Вы пробовали заказать в Макдональдсе жаренного на орудийном шомполе поросенка с домашним вином и, на десерт, девушку рядом с вами за столиком, для приятной беседы во время трапезы? Даже не думали об этом?? Вот-вот — статья как раз об этом, о стереотипах программиста и лени, двигающей прогресс. А если серьезно — в статье мы напишем очень полезный многим высокопроизводительный сетевой сервер на PHP за пару часов. Я совершенно серьезно :-)

В старые добрые времена, когда люди были ближе к природе, свежее пиво радовало приятной горчинкой и женщины изысканно пахли — программисты были ближе к «железу» и писали на С и, в моменты вдохновения — на ассемблере. Но наверно самое важное — программисты понимали, что такое tcp, чем оно отличается от udp, и как эффективно взаимодействовать с ядром операционной системы через интерфейс системных вызовов.

Но лень брала свое и постепенно сформировался подход к разработке — близкий к идеологии выдуманного абстрактного мира из Властелина Колец.

Люди стали создавать в программах объекты вымышленного мира, философские концепции, обменивающиеся сообщениями и все больше стали отрываться от реальности и природы. И если в C++ еще пытались задержаться наедине с природой через указатели и контролируемую работу с памятью, то в Java и C# лень взяла свое и программисты оказались в идеальной, но далеко не эффективной вселенной резиновых женщин и безалкогольного пива. Философия проиграла в создании универсального API для работы со всеми видами файловых систем или обязательной обработке исключений (Java).

А сейчас даже по сторонам стало страшно смотреть: разработчики вообще «разленились» до такой степени, что не пользуются компиляторами :-) Многие системы создаются на слаботипизированных скриптовых языках типа Python/PHP — которые не только неплохо поддерживают ООП, но такое настолько мощны, что позволяют одной функцией эффективно загрузить файл в переменную :-)
Многие свято верили в аппаратную поддержку ООП на уровне процессора в 90-ые, этого так и не случилось. Но лень продолжает влиять и заставляет сейчас свято верить в эффективную реализацию потоков языка программирования — с учетом моды на размножение ядер процессоров. Т.е. не хочется напрягаться и стоит лишь написать «new Thread» и все заработает эффективно и быстро.

А тем временем мир захватывают эффективные решения на C в стиле nginx,создаются «близкие к железу» производительные NoSQL решения и когда речь заходит о скорости, производительности — одержимый ленью и рекламой мозг начинает шевелиться и ощущать — что-то не то! «Врут» же про потоки — не работают они достаточно эффективно, даже на мультиядерных железках. Хотя теоретически — должны!
Спроси сейчас у разработчика о разнице close и shutdown или об отличиях процесса от потока… и все чаще и чаще видишь, что значит «экспрессивно грызть ногти» :-) А ведь чтобы написать полезный сервер, нужно хорошо понимать, как устроена операционная система, какие бывают сетевые протоколы, как вообще устроена природа вещей и что такое настоящее пиво! :-)
И неважно, поверьте, на каком языке программирования вы собираетесь сделать полезный сетевой сервер. Важно — насколько вы глубоко понимаете то, что собираетесь сделать и каким иммунитетом обладаете против рекламы и собственной технологической лени.
Как эффективно обрабатывать сетевые сокеты люди, когда были ближе к природе, знали. Конечно, этим должно заниматься ядро операционной системы и уведомлять вас о наступлении события:
1) Пришел новый сокет в слушающем соединении (listen) — и его можно взять в обработку (accept)
2) Можно прочитать из сокета, не блокируя процесс (read).
3) Можно записать в сокет, не блокируя процесс (write).
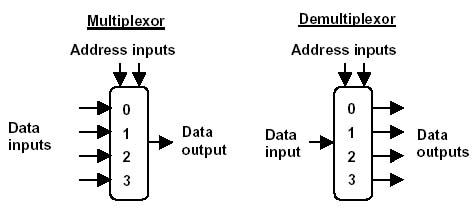
В мире физических законов другие методы обработки соединений, типа создать кучу потоков или, простите, но так иногда делают по причине лени и перфекционизма, процессов — работают медленнее и «жрут» значительно больше памяти. И хотя часто «отмазки» типа: «дешевле купить еще одну железку чем учить программиста асинхронной обработке демультиплексированных сокетов» — работают, иногда вы попадаете в ситуацию, когда нужно решить задачу эффективно на текущем оборудовании — сократив издержки на 1-2 порядка.
Именно по данному принципу работает известный всем nginx, обрабатывающий десятки тысяч соединений несколькими процессами операционной системы.
Для меня до сих пор остается загадкой, почему, несмотря на появление в той же java около 10 лет назад библиотеки для решения серверных задач «в стиле nginx» — она так и не получила должного распространения и приложения продолжают «фигачить» на потоках, несмотря на всю тупиковость и расточительность такого подхода! :-)
Просто лень :-) Хотя также считается, что асинхронная обработка демультипрексированных сокетов — это гораздо сложнее с точки зрения программирования, чем 50 строк в отдельном процессе. Но ниже я покажу, как даже на заточенном немного на другие задачи PHP написать аналогичный сервер — совсем просто.
В PHP есть поддержка «родных дорогих» BSD-сокетов. Но это расширение, к большому сожалению, не поддерживает ssl/tls.
Поэтому нужно лезть в немного отстраненный от природы и здорового образа жизни, наполненный абстракциями, «гоблинами и некроморфами» интерфейс потоков — streams. Если взять лопату и отбросить кучу шелухи, за этим интерфейсом можно увидеть сетевые сокеты и довольно эффективно с ними работать.

Я не буду приводить целиком исходный код сетевого сервера, а пройдусь по ключевым частям кода. В целом же, сервер устойчиво держит без перекомпиляции PHP до 1024 открытых сокета в одном процессе, занимая около 18-20МБ (это дофига по меркам C, но поверьте, бывают PHP-скрипты, кушающие гигабайты) и напрягая лишь одно ядро процессора (да, syscpu заметно больше, но как без него). Если пересобрать PHP, то select может работать с гораздо большим числом сокетов.
Задачи ядра сервера:
1) Проверить массив заданий
2) Для каждого задания создать соединение
3) Проверить, что сокет в задании можно прочитать или записать без блокировки процесса
4) Освободить ресурсы (сокет и т.п) задания
5) Принять соединение от управляющего сокета на добавление задания — без блокировки процесса
Говоря простыми словами, мы набиваем в ядро сервера задания на работу сокетами (например ходить по сайтам и собирать данные и т.п.) и ядро В ОДНОМ ПРОЦЕССЕ начинает шуровать сотни заданий одновременно.
Задание это объект в терминологии ООП типа FSM. Внутри объекта имеется стратегия — допустим: «зайди по этому адресу, создай запрос, загрузи ответ, распарси и т.п. возвраты в начало и в конце запиши результат в NoSQL». Т.е. можно создать задание от простой загрузки содержимого, до сложной цепочки нагрузочного тестирования с многочисленными ветвлениями — и это все, напоминаю, живет в объекте задания.
Задания в данной реализации ставятся через отдельный управляющий сокет на 8000 порту — пишутся json-объекты в tcp-сокет и затем начинают свое движение в сервером ядре.
Главное — не позволить серверному процессу заблокироваться в ожидании ответа в функции при чтении или записи информации в сетевой сокет, при ожидании нового соединения на управляющий сокет или где-нибудь в сложных вычислениях/циклах. Поэтому все сокеты заданий проверяются в системном вызове select и ядро ОС уведомляет нас лишь тогда, когда событие случается (либо по таймауту).
Далее, когда событие произошло и ОС уведомила нас — начинаем в неблокирующем режиме обработку сокетов. Да, можно еще немного оптимизировать обход массива заданий, индексировать задания по номеру сокета и выиграть 10мс — но пока ..., точно угадали, лень :-)
Сам сокет инициируется также в неблокирующем режиме, важно установить флаги, причем оба! STREAM_CLIENT_ASYNC_CONNECT|STREAM_CLIENT_CONNECT:
Ну и посмотрим в код самого задания — оно должно уметь работать с частичными ответами/запросами. Для начала сообщим ядру сервера что мы хотим записать в сокет.
Теперь пишем запрос, определяя сколько еще осталось.
После получения запроса, читаем ответ. Важно понять, когда ответ прочитан полностью. Возможно вам понадобиться установить таймаут на чтение — мне это не потребовалось.
В последнем фрагменте мы можем иерархически направлять FSM по заложенной стратегии, реализуя различные варианты работы задания.
В момент написания класса задания не покидало ощущение, что пишешь плагин для nginx ;-)
Вот видите, как просто и лаконично удалось решить задачу одновременной работы с сотнями и тысячами заданий и сокетов всего в одном процессе PHP. А представьте, если мы поднимем для данного сервера сколько процессов PHP, сколько ядер на сервере — да, это тысячи обслуживаемых клиентов. И тут нет огорода с потоками и неэффективным переключением контекста процессора и повышенных требований к памяти. Серверный процесс PHP потребляет всего около 20МБ памяти, а работает как лошадь :-)

Понимая, какую пользу нам может принести ядро операционной системы для эффективной обработки сетевых сокетов — мы подстроились под нее и реализовали высокопроизводительный сервер на PHP — обслуживающий сотни открытых сетевых сокетов в одном процессе. При необходимости, можно перекомпилировать PHP и обрабатывать тысячи сокетов в одном процессе.
Расширяйте круг знаний, не ленитесь под гнетом стереотипов — используя даже скриптовые слаботипизированные языки можно делать производительные серверы — главное знать как и не бояться экспериментировать :-) Всем удачи!

В старые добрые времена...
В старые добрые времена, когда люди были ближе к природе, свежее пиво радовало приятной горчинкой и женщины изысканно пахли — программисты были ближе к «железу» и писали на С и, в моменты вдохновения — на ассемблере. Но наверно самое важное — программисты понимали, что такое tcp, чем оно отличается от udp, и как эффективно взаимодействовать с ядром операционной системы через интерфейс системных вызовов.

Лень наступает...
Но лень брала свое и постепенно сформировался подход к разработке — близкий к идеологии выдуманного абстрактного мира из Властелина Колец.

Люди стали создавать в программах объекты вымышленного мира, философские концепции, обменивающиеся сообщениями и все больше стали отрываться от реальности и природы. И если в C++ еще пытались задержаться наедине с природой через указатели и контролируемую работу с памятью, то в Java и C# лень взяла свое и программисты оказались в идеальной, но далеко не эффективной вселенной резиновых женщин и безалкогольного пива. Философия проиграла в создании универсального API для работы со всеми видами файловых систем или обязательной обработке исключений (Java).

А сейчас даже по сторонам стало страшно смотреть: разработчики вообще «разленились» до такой степени, что не пользуются компиляторами :-) Многие системы создаются на слаботипизированных скриптовых языках типа Python/PHP — которые не только неплохо поддерживают ООП, но такое настолько мощны, что позволяют одной функцией эффективно загрузить файл в переменную :-)
Процессоры и потоки
Многие свято верили в аппаратную поддержку ООП на уровне процессора в 90-ые, этого так и не случилось. Но лень продолжает влиять и заставляет сейчас свято верить в эффективную реализацию потоков языка программирования — с учетом моды на размножение ядер процессоров. Т.е. не хочется напрягаться и стоит лишь написать «new Thread» и все заработает эффективно и быстро.

А тем временем...
А тем временем мир захватывают эффективные решения на C в стиле nginx,
Забыли истоки...
Спроси сейчас у разработчика о разнице close и shutdown или об отличиях процесса от потока… и все чаще и чаще видишь, что значит «экспрессивно грызть ногти» :-) А ведь чтобы написать полезный сервер, нужно хорошо понимать, как устроена операционная система, какие бывают сетевые протоколы, как вообще устроена природа вещей и что такое настоящее пиво! :-)
Дело не в языке программирования
И неважно, поверьте, на каком языке программирования вы собираетесь сделать полезный сетевой сервер. Важно — насколько вы глубоко понимаете то, что собираетесь сделать и каким иммунитетом обладаете против рекламы и собственной технологической лени.
Обработка соединений
Как эффективно обрабатывать сетевые сокеты люди, когда были ближе к природе, знали. Конечно, этим должно заниматься ядро операционной системы и уведомлять вас о наступлении события:
1) Пришел новый сокет в слушающем соединении (listen) — и его можно взять в обработку (accept)
2) Можно прочитать из сокета, не блокируя процесс (read).
3) Можно записать в сокет, не блокируя процесс (write).
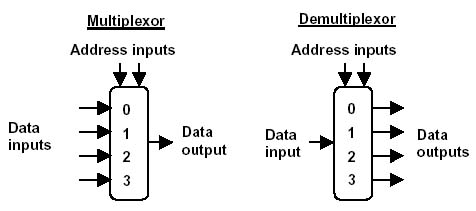
В мире физических законов другие методы обработки соединений, типа создать кучу потоков или, простите, но так иногда делают по причине лени и перфекционизма, процессов — работают медленнее и «жрут» значительно больше памяти. И хотя часто «отмазки» типа: «дешевле купить еще одну железку чем учить программиста асинхронной обработке демультиплексированных сокетов» — работают, иногда вы попадаете в ситуацию, когда нужно решить задачу эффективно на текущем оборудовании — сократив издержки на 1-2 порядка.
Именно по данному принципу работает известный всем nginx, обрабатывающий десятки тысяч соединений несколькими процессами операционной системы.
Для меня до сих пор остается загадкой, почему, несмотря на появление в той же java около 10 лет назад библиотеки для решения серверных задач «в стиле nginx» — она так и не получила должного распространения и приложения продолжают «фигачить» на потоках, несмотря на всю тупиковость и расточительность такого подхода! :-)

А почему все так не делают?
Просто лень :-) Хотя также считается, что асинхронная обработка демультипрексированных сокетов — это гораздо сложнее с точки зрения программирования, чем 50 строк в отдельном процессе. Но ниже я покажу, как даже на заточенном немного на другие задачи PHP написать аналогичный сервер — совсем просто.
PHP и сокеты
В PHP есть поддержка «родных дорогих» BSD-сокетов. Но это расширение, к большому сожалению, не поддерживает ssl/tls.
Поэтому нужно лезть в немного отстраненный от природы и здорового образа жизни, наполненный абстракциями, «гоблинами и некроморфами» интерфейс потоков — streams. Если взять лопату и отбросить кучу шелухи, за этим интерфейсом можно увидеть сетевые сокеты и довольно эффективно с ними работать.

Кусочки кода
Я не буду приводить целиком исходный код сетевого сервера, а пройдусь по ключевым частям кода. В целом же, сервер устойчиво держит без перекомпиляции PHP до 1024 открытых сокета в одном процессе, занимая около 18-20МБ (это дофига по меркам C, но поверьте, бывают PHP-скрипты, кушающие гигабайты) и напрягая лишь одно ядро процессора (да, syscpu заметно больше, но как без него). Если пересобрать PHP, то select может работать с гораздо большим числом сокетов.
Ядро сервера
Задачи ядра сервера:
1) Проверить массив заданий
2) Для каждого задания создать соединение
3) Проверить, что сокет в задании можно прочитать или записать без блокировки процесса
4) Освободить ресурсы (сокет и т.п) задания
5) Принять соединение от управляющего сокета на добавление задания — без блокировки процесса
Говоря простыми словами, мы набиваем в ядро сервера задания на работу сокетами (например ходить по сайтам и собирать данные и т.п.) и ядро В ОДНОМ ПРОЦЕССЕ начинает шуровать сотни заданий одновременно.
Задание
Задание это объект в терминологии ООП типа FSM. Внутри объекта имеется стратегия — допустим: «зайди по этому адресу, создай запрос, загрузи ответ, распарси и т.п. возвраты в начало и в конце запиши результат в NoSQL». Т.е. можно создать задание от простой загрузки содержимого, до сложной цепочки нагрузочного тестирования с многочисленными ветвлениями — и это все, напоминаю, живет в объекте задания.
Задания в данной реализации ставятся через отдельный управляющий сокет на 8000 порту — пишутся json-объекты в tcp-сокет и затем начинают свое движение в сервером ядре.
Принцип обработки заданий и сокетов
Главное — не позволить серверному процессу заблокироваться в ожидании ответа в функции при чтении или записи информации в сетевой сокет, при ожидании нового соединения на управляющий сокет или где-нибудь в сложных вычислениях/циклах. Поэтому все сокеты заданий проверяются в системном вызове select и ядро ОС уведомляет нас лишь тогда, когда событие случается (либо по таймауту).
while (true) {
$ar_read = null;
$ar_write = null;
$ar_ex = null;
//Собираемся читать также управляющий сокет, вместе с сокетами заданий
$ar_read[] = $this->controlSocket;
foreach ($this->jobs as $job) {
//job cleanup
if ( $job->isFinished() ) {
$key = array_search($job, $this->jobs);
if (is_resource($job->getSocket())) {
//"надежно" закрываем сокет
stream_socket_shutdown($job->getSocket(),STREAM_SHUT_RDWR);
fclose($job->getSocket());
}
unset($this->jobs[$key]);
$this->jobsFinished++;
continue;
}
//Задания могут "засыпать" на определенное время, например при ошибке удаленного сервера
if ($job->isSleeping()) continue;
//Заданию нужно инициировать соединение
if ($job->getStatus()=='DO_REQUEST') {
$socket = $this->createJobSocket($job);
if ($socket) {
$ar_write[] = $socket;
}
//Задание хочет прочитать ответ из сокета
} else if ($job->getStatus()=='READ_ANSWER') {
$socket = $job->getSocket();
if ($socket) {
$ar_read[] = $socket;
}
//Заданию нужно записать запрос в сокет
} else if ( $job->getStatus()=='WRITE_REQUEST' ) {
$socket = $job->getSocket();
if ($socket) {
$ar_write[] = $socket;
}
}
}
//Ждем когда ядро ОС нас уведомит о событии или делаем дежурную итерацию раз в 30 сек
$num = stream_select($ar_read, $ar_write, $ar_ex, 30);
Далее, когда событие произошло и ОС уведомила нас — начинаем в неблокирующем режиме обработку сокетов. Да, можно еще немного оптимизировать обход массива заданий, индексировать задания по номеру сокета и выиграть 10мс — но пока ..., точно угадали, лень :-)
if (is_array($ar_write)) {
foreach ($ar_write as $write_ready_socket) {
foreach ($this->getJobs() as $job) {
if ($write_ready_socket == $job->getSocket()) {
$dataToWrite = $job->readyDataWriteEvent();
$count = fwrite($write_ready_socket , $dataToWrite, 1024);
//Сообщаем объекту сколько байт удалось записать в сокет
$job->dataWrittenEvent($count);
}
}
}
}
if (is_array($ar_read)) {
foreach ($ar_read as $read_ready_socket) {
///// command processing
///
//Пришло соединение на управляющий сокет, обрабатываем команду
if ($read_ready_socket == $this->controlSocket) {
$csocket = stream_socket_accept($this->controlSocket);
//Тут упрощение - верим локальному клиенту, что он закроет соединение. Иначе ставьте таймаут.
if ($csocket) {
$req = '';
while ( ($data = fread($csocket,10000)) !== '' ) {
$req .= $data;
}
//Обрабатываем команду также в неблокирующем режиме
$this->processCommand(trim($req), $csocket);
stream_socket_shutdown($csocket, STREAM_SHUT_RDWR);
fclose($csocket);
}
continue;
///
/////
} else {
//Читаем из готового к чтению сокета без блокировки
$data = fread($read_ready_socket , 10000);
foreach ($this->getJobs() as $job) {
if ($read_ready_socket == $job->getSocket()) {
//Передаем заданию считанные данные. Если сокет закроется, считаем пустую строку.
$job->readyDataReadEvent($data);
}
}
}
}
}
}
Сам сокет инициируется также в неблокирующем режиме, важно установить флаги, причем оба! STREAM_CLIENT_ASYNC_CONNECT|STREAM_CLIENT_CONNECT:
private function createJobSocket(BxRequestJob $job) {
//Check job protocol
if ($job->getSsl()) {
//https
$ctx = stream_context_create(
array('ssl' =>
array(
'verify_peer' => false,
'allow_self_signed' => true
)
)
);
$errno = 0;
$errorString = '';
//Вот тут происходит временами блокировочка в 30-60мс, видимо из-за установки TCP-соединения с удаленным хостом, надо глянуть в исходники, но снова ... лень
$socket = stream_socket_client('ssl://'.$job->getConnectServer().':443',$errno,$errorString,30,STREAM_CLIENT_ASYNC_CONNECT|STREAM_CLIENT_CONNECT,$ctx);
if ($socket === false) {
$this->log(__METHOD__." connect error: ". $job->getConnectServer()." ". $job->getSsl() ."$errno $errorString");
$job->connectedSocketEvent(false);
$this->connectsFailed++;
return false;
} else {
$job->connectedSocketEvent($socket);
$this->connectsCreated++;
return $socket;
}
} else {
//http
...
Ну и посмотрим в код самого задания — оно должно уметь работать с частичными ответами/запросами. Для начала сообщим ядру сервера что мы хотим записать в сокет.
//Формируем тело следующего запроса
function readyDataWriteEvent() {
if (!$this->dataToWrite) {
if ($this->getParams()) {
$str = http_build_query($this->getParams());
$headers = $this->getRequestMethod()." ".$this->getUri()." HTTP/1.0\r\nHost: ".$this->getConnectServer()."\r\n".
"Content-type: application/x-www-form-urlencoded\r\n".
"Content-Length:".strlen($str)."\r\n\r\n";
$this->dataToWrite = $headers;
$this->dataToWrite .= $str;
} else {
$headers = $this->getRequestMethod()." ".$this->getUri()." HTTP/1.0\r\nHost: ".$this->getConnectServer()."\r\n\r\n";
$this->dataToWrite = $headers;
}
return $this->dataToWrite;
} else {
return $this->dataToWrite;
}
}
Теперь пишем запрос, определяя сколько еще осталось.
//Пишем запрос в сокет до того момента, когда полностью запишем его тело
function dataWrittenEvent($count) {
if ($count === false ) {
//socket was reset
$this->jobFinished = true;
} else {
$dataTotalSize = strlen($this->dataToWrite);
if ($count<$dataTotalSize) {
$this->dataToWrite = substr($this->dataToWrite,$count);
$this->setStatus('WRITE_REQUEST');
} else {
//Когда успешно записали запрос в сокет, переходим в режим чтения ответа
$this->setStatus('READ_ANSWER');
}
}
}
После получения запроса, читаем ответ. Важно понять, когда ответ прочитан полностью. Возможно вам понадобиться установить таймаут на чтение — мне это не потребовалось.
//Читаем из сокета до момента, когда полностью прочитаем ответ и совершаем переход в другой статус
function readyDataReadEvent($data)
{
////////// Successfull data read
/////
if ($data) {
$this->body .= $data;
$this->setStatus('READ_ANSWER');
$this->bytesRead += strlen($data);
/////
//////////
} else {
////////// А тут мы уже считали ответ и начинаем его парсить
/////
////////// redirect
if ( preg_match("|\r\nlocation:(.*)\r\n|i",$this->body, $ar_matches) ) {
$url = parse_url(trim($ar_matches[1]));
$this->setStatus('DO_REQUEST');
} else if (...) {
//Так мы сигнализируем ядру сервера, что задание нужно завершить
$this->jobFinished = true;
...
} else if (...) {
$this->setSleepTo(time()+$this->sleepInterval);
$this->sleepInterval *=2;
$this->retryCount--;
$this->setStatus('DO_REQUEST');
}
$this->body = '';
...
В последнем фрагменте мы можем иерархически направлять FSM по заложенной стратегии, реализуя различные варианты работы задания.
В момент написания класса задания не покидало ощущение, что пишешь плагин для nginx ;-)
Результат
Вот видите, как просто и лаконично удалось решить задачу одновременной работы с сотнями и тысячами заданий и сокетов всего в одном процессе PHP. А представьте, если мы поднимем для данного сервера сколько процессов PHP, сколько ядер на сервере — да, это тысячи обслуживаемых клиентов. И тут нет огорода с потоками и неэффективным переключением контекста процессора и повышенных требований к памяти. Серверный процесс PHP потребляет всего около 20МБ памяти, а работает как лошадь :-)

Итоги
Понимая, какую пользу нам может принести ядро операционной системы для эффективной обработки сетевых сокетов — мы подстроились под нее и реализовали высокопроизводительный сервер на PHP — обслуживающий сотни открытых сетевых сокетов в одном процессе. При необходимости, можно перекомпилировать PHP и обрабатывать тысячи сокетов в одном процессе.
Расширяйте круг знаний, не ленитесь под гнетом стереотипов — используя даже скриптовые слаботипизированные языки можно делать производительные серверы — главное знать как и не бояться экспериментировать :-) Всем удачи!
