
Привет, Хабр! Меня зовут Виталий Котов, я работаю в Badoo в отделе QA, занимаюсь автоматизацией тестирования, а иногда и автоматизацией автоматизации тестирования.
Сегодня я расскажу о том, как мы в Badoo упростили работу с Selenium-тестами, научили ребят из отдела ручного тестирования работать с ними и какой профит с этого получили. Прочитав статью, вы сможете оценить трудозатратность каждого из этапов и, возможно, захотите частично перенять наш опыт.
Введение
Со временем количество автотестов становится довольно внушительным, и приходит понимание, что система, в которой количество автоматизаторов – константа, а количество тестов непрерывно растёт, – неэффективна.
В Badoo серверная часть наравне с Desktop Web релизится два раза в день. Об этом очень подробно и интересно рассказал мой коллега Илья Кудинов в статье «Как мы уже 4 года выживаем в условиях двух релизов в день». Я советую ознакомиться с ней, чтобы дальнейшие примеры в этой статье были вам более понятны.
Вполне очевидно, что чем выше покрытие автотестов, тем бóльшее их количество окажется затронутым в процессе релиза. Где-то изменили функционал, где-то поменяли вёрстку и локаторы перестали находить нужные элементы, где-то включили A/B-тест и бизнес-логика для части юзеров стала другой и так далее.
В какой-то момент мы оказались в ситуации, когда правка тестов после релиза занимала почти всё время, которое было у автоматизатора до следующего релиза. И так по кругу. Не оставалось времени на написание новых тестов, на поддержку и развитие архитектуры и решение каких-то новых задач. Что делать в такой ситуации? Первое решение, которое приходит в голову, — нанять ещё одного автоматизатора. Однако у такого решения есть существенный минус: когда тестов снова станет в два раза больше, мы снова будем вынуждены нанимать ещё одного автоматизатора.
Поэтому мы пошли по другому пути, мы решили научить ребят из отдела ручного тестирования работать с тестами, условившись, что в своих задачах они будут самостоятельно править тесты до релиза. Какие плюсы у этого решения?
Во-первых, если тестировщик способен поправить автотест, он тем более способен разобраться в причине его падения. Таким образом, повышается вероятность, что он найдет баг на максимально раннем этапе тестирования. Это хорошо, потому что исправить проблему в этом случае можно быстро и просто, а задача уедет на продакшн в назначенный due date.
Во-вторых, наши автотесты для Desktop Web написаны на PHP, как и сам продукт. Следовательно, работая с кодом автотестов, тестировщик развивает в себе навык работы с этим языком программирования, и ему становится легче и проще понять дифф задачи и разобраться, что там было сделано и куда стоит в первую очередь посмотреть при тестировании.
В-третьих, если ребята правят тесты, они иногда могут выделять время для написания новых. Это и интересно самому тестировщику, и полезно для покрытия.
И последнее, как вы уже поняли, у автоматизатора появляется больше времени, которое он может тратить на решение архитектурных вопросов, ускоряя прохождение тестов и делая их проще и понятнее.
С плюсами разобрались. Теперь давайте подумаем, какие могут быть минусы.
Тестирование задачи начнет занимать больше времени, потому что QA-инженеру придется помимо проверки функционала исправлять тесты. С одной стороны это действительно так. С другой стороны стоит понимать, что маленькие задачи у нас в Badoo превалируют над масштабными рефакторингами, где затрагивается всё или почти всё. О том, почему это так и как мы к этому пришли, хорошо рассказал глава отдела QA Илья Агеев в статье «Как workflow разработки влияет на декомпозицию задач». Следовательно, исправления должны сводиться к нескольким строчкам кода, а это не займет много времени.
В крупных же задачах, где сломалось большое количество тестов, и багов тоже может быть много. Не раз мы сталкивались с ситуацией, когда в процессе починки тестов после таких рефакторингов находились баги, пропущенные при ручном тестировании. А как мы помним, чем раньше мы найдём баг, тем легче его исправить.
Итак, дело за малым – сделать тесты пригодными для того, чтобы в них мог разобраться человек, не имеющий опыта написания автотестов.
Рефакторинг тестов
Первый этап был довольно скучным. Мы принялись за рефакторинг наших тестов, стараясь максимально отделить логику работы теста со страницей от логики самого теста, так, чтобы при изменении внешнего вида проекта было достаточно поправить несколько констант-локаторов, не трогая при этом код самого теста. В итоге у нас получились классы наподобие PageObject. Каждый из них описывает элементы, относящиеся к одной странице или одному компоненту, и методы взаимодействия с ними: дождаться элемент, подсчитать количество элементов, кликнуть по нему и так далее. Мы договорились, что никаких логических проверок типа assert в таких классах быть не должно – только взаимодействие с UI.
Благодаря этому мы получили тесты, которые читаются довольно просто:
$Navigator->openSignInPage();
$SignInPage->enterEmail($email);
$SignInPage->enterPassword($password);
$SignInPage->submitForm();
$Navigator->waitForAuthPage();И простые UI-классы, которые выглядят примерно так:
сlass SignInPage extends Api
{
const INPUT_EMAIL = ‘input.email’;
const INPUT_PASSWORD = ‘input.password’;
const INPUT_SUBMIT_BUTTON = ‘button[type=”submit”]’;
public function enterEmail($email)
{
$this->driver->element(self::INPUT_EMAIL)->type($email);
}
public function enterPassword($password)
{
$this->driver->element(self::INPUT_PASSWORD)->type($password);
}
public function submitForm()
{
$this->driver->element(self::INPUT_SUBMIT_BUTTON)->click();
}
}Теперь, если локатор для пароля изменится, и тест сломается, не найдя нужное поле ввода, будет понятно, как его поправить. Более того, если метод enterPassword() используется в нескольких тестах, изменение соответствующего локатора починит сразу всё.
В таком виде тесты уже можно показывать ребятам. Они читаемые, и с ними вполне можно работать, не имея опыта написания кода на PHP. Достаточно рассказать основы. Для этого мы провели ряд обучающих семинаров с примерами и заданиями для самостоятельного решения.
Обучение
Обучение велось постепенно, от простого к сложному. После первого занятия была задача починить сломанный тест, где нужно было поправить несколько локаторов. После второго занятия требовалось расширить существующий тест, дописав несколько методов в UI-класс и использовав их в тесте. После третьего ребята уже вполне могли написать новый тест самостоятельно.
На основе этих семинаров были написаны статьи в нашу внутреннюю Wiki о том, как правильно работать с тестами и с какими подводными камнями можно столкнуться в процессе. В них мы собрали best practices и ответы на часто задаваемые вопросы: как правильно составить локатор, в каком случае стоит создавать новый класс под тест, а в каком – добавлять тест в уже существующий, когда создавать новый UI-класс, как правильно называть константы для локаторов и так далее.
Сейчас, когда в компанию приходит новый QA-инженер, он получает список тех самых статей из Wiki, с которыми необходимо ознакомиться для работы с автотестами. И когда он в процессе тестирования впервые сталкивается с падающим тестом, он уже во всеоружии и знает, что делать. Само собой, в любой момент он может подойти ко мне или к другому автоматизатору и что-то уточнить или спросить, это нормально.
У нас есть договорённость, что умение QA инженера работать с автотестами, в том числе писать новые – это одно из требований для роста внутри компании. Если ты хочешь развиваться (а кто же не хочет, верно?), надо быть готовым к тому, что придётся заниматься и автоматизацией в том числе.
TeamCity
Наши Selenium-тесты лежат в том же репозитории, где и код проекта. Когда мы только начинали писать первые Selenium-тесты, у нас уже был PHPUnit и некоторое количество unit-тестов. Чтобы не плодить технологии, мы решили запускать Selenium-тесты, используя тот же PHPUnit, и положили их в соседнюю с unit-тестами папку. Пока тестами занимались только автоматизаторы, мы могли вносить правки в тесты сразу в Master, поскольку делали это уже после релиза. И, соответственно, запускали в TeamCity тесты тоже с Master.
Когда ребята начали работать с тестами в своих задачах, мы договорились, что правки будут вноситься в ту же ветку, где лежит код задачи. Во-первых, это обеспечивало одновременную доставку правок для тестов в Master с самой задачей, во-вторых, в случае отката задачи из релиза правки для неё также откатывались без дополнительных действий. В итоге мы начали запускать тесты в TeamCity с ветки релиза.
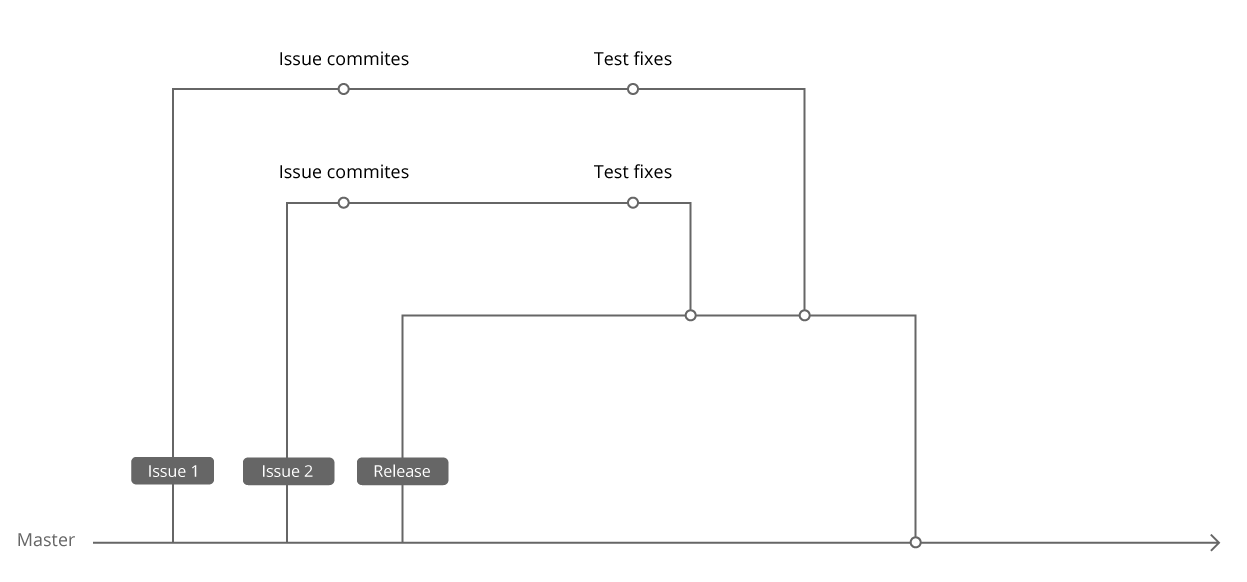
Таким образом, мы получили систему, в которой автоматизатор может следить только за тестами для релиза, а новая задача при этом приходит в релиз сразу с правками для тестов. В такой системе пожизненный зелёный билд обеспечен. :)
Но это ещё не всё.
Запуск тестов по диффу задачи
Гонять все тесты для каждой задачи крайне затратно как по времени, так и по ресурсам. Каждый тест необходимо обеспечить браузером, следовательно, нужно поддерживать мощную Selenium-ферму. Также нужен мощный сервер, на котором будет развёрнут проект и по которому параллельно будет ходить большое число автотестов. А это – дорогое удовольствие.
Мы решили, что было бы круто вычислять динамически для каждой задачи, какие именно тесты стоит запускать. Для этого мы каждому тесту присвоили набор групп, которые привязаны к проверяемым фичам или страницам: Search, Profile, Registration, Chat, и написали скрипт, который отлавливает тесты без групп и пишет соответствующие нотификации автоматизаторам.
Далее перед запуском тестов на задаче мы при помощи Git научились анализировать изменённые файлы. Они по большей части тоже называются как-то похоже на фичи, к которым имеют отношение, или лежат в соответствующих папках:
/js/search/common.js/View/Chat/GetList.php/tpls/profile/about_me_block.tpl
Мы придумали пару правил для файлов, которые не соответствуют названию ни одной группы. Например, у нас часть файлов называется, скажем, не chat, а messager. Мы сделали карту алиасов и, если натыкаемся на файл, который называется messager, запускаем тесты для группы Chat, а если файл лежит где-то в core-папках, то мы делаем вывод, что стоит запустить полный набор тестов.
Конечно, универсального алгоритма решения такой задачи не существует – всегда есть вероятность, что изменение в каком-то классе затронет проект в самом неожиданном месте. Но это нестрашно, поскольку на стейджинге мы запускаем полный набор тестов и обязательно заметим проблему. Более того, мы придумаем правило, как в следующий раз не пропустить подобную проблему и обнаружить её заранее.
Нестабильные и сломанные тесты
Последнее, что осталось сделать, — это разобраться с нестабильными и сломанными тестами. Никто не захочет возиться с сотней упавших тестов, разбираясь, какие из них сломаны на Master, а какие – просто упали, потому что проходят в 50% случаев. Если доверия к тестам нет, тестировщик не будет внимательно их изучать и тем более править.
Бывает, что при релизе больших задач допускается некоторое количество мелких багов, которые незаметны пользователю (например, JS-ошибка, которая не влияет на функционал) и которые можно исправить в следующем релизе, не задерживая выкладку важных изменений на продакшн.
И если с тестировщиком можно договориться, то с тестами всё сложнее – они честно будут находить проблему и падать. Причём, когда баг окажется в Master, тесты начнут падать на других задачах, что совсем плохо.
Для таких тестов мы придумали следующую систему. Мы завели MySQL-табличку, где можно указать название падающего теста и тикет, в котором проблему исправят. Тесты перед запуском получают этот список, и каждый тест ищет себя в нём. Если находит, помечается как Skipped с сообщением, что такой-то тикет не готов, и тест запускать нет смысла.
В качестве багтрекера мы используем JIRA. Параллельно по cron’у гоняется скрипт, который через JIRA API проверяет статусы тикетов из этой таблицы. Если тикет переходит в статус Closed, мы удаляем запись, и тест автоматически начинает снова запускаться.
В итоге сломанные тесты исключаются из результатов прогонов. С одной стороны, это хорошо – на них больше не тратится время при прогоне, и они не «засоряют» результаты этого прогона. С другой стороны, тестировщику приходится постоянно открывать SeleniumManager и смотреть, какие тесты отключены, чтобы при необходимости проверять кейзы руками. Так что мы стараемся не злоупотреблять этой фичей, у нас редко бывает больше одного–двух отключенных тестов.
Теперь вернёмся к проблеме нестабильных тестов. Поскольку речь в статье идёт о UI-тестах, нужно понимать, что это тесты высокого уровня: интеграционные и системные. Такие тесты по определению нестабильны, это нормально. Однако хочется всё же ловить эти нестабильности и отделять от тестов, явно падающих «по делу».
Мы довольно давно пришли к выводу, что стоит логировать запуски всех тестов в специальную MySQL-таблицу. Название теста, время прогона, результат, для какой задачи или на стейджинге был запущен этот тест и так далее. Во-первых, нам это нужно для статистики; во-вторых, эта таблица используется в SeleniumManager – веб-интерфейсе для запуска и мониторинга тестов. О нём однажды я напишу отдельную статью. :)
Помимо вышеперечисленных полей, в таблицу было добавлено новое – код ошибки. Этот код формируется на основе трейса упавшего теста. Например, в задаче А тест упал на строке 74, где он вызвал строку 85, где был вызван UI-класс на строке 15. Почему бы нам не склеить и не записать эту информацию: 748515? В следующий раз, когда тест упадёт на какой-то другой задаче Б, мы получим код для текущей ошибки и простым select’ом из таблицы узнаем, были ли ранее похожие падения. Если были, то тест очевидно нестабильный, о чём можно сделать соответствующую пометку.
Само собой, тесты иногда меняются, и строки, на которых они падают, тоже могут измениться. И какое-то время старая ошибка будет считаться новой. Но, с другой стороны, это происходит не так часто, поскольку, как вы помните, логика теста отделена от логики UI и меняется редко. Так что бóльшую часть нестабильных тестов таким образом мы действительно отлавливаем и помечаем. В SeleniumManager есть интерфейс, позволяющий перезапускать нестабильные тесты для выбранной задачи с целью убедиться, что функционал работает.
Итог
Я постарался подробно, но без излишней дотошности описать наш путь от точки А, где автотестами занималась только группа «избранных» ребят, до точки Б, где тесты стали удобными и понятными всем.
Этот путь состоял из следующих этапов:
- Разработка специальной архитектуры, в рамках которой должны быть написаны все тесты. Рефакторинг старых тестов.
- Проведение обучающих семинаров и написание документации для новых сотрудников.
- Оптимизация работы автотестов: изменение флоу запуска тестов в TeamCity, запуск тестов по диффу для конкретной задачи.
- Упрощение результатов прогона тестов: тестировщик в первую очередь должен видеть те упавшие тесты, которые наверняка связаны с его задачей.
В итоге мы пришли к системе, в которой ручным тестировщикам довольно комфортно работать с Selenium-тестами. Они понимают, как они устроены и как их запускать, умеют их править и могут при необходимости писать новые.
В то же время автоматизаторы получили возможность и время заниматься сложными задачами: создавать более точные системы для отлавливания нестабильных тестов и править их, создавать удобные интерфейсы для запуска тестов и интерпретации результатов прогонов, ускорять и улучшать сами тесты.
Совершенствуйте свои инструменты и делайте их проще в использовании и будет вам «щасте». Спасибо за внимание!
