Как написал у себя в твиттере один из наших партнеров: «Напиши лет пять назад «молния вызвала падение облака» и тебя бы посчитали идиотом». Но именно это и случилось в воскресенье вечером – молния попала в трансформатор, что полностью обесточило датацентр Amazon в Ирландии. К сожалению, сайты компании «1С-Битрикс» находились именно в этом датацентре.

Мы приносим искренние извинения всем нашим клиентам и партнерам, кому временная недоступность наших сайтов могла доставить те или иные неудобства.
И сегодня хотим рассказать вам о том, «как это было», о наших действиях и выводах, которые мы сделали после данного инцидента.
Вся история «глазами Амазон» доступна на специальном сайте, который позволяет мониторить все сервисы Амазона — status.aws.amazon.com:
Зафиксированное начало аварии – 7-го августа (воскресенье) в 21:13 (по московскому времени).
Первый минус в карму нам – мы со своей стороны не отмониторили проблему. Почему так произошло?
Все веб-сайты нашей компании обслуживаются несколькими серверами в «облаке»: две виртуальные машины – бэкенды кластера, одна машина – балансировщик нагрузки между ними, и еще одна машина – сервер мониторинга, на котором установлен nagios, мониторящий кучу самых разных нужных нам сервисов (Load average на серверах, корректную работу репликации в MySQL, запуск нужных нам процессов и т.п.)
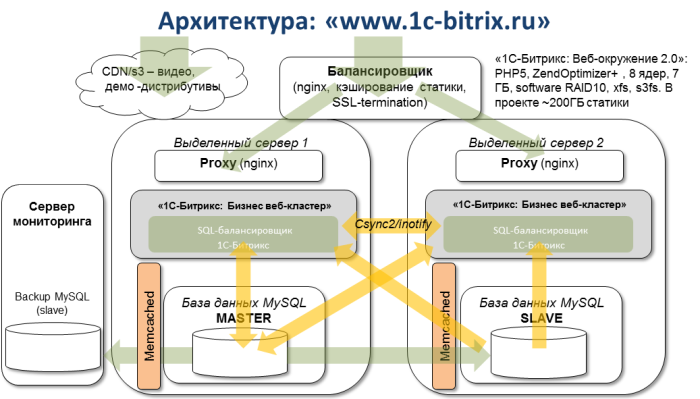
По сути, мы мониторим всё. Кроме самого мониторинга. И этот сервер оказался в том же датацентре. Именно поэтому о проблеме мы узнали только в понедельник утром.
Первый вывод: нужно дублировать мониторинг, использовать для его целей совершенно внешние ресурсы.
Но, продолжим… Понедельник, утро, сайты не доступны. Административный интерфейс Амазона говорит о том, что машины запущены. Однако снаружи, из интернета доступны лишь часть из них, и нет связи между ними внутри. При этом периодически картина меняется, перестает быть доступным что-то, что было доступно ранее, что дает некоторую надежду на то, что инженеры Амазона работают и скоро все будет доступно.
Небольшое отступление – почему процесс восстановления данных со стороны Амазона занимает так много времени.
Поднять сами виртуальные машины – не такая большая проблема. Хуже обстоит дело с дисками. В терминах Amazon это – EBS (Elastic Block Store), некие виртуальные блочные устройства, которые можно подключать как обычные диски, организовывать из них RAID и т.п.
Из-за аварии были обесточены в том числе и серверы, управляющие EBS. Что в итоге – по словам Amazon – потребовало многих ручных операций, создание дополнительных копий данных и экстренный ввод в эксплуатацию дополнительных мощностей.
Возвращаемся к нашей истории. Примерно в 11 утра понедельника стало понятно, что быстрого восстановления наших машин не случится: оба бэкенда кластера (файлы, база) были недоступны.
Быстрый вариант запуска – поднять новую виртуальную машину в другом датацентре, но в той же Availability Zone.
Почему так, и что такое Availability Zone?
Одна зона объединяет в себе несколько датацентров. Именно внутри одной зоны можно, например, средствами Амазона быстро сделать snapshot («снимок») диска и подключить его в виде нового диска к другому серверу, даже расположенному в другом датацентре. Важно именно то, чтобы он находился в той же «зоне». Также именно внутри одной зоны можно переключать между разными серверами (в том числе – и в разных датацентрах) Elastic IP – внешние IP-адреса, по которым доступны виртуальные серверы.
У Амазона есть несколько Availability Zone: US East, US West, Asia Pacific (Сингапур), Asia Pacific (Токио) и EU – Ирландия, где и находятся наши серверы.
При этом в Ирландии – три датацентра. Назовем их условно A, B, C.
Самой первой мыслью было решение запуститься вообще в другой зоне. Например, где-то в Штатах. Но практика показала, что это было бы крайне долгим процессом – все данные (а их у нас несколько сот гигабайт) пришлось бы нудно и долго копировать по сети. А главной сложностью было бы то, что для начала надо было бы поднять тот сервер, с которого все можно скопировать.
(Ну, а если мы уже нашли возможность его поднять, то почему бы просто не запустить на нем сайт?)
Итак. Все наши серверы находились в датацентре A. Да, конечно, правильнее было бы ставить их в разных датацентрах (для обеспечения надежности). Однако с точки зрения производительности (синхронизация файлов, репликация в MySQL) удобнее использовать конфигурацию, в которой между серверами минимальны сетевые задержки.
1. Мы подняли в датацентре B новую машину – аналогичную по конфигурации.
2. Рутовый раздел ( / — все настройки ПО и т.п.) был в несколько приемов перенесен со одного из бэкендов кластера (к счастью, несмотря на то, что машина не была доступна через интернет, большинство операций можно было выполнять из админки Амазона):
Вся операция (в отличие от простого копирования) выполняется достаточно быстро, занимается минуты. Кстати, именно это – стандартный механизм переноса данных между разными датацентрами в Амазоне. Но, как и сказано выше, работает только внутри одной Availability Zone.
3. Следующий шаг – перенос основных данных (контент, база). Они находятся у нас на RAID-10, который обеспечивает и скорость, и надежность.
И – проблема. Не со всех дисков рейда получается сделать snapshot. Получаем в админке краткое и не очень емкое: «Internal error».
Для файлов берем бэкап суточной давности (снэпшоты всех дисков, в том числе и дисков рейда, делаются у нас автоматически раз в сутки). Восстанавливаем RAID (процедура бэкапа и восстановления софтверного RAID-10 – вообще отдельная тема, если кому-то она интересна – пишите, расскажем).
4. Использовать бэкап суточной давности для базы – очень не хочется, это – самая крайняя мера. Терять последние изменения в базе, попавшие с сайта – очень и очень грустно…
И тут нас спасает то, что в нашем веб-кластере в репликации MySQL был подключен не один slave (на втором бэкенде), а два. Второй slave был на машине мониторинге и использовался только как real-time backup: данные на этот сервер копировались в реальном времени, но запросы на этот сервер не распределялись.
Казалось бы, счастье уже близко… Однако в момент копирования данных MySQL на новую машину… эта самая машина перестала быть доступна.
Это было примерно в 13:00-13:30. Иронии добавляет то, что примерно в это же время появился очередной – достаточно позитивный – апдейт от Амазона:
Звучит-то позитивно, но на практике означает то, что хранилище внутри одной зоны централизовано. И даже то, что молния обесточила лишь один датацентр, не гарантирует нам того, что все будет хорошо работать в другом датацентре.
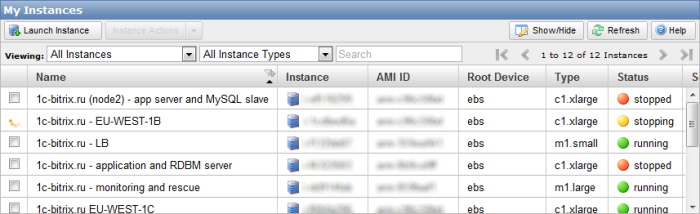
Новую машину в датацентре B мы больше так и не увидели…
Кстати, она до сих пор остается в каком-то «подвешенном» состоянии (статус — stopping):
В 13:30 начался следующий этап восстановления – мы подняли новую машину в датацентре C.
Описанные выше пункты 1-3 повторили. Пункт 4 – успешно закончили.
5. Переключили базу MySQL из режима slave в режим master.
6. Поправили все конфигурационные файлы, стартовали все сервисы.
7. Проверили работу сайта, после чего переключили внешний Elastic IP (собственно, тот адрес, в который резолвится www.1c-bitrix.ru) на новую машину в админке Амазона.
Было примерно 15:30 понедельника.
* * *
Недоступность сайтов – это всегда неприятно. Однако, даже несмотря на столь досадный инцидент, мы постарались извлечь из него максимум опыта и сделать несколько выводов.
1. Многие задали вопрос: «Чем же вам помогло облако?»
Очень помогло – как ни парадоксально звучит, скоростью восстановления. Несколько часов (по сути – для двух восстановлений) – это очень неплохой результат.
Если бы мы располагались в каком-то датацентре на реальных физических серверах:
Никакого разочарования в «облачной» концепции у нас не появилось.
2. Еще один вопрос: «Чем вам помог ваш кластер?»
Самое главное преимущество – доступность актуальных данных.
Без них мы бы ждали восстановления сервиса в Амазоне (по состоянию на 19:30 понедельника работа всех сервисов не была восстановлена, для всех пользователей была опубликована примерна та же инструкция по переезду в другой датацентр, которая описана выше; по состоянию на момент написания этой статьи инцидент на сайте status.aws.amazon.com не был закрыт — прошло 39 часов) или же поднимали данные из бэкапа, потеряв последние изменения (для нашего сайта они критичны).
Кроме того, мы сделали очень важные выводы по поддержке симметричного веб-кластера в платформе «1С-Битрикс». Он как раз позволяет запускать разные ноды веб-проекта сразу в нескольких датацентрах в любой удаленности друг от друга. Такая схема позволила бы нам сейчас расположить одну ноду, например, в той же Ирландии, а другую – например, в США. Выход из строя всей Availability Zone, а не только одного датацентра, не затронул бы другую зону, и время простоя наших сайтов было бы минимальным.
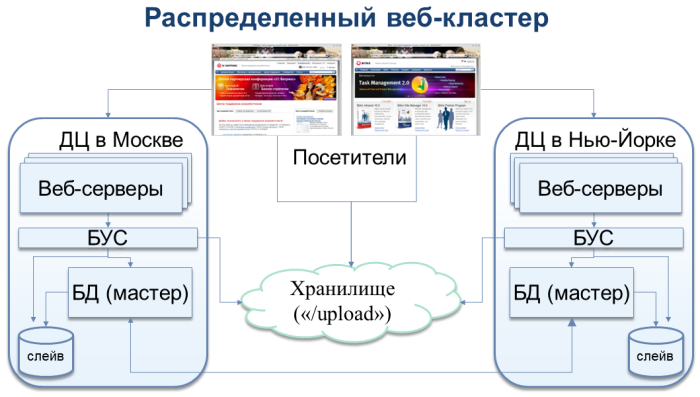
Поддержка этого решения была анонсирована на последней партнерской конференции «1С-Битрикс». Она будет включена в следующий релиз платформы «1С-Битрикс» 10.5, который выйдет осенью этого года.
Подготовимся к разгулам стихий и будем верить в то, что у природы нет плохой погоды. :)

Мы приносим искренние извинения всем нашим клиентам и партнерам, кому временная недоступность наших сайтов могла доставить те или иные неудобства.
И сегодня хотим рассказать вам о том, «как это было», о наших действиях и выводах, которые мы сделали после данного инцидента.
Вся история «глазами Амазон» доступна на специальном сайте, который позволяет мониторить все сервисы Амазона — status.aws.amazon.com:
| 11:13 AM PDT We are investigating connectivity issues in the EU-WEST-1 region. 11:27 AM PDT EC2 APIs in the EU-WEST-1 region are currently impaired. We are working to restore full service. We are also investigating instance connectivity that we believe to be limited to a single Availability Zone. |
Зафиксированное начало аварии – 7-го августа (воскресенье) в 21:13 (по московскому времени).
Первый минус в карму нам – мы со своей стороны не отмониторили проблему. Почему так произошло?
Все веб-сайты нашей компании обслуживаются несколькими серверами в «облаке»: две виртуальные машины – бэкенды кластера, одна машина – балансировщик нагрузки между ними, и еще одна машина – сервер мониторинга, на котором установлен nagios, мониторящий кучу самых разных нужных нам сервисов (Load average на серверах, корректную работу репликации в MySQL, запуск нужных нам процессов и т.п.)
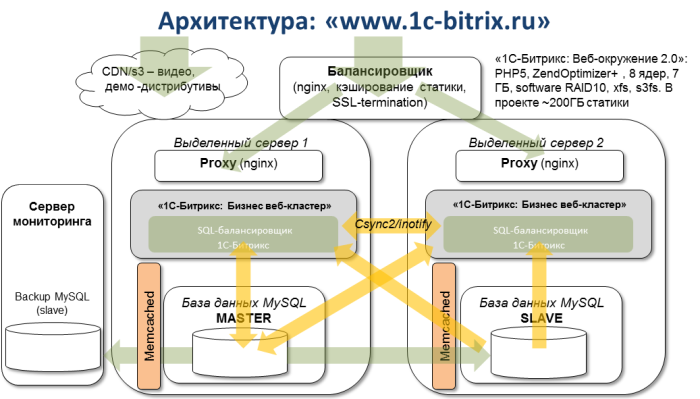
По сути, мы мониторим всё. Кроме самого мониторинга. И этот сервер оказался в том же датацентре. Именно поэтому о проблеме мы узнали только в понедельник утром.
Первый вывод: нужно дублировать мониторинг, использовать для его целей совершенно внешние ресурсы.
Но, продолжим… Понедельник, утро, сайты не доступны. Административный интерфейс Амазона говорит о том, что машины запущены. Однако снаружи, из интернета доступны лишь часть из них, и нет связи между ними внутри. При этом периодически картина меняется, перестает быть доступным что-то, что было доступно ранее, что дает некоторую надежду на то, что инженеры Амазона работают и скоро все будет доступно.
| 9:36 PM PDT We have now recovered 75% of the impacted instances. |
Небольшое отступление – почему процесс восстановления данных со стороны Амазона занимает так много времени.
Поднять сами виртуальные машины – не такая большая проблема. Хуже обстоит дело с дисками. В терминах Amazon это – EBS (Elastic Block Store), некие виртуальные блочные устройства, которые можно подключать как обычные диски, организовывать из них RAID и т.п.
Из-за аварии были обесточены в том числе и серверы, управляющие EBS. Что в итоге – по словам Amazon – потребовало многих ручных операций, создание дополнительных копий данных и экстренный ввод в эксплуатацию дополнительных мощностей.
Возвращаемся к нашей истории. Примерно в 11 утра понедельника стало понятно, что быстрого восстановления наших машин не случится: оба бэкенда кластера (файлы, база) были недоступны.
Быстрый вариант запуска – поднять новую виртуальную машину в другом датацентре, но в той же Availability Zone.
Почему так, и что такое Availability Zone?
Одна зона объединяет в себе несколько датацентров. Именно внутри одной зоны можно, например, средствами Амазона быстро сделать snapshot («снимок») диска и подключить его в виде нового диска к другому серверу, даже расположенному в другом датацентре. Важно именно то, чтобы он находился в той же «зоне». Также именно внутри одной зоны можно переключать между разными серверами (в том числе – и в разных датацентрах) Elastic IP – внешние IP-адреса, по которым доступны виртуальные серверы.
У Амазона есть несколько Availability Zone: US East, US West, Asia Pacific (Сингапур), Asia Pacific (Токио) и EU – Ирландия, где и находятся наши серверы.
При этом в Ирландии – три датацентра. Назовем их условно A, B, C.
Самой первой мыслью было решение запуститься вообще в другой зоне. Например, где-то в Штатах. Но практика показала, что это было бы крайне долгим процессом – все данные (а их у нас несколько сот гигабайт) пришлось бы нудно и долго копировать по сети. А главной сложностью было бы то, что для начала надо было бы поднять тот сервер, с которого все можно скопировать.
(Ну, а если мы уже нашли возможность его поднять, то почему бы просто не запустить на нем сайт?)
Итак. Все наши серверы находились в датацентре A. Да, конечно, правильнее было бы ставить их в разных датацентрах (для обеспечения надежности). Однако с точки зрения производительности (синхронизация файлов, репликация в MySQL) удобнее использовать конфигурацию, в которой между серверами минимальны сетевые задержки.
1. Мы подняли в датацентре B новую машину – аналогичную по конфигурации.
2. Рутовый раздел ( / — все настройки ПО и т.п.) был в несколько приемов перенесен со одного из бэкендов кластера (к счастью, несмотря на то, что машина не была доступна через интернет, большинство операций можно было выполнять из админки Амазона):
- сделан snapshot имеющего диска со старой машины в датацентре A;
- из снэпшота сделан диск (volume), доступный в датацентре B;
- новый диск замонтирован на новой машине в датацентре B.
Вся операция (в отличие от простого копирования) выполняется достаточно быстро, занимается минуты. Кстати, именно это – стандартный механизм переноса данных между разными датацентрами в Амазоне. Но, как и сказано выше, работает только внутри одной Availability Zone.
3. Следующий шаг – перенос основных данных (контент, база). Они находятся у нас на RAID-10, который обеспечивает и скорость, и надежность.
И – проблема. Не со всех дисков рейда получается сделать snapshot. Получаем в админке краткое и не очень емкое: «Internal error».
Для файлов берем бэкап суточной давности (снэпшоты всех дисков, в том числе и дисков рейда, делаются у нас автоматически раз в сутки). Восстанавливаем RAID (процедура бэкапа и восстановления софтверного RAID-10 – вообще отдельная тема, если кому-то она интересна – пишите, расскажем).
4. Использовать бэкап суточной давности для базы – очень не хочется, это – самая крайняя мера. Терять последние изменения в базе, попавшие с сайта – очень и очень грустно…
И тут нас спасает то, что в нашем веб-кластере в репликации MySQL был подключен не один slave (на втором бэкенде), а два. Второй slave был на машине мониторинге и использовался только как real-time backup: данные на этот сервер копировались в реальном времени, но запросы на этот сервер не распределялись.
Казалось бы, счастье уже близко… Однако в момент копирования данных MySQL на новую машину… эта самая машина перестала быть доступна.
Это было примерно в 13:00-13:30. Иронии добавляет то, что примерно в это же время появился очередной – достаточно позитивный – апдейт от Амазона:
| 2:26 AM PDT We have brought additional EBS capacity online in the impacted zone, and we have again started restoring EBS volumes and EBS backed EC2 instances. We're continuing to bring additional capacity online. We will continue to post updates as we have new information. |
Звучит-то позитивно, но на практике означает то, что хранилище внутри одной зоны централизовано. И даже то, что молния обесточила лишь один датацентр, не гарантирует нам того, что все будет хорошо работать в другом датацентре.
Новую машину в датацентре B мы больше так и не увидели…
Кстати, она до сих пор остается в каком-то «подвешенном» состоянии (статус — stopping):

В 13:30 начался следующий этап восстановления – мы подняли новую машину в датацентре C.
Описанные выше пункты 1-3 повторили. Пункт 4 – успешно закончили.
5. Переключили базу MySQL из режима slave в режим master.
6. Поправили все конфигурационные файлы, стартовали все сервисы.
7. Проверили работу сайта, после чего переключили внешний Elastic IP (собственно, тот адрес, в который резолвится www.1c-bitrix.ru) на новую машину в админке Амазона.
Было примерно 15:30 понедельника.
* * *
Недоступность сайтов – это всегда неприятно. Однако, даже несмотря на столь досадный инцидент, мы постарались извлечь из него максимум опыта и сделать несколько выводов.
1. Многие задали вопрос: «Чем же вам помогло облако?»
Очень помогло – как ни парадоксально звучит, скоростью восстановления. Несколько часов (по сути – для двух восстановлений) – это очень неплохой результат.
Если бы мы располагались в каком-то датацентре на реальных физических серверах:
- Если бы обесточился этот датацентр, у нас бы не было доступа к нашим данным. Вообще. Мы бы ждали, пока он поднимется.
- Если бы не захотели ждать, нужно было бы брать данные из бэкапа. Из какого? Как и куда его делать? В другой датацентр?
- Хороший вопрос – в какой другой датацентр переезжать во время аварии. Найти сервер нужной нам конфигурации – не самая тривиальная задача. Требующая времени.
- Переехали. Надо менять DNS. Это – опять время.
Никакого разочарования в «облачной» концепции у нас не появилось.
2. Еще один вопрос: «Чем вам помог ваш кластер?»
Самое главное преимущество – доступность актуальных данных.
Без них мы бы ждали восстановления сервиса в Амазоне (по состоянию на 19:30 понедельника работа всех сервисов не была восстановлена, для всех пользователей была опубликована примерна та же инструкция по переезду в другой датацентр, которая описана выше; по состоянию на момент написания этой статьи инцидент на сайте status.aws.amazon.com не был закрыт — прошло 39 часов) или же поднимали данные из бэкапа, потеряв последние изменения (для нашего сайта они критичны).
Кроме того, мы сделали очень важные выводы по поддержке симметричного веб-кластера в платформе «1С-Битрикс». Он как раз позволяет запускать разные ноды веб-проекта сразу в нескольких датацентрах в любой удаленности друг от друга. Такая схема позволила бы нам сейчас расположить одну ноду, например, в той же Ирландии, а другую – например, в США. Выход из строя всей Availability Zone, а не только одного датацентра, не затронул бы другую зону, и время простоя наших сайтов было бы минимальным.
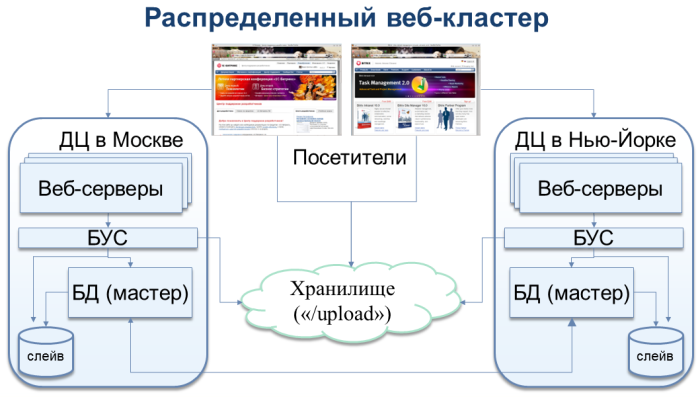
Поддержка этого решения была анонсирована на последней партнерской конференции «1С-Битрикс». Она будет включена в следующий релиз платформы «1С-Битрикс» 10.5, который выйдет осенью этого года.
Подготовимся к разгулам стихий и будем верить в то, что у природы нет плохой погоды. :)
