Badoo — это проект с гигантским git-репозиторием, в котором есть тысячи веток и тегов. Мы используем сильно модифицированный GitPHP (http://gitphp.org) версии 0.2.4, над которой сделали множество надстроек (включая интеграцию с нашим workflow в JIRA, организацию процесса ревью и т.д.). В целом нас этот продукт устраивал, пока мы не стали замечать, что наш основной репозиторий открывается более 20 секунд. И сегодня мы расскажем о том, как мы исследовали производительность GitPHP и каких результатов добились, решая эту проблему.
При разработке badoo.com в девелоперском окружении мы используем весьма простую debug-панель для расстановки таймеров и отладки SQL-запросов. Поэтому первым делом мы переделали ее в GitPHP и стали измерять время выполнения участков кода, не учитывая вложенные таймеры. Вот так выглядит наша debug-панель:
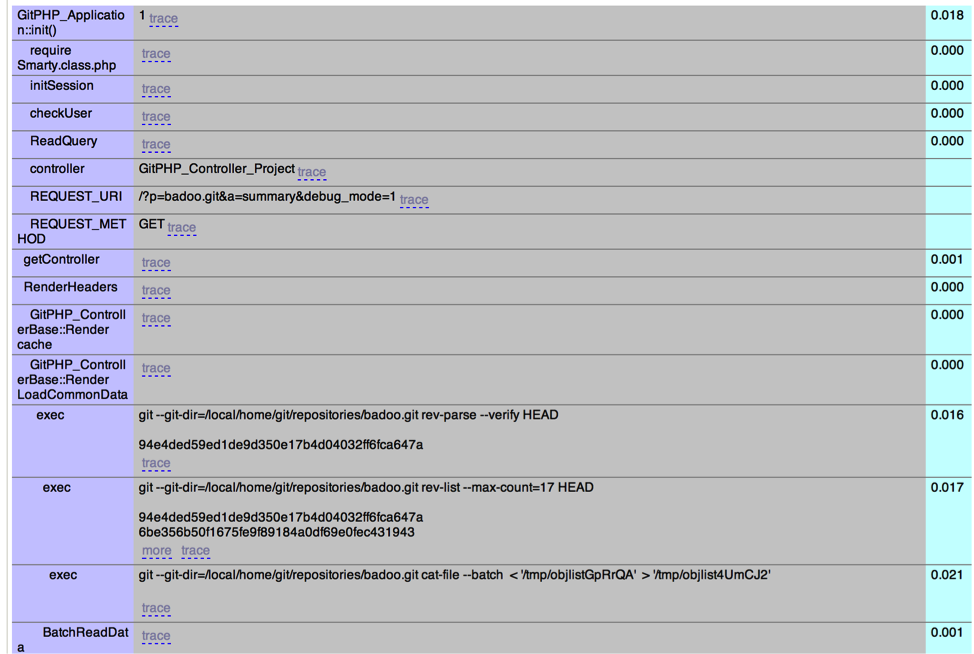
В первой колонке находится имя вызываемого метода (или действия), во второй — дополнительная информация: аргументы для запуска, начало вывода команды и trace. В последнем столбце находится потраченное на вызов время (в секундах).
Вот небольшая выдержка из реализации самих таймеров:
Использование такого API очень простое. В начале измеряемого кода вызывается
При этом вызовы могут быть вложенными, и приведенный выше класс учтет это при подсчете.
Для более легкой отладки кода внутри Smarty мы сделали «автотаймеры». Они позволяют легко измерять время, потраченное на работу методов с множеством точек выхода (много мест, где выполняется return):
Использовать такой класс очень просто: нужно вставить
Благодаря расставленным таймерам мы быстро смогли найти, где GitPHP версии 0.2.4 тратил большую часть времени. На каждый тег в репозитории делался один вызов
Как так получилось, что GitPHP нужно было для каждого тега в репозитории узнавать, является ли он «легковесным»? Все довольно просто.
На всех страницах GitPHP рядом с коммитом выводятся ветки и теги, которые на него указывают:

Для этого в классе
Т.е. для каждого коммита, для которого нужно получить список тегов, выполняется следующее:
Помимо того что можно сначала составить карту вида
Т.е. чтобы показать, какие ветки и теги входят в какой-либо коммит, GitPHP загружает список всех тегов и вызывает git cat-file -t для каждого из них. Неплохо, Кристофер, так держать!
Аналогичная ситуация и с информацией о коммите. Чтобы загрузить дату, сообщение коммита, автора и т.д, каждый раз вызывался git rev-list --max-count=1 … <commit>. Эта операция тоже не является бесплатной:
Для того чтобы не делать много одиночных обращений к git cat-file, Git позволяет загружать сразу много коммитов с использованием опции --batch. При этом он принимает список коммитов в stdin, а результат записывает в stdout. Соответственно, можно сначала записать в файл все хэши коммитов, которые нам нужны, запустить
Вот пример кода, который это делает (код приведен для версии GitPHP 0.2.4 и операционных систем семейства *nix):
Мы стали использовать эту функцию для большей части страниц, где показывается информация о коммитах (т.е. мы собираем список коммитов и загружаем их все одним вызовом
Немного подумав, мы поняли, что можно было не переписывать весь код для использования
Вот выдержка из реализации (для удобства чтения обработка ошибок убрана):
Учитывая, что мы теперь можем очень быстро загружать содержимое объектов, не делая каждый раз вызов команды git, получить большой прирост производительности стало просто: достаточно лишь поменять все вызовы
Мы собрали все изменения в один коммит и отправили pull-request разработчику GitPHP. Через какое-то время патч приняли! Вот этот коммит:
source.gitphp.org/projects/gitphp.git/commitdiff/3c87676b3afe4b0c1a1f7198995cecc176200482
Автором были внесены некоторые исправления в код (отдельными коммитами), и сейчас в ветке master находится значительно ускоренная версия GitPHP! Для использования оптимизаций требуется выключить «режим совместимости», то есть поставить
Юрий youROCK Насретдинов, PHP-разработчик, Badoo
Евгений eZH Махров, QA-инженер, Badoo
Расстановка таймеров
При разработке badoo.com в девелоперском окружении мы используем весьма простую debug-панель для расстановки таймеров и отладки SQL-запросов. Поэтому первым делом мы переделали ее в GitPHP и стали измерять время выполнения участков кода, не учитывая вложенные таймеры. Вот так выглядит наша debug-панель:

В первой колонке находится имя вызываемого метода (или действия), во второй — дополнительная информация: аргументы для запуска, начало вывода команды и trace. В последнем столбце находится потраченное на вызов время (в секундах).
Вот небольшая выдержка из реализации самих таймеров:
<?php
class GitPHP_Log {
// ...
public function timerStart() {
array_push($this->timers, microtime(true));
}
public function timerStop($name, $value = null) {
$timer = array_pop($this->timers);
$duration = microtime(true) - $timer;
// Вычтем потраченное время из всех таймеров, которые включают этот таймер
foreach ($this->timers as &$item) $item += $duration;
$this->Log($name, $value, $duration);
}
// ...
}
Использование такого API очень простое. В начале измеряемого кода вызывается
timerStart(), в конце — timerStop() с именем таймера и опциональными дополнительными данными:<?php
$Log = new GitPHP_Log;
$Log->timerStart();
$result = 0;
$mult = 4;
for ($i = 1; $i < 1000000; $i+=2) {
$result += $mult / $i;
$mult = -$mult;
}
$Log->timerStop("PI computation", $result);
При этом вызовы могут быть вложенными, и приведенный выше класс учтет это при подсчете.
Для более легкой отладки кода внутри Smarty мы сделали «автотаймеры». Они позволяют легко измерять время, потраченное на работу методов с множеством точек выхода (много мест, где выполняется return):
<?php
class GitPHP_DebugAutoLog {
private $name;
public function __construct($name) {
$this->name = $name;
GitPHP_Log::GetInstance()->timerStart();
}
public function __destruct() {
GitPHP_Log::GetInstance()->timerStop($this->name);
}
}
Использовать такой класс очень просто: нужно вставить
$Log = new GitPHP_DebugAutoLog(‘timer_name’); в начало любой функции или метода, и при выходе из функции будет автоматически измерено время ее исполнения:<?php
function doSomething($a) {
$Log = GitPHP_DebugAutoLog('doSomething');
if ($a > 5) {
echo "Hello world!\n";
sleep(5);
return;
}
sleep(1);
}
Тысячи вызовов git cat-file -t <commit>
Благодаря расставленным таймерам мы быстро смогли найти, где GitPHP версии 0.2.4 тратил большую часть времени. На каждый тег в репозитории делался один вызов
git cat-file -t только для того, чтобы узнать тип коммита, и является ли этот коммит «легковесным тегом» (http://git-scm.com/book/en/Git-Basics-Tagging#Lightweight-Tags). Легковесные теги в Git — это тип тега, который создается по умолчанию и содержит ссылку на конкретный коммит. Поскольку в нашем репозитории никакие другие типы тегов не присутствовали, мы просто убрали эту проверку и сэкономили пару тысяч вызовов git cat-file -t, занимавших около 20 секунд.Как так получилось, что GitPHP нужно было для каждого тега в репозитории узнавать, является ли он «легковесным»? Все довольно просто.
На всех страницах GitPHP рядом с коммитом выводятся ветки и теги, которые на него указывают:

Для этого в классе
GitPHP_TagList есть метод, который отвечает за получение списка тегов, ссылающихся на указанный коммит:<?php
class GitPHP_TagList extends GitPHP_RefList {
// ...
public function GetCommitTags($commit) {
if (!$commit) return array();
$commitHash = $commit->GetHash();
if (!$this->dataLoaded) $this->LoadData();
$tags = array();
foreach ($this->refs as $tag => $hash) {
if (isset($this->commits[$tag])) {
// ...
} else {
$tagObj = $this->project->GetObjectManager()->GetTag($tag, $hash);
$tagCommitHash = $tagObj->GetCommitHash();
// ...
if ($tagCommitHash == $commitHash) {
$tags[] = $tagObj;
}
}
}
return $tags;
}
// ...
}
Т.е. для каждого коммита, для которого нужно получить список тегов, выполняется следующее:
- При первом вызове загружается список всех тегов в репозитории (вызов LoadData()).
- Перебирается список всех тегов.
- Для каждого тега загружается соответствующий ему объект.
- Вызывается GetCommitHash() у объекта тега и полученное значение сравнивается с искомым.
Помимо того что можно сначала составить карту вида
array( commit_hash => array(tags) ), нужно обратить внимание на метод GetCommitHash(): он вызывает метод Load($tag), который в реализации с использованием внешней утилиты Git делает следующее:<?php
class GitPHP_TagLoad_Git implements GitPHP_TagLoadStrategy_Interface {
// ...
public function Load($tag) {
// ...
$args[] = '-t';
$args[] = $tag->GetHash();
$ret = trim($this->exe->Execute($tag->GetProject()->GetPath(), GIT_CAT_FILE, $args));
if ($ret === 'commit') {
// ...
return array(/* ... */);
}
// ...
$ret = $this->exe->Execute($tag->GetProject()->GetPath(), GIT_CAT_FILE, $args);
// ...
return array(/* ... */);
}
}
Т.е. чтобы показать, какие ветки и теги входят в какой-либо коммит, GitPHP загружает список всех тегов и вызывает git cat-file -t для каждого из них. Неплохо, Кристофер, так держать!
Сотни вызовов git rev-list --max-count=1 … <commit>
Аналогичная ситуация и с информацией о коммите. Чтобы загрузить дату, сообщение коммита, автора и т.д, каждый раз вызывался git rev-list --max-count=1 … <commit>. Эта операция тоже не является бесплатной:
<?php
class GitPHP_CommitLoad_Git extends GitPHP_CommitLoad_Base {
public function Load($commit) {
// ...
/* get data from git_rev_list */
$args = array();
$args[] = '--header';
$args[] = '--parents';
$args[] = '--max-count=1';
$args[] = '--abbrev-commit';
$args[] = $commit->GetHash();
$ret = $this->exe->Execute($commit->GetProject()->GetPath(), GIT_REV_LIST, $args);
// ...
return array(
// ...
);
}
// ...
}
Решение: пакетная загрузка коммитов (git cat-file --batch)
Для того чтобы не делать много одиночных обращений к git cat-file, Git позволяет загружать сразу много коммитов с использованием опции --batch. При этом он принимает список коммитов в stdin, а результат записывает в stdout. Соответственно, можно сначала записать в файл все хэши коммитов, которые нам нужны, запустить
git cat-file --batch и загрузить сразу все результаты.Вот пример кода, который это делает (код приведен для версии GitPHP 0.2.4 и операционных систем семейства *nix):
<?php
class GitPHP_Project {
// ...
public function BatchReadData(array $hashes) {
if (!count($hashes)) return array();
$outfile = tempnam('/tmp', 'objlist');
$hashlistfile = tempnam('/tmp', 'objlist');
file_put_contents($hashlistfile, implode("\n", $hashes));
$Git = new GitPHP_GitExe($this);
$Git->Execute(GIT_CAT_FILE, array('--batch', ' < ' . escapeshellarg($hashlistfile), ' > ' . escapeshellarg($outfile)));
unlink($hashlistfile);
$fp = fopen($outfile, 'r');
unlink($outfile);
$types = $contents = array();
while (!feof($fp)) {
$ln = rtrim(fgets($fp));
if (!$ln) continue;
list($hash, $type, $n) = explode(" ", rtrim($ln));
$contents[$hash] = fread($fp, $n);
$types[$hash] = $type;
}
return array('contents' => $contents, 'types' => $types);
}
// ...
}
Мы стали использовать эту функцию для большей части страниц, где показывается информация о коммитах (т.е. мы собираем список коммитов и загружаем их все одним вызовом
git cat-file --batch). Такая оптимизация сократила среднее время загрузки страницы с 20 с лишним секунд до 0,5 секунды. Таким образом мы решили проблему медленной работы GitPHP в нашем проекте.Open-source: оптимизации GitPHP 0.2.9 (master)
Немного подумав, мы поняли, что можно было не переписывать весь код для использования
git cat-file --batch. Хоть это и не отражено в документации, эта команда позволяет загружать информацию по одному коммиту за раз, не теряя в производительности! Во время работы производится чтение по одной строке из стандартного ввода и отправка результатов в стандартный вывод без их буферизации. Это означает, что мы можем открыть git cat-file --batch через proc_open() и получать результаты немедленно, без переделывания архитектуры!Вот выдержка из реализации (для удобства чтения обработка ошибок убрана):
<?php
// ...
class GitPHP_GitExe implements GitPHP_Observable_Interface {
// ...
public function GetObjectData($projectPath, $hash) {
$process = $this->GetProcess($projectPath);
$pipes = $process['pipes'];
$data = $hash . "\n";
fwrite($pipes[0], $data);
fflush($pipes[0]);
$ln = rtrim(fgets($pipes[1]));
$parts = explode(" ", rtrim($ln));
list($hash, $type, $n) = $parts;
$contents = '';
while (strlen($contents) < $n) {
$buf = fread($pipes[1], min(4096, $n - strlen($contents)));
$contents .= $buf;
}
return array(
'contents' => $contents,
'type' => $type,
);
}
// ...
}
Учитывая, что мы теперь можем очень быстро загружать содержимое объектов, не делая каждый раз вызов команды git, получить большой прирост производительности стало просто: достаточно лишь поменять все вызовы
git cat-file и git rev-list на вызов нашей оптимизированной функции.Мы собрали все изменения в один коммит и отправили pull-request разработчику GitPHP. Через какое-то время патч приняли! Вот этот коммит:
source.gitphp.org/projects/gitphp.git/commitdiff/3c87676b3afe4b0c1a1f7198995cecc176200482
Автором были внесены некоторые исправления в код (отдельными коммитами), и сейчас в ветке master находится значительно ускоренная версия GitPHP! Для использования оптимизаций требуется выключить «режим совместимости», то есть поставить
$compat = false; в конфигурации.Юрий youROCK Насретдинов, PHP-разработчик, Badoo
Евгений eZH Махров, QA-инженер, Badoo
