* А что это ваш бэкап такой несвежий? (Одесск.)

Даже самые дорогие системы, выполняющие периодическое резервное копирование (например, каждую ночь), обладают одним существенным ограничением: всё, что было сделано на компьютере после последнего резервного копирования, никак не защищено, и будет безвозвратно потеряно, если компьютер выйдет из строя.
Пусть, например, вчера была написана первая часть «Мёртвых Душ», и ночью сделана резервная копия. А сегодня написана вторая часть, и в эмоциональном порыве уничтожена ещё до того, как настало время очередного резервного копирования.
Бороться с такими ситуациями призвана технология непрерывного резервного копирования (Continuous Data Protection, CDP). Всё, что записывается на диск, одновременно отправляется в резервную копию.
Рассмотрим подробнее, как это делается в продукте Arcserve RHA (Replication and High Availability) на реальных примерах в средах Windows и Linux.
Содержание
Введение
1. Архитектура
2. Установка программного обеспечения
2.1. Установка управляющих компонентов
2.2. Установка управляемых компонентов на Windows
2.3. Установка управляемых компонентов на Linux
3. Эксперименты по восстановлению данных
3.1. Восстановление файлов на заданный момент времени
3.2. Восстановление базы данных MS SQL на заданный момент времени
3.3 Восстановление базы данных MySQL на Linux на заданный момент времени
4. Заключение и реклама
Пусть мы имеем два сервера.
Боевой сервер (Master) содержит постоянно обновляющиеся данные. Мы следим за изменениями и ведём ведомость (журнал) изменений в виде «было -> стало», например:
Журнал изменений постоянно пересылается на резервный сервер (Replica) и применяется к его файлам. Таким образом файлы боевого и резервного серверов становятся идентичными.
Некоторые детали:

Для того, чтобы описанная выше схема заработала, нам потребуется установить на машины Master и Replica компонент, именуемый Engine, который берёт на себя основную работу по отслеживанию изменений в файлах и репликации данных с одной машины на другую.
Для того, чтобы сконфигурировать работу этих двух Engine, установим на ещё одну машину (Manager) сервис управления (Control Service). Эта машина требуется только для конфигурации, получения отчётов и запуска отдельных действий на управляемых машинах. Она не должна быть постоянно включенной.
Наконец, пользовательский интерфейс мы получим, соединившись интернет-браузером с сервисом управления, и скачав оттуда windows-приложение.
Скачаем Arcserve RHA (iso или zip) с сайта разработчика (как указано на странице arcserve.zendesk.com/hc/en-us/articles/205009209-RHA-R16-5-SP5-ARCSERVE-RHA-16-5-SP5 ):
Продукт работает 30 дней без лицензионных ключей.
Начнём с того, что установим Control Service на управляющую машину (Manager).
Для его работы требуется .NET Framework 3.5.
Теперь запускаем Setup.exe с дистрибутива Arcserve RHA и выбираем “Install Components”:

На следующем экране выбираем “Install Arcserve RHA Control Service”. (Особенность: на слова “Install Arcserve RHA …” кликнуть не получается, а на “… Control Service” – получается):

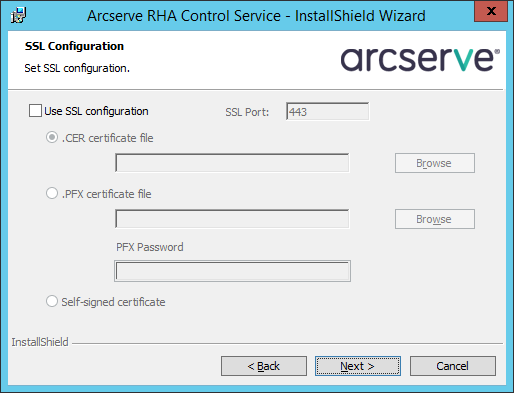
Потом прощёлкаем несколько экранов, пока не дойдём до конфигурации SSL. Для тестирования включать SSL не будем, а при рабочем применении можете добавить здесь ваш сертификат или использовать самоподписанный:
Будем запускать сервис от имени Local System:

Следующий экран касается возможности иметь две управляющих машины для повышения отказоустойчивости. Мы для целей тестирования ограничимся одной:

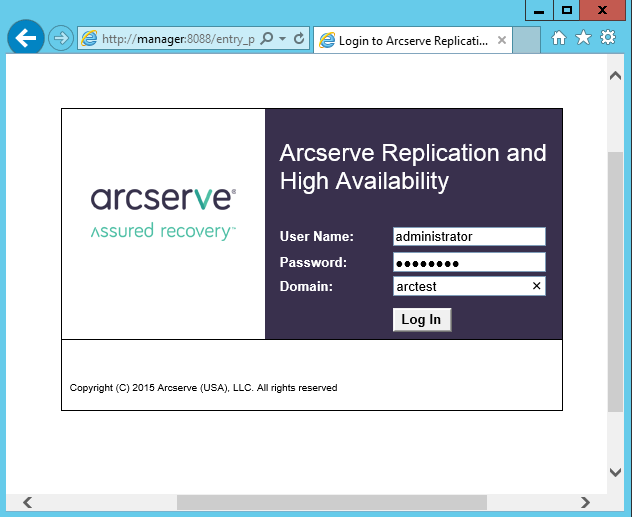
После завершения установки соединимся интернет-браузером с машиной Manager на порту 8088. Войти можно под пользователем, у которого есть права локального администратора на машине Manager:
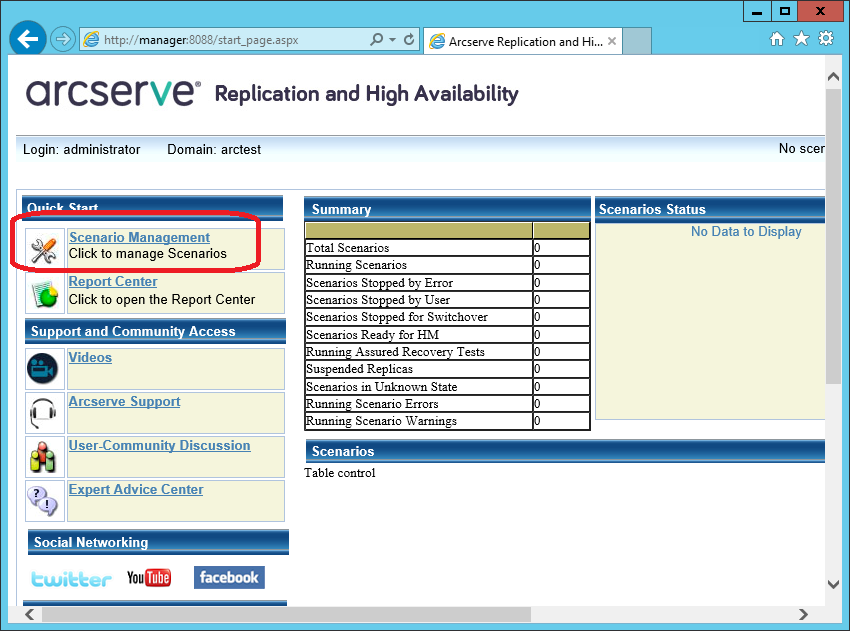
Мы получим доступ к странице, на которой будет публиковаться статистика работы различных машин. Но для реального управления нам потребуется скачать с этого сайта и запустить windows-утилиту “Arcserve RHA Manager”. Её можно запускать уже не на сервере, а на рабочей станции (например, Windows 7 или 10). Для скачивания нажмём на ссылку “Scenario Management”:
После предупреждений безопасности должна запуститься программа “Arcserve RHA Manager”:

Эта программа и в дальнейшем будет запускаться только с веб-страницы.
На машины Master и Replica установим рабочие компоненты – Engine.
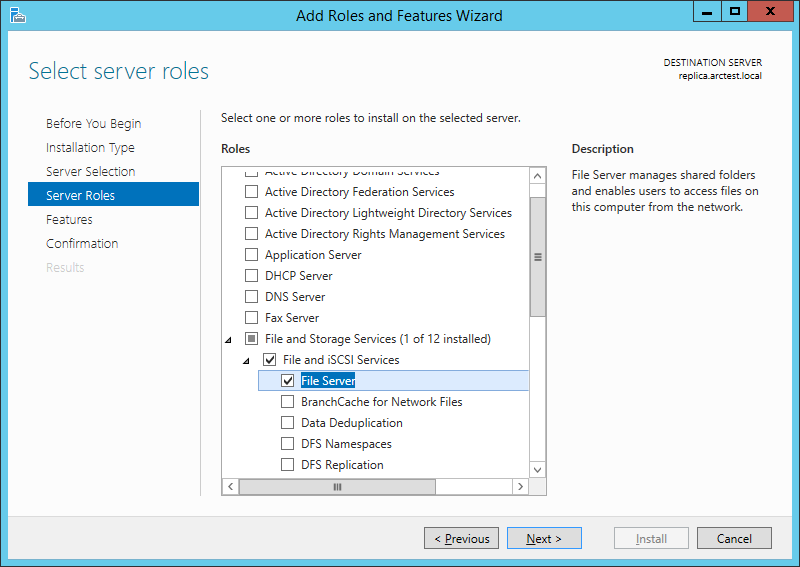
Можно установить их локально с дистрибутива, а можно – удалённо. Для удалённой установки на сервер требуется, чтобы у сервера была установлена роль “File Server”:
Если роль “File Server” установлена на машинах master и replica, то на машине Manager мы можем обратиться к “\\master\C$” и “\\replica\C$”.
Из утилиты Arcserve RHA Manager, о которой шла речь в предыдущем разделе, запустим удалённую установку через меню “Tools -> Launch Remote Installer”.
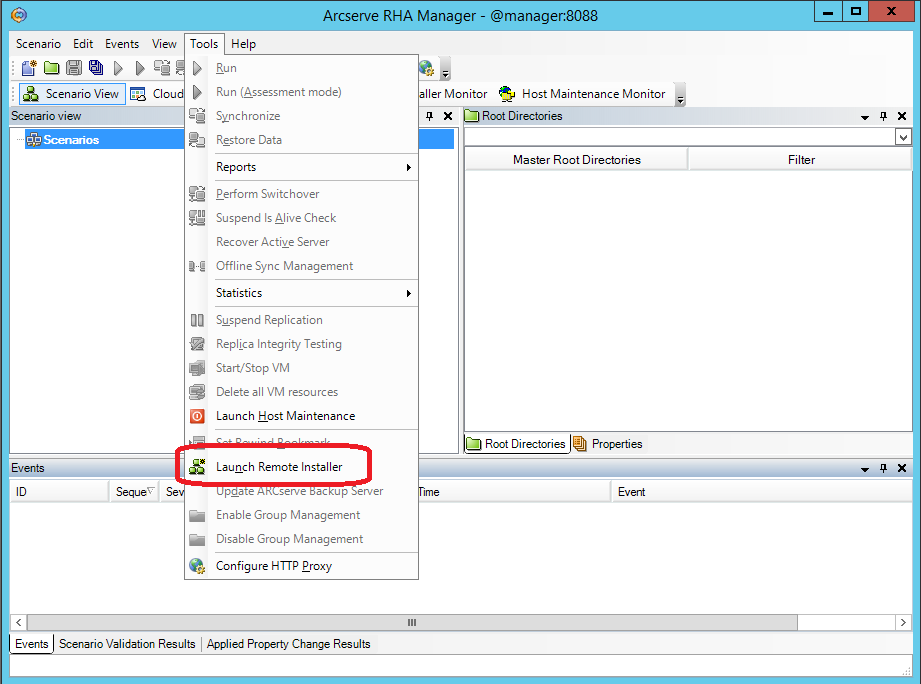
На следующем экране нажимаем кнопку “Start host discovery” (1) и получаем список машин из кэша Active Directory.
Выделяем машины master и replica и добавляем их в список кандидатов на установку Engine при помощи кнопки “Add” (3)
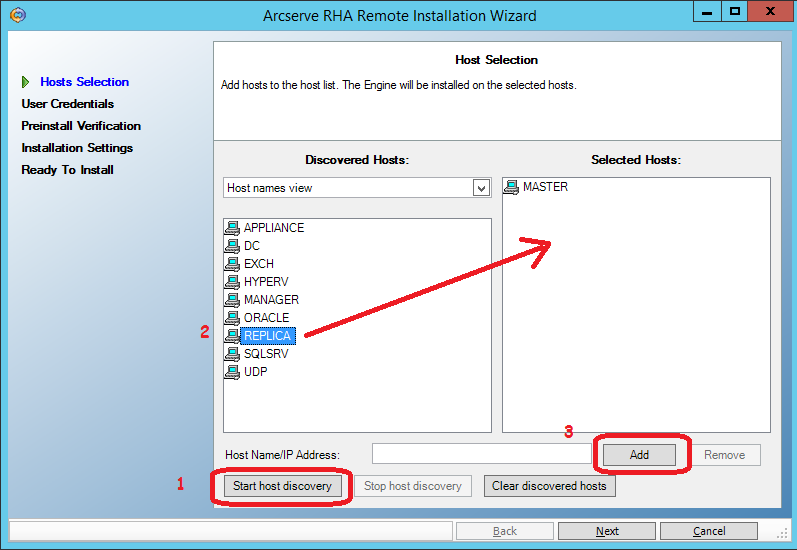
На следующем экране введём пользователя (администратора домена), под которым будет выполняться удалённая установка:

Далее убеждаемся, что оба сервера (master и replica) позволяют выполнить удалённую установку и помечены галочками:

На следующем экране введём пользователя, под которым будет запускаться служба Engine.
Для целей непрерывного резервного копирования достаточно пользователя с правами локального администратора (Local System). А вот если мы хотим использовать функционал High Availability, когда резервная машина сможет изображать из себя вышедшую из строя основную машину, то нам нужно запускать сервис под доменным администратором. Описанный ниже пример из раздела () требует именно таких полномочий:

Нажимаем всякие Next -> Install -> Yes и ждём завершения установки:

Установить компонент Engine на сервер можно, покопавшись в каталоге UNIX_Linux на дистрибутиве и найдя нужный агент в tar-архиве. В частности, для установки на CentOS 6.5 я использовал архив arcserverha_rhel6.tgz
Если на машине не установлены 32-битные библиотеки, нужно их поставить. Например, на CentOS 6.5 мне пришлось выполнить:
(предварительно обновив их 64-битные версии: “yum install glibc libstdc++ pam” )
затем запускаем ./install.sh и соглашаемся со всеми подсказками.
В firewall открываем порт 25000 (TCP)
Создадим на машине Master каталог “C:\Ax-уехала-жена\” и положим туда файлы:
Таня.jpg
Лена.jpg
Джоконда.jpg
Создадим сценарий репликации этого каталога на машину Replica. В меню “Arcserve RHA Manager” выберем Scenario -> New
Первый экран мастера создания сценариев оставляем без изменений:
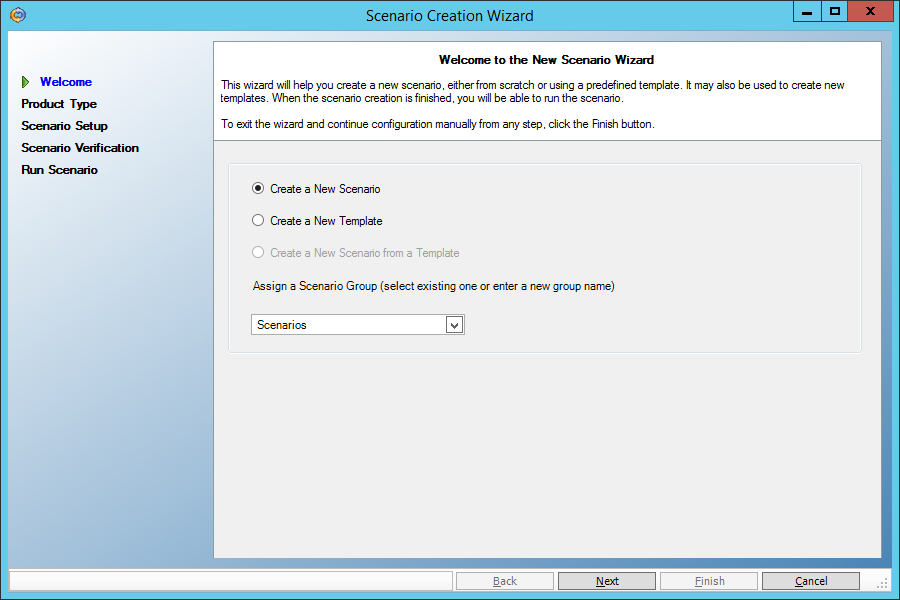
На втором экране также ничего не меняем – там должен быть выбран сценарий репликации файлов (File Server):

Выберем в качестве основной машины сервер Master, а в качестве резервной – Replica:

На следующем экране видим подтверждение того, что служба Engine установлена на обеих машинах. Если мы не установили её ранее, то можем сделать это удалённо отсюда.
На следующем экране выберем исходный каталог “C:\Ax-уехала-жена\” на машине Master:

На следующем экране нам предложат реплицировать этот каталог в каталог с таким же именем на машине Replica. Согласимся:
На следующем экране ничего не меняем:
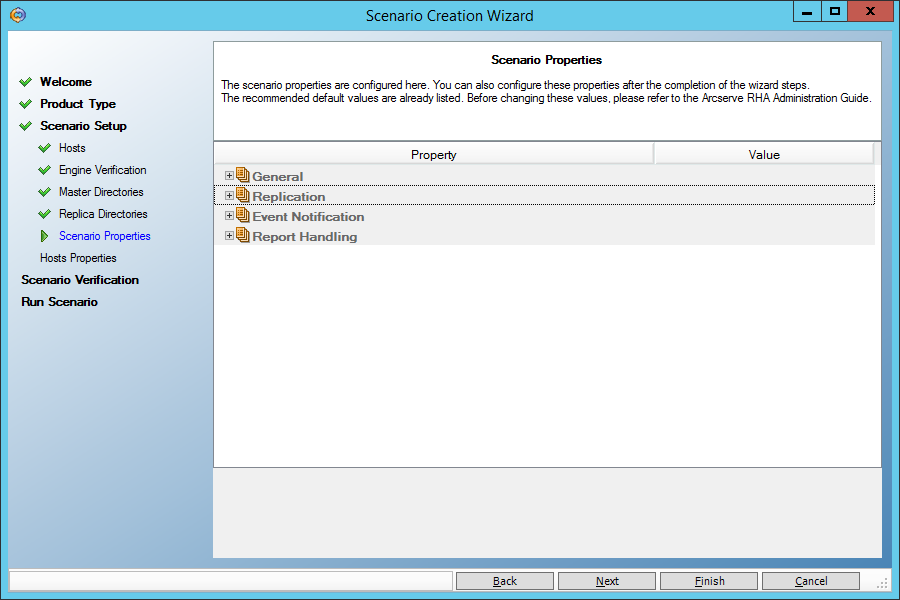
А вот здесь нам нужно выставить параметр “Data Rewind” в “On”, чтобы иметь возможность восстанавливать данные на произвольный момент времени в прошлом:

Наконец, нам скажут, что сценарий не содержит ошибок:

Запустим сценарий, нажав кнопку “Run Now”:

На главном экране мы увидим, как работает сценарий. Заданный каталог быстро синхронизируется (станет одинаковым на основной и резервной машине), и теперь любое изменение в каталоге на машине Master приведёт к аналогичному изменению его копии на машине Replica.

Выполним три действия на машине Master:
1. Изменим файл Джоконда.jpg

2. Сотрём файл Таня.jpg
3. Добавим файл Маша.jpg
Убедимся, что на машине Replica с файлами произошло то же самое.
Теперь мы хотели бы вернуть Джоконде прежний облик. Для этого отмотаем время назад на машине Replica, воспользовавшись инструментом Data Recovery.
Сначала мы должны остановить сценарий (меню Tools -> Stop)
Затем щёлкнуть мышью на машине Replica и вызвать меню Tools -> Data Recovery:

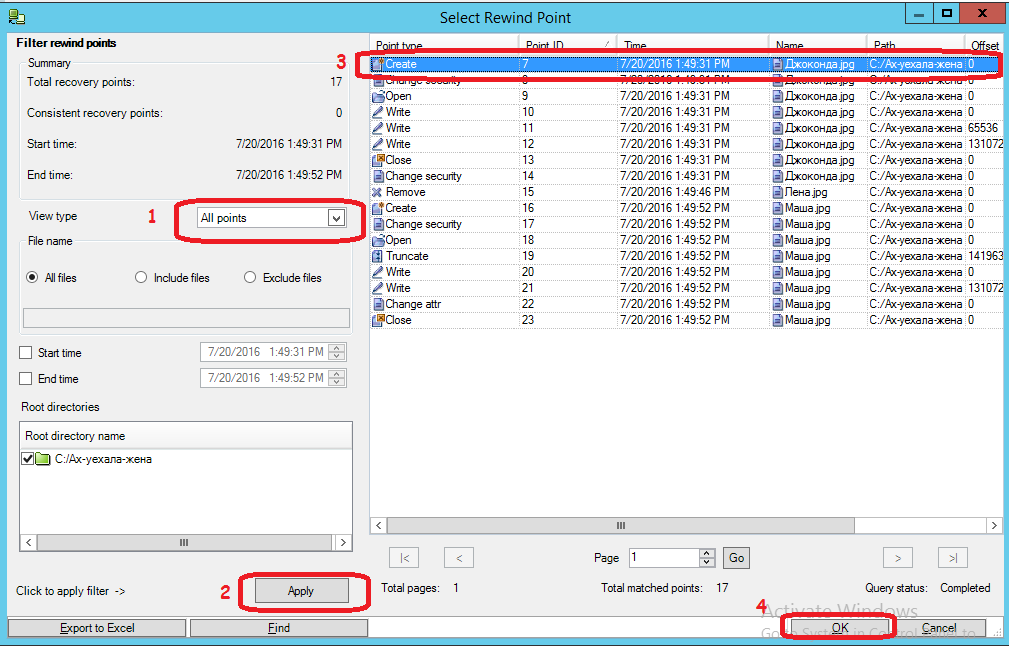
Нажав в следующем окне кнопку “Select Recovery Point”, попадаем вот в такое окно, где нужно:
(1) Установить просмотр всех временных точек, на которые возможен откат по времени
(2) Нажать кнопку Apply
(3) Выделить самую первую точку, когда Джоконда ещё не была повреждена
(4) Нажать на кнопку “OK”
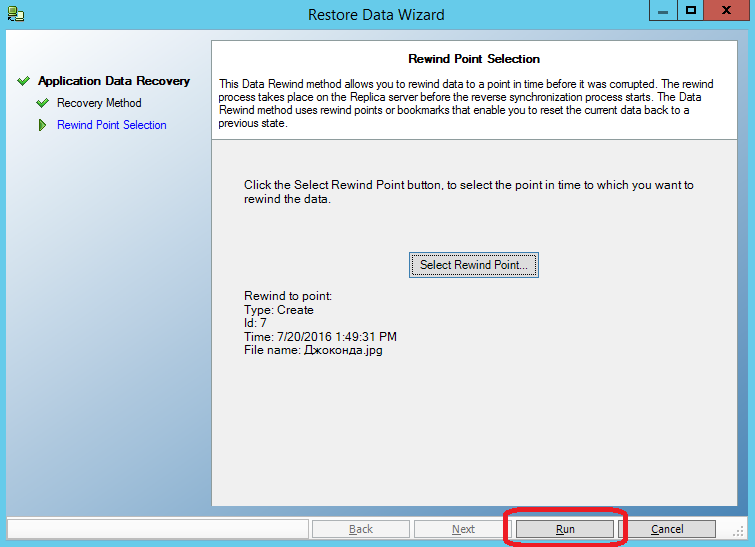
Затем нажимаем кнопку “Run”:

Проверяем, что произошло с файлами на машине Replica.
— Джоконда.jpg снова вернулась в начальное состояние
— Маша.jpg исчезла
— Лена.jpg появилась
Именно для того, чтобы не потерять Машу.jpg, мы не стали восстанавливать данные на обеих машинах. Теперь достаточно переписать файл “Джоконда.jpg” на машину Master, и мы снова получим в работу неиспорченный файл, не затрагивая все остальные.
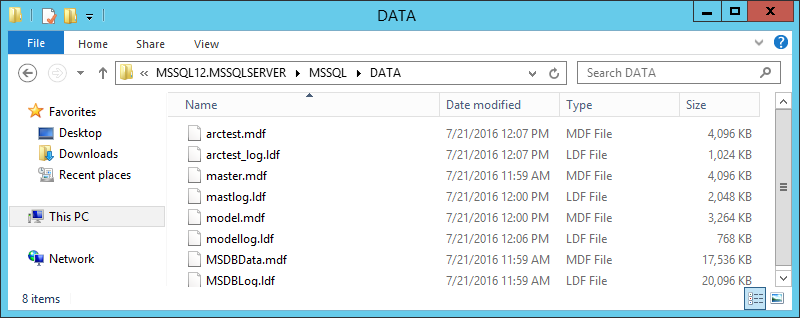
Предположим, что MS SQL установлен на машине Master. На машину Replica можно MS SQL не ставить, тогда она будет служить лишь хранилищем копии каталога DATA:
Сценарий репликации MS SQL похож на сценарий репликации файлов, но добавляются три вещи, которые облегчают нам жизнь:
1. Выбирается правильный метод начальной синхронизации – поблочный. Перед тем, как начать репликацию, система должна убедиться, что данные на двух машинах идентичны и синхронизировать то, что отличается.
Для сценария типа “File Server” по умолчанию применяется упрощённая начальная синхронизация, при которой файлы считаются идентичными, если их размер и время изменения совпадают. Такое допущение даёт хорошую экономию времени начальной синхронизации на файловых серверах, но совершенно неприемлемо для баз данных, поэтому сценарий для MS SQL сравнивает один за другим все блоки данных, из которых состоят файлы.
2. нам не придётся явно указывать, где находятся файлы базы данных, эта информация автоматически подтянется:

2. при восстановлении данных на основную машину (Master) сервисы MS SQL будут автоматически потушены и переведены в режим ручного запуска. После восстановления всё вернётся на место:
Предположим, что кто-то забыл написать “where” в команде “update”:
(кто сам такое делал – поймёт глубину падения).
Так же, как и в предыдущем случае, останавливаем сценарий репликации, запускаем “Tools->Data Recovery”, но выбираем восстановление не только на резервную машину, но и на основную:

Остаётся только выбрать точку во времени, предшествующую моменту порчи данных, и провести восстановление:

На двух машинах co-master и co-replica установлены CentOS 6.5 и MySQL (в одинаковых каталогах).
Строго говоря, на резервной машине (co-replica) MySQL можно и не ставить, но мы попробуем зайти чуть дальше и подхватить реплицированные данные на резервном MySQL-сервере.
На машине co-master сервис MySQL запущен, на машине co-replica – выключен.
Создаём новый сценарий типа “Custom Application”.

В отличие от сценария “File Server” (п. 3.1) сценарий “Custom Application” по умолчанию имеет поблочную начальную синхронизацию. Ещё раз повторю: для сценария типа “File Server” по умолчанию применяется упрощённая начальная синхронизация, при которой файлы считаются идентичными, если их размер и время изменения совпадают. Такое допущение даёт хорошую экономию времени начальной синхронизации на файловых серверах, но совершенно неприемлемо для баз данных, поэтому для репликации MySQL сценарий типа “File Server” неприемлем.
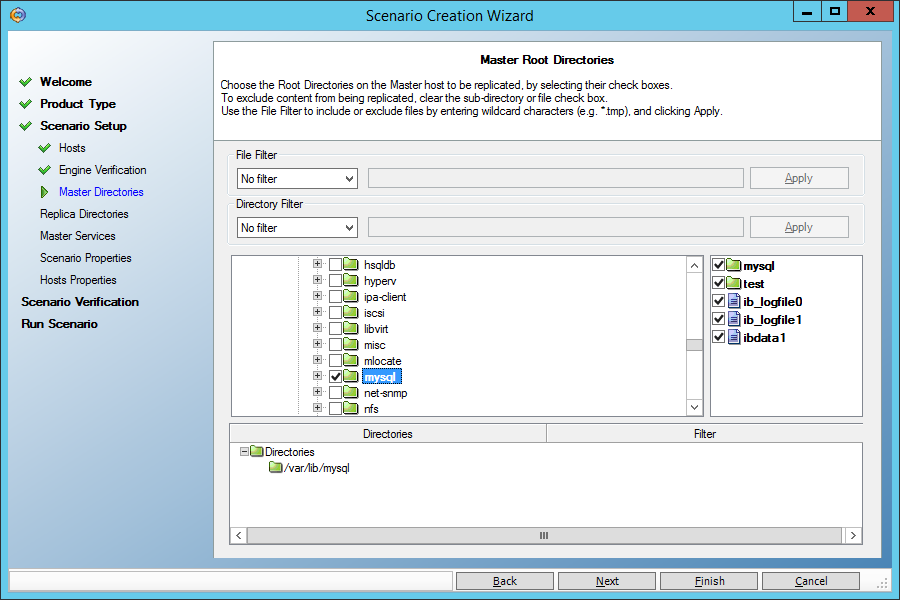
На экране, где задаются каталоги для репликации, задаём каталог с данными MySQL (var/lib/mysql/ в моём случае). Только убедитесь, что нём нет socket-файла mysql.sock. Если есть, укажите ему другое место в файле конфигурации my.cnf.
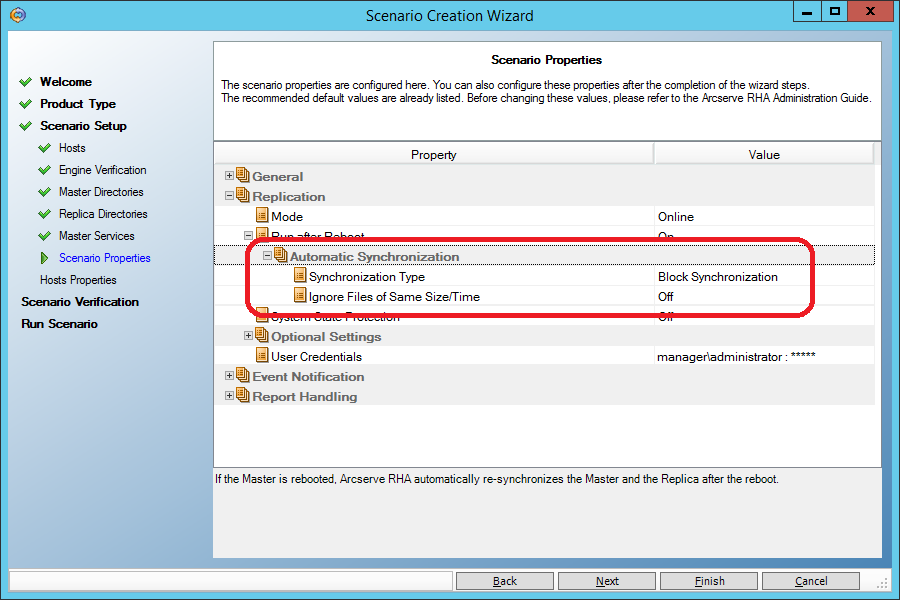
Не забываем, как во всех предыдущих сценариях, разрешить откат на момент времени в прошлом при восстановлении:

На машине co-master посмотрим на таблицу Table_1:
И испортим её, сделав фамилию во всех записах одинаковой:
Теперь вернём всё назад, воспользовавшись функцией восстановления на заданный момент времени. Как и раньше, остановим сценарий репликации и восстановим данные на обеих машинах. Но прежде всего остановим сервис mysqld:
Выберем точку во времени, когда база ещё не была испорчена:

После этого запустим сервис MySQL на машине master и убедимся, что данные восстановлены.
А теперь – сюрприз! Запустим сервис MySQL на машине co-replica и получим работающую базу на резервной машине. Мы вплотную подошли к расширенной функциональности Arcserve RHA, когда вместо потерянной системы в работу вступает резервная система с актуальными данными.
Сегодня мы подняли резервный сервис MySQL вручную. Но продукт Arcserve RHA способен самостоятельно запустить резервную систему так, чтобы она выглядела, как вышедшая из строя. Например, запустить необходимые сервисы, сменить записи в DNS, IP-адрес, даже NetBIOS-имя машины. Это возможно сделать в сценариях типа “High Availfbility”, но это уже тема для отдельной статьи.
В этой статье мы рассмотрели только основные возможности продукта Arcserve RHA, направленные на восстановление данных на заданный момент времени в прошлом. То есть, расшифровали только половину названия “Replication and High Availability”. В следующей статье вы увидите, как реализуется вторая часть названия – High Availability. Мы посмотрим, как вышедшая из строя машина (физическая или виртуальная) будет подменятся резервной машиной, содержащей актуальную копию данных.
[Реклама] В настоящее время, до конца сентября 2016 года, вы можете бесплатно получить продукт Arcserve RHA, приобретая продукт Arcserve UDP Premium Plus по цене Arcserve UDP Premium.
Подробнее можете узнать у партнеров компании Arcserve.

Даже самые дорогие системы, выполняющие периодическое резервное копирование (например, каждую ночь), обладают одним существенным ограничением: всё, что было сделано на компьютере после последнего резервного копирования, никак не защищено, и будет безвозвратно потеряно, если компьютер выйдет из строя.
Пусть, например, вчера была написана первая часть «Мёртвых Душ», и ночью сделана резервная копия. А сегодня написана вторая часть, и в эмоциональном порыве уничтожена ещё до того, как настало время очередного резервного копирования.
Бороться с такими ситуациями призвана технология непрерывного резервного копирования (Continuous Data Protection, CDP). Всё, что записывается на диск, одновременно отправляется в резервную копию.
Рассмотрим подробнее, как это делается в продукте Arcserve RHA (Replication and High Availability) на реальных примерах в средах Windows и Linux.
Содержание
Введение
1. Архитектура
2. Установка программного обеспечения
2.1. Установка управляющих компонентов
2.2. Установка управляемых компонентов на Windows
2.3. Установка управляемых компонентов на Linux
3. Эксперименты по восстановлению данных
3.1. Восстановление файлов на заданный момент времени
3.2. Восстановление базы данных MS SQL на заданный момент времени
3.3 Восстановление базы данных MySQL на Linux на заданный момент времени
4. Заключение и реклама
Введение
Пусть мы имеем два сервера.
Боевой сервер (Master) содержит постоянно обновляющиеся данные. Мы следим за изменениями и ведём ведомость (журнал) изменений в виде «было -> стало», например:
| Время | Содержимое файла «мытьё» | Журнал изменений |
|---|---|---|
| 10:30:51 | МАМА МЫЛА РАМУ | |
| 10:30:52 | МАМА МЫЛА ПАПУ | Файл «мытьё», смещение 10, «РАМ» -> «ПАП» |
Журнал изменений постоянно пересылается на резервный сервер (Replica) и применяется к его файлам. Таким образом файлы боевого и резервного серверов становятся идентичными.
Некоторые детали:
- Изменения отслеживаются на уровне байтов, то есть при изменении одного байта журнал будет содержать информацию только об этом байте, а не о всём блоке данных;
- Журнал изменений пересылается по обычной IP-сети, то есть разнести боевой и резервный серверы можно на значительные расстояния, в том числе, в разные города;
- При разрыве соединения данные накапливаются в буфере и, как только связь восстановится, будут переданы и применены к резервному серверу;
- История изменений (в заданном объёме, например, последние 500 Мегабайт) сохраняется на резервной машине и может быть применена в обратной последовательности, вернув содержимое файлов в состояние на определённый момент времени.
1. Архитектура
Для того, чтобы описанная выше схема заработала, нам потребуется установить на машины Master и Replica компонент, именуемый Engine, который берёт на себя основную работу по отслеживанию изменений в файлах и репликации данных с одной машины на другую.
Для того, чтобы сконфигурировать работу этих двух Engine, установим на ещё одну машину (Manager) сервис управления (Control Service). Эта машина требуется только для конфигурации, получения отчётов и запуска отдельных действий на управляемых машинах. Она не должна быть постоянно включенной.
Наконец, пользовательский интерфейс мы получим, соединившись интернет-браузером с сервисом управления, и скачав оттуда windows-приложение.
2. Установка программного обеспечения
Скачаем Arcserve RHA (iso или zip) с сайта разработчика (как указано на странице arcserve.zendesk.com/hc/en-us/articles/205009209-RHA-R16-5-SP5-ARCSERVE-RHA-16-5-SP5 ):
Продукт работает 30 дней без лицензионных ключей.
2.1. Установка управляющих компонентов
Начнём с того, что установим Control Service на управляющую машину (Manager).
Для его работы требуется .NET Framework 3.5.
В Windows 2012R2 .NET Framework 3.5 устанавливается так.
В Server Manager выбираем Manage -> Add Roles and Features. Отмечаем галочкой “.NET Framework 3.5 Features”.
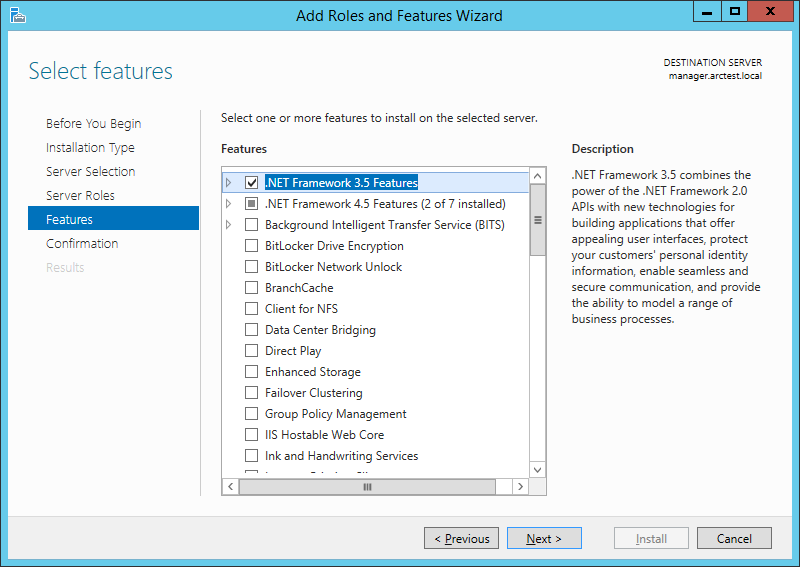
Важно! Нужно явно указать, где на дистрибутиве Windows находится этот компонент. Для этого на следующем экране нажать “Specify an alternate source path”:
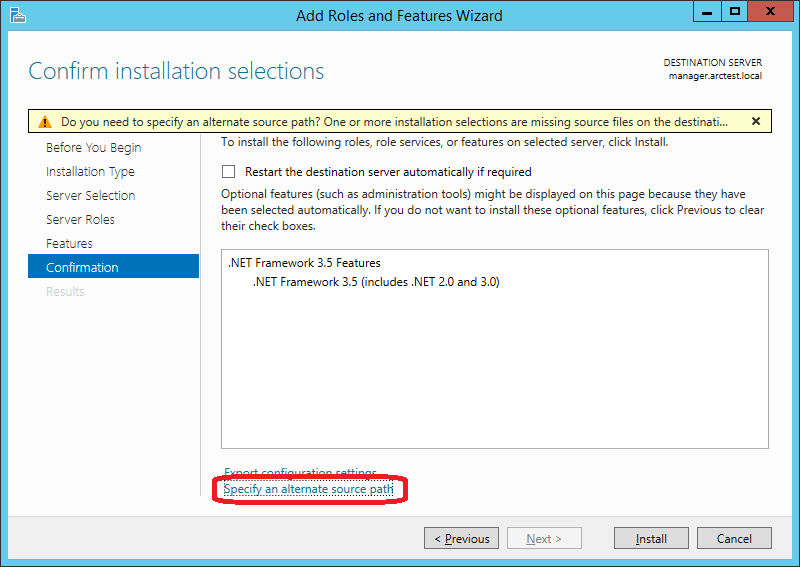
В моём случае путь выглядит вот так (D: — DVD c дистрибутивом Windows):

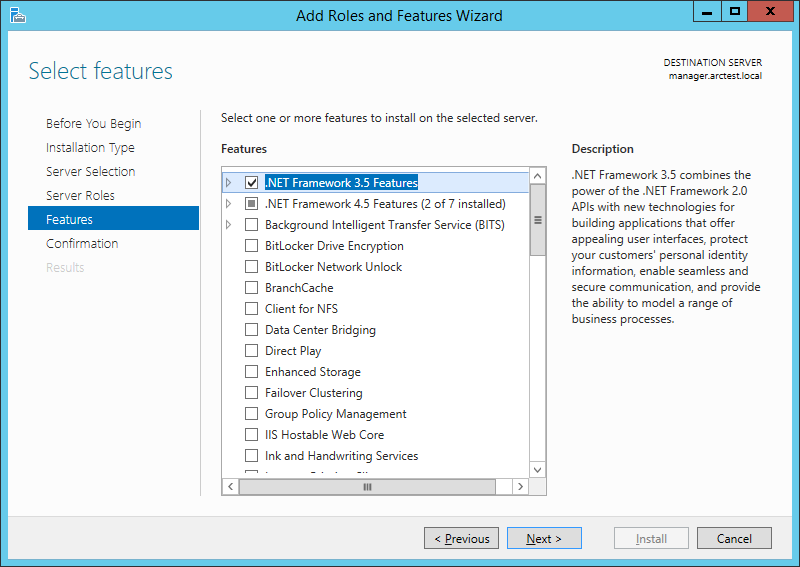
Важно! Нужно явно указать, где на дистрибутиве Windows находится этот компонент. Для этого на следующем экране нажать “Specify an alternate source path”:
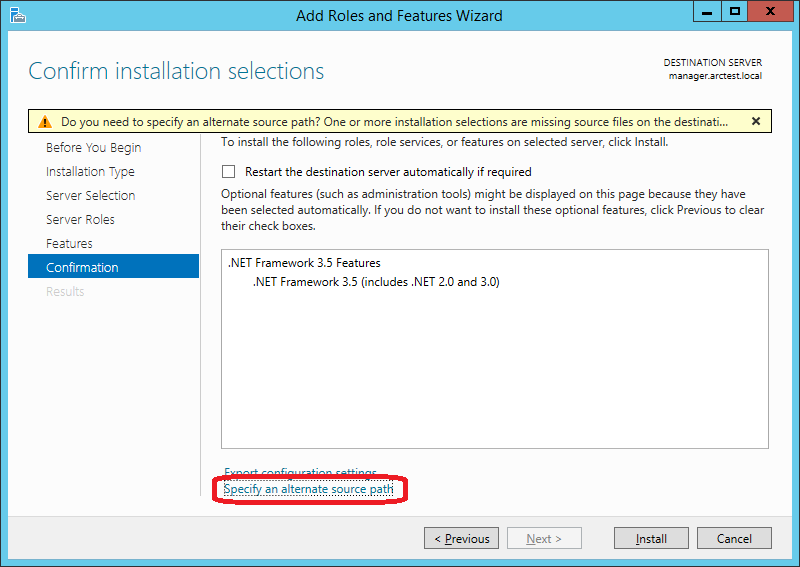
В моём случае путь выглядит вот так (D: — DVD c дистрибутивом Windows):
Теперь запускаем Setup.exe с дистрибутива Arcserve RHA и выбираем “Install Components”:

На следующем экране выбираем “Install Arcserve RHA Control Service”. (Особенность: на слова “Install Arcserve RHA …” кликнуть не получается, а на “… Control Service” – получается):

Потом прощёлкаем несколько экранов, пока не дойдём до конфигурации SSL. Для тестирования включать SSL не будем, а при рабочем применении можете добавить здесь ваш сертификат или использовать самоподписанный:
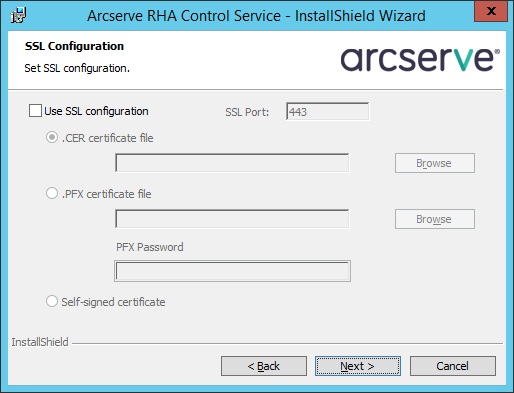
Будем запускать сервис от имени Local System:
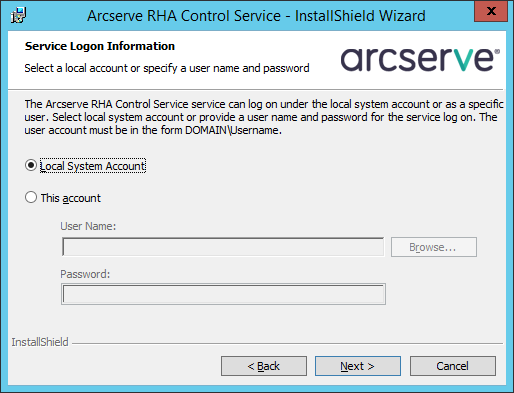
Следующий экран касается возможности иметь две управляющих машины для повышения отказоустойчивости. Мы для целей тестирования ограничимся одной:
После завершения установки соединимся интернет-браузером с машиной Manager на порту 8088. Войти можно под пользователем, у которого есть права локального администратора на машине Manager:
Мы получим доступ к странице, на которой будет публиковаться статистика работы различных машин. Но для реального управления нам потребуется скачать с этого сайта и запустить windows-утилиту “Arcserve RHA Manager”. Её можно запускать уже не на сервере, а на рабочей станции (например, Windows 7 или 10). Для скачивания нажмём на ссылку “Scenario Management”:
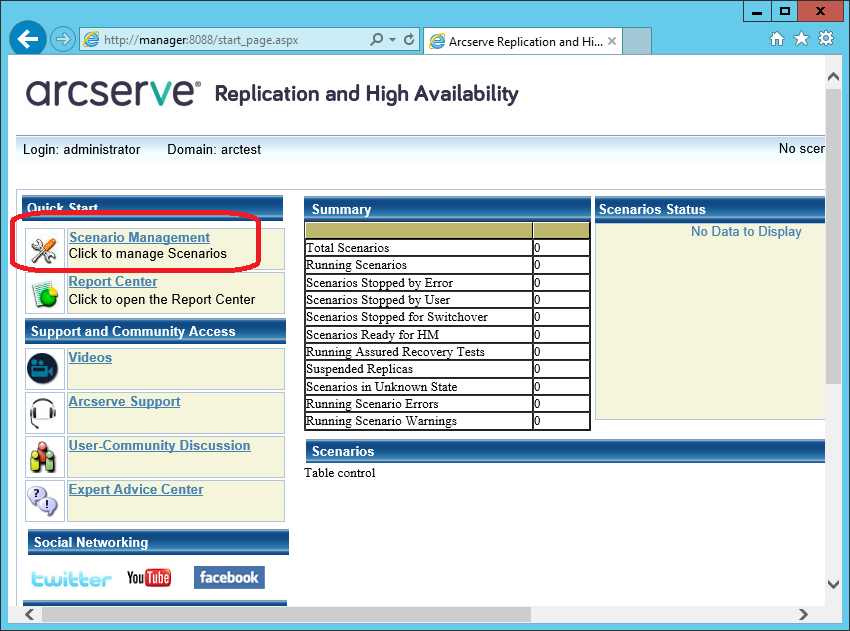
После предупреждений безопасности должна запуститься программа “Arcserve RHA Manager”:
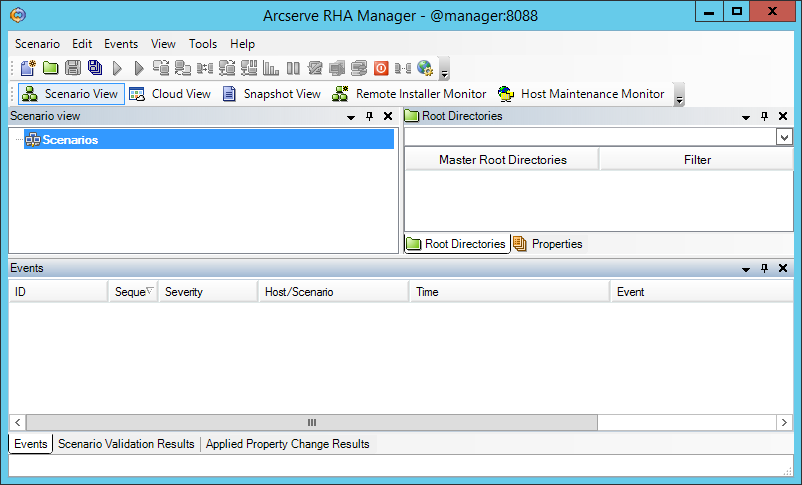
Эта программа и в дальнейшем будет запускаться только с веб-страницы.
2.2. Установка управляемых компонентов на Windows
На машины Master и Replica установим рабочие компоненты – Engine.
Можно установить их локально с дистрибутива, а можно – удалённо. Для удалённой установки на сервер требуется, чтобы у сервера была установлена роль “File Server”:
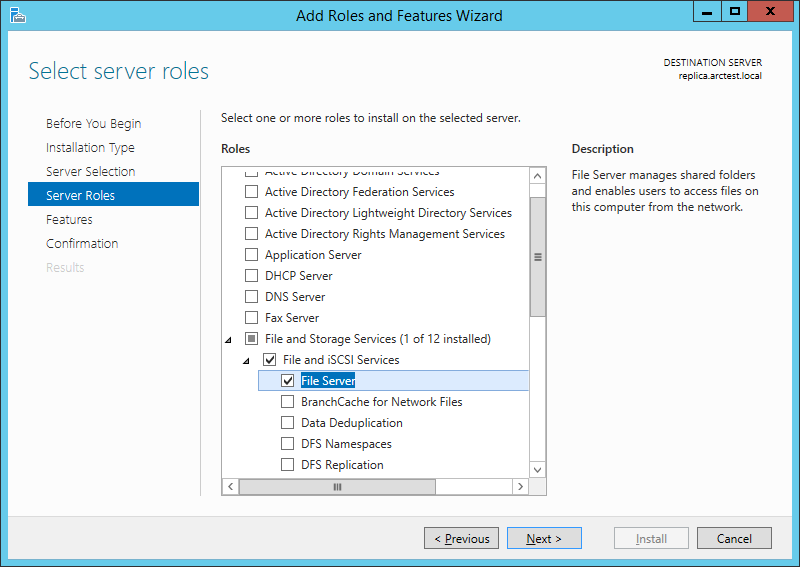
Если роль “File Server” установлена на машинах master и replica, то на машине Manager мы можем обратиться к “\\master\C$” и “\\replica\C$”.
Из утилиты Arcserve RHA Manager, о которой шла речь в предыдущем разделе, запустим удалённую установку через меню “Tools -> Launch Remote Installer”.
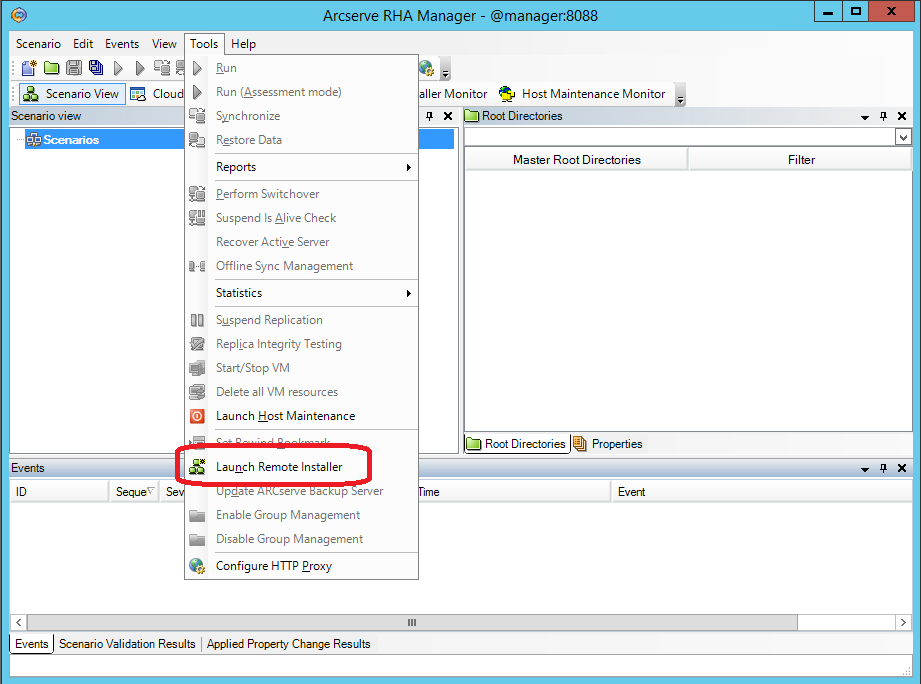
На следующем экране нажимаем кнопку “Start host discovery” (1) и получаем список машин из кэша Active Directory.
Выделяем машины master и replica и добавляем их в список кандидатов на установку Engine при помощи кнопки “Add” (3)
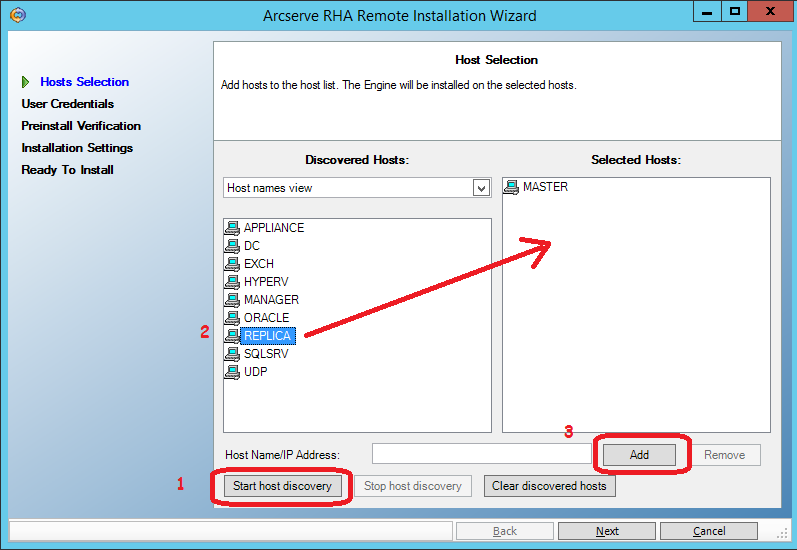
На следующем экране введём пользователя (администратора домена), под которым будет выполняться удалённая установка:
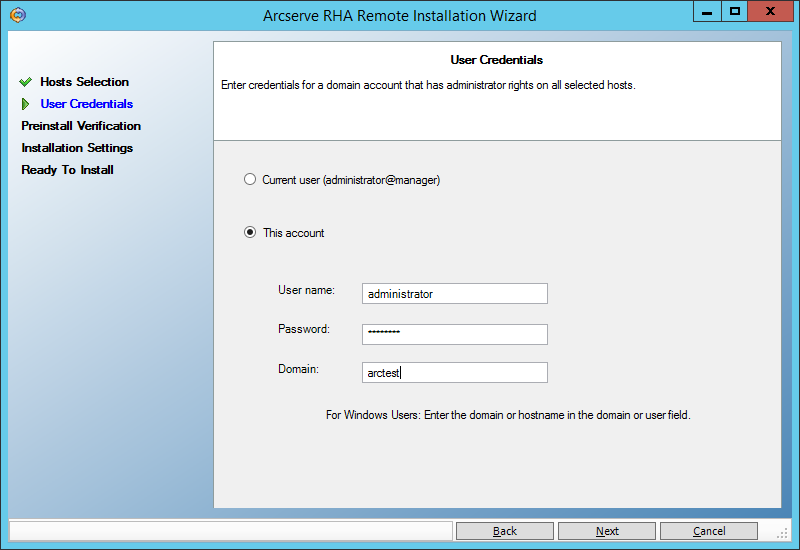
Далее убеждаемся, что оба сервера (master и replica) позволяют выполнить удалённую установку и помечены галочками:
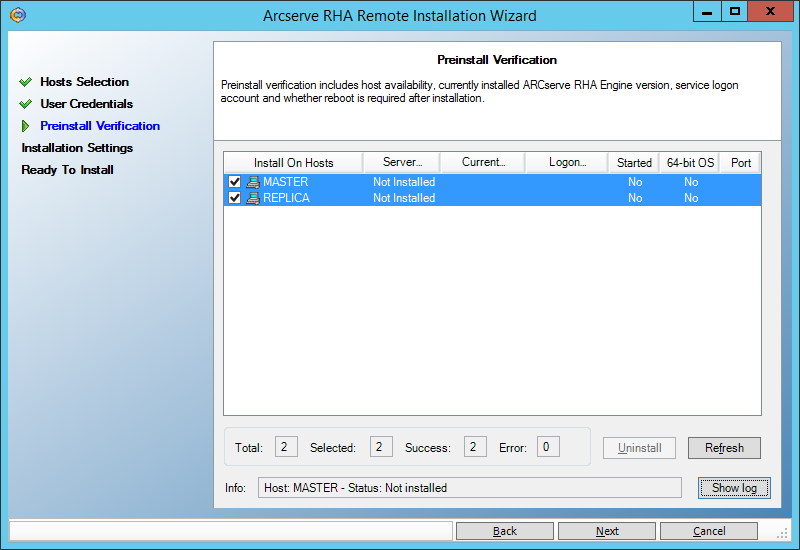
На следующем экране введём пользователя, под которым будет запускаться служба Engine.
Для целей непрерывного резервного копирования достаточно пользователя с правами локального администратора (Local System). А вот если мы хотим использовать функционал High Availability, когда резервная машина сможет изображать из себя вышедшую из строя основную машину, то нам нужно запускать сервис под доменным администратором. Описанный ниже пример из раздела () требует именно таких полномочий:
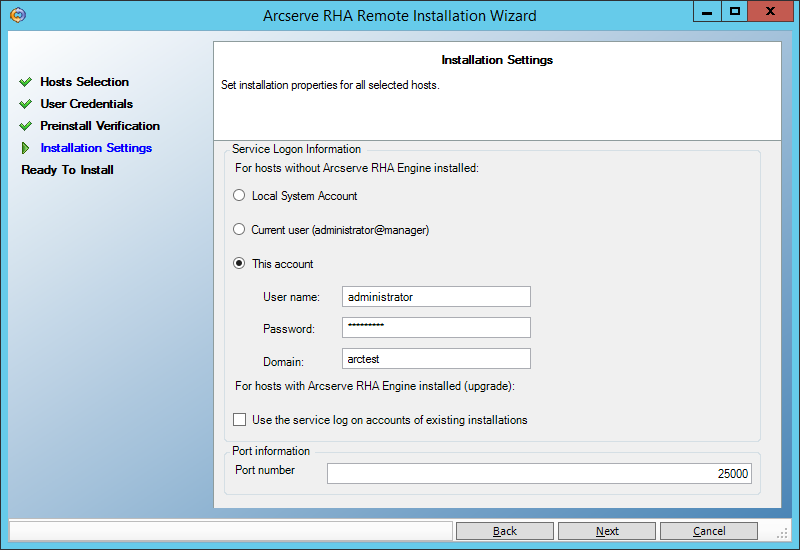
Нажимаем всякие Next -> Install -> Yes и ждём завершения установки:
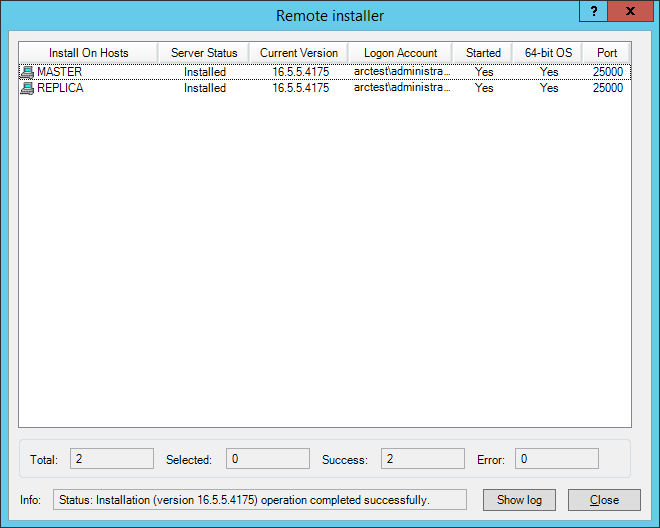
2.3. Установка управляемых компонентов на Linux
Установить компонент Engine на сервер можно, покопавшись в каталоге UNIX_Linux на дистрибутиве и найдя нужный агент в tar-архиве. В частности, для установки на CentOS 6.5 я использовал архив arcserverha_rhel6.tgz
Если на машине не установлены 32-битные библиотеки, нужно их поставить. Например, на CentOS 6.5 мне пришлось выполнить:
yum install glibc.i686 libstdc++.i686 pam.i686
(предварительно обновив их 64-битные версии: “yum install glibc libstdc++ pam” )
затем запускаем ./install.sh и соглашаемся со всеми подсказками.
В firewall открываем порт 25000 (TCP)
3. Эксперименты по восстановлению данных
3.1. Восстановление файлов на заданный момент времени
Создадим на машине Master каталог “C:\Ax-уехала-жена\” и положим туда файлы:
Таня.jpg
Лена.jpg
Джоконда.jpg
Создадим сценарий репликации этого каталога на машину Replica. В меню “Arcserve RHA Manager” выберем Scenario -> New
Первый экран мастера создания сценариев оставляем без изменений:
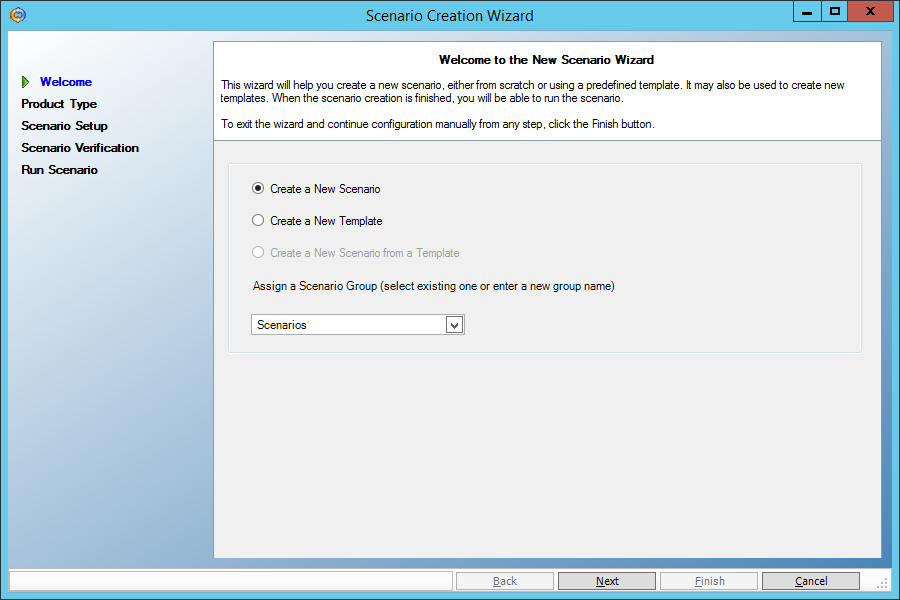
На втором экране также ничего не меняем – там должен быть выбран сценарий репликации файлов (File Server):

Выберем в качестве основной машины сервер Master, а в качестве резервной – Replica:
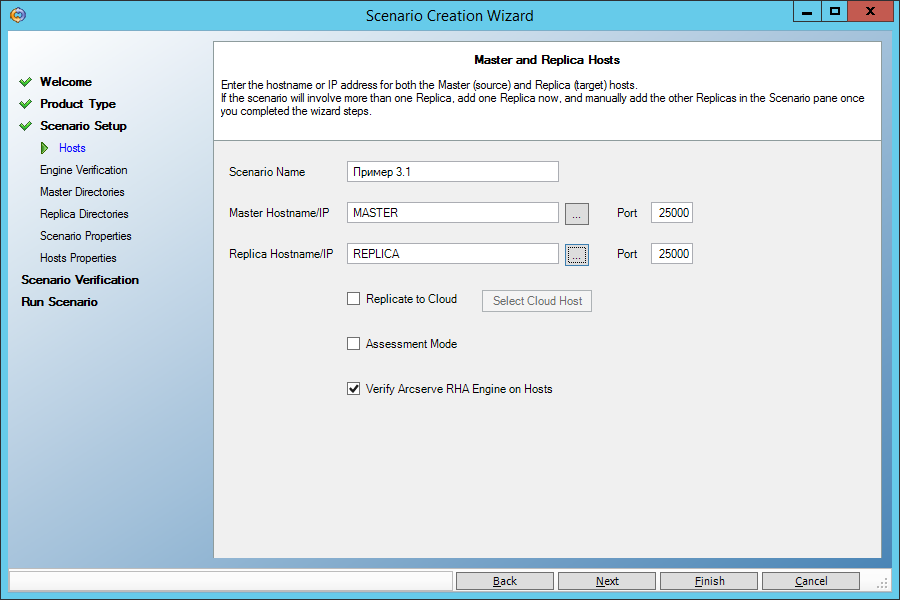
На следующем экране видим подтверждение того, что служба Engine установлена на обеих машинах. Если мы не установили её ранее, то можем сделать это удалённо отсюда.
На следующем экране выберем исходный каталог “C:\Ax-уехала-жена\” на машине Master:
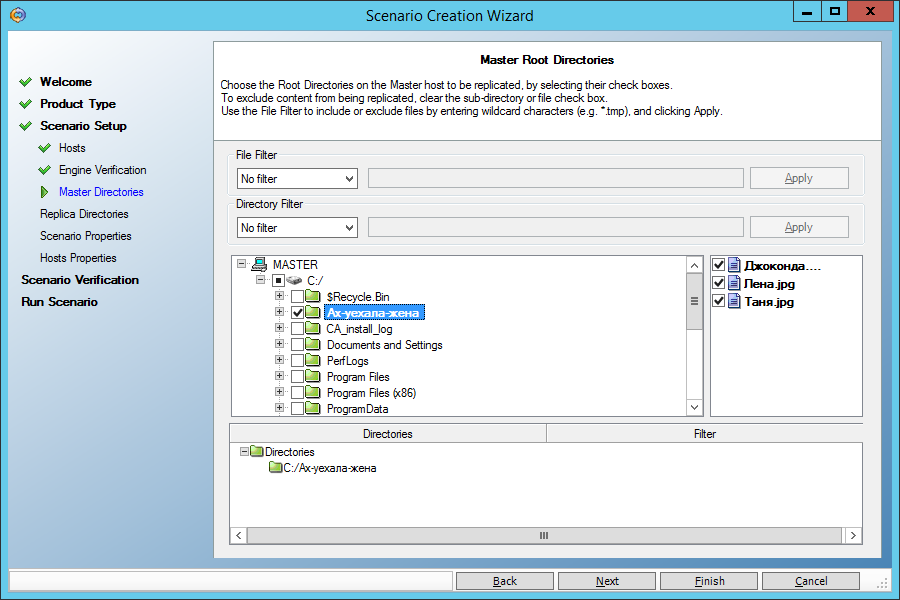
На следующем экране нам предложат реплицировать этот каталог в каталог с таким же именем на машине Replica. Согласимся:
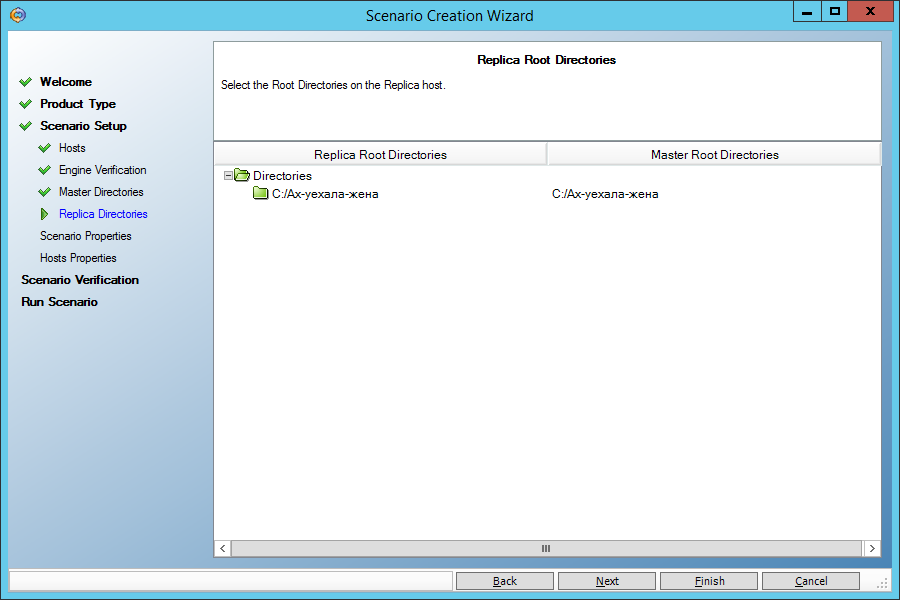
На следующем экране ничего не меняем:
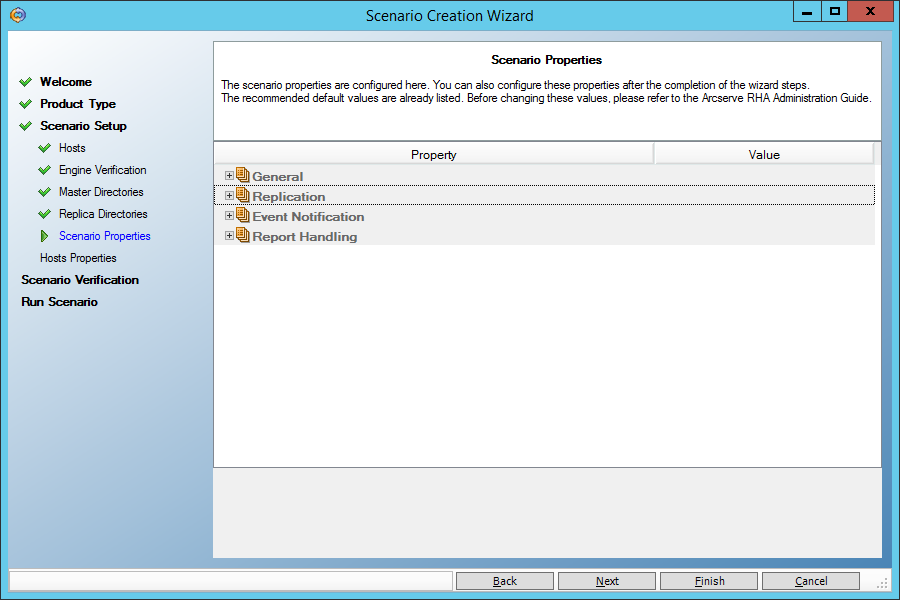
А вот здесь нам нужно выставить параметр “Data Rewind” в “On”, чтобы иметь возможность восстанавливать данные на произвольный момент времени в прошлом:

Наконец, нам скажут, что сценарий не содержит ошибок:
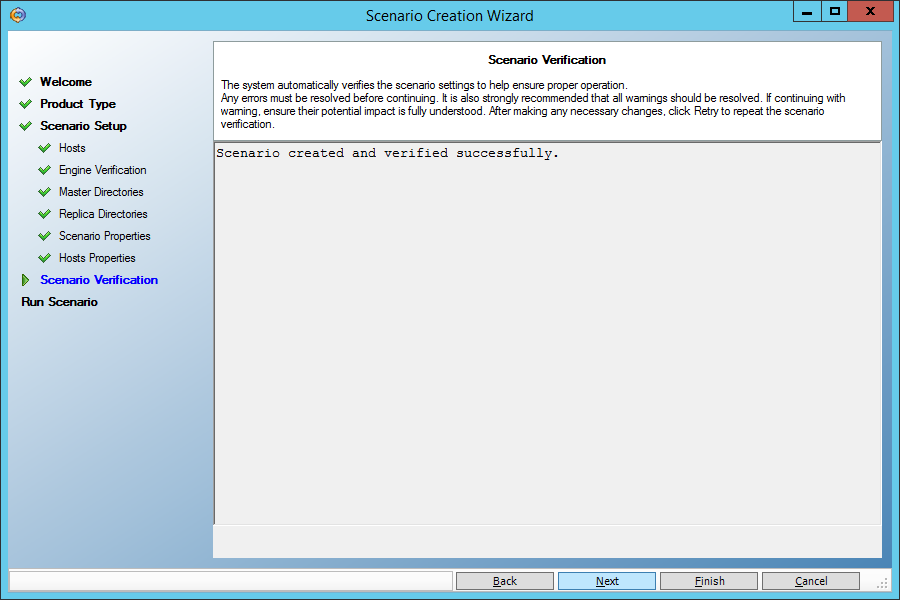
Запустим сценарий, нажав кнопку “Run Now”:

На главном экране мы увидим, как работает сценарий. Заданный каталог быстро синхронизируется (станет одинаковым на основной и резервной машине), и теперь любое изменение в каталоге на машине Master приведёт к аналогичному изменению его копии на машине Replica.
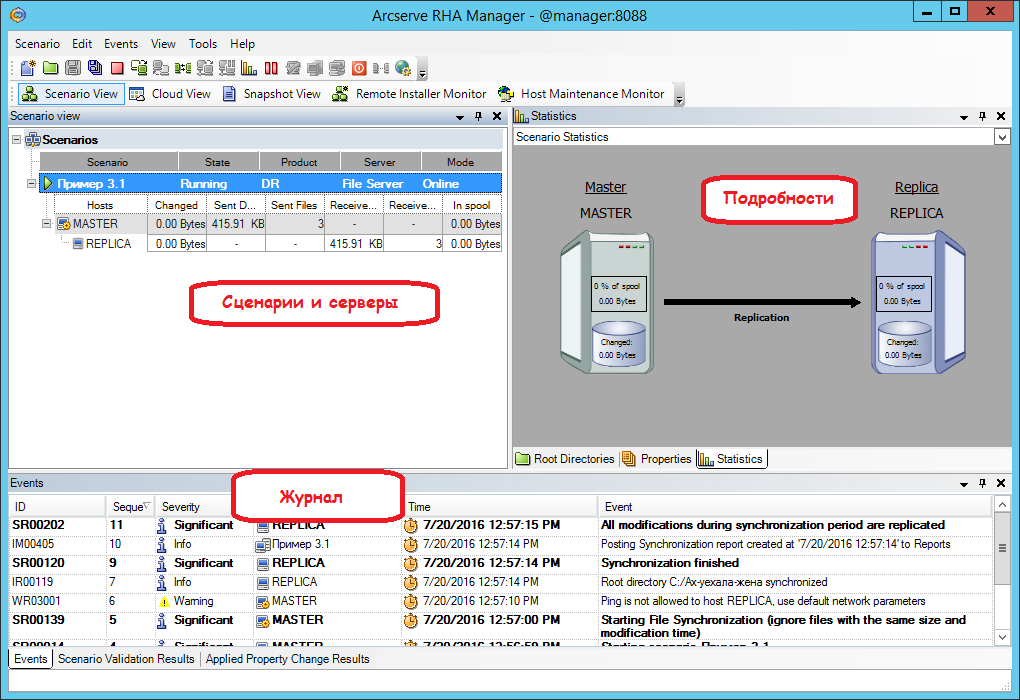
Выполним три действия на машине Master:
1. Изменим файл Джоконда.jpg

2. Сотрём файл Таня.jpg
3. Добавим файл Маша.jpg
Убедимся, что на машине Replica с файлами произошло то же самое.
Теперь мы хотели бы вернуть Джоконде прежний облик. Для этого отмотаем время назад на машине Replica, воспользовавшись инструментом Data Recovery.
Сначала мы должны остановить сценарий (меню Tools -> Stop)
Затем щёлкнуть мышью на машине Replica и вызвать меню Tools -> Data Recovery:
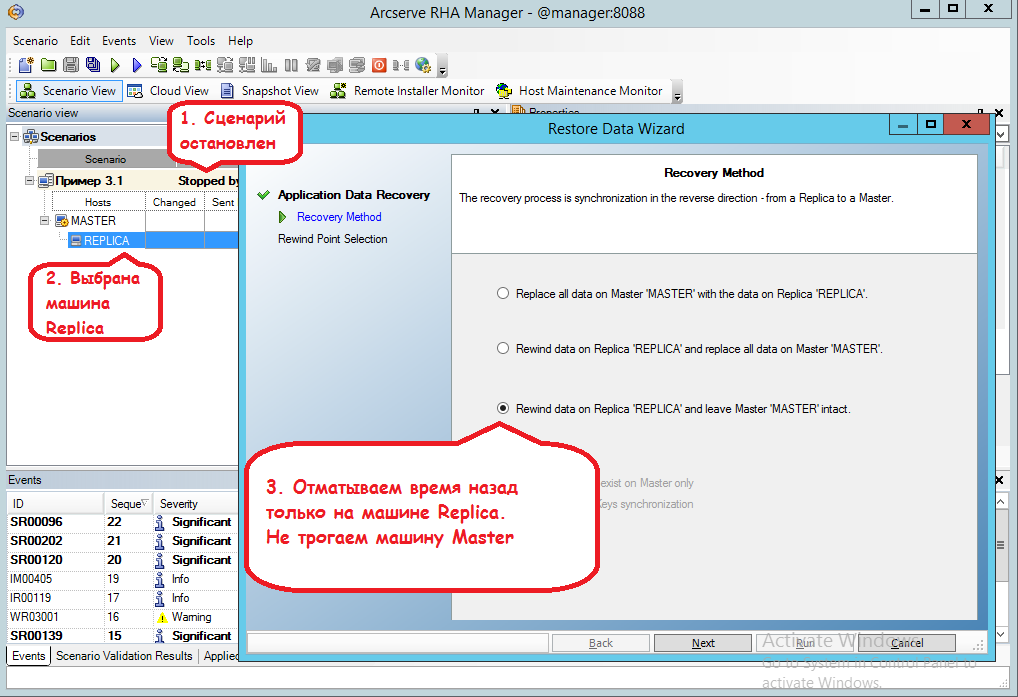
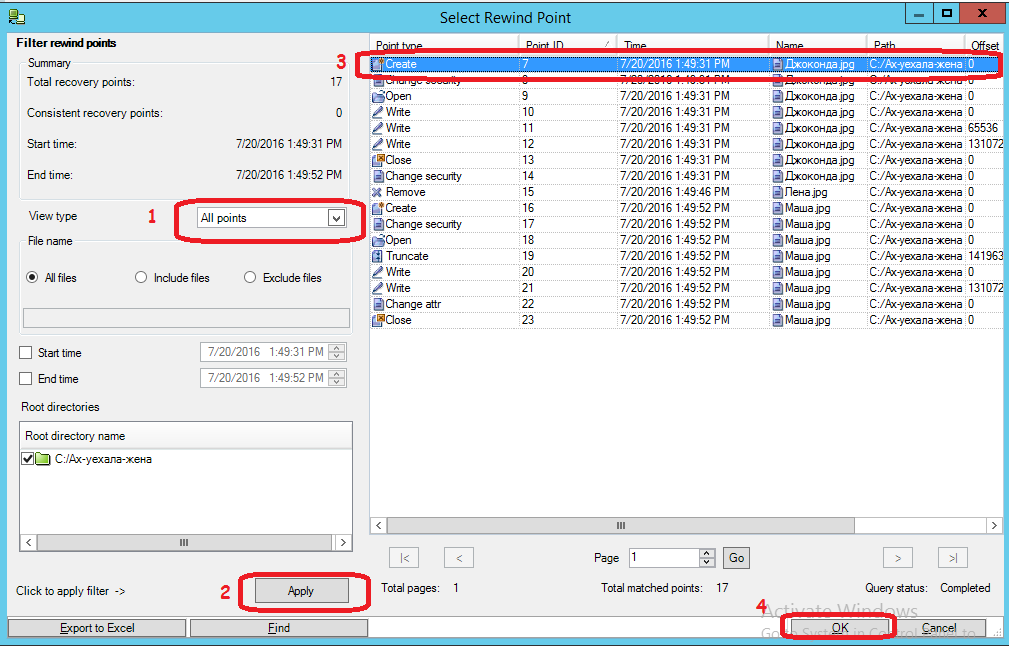
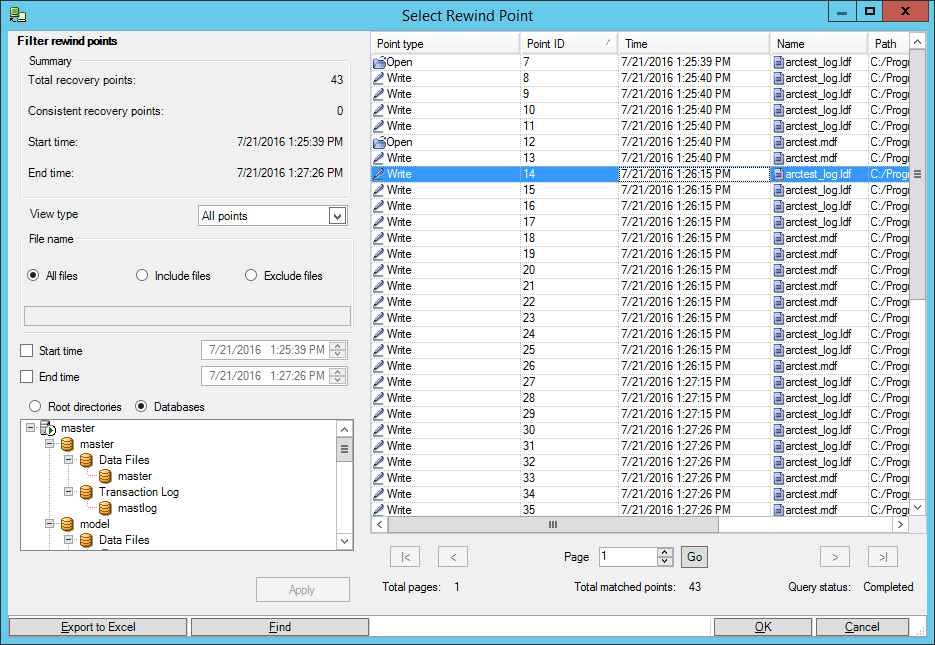
Нажав в следующем окне кнопку “Select Recovery Point”, попадаем вот в такое окно, где нужно:
(1) Установить просмотр всех временных точек, на которые возможен откат по времени
(2) Нажать кнопку Apply
(3) Выделить самую первую точку, когда Джоконда ещё не была повреждена
(4) Нажать на кнопку “OK”
Затем нажимаем кнопку “Run”:
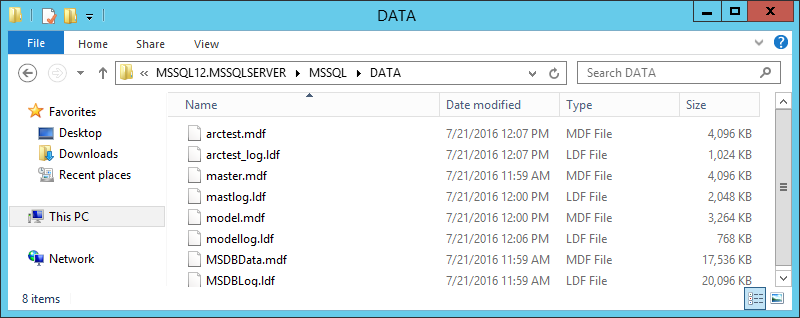
Проверяем, что произошло с файлами на машине Replica.
— Джоконда.jpg снова вернулась в начальное состояние
— Маша.jpg исчезла
— Лена.jpg появилась
Именно для того, чтобы не потерять Машу.jpg, мы не стали восстанавливать данные на обеих машинах. Теперь достаточно переписать файл “Джоконда.jpg” на машину Master, и мы снова получим в работу неиспорченный файл, не затрагивая все остальные.
3.2. Восстановление базы данных MS SQL на заданный момент времени
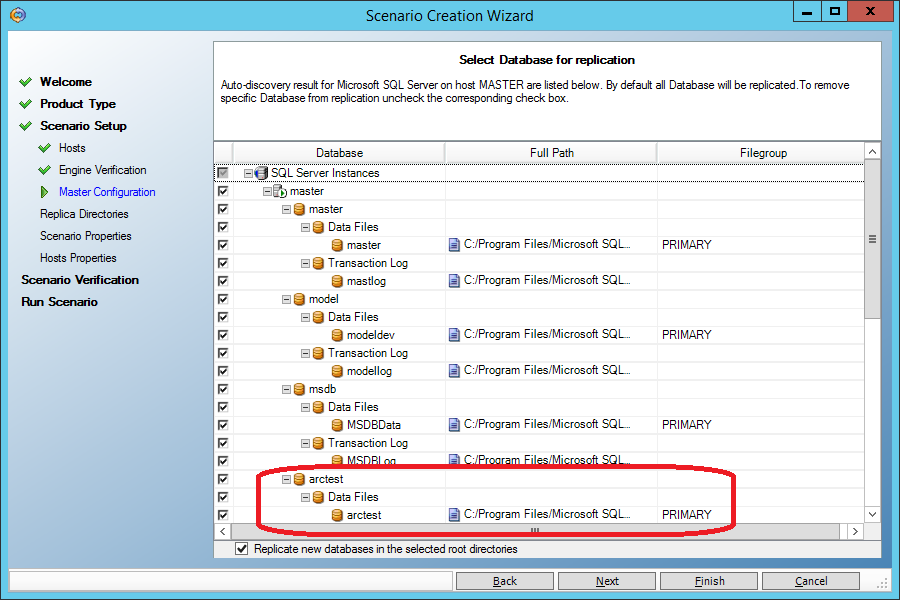
Предположим, что MS SQL установлен на машине Master. На машину Replica можно MS SQL не ставить, тогда она будет служить лишь хранилищем копии каталога DATA:
Сценарий репликации MS SQL похож на сценарий репликации файлов, но добавляются три вещи, которые облегчают нам жизнь:
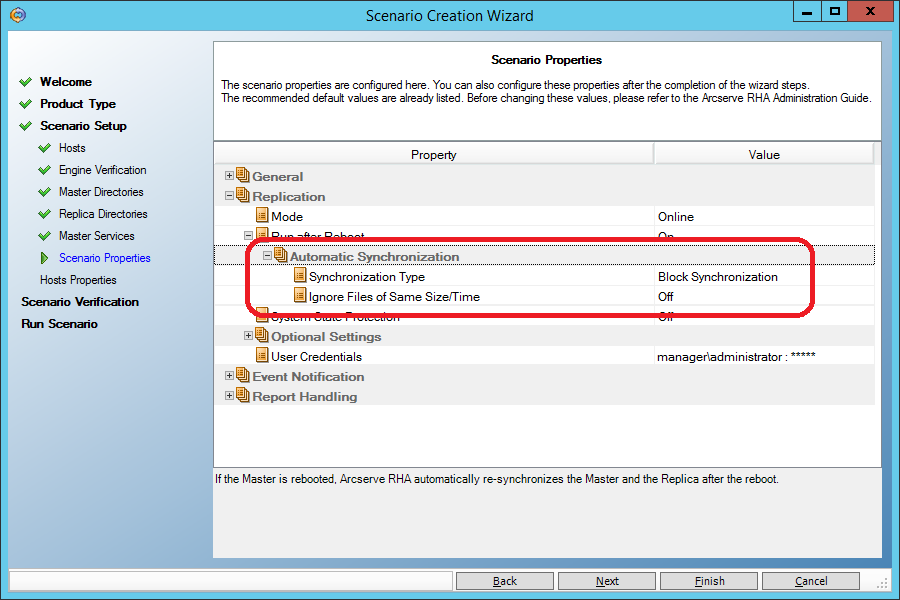
1. Выбирается правильный метод начальной синхронизации – поблочный. Перед тем, как начать репликацию, система должна убедиться, что данные на двух машинах идентичны и синхронизировать то, что отличается.
Для сценария типа “File Server” по умолчанию применяется упрощённая начальная синхронизация, при которой файлы считаются идентичными, если их размер и время изменения совпадают. Такое допущение даёт хорошую экономию времени начальной синхронизации на файловых серверах, но совершенно неприемлемо для баз данных, поэтому сценарий для MS SQL сравнивает один за другим все блоки данных, из которых состоят файлы.
2. нам не придётся явно указывать, где находятся файлы базы данных, эта информация автоматически подтянется:
2. при восстановлении данных на основную машину (Master) сервисы MS SQL будут автоматически потушены и переведены в режим ручного запуска. После восстановления всё вернётся на место:

Предположим, что кто-то забыл написать “where” в команде “update”:
begin transaction;
update dbo.Table_1 set name='Сидоров';
commit;
(кто сам такое делал – поймёт глубину падения).
Так же, как и в предыдущем случае, останавливаем сценарий репликации, запускаем “Tools->Data Recovery”, но выбираем восстановление не только на резервную машину, но и на основную:
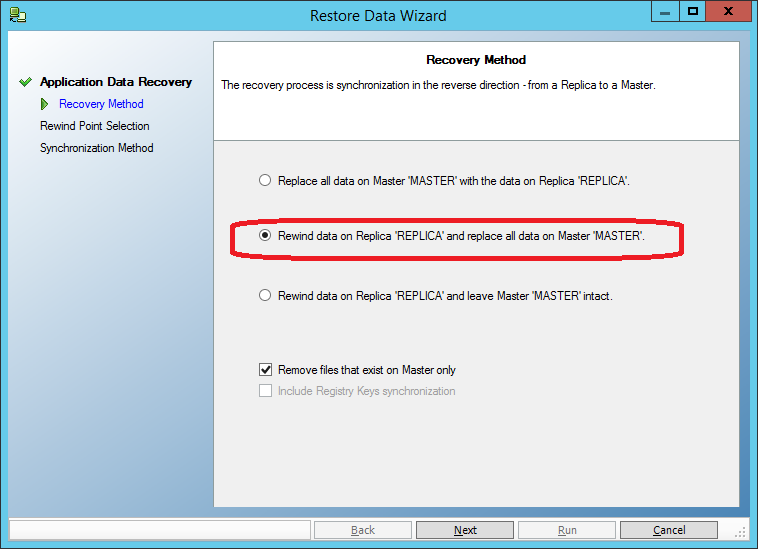
Остаётся только выбрать точку во времени, предшествующую моменту порчи данных, и провести восстановление:
3.3. Восстановление базы данных MySQL на Linux на заданный момент времени
На двух машинах co-master и co-replica установлены CentOS 6.5 и MySQL (в одинаковых каталогах).
Строго говоря, на резервной машине (co-replica) MySQL можно и не ставить, но мы попробуем зайти чуть дальше и подхватить реплицированные данные на резервном MySQL-сервере.
На машине co-master сервис MySQL запущен, на машине co-replica – выключен.
Создаём новый сценарий типа “Custom Application”.
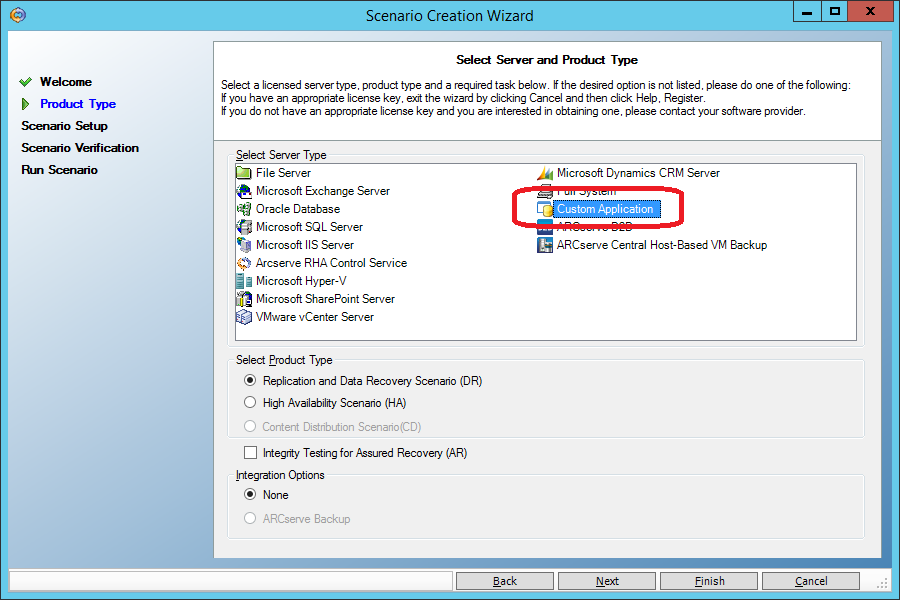
В отличие от сценария “File Server” (п. 3.1) сценарий “Custom Application” по умолчанию имеет поблочную начальную синхронизацию. Ещё раз повторю: для сценария типа “File Server” по умолчанию применяется упрощённая начальная синхронизация, при которой файлы считаются идентичными, если их размер и время изменения совпадают. Такое допущение даёт хорошую экономию времени начальной синхронизации на файловых серверах, но совершенно неприемлемо для баз данных, поэтому для репликации MySQL сценарий типа “File Server” неприемлем.
На экране, где задаются каталоги для репликации, задаём каталог с данными MySQL (var/lib/mysql/ в моём случае). Только убедитесь, что нём нет socket-файла mysql.sock. Если есть, укажите ему другое место в файле конфигурации my.cnf.
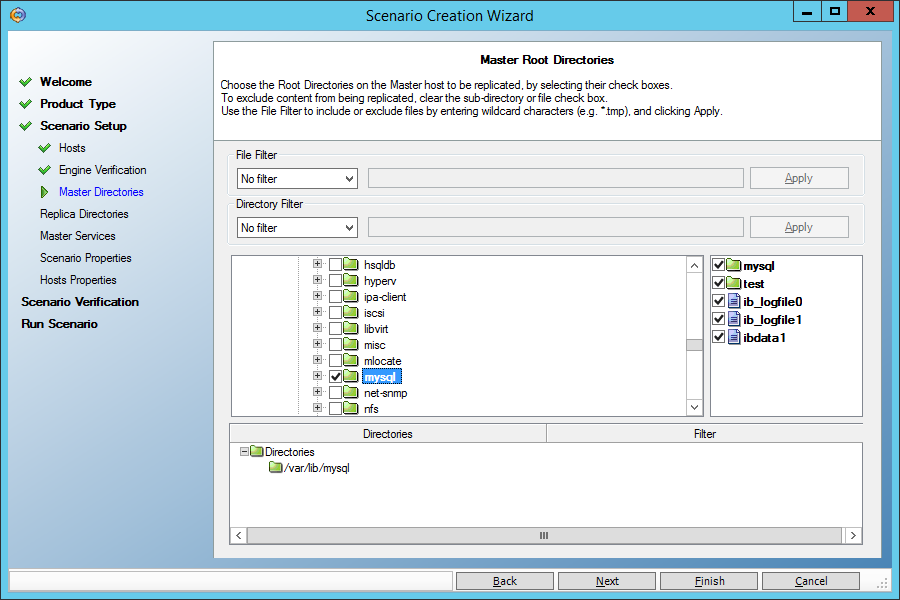
Не забываем, как во всех предыдущих сценариях, разрешить откат на момент времени в прошлом при восстановлении:

На машине co-master посмотрим на таблицу Table_1:
mysql> select * from Table_1; +----+--------------+ | id | name | +----+--------------+ | 1 | Иванов | | 2 | Петров | +----+--------------+ 2 rows in set (0.01 sec)
И испортим её, сделав фамилию во всех записах одинаковой:
mysql> update Table_1 set name='Сидоров'; Query OK, 2 rows affected (0.00 sec) Rows matched: 2 Changed: 2 Warnings: 0
Теперь вернём всё назад, воспользовавшись функцией восстановления на заданный момент времени. Как и раньше, остановим сценарий репликации и восстановим данные на обеих машинах. Но прежде всего остановим сервис mysqld:
[root@co-master mysql]# service mysqld stop Stopping mysqld: [ OK ]
Выберем точку во времени, когда база ещё не была испорчена:
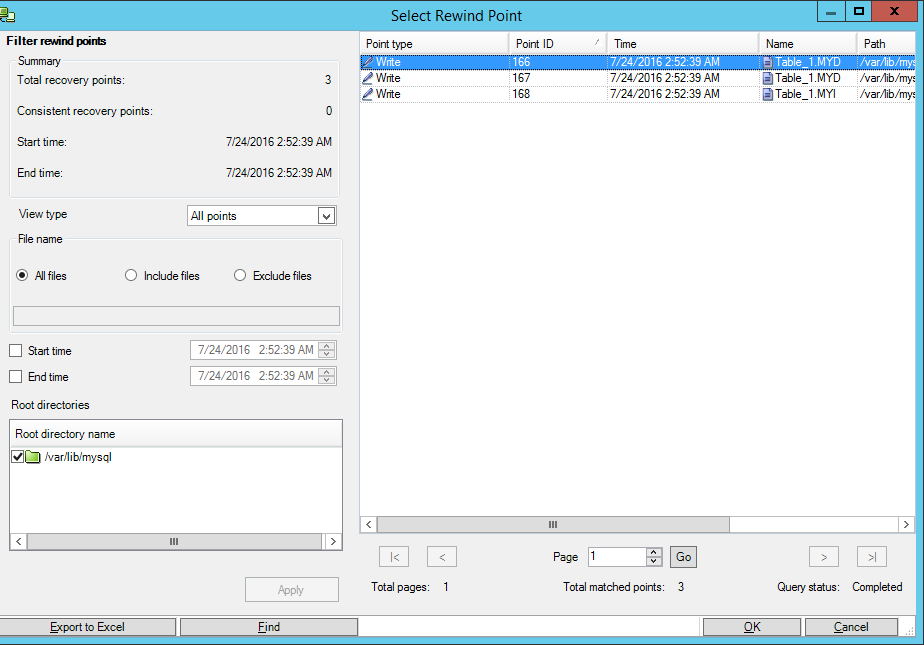
После этого запустим сервис MySQL на машине master и убедимся, что данные восстановлены.
А теперь – сюрприз! Запустим сервис MySQL на машине co-replica и получим работающую базу на резервной машине. Мы вплотную подошли к расширенной функциональности Arcserve RHA, когда вместо потерянной системы в работу вступает резервная система с актуальными данными.
Сегодня мы подняли резервный сервис MySQL вручную. Но продукт Arcserve RHA способен самостоятельно запустить резервную систему так, чтобы она выглядела, как вышедшая из строя. Например, запустить необходимые сервисы, сменить записи в DNS, IP-адрес, даже NetBIOS-имя машины. Это возможно сделать в сценариях типа “High Availfbility”, но это уже тема для отдельной статьи.
4. Заключение и реклама
В этой статье мы рассмотрели только основные возможности продукта Arcserve RHA, направленные на восстановление данных на заданный момент времени в прошлом. То есть, расшифровали только половину названия “Replication and High Availability”. В следующей статье вы увидите, как реализуется вторая часть названия – High Availability. Мы посмотрим, как вышедшая из строя машина (физическая или виртуальная) будет подменятся резервной машиной, содержащей актуальную копию данных.
[Реклама] В настоящее время, до конца сентября 2016 года, вы можете бесплатно получить продукт Arcserve RHA, приобретая продукт Arcserve UDP Premium Plus по цене Arcserve UDP Premium.
Подробнее можете узнать у партнеров компании Arcserve.
