 В этой статье мы описываем простую методику оптимизации с использованием Intel Cilk Plus и компилятора Intel C++ на основе результатов анализа производительности, проведенного с помощью Intel VTune Amplifier. Intel System Studio 2015 содержит упомянутые компоненты, использованные для этой статьи.
В этой статье мы описываем простую методику оптимизации с использованием Intel Cilk Plus и компилятора Intel C++ на основе результатов анализа производительности, проведенного с помощью Intel VTune Amplifier. Intel System Studio 2015 содержит упомянутые компоненты, использованные для этой статьи.• Intel VTune Amplifier — интегрированный инструмент для анализа производительности, помогает разработчикам анализировать сложный код и быстро обнаруживать узкие места.
• Компилятор Intel C++ создает оптимизированный код для архитектур IA-32 и Intel 64. Также предоставляются различные возможности, помогающие разработчикам повышать производительность своих программ.
• Intel Cilk Plus — это расширение языка C/C++, входящее в состав компилятора Intel C++, позволяет повышать производительность за счет распараллеливания новых или существующих программ на языке C или C++.
Примечание редакцииВ этом посте автор использует для профилирования дебажную версию приложения, что не совсем правильно, поскольку в данной версии совершенно отсутствуют оптимизации компилятора. После автоматической оптимизации профиль приложения существенно изменится, и сначала нужно делать именно ее. Тем не менее, с точки зрения методологии весь процесс описан верно, поэтому мы решили опубликовать этот пост.
Оригинал исправлен и перевод тоже.
Оригинал исправлен и перевод тоже.
Стратегия
Мы используем один из примеров кода в учебном руководстве по VTune, tachyon_amp_xe, в качестве целевого кода для повышения производительности. Этот пример выводит изображение сложных объектов.
Методика оптимизации производительности, применимая к этому примеру, описана ниже.
- Запуск простого анализа узких мест или общего анализа для примера проекта в интегрированной среде разработки, например в Visual Studio* 2013.
- Выявление узких мест и других возможностей для оптимизации.
- Применение изменений кода к обнаруженным узким местам.
- Изучение возможностей оптимизации в компиляторе.
- Распараллеливание кода.
Оптимизация
Тестовая среда
ОС: Windows 8.1
Набор инструментов: Intel System Studio для Windows, обновление 3
Среда разработки: Microsoft Visual Studio 2013
Шаг 1. Интерпретация и анализ данных результатов
Запуск общего анализа (если это невозможно, перейдите к простому анализу узких мест) и обнаружение узких мест. Этот пример кода создан как пример для обнаружения узких мест и повышения производительности. Поэтому для работы с ним можно использовать страницу примера the tachyon_amp_ex. После запуска примера в VTune мы получим следующие результаты.
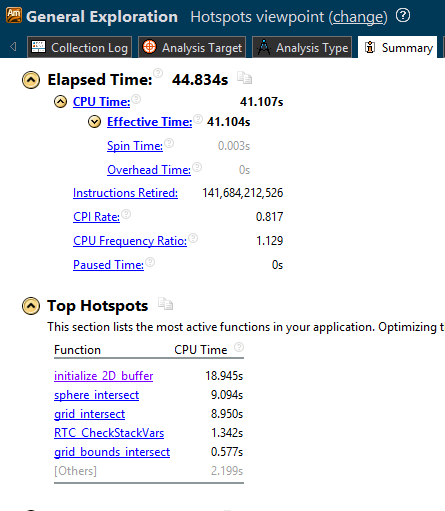
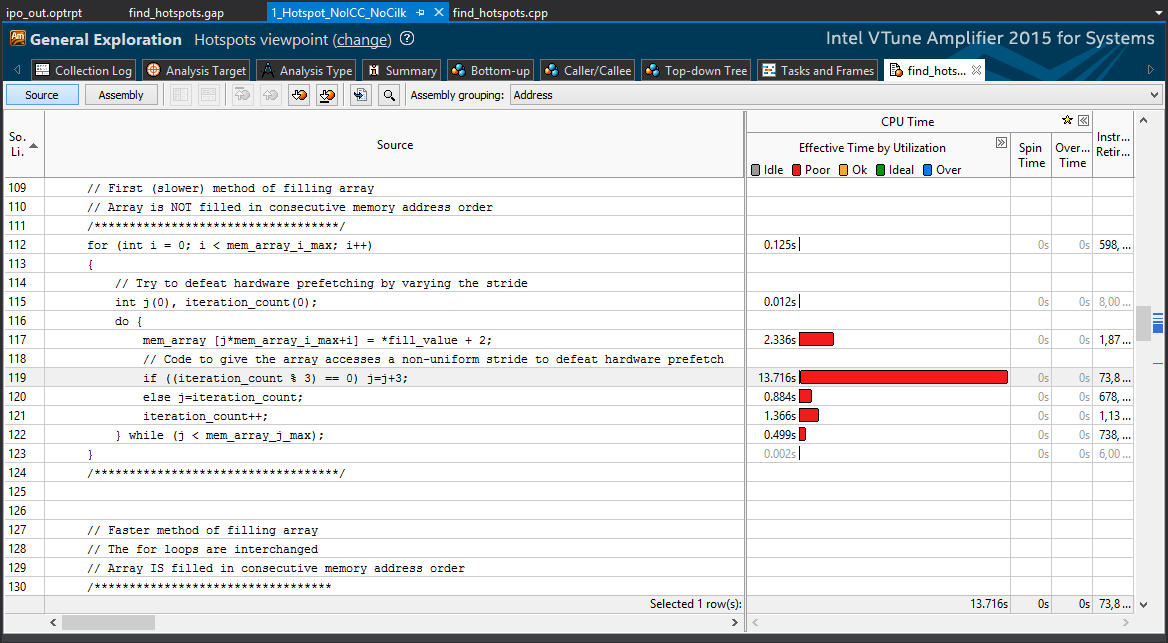
Видно, что время, затраченное этим приложением, составило 44,834 секунды, и этот базовый уровень производительности мы попытаемся улучшить.
Кроме того, в этом примере приложения функция initialize_2D_buffer расходует больше всего времени — 18,945 секунды, поэтому она занимает верхнюю строку в списке ресурсоемких функций. Мы попробуем оптимизировать именно эту функцию, занимающую больше всего времени.
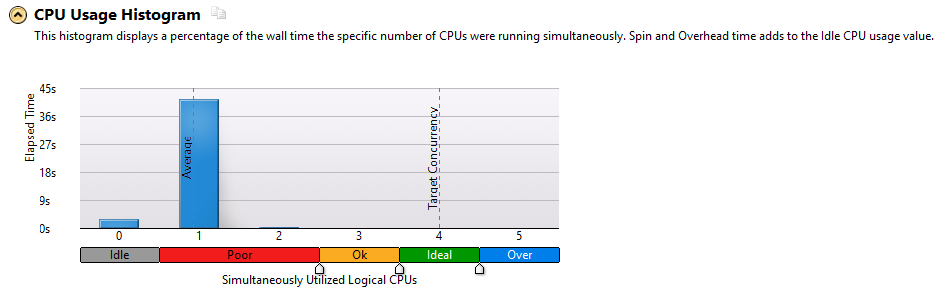
Гистограмма нагрузки на ЦП, приведенная выше, показывает, что в этом примере не используется параллельная обработка. Поэтому есть возможность использовать многопоточную архитектуру для ускорения обработки ресурсоемких задач.
Шаг 2. Алгоритмический подход для функции initialize_2D_buffer
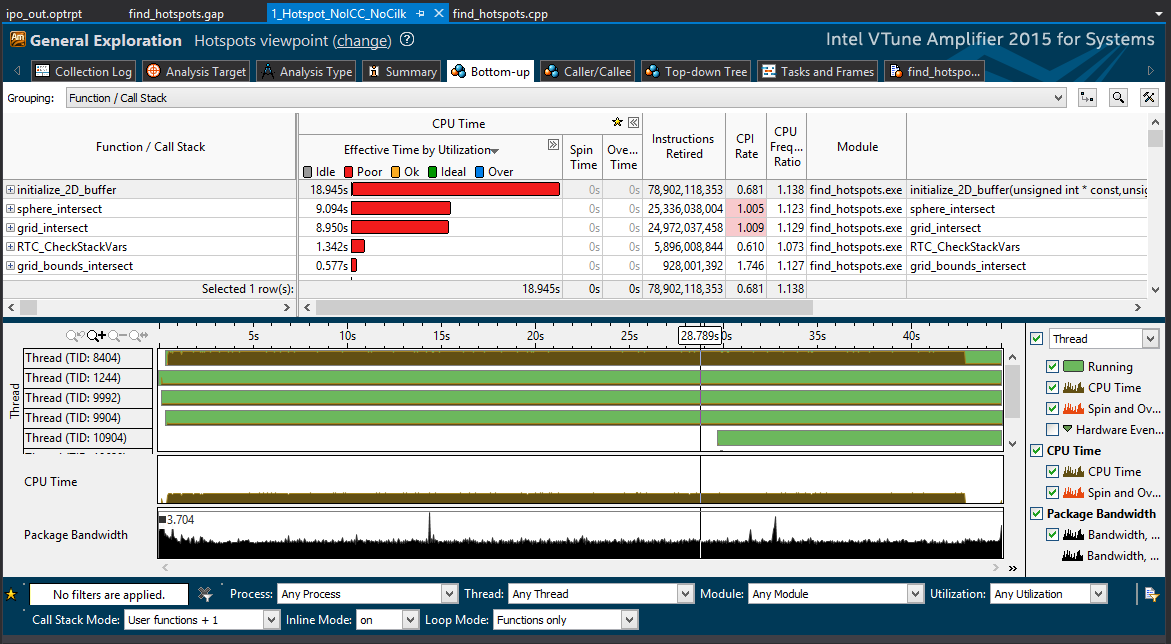
Как мы видели, выполнение функции initialize_2D_buffer занимает больше всего времени, причем эта функция задействует наибольшее количество инструкций. Из этого следует, что если где-то и можно добиться повышения производительности, то именно здесь эффект будет наибольшим.
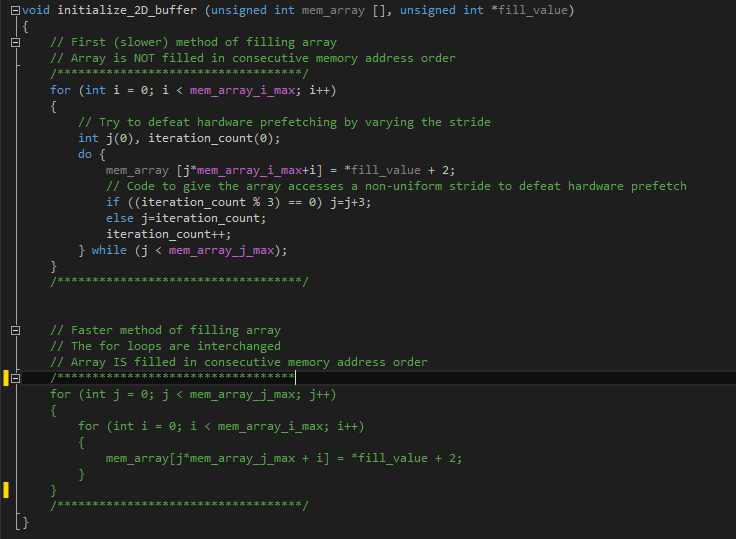
Дважды щелкните имя функции. VTune Amplifier откроет файл с исходным кодом именно на той строке, где на работу этой функции затрачивается больше всего времени. Для функции initialize_2D_buffer эта строка служит для инициализации массива памяти с помощью разрозненных расположений в памяти (находящихся не подряд). У этого примера кода уже есть более быстрая альтернатива циклу for.
Ниже приведен фактический код функции initialize_2D_buffer. Первый цикл for заполняет целевой массив непоследовательно, тогда как второй цикл for выполняет эту же задачу последовательно. Можно повысить производительность, задействовав второй цикл for.
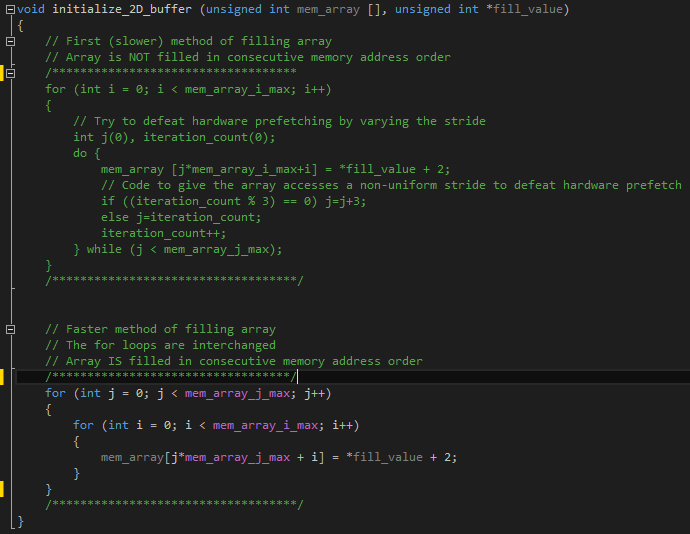
После замены цикла for на второй мы отмечаем некоторый прирост производительности. Рассмотрим новые результаты профилирования в VTune.
По сравнению с прежним результатом общее время выполнения снизилось с 44,834 до 35,742 секунды, то есть примерно в 1,25 раза. Время работы нашей целевой функции сократилось с 18,945 до 11,318 секунды, то есть примерно в 1,67 раза.
Шаг 3. Возможности оптимизации компилятора
Мы зачастую упускаем из вида возможности автоматической оптимизации, доступные в компиляторах. В этом случае мы просто включаем встроенную оптимизацию компилятора Intel C++, указав параметр /O3 при компиляции. Это же можно сделать и с помощью графического пользовательского интерфейса. Чтобы использовать параметр «/O3», нужно сначала установить компилятор Intel C++ в качестве компилятора по умолчанию для данного проекта.
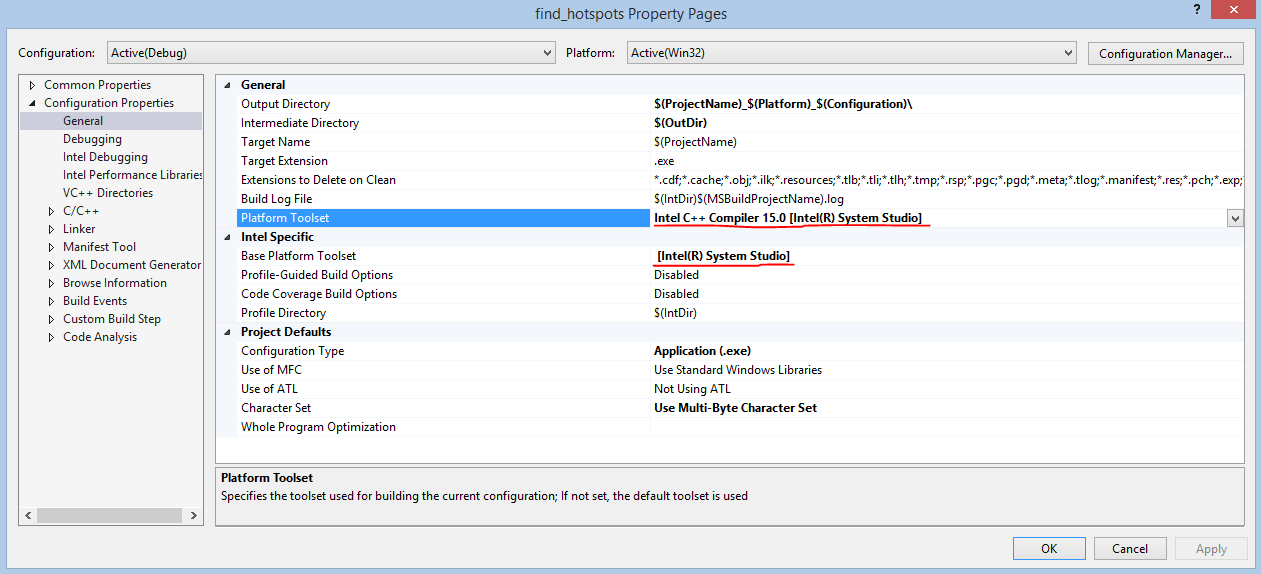
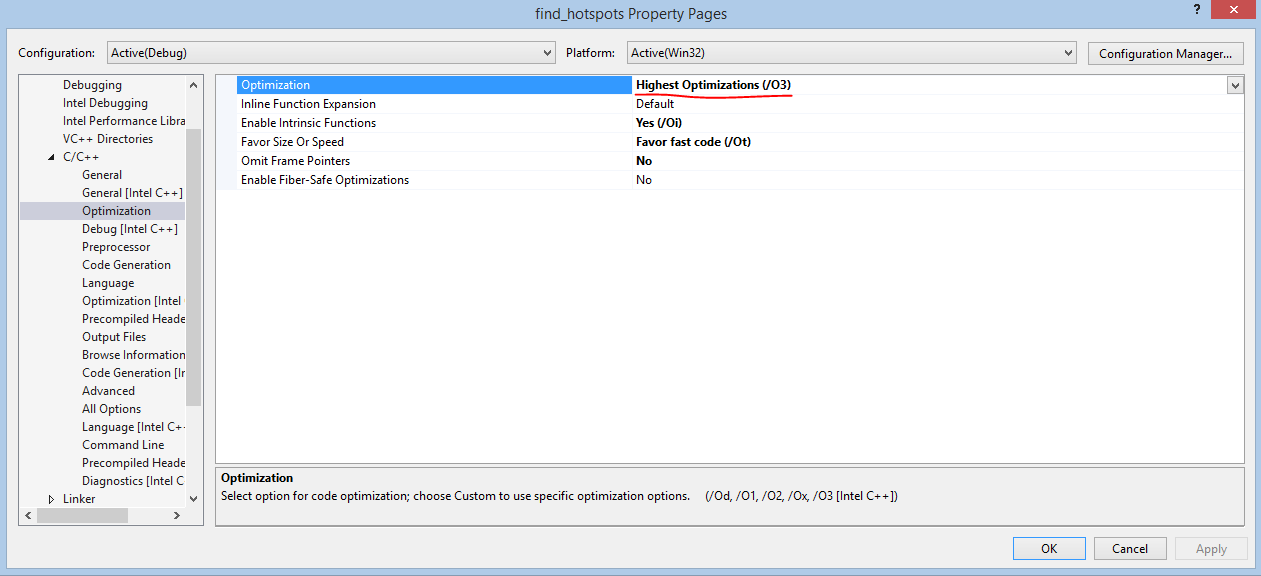
Одного лишь добавления этого параметра иногда бывает достаточно для существенного повышения производительности. Подробные сведения о параметре оптимизации /O[n] см. здесь. Новые результаты: для выполнения задачи достаточно 24,979 секунды. Прежде нужно было 35,742 секунды, то есть теперь программа работает в 1,43 раза быстрее.
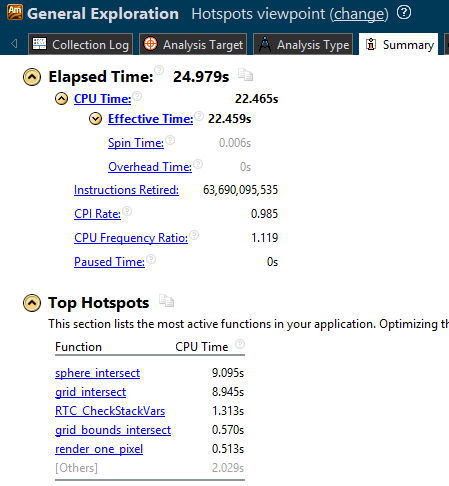
Шаг 4. Распараллеливание с помощью Cilk Plus
Само по себе параллельное программирование — достаточно обширная область. Существует множество способов реализации параллельных вычислений в системе, рассчитанных на работу на многоядерных платформах. На этот раз мы используем Intel Cilk Plus — это довольно простое расширение языка, которое очень неплохо работает.
При изучении и анализе кода с использованием результатов VTune мы можем найти точку, в которой код многократно вызывает самую ресурсоемкую процедуру. Именно здесь наибольший потенциал для распараллеливания. Обычно это делается так: изучаем дерево вызывающих и вызываемых объектов и возвращаемся к исходному узкому месту до обнаружения фрагмента, пригодного для распараллеливания.
На этот раз мы просто будем работать с функцией draw_trace в файле find_hotspots.cpp. Достаточно просто добавить cilk_for для распараллеливания нужной нам задачи: вместо одного потока будет задействовано несколько. После этого наглядно видна работа четырех потоков (код тестировался на двухъядерном процессоре с технологией гипертрединга), одновременно рисующих разные линии.
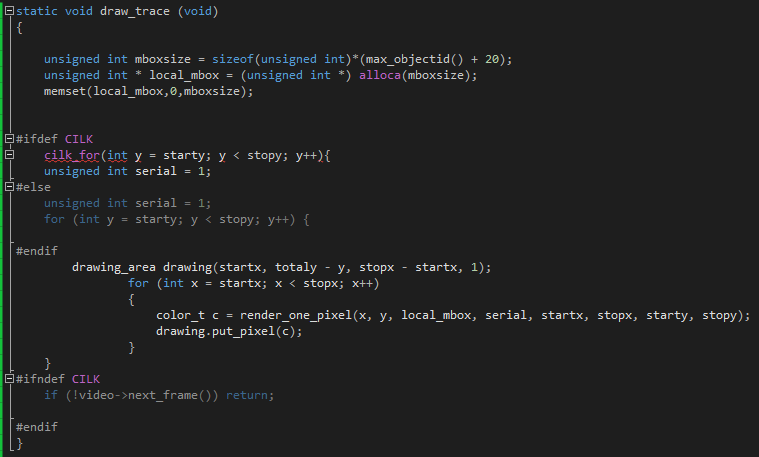

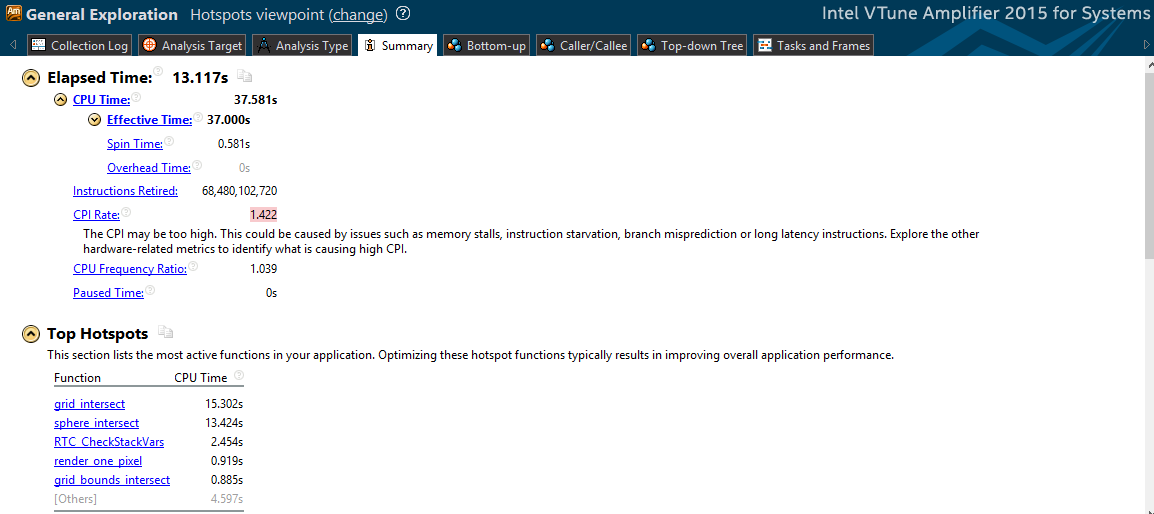
Теперь для завершения работы достаточно 11,656 секунды, что значительно лучше первоначального времени. Рассмотрим результаты VTune.
Общее время работы составляет 13,117 секунды, то есть в 1,9 раза быстрее, чем раньше. Мы видим, что многоядерная архитектура эффективно используется.
Заключение
Время работы всей программы снизилось с 44,834 до 13,117 секунды, то есть в 3,41 раза.
Такого уровня оптимизации удалось достичь всего лишь с помощью простого анализа в VTune, добавления параметра компилятора Intel C++ и применения Cilk Plus.
Компоненты Intel System Studio помогают разработчикам без особых усилий существенно улучшать свои программы.
