Психология — интересная и иногда полезная наука. Многочисленные исследования показывают, что задержка в отображении веб-страницы дольше 300 мс заставляет пользователя отвлечься от веб-ресурса и задуматься: «что за хрень?». Поэтому УСКОРИВ веб-проект до психологически невоспринимаемых значений, можно ПРОСТО удерживать пользователей дольше. И именно поэтому бизнес готов тратиться на скорость: $80М — чтобы уменьшить latenсy всего на 1 мс.
Однако, чтобы ускорить современный веб-проект, придется кровушки пустить и основательно покопаться в этой теме — поэтому базовое знание сетевых протоколов приветствуется. Зная принципы, можно без особых усилий ускорить свою веб-систему на сотни миллисекунд всего за несколько подходов. Ну что, готовы сэкономить сотни миллионов? Наливайте кофе.
Это очень горячая тема — как удовлетворить пользователя сайта — и юзабилисты скорее всего заставят меня выпить коктейль Молотова, закусить гранатой без чеки и успеть выкрикнуть перед взрывом: «несу ересь». Поэтому хочется зайти с другой стороны. Широко известно, что задержка в отображении страницы больше 0.3 сек — заставляет пользователя заметить это и… «проснуться» от процесса общения с сайтом. А задержка в отображении больше секунды — задуматься на тему: «а что я тут делаю вообще? чего они меня мучают и заставляю ждать?».
Поэтому отдадим юзабелистам их «юзабелизм», а сами займемся решением практической задачи — как не тревожить «сон» клиента и способствовать его работе с сайтом как можно дольше, без отвлечений на «тормоза».
Ну кто, конечно Вы. Иначе вряд ли бы Вы начали читать пост. Если серьезно, то тут проблема — ибо вопрос скорости делят на 2 слабо связанные и технологически, и социально части: фронтэнд и бэкэнд. И нередко забывают про третью ключевую составляющую — сеть.
Для начала вспомним, что первые сайты в начале девяностых были… набором статических страниц. И HTML — был простым, понятным и лаконичным: сначала текст, потом текст и ресурсы. Вакханалия началась с динамической генерацией веб-страниц и распространением java, perl и в настоящее время — это уже плеяда технологий, в числе которых php.
Чтобы снизить влияние этой гонки на жизнеспособность сети — вдогонку принимают HTTP/1.0 в 1996, а через 3 года — HTTP/1.1 в 1999. В последнем, наконец, договорились — что не нужно гонять TCP handshakes с ~2/3 скорости света (в оптоволокне) туда-суда для каждого запроса, устанавливая новое соединение, а правильнее открыть TCP-соединение один раз и работать через него.
Тут мало что изменилось за последние 40 лет. Ну может «пародию» на реляционную теорию добавили под названием NoSQL — которая дает как плюсы, так и минусы. Хотя, как показывает практика — пользы бизнесу от нее вроде больше (но и бессонных ночей с поиском ответа на вопрос: «кто лишил данные целостности и под каким предлогом» — стало скорее больше).
Тут все понятно с точки зрения обеспечения скорости:
Больше не будем говорить про разгон «приложения» — про это написали много книг и статей и все довольно линейно и просто.
Главное одно — чтобы приложение было прозрачно и можно было померить скорость прохождения запроса через разные компоненты приложения. Если этого нет — дальше можно не читать, не поможет.
Как этого добиться? Пути известны:
Если логов у вас много и вы запутываетесь в них — агрегируйте данные, смотрите процентили и распределение. Просто и прямолинейно. Обнаружили запрос более 0.3 секунды — начинайте разбор полетов и так до победного конца.
Движемся наружу. Веб-сервер. Тут тоже мало что сильно поменялось, но может только что костылизация — через установку обратного прокси-веб-сервера перед веб-сервером (fascgi-сервером). Да, это конечно помогает:
Но вопрос остался — почему apache сразу не стали делать «правильно» и иногда приходится ставить веб-серверы паровозиком.
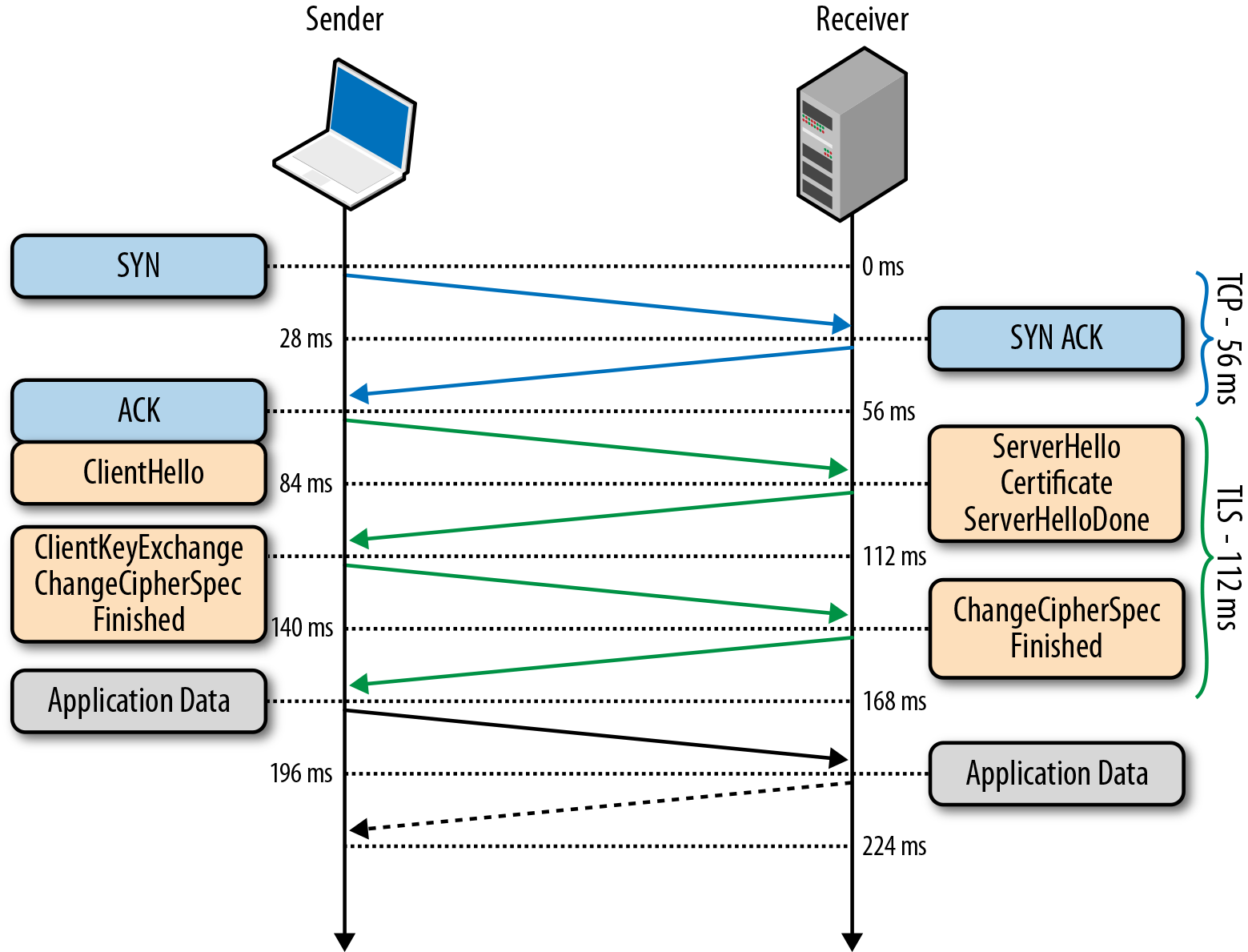
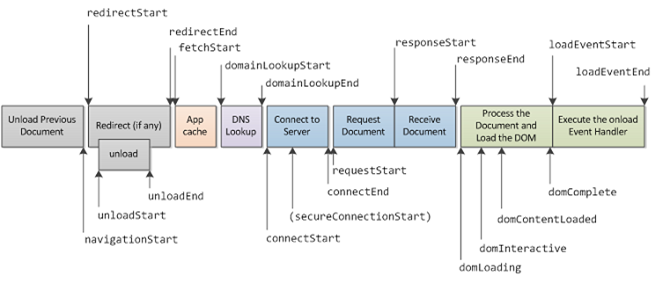
Установление TCP-соединения занимает 1 RTT. Распечатайте диаграмку и повесьте перед собой. Ключ к пониманию появления тормозов — тут.

Эта величина довольно тесно коррелирует с расположением вашего пользователя относительно веб-сервера (да, есть скорость света, есть скорость распространения света в материале, есть маршрутизация) и может занимать (особенно с учетом провайдера последней мили) — десятки и сотни миллисекунд, что конечно много. И беда, если это установление соединения происходит для каждого запроса, что было распространено в HTTP/1.0.
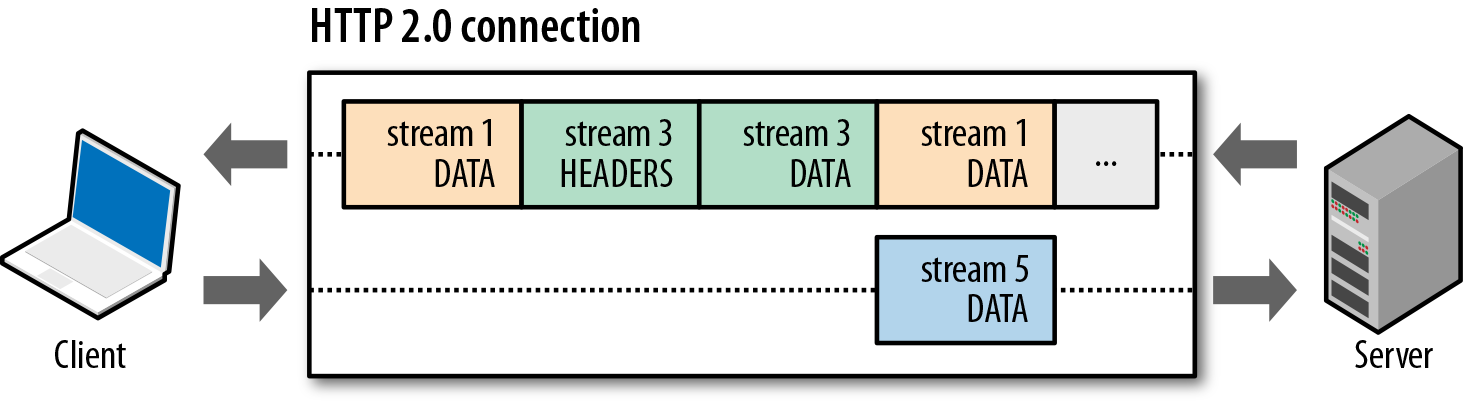
Ради этого по большому счету и затевался HTTP 1.1 и в этом направлении развивается и HTTP 2.0 (в лице spdy). IETF с Google в настоящее время пытаются сделать все, чтобы выжать из текущей архитектуры сети максимум — не ломая ее. А это можно сделать… ну да, максимально эффективно используя TCP-соединения, используя их полосу пропускания как можно плотнее через мультиплексирование, восстановление после потерь пакетов и др.
Поэтому обязательно проверьте использование постоянных соединений на веб-серверах и в приложении.
Без TLS, который изначально зародился в недрах Netscape Communications как SSL — в современном мире никуда. И хотя, говорят, Последняя «дырочка» в этом протоколе заставила многих поседеть значительно раньше срока — альтернативы практически нет.
Но не все почему-то помнят, что TLS ухудшает «послевкусие» — добавляя 1-2 RTT дополнительно к 1 RTT соединению через TCP. В nginx вообще по умолчанию кэш сессий TLS — выключен — что добавляет лишний RTT.
Поэтому проследите, чтобы TLS-сессии в обязательном порядке кэшировались — и так мы сэкономим еще 1 RTT (а один RTT все-таки останется, к сожалению, как плата за безопасность).
Про бэкэнд, наверное, все. Дальше будет сложнее, но интереснее.
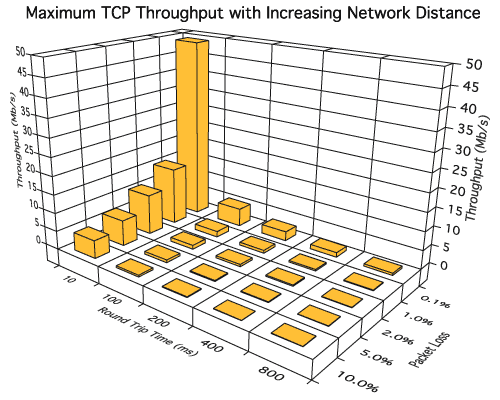
Часто можно услышать — у нас 50МБит/с, 100МБит/с, 4G даст еще больше… Но редко можно увидеть понимание, что для типичного веб-приложения пропускная способность не особо важна (если только файлы не качать) — гораздо важнее lantency, т.к. делается много небольших запросов по разным соединениям и TCP-окно просто не успевает раскачаться.
И разумеется, чем дальше клиент от веб-сервера, тем дольше. Но бывает что нельзя иначе или трудно. Именно поэтому придумали:
Что еще можно сделать… увеличить TCP’s initial congestion window — да, это нередко помогает, т.к. веб-страничка отдается одним набором пакетов без подтверждения. Попробуйте.
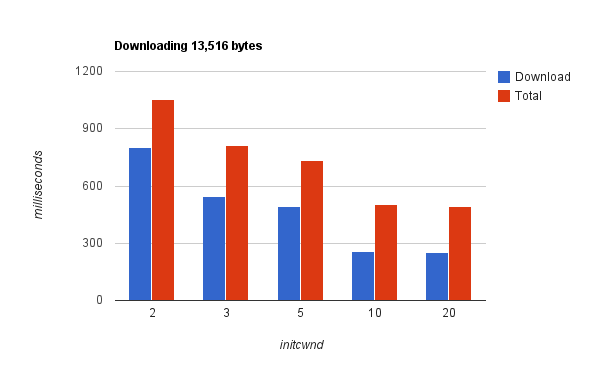
Включите отладчик браузера, посмотрите время загрузки веб-страницы и подумайте о latency и способах ее уменьшения.
Помните, что TCP-окошко соединения должно разогнаться сначала. Если веб-страница загружается меньше секунды — окошко может не успеть увеличиться. Средняя пропускная способность сети в мире — немного превышает 3 МБит\с. Вывод — передавайте через одно установленное соединение как можно больше, «разогрев» его.

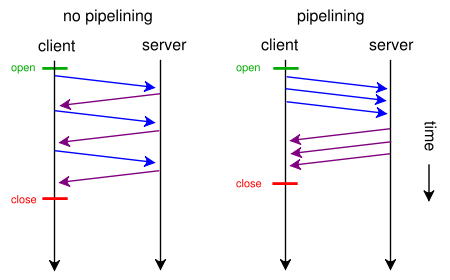
Помочь тут может конечно мультиплексирование HTTP-ресурсов внутри одного TCP-соединения: передача нескольких ресурсов вперемешку как в запросе, так и ответе. И даже эту технику включили в стандарт, но недоописали и в итоге она не взлетела (в chrome ее не так давно вообще убрали). Поэтому тут можно пока попробовать spdy, ждать HTTP 2.0 или использовать таки pipelining — но не из браузера, а из приложения напрямую.
А как же очень популярная техника шардинга доменов — когда браузер/приложение преодолевает ограничение в >=6 соединений на домен, открывая еще по >=6 и более соединений на фиктивные домены: img1.mysite.ru, img2.mysite.ru…? Тут весело, т.к. с точки зрения HTTP/1.1 — это вас вероятнее всего ускорит, а с точки зрения HTTP/2.0 — это антипаттерн, т.к. мультиплексирование HTTP-трафика через TCP-соединение может обеспечить лучшую пропускную способность.
Так что пока — шардим домены и ждем HTTP/2.0 чтобы этого больше не делать. И конечно — лучше измерить конкретно для вашего веб-приложения и сделать обоснованный выбор.
Про известные вещи типа скорости рендеринга веб-страницы и размера изображений и JavaScript, порядка загрузки ресурсов и т.п. — писать не интересно. Тема избита и убита. Если кратко и неточно — кэшируйте ресурсы на стороне веб-браузера, но… с головой. Кэшировать 10МБ js-файл и парсить его внутри браузера на каждой веб-странице — понимаем к чему приведет. Включаем отладчик браузера, наливаем кофе и к исходу дня — тренды налицо. Набрасываем план и реализуем. Просто и прозрачно.
Гораздо более острые подводные камни могут скрываться за достаточно новыми и бурно развивающимися сетевыми возможностями веб-браузера. О них и поговорим:
Изначально браузер воспринимался как клиентское приложение для отображения HTML-разметки. Но с каждым годом происходило превращение его в центр управления плеядой технологий — в итоге HTTP-сервер и веб-приложение за ним теперь воспринимается лишь как вспомогательный компонентик внутри браузера. Интересный технологический сдвиг акцентов.
Более того, с появлением встроенной в браузер «телестудии» WebRTC и средств сетевого взаимодействия браузера с внешним миром — вопрос обеспечения производительности плавно переместился от серверной инфраструктуры к браузеру. Если эта внутренняя кухня у клиента будет тормозить — про php на веб-сервере или join в БД никто и не вспомнит.
Разберем на запчасти этот непрозрачный монолит.
Это всем известный AJAX — способность браузера обращаться к внешним ресурсам по HTTP. С появлением CORS — начался совершенный «беспредел». Теперь чтобы определить причину торможения, нужно лазать по всем ресурсам и смотреть логи везде.
Если серьезно, технология несомненно взорвала возможности браузера, превратив его в мощную платформу динамического рендеринга информации. Писать о ней нет смысла, тема многим известна. Однако опишу ограничения:
Тем не менее, технология очень популярна и сделать ее прозрачной с точки зрения мониторинга скорости — несложно.
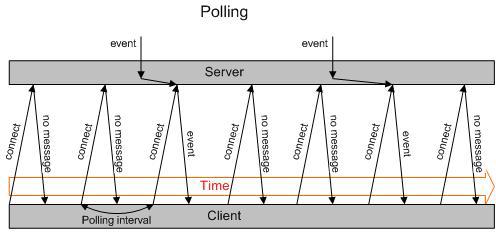
Как сделать веб-чат? Да, нужно как-то передавать со стороны сервера в браузер информацию об изменениях. Напрямую через HTTP — нельзя, не умеет. Только: запрос и ответ. Вот в лоб люди и решили: сделать запрос и ждать ответ, секунду, 30 секунд, минуту. Если что нибудь пришло — отдать в ответ и разорвать соединение.
Да, куча антипаттернов, костылей — но технология очень широко распространена и работает всегда. Но, т.к. Вы отвечаете за скорость — знайте, нагрузка на серверы при таком подходе — очень высока, и может сопоставляться с нагрузкой от основной посещаемости веб-проекта. А если обновления от сервера к браузерам распространяются часто — то может основную нагрузку превышать в разы!
Что делать-то?
Тут открывается TCP-соединение с веб-сервером, не закрывается и в него сервер пишет разную инфу в UTF-8. Нельзя правда бинарные данные передавать оптимально без предварительного Base64 (+33% увеличение в размере), но как канал управления в одну сторону — превосходное решение. Правда в IE — не поддерживается (см. пункт выше, который везде работает).
Плюсы технологии в том, что она:
Для системного администратора это даже не зверь, а скорее ночной некроморф. «Хитрым» способом через HTTP 1.1 Upgrade браузер меняет «тип» HTTP соединения и оно остается открытым.

Затем по соединению в ОБЕ (!) стороны можно начать передавать данные, оформленные в сообщения (frames). Сообщения бывают не только с информацией, но и контрольные, в т.ч. типа «PING», «PONG». Первое впечатление — снова изобрели велосипед, снова TCP на базе TCP.
С точки зрения разработчика — конечно это удобно, появляется дуплексный канал между браузером и веб-приложением на сервере. Хочешь streaming, хочешь messages. Но:
Как отслеживать производительность Web Sockets? Очень хороший вопрос, оставленный специально на закуску. Со стороны клиента — сниффер пакетов WireShark, со стороны сервера и с включенным TLS — мы решаем задачу через патчинг модулей для nginx, но видимо есть более простое решение.
Главное понимать, как Web Sockets устроены изнутри, а Вы уже это знаете и контроль за скоростью — будет обеспечен.
Так что же лучше: XMLHttpRequest, Long Polling, Server-Sent Events или Web Sockets? Успех — в грамотном сочетании этих технологий. Например, можно управлять приложением через WebSockets, а загружать ресурсы с использованием встроенного кэширования через AJAX.
Научиться измерять и реагировать на превышение заданных значений. Обрабатывайте логи веб-приложения, разбирайтесь с медленными запросами в них. Скорость на стороне клиента тоже стало возможным мерить благодаря Navigation timing API — мы собираем данные по производительности в браузерах, отправляем их средствами JavaScript в облако, агрегируем в pinba и реагируем на отклонения. Очень полезное API, пользуйтесь обязательно.
В результате вы найдете себя в окружении системы мониторинга типа nagiоs, с десятком-другим автоматических тестов, на которых видно, что со скоростью работы вашей веб-системы все в порядке. А в случае срабатываний — команда собирается и принимается решение. Кейсы могут быть, например, такими:
и т.д.
Мы прошлись по основным компонентам современного веб-приложения. Узнали о трендах HTTP 2.0, контрольных точках, которые важно понимать и научиться измерять для обеспечения скорости ответа веб-приложения по возможности ниже 0.3 сек. Заглянули в суть современных сетевых технологий, использующихся в браузерах, обозначили их достоинства и узкие места.
Поняли, что понимать работу сети, ее скорость, latency и пропускную способность — важно. И что пропускная способность важна далеко не всегда.
Стало понятно, что теперь недостаточно «протюнить» веб-сервер и базу данных. Нужно разбираться в букете сетевых технологий, используемых браузером, знать их изнутри и эффективно измерять.Поэтому сниффер TCP-трафика должен теперь стать вашей правой рукой, а мониторинг ключевых показателей производительности в логах серверов — левой ногой.
Можно попытаться решить задачу обработки запроса клиента за «0.3 сек» по-разному. Главное — определить метрики, автоматически собирать их и действовать в случае их превышения — докапываться к каждом конкретном случае до корня. В нашем продукте мы решили задачу обеспечения максимально низкой latency благодаря комплексной технологии кэширования, объединяющую технологии статического и динамического сайта
В заключение, приглашаем посетить нашу технологическую конференцию, которая пройдет уже скоро, 23 мая. Всем удачи и успехов в нелегком деле обеспечения производительности веб-проектов!
Однако, чтобы ускорить современный веб-проект, придется кровушки пустить и основательно покопаться в этой теме — поэтому базовое знание сетевых протоколов приветствуется. Зная принципы, можно без особых усилий ускорить свою веб-систему на сотни миллисекунд всего за несколько подходов. Ну что, готовы сэкономить сотни миллионов? Наливайте кофе.
Послевкусие
Это очень горячая тема — как удовлетворить пользователя сайта — и юзабилисты скорее всего заставят меня выпить коктейль Молотова, закусить гранатой без чеки и успеть выкрикнуть перед взрывом: «несу ересь». Поэтому хочется зайти с другой стороны. Широко известно, что задержка в отображении страницы больше 0.3 сек — заставляет пользователя заметить это и… «проснуться» от процесса общения с сайтом. А задержка в отображении больше секунды — задуматься на тему: «а что я тут делаю вообще? чего они меня мучают и заставляю ждать?».
Поэтому отдадим юзабелистам их «юзабелизм», а сами займемся решением практической задачи — как не тревожить «сон» клиента и способствовать его работе с сайтом как можно дольше, без отвлечений на «тормоза».
Кто отвечает за скорость
Ну кто, конечно Вы. Иначе вряд ли бы Вы начали читать пост. Если серьезно, то тут проблема — ибо вопрос скорости делят на 2 слабо связанные и технологически, и социально части: фронтэнд и бэкэнд. И нередко забывают про третью ключевую составляющую — сеть.
Просто HTML
Для начала вспомним, что первые сайты в начале девяностых были… набором статических страниц. И HTML — был простым, понятным и лаконичным: сначала текст, потом текст и ресурсы. Вакханалия началась с динамической генерацией веб-страниц и распространением java, perl и в настоящее время — это уже плеяда технологий, в числе которых php.
Чтобы снизить влияние этой гонки на жизнеспособность сети — вдогонку принимают HTTP/1.0 в 1996, а через 3 года — HTTP/1.1 в 1999. В последнем, наконец, договорились — что не нужно гонять TCP handshakes с ~2/3 скорости света (в оптоволокне) туда-суда для каждого запроса, устанавливая новое соединение, а правильнее открыть TCP-соединение один раз и работать через него.
Бэкэнд
Приложение
Тут мало что изменилось за последние 40 лет. Ну может «пародию» на реляционную теорию добавили под названием NoSQL — которая дает как плюсы, так и минусы. Хотя, как показывает практика — пользы бизнесу от нее вроде больше (но и бессонных ночей с поиском ответа на вопрос: «кто лишил данные целостности и под каким предлогом» — стало скорее больше).
- Приложение и/или веб-сервер (php, java, perl, python, ruby и т.п.) — принимает запрос клиента
- Приложение обращается к БД и получает данные
- Приложение формирует html
- Приложение и/или веб-сервер — отдает данные клиенту
Тут все понятно с точки зрения обеспечения скорости:
- оптимальный код приложения, без зацикливаний на секунды
- оптимальные данные в БД, индексация, денормализация
- кэширование выборки из БД
Больше не будем говорить про разгон «приложения» — про это написали много книг и статей и все довольно линейно и просто.
Главное одно — чтобы приложение было прозрачно и можно было померить скорость прохождения запроса через разные компоненты приложения. Если этого нет — дальше можно не читать, не поможет.
Как этого добиться? Пути известны:
- Стандартное логирование запросов (nginx, apache, php-fpm)
- Логирование медленных запросов БД (опция в mysql)
- Инструменты фиксации узких мест при прохождении запроса. Для php это xhprof, pinba.
- Встроенные инструменты внутри веб-приложения, например отдельный модуль трассировки.
Если логов у вас много и вы запутываетесь в них — агрегируйте данные, смотрите процентили и распределение. Просто и прямолинейно. Обнаружили запрос более 0.3 секунды — начинайте разбор полетов и так до победного конца.
Веб-сервер
Движемся наружу. Веб-сервер. Тут тоже мало что сильно поменялось, но может только что костылизация — через установку обратного прокси-веб-сервера перед веб-сервером (fascgi-сервером). Да, это конечно помогает:
- держать значительно больше открытых соединений с клиентами (за счет?.. да, другой архитектуры кэширующего прокси — для nginx это использование мультиплексирования сокетов небольшим числом процессов и низкого объема памяти для одного соединения)
- более эффективно отдавать статические ресурсы напрямую с дисков, не фильтруя через код приложения
Но вопрос остался — почему apache сразу не стали делать «правильно» и иногда приходится ставить веб-серверы паровозиком.
Постоянные соединения
Установление TCP-соединения занимает 1 RTT. Распечатайте диаграмку и повесьте перед собой. Ключ к пониманию появления тормозов — тут.
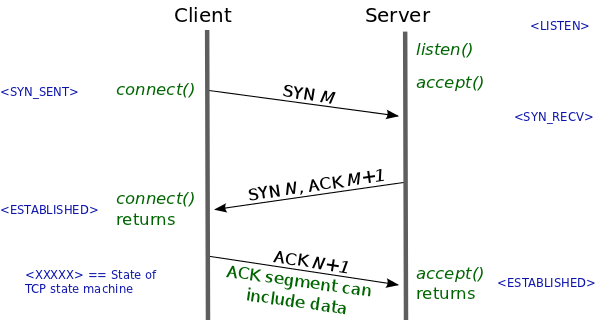
Эта величина довольно тесно коррелирует с расположением вашего пользователя относительно веб-сервера (да, есть скорость света, есть скорость распространения света в материале, есть маршрутизация) и может занимать (особенно с учетом провайдера последней мили) — десятки и сотни миллисекунд, что конечно много. И беда, если это установление соединения происходит для каждого запроса, что было распространено в HTTP/1.0.
Ради этого по большому счету и затевался HTTP 1.1 и в этом направлении развивается и HTTP 2.0 (в лице spdy). IETF с Google в настоящее время пытаются сделать все, чтобы выжать из текущей архитектуры сети максимум — не ломая ее. А это можно сделать… ну да, максимально эффективно используя TCP-соединения, используя их полосу пропускания как можно плотнее через мультиплексирование, восстановление после потерь пакетов и др.

Поэтому обязательно проверьте использование постоянных соединений на веб-серверах и в приложении.
TLS
Без TLS, который изначально зародился в недрах Netscape Communications как SSL — в современном мире никуда. И хотя, говорят, Последняя «дырочка» в этом протоколе заставила многих поседеть значительно раньше срока — альтернативы практически нет.
Но не все почему-то помнят, что TLS ухудшает «послевкусие» — добавляя 1-2 RTT дополнительно к 1 RTT соединению через TCP. В nginx вообще по умолчанию кэш сессий TLS — выключен — что добавляет лишний RTT.
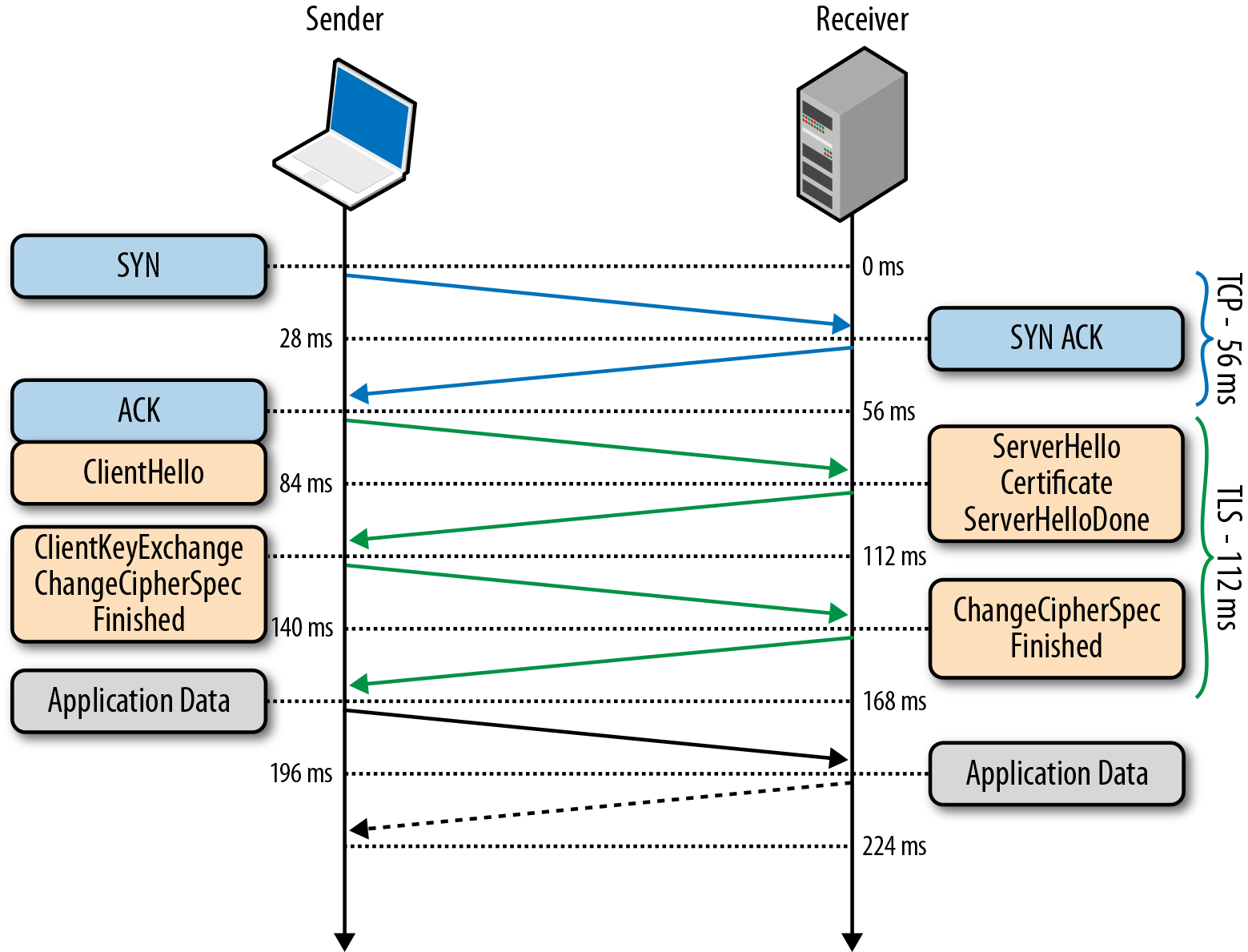
Поэтому проследите, чтобы TLS-сессии в обязательном порядке кэшировались — и так мы сэкономим еще 1 RTT (а один RTT все-таки останется, к сожалению, как плата за безопасность).
Про бэкэнд, наверное, все. Дальше будет сложнее, но интереснее.
Сеть. Расстояние и пропускная способность сети
Часто можно услышать — у нас 50МБит/с, 100МБит/с, 4G даст еще больше… Но редко можно увидеть понимание, что для типичного веб-приложения пропускная способность не особо важна (если только файлы не качать) — гораздо важнее lantency, т.к. делается много небольших запросов по разным соединениям и TCP-окно просто не успевает раскачаться.
И разумеется, чем дальше клиент от веб-сервера, тем дольше. Но бывает что нельзя иначе или трудно. Именно поэтому придумали:
- CDN
- Динамическое проксирование (CDN-наоборот). Когда в регионе ставится например nginx, открывающий постоянные коннекты на веб-сервер и терминирующий ssl. Понятно зачем? Именно — в разы ускоряется установление соединений от клиента с веб-прокси (хэндшейки начинают летать), а дальше используется прогретое TCP-соединение.
Что еще можно сделать… увеличить TCP’s initial congestion window — да, это нередко помогает, т.к. веб-страничка отдается одним набором пакетов без подтверждения. Попробуйте.
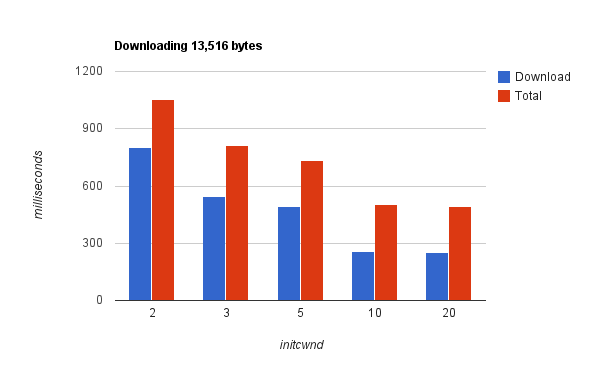
Включите отладчик браузера, посмотрите время загрузки веб-страницы и подумайте о latency и способах ее уменьшения.
Пропускная способность
Помните, что TCP-окошко соединения должно разогнаться сначала. Если веб-страница загружается меньше секунды — окошко может не успеть увеличиться. Средняя пропускная способность сети в мире — немного превышает 3 МБит\с. Вывод — передавайте через одно установленное соединение как можно больше, «разогрев» его.

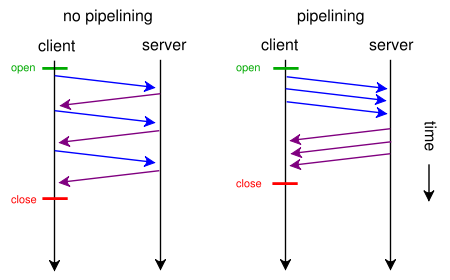
Помочь тут может конечно мультиплексирование HTTP-ресурсов внутри одного TCP-соединения: передача нескольких ресурсов вперемешку как в запросе, так и ответе. И даже эту технику включили в стандарт, но недоописали и в итоге она не взлетела (в chrome ее не так давно вообще убрали). Поэтому тут можно пока попробовать spdy, ждать HTTP 2.0 или использовать таки pipelining — но не из браузера, а из приложения напрямую.
Шардинг доменов
А как же очень популярная техника шардинга доменов — когда браузер/приложение преодолевает ограничение в >=6 соединений на домен, открывая еще по >=6 и более соединений на фиктивные домены: img1.mysite.ru, img2.mysite.ru…? Тут весело, т.к. с точки зрения HTTP/1.1 — это вас вероятнее всего ускорит, а с точки зрения HTTP/2.0 — это антипаттерн, т.к. мультиплексирование HTTP-трафика через TCP-соединение может обеспечить лучшую пропускную способность.
Так что пока — шардим домены и ждем HTTP/2.0 чтобы этого больше не делать. И конечно — лучше измерить конкретно для вашего веб-приложения и сделать обоснованный выбор.
Фронтэнд
Про известные вещи типа скорости рендеринга веб-страницы и размера изображений и JavaScript, порядка загрузки ресурсов и т.п. — писать не интересно. Тема избита и убита. Если кратко и неточно — кэшируйте ресурсы на стороне веб-браузера, но… с головой. Кэшировать 10МБ js-файл и парсить его внутри браузера на каждой веб-странице — понимаем к чему приведет. Включаем отладчик браузера, наливаем кофе и к исходу дня — тренды налицо. Набрасываем план и реализуем. Просто и прозрачно.
Гораздо более острые подводные камни могут скрываться за достаточно новыми и бурно развивающимися сетевыми возможностями веб-браузера. О них и поговорим:
- XMLHttpRequest
- Long Polling
- Server-Sent Events
- Web Sockets
Браузер — как операционная система
Изначально браузер воспринимался как клиентское приложение для отображения HTML-разметки. Но с каждым годом происходило превращение его в центр управления плеядой технологий — в итоге HTTP-сервер и веб-приложение за ним теперь воспринимается лишь как вспомогательный компонентик внутри браузера. Интересный технологический сдвиг акцентов.
Более того, с появлением встроенной в браузер «телестудии» WebRTC и средств сетевого взаимодействия браузера с внешним миром — вопрос обеспечения производительности плавно переместился от серверной инфраструктуры к браузеру. Если эта внутренняя кухня у клиента будет тормозить — про php на веб-сервере или join в БД никто и не вспомнит.
Разберем на запчасти этот непрозрачный монолит.
XMLHttpRequest
Это всем известный AJAX — способность браузера обращаться к внешним ресурсам по HTTP. С появлением CORS — начался совершенный «беспредел». Теперь чтобы определить причину торможения, нужно лазать по всем ресурсам и смотреть логи везде.
Если серьезно, технология несомненно взорвала возможности браузера, превратив его в мощную платформу динамического рендеринга информации. Писать о ней нет смысла, тема многим известна. Однако опишу ограничения:
- опять отсутствие мультиплексирования нескольких «каналов» заставляет неэффективно и не полностью использовать пропускную способность TCP-соединения
- нет адекватной поддержки streaming (открыл соединение и висишь, ждешь), т.е. остается дергать сервер и смотреть что он ответил
Тем не менее, технология очень популярна и сделать ее прозрачной с точки зрения мониторинга скорости — несложно.
Long Polling
Как сделать веб-чат? Да, нужно как-то передавать со стороны сервера в браузер информацию об изменениях. Напрямую через HTTP — нельзя, не умеет. Только: запрос и ответ. Вот в лоб люди и решили: сделать запрос и ждать ответ, секунду, 30 секунд, минуту. Если что нибудь пришло — отдать в ответ и разорвать соединение.
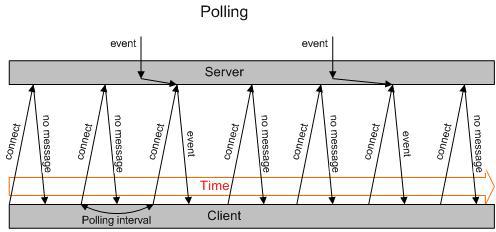
Да, куча антипаттернов, костылей — но технология очень широко распространена и работает всегда. Но, т.к. Вы отвечаете за скорость — знайте, нагрузка на серверы при таком подходе — очень высока, и может сопоставляться с нагрузкой от основной посещаемости веб-проекта. А если обновления от сервера к браузерам распространяются часто — то может основную нагрузку превышать в разы!
Что делать-то?
Server-Sent Events
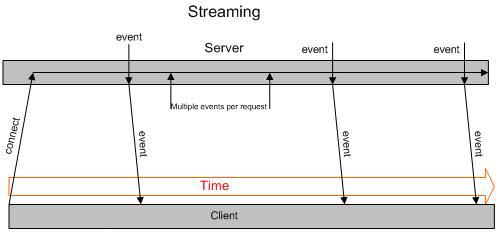
Тут открывается TCP-соединение с веб-сервером, не закрывается и в него сервер пишет разную инфу в UTF-8. Нельзя правда бинарные данные передавать оптимально без предварительного Base64 (+33% увеличение в размере), но как канал управления в одну сторону — превосходное решение. Правда в IE — не поддерживается (см. пункт выше, который везде работает).
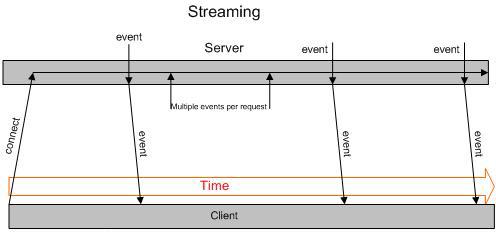

Плюсы технологии в том, что она:
- очень проста
- не нужно после получения сообщения заново переоткрывать соединение с сервером
Web Sockets
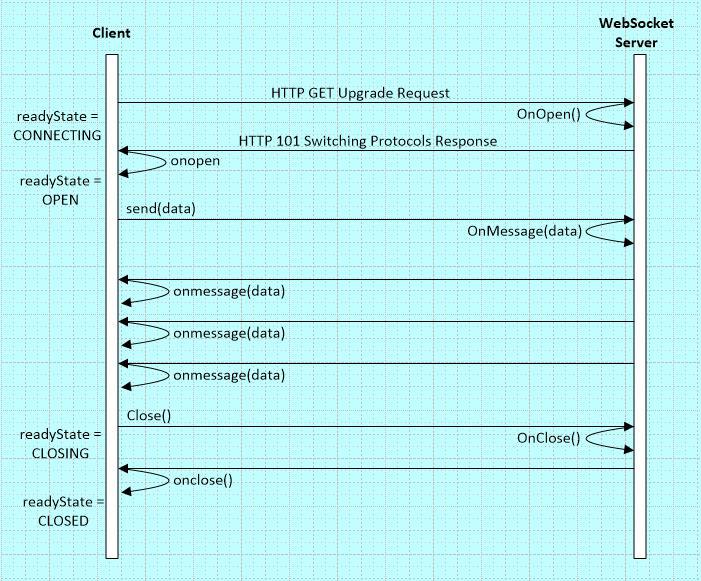
Для системного администратора это даже не зверь, а скорее ночной некроморф. «Хитрым» способом через HTTP 1.1 Upgrade браузер меняет «тип» HTTP соединения и оно остается открытым.
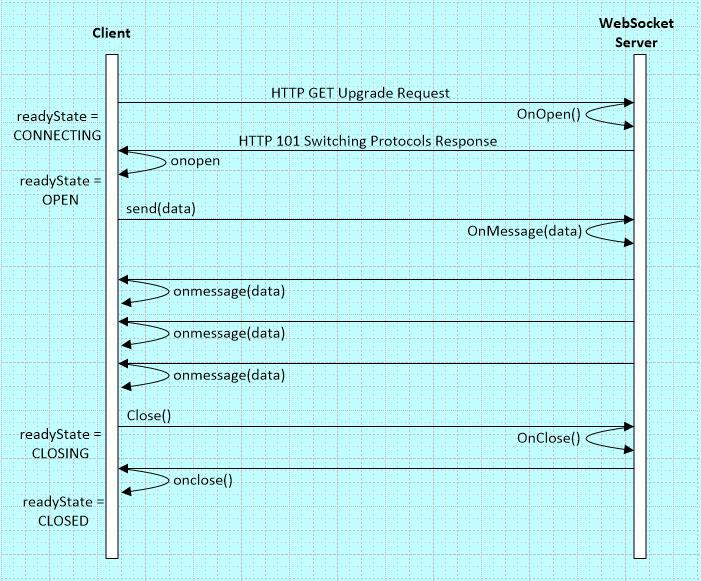
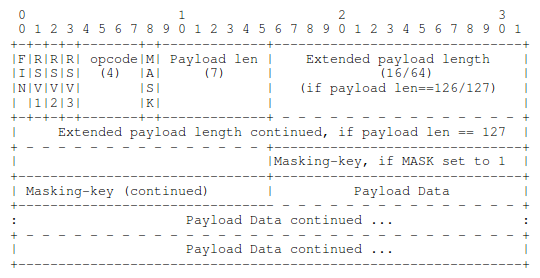
Затем по соединению в ОБЕ (!) стороны можно начать передавать данные, оформленные в сообщения (frames). Сообщения бывают не только с информацией, но и контрольные, в т.ч. типа «PING», «PONG». Первое впечатление — снова изобрели велосипед, снова TCP на базе TCP.
С точки зрения разработчика — конечно это удобно, появляется дуплексный канал между браузером и веб-приложением на сервере. Хочешь streaming, хочешь messages. Но:
- не поддерживается html-кэширование, т.к. работаем через бинарный framing-протокол
- не поддерживается сжатие, его нужно реализовать самостоятельно
- жутки глюки и задержки при работе без TLS — из-за устаревших прокси серверов
- нет мультиплексирования, в результате чего каждое bandwidth каждого соединения используется неэффективно
- на сервере появляется много висящих и делающих что-то «гадкое с базой данных» прямых TCP-соединений от браузеров
Как отслеживать производительность Web Sockets? Очень хороший вопрос, оставленный специально на закуску. Со стороны клиента — сниффер пакетов WireShark, со стороны сервера и с включенным TLS — мы решаем задачу через патчинг модулей для nginx, но видимо есть более простое решение.
Главное понимать, как Web Sockets устроены изнутри, а Вы уже это знаете и контроль за скоростью — будет обеспечен.
Так что же лучше: XMLHttpRequest, Long Polling, Server-Sent Events или Web Sockets? Успех — в грамотном сочетании этих технологий. Например, можно управлять приложением через WebSockets, а загружать ресурсы с использованием встроенного кэширования через AJAX.
Что теперь делать?
Научиться измерять и реагировать на превышение заданных значений. Обрабатывайте логи веб-приложения, разбирайтесь с медленными запросами в них. Скорость на стороне клиента тоже стало возможным мерить благодаря Navigation timing API — мы собираем данные по производительности в браузерах, отправляем их средствами JavaScript в облако, агрегируем в pinba и реагируем на отклонения. Очень полезное API, пользуйтесь обязательно.
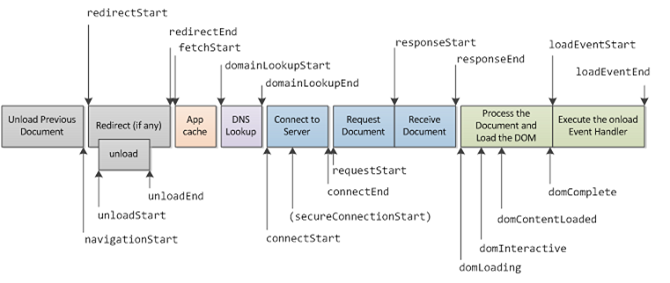
В результате вы найдете себя в окружении системы мониторинга типа nagiоs, с десятком-другим автоматических тестов, на которых видно, что со скоростью работы вашей веб-системы все в порядке. А в случае срабатываний — команда собирается и принимается решение. Кейсы могут быть, например, такими:
- Медленный запрос в БД. Решение — оптимизация запроса, денормализация в случае крайней необходимости.
- Медленная отработка кода приложения. Решение — оптимизация алгоритма, кэширование.
- Медленная передача тела страницы по сети. Решение (в порядке увеличения стоимости) — увеличиваем tcp initial cwnd, ставим динамический прокси рядом с клиентом, переносим серверы поближе
- Медленная отдача статических ресурсов клиентам. Решение — CDN.
- Блокировка в ожидании соединения с серверами в браузере. Решение — шардинг доменов.
- Long Polling создает нагрузку на серверы, большую чем хиты клиентов. Решение — Server-Sent Events, Web Sockets.
- Тормозят, неустойчиво работают Web Sockets. Решение — TLS для них (wss).
и т.д.
Итоги
Мы прошлись по основным компонентам современного веб-приложения. Узнали о трендах HTTP 2.0, контрольных точках, которые важно понимать и научиться измерять для обеспечения скорости ответа веб-приложения по возможности ниже 0.3 сек. Заглянули в суть современных сетевых технологий, использующихся в браузерах, обозначили их достоинства и узкие места.
Поняли, что понимать работу сети, ее скорость, latency и пропускную способность — важно. И что пропускная способность важна далеко не всегда.
Стало понятно, что теперь недостаточно «протюнить» веб-сервер и базу данных. Нужно разбираться в букете сетевых технологий, используемых браузером, знать их изнутри и эффективно измерять.Поэтому сниффер TCP-трафика должен теперь стать вашей правой рукой, а мониторинг ключевых показателей производительности в логах серверов — левой ногой.
Можно попытаться решить задачу обработки запроса клиента за «0.3 сек» по-разному. Главное — определить метрики, автоматически собирать их и действовать в случае их превышения — докапываться к каждом конкретном случае до корня. В нашем продукте мы решили задачу обеспечения максимально низкой latency благодаря комплексной технологии кэширования, объединяющую технологии статического и динамического сайта
В заключение, приглашаем посетить нашу технологическую конференцию, которая пройдет уже скоро, 23 мая. Всем удачи и успехов в нелегком деле обеспечения производительности веб-проектов!
