а записи или целые страницы будут помечены как удаленные. Эта команда позволяет удалить неиспользуемые фрагменты и перестроить индексы.
Итак, в данной статье мы рассмотрели некоторые подходы к оптимизации БД на примере мобильного приложения ICQ. Безусловно, почти все рекомендации можно найти на www.sqlite.org и других тематических ресурсах, но решение конкретной задачи позволяет лучше всего понять, что именно происходит в недрах СУБД.
Несколько слов об исходной задаче. Основная сущность у нас — профиль ICQ, у которого есть список контактов, а у тех есть сообщения. Наше приложение существует уже много лет, разрабатывалось разными людьми с разными подходами, номер версии основной БД уверенно приближался к 30. Кроме того, количество фич в продукте невозможно предсказать заранее, это тоже повлияло на архитектуру. В общем, модель данных изначально была примерно такой:
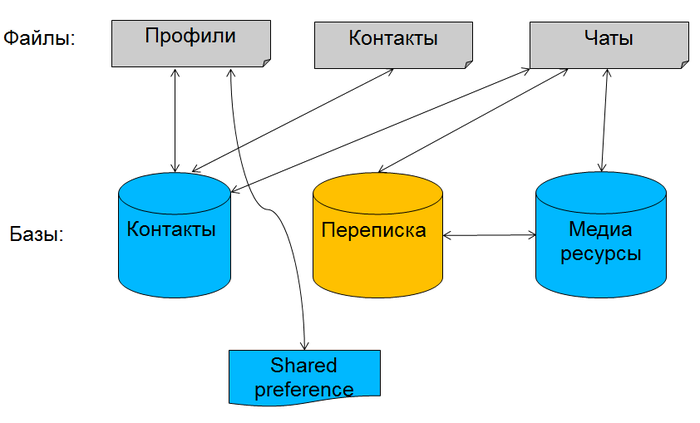
У нас было несколько файлов, где мы хранили в бинарном виде профили, контакты и список активных чатов. Переписка изначально хранилась в базе данных отдельно, для каждого профиля она была своя. В какой-то момент данные о контактах были перенесены в новую БД. Потом в приложение добавили поддержку медиа-сообщений: файлов, картинок и видео. [irony]Логично[/irony], для них создали отдельную БД. Кроме того, мы использовали кусочек shared preferences, где хранили критичные данные о нашем доступе к сети, чтобы не привязывать их к основным базам данных. Постепенно работа с файлами стала сильно напрягать. Представьте, у вас изменился один контакт, но вам все равно приходится сериализовывать и записывать в файл все контакты! Однажды мы решили, что в этой структуре больше невозможно разбираться и развивать ее, стали появляться проблемы синхронизации, например, когда нужно атомарно записать и в файл, и в базу (а транзакции недоступны!). Хотелось все данные поместить в единую БД и наслаждаться преимуществами реляционной структуры и СУБД. Для всех данных, кроме истории переписки, вопросов с хранением не было.
Это наша примерная таблица с сообщениями, отметим, что здесь два ключевых поля — text и integer:
Мы выбирали между двумя вариантами хранения истории: для каждого контакта создавалась отдельная таблица со структурой выше, либо вся история велась в одной таблице, а информация о контакте была в отдельном ключевом поле. Соответственно, в первом варианте id контакта содержалось в имени таблицы. Примерно так:
Первый вариант довольно быстр, если мы много работаем с одним чатом, т.е. когда нужно читать и записывать сообщения для одного контакта. Однако приложение содержало много кода, который определяет, в какую именно таблицу нужно писать, какие индексы использовать, и поэтому показалось логичным перенести все это в одну большую таблицу. Но волновала проблема с производительностью. Если искать ответ на вопрос в интернете, как в таких ситуациях лучше хранить данные, то чаще всего ответы будут примерно такими: «Если у вас количество таблиц невелико и заранее известно, то лучше их разбить. Если вы часто обращаетесь к данным из разных таблиц, то лучше их объединить». Чтобы точно понять, какая структура лучше, мы написали небольшое тестовое приложение и сравнили скорость работы запросов. Рассмотрим пример из жизни. У пользователя 30 контактов, всего хранится 20000 сообщений. Активный пользователь отправляет в среднем около 30 сообщений в день и получает примерно в два раза больше. Итого 100 сообщений в день, то есть 20 тысяч — это примерно полугодовая переписка.
Создадим две базы данных: в одной данные раскиданы по разным таблицам, во второй — все хранится в одной таблице. Сразу после создания файлов мы увидим, что в первом случае размер нашей базы данных составляет почти 400 Кб, а во втором — всего 32 килобайта. Почему так происходит? Размер файла с базой данных всегда кратен некоторой величине — размеру странички. База данных хранит внутри себя данные постранично. Размер страницы может быть настроен в системе командой Pragma page_size, в Android по умолчанию это 4 килобайта. Мы экспериментировали с этим параметром, пытались его увеличивать и уменьшать. Максимальный размер странички согласно документации сейчас 64 килобайта, минимальный — 512 байт. Любые изменения этого параметра приводили к ухудшениям в каких-либо тестах. На самом деле, размер странички в каждой операционной системе оптимизирован под дисковые операции. Известно, что данные читаются по секторам, и такой размер странички лучше всего заточен под работу с диском. Более подробно о формате файла — в официальной документации.
После добавления тестовых данных размеры наших файлов в страницах подравнялись, но подход с кучей таблиц ожидаемо проигрывает.
Оптимизация вставок
Давайте рассмотрим варианты инсертов. Самый грубый вариант: сообщения добавляются в цикле безо всяких транзакций, в обоих случаях это займет неприличные 5,5 минут. Если же в нашем примере сгруппировать по 1000 записей в одну транзакцию, то затрачиваемое время существенно сократится. Что еще можно сделать, кроме транзакций? Когда вызываем метод insert() из класса SQLiteDatabase, то он внутри БД каждый раз создает prepared statement — скомпилированное SQL-выражение — и исполняет этот statement на каждый запрос. Это довольно накладно с точки зрения производительности. Поэтому SQL Statement, который мы используем для вставок, можно вынести наружу. Каждый раз нам нужно только наполнять его новыми данными. Если мы применим этот подход, то выиграем еще около 20%.
Чтобы получить еще больший прирост производительности, нам нужно немного повозиться с настройками БД. Небольшое техническое отступление на тему транзакций. Транзакция в БД должна обладать следующими свойствами: атомарность, консистентность, независимость, надежность (https://ru.wikipedia.org/wiki/ACID). Для поддержания всех этих свойств база данных не может записывать транзакции сразу непосредственно в файл с базой данных, на диск. Ей необходимо вести отдельную структуру — журнал транзакций. Это довольно мощный инструмент, который позволяет поддерживать указанные выше свойства транзакций.
В SQLite есть много интересных режимов ведения журнала транзакций, например, in-memory. В этом режиме журнал транзакций ведется непосредственно в памяти, и достигается колоссальная производительность базы данных. Но если случайно выключится питание, то данные будут потеряны. Более подробно о журналах транзакций.
Нам будут интересны два режима работы, при которых данные надежно сохраняются. Первый — режим по умолчанию в Android — journal_mode rollback. Если его настраивать через «pragma», то он задается как «journal_mode=delete». В этом случае база данных создает специальный файл db-journal. В него пишутся данные, необходимые для отката транзакции, если что-то пошло не так. А данные транзакции пишутся в основной файл БД. Если транзакция успешно завершена, то файл journal помечается специальным флагом, что он не используется. Нам важно, что в этом режиме база данных пишет сразу в два файла: файл отката и основной файл БД.
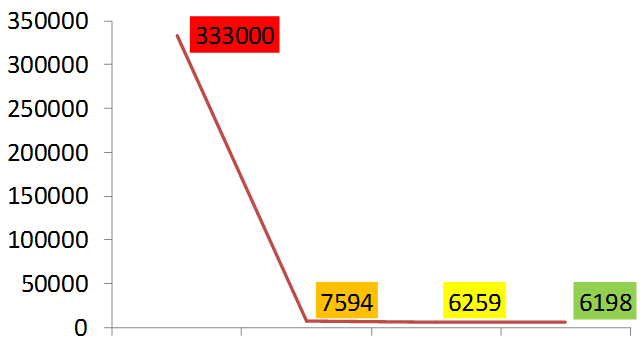
В SQLite версии 3.7 (это Android API 16) появился новый режим журнала транзакций, Write Ahead Logging. В этом режиме данные пишутся не в основной файл базы, а во временный, который называется db-wal. А чтобы приложение могло работать с ним так же, как с основной базой данных, создается файл с индексами — db-shm. Работает это примерно так. Данные транзакций пишутся во временный файл WAL, который имеет такую же страничную структуру. Когда количество страниц достигает какого-то порогового значения, данные из файла WAL переносятся в основную базу данных. Если в этот момент отключится питание, и данные не будут перенесены, то при следующем старте SQLite найдет этот файл и восстановит структуру. Что касается нашего теста, то при включении данного режима производительность еще вырастет. Здесь мы выигрываем немного, потому что у нас всего 20 транзакций. Но если их много, то в разных тестах ускорение может достигать 40%. Поэтому использование wal на новых моделях гаджетов будет хорошим решением.
На графике ниже показано, насколько мы ускорили вставки записей.
Оптимизация выборки
Давайте рассмотрим выборку данных. Для нашего приложения это, пожалуй, важнее, поскольку приложения чаще всего именно читает данные. Здесь я расскажу довольно очевидные вещи, которые наверняка использует большинство из вас. Тем не менее, для многих приложений это все еще актуально. Во-первых, необходимо использовать индексы. Это специальная структура, хранящаяся отдельно от таблицы, сопоставляющая данные по некоторому ключу с записью в основной таблице. При использовании индекса СУБД вместо полного сканирования всей таблицы сперва ищет id искомых записей в индексе по ключевому полю за O(log N), а потом точечно читает нужные данные из таблицы.
Однако даже при использовании индексов еще много чего можно ускорить. Рассмотрим такой пример: при запуске приложения нужно прочитать для каждого контакта по одному сообщению, чтобы отобразить чаты. Если просто считывать в цикле каждое сообщение, то, к примеру, при 100 итерациях общее время чтения составит примерно 5-6 секунд. Вместо отдельных запросов лучше сгруппировать искомые ключи в один запрос. Например, мы можем использовать конструкцию where in и передавать список id. Однако самый эффективный вариант — это чтение данных из самого индекса. В индексах можно хранить не одно поле, а несколько. Такие индексы называются составными. Это несколько замедляет вставки, но зато при выборке полей, из которых состоит индекс, БД будет читать не две структуры — индекс и основной файл, — а лишь индекс. Если доставать данные по ID, которые уже лежат в индексе, то можно получить существенное ускорение.
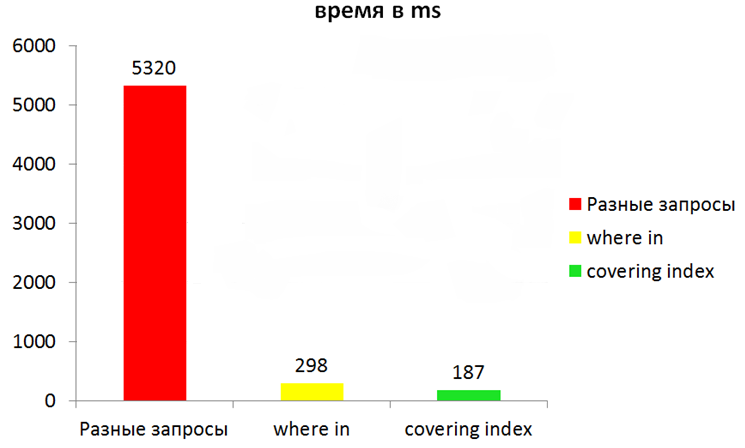
Казалось бы, хороший результат, но если включить wal, то при определенных условиях можно еще больше ускорить приложение. Причина в том, что в этом режиме задействуются отдельные каналы данных для записи и чтения (запись не блокирует чтение: www.sqlite.org/wal.html).
Нельзя не упомянуть про очень удобный инструмент для отладки запросов. В SQLite есть команда «explain query plan». Рассмотрим пример этой команды.
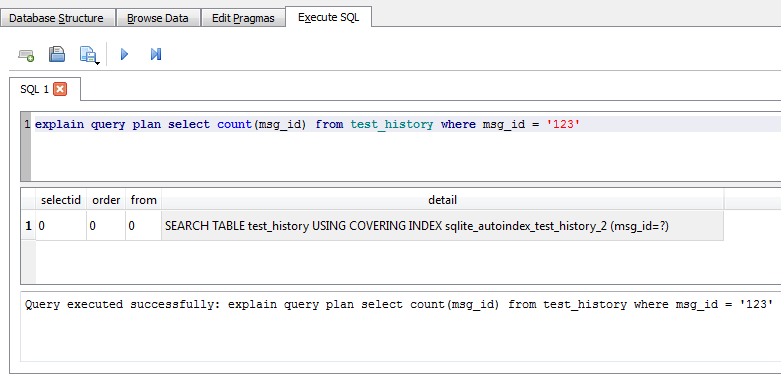
При исполнении данного запроса DB Browser показывает, что именно делает СУБД при выполнении SQL-запроса. В данном случае мы видим, что SQLite производит поиск по индексу (using covering index). Эта команда может вернуть нам четыре разных результата:
- scan table — база данных будет полнотекстовым поиском перебирать каждую запись и искать соответствие, это самый неэффективный вариант;
- search table using index — существует нужный индекс для поиска записей, но искомые данные не включены в него;
- search table using covering index — самый эффективный случай, искомые данные уже лежат в индексе;
- use temp B-TREE — если мы используем в запросе конструкции типа group by, order by, и по этому полю индекса нет, то чаще всего база данных должна сделать следующее: достать все записи, которые удовлетворяют критерию, и построить в памяти дерево для сортировки этих данных. Обычно это медленный процесс. Если вам нужно что-то группировать или упорядочивать, то на это поле лучше тоже держать индекс.
Повторюсь: каждый запрос, который вы хотите оптимизировать, желательно прогонять с помощью «explain query plan» и смотреть, что именно делает база данных. Перейдем теперь к миграции: необходимо перенести громоздкую структуру в единую базу так, чтобы не потерять данные.
Вероятно, многие пользуются классом SQLiteOpenHelper, который позволяет отследить изменение версии базы данных и в методе onUpgrade выполнить код, меняющий вашу структуру. Надо сказать, что этот метод вызывается внутри одной транзакции. Если вы попытаетесь в методе onUpgrade копировать данные или выполнять какие-либо сложные действия, которые могут кинуть исключения, вы рискуете не обновить ничего. Рекомендую использовать этот метод только для изменения структуры. А для переноса самих данных лучше вызывать отдельный метод.
Кстати, в одном из апгрейдов у нас была досадная ошибка. Мы использовали константы в SQL-коде, и в какой-то момент константы поменялись. А версии приложения, с которых мы попытались апгрейдить структуру, естественно, работали со старыми именами таблиц и полей. При этом у нас в коде все работало в текущем апгрейде с прошлой версии, а в апгрейде с позапрошлой версии — нет, ведь мы поменяли константу, и было совершенно неочевидно, где искать ошибку. Поэтому мы решили больше вообще не использовать константы в SQL-запросах.
После того как мы обновили структуру БД, нам необходимо было скопировать кучу записей из разных старых баз. Самое простое решение — прочитать все старые данные в курсор, распарсить каждую запись и добавить в новую базу, но это жутко медленно. Если у нас большая история переписки, десятки тысяч сообщений, то этот процесс занимает несколько секунд. Пользователь начнет скучать, может подумать, что приложение повисло и, в худшем случае, откажется от него совсем. Поэтому нам важно было ускорить эту процедуру. Оказалось, что в SQLite есть очень удобная команда «Attach database», которая позволяет подключать к вашей базе сторонние БД. Чтобы обратиться к таблицам из присоединенных баз, нужно всего лишь дописать имя базы к имени таблицы. Таким образом, можно для миграции без всякого парсинга использовать средства SQLite.
У этого подхода есть некоторые ограничения. Сама команда Attach database, которая является расширением SQLite, не работает внутри транзакции, поэтому в рамках метода onUpgrade вызвать ее не получится. Кроме того, транзакции в рамках Attach database работают только при запросах к одной БД. В нашем варианте, когда нужно было несколько баз данных слить в одну, приходилось работу с каждой базой выносить в транзакцию. Но зато это работает существенно быстрее курсоров, мы могли аккуратно перенести все данные меньше чем за секунду!
Также после апгрейда самое время задуматься о том, чтобы включить эффективные режимы работы с базой данных, WAL, например. Если ваше приложение поддерживает старый API, то нужно проверить, что текущий API выше версии 16.
Еще полезно будет провести некоторую дефрагментацию данных внутри базы. В SQLite есть очень удобная команда Vacuum, она позволяет удалить все неиспользуемые страницы и дефрагментировать данные. Не секрет, что если просто выполнить команду delete, то физически данные с диска не удалятся, а записи или целые страницы будут помечены как удаленные. Эта команда позволяет удалить неиспользуемые фрагменты и перестроить индексы.
Заключение
Итак, в данной статье мы рассмотрели некоторые подходы к оптимизации БД на примере мобильного приложения ICQ. Безусловно, почти все рекомендации можно найти на www.sqlite.org и других тематических ресурсах, но решение конкретной задачи позволяет лучше всего понять, что именно происходит в недрах СУБД.
