Привет, Хабр!
В этой статье мы расскажем, как построен процесс разработки платформы «1С:Предприятие», как мы работаем над обеспечением качества, и поделимся уроками, которые получили, создавая один из самых больших российских программных комплексов.
Над платформой трудятся несколько групп до 10 программистов в каждой, три четверти из которых пишут на C++, а остальные — на Java и JavaScript.
Каждая группа работает над отдельным направлением развития, например:
Всего групп более десятка. Отдельно есть группа обеспечения качества.
Конечно, на проекте такого размера (более 10 миллионов строк кода) речь об общем владении кода не идёт, удержать в голове такой объем невозможно. Мы стараемся двигаться к тому, чтобы обеспечить "фактор автобуса" в группе не ниже двух.
Мы стараемся выдерживать баланс между самостоятельностью команд, дающей гибкость и повышающей скорость разработки, и однородностью, позволяющей командам эффективно взаимодействовать между собой и внешним миром. Так, у нас общая система контроля версий, сервер сборки и таск-трекер (речь о них пойдёт ниже), а также стандарт кодирования на C++, шаблоны проектной документации, регламент обработки ошибок, пришедших от пользователей и некоторые другие аспекты. Правила, которые должны выполнять все команды, вырабатываются и принимаются общим решением руководителей групп.
С другой стороны, в практиках, которые направлены «вовнутрь», команды достаточно автономны. Например, инспекции кода сейчас применяются во всех командах (и существуют общие правила, определяющие обязательность прохождения ревью), но были внедрены в разное время и процесс построен по разным правилам.
То же самое касается организации процесса — кто-то практикует варианты Agile, кто-то использует другие стили ведения проекта. Канонического SCRUM, кажется, нет нигде — специфика коробочного продукта накладывает свои ограничения. Например, замечательная практика демонстрации оказывается неприменимой в неизменном виде. Другие практики, например, роль Product Owner, имеют у нас свои аналоги. В качестве Product Owner по своему направлению обычно выступает руководитель группы. Помимо технического лидерства в команде, одной из самых главных его задач является определение дальнейших направлений развития. Процессы выработки стратегии и тактики развития платформы – это сложная и интересная тема, которой мы посвятим отдельную статью.
Когда принято решение о реализации того или иного функционала, его облик определяется в серии обсуждений, в которых участвуют, как минимум, разработчик, ответственный за задачу и руководитель группы. Часто привлекаются другие члены команды или сотрудники из других групп, обладающие нужной экспертизой. Окончательный вариант утверждается руководством разработки платформы 1С: Предприятия.
В таких обсуждениях принимаются решения:
Кроме того, последнее время мы стараемся обсуждать задачу с более широким кругом потенциальных потребителей — например, на прошедшем открытом семинаре мы рассказали о находящихся в процессе проектирования новых возможностях работы с двоичными данными, ответили на вопросы и сумели выделить из обсуждения несколько возможных случаев применения, о которых не думали ранее.
При начале работы над новой функцией для неё создаётся задача в таск-трекере. Трекер, кстати, написан на «1С:Предприятие» и бесхитростно называется «База задач». Для каждой задачи в таск-трекере хранится проектный документ — по сути, спецификация на задачу. Он состоит из трех главных частей:
Подготовка проектного документа может начинаться до реализации, а может стартовать и позже, если для задачи сначала делается какое-то исследование или прототип. В любом случае это итеративный процесс, не похожий на водопадную модель, развитие и уточнение проектного документа делается параллельно с реализацией. Главное, чтобы к моменту, когда задача была готова, проектный документ был утверждён во всех деталях. А таких деталей может быть множество, например:
Кроме того, в проекте тезисно фиксируются обсуждения задачи, так, чтобы позднее можно было понять почему были приняты или отвергнуты те или иные варианты.
После того, как проект утверждён и разработчик реализовал новый функционал в ветке задачи (feature branch) в SVN (а при разработке новой IDE — в Git), задача проходит инспекцию кода и ручную проверку другими членами группы. Кроме того, на ветке задачи прогоняются автоматические тесты, о которых рассказывается ниже. На этом же этапе создаётся еще один технический документ – описание задачи, который предназначен для тестировщиков и технических писателей. В отличие от проекта документ не содержит технических деталей реализации, но зато структурирован так, что помогает быстро понять, какие разделы документации нужно дополнить, привносит ли новая функция несовместимые изменения и т.д.
Проверенная и исправленная задача вливается в основную ветку релиза и становится доступной группе тестирования.
Вообще, «качество» и «обеспечение качества» — очень широкие термины. Как минимум, можно выделить два процесса — верификацию и валидацию. Под верификацией обычно понимают соответствие поведения ПО спецификации и отсутствие других явных ошибок, а под валидацией — проверку на соответствие потребностям пользователя. В этом разделе речь пойдёт об обеспечении качества в смысле верификации.
Тестировщики получают доступ к задаче уже после ее вливания, но процесс обеспечения качества начинается намного раньше. В последнее время нам пришлось приложить значительные усилия по его совершенствованию, т.к. стало очевидно, что существовавшие механизмы стали недостаточно адекватны увеличившемуся объёму функционала и заметно возросшей сложности. Эти усилия, по отзывам партнёров о новой версии 8.3.6, как нам кажется, уже дали эффект, но много работы, конечно, ещё впереди.
Существующие механизмы обеспечения качества можно условно разделить на организационные и технологические. Начнём с последних.
Когда речь заходит о механизмах обеспечения качества, сразу на ум приходят тесты. Мы, конечно, их тоже используем, причём в нескольких вариантах:
На C++ мы пишем unit-тесты. Как уже упоминалось в предыдущей статье, мы используем модифицированные варианты Google Test и Google Mock. Например, типичный тест, проверяющий экранирование символа амперсанда ("&") при записи JSON, может выглядеть так:
Следующий уровень тестирования — интеграционные тесты, написанные на языке «1С:Предприятие». Именно они образуют основную часть наших тестов. Типичный набор тестов представляет собой отдельную информационную базу, хранящуюся в *.dt файле. Инфраструктура тестов загружает эту базу и вызывает в ней заранее известный метод, который вызывает уже отдельные тесты, написанные разработчиками, и форматирует их результаты так, чтобы их могла интерпретировать инфраструктура CI (Continuous Integration).
В данном случае, если результат записи разойдётся с эталоном, вылетит исключение, которое инфраструктура перехватит и интерпретирует как провал теста.
Наша система CI сама выполняет эти тесты под различные версии ОС и СУБД, включая 32- и 64-разрядные Windows и Linux, а из СУБД — MS SQL Server, Oracle, PostgreSQL, IBM DB2, а также нашу собственную файловую базу.
Третий и самый громоздкий вид тестов — это т.н. «Пользовательские тестовые системы». Они применяются тогда, когда проверяемый сценарий выходит за пределы одной базы на 1С, например, при тестировании взаимодействия с внешними системами через веб-сервисы. Для каждой группы тестов выделяется одна или несколько виртуальных машин, на каждую из которых устанавливается специальная программа-агент. В остальном разработчик теста имеет полную свободу, ограниченную только требованием выдавать результат в виде файла в формате Google Test, который может быть прочитан CI.
Например, для тестирования клиента SOAP веб-сервисов используется сервис, написанный на C#, а для проверки различных возможностей конфигуратора — объёмный фреймворк тестов, написанных на питоне.
Оборотной стороной такой свободы является необходимость ручной настройки тестов под каждую ОС, управление парком виртуальных машин и прочие накладные расходы. Поэтому, по мере развития наших интеграционных тестов (описанных в предыдущем разделе), мы планируем ограничивать использование пользовательских тестовых систем.
Упомянутые выше тесты пишут сами разработчики платформы, на С++ или создавая небольшие конфигурации (прикладные решения), заточенные под тестирование конкретного функционала. Это является необходимым условием отсутствия ошибок, но не достаточным, особенно в такой системе как платформа 1С: Предприятие, где большая часть возможностей не являются прикладными (используемыми пользователем напрямую), а служат основой для построения прикладных программ. Поэтому существует ещё один эшелон тестирования: автоматизированные и ручные сценарные тесты на реальных прикладных решениях. К этой же группе можно отнести и нагрузочные тесты. Это интересная и большая тема, про которую мы планируем отдельную статью.
При этом все виды тестов выполняются на CI. В качестве сервера непрерывной интеграции используется Jenkins. Вот как он выглядит на момент написания статьи:
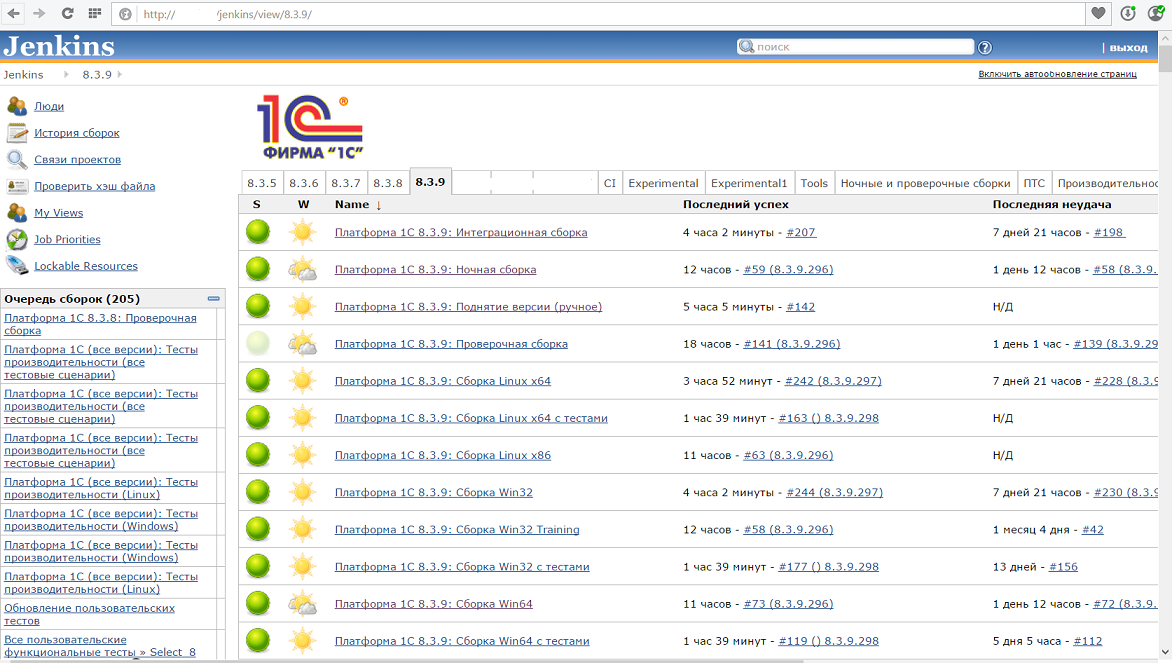
Для каждой конфигурации сборки(Windows x86 и x64, Linux x86 и x64) заведены свои задачи по сборке, которые запускаются параллельно на разных машинах. Сборка одной конфигурации занимает длительное время — даже на мощном оборудовании компиляция и линковка больших объёмов C++ представляет непростую задачу. Кроме того, создание пакетов под Linux (deb и rpm), как оказалось, занимает сопоставимое с компиляцией время.
Поэтому в течение дня работает «укороченная сборка», которая проверяет компилируемость под Windows x86 и Linux x64 и выполняет минимальный набор тестов, а каждую ночь работает регулярная сборка, собирающая все конфигурации и прогоняющая все тесты. Каждая собранная и проверенная ночная сборка помечается тэгом — так, чтобы разработчик, создавая ветку для задачи или вливая изменения из основной ветки, был уверен, что работает с компилирующейся и работоспособной копией. Сейчас мы работаем над тем, чтобы регулярная сборка запускалась чаще и включала больше тестов. Конечная цель этой работы — обнаружение ошибки тестами (если её можно обнаружить тестами) в течение не более двух часов после коммита, чтобы найденная ошибка была исправлена до конца рабочего дня. Такое время реакции резко повышает эффективность: во-первых, самому разработчику не нужно восстанавливать контекст, с которым он работал во время привнесения ошибки, во-вторых, меньше вероятность, что ошибка заблокирует чью-нибудь ещё работу.
Но не тестами едиными жив человек! Мы используем ещё и статический анализ кода, который доказал свою эффективность за многие годы. Раз в неделю находится как минимум одна ошибка, причём часто такая, которую не поймало бы поверхностное тестирование.
Мы используем три разных анализатора:
Все они работают немного по-разному, находят разные типы ошибок и нам нравится, как они дополняют друг друга.
Помимо статических средств мы еще проверяем поведение системы в runtime при помощи инструментов Address Sanitizer (часть проекта CLang) и Valgrind.
Эти два очень разных по принципу действия инструмента используются примерно для одного и того же — поиска ситуаций неправильной работы с памятью, например
Несколько раз динамический анализ находил ошибки, которые до этого долго пытались расследовать вручную. Это послужило стимулом для организации автоматизированного периодического запуска некоторых групп тестов с включённым динамическим анализом. Постоянно использовать динамический анализ для всех групп тестов не позволяют ограничения производительности — при использовании Memory Sanitizer производительность снижается примерно в 3 раза, а при использовании Valgrind — на 1-2 порядка! Но даже их ограниченное использование дает неплохие результаты.
Помимо автоматических проверок, выполняемых машинами, мы стараемся встраивать обеспечение качества в ежедневный процесс разработки.
Наиболее широко применяемая практика для этого — peer code review. Как показывает наш опыт, постоянные инспекции кода не столько отлавливают конкретные ошибки (хотя и это периодически происходит), сколько предотвращают их появление за счёт обеспечения более читаемого и хорошо организованного кода, т.е. обеспечивают качество «в долгую».
Другие цели преследует ручная проверка работы друг друга программистами внутри группы — оказывается, даже поверхностное тестирование не погруженным в задачу человеком помогает выявить ошибки на раннем этапе, ещё до того, как задача влита в ствол.
Но самым эффективным из всех организационных мер оказывается подход, который в Microsoft называется «eat your own dogfood», при котором разработчики продукта оказываются первыми его пользователями. В нашем случае «продуктом» оказывается наш таск-трекер (упомянутая выше «База задач»), с которой разработчик работает в течение дня. Каждый день эта конфигурация переводится на последнюю собранную на CI версию платформы, и все недочеты и недостатки сразу сказываются на их авторах.
Хочется подчеркнуть, что «База задач» — серьёзная информационная система, хранящая информацию о десятках тысяч задач и ошибок, а число пользователей превышает сотню. Это не сравнимо с самыми крупными внедрениями 1С: Предприятия, но вполне сопоставимо с фирмой среднего размера. Конечно, не все механизмы можно проверить таким способом (например, никак не задействована бухгалтерская подсистема), но для того, чтобы увеличить покрытие проверяемого функционала, есть договоренность, что разные группы разработчиков используют разные способы подключения, например, кто-то использует Web-клиент, кто-то тонкий клиент на Windows, а кто-то на Linux. Кроме того, используется несколько экземпляров сервера базы задач, работающие в разных конфигурациях (разные версии, разные ОС и т.д.), которые синхронизируются между собой, используя входящие в платформу механизмы.
Помимо Базы задач есть и другие «подопытные» базы, но менее функциональные и менее нагруженные.
Развитие системы обеспечения качества будет продолжаться и дальше (да и вообще, вряд ли когда-нибудь можно поставить точку на этом пути), а сейчас мы готовы поделиться некоторыми выводами:
И ещё один вывод, который не следует прямо из статей, но послужит анонсом следующих: самое лучшее тестирование фреймворка — это тестирование построенных на нем прикладных приложений. Но о том, как мы тестируем Платформу с применением прикладных решений, таких как «1С:Бухгалтерия», мы расскажем в одной из следующих статей.
В этой статье мы расскажем, как построен процесс разработки платформы «1С:Предприятие», как мы работаем над обеспечением качества, и поделимся уроками, которые получили, создавая один из самых больших российских программных комплексов.
Люди и процессы
Над платформой трудятся несколько групп до 10 программистов в каждой, три четверти из которых пишут на C++, а остальные — на Java и JavaScript.
Каждая группа работает над отдельным направлением развития, например:
- Средства разработки (Конфигуратор)
- Веб-клиент
- Серверная инфраструктура и отказоустойчивый кластер
- и т.д.
Всего групп более десятка. Отдельно есть группа обеспечения качества.
Конечно, на проекте такого размера (более 10 миллионов строк кода) речь об общем владении кода не идёт, удержать в голове такой объем невозможно. Мы стараемся двигаться к тому, чтобы обеспечить "фактор автобуса" в группе не ниже двух.
Мы стараемся выдерживать баланс между самостоятельностью команд, дающей гибкость и повышающей скорость разработки, и однородностью, позволяющей командам эффективно взаимодействовать между собой и внешним миром. Так, у нас общая система контроля версий, сервер сборки и таск-трекер (речь о них пойдёт ниже), а также стандарт кодирования на C++, шаблоны проектной документации, регламент обработки ошибок, пришедших от пользователей и некоторые другие аспекты. Правила, которые должны выполнять все команды, вырабатываются и принимаются общим решением руководителей групп.
С другой стороны, в практиках, которые направлены «вовнутрь», команды достаточно автономны. Например, инспекции кода сейчас применяются во всех командах (и существуют общие правила, определяющие обязательность прохождения ревью), но были внедрены в разное время и процесс построен по разным правилам.
То же самое касается организации процесса — кто-то практикует варианты Agile, кто-то использует другие стили ведения проекта. Канонического SCRUM, кажется, нет нигде — специфика коробочного продукта накладывает свои ограничения. Например, замечательная практика демонстрации оказывается неприменимой в неизменном виде. Другие практики, например, роль Product Owner, имеют у нас свои аналоги. В качестве Product Owner по своему направлению обычно выступает руководитель группы. Помимо технического лидерства в команде, одной из самых главных его задач является определение дальнейших направлений развития. Процессы выработки стратегии и тактики развития платформы – это сложная и интересная тема, которой мы посвятим отдельную статью.
Работа над задачами
Когда принято решение о реализации того или иного функционала, его облик определяется в серии обсуждений, в которых участвуют, как минимум, разработчик, ответственный за задачу и руководитель группы. Часто привлекаются другие члены команды или сотрудники из других групп, обладающие нужной экспертизой. Окончательный вариант утверждается руководством разработки платформы 1С: Предприятия.
В таких обсуждениях принимаются решения:
- что входит, а что не входит в scope задачи
- какие мы представляем себе сценарии использования. Еще важнее понять, какие возможные сценарии мы не будем поддерживать
- как будут выглядеть пользовательские интерфейсы
- как будут выглядеть API для прикладного разработчика
- как новый механизм будет сочетаться с уже существующими
- что будет с безопасностью
- и т.д.
Кроме того, последнее время мы стараемся обсуждать задачу с более широким кругом потенциальных потребителей — например, на прошедшем открытом семинаре мы рассказали о находящихся в процессе проектирования новых возможностях работы с двоичными данными, ответили на вопросы и сумели выделить из обсуждения несколько возможных случаев применения, о которых не думали ранее.
При начале работы над новой функцией для неё создаётся задача в таск-трекере. Трекер, кстати, написан на «1С:Предприятие» и бесхитростно называется «База задач». Для каждой задачи в таск-трекере хранится проектный документ — по сути, спецификация на задачу. Он состоит из трех главных частей:
- Анализ проблемы и вариантов решения
- Описание выбранного решения
- Описания технических деталей реализации
Подготовка проектного документа может начинаться до реализации, а может стартовать и позже, если для задачи сначала делается какое-то исследование или прототип. В любом случае это итеративный процесс, не похожий на водопадную модель, развитие и уточнение проектного документа делается параллельно с реализацией. Главное, чтобы к моменту, когда задача была готова, проектный документ был утверждён во всех деталях. А таких деталей может быть множество, например:
- Единство используемых терминов. Если в одном месте Платформы в похожей ситуации был использован термин «записать», то использование «сохранить» должно быть очень серьёзно оправданным
- Единство подходов. Иногда ради упрощения изучения и единого опыта использования приходится повторять в новых задачах старые подходы, даже если очевидны их минусы
- Совместимость. В тех случаях, когда старое поведение сохранять нельзя, нужно все равно подумать о совместимости. Часто бывает, что прикладные решения могут быть завязаны на ошибку и резкое изменение повлечёт неработоспособность на стороне конечных пользователей. Поэтому, мы часто оставляем старое поведение «в режиме совместимости». Существующие конфигурации, запущенные на новом релизе платформы будут использовать «режим совместимости» до тех пор, пока их разработчиком не будет принято сознательное решение о его отключении.
Кроме того, в проекте тезисно фиксируются обсуждения задачи, так, чтобы позднее можно было понять почему были приняты или отвергнуты те или иные варианты.
После того, как проект утверждён и разработчик реализовал новый функционал в ветке задачи (feature branch) в SVN (а при разработке новой IDE — в Git), задача проходит инспекцию кода и ручную проверку другими членами группы. Кроме того, на ветке задачи прогоняются автоматические тесты, о которых рассказывается ниже. На этом же этапе создаётся еще один технический документ – описание задачи, который предназначен для тестировщиков и технических писателей. В отличие от проекта документ не содержит технических деталей реализации, но зато структурирован так, что помогает быстро понять, какие разделы документации нужно дополнить, привносит ли новая функция несовместимые изменения и т.д.
Проверенная и исправленная задача вливается в основную ветку релиза и становится доступной группе тестирования.
Уроки и рецепты
- Ценность проектного документа, как любой документации, не всегда бывает очевидна. Для нас она в следующем:
- Во время проектирования помогает всем участникам быстро восстановить контекст обсуждения и быть уверенными, что принятые решения не будут забыты или искажены
- Позже, в сомнительных ситуациях, когда мы не уверены в правильности поведения, проектный документ помогает вспомнить само решение и мотивацию, которая стояла за его принятием.
- Проектный документ служит отправной точкой для пользовательской документации. Разработчику не нужно что-то писать с нуля или устно объяснять техническим писателям — уже есть готовая основа.
- Всегда нужно описывать сценарии использования создаваемого функционала, причём не общими фразами, а чем подробнее, тем лучше. Если этого не делать, то могут получаться решения, которые будет использовать или неудобно, или невозможно, а причиной может служить какая-нибудь маленькая деталь. В Agile-разработке такие детали легко поправить на следующей итерации, а в нашем случае до пользователя исправление может дойти через годы (полный цикл: пока будет выпущена финальная версия платформы-> выпущены конфигурации, использующие нововведения -> будет собрана обратная связь от пользователей -> сделано исправление -> выпущена новая версия -> обновлены конфигурации с учётом исправления -> пользователь поставит себе новую версию конфигурации).
- Ещё лучше, чем сценарии, помогает использование прототипа реальными пользователями (разработчиками конфигураций) до официального выпуска версии и фиксации поведения. Эта практика у нас только начинает широко использоваться, и почти во всех случаях приносила ценное знание. Часто это знание могло быть не связано с функциональными возможностями, а относилось к нефункциональным особенностям поведения (например, наличие логирования или лёгкость диагностики ошибок).
- Точно так же нужно заранее определяться с критериями производительности и проверять их выполнение. Пока эти требования не добавили в чеклист при сдаче задачи, это делалось не всегда.
Обеспечение качества
Вообще, «качество» и «обеспечение качества» — очень широкие термины. Как минимум, можно выделить два процесса — верификацию и валидацию. Под верификацией обычно понимают соответствие поведения ПО спецификации и отсутствие других явных ошибок, а под валидацией — проверку на соответствие потребностям пользователя. В этом разделе речь пойдёт об обеспечении качества в смысле верификации.
Тестировщики получают доступ к задаче уже после ее вливания, но процесс обеспечения качества начинается намного раньше. В последнее время нам пришлось приложить значительные усилия по его совершенствованию, т.к. стало очевидно, что существовавшие механизмы стали недостаточно адекватны увеличившемуся объёму функционала и заметно возросшей сложности. Эти усилия, по отзывам партнёров о новой версии 8.3.6, как нам кажется, уже дали эффект, но много работы, конечно, ещё впереди.
Существующие механизмы обеспечения качества можно условно разделить на организационные и технологические. Начнём с последних.
Тесты
Когда речь заходит о механизмах обеспечения качества, сразу на ум приходят тесты. Мы, конечно, их тоже используем, причём в нескольких вариантах:
Unit-тесты
На C++ мы пишем unit-тесты. Как уже упоминалось в предыдущей статье, мы используем модифицированные варианты Google Test и Google Mock. Например, типичный тест, проверяющий экранирование символа амперсанда ("&") при записи JSON, может выглядеть так:
TEST(TestEscaping, EscapeAmpersand)
{
// Arrange
IFileExPtr file = create_instance<ITempFile>(SCOM_CLSIDOF(TempFile));
JSONWriterSettings settings;
settings.escapeAmpersand = true;
settings.newLineSymbols = eJSONNewLineSymbolsNone;
JSONStreamWriter::Ptr writer = create_json_writer(file, &settings);
// Act
writer->writeStartObject();
writer->writePropertyName(L"_&_Prop");
writer->writeStringValue(L"_&_Value");
writer->writeEndObject();
writer->close();
// Assert
std::wstring result = helpers::read_from_file(file);
std::wstring expected = std::wstring(L"{\"_\\u0026_Prop\":\"_\\u0026_Value\"}");
ASSERT_EQ(expected, result);
}
Интеграционные тесты
Следующий уровень тестирования — интеграционные тесты, написанные на языке «1С:Предприятие». Именно они образуют основную часть наших тестов. Типичный набор тестов представляет собой отдельную информационную базу, хранящуюся в *.dt файле. Инфраструктура тестов загружает эту базу и вызывает в ней заранее известный метод, который вызывает уже отдельные тесты, написанные разработчиками, и форматирует их результаты так, чтобы их могла интерпретировать инфраструктура CI (Continuous Integration).
&НаСервере
Процедура тест_Массив_Простой() Экспорт
ИмяФайла = ПолучитьИмяВременногоФайла("json");
ИмяЭталона = "эталон_Массив_Простой";
Значение = Общие.ПолучитьПростойМассив();
ЗаписьJSON = ПолучитьОткрытуюЗаписьJSON(ИмяФайла);
ЗаписатьJSON(ЗаписьJSON, Значение);
ЗаписьJSON.Закрыть();
Общие.СравнитьФайлСЭталоном(ИмяФайла, ИмяЭталона);
КонецПроцедуры
В данном случае, если результат записи разойдётся с эталоном, вылетит исключение, которое инфраструктура перехватит и интерпретирует как провал теста.
Наша система CI сама выполняет эти тесты под различные версии ОС и СУБД, включая 32- и 64-разрядные Windows и Linux, а из СУБД — MS SQL Server, Oracle, PostgreSQL, IBM DB2, а также нашу собственную файловую базу.
Пользовательские тестовые системы
Третий и самый громоздкий вид тестов — это т.н. «Пользовательские тестовые системы». Они применяются тогда, когда проверяемый сценарий выходит за пределы одной базы на 1С, например, при тестировании взаимодействия с внешними системами через веб-сервисы. Для каждой группы тестов выделяется одна или несколько виртуальных машин, на каждую из которых устанавливается специальная программа-агент. В остальном разработчик теста имеет полную свободу, ограниченную только требованием выдавать результат в виде файла в формате Google Test, который может быть прочитан CI.
Например, для тестирования клиента SOAP веб-сервисов используется сервис, написанный на C#, а для проверки различных возможностей конфигуратора — объёмный фреймворк тестов, написанных на питоне.
Оборотной стороной такой свободы является необходимость ручной настройки тестов под каждую ОС, управление парком виртуальных машин и прочие накладные расходы. Поэтому, по мере развития наших интеграционных тестов (описанных в предыдущем разделе), мы планируем ограничивать использование пользовательских тестовых систем.
Упомянутые выше тесты пишут сами разработчики платформы, на С++ или создавая небольшие конфигурации (прикладные решения), заточенные под тестирование конкретного функционала. Это является необходимым условием отсутствия ошибок, но не достаточным, особенно в такой системе как платформа 1С: Предприятие, где большая часть возможностей не являются прикладными (используемыми пользователем напрямую), а служат основой для построения прикладных программ. Поэтому существует ещё один эшелон тестирования: автоматизированные и ручные сценарные тесты на реальных прикладных решениях. К этой же группе можно отнести и нагрузочные тесты. Это интересная и большая тема, про которую мы планируем отдельную статью.
При этом все виды тестов выполняются на CI. В качестве сервера непрерывной интеграции используется Jenkins. Вот как он выглядит на момент написания статьи:
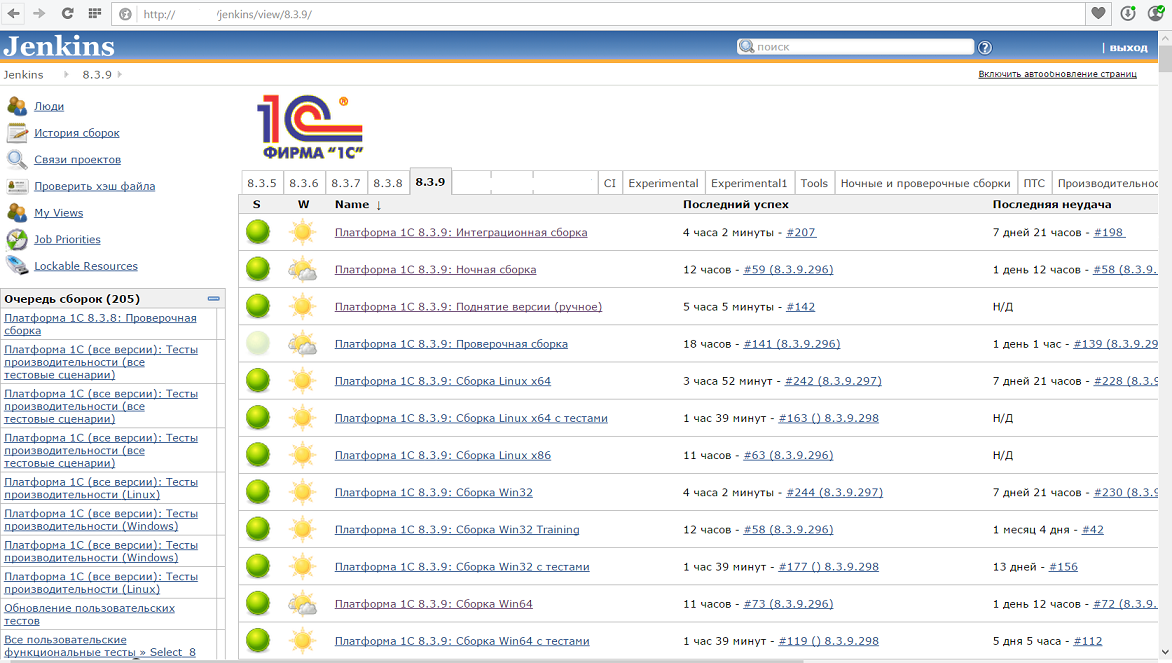
Для каждой конфигурации сборки(Windows x86 и x64, Linux x86 и x64) заведены свои задачи по сборке, которые запускаются параллельно на разных машинах. Сборка одной конфигурации занимает длительное время — даже на мощном оборудовании компиляция и линковка больших объёмов C++ представляет непростую задачу. Кроме того, создание пакетов под Linux (deb и rpm), как оказалось, занимает сопоставимое с компиляцией время.
Поэтому в течение дня работает «укороченная сборка», которая проверяет компилируемость под Windows x86 и Linux x64 и выполняет минимальный набор тестов, а каждую ночь работает регулярная сборка, собирающая все конфигурации и прогоняющая все тесты. Каждая собранная и проверенная ночная сборка помечается тэгом — так, чтобы разработчик, создавая ветку для задачи или вливая изменения из основной ветки, был уверен, что работает с компилирующейся и работоспособной копией. Сейчас мы работаем над тем, чтобы регулярная сборка запускалась чаще и включала больше тестов. Конечная цель этой работы — обнаружение ошибки тестами (если её можно обнаружить тестами) в течение не более двух часов после коммита, чтобы найденная ошибка была исправлена до конца рабочего дня. Такое время реакции резко повышает эффективность: во-первых, самому разработчику не нужно восстанавливать контекст, с которым он работал во время привнесения ошибки, во-вторых, меньше вероятность, что ошибка заблокирует чью-нибудь ещё работу.
Статический и динамический анализ
Но не тестами едиными жив человек! Мы используем ещё и статический анализ кода, который доказал свою эффективность за многие годы. Раз в неделю находится как минимум одна ошибка, причём часто такая, которую не поймало бы поверхностное тестирование.
Мы используем три разных анализатора:
- CppCheck
- PVS-Studio
- Встроенный в Microsoft Visual Studio
Все они работают немного по-разному, находят разные типы ошибок и нам нравится, как они дополняют друг друга.
Помимо статических средств мы еще проверяем поведение системы в runtime при помощи инструментов Address Sanitizer (часть проекта CLang) и Valgrind.
Эти два очень разных по принципу действия инструмента используются примерно для одного и того же — поиска ситуаций неправильной работы с памятью, например
- обращений к неинициализированной памяти
- обращений к освобождённой памяти
- выходов за границы массива и т.д.
Несколько раз динамический анализ находил ошибки, которые до этого долго пытались расследовать вручную. Это послужило стимулом для организации автоматизированного периодического запуска некоторых групп тестов с включённым динамическим анализом. Постоянно использовать динамический анализ для всех групп тестов не позволяют ограничения производительности — при использовании Memory Sanitizer производительность снижается примерно в 3 раза, а при использовании Valgrind — на 1-2 порядка! Но даже их ограниченное использование дает неплохие результаты.
Организационные меры обеспечения качества
Помимо автоматических проверок, выполняемых машинами, мы стараемся встраивать обеспечение качества в ежедневный процесс разработки.
Наиболее широко применяемая практика для этого — peer code review. Как показывает наш опыт, постоянные инспекции кода не столько отлавливают конкретные ошибки (хотя и это периодически происходит), сколько предотвращают их появление за счёт обеспечения более читаемого и хорошо организованного кода, т.е. обеспечивают качество «в долгую».
Другие цели преследует ручная проверка работы друг друга программистами внутри группы — оказывается, даже поверхностное тестирование не погруженным в задачу человеком помогает выявить ошибки на раннем этапе, ещё до того, как задача влита в ствол.
Eat your own dogfood
Но самым эффективным из всех организационных мер оказывается подход, который в Microsoft называется «eat your own dogfood», при котором разработчики продукта оказываются первыми его пользователями. В нашем случае «продуктом» оказывается наш таск-трекер (упомянутая выше «База задач»), с которой разработчик работает в течение дня. Каждый день эта конфигурация переводится на последнюю собранную на CI версию платформы, и все недочеты и недостатки сразу сказываются на их авторах.
Хочется подчеркнуть, что «База задач» — серьёзная информационная система, хранящая информацию о десятках тысяч задач и ошибок, а число пользователей превышает сотню. Это не сравнимо с самыми крупными внедрениями 1С: Предприятия, но вполне сопоставимо с фирмой среднего размера. Конечно, не все механизмы можно проверить таким способом (например, никак не задействована бухгалтерская подсистема), но для того, чтобы увеличить покрытие проверяемого функционала, есть договоренность, что разные группы разработчиков используют разные способы подключения, например, кто-то использует Web-клиент, кто-то тонкий клиент на Windows, а кто-то на Linux. Кроме того, используется несколько экземпляров сервера базы задач, работающие в разных конфигурациях (разные версии, разные ОС и т.д.), которые синхронизируются между собой, используя входящие в платформу механизмы.
Помимо Базы задач есть и другие «подопытные» базы, но менее функциональные и менее нагруженные.
Выученные уроки
Развитие системы обеспечения качества будет продолжаться и дальше (да и вообще, вряд ли когда-нибудь можно поставить точку на этом пути), а сейчас мы готовы поделиться некоторыми выводами:
- В таком большом и массово используемом продукте дешевле написать тест, чем не написать. Если в функциональности есть ошибка и она будет пропущена — затраты конечных пользователей, партнеров, службы поддержки и даже одного отдела разработки, связанные с воспроизведением, исправлением и последующей проверкой ошибки будут куда больше.
- Даже если написание автоматических тестов затруднительно, можно попросить разработчика подготовить формализованное описание ручных тестов. Прочитав его, можно будет найти лакуны в том, как разработчик проверял своё детище, а значит, и потенциальные ошибки.
- Создание инфраструктуры для CI и тестов — дело затратное и по финансам, и по времени. Особенно, если приходится это делать для уже зрелого проекта. Поэтому начинайте как можно раньше!
И ещё один вывод, который не следует прямо из статей, но послужит анонсом следующих: самое лучшее тестирование фреймворка — это тестирование построенных на нем прикладных приложений. Но о том, как мы тестируем Платформу с применением прикладных решений, таких как «1С:Бухгалтерия», мы расскажем в одной из следующих статей.
