Немного истории
В самом начале 2010 года Vincent Driessen пишет отличную статью A successful Git branching model. Для понимания того, о чем пойдет речь дальше, со статьей нужно, конечно же, познакомиться. А для тех, кому сложен язык оригинальной статьи, на хабре есть её отличный перевод.
С этого момента описанная модель ветвления GitFlow, начинает, что называется, расходиться по миру. Её берут на вооружение многие команды. Авторы пишут много статей об успешном её использовании. Она получает поддержку в большинстве инструментов, которые используют разработчики:
- Плагин к самому Git'у
- Плагины к различным IDE: IDEA, Eclipse
- Встроенная поддержка в GUI клиентах: SourceTree и Git Extensions
- Плагины для систем сборки: Maven, Gradle, и т.д.
- Встроенная поддержка в менеджерах репозиториев: GitHub, BitBucket, GitLab и т.д.

Кажется, что модель идеальна. Быть может так оно и есть, если у вас небольшая команда, неизменяемый скоуп релизов, высокая культура работы с VCS. Тогда, действительно, GitFlow может и удовлетворит все ваши потребности. Но, к сожалению, описанные условия подходят не всем командам и не всем проектам. К слову, найти статьи, в которых бы авторы описывали проблемы этой модели не так уж и просто даже в 2016 году. Но как мы все знаем, серебряной пули нет, а, значит, и в этой модели всё хорошо далеко не для всех.
Что не так с классическим GitFlow?
История начинается с того, что классический GitFlow предполагает большое число merge-коммитов. Причем проблема не в самих merge-коммитах (которые, как вы дальше увидите, всё равно будут присутствовать в истории), а в их огромном количестве. Дебаты на тему «Merge vs Rebase» часто встречаются на просторах интернета (поисковики подскажут). У Atlassian, кстати, есть хорошая статья, в которой описывается разница этих двух подходов. Так в чем же дело?
История коммитов становится просто ужасной. На фото ниже всего один день работы команды.

Да, у нас естьgit log --first-parentи другие возможности отфильтровать дерево, но это несильно помогает полноценному анализу истории. Если же у команды разработчиков, кроме классического GitFlow, нет никаких других соглашений по ведению Git-репозитория, то в этой истории можно будет целыми пачками наблюдать коммиты c абсолютно бессмысленными сообщениями "fix", "refactoring", "", и т.д. Это сделает историю коммитов практически непригодной даже для самого поверхностного анализа.
Если ваш релизный скоуп меняется (а в Agile это бывает не редко), то классический GitFlow вам вряд ли подойдет. Если в вашем рабочем процессе часто встречаются фразы, попадающие под шаблон "Заказчику срочно нужна сборка, в которой [\w]*", то с историей коммитов, наглядно представленной в предыдущем пункте, ваша жизнь превратится в сущий ад. Я не шучу.
- Из-за merge-коммитов усложняется использование
git bisect

А что хотелось бы?
Очень сложно объяснить, почему так важно, чтобы история коммитов была чистой. Опытным разработчикам не требуется объяснения, почему чистым должен быть исходный код, для них это утверждение — аксиома. На мой взгляд аналогия тут абсолютно прямая. Также как и каждая строчка чистого кода, каждый коммит истории должен быть на своем месте и понятен любому, даже стороннему, разработчику. Да, грязный код тоже может быть рабочим, но на сколько удобно с ним работать? Как быстро удастся в нем разобраться новому сотруднику? То же самое и с историей коммитов. Даже грязная история будет знать абсолютно всё обо всех изменениях в проекте, но удобно ли будет с ней работать?
Для того чтобы работа с Git-репозиторием была простой, удобной и понятной, на мой взгляд необходимы всего две вещи:
Линейность истории изменений. Это свойство ограничивает толщину дерева коммитов константой, делая его максимально простым и наглядным для анализа.
- Логическая завершенность каждого коммита. Это свойство сильно увеличивает гибкость истории изменений. В этом случае, если потребуется, отдельные доработки могут быть без лишних сложностей перенесены с помощью команды
git cherry-pick. Или полностью отменены с помощью командыgit revert, которая в случае простого коммита гораздо проще, чем в случае merge-коммита.
Если оба свойства выполняются, дерево коммитов будет выглядеть следующим образом:

Как этого достигнуть?
Нужно совсем не много подредактировать классический GitFlow. При этом работа с develop, master, release и hotfix бранчами остаётся ровно такой же, как и в классическом GitFlow. Правки же коснутся исключительно работы с feature-бранчами.
Перед вливанием feature-бранча в итоговый, ему необходимо сделать интерактивный rebase командой
git rebase -i develop, при этом все промежуточные коммиты в бранче слить (squash'ить) в один. Бывают случаи, когда историю коммитов в feature-бранче имеет смысл оставить, но эти случаи на практике очень редки. При хорошей декомпозиции задач каждая небольшая задача представляет собой атомарное и логически завершенное изменение системы, которое отлично укладывается в одном коммите. Учитывая, что все изменения в рамках задачи можно соединить в один коммит в самый последний момент, во время работы над задачей разработчик может по-прежнему беспрепятственно создавать множество промежуточных коммитов, необходимых ему для потенциального отката. Ну и не лишним будет добавить, что есть отличная команда rerere, помогающая разработчикам, часто выполняющим операцию rebase.
Заливать feature-бранч в удалённый репозиторий необходимо с помощью команды
git push --force, так как в предыдущем пункте мы произвели rebase-бранча.
- Вливать feature-бранч в итоговый необходимо командой
git merge --ff-only feature, так как только в этом случае удастся сохранить линейность истории коммитов и избежать появления merge-коммита.
Как видите, изменений по работе с репозиторием совсем не много. И, подводя некий итог этой части статьи, хочу поделиться ссылкой на отличную статью, где также рассматриваются плюсы и минусы классического GitFlow и Rebase Flow.
Поддержка Rebase Flow в менеджерах репозиториев
Как я уже упоминал в самом начале статьи, поддержка классического GitFlow есть во множестве инструментов, в том числе и в различных менеджерах репозиториев. Поэтому дальше я рассмотрю вопрос о том, как сейчас обстоят дела с поддержкой Rebase Flow в популярных менеджерах репозиториев. При этом моя оценка будет в формате обычной университетской отметки.
GitHub
Поддержка Rebase Flow: ХОРОШО
На самом деле, у GitHub есть практически всё что нужно. В настройках репозитория есть галочка «Allow squash merging».
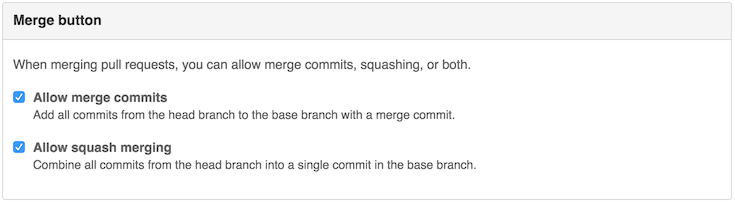
Она позволяет при мерже pull request'а выбрать соответствующий пункт и отредактировать итоговое сообщение к коммиту

В результате pull request будет смержен линейно и все коммиты будут схлопнуты в один.
Единственный минус, который я вижу на стороне GitHub, это
- отсутствие возможности смержить pull request без слияния коммитов. Очень редко, но это всё-таки требуется и, в случае с GitHub, этот мерж придётся выполнить вручную.
Всё вышесказанное относится и к GitHub Enterprise, который может быть развернут на серверах вашей компании.
BitBucket
Поддержка Rebase Flow: НЕУДОВЛЕТВОРИТЕЛЬНО
А по факту её просто нет. Если вы хотите использовать в своей работе Rebase Flow, то BitBucket в этом вам никак не поможет, всё придётся делать самостоятельно.
И это удивительно, учитывая что по тексту этой статьи я не раз ссылался на отличные статьи с сайта Atlassian. Будем надеяться, что в будущем ситуация с поддержкой Rebase Flow изменится, тем более что задачи на это уже давно заведены
- Forced non fast forward merge of pull request?
- Provide the option to use "git merge --squash" for pull requests
- Force fast-forward only merges on pull requests for specific branches
- Detect and handle rebasing and auto-merge in more situations
- и т.д.
Давайте теперь посмотрим, что с поддержкой Rebase Flow у платного продукта от Atlassian.
Atlassian BitBucket Server (a.k.a. Atlassian Stash)
Поддержка Rebase Flow: УДОВЛЕТВОРИТЕЛЬНО
Я рассматриваю BitBucket v4.5.2 и, возможно, в будущих версиях ситуация изменится в лучшую сторону. Сейчас же с поддержкой в BitBucket Server несколько лучше, чем в его облачном брате. Если у вас есть доступ к администраторам, то вы можете их любезно попросить в файле bitbucket.properties поменять для вашего проекта/репозитория настройки мержа pull request'ов (документация)
plugin.bitbucket-git.pullrequest.merge.strategy.KEY.slug— настройка для конкретного репозиторияslugв проектеKEY.plugin.bitbucket-git.pullrequest.merge.strategy.KEY— настройка для конкретного проектаKEY.plugin.bitbucket-git.pullrequest.merge.strategy— глобальное настройка для всего BitBucket Server.
Значения настроек могут быть следующими
no-ff— никакого fast-forward. Это значение по умолчанию.ff–- при возможности, будет выполнен fast-forward мерж.ff-only— всегда fast-forward мерж. Вы просто не сможете смержить pull request, если это нельзя сделать линейно.squash— сливает все коммиты в один и не создает merge-коммита.squash-ff-only— сливает все коммиты в один и не создает merge-коммита, но делает это только в том случае, если возможен fast-forward мерж.
Как вы видите, настройки достаточно гибкие, но есть две проблемы
- Нет web-интерфейса настроек, а обращения к администраторам сильно усложняют рабочий процесс.
- Нельзя выбрать поведение для конкретного pull request'а, минимальной настраиваемой сущностью является репозиторий.
Как только эти две проблемы будут устранены, поддержку Rebase Flow у BitBucket можно будет оценить на отлично. А пока ...
GitLab
Поддержка Rebase Flow: ХОРОШО
Оценивая поддержку на https://gitlab.com, мы, по сути, оцениваем поддержку в продукте GitLab EE, на базе которого он реализован. Что же касается поддержки Rebase Flow в GitLab CE, то её там попросту нет.
Для понимания того, как именно организована поддержка Rebase Flow, взглянем на настройки проекта

Как вы видите, тут даже есть промежуточный вариант полулинейной истории, когда merge-коммиты остаются, но возможность принять pull request появляется только в том случае, если feature-бранч является линейным продолжением. Если выбран этот вариант с полулинейной историей или «Fast-forward merge», у нас появляется дополнительная возможность управления pull request'ом. А именно появляется кнопка «Rebase onto ...», позволяющая сделать из feature-бранча линейное продолжение истории.
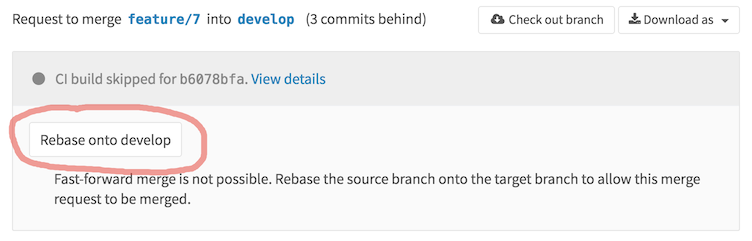
После чего можно без проблем принять pull request, который будет смержен без создания отдельного merge-коммита.

Более подробное описание этой функциональности можно посмотреть в документации (раз, два). Несмотря на то, что скриншоты в ней немного устарели, она не потеряла своей актуальности. На этом в принципе поддержка Rebase Flow заканчивается. То что она вообще есть — это, конечно, плюс, но в ней явно не хватает
- Возможности выбрать поведение для конкретного pull request'а. Да, перед принятием pull request'а можно поменять настройки самого проекта, но это не очень удобно.
- Возможности автоматического слияния коммитов feature-бранча в один.
Что в итоге?
Сейчас большинство менеджеров Git-репозиториев реализуют поддержку Rebase Flow в каком-то виде. И удобство работы в них сейчас на порядок выше, чем несколько лет назад. Но всё-таки, на мой взгляд, минусы пока есть у всех продуктов, и я продолжаю верить, что в будущем они их исправят.
