Ола, Хабрасообщество!
Данный доклад изначально был подготовлен для выступления на конференции компании FastVPS ROCK IT 2013, прошедшей 24-25 августа 2013 года в Городе Tallinn, Estonia.
Возможно, кто-то слышал его лично (спасибо!), но все равно рекомендую ознакомиться, так как данная публикация является более подробной и рассматривает намного больше опущенных в докладе деталей (smile)
Публикация имеет целью провести краткий обзор имеющихся на рынке open source средств для развертывания нескольких виртуальных окружений на базе физического сервера с Linux на борту, а также рассказать о преимуществах использования контейнеров для создания облаков :)
Встречайте героев сегодняшнего рассказа!

Поименно:
Таблица: сравнение имеющихся технологий для реализации виртуальных окружений в Linux

Хотелось бы отметить, что Oracle VirtualBox был не включен в таблицу осознанно, так как не является полностью открытым, а в статье мы рассматриваем только открытые технологии.
Данная таблица позволяет легко сделать выводы, что готовых для промышленного использования технологий на сегодняшний день всего три: KVM, Xen и OpenVZ. Также очень активными темпами развивается технология LXC и по этой причине мы просто обязаны ее рассмотреть. Все четыре технологии в свою очередь реализуют два подхода к изоляции — полная виртуализация и контейнеризация, о них мы и поговорим.
Давайте отойдем от сугубо теоретических описаний и посмотрим наглядную схему на примере KVM.
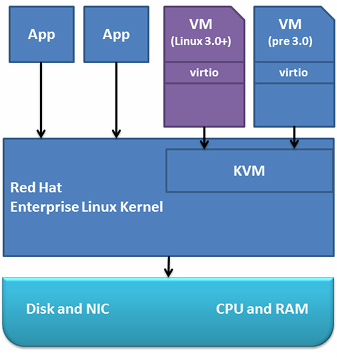
Как Вы видите, у нас имеется три уровня:
Все взаимодействие здесь довольно прозрачно — базовое ядро Linux (HWN) взаимодействует с железом (процессор, память, ввод-вывод), и в свою очередь обеспечивает возможность работы процессов, в которых и крутятся с помощью специального модуля ядра полноценные ядра Linux, FreeBSD или даже Windows. Стоит обратить внимание, что это не совсем обычные процессы, работа виртуальных машин обеспечивается посредством модуля ядра (KVM) осуществляющего трансляцию системных вызовов из клиентской операционной системы к HWN. Данное описание работы нельзя считать полностью корректным, но оно полностью передает смысл данного подхода.Самое важное на что стоит обратить внимание, что трансляция из вызовов клиентской ОС в вызовы HWN осуществляется с помощью специальной технологии процессора (AMD-V, Intel VT).
Недостатки данного типа изоляции сводятся к дополнительным задержкам в работе дисковой подсистемы, сетевой подсистемы, памяти, процессора из-за использования дополнительного аппаратно-программного слоя абстракции между реальным железом и виртуальной средой. Силами различных технологий и подходов (например, программный virtio, аппаратный VT-d) эти задержки сводятся к минимуму, но устранить их полностью не удастся никогда (разве что виртуализацию встроят в железо) по причине того, что это дополнительный слой абстракции, за который нужно платить.
Согласно недавним исследованиям IBM оверхед (это разница между производительностью приложения внутри виртуального окружения и того же приложения работающего без использования виртуализации вообще) технологии KVM при вводе-выводе составляет около 15% при тестировании на SUSE Linux Enterprise Server 11 Service Pack 3.
Также есть очень интересное тестирование, представленное в Journal of Physics: Conference 219 (2010), в котором озвучиваются цифры: 3-4% оверхед для процессора, и 20-30% для дискового ввода-вывода.
В это же время в презентации RedHat за 2013й год озвучивается цифра в 12% (то есть 88% производительности конфигурации работающей без виртуализации).
Разумеется, эти тесты проведены в разных конфигурациях ПО, для разных паттернов нагрузки, для разного оборудования и я даже допускаю, что часть из них проведены некорректно, но суть их сводится к одному — накладные расходы (оверхед) при использовании как KVM, так и Xen достигают 5-15% в зависимости от типа используемого по и конфигурации системы. Согласитесь, немало?
Поступим аналогично, воспользуемся иллюстрацией.

Сразу хочется оговорится, что все сказанное ниже справедливо как для OpenVZ, так и для LXC. Эти технологии очень и очень похожи и являются крайне близкими родственниками (эту тему я постараюсь раскрыть в следующей своей публикации).
Хоть и изображение нарисовано в немного ином стиле, сразу же бросается в глаза ключевое отличие — ядро используется лишь одно и никаких виртуальных машин (VM) нет в помине! Но как же оно работает? На низком уровне все происходит аналогично — Linux ядро HWN взаимодействует с аппаратным обеспечение и выполняет все запросы, касающиеся обращения к аппаратной части, из виртуальных окружений. Но как же виртуальные окружения отделены друг от друга? Они отделены с помощью встроенных в Linux ядро механизмов!
В первую очередь это видоизмененный аналог chroot (видоизменения касаются в первую очередь защиты, чтобы не было возможности вырваться из chroot'нутого окружения в корневую файловую систему), который всем нам хорошо знаком, он позволяет создать изолированные друг от друга иерархии внутри одной файловой системы. Но chroot не позволяет, например, запустить свой собственный init процесс (pid 1, так как на HWN уже существует init процесс с данными PID), а это обязательное требование, если мы хотим иметь полностью изолированную клиентскую ОС внутри контейнера. Для этого используется механизм PID namespaces, который внутри каждого chroot окружения создает полностью независимую от HWN систему идентификаторов процессов, где мы можем иметь свой собственный процесс с PID 1 даже если на самом сервере уже запущен init процесс. В общем случае, мы можем создать сотни и даже тысячи отдельных контейнеров, никак не связанных друг с другом.
Как же при этом ограничивается память, нагрузка на процессор и жесткий диск? Они ограничиваются также посредством механизма cgroups, который, к слову, также используется и для точь-в-точь тех же самых целей в технологии KVM.
Как мы обсуждали ранее, любая технология изоляции имеет оверхед, хотим мы этого или не хотим. Но в случае контейнеризации этот оверхед ничтожно мал (0.1-1%) за счет того, что используются очень простые преобразования, который зачастую можно объяснить буквально на пальцах. Например, изоляция PID процессов и пространств сокетов осуществляется посредством добавления дополнительного 4-х байтного идентификатора, обозначающего, к какому контейнеру принадлежит процесс. С памятью все немного сложнее и происходит ее определенная потеря (из-за особенностей выделения памяти), но на скорость выделения и работы с памятью это почти не влияет. С дисковой системой и подсистемой ввода вывода ситуация аналогична. В цифрах оценки оверхеда для OpenVZ приводятся в работах — инженеров HP и исследователей из Университета Бразилии для HPC и они находятся в районе 0.1-1% в зависимости от типа нагрузки и методики тестирования.
Вот мы и подошли к теме заявленной в самом начале! Мы обсудили оверхед технологий полной виртуализации и технологий контейнеризации, теперь самое время сравнить их напрямую между собой. Обращаю внимание, что в некоторых тестах вместо OpenVZ используется его коммерческая версия PCS, это имеет минимальное влияние на тесты, так как ядро используемое как в открытой, так и коммерческой ОС полностью идентично.
В сети довольно мало качественно проведенных тестов с участием всех трех игроков и почти все они проведены компанией Parallels, которая в свою очередь разработчик OpenVZ. Если приводить такие тесты без возможности их проверки и повторения — могут возникнуть вопросы о предвзятости.
Я довольно долго думал как этого добиться и мне в руки попался чудесный документ, в котором KVM, XEN и OpenVZ/PCS тестируются на основе тестовой методологии разработанной компанией Intel — vConsolidate, а также стандартизированного LAMP теста, что позволяет проверить все результаты в домашних условиях и убедиться в их истинности.
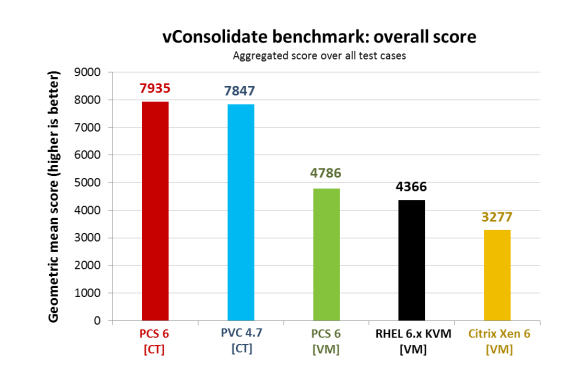
Так как данный тест сугубо в попугаях, я не стал приводить его промежуточных графиков и вывел итоговые результаты. Как можно видеть — преимущество OpenVZ на лицо. Разумеется, компания Intel учла многое в своем тесте, но все же очень сложно интерпретировать эти цифры.
Поэтому предлагаю более понятный LAMP тест, из того же документа от Parallels, он тестирует производительность LAMP приложения в зависимости от числа запущенных виртуальных окружений:

Тут все намного понятнее и четко виден почти 2-х кратный прирост в суммарном числе транзакций выполняемых LAMP приложением! Чего же еще можно пожелать? :)
Разумеется, можно было охватить еще больше тестов, но, к сожалению, мы итак сильно вышли за рамки типовой Хабра-статьи, поэтому милости прошу вот сюда.
Надеюсь, я смог Вас убедить в том, что решения на базе контейнеризации позволяют выжать из железа почти всю возможную его мощность
В данной статье мы попробовали доказать, что эффективность использования аппаратных ресурсов при использовании контейнеризации вместо полной виртуализации позволяет экономить до 10% (мы берем среднюю оценку) всех вычислительных ресурсов сервера. Довольно сложно судить в процентах, намного проще представить, что у Вас было 100 серверов и они решали некую задачу с использованием полной виртуализации, то внедрив контейнеризацию можно освободить почти 10 полноценных серверов, которые потребляют много электричества, занимают место (которое стоит очень дорого в случае современных ЦОД), стоят сами по себе много денег, а также требуют персонала для их обслуживания.
Как же уйти от абстрактных «дорого» к реальным цифрам? Наиболее весомую экономию нам дает экономия на электричестве. Затраты на электричество, по данным Intel, составляют почти 10% всех операционных затрат на эксплуатацию Дата Центров. Которые в свою очередь, по данным Агентства Защиты Окружающей среды, US EPA, потребляют суммарно почти 1.5% всего электричества вырабатываемого в США. Таким образом, мы не просто экономим средства компаний, но и вносим значительный вклад в сохранение экологии за счет меньшего потребления электричества и более эффективного его использования!
Также стоит отметить, что самые крупные системы вычислений в мире — собственные облака Google, Yandex, Heroku и многих-многих других построены именно с использование технологии LXC, что еще раз доказывает преимущество контейнеризации в облачных вычислениях и показывает на примере реальных компаний.
Кроме того, обе озвученные технологии контейнеризации — OpenVZ и LXC имеют свободные лицензии и крайне активно развиваются и LXC (пусть, частично) есть на почти любом Linux сервере установленном в последние год-полтора. Открытые лицензии и активное сообщество разработчиков — залог успеха технологии в ближайшем будущем.
В ближайших публикациях мы остановимся на технологиях OpenVZ и LXC, а также обязательно проведем их сравнительный анализ :)
Update, продолжение серии публикаций:
Отдельно хотелось бы поблагодарить Василия Аверина (Parallels) за объяснение особо сложных аспектов технологии LXC.
C уважением, Павел Одинцов
CTO FastVPS LLC
Введение
Данный доклад изначально был подготовлен для выступления на конференции компании FastVPS ROCK IT 2013, прошедшей 24-25 августа 2013 года в Городе Tallinn, Estonia.
Возможно, кто-то слышал его лично (спасибо!), но все равно рекомендую ознакомиться, так как данная публикация является более подробной и рассматривает намного больше опущенных в докладе деталей (smile)
Публикация имеет целью провести краткий обзор имеющихся на рынке open source средств для развертывания нескольких виртуальных окружений на базе физического сервера с Linux на борту, а также рассказать о преимуществах использования контейнеров для создания облаков :)
Open source решения на базе Linux для создания виртуальных окружений
Встречайте героев сегодняшнего рассказа!

Поименно:
- KVM
- Xen
- Linux VServer
- OpenVZ
- LXC (Linux Containers)
Таблица: сравнение имеющихся технологий для реализации виртуальных окружений в Linux

Хотелось бы отметить, что Oracle VirtualBox был не включен в таблицу осознанно, так как не является полностью открытым, а в статье мы рассматриваем только открытые технологии.
Данная таблица позволяет легко сделать выводы, что готовых для промышленного использования технологий на сегодняшний день всего три: KVM, Xen и OpenVZ. Также очень активными темпами развивается технология LXC и по этой причине мы просто обязаны ее рассмотреть. Все четыре технологии в свою очередь реализуют два подхода к изоляции — полная виртуализация и контейнеризация, о них мы и поговорим.
Полная виртуализация
Давайте отойдем от сугубо теоретических описаний и посмотрим наглядную схему на примере KVM.
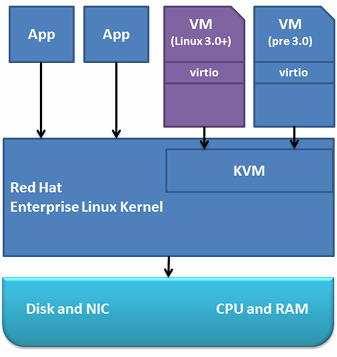
Как Вы видите, у нас имеется три уровня:
- Аппаратное обеспечение (Disk, NIC, CPU, Memory на изображении — система хранения, сетевые устройства, процессор и память)
- Linux ядро (совершенно любое, из любого более-менее современного дистрибутива, но рекомендуется 2.6.32 и выше; для определенности назовем его HWN, HardWare Node)
- Виртуальные машины (клиентские ОС), работающие как обычные процессы в Linux системе рядом с обычными Linux демонами
Все взаимодействие здесь довольно прозрачно — базовое ядро Linux (HWN) взаимодействует с железом (процессор, память, ввод-вывод), и в свою очередь обеспечивает возможность работы процессов, в которых и крутятся с помощью специального модуля ядра полноценные ядра Linux, FreeBSD или даже Windows. Стоит обратить внимание, что это не совсем обычные процессы, работа виртуальных машин обеспечивается посредством модуля ядра (KVM) осуществляющего трансляцию системных вызовов из клиентской операционной системы к HWN. Данное описание работы нельзя считать полностью корректным, но оно полностью передает смысл данного подхода.Самое важное на что стоит обратить внимание, что трансляция из вызовов клиентской ОС в вызовы HWN осуществляется с помощью специальной технологии процессора (AMD-V, Intel VT).
Недостатки данного типа изоляции сводятся к дополнительным задержкам в работе дисковой подсистемы, сетевой подсистемы, памяти, процессора из-за использования дополнительного аппаратно-программного слоя абстракции между реальным железом и виртуальной средой. Силами различных технологий и подходов (например, программный virtio, аппаратный VT-d) эти задержки сводятся к минимуму, но устранить их полностью не удастся никогда (разве что виртуализацию встроят в железо) по причине того, что это дополнительный слой абстракции, за который нужно платить.
Затраты на реализацию полной виртуализации
Согласно недавним исследованиям IBM оверхед (это разница между производительностью приложения внутри виртуального окружения и того же приложения работающего без использования виртуализации вообще) технологии KVM при вводе-выводе составляет около 15% при тестировании на SUSE Linux Enterprise Server 11 Service Pack 3.
Также есть очень интересное тестирование, представленное в Journal of Physics: Conference 219 (2010), в котором озвучиваются цифры: 3-4% оверхед для процессора, и 20-30% для дискового ввода-вывода.
В это же время в презентации RedHat за 2013й год озвучивается цифра в 12% (то есть 88% производительности конфигурации работающей без виртуализации).
Разумеется, эти тесты проведены в разных конфигурациях ПО, для разных паттернов нагрузки, для разного оборудования и я даже допускаю, что часть из них проведены некорректно, но суть их сводится к одному — накладные расходы (оверхед) при использовании как KVM, так и Xen достигают 5-15% в зависимости от типа используемого по и конфигурации системы. Согласитесь, немало?
Контейнеризация
Поступим аналогично, воспользуемся иллюстрацией.
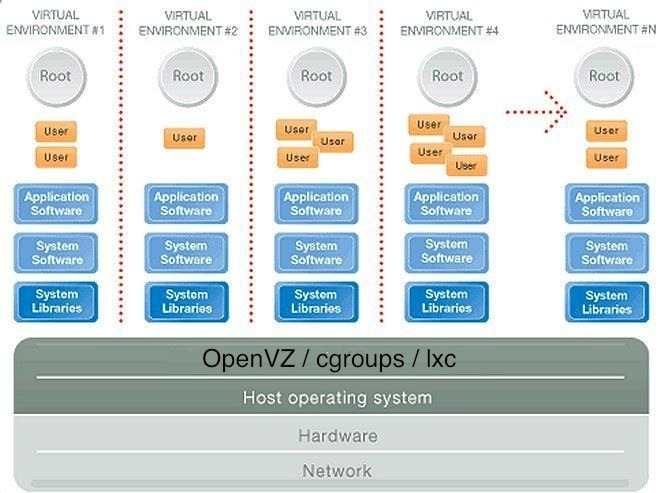
Сразу хочется оговорится, что все сказанное ниже справедливо как для OpenVZ, так и для LXC. Эти технологии очень и очень похожи и являются крайне близкими родственниками (эту тему я постараюсь раскрыть в следующей своей публикации).
Хоть и изображение нарисовано в немного ином стиле, сразу же бросается в глаза ключевое отличие — ядро используется лишь одно и никаких виртуальных машин (VM) нет в помине! Но как же оно работает? На низком уровне все происходит аналогично — Linux ядро HWN взаимодействует с аппаратным обеспечение и выполняет все запросы, касающиеся обращения к аппаратной части, из виртуальных окружений. Но как же виртуальные окружения отделены друг от друга? Они отделены с помощью встроенных в Linux ядро механизмов!
В первую очередь это видоизмененный аналог chroot (видоизменения касаются в первую очередь защиты, чтобы не было возможности вырваться из chroot'нутого окружения в корневую файловую систему), который всем нам хорошо знаком, он позволяет создать изолированные друг от друга иерархии внутри одной файловой системы. Но chroot не позволяет, например, запустить свой собственный init процесс (pid 1, так как на HWN уже существует init процесс с данными PID), а это обязательное требование, если мы хотим иметь полностью изолированную клиентскую ОС внутри контейнера. Для этого используется механизм PID namespaces, который внутри каждого chroot окружения создает полностью независимую от HWN систему идентификаторов процессов, где мы можем иметь свой собственный процесс с PID 1 даже если на самом сервере уже запущен init процесс. В общем случае, мы можем создать сотни и даже тысячи отдельных контейнеров, никак не связанных друг с другом.
Как же при этом ограничивается память, нагрузка на процессор и жесткий диск? Они ограничиваются также посредством механизма cgroups, который, к слову, также используется и для точь-в-точь тех же самых целей в технологии KVM.
Затраты на реализацию контейнеризации
Как мы обсуждали ранее, любая технология изоляции имеет оверхед, хотим мы этого или не хотим. Но в случае контейнеризации этот оверхед ничтожно мал (0.1-1%) за счет того, что используются очень простые преобразования, который зачастую можно объяснить буквально на пальцах. Например, изоляция PID процессов и пространств сокетов осуществляется посредством добавления дополнительного 4-х байтного идентификатора, обозначающего, к какому контейнеру принадлежит процесс. С памятью все немного сложнее и происходит ее определенная потеря (из-за особенностей выделения памяти), но на скорость выделения и работы с памятью это почти не влияет. С дисковой системой и подсистемой ввода вывода ситуация аналогична. В цифрах оценки оверхеда для OpenVZ приводятся в работах — инженеров HP и исследователей из Университета Бразилии для HPC и они находятся в районе 0.1-1% в зависимости от типа нагрузки и методики тестирования.
Контейнеризация против виртуализации
Вот мы и подошли к теме заявленной в самом начале! Мы обсудили оверхед технологий полной виртуализации и технологий контейнеризации, теперь самое время сравнить их напрямую между собой. Обращаю внимание, что в некоторых тестах вместо OpenVZ используется его коммерческая версия PCS, это имеет минимальное влияние на тесты, так как ядро используемое как в открытой, так и коммерческой ОС полностью идентично.
В сети довольно мало качественно проведенных тестов с участием всех трех игроков и почти все они проведены компанией Parallels, которая в свою очередь разработчик OpenVZ. Если приводить такие тесты без возможности их проверки и повторения — могут возникнуть вопросы о предвзятости.
Я довольно долго думал как этого добиться и мне в руки попался чудесный документ, в котором KVM, XEN и OpenVZ/PCS тестируются на основе тестовой методологии разработанной компанией Intel — vConsolidate, а также стандартизированного LAMP теста, что позволяет проверить все результаты в домашних условиях и убедиться в их истинности.
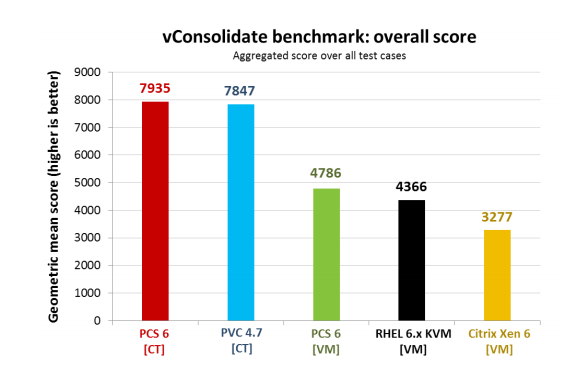
Так как данный тест сугубо в попугаях, я не стал приводить его промежуточных графиков и вывел итоговые результаты. Как можно видеть — преимущество OpenVZ на лицо. Разумеется, компания Intel учла многое в своем тесте, но все же очень сложно интерпретировать эти цифры.
Поэтому предлагаю более понятный LAMP тест, из того же документа от Parallels, он тестирует производительность LAMP приложения в зависимости от числа запущенных виртуальных окружений:
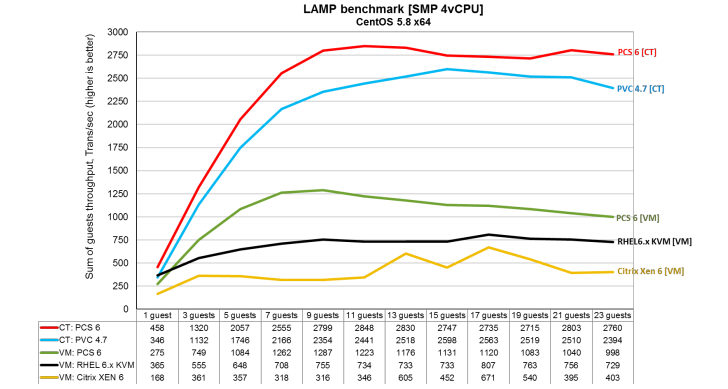
Тут все намного понятнее и четко виден почти 2-х кратный прирост в суммарном числе транзакций выполняемых LAMP приложением! Чего же еще можно пожелать? :)
Разумеется, можно было охватить еще больше тестов, но, к сожалению, мы итак сильно вышли за рамки типовой Хабра-статьи, поэтому милости прошу вот сюда.
Надеюсь, я смог Вас убедить в том, что решения на базе контейнеризации позволяют выжать из железа почти всю возможную его мощность
Контейнеризация — это будущее облаков!
В данной статье мы попробовали доказать, что эффективность использования аппаратных ресурсов при использовании контейнеризации вместо полной виртуализации позволяет экономить до 10% (мы берем среднюю оценку) всех вычислительных ресурсов сервера. Довольно сложно судить в процентах, намного проще представить, что у Вас было 100 серверов и они решали некую задачу с использованием полной виртуализации, то внедрив контейнеризацию можно освободить почти 10 полноценных серверов, которые потребляют много электричества, занимают место (которое стоит очень дорого в случае современных ЦОД), стоят сами по себе много денег, а также требуют персонала для их обслуживания.
Как же уйти от абстрактных «дорого» к реальным цифрам? Наиболее весомую экономию нам дает экономия на электричестве. Затраты на электричество, по данным Intel, составляют почти 10% всех операционных затрат на эксплуатацию Дата Центров. Которые в свою очередь, по данным Агентства Защиты Окружающей среды, US EPA, потребляют суммарно почти 1.5% всего электричества вырабатываемого в США. Таким образом, мы не просто экономим средства компаний, но и вносим значительный вклад в сохранение экологии за счет меньшего потребления электричества и более эффективного его использования!
Также стоит отметить, что самые крупные системы вычислений в мире — собственные облака Google, Yandex, Heroku и многих-многих других построены именно с использование технологии LXC, что еще раз доказывает преимущество контейнеризации в облачных вычислениях и показывает на примере реальных компаний.
Кроме того, обе озвученные технологии контейнеризации — OpenVZ и LXC имеют свободные лицензии и крайне активно развиваются и LXC (пусть, частично) есть на почти любом Linux сервере установленном в последние год-полтора. Открытые лицензии и активное сообщество разработчиков — залог успеха технологии в ближайшем будущем.
В ближайших публикациях мы остановимся на технологиях OpenVZ и LXC, а также обязательно проведем их сравнительный анализ :)
Update, продолжение серии публикаций:
- Контейнеризация на Linux в деталях — LXC и OpenVZ. Часть 1
Отдельно хотелось бы поблагодарить Василия Аверина (Parallels) за объяснение особо сложных аспектов технологии LXC.
C уважением, Павел Одинцов
CTO FastVPS LLC
