(Новая запись от Марины Ильиных virtualtomato, старшего менеджера проектов в All Correct Localization)
В комментариях к одной из наших статей был вопрос о том, что, собственно, локализатор делает с файлами, которые необходимо перевести. Признаться, эта часть нашей работы кажется мне наименее захватывающей, но если хотя бы одному читателю это интересно, то мы с удовольствием расскажем об этом на примере ПО, которое использует наша команда. Так как разговор это не короткий, то мы решили поделить повествование на две части: подготовка проекта и управление им (функционал для менеджера) и работа с текстом (функционал для переводчика и редактора).

Иллюстрация с сайта Dageron.com
Думаю, ни для кого не секрет, что любой профессионал испытывает довольно сильные чувства по отношению к инструментам, с которыми ему приходится работать. Если инструмент плохо помогает в работе или даже мешает, то работник испытывает праведный гнев. Если же при этом отказаться от этого инструмента нельзя, то выражение праведного гнева иногда может выйти за рамки, допустимые в приличном обществе. Но нам повезло — наш основной рабочий инструмент, программа MemoQ, если и доводит нас иногда до употребления ненормативной лексики, то исключительно по причине полного восторга от ее функционала.
MemoQ принадлежит к категории ТМ-программ. TM — это translation memory, память перевода. На мой взгляд, хорошо переводить без использования подобных программ можно лишь в ряде ограниченных случаев. И сейчас речь пойдет о той части работы, которую выполняет в MemoQ менеджер проектов.
Все начинается с того, что появляется файл на перевод. Это может быть Excel, Word, txt, xml, po, json… Да все, что угодно. Все операции с файлом: подсчет статистики, перевод, редактирование, проверка качества — проводятся в MemoQ. После выгрузки файла из программы исходный текст в нем заменяется переводом.
Особенностью ТМ-программ является то, что они сегментируют текст (делят его на ячейки) по одному из заданных заранее правил. И если в тексте есть повторяющиеся сегменты, то программа автоматически подставит ваш перевод во все эти сегменты далее по тексту. К каждому проекту подключается TM — память переводов. В ней хранятся все переводы, которые вы ранее выполняли по данному проекту. То есть у вас никогда не возникнет случая, когда вам придется перевести тот или иной текст дважды. За это ТМ-программы все и любят.
Вот, например, это всем известное стихотворение изобилует повторами:
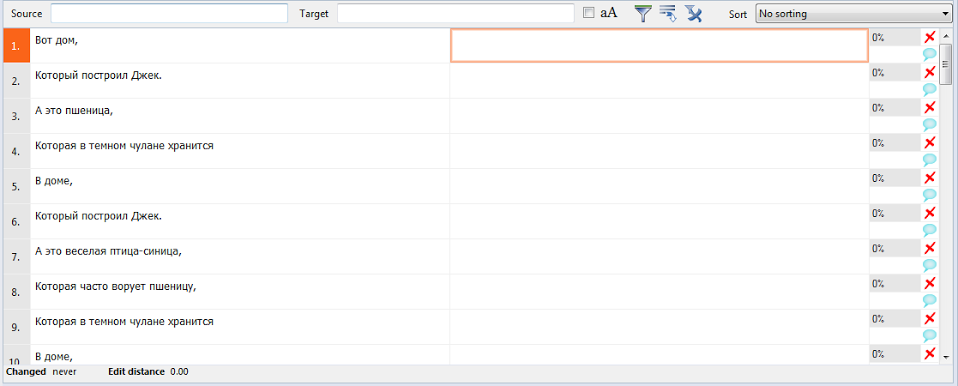
А вот как перевод одного сегмента подставляется во все остальные:
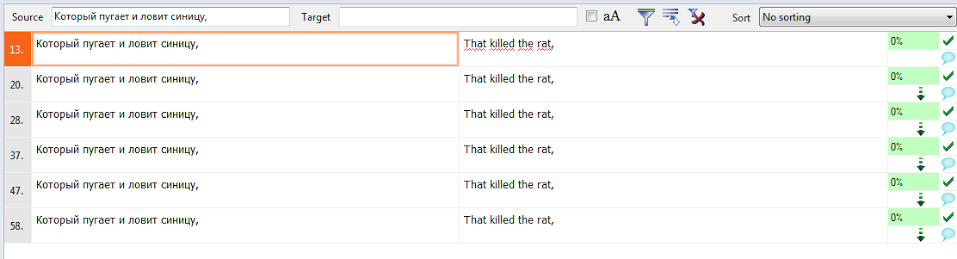
Статистика показывает, что в данном тексте 67% повторяющихся сегментов. Вместо 246 слов нужно фактически перевести всего 81 слово.

На крупных проектах (игры объемом от 20 000 слов) такое количество повторов — это большая редкость. Обычно их доля колеблется на уровне 5-18%. Например, в Rayman Legends из 21 000 слов 2057 оказались повторами. А в одном из последних моих проектов по локализации социальной игры доля повторов в тексте достигла 18,2%. Представьте себе экономию на таком проекте, если игра локализуется, скажем, на 6 языков. Так что требуйте у локализатора скидку на повторы!
Как я уже сказала, текст сегментируется по заранее заданным правилам. Выбор правил сегментации — это одно из первых важных решений, которое должен принять менеджер. В большинстве случаев текст на перевод приходит в формате Excel. И тогда мы обычно выбираем сегментацию по ячейке. То есть одна ячейка Excel-таблицы соответствует одному сегменту в MemoQ. Также довольно часто мы сегментируем текст по предложениям. Но бывают совершенно уникальные проекты, где приходится применять что-то весьма специфическое.
Однажды мы переводили проект с корейского на русский. У клиента был определенный бюджет, поэтому, чтобы помочь ему сэкономить, мы сделали сегментацию «помельче», чтобы в проекте было побольше повторяющихся сегментов. Не вдаваясь в лишние подробности, скажу, что повторов стало действительно больше, но вот только мы не учли, что строй корейского языка разительно отличается от, скажем, русского. И в результате мы сами того не ведая активировали режим Йоды. Вот такие забавные истории у нас получились (каждая строчка была отдельным сегментов в MemoQ):
Кесивион, поссорившись с мужем,
Приготовить блюдо примирения
Собирается.
Или вот:
На ночном рынке из любопытства
Играла в казино и проиграла Елена.
И мое любимое:
Морские слоны точно сошли с ума.
Раньше на них много людей
Приходило смотреть, турбизнес
Цвел. А с каких-то пор
Они решили в футболках супермена
Нападать на туристов,
Куда годится?!
В подавляющем большинстве игр разработчики используют переменные. MemoQ может облегчить работу с ними. Например, у вас есть вот такой текст на перевод:
Get {X} [cash] for {Y} [feez]?
Do you want to refill for {X} [feez]?
Loot for {0} Fee'z?
Менеджер (да и переводчик) может (и обязательно сделает) для ваших текстов шаблон, по которому все переменные и тэги будут идентифицироваться и отображаться в виде нередактируемых сегментов (красные флажки).

После осуществления такой нехитрой процедуры тэги и переменные не учитываются в смете на перевод (еще немного экономии!). Неоспоримым плюсом такого подхода является легкость подстановки переменных в перевод. Они вставляются нажатием одной клавиши, а не бесконечным клацаньем по Ctll+C, Ctrl+V или набором их с нуля. Так снижается риск ошибки и сокращаются трудозатраты.
Очень часто нам присылают тексты в формате xml с вопросом, можем ли мы переводить так. Конечно, если переводчик откроет такой файл в блокноте, то он увидит примерно следующее:

Переводить «так» нельзя. Этот документ еще достаточно неплохо выглядит. Бывают случаи, когда ты просто теряешься в том хаосе из кода, который видишь, открыв документ. Риск пропустить что-то или повредить код слишком велик.
Самый стандартный xml-фильтр MemoQ менее чем за минуту приведет документ вот в такой прекрасный вид:

При этом переводчик работает только с текстом, но в окне предварительного просмотра сразу видит результаты своей работы. Для более сложных документов можно создавать уникальные фильтры, которые хранятся на сервере и могут прийти на помощь в любой нужный момент.
Случилось так, что над игрой должна работать команда переводчиков. То есть более одного переводчика на один язык. Как поделить текст? Кромсать сам файл возьмется разве что какой-нибудь менеджер-эскулап. MemoQ может поделить файл ровно на столько кусочков, сколько нужно (однажды я делила файл на 12 частей). При этом сам файл остается нетронутым, создаются виртуальные копии, в которых переводчик может вносить изменения только в ту часть, к которой ему предоставил доступ менеджер. Но он видит весь документ и ход работы своего коллеги, так как они работают в одном серверном проекте. Чтобы все стало еще понятнее: мы не обмениваемся с переводчиками файлами. Они получают доступ к проектам на сервере и работают только в MemoQ.
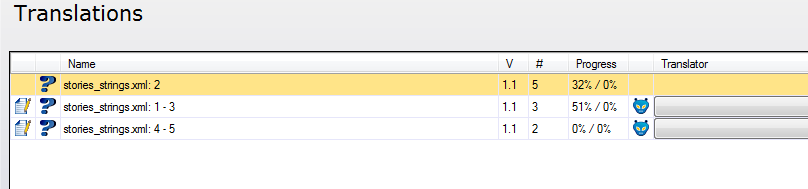
Вот такими нехитрыми, а иногда, конечно, и хитрыми способами мы готовим проект к локализации: подсчитываем статистику на перевод, работаем с тегами и переменными, распределяем файлы между переводчиками. Теперь вы можете не бояться, что ваши файлы безжалостно расчленят, испортят код, а вам еще и за «перевод» тегов придется платить. Ни один нормальный поставщик услуг локализации этого не допустит. Мы скоро обязательно напишем статью о том, что же видит в MemoQ переводчик и редактор, какие преимущества дает программа им, и как это влияет на качество локализации. И эта статья обещает быть большой!
Часть 1
В комментариях к одной из наших статей был вопрос о том, что, собственно, локализатор делает с файлами, которые необходимо перевести. Признаться, эта часть нашей работы кажется мне наименее захватывающей, но если хотя бы одному читателю это интересно, то мы с удовольствием расскажем об этом на примере ПО, которое использует наша команда. Так как разговор это не короткий, то мы решили поделить повествование на две части: подготовка проекта и управление им (функционал для менеджера) и работа с текстом (функционал для переводчика и редактора).

Иллюстрация с сайта Dageron.com
Думаю, ни для кого не секрет, что любой профессионал испытывает довольно сильные чувства по отношению к инструментам, с которыми ему приходится работать. Если инструмент плохо помогает в работе или даже мешает, то работник испытывает праведный гнев. Если же при этом отказаться от этого инструмента нельзя, то выражение праведного гнева иногда может выйти за рамки, допустимые в приличном обществе. Но нам повезло — наш основной рабочий инструмент, программа MemoQ, если и доводит нас иногда до употребления ненормативной лексики, то исключительно по причине полного восторга от ее функционала.
MemoQ принадлежит к категории ТМ-программ. TM — это translation memory, память перевода. На мой взгляд, хорошо переводить без использования подобных программ можно лишь в ряде ограниченных случаев. И сейчас речь пойдет о той части работы, которую выполняет в MemoQ менеджер проектов.
Подгрузка и статистика
Все начинается с того, что появляется файл на перевод. Это может быть Excel, Word, txt, xml, po, json… Да все, что угодно. Все операции с файлом: подсчет статистики, перевод, редактирование, проверка качества — проводятся в MemoQ. После выгрузки файла из программы исходный текст в нем заменяется переводом.
Особенностью ТМ-программ является то, что они сегментируют текст (делят его на ячейки) по одному из заданных заранее правил. И если в тексте есть повторяющиеся сегменты, то программа автоматически подставит ваш перевод во все эти сегменты далее по тексту. К каждому проекту подключается TM — память переводов. В ней хранятся все переводы, которые вы ранее выполняли по данному проекту. То есть у вас никогда не возникнет случая, когда вам придется перевести тот или иной текст дважды. За это ТМ-программы все и любят.
Вот, например, это всем известное стихотворение изобилует повторами:
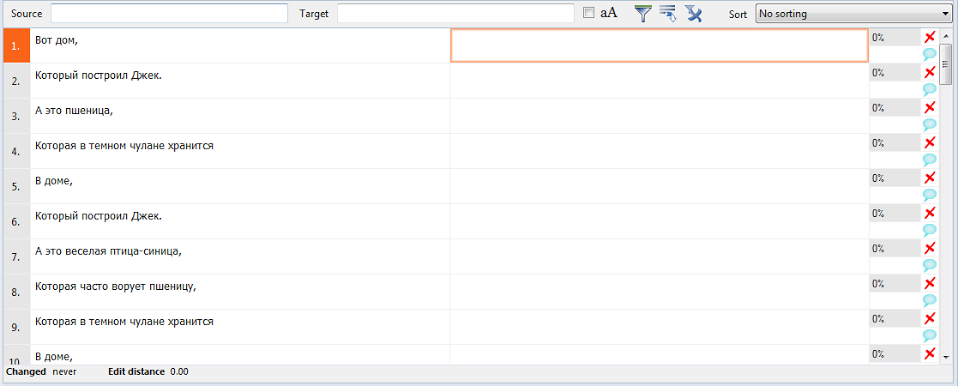
А вот как перевод одного сегмента подставляется во все остальные:
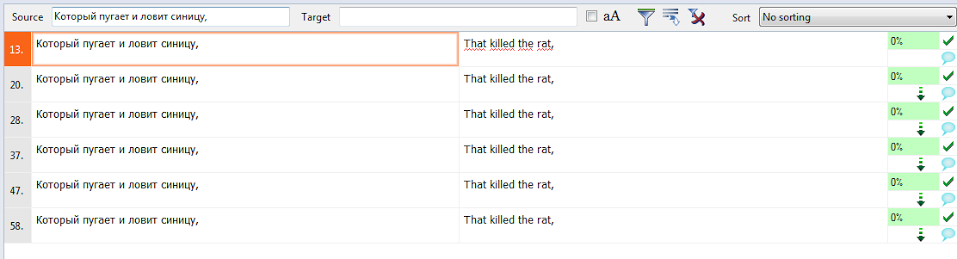
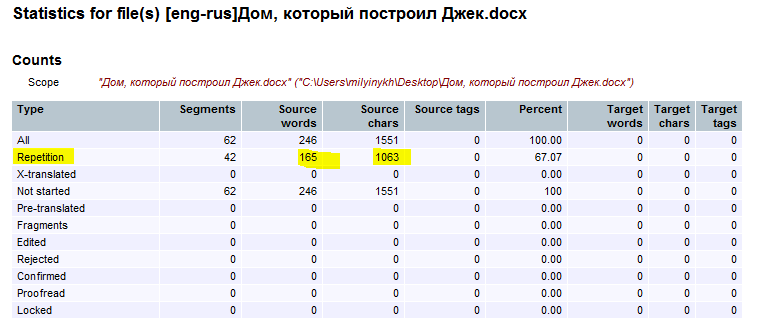
Статистика показывает, что в данном тексте 67% повторяющихся сегментов. Вместо 246 слов нужно фактически перевести всего 81 слово.
На крупных проектах (игры объемом от 20 000 слов) такое количество повторов — это большая редкость. Обычно их доля колеблется на уровне 5-18%. Например, в Rayman Legends из 21 000 слов 2057 оказались повторами. А в одном из последних моих проектов по локализации социальной игры доля повторов в тексте достигла 18,2%. Представьте себе экономию на таком проекте, если игра локализуется, скажем, на 6 языков. Так что требуйте у локализатора скидку на повторы!
Как я уже сказала, текст сегментируется по заранее заданным правилам. Выбор правил сегментации — это одно из первых важных решений, которое должен принять менеджер. В большинстве случаев текст на перевод приходит в формате Excel. И тогда мы обычно выбираем сегментацию по ячейке. То есть одна ячейка Excel-таблицы соответствует одному сегменту в MemoQ. Также довольно часто мы сегментируем текст по предложениям. Но бывают совершенно уникальные проекты, где приходится применять что-то весьма специфическое.
Однажды мы переводили проект с корейского на русский. У клиента был определенный бюджет, поэтому, чтобы помочь ему сэкономить, мы сделали сегментацию «помельче», чтобы в проекте было побольше повторяющихся сегментов. Не вдаваясь в лишние подробности, скажу, что повторов стало действительно больше, но вот только мы не учли, что строй корейского языка разительно отличается от, скажем, русского. И в результате мы сами того не ведая активировали режим Йоды. Вот такие забавные истории у нас получились (каждая строчка была отдельным сегментов в MemoQ):
Кесивион, поссорившись с мужем,
Приготовить блюдо примирения
Собирается.
Или вот:
На ночном рынке из любопытства
Играла в казино и проиграла Елена.
И мое любимое:
Морские слоны точно сошли с ума.
Раньше на них много людей
Приходило смотреть, турбизнес
Цвел. А с каких-то пор
Они решили в футболках супермена
Нападать на туристов,
Куда годится?!
Работа с переменными
В подавляющем большинстве игр разработчики используют переменные. MemoQ может облегчить работу с ними. Например, у вас есть вот такой текст на перевод:
Get {X} [cash] for {Y} [feez]?
Do you want to refill for {X} [feez]?
Loot for {0} Fee'z?
Менеджер (да и переводчик) может (и обязательно сделает) для ваших текстов шаблон, по которому все переменные и тэги будут идентифицироваться и отображаться в виде нередактируемых сегментов (красные флажки).

После осуществления такой нехитрой процедуры тэги и переменные не учитываются в смете на перевод (еще немного экономии!). Неоспоримым плюсом такого подхода является легкость подстановки переменных в перевод. Они вставляются нажатием одной клавиши, а не бесконечным клацаньем по Ctll+C, Ctrl+V или набором их с нуля. Так снижается риск ошибки и сокращаются трудозатраты.
«Сложные» форматы
Очень часто нам присылают тексты в формате xml с вопросом, можем ли мы переводить так. Конечно, если переводчик откроет такой файл в блокноте, то он увидит примерно следующее:

Переводить «так» нельзя. Этот документ еще достаточно неплохо выглядит. Бывают случаи, когда ты просто теряешься в том хаосе из кода, который видишь, открыв документ. Риск пропустить что-то или повредить код слишком велик.
Самый стандартный xml-фильтр MemoQ менее чем за минуту приведет документ вот в такой прекрасный вид:

При этом переводчик работает только с текстом, но в окне предварительного просмотра сразу видит результаты своей работы. Для более сложных документов можно создавать уникальные фильтры, которые хранятся на сервере и могут прийти на помощь в любой нужный момент.
Большие файлы
Случилось так, что над игрой должна работать команда переводчиков. То есть более одного переводчика на один язык. Как поделить текст? Кромсать сам файл возьмется разве что какой-нибудь менеджер-эскулап. MemoQ может поделить файл ровно на столько кусочков, сколько нужно (однажды я делила файл на 12 частей). При этом сам файл остается нетронутым, создаются виртуальные копии, в которых переводчик может вносить изменения только в ту часть, к которой ему предоставил доступ менеджер. Но он видит весь документ и ход работы своего коллеги, так как они работают в одном серверном проекте. Чтобы все стало еще понятнее: мы не обмениваемся с переводчиками файлами. Они получают доступ к проектам на сервере и работают только в MemoQ.
Вот такими нехитрыми, а иногда, конечно, и хитрыми способами мы готовим проект к локализации: подсчитываем статистику на перевод, работаем с тегами и переменными, распределяем файлы между переводчиками. Теперь вы можете не бояться, что ваши файлы безжалостно расчленят, испортят код, а вам еще и за «перевод» тегов придется платить. Ни один нормальный поставщик услуг локализации этого не допустит. Мы скоро обязательно напишем статью о том, что же видит в MemoQ переводчик и редактор, какие преимущества дает программа им, и как это влияет на качество локализации. И эта статья обещает быть большой!
