В рамках ICBDA 2015 Сбербанк проводил конкурс про предсказание оттока своих клиентов. Я неслабо заморочился по этому поводу, ничего не выиграл и тем не менее хотел бы описать процесс решения.
Сбербанк щедро отгрузил данных. Нам дали ~20 000 пользователей, про которых было известно попали они в отток в ноябре, декабре, январе или нет. И было ~30 000 пользователей, для которых нужно было угадать уйдут ли они в феврале. Кроме этого прилагался файлик на 35Гб примерно такого содержания:
Физический смысл полей специально не раскрывался. Сказали «так интереснее». Было известно только, где искать id пользователей. Такой расклад показался мне крайне странным. Впрочем, Сбербанк тоже можно понять. Для начала этот адский массив данных я решил оставить в стороне и подробнее изучить пользователей из обучающего и тестового наборов.
Выяснилось невероятное: если пользователь не ушёл в ноябре и декабре, то и в январе он скорее всего не уйдёт. Если пользователь ушёл, то он скорее всего не вернётся:
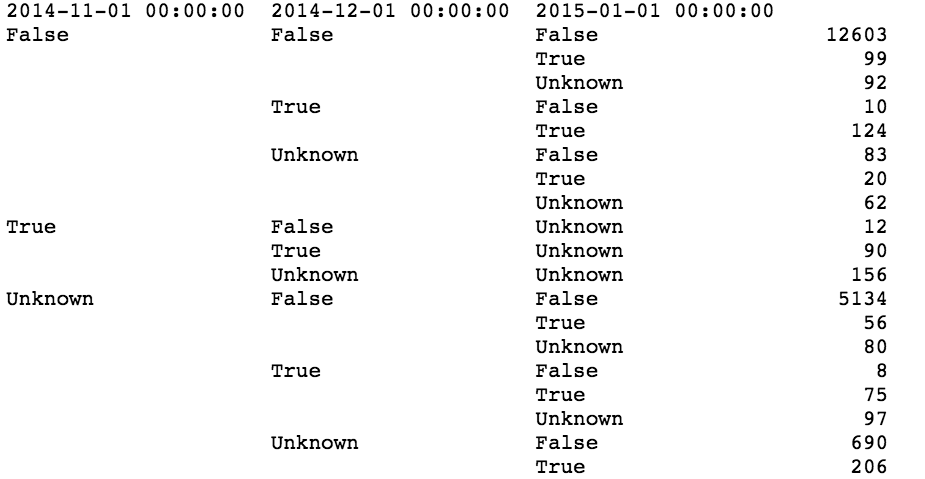
Кроме этого оказалось, что 70% пользователей из тестовой выборки есть в обучающей. То есть напрашивается следующий гениальный классификатор: если пользователь ушёл в январе, то он будет в оттоке и в феврале, если не ушёл в январе, то и в оттоке его не будет. Чтобы прикинуть качество такого решения, берём всех пользователей из января и делаем для них предсказание по данным за декабрь. Получается не очень, но лучше чем ничего:
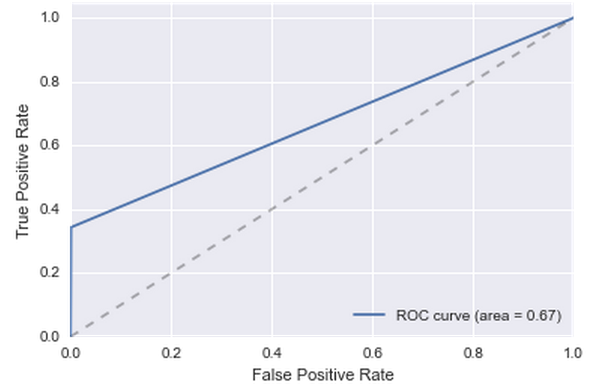
Да, понятно, что январь и февраль совершенно разные месяцы. Конец декабря, первая половина января вообще особенные для россиян. Но особого выбора нет, нужно же на чём-то проверять алгоритм.
Чтобы как-то улучшить решение, всё-таки придётся поразбираться в гигантском файле без описания. Первым делом я решил выкинуть все записи, в которых id не принадлежит ни одному пользователю из обучающей или тестовой выборки. О ужас, ни одной записи выкинуть не удалось. Одному пользователю там соответствует ни одна, а, в среднем, 300 записей. То есть, это какие-то логи, а не агрегированные данные. Кроме того, 50 из 60 колонок — это хеши. Логи с хешами вместо значений. В моём представлении это полный бред. Я люблю анализ данных за те моменты, когда удаётся открывать какие-то новые знания. В данном случае открытия могут выглядеть так: «если у пользователя в седьмом столбике часто встречается 8UCcQrvgqGa2hc4s2vzPs3dYJ30= значит, наверное, он скоро уйдёт». Не очень интересно. Тем не менее я решил проверить несколько гипотез, посмотреть, что получится.
Известно, что в каждой строчке лога есть два id, а не один. Поэтому я предположил, что мы работаем с какими-то транзакциями. Чтобы как-то это проверить, был построен граф, где в вершинах располагались id, а рёбра появлялись, если два id встречались в одной записи. Если в логе действительно транзакции, граф должен получится очень разреженным и должен хорошо группироваться в кластеры. Получилось не совсем то, что я ожидал, между кластерами на глаз было много связей:
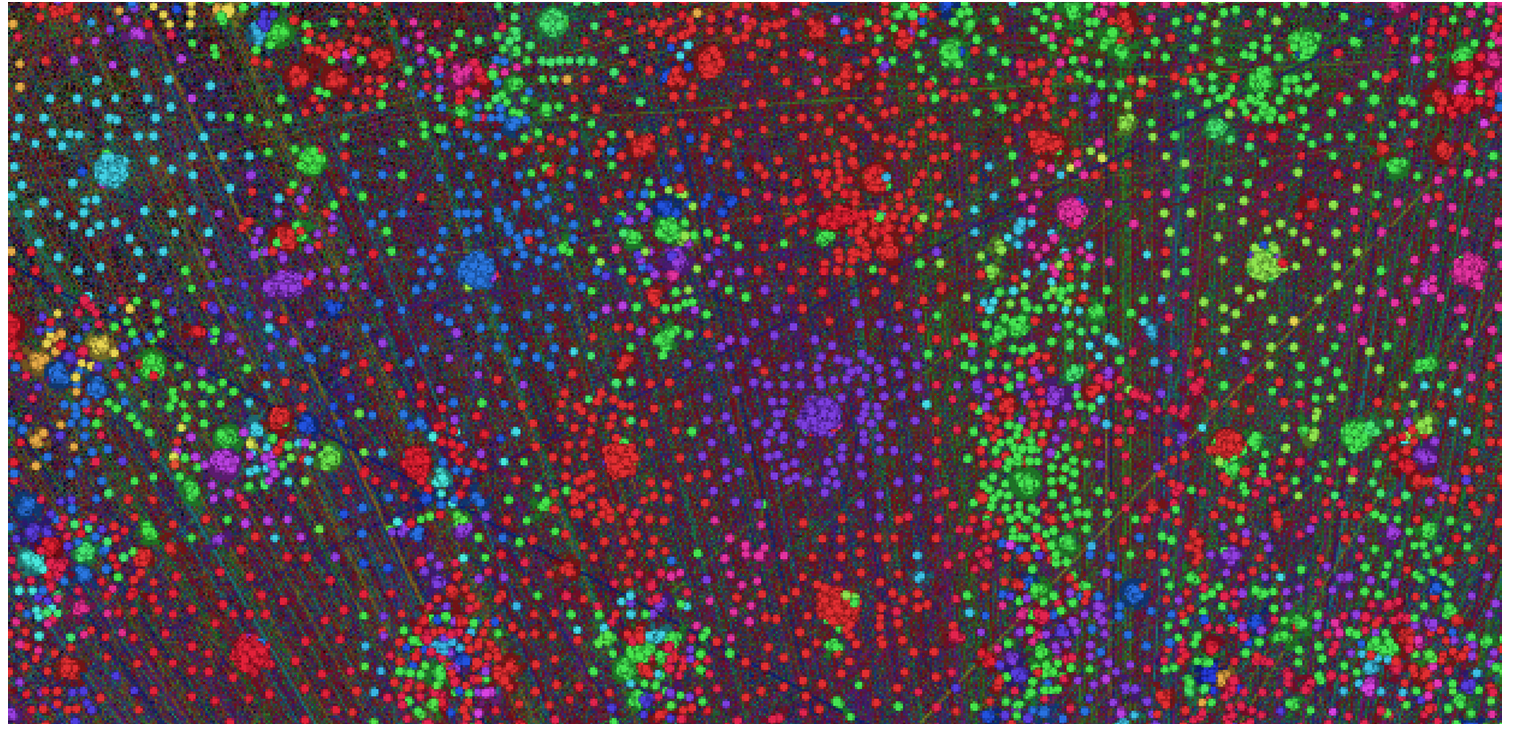
Но, формально модулярность была очень высокой и кластера, часто формировались вокруг одной вершины, поэтому я решил, что всё-таки это транзакции. Тем более, что лучше идей не было.
Хорошо, если мы имеем дело с транзакциями, логичным дополнением к модели будет число входящих и исходящих транзакций. Действительно, среди тех, кто ушёл в январе, почти 40% имели менее десяти входящих транзакций.
Добавим это нехитрое условие в модель и получим уже неплохое качество:
Понятно, что просто количество транзакций — это не очень круто. Пользователь может сделать 500 транзакций в январе 2014 и легко уйти в январе 2015. Нужно смотреть на тренд. У утёкших, действительно, всё заканчивается на первом, втором месяце:
А у тех, кто остался историй посложнее:
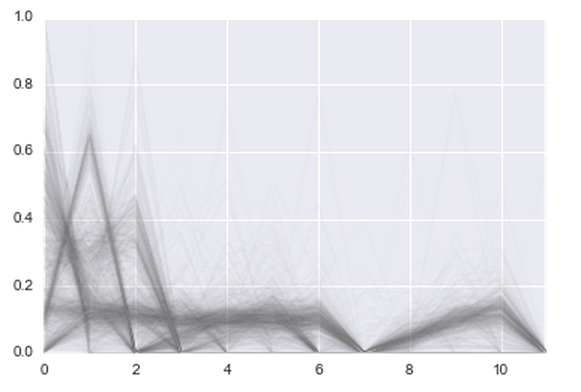
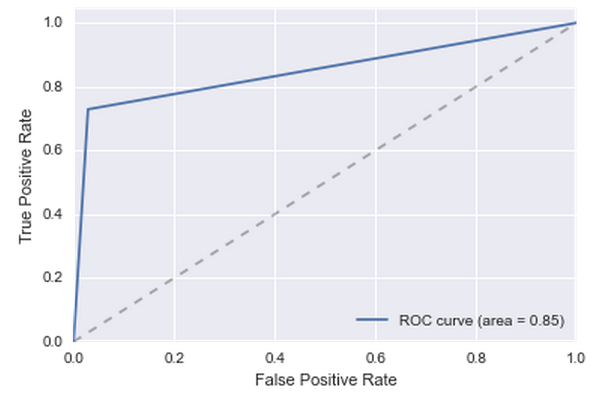
Как-то просто добавить это условие в модель мне не удалось, поэтому пришлось обратиться к машинному обучению. Запилил RandomForest на 500 деревьев глубиной 10 на фичах типа: «месяцев до первой транзакции», «месяцев до последней транзакции», «число месяцев с транзакциями». Качество немного подросло:
Резерв простых понятных решений был исчерпан. Поэтому пришлось закопаться в гигантский файл без описания ещё глубже. Для всех колонок было посчитано сколько уникальных значений там встречается.

Почему число уникальных значений дробное? Потому что пришлось использовать хитрый метод подсчёта уникальных значений с фиксированной памятью. Если всё просто запихивать в сеты, памяти не напасёшься.
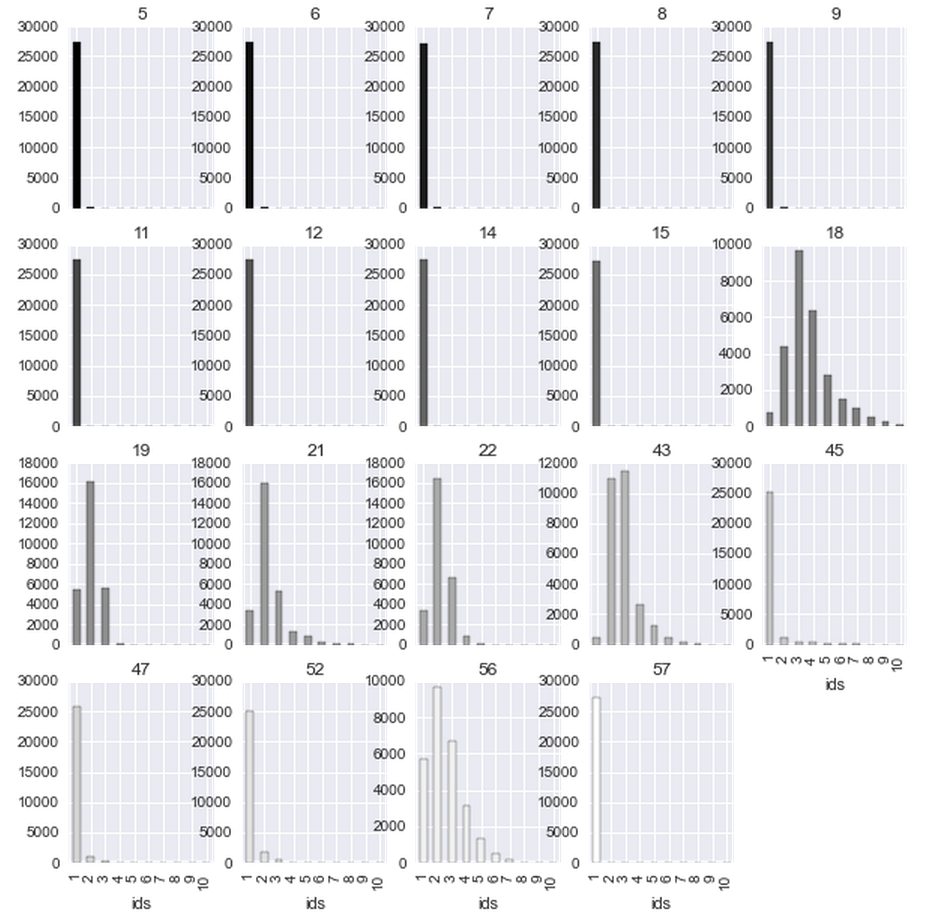
Затем для колонок, в которых разумное число разных значений были посчитаны гистограммы:

Видно, что некоторые гистограммы похожи, например, 14 и 33, 22 и 41. Действительно, большинство полей идут парами (да, я вручную запилил граф корреляции признаков):

То есть часть колонок описывают id1, часть id2. Некоторые поля являются признаками транзакции. Чтобы наверняка убедиться какие колонки описывают пользователя, я посчитал как часто для одного id они принимают разные значения. Оказалось, что колонки с 5 по 15 почти никогда не принимают больше одного значения на id. Действительно, некоторые из них это название города, почтовый индекс. Они вошли в модель как категориальные. Остальные могут принимать разные значения для одного id (в основном null, конечно), поэтому они вошли в модель с весами.
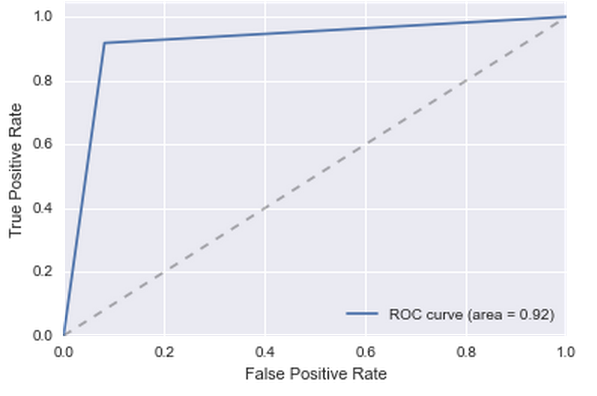
Из-за всех этих категориальных фичей сложность модели очень сильно увеличилась, большинство новых признаков особого вклада не внесли. Но нашлась одна фича — 56-я. Она сильно повлияла. Качество значительно подросло:
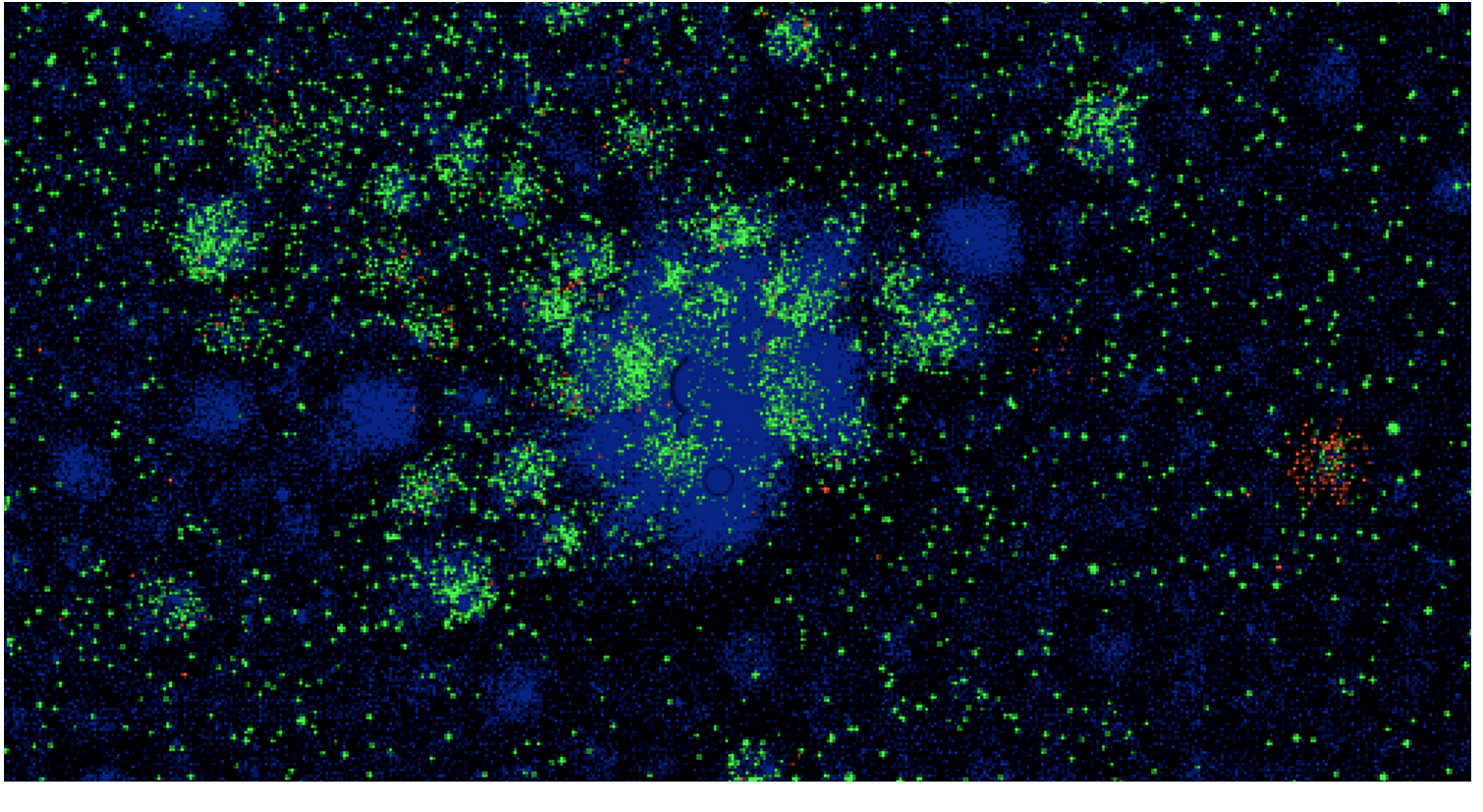
Попробовал ещё одну прикольную фичу. Достал граф транзакций, который построил в самом начале и посмотрел, где там находятся пользователи, которые утекли и остались. С удивлением отметил, что есть кластер, где почти одни утекшие. Правда, классификатор и так на них не делал ошибок, поэтому прироста качества не получилось.
Поподбирал ещё параметры для RandomForest. Разметил тестовую выборку. Убедился, что все кто ушли в январе, ушли и в феврале. Проверил что в целом доля ушедших нормальная. И заслал в Сбербанк. Но что-то видимо пошло не так, потому что в топ-3 я себя не обнаружил. А топ большего размера нам не показали.
Сбербанк щедро отгрузил данных. Нам дали ~20 000 пользователей, про которых было известно попали они в отток в ноябре, декабре, январе или нет. И было ~30 000 пользователей, для которых нужно было угадать уйдут ли они в феврале. Кроме этого прилагался файлик на 35Гб примерно такого содержания:
Сорри, НДА
Физический смысл полей специально не раскрывался. Сказали «так интереснее». Было известно только, где искать id пользователей. Такой расклад показался мне крайне странным. Впрочем, Сбербанк тоже можно понять. Для начала этот адский массив данных я решил оставить в стороне и подробнее изучить пользователей из обучающего и тестового наборов.
Выяснилось невероятное: если пользователь не ушёл в ноябре и декабре, то и в январе он скорее всего не уйдёт. Если пользователь ушёл, то он скорее всего не вернётся:
Кроме этого оказалось, что 70% пользователей из тестовой выборки есть в обучающей. То есть напрашивается следующий гениальный классификатор: если пользователь ушёл в январе, то он будет в оттоке и в феврале, если не ушёл в январе, то и в оттоке его не будет. Чтобы прикинуть качество такого решения, берём всех пользователей из января и делаем для них предсказание по данным за декабрь. Получается не очень, но лучше чем ничего:
Да, понятно, что январь и февраль совершенно разные месяцы. Конец декабря, первая половина января вообще особенные для россиян. Но особого выбора нет, нужно же на чём-то проверять алгоритм.
Чтобы как-то улучшить решение, всё-таки придётся поразбираться в гигантском файле без описания. Первым делом я решил выкинуть все записи, в которых id не принадлежит ни одному пользователю из обучающей или тестовой выборки. О ужас, ни одной записи выкинуть не удалось. Одному пользователю там соответствует ни одна, а, в среднем, 300 записей. То есть, это какие-то логи, а не агрегированные данные. Кроме того, 50 из 60 колонок — это хеши. Логи с хешами вместо значений. В моём представлении это полный бред. Я люблю анализ данных за те моменты, когда удаётся открывать какие-то новые знания. В данном случае открытия могут выглядеть так: «если у пользователя в седьмом столбике часто встречается 8UCcQrvgqGa2hc4s2vzPs3dYJ30= значит, наверное, он скоро уйдёт». Не очень интересно. Тем не менее я решил проверить несколько гипотез, посмотреть, что получится.
Известно, что в каждой строчке лога есть два id, а не один. Поэтому я предположил, что мы работаем с какими-то транзакциями. Чтобы как-то это проверить, был построен граф, где в вершинах располагались id, а рёбра появлялись, если два id встречались в одной записи. Если в логе действительно транзакции, граф должен получится очень разреженным и должен хорошо группироваться в кластеры. Получилось не совсем то, что я ожидал, между кластерами на глаз было много связей:
Но, формально модулярность была очень высокой и кластера, часто формировались вокруг одной вершины, поэтому я решил, что всё-таки это транзакции. Тем более, что лучше идей не было.
Хорошо, если мы имеем дело с транзакциями, логичным дополнением к модели будет число входящих и исходящих транзакций. Действительно, среди тех, кто ушёл в январе, почти 40% имели менее десяти входящих транзакций.
Добавим это нехитрое условие в модель и получим уже неплохое качество:
Понятно, что просто количество транзакций — это не очень круто. Пользователь может сделать 500 транзакций в январе 2014 и легко уйти в январе 2015. Нужно смотреть на тренд. У утёкших, действительно, всё заканчивается на первом, втором месяце:
А у тех, кто остался историй посложнее:
Как-то просто добавить это условие в модель мне не удалось, поэтому пришлось обратиться к машинному обучению. Запилил RandomForest на 500 деревьев глубиной 10 на фичах типа: «месяцев до первой транзакции», «месяцев до последней транзакции», «число месяцев с транзакциями». Качество немного подросло:
Резерв простых понятных решений был исчерпан. Поэтому пришлось закопаться в гигантский файл без описания ещё глубже. Для всех колонок было посчитано сколько уникальных значений там встречается.
Почему число уникальных значений дробное? Потому что пришлось использовать хитрый метод подсчёта уникальных значений с фиксированной памятью. Если всё просто запихивать в сеты, памяти не напасёшься.
Затем для колонок, в которых разумное число разных значений были посчитаны гистограммы:
Видно, что некоторые гистограммы похожи, например, 14 и 33, 22 и 41. Действительно, большинство полей идут парами (да, я вручную запилил граф корреляции признаков):
То есть часть колонок описывают id1, часть id2. Некоторые поля являются признаками транзакции. Чтобы наверняка убедиться какие колонки описывают пользователя, я посчитал как часто для одного id они принимают разные значения. Оказалось, что колонки с 5 по 15 почти никогда не принимают больше одного значения на id. Действительно, некоторые из них это название города, почтовый индекс. Они вошли в модель как категориальные. Остальные могут принимать разные значения для одного id (в основном null, конечно), поэтому они вошли в модель с весами.
Из-за всех этих категориальных фичей сложность модели очень сильно увеличилась, большинство новых признаков особого вклада не внесли. Но нашлась одна фича — 56-я. Она сильно повлияла. Качество значительно подросло:
Попробовал ещё одну прикольную фичу. Достал граф транзакций, который построил в самом начале и посмотрел, где там находятся пользователи, которые утекли и остались. С удивлением отметил, что есть кластер, где почти одни утекшие. Правда, классификатор и так на них не делал ошибок, поэтому прироста качества не получилось.
Поподбирал ещё параметры для RandomForest. Разметил тестовую выборку. Убедился, что все кто ушли в январе, ушли и в феврале. Проверил что в целом доля ушедших нормальная. И заслал в Сбербанк. Но что-то видимо пошло не так, потому что в топ-3 я себя не обнаружил. А топ большего размера нам не показали.
