Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.В этой статье мы рассмотрим ряд примеров иллюстрирующих различные особенности работы кэшей и их влияние на производительность. Примеры будут на C#, выбор языка и платформы не так сильно влияет на оценку производительности и конечные выводы. Естественно, в разумных пределах, если вы выберите язык, в котором чтение значения из массива равносильно обращению к хеш-таблице, никаких результатов пригодных к интерпретации вы не получите. Курсивом идут примечания переводчика.
- - - habracut - - -
Пример 1: доступ к памяти и производительность
Как вы думаете, насколько второй цикл быстрее первого?
int[] arr = new int[64 * 1024 * 1024];
// первый
for (int i = 0; i < arr.Length; i++) arr[i] *= 3;
// второй
for (int i = 0; i < arr.Length; i += 16) arr[i] *= 3;Первый цикл умножает все значения массива на 3, второй цикл только каждое шестнадцатое значение. Второй цикл совершает только 6% работы первого цикла, но на современных машинах оба цикла выполняются примерно за равное время: 80 мс и 78 мс соответственно (на моей машине).
Разгадка проста — доступ к памяти. Скорость работы этих циклов в первую очередь определяется скоростью работы подсистемы памяти, а не скоростью целочисленного умножения. Как мы увидим в следующем примере, количество обращений к оперативной памяти одинаково и в первом и во втором случае.
Пример 2: влияние строк кэша
Копнём глубже — попробуем другие значения шага, не только 1 и 16:
for (int i = 0; i < arr.Length; i += K /* шаг */ ) arr[i] *= 3;Вот время работы этого цикла для различных значений шага K:
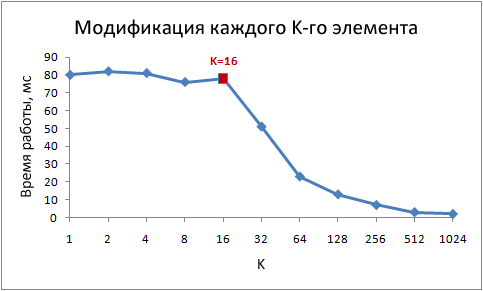
Обратите внимание, при значениях шага от 1 до 16 время работы практически не изменяется. Но при значениях больше 16, время работы уменьшается примерно вдвое каждый раз когда мы увеличиваем шаг в два раза. Это не означает, что цикл каким-то магическим образом начинает работать быстрее, просто количество итераций при этом так же уменьшается. Ключевой момент — одинаковое время работы при значениях шага от 1 до 16.
Причина этого в том, что современные процессоры осуществляют доступ к памяти не побайтно, а небольшими блоками, которые называют строками кэша. Обычно размер строки составляет 64 байта. Когда вы читаете какое-либо значение из памяти, в кэш попадает как минимум одна строка кэша. Последующий доступ к какому-либо значению из этой строки происходит очень быстро.
Из-за того, что 16 значений типа int занимают 64 байта, циклы с шагами от 1 до 16 обращаются к одинаковому количеству строк кэша, точнее говоря, ко всем строкам кэша массива. При шаге 32, обращение происходит к каждой второй строке, при шаге 64, к каждой четвёртой.
Понимание этого очень важно для некоторых способов оптимизации. От места расположения данных в памяти зависит число обращений к ней. Например, из-за невыровненных данных может потребоваться два обращения к оперативной памяти, вместо одного. Как мы выяснили выше, скорость работы при этом будет в два раза ниже.
Пример 3: размеры кэшей первого и второго уровня (L1 и L2)
Современные процессоры, как правило, имеют два или три уровня кэшей, обычно их называют L1, L2 и L3. Для того, чтобы узнать размеры кэшей различных уровней, можно воспользоваться утилитой CoreInfo или функцией Windows API GetLogicalProcessorInfo. Оба способа так же предоставляют информацию о размере строки кэша для каждого уровня.
На моей машине CoreInfo сообщает о кэшах данных L1 объёмом по 32 Кбайт, кэшах инструкций L1 объёмом по 32 Кбайт и кэшах данных L2 объёмом по 4 Мбайт. Каждое ядро имеет свои персональные кэши L1, кэши L2 общие для каждой пары ядер:
Logical Processor to Cache Map: *--- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64 *--- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64 -*-- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64 -*-- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64 **-- Unified Cache 0, Level 2, 4 MB, Assoc 16, LineSize 64 --*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64 --*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64 ---* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64 ---* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64 --** Unified Cache 1, Level 2, 4 MB, Assoc 16, LineSize 64
Проверим эту информацию экспериментально. Для этого, пройдёмся по нашему массиву инкрементируя каждое 16-ое значение — простой способ изменить данные в каждой строке кэша. При достижении конца, возвращаемся к началу. Проверим различные размеры массива, мы должны увидеть падение производительности когда массив перестаёт помещаться в кэши разных уровней.
Код такой:
int steps = 64 * 1024 * 1024; // количество итераций
int lengthMod = arr.Length - 1; // размер массива -- степень двойки
for (int i = 0; i < steps; i++)
{
// x & lengthMod = x % arr.Length, ибо степени двойки
arr[(i * 16) & lengthMod]++;
}
Результаты тестов:

На моей машине заметны падения производительности после 32 Кбайт и 4 Мбайт — это и есть размеры кэшей L1 и L2.
Пример 4: параллелизм инструкций
Теперь давайте взглянем на кое-что другое. По вашему мнению, какой из этих двух циклов выполнится быстрее?
int steps = 256 * 1024 * 1024;
int[] a = new int[2];
// первый
for (int i = 0; i < steps; i++) { a[0]++; a[0]++; }
// второй
for (int i = 0; i < steps; i++) { a[0]++; a[1]++; }Оказывается, второй цикл выполняется почти в два раза быстрее, по крайней мере, на всех протестированных мной машинах. Почему? Потому, что команды внутри циклов имеют разные зависимости по данным. Команды первого имеют следующую цепочку зависимостей:

Во втором цикле зависимости такие:

Функциональные части современных процессоров способны выполнять определённое число некоторых операций одновременно, как правило, не очень большое число. Например, возможен параллельный доступ к данным из кэша L1 по двум адресам, так же возможно одновременное выполнение двух простых арифметических команд. В первом цикле процессор не может задействовать эти возможности, но может во втором.
Пример 5: ассоциативность кэша
Один из ключевых вопросов, на который необходимо дать ответ при проектировании кэша — могут ли данные из определённой области памяти храниться в любых ячейках кэша или только в некоторых из них. Три возможных решения:
- Кэш прямого отображения, данные каждой строки кэша в оперативной памяти хранятся только в одной заранее определённой ячейке кэша. Простейший способ вычисления отображения: индекс_строки_в_памяти % количество_ячеек_кэша. Две строки, отображённые на одну и ту же ячейку, не могут находится в кэше одновременно.
- N-входовый частично-ассоциативный кэш, каждая строка может храниться в N различных ячейках кэша. Например, в 16-входовом кэше строка может храниться в одной из 16-ти ячеек составляющих группу. Обычно, строки с равными младшими битами индексов разделяют одну группу.
- Полностью ассоциативный кэш, любая строка может быть сохранена в любую ячейку кэша. Решение эквивалентно хеш-таблице по своему поведению.
К примеру, на моей машине кэш L2 размером в 4 Мбайт является 16-входовым частично-ассоциативным кэшем. Вся оперативная память разделена на множества строк по младшим битам их индексов, строки из каждого множества соревнуются за одну группу из 16 ячеек кэша L2.
Так как кэш L2 имеет 65 536 ячеек (4 * 220 / 64) и каждая группа состоит из 16 ячеек, всего мы имеем 4 096 групп. Таким образом, младшие 12 битов индекса строки определяют к какой группе относится эта строка (212 = 4 096). В результате, строки с адресами кратными 262 144 (4 096 * 64) разделяют одну и ту же группу из 16-ти ячеек и соревнуются за место в ней.
Чтобы эффекты ассоциативности проявили себя, нам необходимо постоянно обращаться к большому количеству строк из одной группы, например, используя следующий код:
public static long UpdateEveryKthByte(byte[] arr, int K)
{
const int rep = 1024 * 1024; // количество итераций
Stopwatch sw = Stopwatch.StartNew();
int p = 0;
for (int i = 0; i < rep; i++)
{
arr[p]++;
p += K; if (p >= arr.Length) p = 0;
}
sw.Stop();
return sw.ElapsedMilliseconds;
}
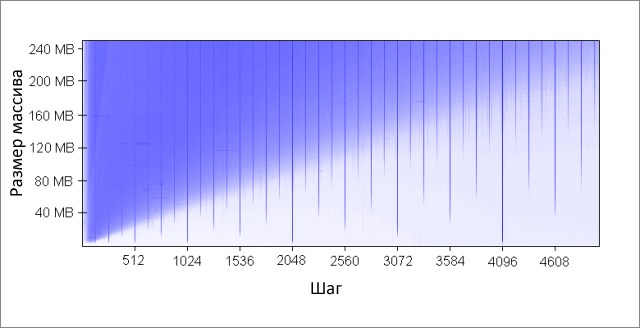
Метод инкрементирует каждый K-ый элемент массива. По достижении конца, начинаем заново. После довольно большого количества итераций (220), останавливаемся. Я сделал прогоны для различных размеров массива и значений шага K. Результаты (синий — большое время работы, белый — маленькое):

Синим областям соответствуют те случаи, когда при постоянном изменении данных кэш не в состоянии вместить все требуемые данные одновременно. Яркий синий цвет говорит о времени работы порядка 80 мс, почти белый — 10 мс.
Разберёмся с синими областями:
- Почему появляются вертикальные линии? Вертикальные линии соответствуют значениям шага при которых осуществляется доступ к слишком большому числу строк (больше 16-ти) из одной группы. Для таких значений, 16-входовый кэш моей машины не может вместить все необходимые данные.
Некоторые из плохих значений шага — степени двойки: 256 и 512. Для примера рассмотрим шаг 512 и массив в 8 Мбайт. При этом шаге, в массиве имеются 32 участка (8 * 220 / 262 144), которые ведут борьбу друг с другом за ячейки в 512-ти группах кэша (262 144 / 512). Участка 32, а ячеек в кэше под каждую группу только 16, поэтому места на всех не хватает.
Другие значения шага, не являющиеся степенями двойки, просто невезучие, что вызывает большое количество обращений к одинаковым группам кэша, а так же приводит к появлению вертикальных синих линий на рисунке. На этом месте любителям теории чисел предлагается задуматься.
- Почему вертикальные линии обрываются на границе в 4 Мбайт? При размере массива в 4 Мбайт или меньше, 16-входовый кэш ведёт себя так же как и полностью ассоциативный, то есть может вместить все данные массива без конфликтов. Имеется не более 16-ти областей ведущих борьбу за одну группу кэша (262 144 * 16 = 4 * 220 = 4 Мбайт).
- Почему слева вверху находится большой синий треугольник? Потому, что при маленьком шаге и большом массиве кэш не в состоянии уместить все необходимые данные. Степень ассоциативности кэша играет тут второстепенную роль, ограничение связано с размером кэша L2.
Например, при размере массива в 16 Мбайт и шаге 128, мы обращаемся к каждому 128-му байту, таким образом, модифицируя каждую вторую строку кэша массива. Чтобы сохранить каждую вторую строку в кэше, необходим его объём в 8 Мбайт, но на моей машине есть только 4 Мбайт.
Даже если бы кэш был полностью ассоциативным, это не позволило бы сохранить в нём 8 Мбайт данных. Заметьте, что в уже рассмотренном примере с шагом 512 и размером массива 8 Мбайт, нам необходим только 1 Мбайт кэша, чтобы сохранить все нужные данные, но это невозможно сделать из-за недостаточной ассоциативности кэша.
- Почему левая сторона треугольника постепенно набирает свою интенсивность? Максимум интенсивности приходится на значение шага в 64 байта, что равно размеру строки кэша. Как мы увидели в первом и во втором примере, последовательный доступ к одной и той же строке практически ничего не стоит. Скажем, при шаге в 16 байт, мы имеем четыре обращения к памяти по цене одного.
Так как количество итераций равно в нашем тесте при любом значении шага, то более дешёвый шаг в результате даёт меньшее время работы.
Ассоциативность кэша — интересная штука, которая может проявить себя при определённых условиях. В отличие от остальных рассмотренных в этой статье проблем, она не является настолько серьёзной. Определённо, это не то, что требует постоянного внимания при написании программ.
Пример 6: ложное разделение кэша
На многоядерных машинах можно столкнуться с другой проблемой — согласование кэшей. Ядра процессора имеют частично или полностью раздельные кэши. На моей машине кэши L1 раздельны (как и обычно), так же имеются два кэша L2, общие для каждой пары ядер. Детали могут различаться, но в целом современные многоядерные процессоры имеют многоуровневые иерархические кэши. Причём самые быстрые, но и самые маленькие кэши, принадлежат индивидуальным ядрам.
Когда одно из ядер модифицирует значение в своём кэше, другие ядра больше не могут использовать старое значение. Значение в кэшах других ядер должно быть обновлено. Более того, должна быть обновлена полностью вся строка кэша, так как кэши оперируют данными на уровне строк.
Продемонстрируем эту проблему на следующем коде:
private static int[] s_counter = new int[1024];
private void UpdateCounter(int position)
{
for (int j = 0; j < 100000000; j++)
{
s_counter[position] = s_counter[position] + 3;
}
}Если на своей четырёхядерной машине я вызову этот метод с параметрами 0, 1, 2, 3 одновременно из четырёх потоков, то время работы составит 4.3 секунды. Но если я вызову метод с параметрами 16, 32, 48, 64, то время работы составит только 0.28 секунды.
Почему? В первом случае, все четыре значения, обрабатываемые потоками в каждый момент времени, с большой вероятностью попадают в одну строку кэша. Каждый раз когда одно ядро увеличивает очередное значение, оно помечает ячейки кэша, содержащие это значение в других ядрах, как невалидные. После этой операции, все остальные ядра должны будут закэшировать строку заново. Это делает механизм кэширования неработоспособным, убивая производительность.
Пример 7: сложность железа
Даже теперь, когда принципы работы кэшей для вас не секрет, железо по-прежнему будет преподносить вам сюрпризы. Процессоры отличаются друг от друга методами оптимизации, эвристиками и прочими тонкостями реализации.
Кэш L1 некоторых процессоров может осуществлять параллельный доступ к двум ячейкам, если они относятся к разным группам, но если они относятся к одной, только последовательно. Насколько мне известно, некоторые даже могут осуществлять параллельный доступ к разным четвертинкам одной ячейки.
Процессоры могут удивить вас хитрыми оптимизациями. Например, код из предыдущего примера про ложное разделение кэша не работает на моём домашнем компьютере так, как задумывалось — в простейших случаях процессор может оптимизировать работу и уменьшить негативные эффекты. Если код немного модифицировать, всё встаёт на свои места.
Вот другой пример странных причуд железа:
private static int A, B, C, D, E, F, G;
private static void Weirdness()
{
for (int i = 0; i < 200000000; i++)
{
<какой-то код>
}
}
Если вместо <какой-то код> подставить три разных варианта, можно получить следующие результаты:

Инкрементирование полей A, B, C, D занимает больше времени, чем инкрементирование полей A, C, E, G. Что ещё страннее, инкрементирование полей A и C занимает больше времени, чем полей A, C и E, G. Не знаю точно каковы причины этого, но возможно они связаны с банками памяти (да-да, с обычными трёхлитровыми сберегательными банками памяти, а не то, что вы подумали). Имеющих соображения на этот счёт, прошу высказываться в комментариях.
У меня на машине вышеописанного не наблюдается, тем не менее, иногда бывают аномально плохие результаты — скорее всего, планировщик задач вносит свои «коррективы».
Из этого примера можно вынести следующий урок: очень сложно полностью предсказать поведение железа. Да, можно предсказать многое, но необходимо постоянно подтверждать свои предсказания с помощью измерений и тестирования.
Заключение
Надеюсь, что всё рассмотренное помогло вам понять устройство кэшей процессоров. Теперь вы можете использовать полученные знания на практике для оптимизации своего кода.
* Source code was highlighted with Source Code Highlighter.