 Работа переводчиков интересна: через них постоянно проходит много информации на разных языках. Часто случается, что перевод очередной 100-страничной инструкции нужен был ещё вчера. И если похожие тексты уже переводились ранее (предыдущие версии инструкции или другая техническая документация), то задача может быть немного проще, но при этом заниматься копипастом и следить, чтобы все изменения были учтены, то еще занятие. Для того чтобы использовать уже существующий перевод и обеспечить при этом его последовательность существует специальный класс программ, называемых CAT-инструментами.
Работа переводчиков интересна: через них постоянно проходит много информации на разных языках. Часто случается, что перевод очередной 100-страничной инструкции нужен был ещё вчера. И если похожие тексты уже переводились ранее (предыдущие версии инструкции или другая техническая документация), то задача может быть немного проще, но при этом заниматься копипастом и следить, чтобы все изменения были учтены, то еще занятие. Для того чтобы использовать уже существующий перевод и обеспечить при этом его последовательность существует специальный класс программ, называемых CAT-инструментами.CAT расшифровывается как Computer-Aided (Assisted) Translation – «перевод с помощью компьютера» или «автоматизированный перевод». Но не стоит отождествлять данные технологии с машинным переводом, когда вы вводите текст на одном языке, нажимаете кнопку и получаете его перевод: автоматизированный перевод — более широкое понятие, и в случае CAT-систем используется уже имеющийся перевод, сделанный человеком.
На днях ABBYY Language Services начала закрытое тестирование SmartCAT — собственной платформы для автоматизации процесса перевода. И в этом посте мы постараемся немного рассказать, что умеют делать CAT-системы.
Во-первых, CAT-инструменты включают в себя различные лингвистические ресурсы, которые облегчают труд переводчиков с однотипными текстами, содержащими стандартные фразы и предложения — технические, юридические и медицинские термины, описания товаров и многое другое. Одними из самых распространенных ресурсов являются базы Translation Memory — базы памяти переводов, которые содержат ранее переведенные сегменты текста (словосочетания и предложения). Они создаются и пополняются на основе пар параллельных текстов. Другой важный ресурс — глоссарии, которые содержат термины и понятия, принятые в той или иной компании (либо утвержденные для определенной группы проектов). Кроме того, SmartCAT позволяет работать с технологией машинного перевода. Зарубежные переводчики уже давно используют этот ресурс, поскольку он помогает ускорить переводческие процессы и повысить производительность труда. В России пока не все понимают, чего можно ожидать от машинного перевода, однако интерес к этой технологии растёт: в этом году участники многих отраслевых конференций (например, Loc Kit, Translation Forum Russia) обсуждали особенности внедрения и использования машинного перевода гораздо активнее, чем на мероприятиях прошлых лет.
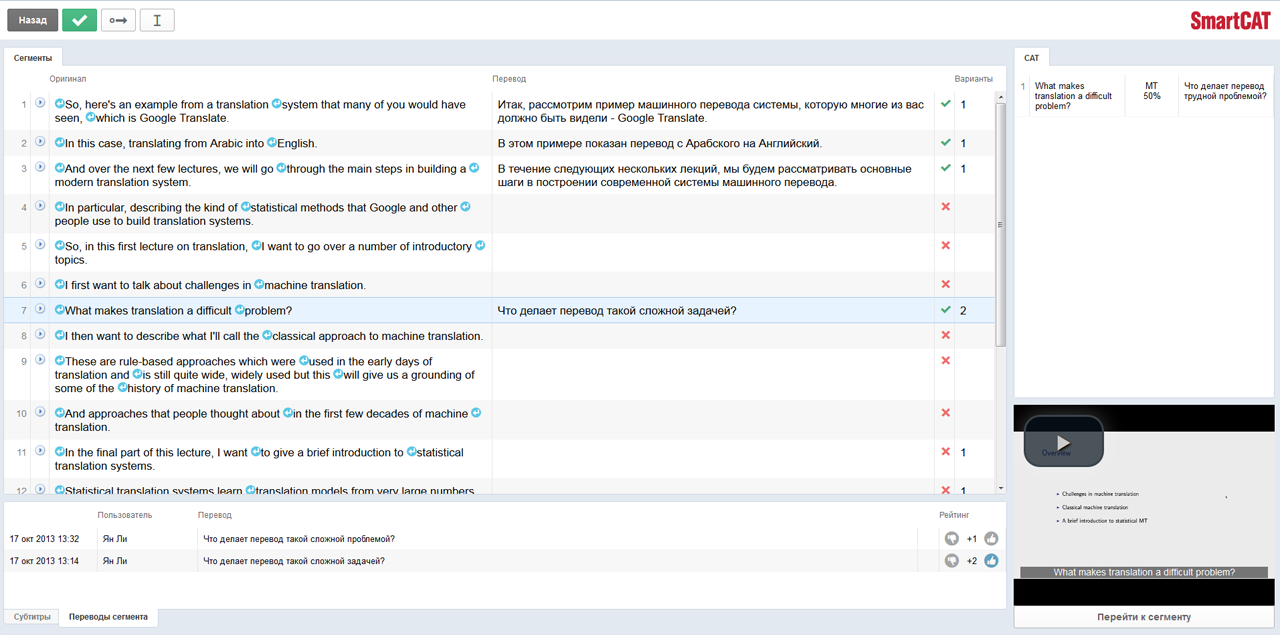
Все вышеперечисленные лингвистические ресурсы упрощают работу переводчику, который пользуется CAT-инструментом. В процессе перевода текста SmartCAT будет предлагать варианты перевода отдельных сегментов, используя при этом подстановки из действующих баз памяти переводов и подключенных глоссариев с корпоративной терминологией. Переводчик может:
- воспользоваться такими подстановками и принять их
- отредактировать предложенные варианты перевода (если необходимо поменять грамматическую форму)
- перевести сегмент по-своему.
При этом измененный вариант также можно добавить в существующие базы памяти переводов, тогда платформа в следующий раз предложит и его. Кроме того, в отдельной панели в правой части интерфейса SmartCAT будут показаны результаты машинного перевода выбранного сегмента. В большинстве случаев гораздо проще отредактировать такой «сырой» материал, чем переводить «с нуля» — это обычно называется постредактированием: переводчик или редактор проверяет готовый текст, сравнивает его с оригиналом, и доводит до нужной языковой нормы или требуемого уровня качества. Это не пройдет с художественными произведениями, творческими текстами (слоганами, рекламными материалами и пр.), личной перепиской и другими подобными текстами.
CAT-инструменты сохраняют форматирование документов. Допустим, переводчик работает над документом со сложной структурой, который содержит разноуровневые списки, стили, ссылки и другие элементы оформления. SmartCAT хранит информацию о вёрстке исходного текста в специальных тегах, которые при работе над переводом можно оставить на месте, и тогда переведенный текст будет выглядеть так же, как и оригинал.
Большинство CAT-инструментов являются десктопными программами — они устанавливаются на один компьютер, и воспользоваться программой можно только на нём. Если вы захотите переводить на другом компьютере — нужна плавающая лицензия или еще какие-нибудь ухищрения. У SmartCAT простой интерфейс и облачная архитектура, которая даёт определенные преимущества:
- над одним проектом могут одновременно работать несколько переводчиков, даже если они находятся в разных уголках мира;
- все необходимые материалы (базы памяти переводов, глоссарии и пр.) одновременно доступны всем переводчикам конкретного проекта.
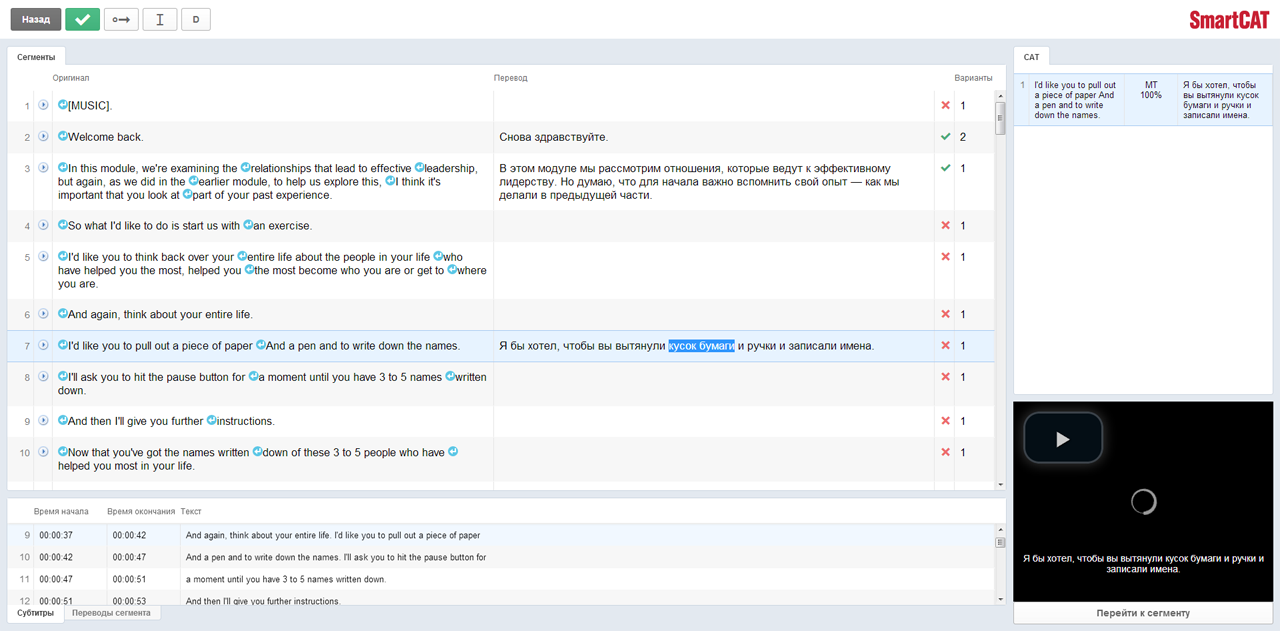
У нашей платформы есть специальный модуль TranslationConnector, который позволяет подключиться к внешним ресурсам — системам разработки и создания контента, электронному документообороту и многим другим. Благодаря этому получить перевод, скажем, сайта или e-commerce-портала можно буквально за один клик: задача во внутреннем ресурсе передается переводчику, ответственному за её решение, и он непосредственно в системе вносит необходимые изменения и возвращает готовый текст. Таким образом, пользователи SmartCAT могут работать с переводом в интерфейсах привычных для них систем, а компании — выстраивать и вести переводческие процессы наиболее удобным способом, создавая на основе платформы решения для конкретных проектов. Переводом может заниматься как внутренняя команда (например, отдел переводов), так и внешняя (переводческие компании).
Иногда переводчикам приходится работать с PDF-документами и изображениями, что приносит значительные неудобства. Текст в таких файлах просто так не изменишь, поэтому перед переводом их нужно распознать — извлечь текстовые данные. Конечно, всегда можно распечатать сканы, повесить их рядом с монитором и перепечатать их содержимое в текстовом редакторе, если не жалко времени и сил. SmartCAT значительно упрощает работу с такими форматами файлов благодаря интеграции с OCR технологиями ABBYY: достаточно загрузить нужный документ в систему, и она автоматически извлечёт текст для перевода. То есть переводчикам даже не придётся выходить из программы.
Кроме того, наш CAT-инструмент умеет измерять производительность переводчиков в конкретных проектах. В марте наши коллеги побывали на конференции TAUS, посвященной вопросам автоматизации перевода. По мнению большинства участников мероприятия, в проектах по постредактированию машинного перевода нужно отслеживать время и объём редактирования на уровне отдельного сегмента. Мы решили, что имеет смысл контролировать не только работу с машинным переводом, но и весь переводческий процесс, и добавили в SmartCAT систему онлайн-мониторинга проектов. Платформа в режиме реального времени анализирует различные метрики и показатели производительности, что позволяет получить информацию для оптимизации работы переводчиков, редакторов и корректоров с лингвистическими материалами. Кроме того, такие данные помогают оценить, насколько оправданы затраты на использование технологий автоматизации в конкретном проекте.
А теперь немного расскажем о том, что сделали наши разработчики, чтобы SmartCAT увидел свет. В частности они написали небольшой, но мощный сервер приложений на 1200 строк кода, который представляет собой загрузчик .Net сборок в win-service. Он может безопасно выключаться или вновь перезагрузиться, если вдруг возникнут ошибки в коде, сторонних компонентах или другая неприятная неожиданность. В этом случае он тщательно залогирует свое падение, чтобы снова встать в строй. При этом подключаемая сборка содержит NInject модуль с обработчиком той части бизнес-процесса, которую не удается уместить в рамки web-запроса. Эта часть представляется в виде задания, которое и ставится в очередь. А для быстрой и масштабируемой работы с очередями заданий в MongoDB и SQL мы разработали обобщенные паттерны.
Кроме того, наши специалисты внедрили красивый и удобный роутинг на атрибутах в WebAPI 5.0. Чтобы не ограничивать обработчики заданий по оперативной памяти или жесткому диску, мы добавили потоковую передачу данных от внешних поставщиков файлов (например, OCR-сервера) в TranslationConnector, а в нем, в свою очередь, такую же переброску в MongoDB GridFS.
Также мы придумали способ организации config-файлов для более простой настройки приложений во время разработки, тестирования и эксплуатации. Например, в развертывании этих файлов не содержится учетной информации для боевых сервисов и баз данных — они динамически подключаются из другой директории. Там же лежат настройки, зависящие от конкретной роли сервера и его сетевых подключений. Всё это позволяет содержать множество обработчиков на разных серверах.
В ближайшее время мы постараемся рассказать вам больше о технических деталях от наших разработчиков и о том, какие преимущества эти технологии дают пользователям SmartCAT. Сама облачная платформа пока находится в стадии закрытого тестирования, но все заинтересованные могут подать заявку на участие в нём на официальном сайте.
Денис Фролов
ABBYY Language Services
