
Ночная зала. Тысячи таинственных ликов в темноте, подсвеченных голубоватым свечением мониторов. Оглушительный треск миллиона клавиш. Подобные выстрелам автомата удары по клавишам «Enter». Зловещее стрекотание сотен тысяч мышек… Так, наверняка, играло воображение каждого разработчика высоконагруженной системы. И если его вовремя не остановить, то может выйти целый триллер или фильм ужасов. Но в данной статье мы будем гораздо ближе к земле. Мы кратко рассмотрим известные подходы к решению задачи поисковых подсказок, как мы научились делать их полнотекстовыми, а также расскажем о парочке уловок, на которые мы пошли, чтобы придать им скорости, но при этом не научить жадности к ресурсам. В конце статьи вас ждёт бонус — небольшой рабочий пример.
Что должно быть «под капотом»?
- Поиск по подсказкам должен быть полнотекстовым, то есть должен уметь искать по текстам подсказок все слова из пользовательского запроса в любой их последовательности. Например, если пользователь ввёл запрос «смотреть», а в базе мы располагаем следующими подсказками:

то пользователь должен увидеть все три, несмотря на то, что слово «смотреть» находится в разных местах этих подсказок. - Запрос пользователя может быть неполным, пока набирает его на клавиатуре. Поэтому искать нужно не по словам, а по их префиксам. Для предыдущего примера мы должны увидеть все три подсказки не только по целому слову «смотреть», но и для любой его префиксной части. Например, «смотр».
- Поиск Mail.Ru — поисковик общего назначения, а значит разнообразие возможных запросов велико, и система должна уметь искать среди десятков миллионов подсказок.
- Скорость реакции крайне важна, поэтому мы хотим выдавать ответ за считанные миллисекунды.
- Наконец, сервис должен быть надёжной системой, работающей в режиме 24/7/365. Со всей России и стран СНГ наши подсказки ежесекундно обрабатывают тысячи запросов. Для отказоустойчивости, а, следовательно, ради простоты реализации и отладки, нам крайне желательно иметь в основе сервиса некую идею, которая была бы крайне проста и элегантна.

Известные подходы
1. Префиксное автодополнение
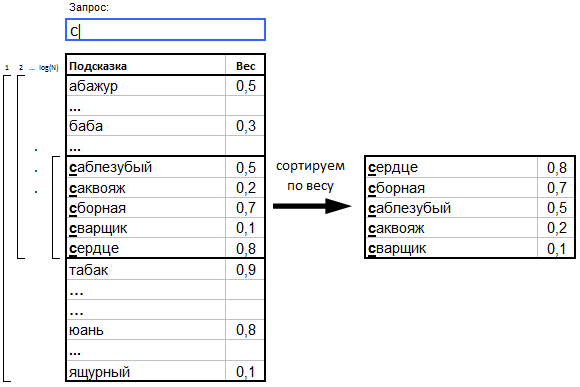
a. Подсказки с весами (вес == популярность) сортируются в лексикографическом порядке по текстам подсказок.
b. Когда пользователь вводит запрос (префикс), бинарным поиском находится подмножество подсказок, начало которых удовлетворяет этому префиксу.
c. Найденное подмножество сортируется по убыванию веса, а ТОП самых «тяжёлых» подсказок отдаётся пользователю в качестве результата.
Очевидной оптимизацией такого подхода является Patricia Tree с весами в узлах дерева. При выборе самых «тяжёлых» запросов, как правило, используется очередь с приоритетами, либо segment tree, что даёт логарифмическое время поиска. При желании можно потратить память сервера, использовав алгоритм LCA via RMQ, и тогда мы получим очень быстрые префиксные подсказки. Плюсов у этого подхода целых три: скорость, компактность и простота реализации. Однако очевидным и самым неприятным недостатком является невозможность искать перестановки слов по текстам подсказок. Иными словами, такие подсказки будут лишь префиксными, а не полнотекстовыми.
2. Полнотекстовое автодополнение
a. Тексты подсказок и запрос пользователя рассматривается как последовательность слов.
b. Когда пользователь вводит запрос, в базе ищется подмножество подсказок, которые содержат все слова пользователя (а точнее, префиксы) вне зависимости от их позиции в подсказке.
c. Найденное подмножество сортируется по убыванию соответствия слов подсказки к словам запроса, затем по убыванию веса, и пользователю возвращается ТОП самых «тяжёлых».

Собственно, это и есть полнотекстовый подход, о котором будем говорить далее. По этой теме в интернете доступно обширное количество публикаций отечественных и зарубежных авторов. Например:
- Реализация нечёткого поиска — автор реализовал поисковые подсказки по названиям баров, ресторанов и прочих заведений, совмещённые с исправлением опечаток. Так как подсказок было всего ~2.5 тысячи, то достаточно оказалось искать перебором по всем подсказкам алгоритмом Вагнера-Фишера, модифицированного под поиск по префиксам слов. Метод качественный, но не подходит нам по причине низкой скорости.
- TASTIER approach — live-поиск по статьям, находит не только точное соответствие, но и связанные по теме публикации. Хранит контекст пользователя в оперативной памяти, чтобы адаптировать его по мере ввода пользовательского запроса, что довольно затратно по памяти и пагубно для скорости.
- Sphinx Simple autocomplete and correction suggestions — автодополнение на базе известного открытого поискового движка Sphinx. Основная идея автодополнения — использование wildcard’а в языке запросов MySQL: «the wor*». Исправление опечаток — на основе n-gram’ного подхода. Разумеется, такой поиск не совсем то, что нам нужно: ведь пользователь не обязательно набирает последнее слово; а как показывает практика, пользователь может вводить слова запроса как угодно, в любой последовательности. Кроме того, n-gram'ный подход потребует много ресурсов, чтобы применить его в real-time подсказках.
Приведённые выше и прочие не рассмотренные здесь подходы не удовлетворили нас по сочетанию: экономичность + скорость + простота. Поэтому мы разработали свой алгоритм, который соответствует нашим потребностям.
Формальная постановка задачи
Перед описанием алгоритма сформулируем нашу задачу более формально. Итак, дано:
- Множество текстов подсказок S = {s1, s2, …, sN}, каждый из которых состоит из слов W(si) = {wi1, wi2, …, wiK}. Тексты подсказок мы получаем из логов запросов, которые пользователи задают нашей поисковой системе.
- Множество весов популярности подсказок F = {f1, f2, …, fN}. Под популярностью здесь мы будем понимать частоту употребления конкретного запроса, то есть как часто пользователи ищут что-то в нашей поисковой системе по данному запросу.
- Неполный пользовательский запрос, состоящий из упорядоченной последовательности префиксов Q = {p1, p2, …, pM}. Как мы уже сказали выше, запрос пользователя мы рассматриваем именно как последовательность префиксов, так как запрос может быть неполным.
Требуется:
- Найти множество R всех подсказок si из S, таких, что каждому префиксу pj из Q соответствует одно уникальное слово wk из W(si).
- Упорядочить найденное множество подсказок R по двум критериям:
- по убыванию соответствия порядка слов wk из W(si) порядку префиксов pi из пользовательского запроса Q;
- по убыванию веса популярности fl из F подсказок si из R.
Индекс
Так как нам нужен полнотекстовый поиск по подсказкам, то и в основу нашего индекса лёг классический подход к реализации полнотекстового поиска общего назначения, на котором базируется любой современный веб-поисковик. Полнотекстовый поиск в общем случае ведётся среди так называемых документов, то есть текстов, внутри которых мы хотим искать слова из запроса пользователя. Суть же алгоритма сводится к двум простым структурам данных, прямому и обратному индексам:
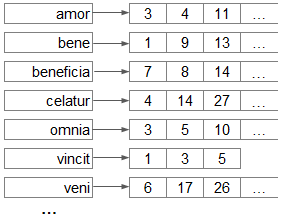
- прямой индекс — список документов, в котором можно найти этот документ по его id. Иными словами, прямой индекс — это массив строк (вектор документов), где id документа — это его индекс.

- обратный индекс — список слов, которые мы «выпотрошили» из всех документов. За каждым словом закреплён список отсортированных id документов (posting list), в которых это слово встретилось.


По этим двум структурам данных достаточно легко найти все документы, удовлетворяющие пользовательскому запросу. Для этого нужно:
- В обратном индексе: по словам из запроса найти списки id тех документов, где эти слова встречались. Получить пересечение этих списков — результирующий список id документов, где встречаются все слова из запроса.
- В прямом индексе: по полученным id найти исходные документы и «отдать» их пользователю.
Описанного вполне достаточно для данной статьи, поэтому за подробностями о поиске мы отправляем вас к книге Стэнфордского университета «An Introduction to Information Retrieval».
Классический алгоритм прост и хорош, но в чистом виде он неприменим к подсказкам, ведь слова в запросе в общем случае являются «незаконченными». Или, как мы сказали выше, запрос состоит не из слов, а скорее из префиксов. Для решения этой проблемы мы доработали обратный индекс, и вот что у нас получилось:
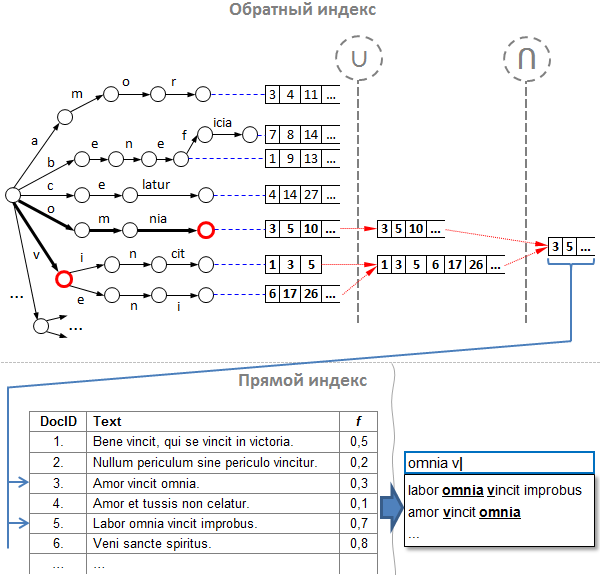
Прим: на рисунке здесь и далее для краткости некоторые узлы дерева «слиты» в один переход из нескольких символов.
Разберём поиск по индексу на примере:
- Предположим, что в нашем распоряжении есть указанный выше индекс, и пользователь уже ввёл часть запроса. Следующая введённая буква на клавиатуре, и вот мы получили неполный запрос «omnia v».
- Разбиваем запрос на слова-префиксы: получаем «omnia» и «v».
- По аналогии с поисковой системой, сначала по заданным словам-префиксам находим списки id подсказок в обратном индексе. Обратим внимание, что наш обратный индекс состоит из двух частей:
a. префиксное дерево (оно же «trie», оно же «бор»), содержащее слова, которые мы «выпотрошили» из текстов подсказок;
b. списки id подсказок — индексы текстов подсказок в прямом индексе, о котором речь пойдёт ниже. Списки отсортированы по возрастанию значения id и находятся в тех вершинах, где заканчиваются слова.
Надо сказать, что trie хорош для нас по двум причинам:
- по нему можно найти любой префикс слова за время O(log(n)), где n — длина префикса;
- для заданного префикса легко определить все варианты его продолжений.
Итак, для каждого префикса углубляемся вниз по дереву и оказываемся в промежуточных узлах. Теперь нужно получить правильные списки id подсказок. - Объединяем списки всех дочерних узлов. Для чего? По аналогии с обычным поисковиком, мы должны бы пересечь списки id для каждого префикса, однако есть два «НО»:
a. во-первых, не всякий узел содержит список id подсказок, а только те узлы, в которых закачивается целое слово;
b. а во-вторых, каждый узел дерева имеет некое продолжение, за исключением листовых узлов. Это значит, что продолжений у одного префикса может быть целое множество, и эти продолжения нужно учесть.
Поэтому, прежде чем найти пресечение, нужно «просуммировать» списки id подсказок для каждого отдельно взятого префикса. Таким образом, для каждого префикса обходим дерево рекурсивно в глубину, начиная с того узла, где мы остановились в дереве по данному префиксу, и конструируем объединение всех списков его дочерних узлов алгоритмом слияния. На рисунке узлы, в которых мы остановились по префиксу, помечены красным кружком, а операция объединения помечена значком «U». - Теперь пересекаем синтетические списки-объединения каждого из префиксов. Надо сказать, что различных алгоритмов пересечения сортированных списков просто море, и каждый подходит больше для различных типов последовательностей. Один из самых эффективных — алгоритм Рикардо Баеза-Ятеса и Алехандро Салингера. В боевых подсказках мы используем свой алгоритм, который наиболее подходит для решения конкретной задачи, однако алгоритм Баеза-Ятеса-Салингера был для нас в своё время вдохновляющим.
- Теперь по найденным id ищем тексты подсказок. Прямой индекс в нашем случае ничем не отличается от прямого индекса любой поисковой системы, то есть представляет собой простой массив (вектор) строк. Кроме текстов подсказок здесь может быть любая дополнительная информация. В частности, здесь мы храним веса популярности.
Итак, к концу шестого этапа мы уже имеем все подсказки, в которых есть все префиксы из пользовательского запроса. Очевидно, что на деле количество подсказок, которые мы получаем к этому этапу, может быть очень много — тысячи или даже сотни тысяч, а «подсказать» пользователю нам нужно только лучшие. Такую задачу решает другой алгоритм — алгоритм ранжирования.
Далее мы рассмотрим один маленький приём, который позволит нам «наполовину» отранжировать подсказки, ровным счётом ничего не делая. И об этом мы поговорим ниже, по ходу рассмотрения двух проблем.
Ускоряемся
«Преждевременная оптимизация — корень всех зол» — твердит народная программистская мудрость, сформулированная Дональдом Кнутом. Но если мы реализуем приведённый выше алгоритм в чистом виде, то отхватим две проблемы с производительностью. Поэтому для нас отсутствие борьбы за скорость будет тем ещё злом.
Проблема первая — медленное объединение списков. Рассмотрим эту проблему подробнее:
- Предположим, в нашем дереве (трае) уже лежит 1000 слов, начинающихся на букву «а» (в реальной ситуации таких слов ещё больше).

- Очевидно, что для 1000 слов минимальное среднее количество id подсказок будет также около 1000. То есть в среднем будет минимум 1000 подсказок, в которых есть слова, начинающиеся на букву «а».
- Теперь представим, что пользователь решил поискать что-нибудь на эту букву «а». По нашему алгоритму, для префикса «а» начинается операция объединения списков для всех дочерних узлов, которые лежат ниже узла «а». Очевидно, эта операция потребует приличных ресурсов: во-первых, на выделение памяти под новый список, а во-вторых, на копирование id в этот новый список.
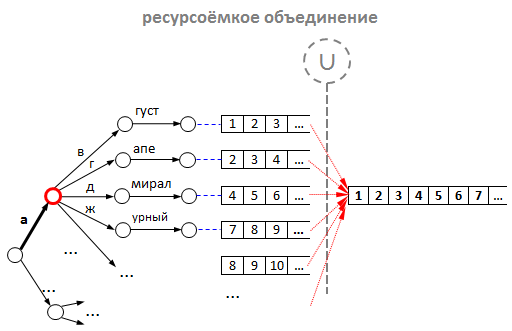
Объединение можно оптимизировать использованием двух приёмов:
- зарезервировать память для итогового списка, дабы не выделять её при каждом новом запросе;
- производить объединение «ленивым» образом, то есть по мере необходимости.
Однако наши эксперименты показали, что любые ухищрения с объединением не идут ни в какое сравнение с оптимизацией за счёт кэширования. Да-да, мы просто стали складывать id подсказок в каждый узел дерева, а не только в листовые вершины. Итого: нет необходимости в объединении — готовые списки для каждого возможного префикса лежат прямо в узлах дерева. А наш обратный индекс приобрёл следующий вид:
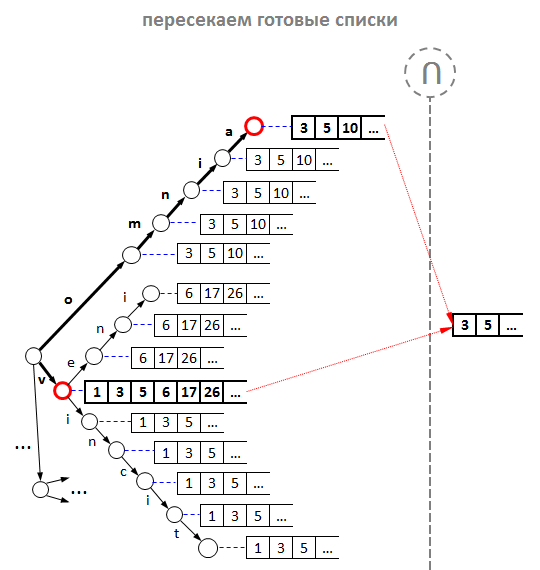
Но стойте! В каждый узел дерева класть id подсказки?! Выглядит крайне расточительно, не правда ли? Но так ли это расточительно? Рассуждаем:
- Для каждой новой подсказки, нам придётся добавить её id столько раз, сколько символов содержится в её тексте. Это в худшем случае, так как для пробелов id добавлять не нужно, а для повторяющихся слов («винни пух и все
все все») повторно добавлять id тоже нет необходимости. - Например, при средней длине подсказки в 25 символов 1 миллион поисковых подсказок содержит 25 млн. символов. А если id подсказки — это 4-байтовое целое (стандартный int), то в худшем случае все списки id подсказок в обратном индексе займут в памяти: 4 байт * 25 000 000 = 100 Мбайт. А такой объём, очевидно, не так уж и расточителен, даже для обычной персоналки. Пропорционально, для 50 миллионов подсказок индекс займёт 5 Гбайт, что для полномасштабного сервиса поисковых подсказок вполне уместно.
Итак, проблему объединения списков мы решили путём кэширования всех списков для каждого возможного префикса.
Проблема вторая — медленное пересечение списков и ранжирование (сортировка) подсказок по весу. По нашему алгоритму после объединения следует два важных этапа, и каждый имеет проблемы с производительностью:
- Пересечение объединённых списков. В большой базе реальные списки слишком длинные, особенно для коротких префиксов. Поэтому пересечение списков для коротких запросов, как «а б», будет слишком долгим.
- Ранжирование подсказок, прежде всего, по убыванию веса. Итоговый список после пересечения может быть также довольно большим, поэтому сортировать тысячи id, как для запроса «а б», тоже оказывается накладно.
Помня, что для результата нам нужно всего-то 7-10 «самых хороших» подсказок, мы обнаружили очень простое решение, которое состоит из двух моментов:
- Правильный порядок id подсказок. Списки id составляем таким образом, чтобы подсказка с наибольшим весом имела наименьший id. Иными словами, подсказки нужно добавлять в индекс в порядке убывания их веса. Таким образом, результирующий список после пересечения уже будет отсортирован одновременно по убыванию веса и значению id. Такой подход мы называем «пре-ранжированием».
- Нам не нужно полное пересечение. Опытным путём было установлено: при пересечении можно брать не всё, а достаточно взять первых K подсказок (где K > N и пропорционально целевому количеству подсказок N), и среди них уже найдутся такие, из которых можно выбрать что-нибудь подходящее как по весу, так и по порядку слов. Например, если нам нужны ТОП N = 10 самых хороших подсказок, то нам достаточно выбрать из результирующего пересечения примерно первых K = 100. Для этого, при пересечении мы можем считать, сколько id в результирующем списке, и как только мы набрали первые 100, останавливаем пересечение.
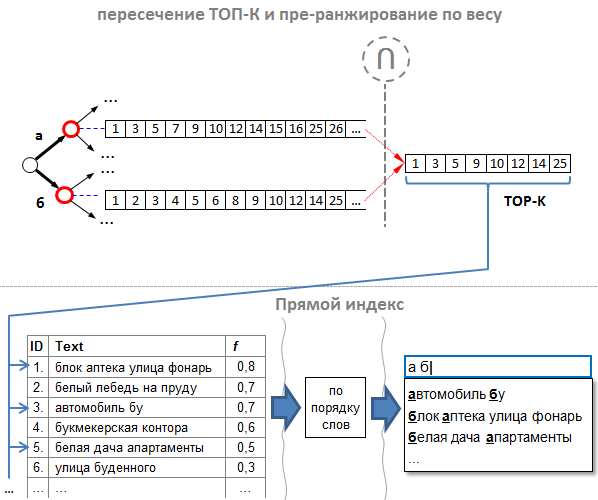
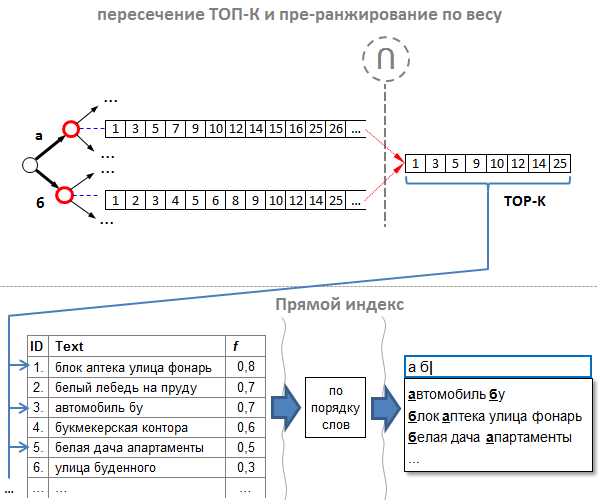
Таким образом, мы оптимизировали как ранжирование по весу, так и пересечение до «ленивых» K первых подсказок.
Реализация
Как и было обещано в начале, мы выкладываем рабочий пример на C++, реализующий описанный в статье алгоритм. В качестве исходной базы можно использовать любой текстовый файл, где каждая строка — это подсказка. Наполнить его можно, например, пословицами и крылатыми выражениями на латыни (первоисточник), чтобы иметь возможность быстро получать их перевод на русский и наоборот.
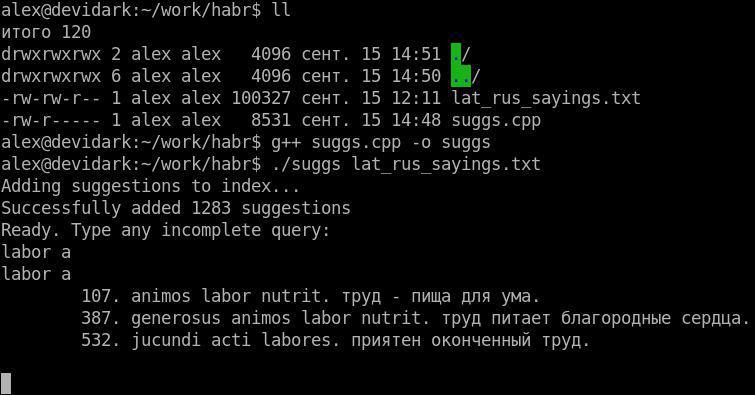
Не будем останавливаться на особенностях реализации, предоставив это читателю: благо пример довольно простой.
Вместо заключения: что осталось «за бортом»
Конечно, представленный здесь алгоритм описан в самом общем виде, и многие вопросы остались за рамками рассмотрения статьи. Над чем ещё было бы полезно подумать разработчику подсказок:
- алгоритм ранжирования подсказок с учётом позиций слов;
- инвертирование языковой раскладки клавиатуры: «ghbdtn» -> «привет»;
- исправление опечаток в пользовательском запросе; здесь мы отправим вас к хорошей статье разработчиков из Microsoft: S. Chaudhuri, R. Kaushik, Extending Autocompletion To Tolerate Errors;
- конструирование концовки запроса пользователя для случая, когда нам нечего подсказать из базы заготовленных подсказок: «что пела в середине 80х алла пу» -> «что пела в середине 80х алла пугачева»;
- учёт географии пользователя: «кинотеатр» -> для пользователя из Саратова не стоит подсказывать московские и питерские кинотеатры, которые ищут часто из-за большой аудитории пользователей;
- масштабирование алгоритма на 2, 3 и более серверов, когда мы захотим добавить 100-200-500 миллионов подсказок и упрёмся в ресурсы памяти и процессора;
- и прочее, и прочее, что только можно ориентировать на нашего любимого пользователя и на наши потребности.
На этом всё. Спасибо за внимание.
Алексей Медвещек,
разработчик поисковых подсказок.
