Понадобилось мне недавно написать аналог функции strstr(поиск подстроки в строке). Я решил его ускорить. В результате получился алгоритм. Я не нашел его по первым ссылкам в поисковике, зато там куча других алгоритмов, поэтому и написал это.
График сравнения скорости работы моего алгоритма, с функцией strstr на 600 кб тексте русскоязычной книги, при поиске строк размером от 1 до 255 байт:

Идея лежащая в основе алгоритма следующая. Сперва обозначения:
S — Строка в которой будет производится поиск будет называться
P — строка, которую ищем будет называться
sl — длина строки S
pl — длина строки P
PInd — табличка составляемая на первом этапе.
Итак идея такая: Если в строке S выбирать элементы с индексами равными: pl1, pl2,..., plJ,..., pl(sl/pl), то если в отрезок pl(J-1)...pl(J+1) входит искомая строка P, то тогда выбранный элемент должен принадлежать строке P. Иначе строка бы не вписывалась по длине.
Картинка, где нарисовано до куда дотягивается P, в pl*3.:
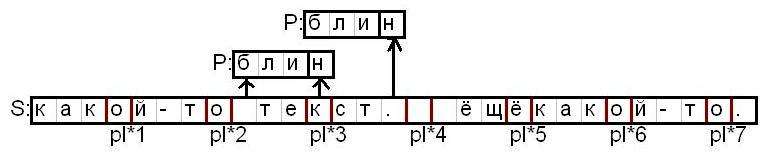
И ещё, так как выбранный элемент входит в строку P обычно маленькое число раз, то можно проверять только эти вхождения, а не весь диапазон.
Итого алгоритм такой:
Этап 1. Сортировка P
Для всех элементов(символов) строки P сортируем индексы этих элементов по значению этих элементов. То есть делаем так, что-бы все номера всех элементов равных какому-то значению, можно было быстро получить. Эта табличка будет дальше называться PInd:
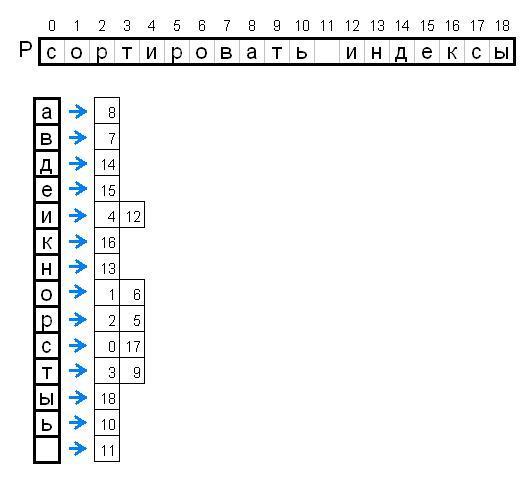
Как видно из этой таблички, при поиске на этапе 2 при искомой строке P равной "сортировать индексы" нам понадобится проверять максимум 2 варианта подстрок в S.
Сначала я для составления этой таблички использовал быструю сортировку и какую-то ещё, а потом я сообразил, что так как элементы строки однобайтовые, то можно использовать поразрядную.
Этап 2. Поиск
Проходим по строке строке S скачками равными pl, выбирая соответствующие элементы. Для каждого выбранного элемента проверяем входит ли он в строку P.
Если входит, то для всех индексов из PInd соответствующего элемента, проверяем совпадает ли подстрока S с началом в соответствующим индексу из PInd смещением относительно выбранного элемента и искомая строка P.
Если совпало, то возвращаем результат, если нет то продолжаем.
Худший вариант для этого алгоритма, зависит от способа сравнения строк во втором этапе. Если простое сравнение, то sl*pl+pl, если какой-то ещё, то другой. Я использовал просто сравнение, как в обычном strstr.
За счёт того, что алгоритм скачет через pl элементов и проверяет только возможные строки он работает быстрее.
Лучший вариант, это когда алгоритм проскачет всю строку S и не найдёт текст или найдёт с первого раза, тогда потратит примерно sl/pl.
Среднюю скорость я не знаю как подсчитать.
Вот одна из моих реализаций этого алгоритма, по которой строился график на языке си. Здесь pl ограничено, то есть таблица PInd строится по префиксу P длины max_len, а не по всей строке. Именно он использовался при построении графика:
char * my_strstr(const char * str1, const char * str2,size_t slen){
unsigned char max_len = 140;
if ( !*str2 )
return((char *)str1);
//Очистка массивов
unsigned char index_header_first[256];
unsigned char index_header_end[256];
unsigned char last_char[256];
unsigned char sorted_index[256];
memset(index_header_first,0x00,sizeof(unsigned char)*256);
memset(index_header_end,0x00,sizeof(unsigned char)*256);
memset(last_char,0x00,sizeof(unsigned char)*256);
memset(sorted_index,0x00,sizeof(unsigned char)*256);
//Этап 1.
char *cp2 = (char*)str2;
unsigned char v;
unsigned int len =0;
unsigned char current_ind = 1;
while((v=*cp2) && (len<max_len)){
if(index_header_first[v] == 0){
index_header_first[v] = current_ind;
index_header_end[v] = current_ind;
sorted_index[current_ind] = len;
}
else{
unsigned char last_ind = index_header_end[v];
last_char[current_ind] = last_ind;
index_header_end[v] = current_ind;
sorted_index[current_ind] = len;
}
current_ind++;
len++;
cp2++;
}
if(len > slen){
return NULL;
}
//Этап 2.
unsigned char *s1, *s2;
//Начинаем проверку с элемента S+pl-1
unsigned char *cp = (unsigned char *) str1+(len-1);
unsigned char *cp_end= cp+slen;
while (cp<cp_end){
unsigned char ind = *cp;
//Если выбранный элемент есть в строке P
if( (ind = index_header_end[ind]) ) {
do{
//Тогда проверяем все возможные варианты с участием этой буквы
unsigned char pos_in_len = sorted_index[ind];
s1 = cp - pos_in_len;
if((char*)s1>=str1)
{
//Сравниваем строки
s2 = (unsigned char*)str2;
while ( *s2 && !(*s1^*s2) )
s1++, s2++;
if (!*s2)
return (char*)(cp-pos_in_len);
}
}
while( (ind = last_char[ind]) );
}
//Прыгаем вперёд на pl
cp+=len;
}
return(NULL);
}Обновление: Это действительно не совсем прямая замена strstr, так как требует дополнительно параметр — длину строки S.
