В сентябре этого года в Киеве прошла конференция, посвящённая большим данным — BigData Conference. По старой традиции, мы публикуем в нашем блоге некоторые материалы, представленные на конференции. И начинаем с доклада Александра Демидова.
Сейчас очень многие интернет-магазины осознали, что одной из главных задач для них является повышение собственной эффективности. Возьмем два магазина, каждый из которых привлек по 10 тыс. посетителей, но один сделал 100 продаж, а другой 200. Вроде бы, аудитория одинаковая, но второй магазин работает в два раза эффективнее.
Тема обработки данных, обработки моделей посетителей магазинов актуальна и важна. Как вообще работают традиционные модели, в которых все связи устанавливаются вручную? Мы составляем соответствие товаров в каталоге, составляем связки с аксессуарами, и так далее. Но, как говорит расхожая шутка:

Невозможно предусмотреть подобную связь и продать покупателю что-то совершенно несвязанное с искомым. Но зато следующей женщине, которая ищет зеленое пальто, мы можем порекомендовать ту самую красную сумку на основании похожей модели поведения предыдущего посетителя.
Такой подход очень ярко иллюстрирует случай, связанный с ритейлинговой сетью Target. Однажды к ним пришел разъяренный посетитель и позвал менеджера. Оказалось, что интернет-магазин в своей рассылке несовершеннолетней дочери этого самого посетителя прислал предложение для беременных. Отец был крайне возмущен этим фактом: «Что вы вытворяете? Она несовершеннолетняя, какая она беременная?». Поругался и ушел. Через пару недель выяснилось, что девушка на самом деле беременна. Причем интернет-магазин узнал об этом раньше ее самой на основе анализа ее предпочтений: заказанные ею товары были сопоставлены с моделями других посетительниц, которые действовали примерно по тем же сценариям.
Результат работы аналитических алгоритмов для многих выглядит как магия. Естественно, многие проекты хотят внедрить у себя подобную аналитику. Но на рынке мало игроков с достаточно большой аудиторией, чтобы можно было действительно что-то посчитать и спрогнозировать. В основном, это поисковики, соцсети, крупные порталы и интернет-магазины.
Когда мы задумались о внедрении анализа больших данных в наши продукты, то задали себе три ключевых вопроса:
Больших интернет-магазинов с миллионными аудиториями вообще очень мало, в том числе и на нашей платформе. Однако общее количество магазинов, использующих «1С-Битрикс: Управление сайтом», очень велико, и все вместе они охватывают внушительную аудиторию в самых разных сегментах рынка.
В итоге мы организовали в рамках проекта внутренний стартап. Поскольку мы не знали, с какого конца браться, решили начать с решения мелкой задачи: как собирать и хранить данные. Этот маленький прототип был нарисован за 30-40 минут:

Существует термин MVP — minimum viable product, продукт с минимальным функционалом. Мы решили начать собирать технические метрики, скорость загрузки страниц у посетителей, и предоставлять пользователям аналитику по скорости работы их проекта. Это еще не имело отношения ни к персонализации, ни к BigData, но позволяло нам научиться обрабатывать всю аудиторию всех посетителей.
В JavaScript существует инструмент под названием Navigation Timing API, который позволяет собирать на стороне клиента данные по скорости страницы, продолжительности DNS resolve, передачи данных по сети, работы на Backend’е, отрисовки страницы. Всё это можно разбивать на самые разные метрики и потом выдавать аналитику.

Мы прикинули, сколько примерно магазинов работает на нашей платформе, сколько данных нам надо будет собирать. Потенциально это десятки тысяч сайтов, десятки миллионов хитов в день, 1000-1500 запросов на запись данных в секунду. Информации очень много, куда ее сохранять, чтобы потом с ней работать? И как обеспечить для пользователя максимальную скорость работы аналитического сервиса? То есть наш JS-счетчик не только обязан очень быстро давать ответ, но и не должен замедлять скорость загрузки страницы.
Наши продукты в основном построены на PHP и MySQL. Первым желанием было просто сохранять всю статистику в MySQL или в любой другой реляционной базе данных. Но даже без тестов и экспериментов мы поняли, что это тупиковый вариант. В какой-то момент нам просто не хватит производительности либо при записи, либо при выборке данных. А любой сбой на стороне этой базы приведет к тому, что, либо сервис будет работать крайне медленно, либо вообще окажется неработоспособен.

Рассмотрели разные NoSQL-решения. Поскольку у нас большая инфраструктура развернута в Amazon, то в первую очередь обратили внимание на DynamoDB. У этого продукта есть некоторое количество преимуществ и недостатков по сравнению с реляционными базами. При записи и масштабировании DynamoDB работает лучше и быстрее, но какие-то сложные выборки делать будет гораздо сложнее. Также есть вопросы с консистентностью данных. Да, она обеспечивается, но, когда вам надо будет постоянно выбирать какие-то данные, не факт, что вы всегда выберете актуальные.
В итоге мы стали использовать DynamoDB для агрегации и последующей выдачи информации пользователям, но не как хранилище для сырых данных.
Рассматривали колоночные базы данных, которые работают уже не со строками, а с колонками. Но из-за низкой производительности при записи пришлось их отвергнуть.
Выбирая походящее решение, мы обсудили самые разные подходы, начиная с записи текстового лога :) и заканчивая сервисами очередей ZeroMQ, Rabbit MQ и т.п. Однако в итоге выбрали совсем другой вариант.
Так совпало, что к тому моменту Amazon разработал сервис Kinesis, который как нельзя лучше подошел для первичного сбора данных. Он представляет собой своеобразный большой высокопроизводительный буфер, куда можно писать всё, что угодно. Он очень быстро принимает данные и рапортует об успешной записи. Затем можно в фоновом режиме спокойно работать с информацией: делать выборки, фильтровать, агрегировать и т.д.
Судя по представленным Amazon данным, Kinesis должен был легко справиться с нашей нагрузкой. Но оставался ряд вопросов. Например, конечный пользователь — посетитель сайта — не мог писать данные напрямую в Kinesis; для работы с сервисом необходимо «подписывать» запросы, используя относительно сложный механизм авторизации в Amazon Web Services v. 4. Поэтому необходимо было решить, как сделать так, чтобы Frontend отправлял данные в Kinesis.
Рассматривали следующие варианты:
В результате мы решили сделать ставку на Lua.
Язык очень гибкий, позволяет обрабатывать и запрос, и ответ. Может встраиваться во все фазы обработки запроса в nginx на уровне рерайта, логирования. На нем можно писать любые подзапросы, причем неблокирующие, с помощью некоторых методов. Существует куча дополнительных модулей для работы с MySQL, с криптующими библиотеками, и так далее.
За два-три дня мы изучили функции Lua, нашли нужные библиотеки и написали прототип.
На первом нагрузочном тесте, конечно же… всё упало. Пришлось настроить Linux под большие нагрузки — оптимизировать сетевой стек. Эта процедура описана во многих документах, но почему-то не делается по умолчанию. Основной проблемой оказалась нехватка портов для исходящих соединений с Kinesis.
Мы расширили диапазон, настроили тайм-ауты. Если вы используете встроенный firewall, типа Iptables, то нужно увеличить для него размер таблиц, иначе они очень быстро переполнятся при таком количестве запросов. Заодно надо скорректировать размеры всяких бэклогов для сетевого интерфейса и для TCP-стека в самой системе.
После этого всё успешно заработало. Система стала исправно обрабатывать 1000 запросов в секунду, и для этого нам хватило одной виртуальной машины.
В какой-то момент мы всё-таки уперлись в потолок и стали получать ошибки “
Решить проблему удалось путем настройки в nginx keepalive-соединений.
Машина с двумя виртуальными ядрами и четырьмя гигабайтами памяти легко обрабатывает 1000 запросов в секунду. Если нам надо больше, то либо добавляем ресурсов этой машине, либо масштабируем горизонтально и ставим за любым балансировщиком 2, 3, 5 таких машин. Решение получается простое и дешевое. Но главное, что мы можем собирать и сохранять любые данные и в любом количестве.

На создание прототипа, собирающего до 70 млн хитов в сутки, ушла примерно неделя. Готовый сервис «Скорость сайтов» для всех клиентов «1С-Битрикс: Управление сайтом» был создан за один месяц усилиями трёх человек. Система не влияет на скорость отображения сайтов, имеет внутреннее администрирование. Стоимость услуг Kinesis — 250 долларов в месяц. Если бы мы делали всё на собственном железе, писали полностью свое решение на любом хранилище, то получилось бы гораздо дороже с точки зрения обслуживания и администрирования. И гораздо менее надежно.

Общую схему системы можно представить следующим образом:

Она должна регистрировать события, сохранять, выполнять какую-то обработку и что-то отдавать клиентам.
Мы создали прототип, теперь надо перейти от технических метрик к оценке бизнес-процессов. По сути, нам неважно, что мы собираем. Можно передавать что угодно:
и так далее.
Хиты можно классифицировать по видам событий. Что нам интересно с точки зрения магазина?
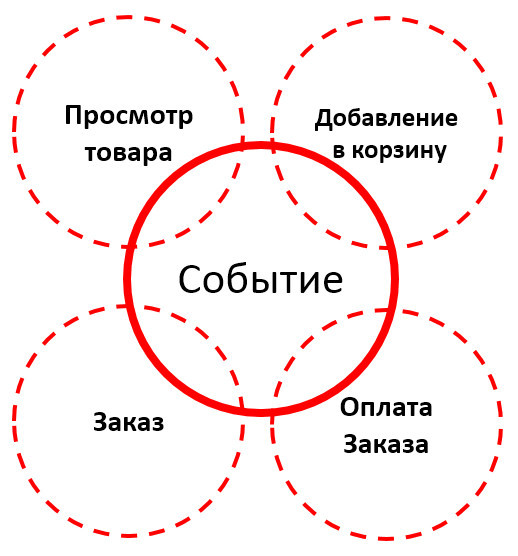
Все технические метрики мы можем собирать и привязывать уже к бизнес-метрикам и последующей аналитике, которая нам потребуется. Но что делать с этим данными, как их обрабатывать?
Пара слов о том, как работают системы рекомендации.
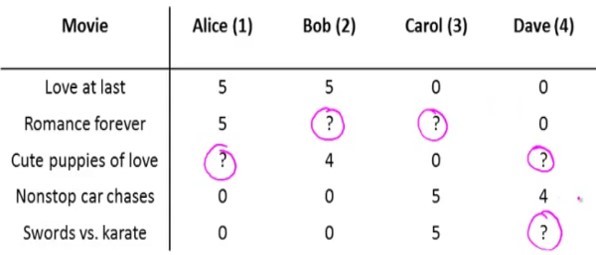
Ключевой механизм, который позволяет рекомендовать посетителям какие-то товары, это механизм коллаборативной фильтрации. Существует несколько алгоритмов. Самый простой — соответствие user-user. Мы сопоставляем профили двух пользователей, и на основании действий первого из них можем прогнозировать для другого пользователя, который выполняет похожие действия, что в следующий момент ему понадобится тот же товар, который заказывал первый пользователь. Это наиболее простая и логически понятная модель. Но она имеет некоторые минусы.
Компания Amazon для своего интернет-магазина придумала другой алгоритм — item-item: соответствия устанавливаются не по пользователям, а по конкретным товарам, в том числе и тем, которые покупают вместе с «основными». Это актуальнее всего для увеличения продаж аксессуаров: купившему телефон человеку можно порекомендовать чехол, зарядку, еще что-то. Эта модель гораздо устойчивее, потому что соответствия товаров меняются редко. Сам алгоритм работает гораздо быстрее.
Есть еще один подход — content based-рекомендации. Анализируются разделы и товары, которыми интересовался пользователь, и его поисковые запросы, после чего выстраивается вектор пользователя. И в качестве подсказок предлагаются те товары, чьи векторы оказываются ближе всего к вектору пользователя.
Можно не выбирать какой-то один алгоритм, а использовать их все, комбинируя друг с другом. Какие есть для этого инструменты:
В своем проекте мы сделали выбор в пользу Spark.
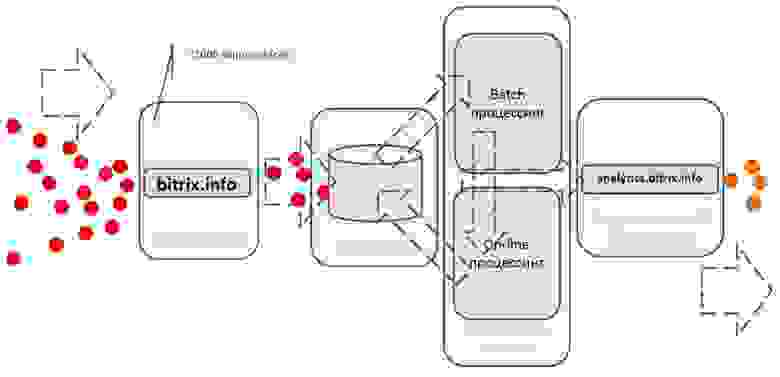
Мы считываем данные из Kinesis с помощью простых воркеров, написанных на PHP. Почему PHP? Просто потому, что он нам привычнее, и нам так удобнее. Хотя у Amazon есть SDK для работы с их сервисами практически для всех популярных языков. Затем делаем первичную фильтрацию хитов: убираем многочисленные хиты поисковых ботов и т.п. Далее отправляем ту статистику, которую можем сразу отдавать в онлайне, в Dynamo DB.

Основной массив данных для последующей обработки, для построения моделей в Spark'е и т.д. мы сохраняем в S3 (вместо традиционного HDFS мы используем хранилище Амазона). Последующей математикой, алгоритмами коллаборативной фильтрации и машинного обучения занимается наш кластер рекомендаций, построенный на базе Apache Mahout.
Использование облачной инфраструктуры и готовых сервисов Amazon AWS экономит нам кучу сил, ресурсов и времени. Нам не нужен большой штат админов для обслуживания этой системы, не нужна многочисленная команда разработчиков. Использование всех вышеперечисленных компонентов позволяет обходиться очень небольшим количеством специалистов.
К тому же вся система получается гораздо дешевле. Все наши терабайты данных выгоднее положить в S3, чем поднять отдельные сервера с дисковыми хранилищами, заботиться о бэкапе и т.д. Гораздо проще и дешевле поднять Kinesis как готовый сервис, начать его использовать буквально в считанные минуты или часы, чем настраивать инфраструктуру, администрировать ее, и решать какие-то низкоуровневые задачи по обслуживанию.
Для разработчика интернет-магазина, который работает на нашей платформе, всё это выглядит как некий сервис. Для работы с этим сервисом используется набор API, с помощью которых можно получить полезную статистику и персональные рекомендации для каждого посетителя.
Мы можем помочь порекомендовать похожие товары, что удобно для продаж аксессуаров и каких-то дополнительных компонентов:
Другой полезный механизм — топ товаров по объему продаж. Вы можете возразить, что всё это можно сделать без возни с большими данными. В самом магазине — да, можно. Но использование нашей статистики позволяет снять немалую долю нагрузки с базы магазина.
Клиент может использовать все эти инструменты в любой комбинации. Облачный сервис персональных рекомендаций максимально полно интегрирован с самой платформой «1С-Битрикс: Управление сайтом», разработчик магазина может очень гибко управлять блоком выдаваемых рекомендаций: «подмешивать» нужные позиции товаров, которые всегда надо показать; использовать сортировку по цене или по каким-то другим критериям и т.п.
При построении модели пользователя учитывается вся статистика его просмотров, а не только текущая сессия. Причем все модели деперсонализированы, то есть каждый посетитель существует в системе только в виде безликого ID. Это позволяет сохранить конфиденциальность.
Мы не делим посетителей в зависимости от магазинов, которые они посещают. У нас единая база данных, и каждому посетителю присваивается единый идентификатор, по каким бы магазинам он ни ходил. В этом одно из главных преимуществ нашего сервиса, потому что маленькие магазины не имеют достаточно большой статистики, позволяющей достоверно прогнозировать поведение пользователей. А благодаря нашей единой базе данных даже магазин с 10 посещениями в день получает возможность с высокой вероятностью успеха порекомендовать товары, которые будут интересны именно этому посетителю.
Данные могут устаревать, так что при построении пользовательской модели мы не будем учитывать статистику годовой давности, например. Учитываются только данные за последний месяц.
Как выглядят на сайте предлагаемые нами инструменты?
Блок персональных рекомендаций, который может быть на главной странице. Он индивидуален для каждого посетителя сайта.

Его можно отображать и в карточке конкретного товара:
Пример блока рекомендуемых товаров:

Блоки можно комбинировать, ища наиболее эффективно сочетание.
Заказы, проданные по персональной рекомендации, отмечаются в админке.

Сотруднику, обрабатывающему заказы, можно в админке сразу выводить список товаров, которые можно порекомендовать покупателю при оформлении.

В отличие от наших инструментов, у сторонних сервисов рекомендаций есть важный недостаток — достаточно маленькая аудитория. Для использования этих сервисов нужно вставить счетчик и виджет для отображения рекомендаций. В то время как наш инструментарий очень тесно интегрирован с платформой, и позволяет дорабатывать выдаваемые посетителям рекомендации. Например, владелец магазина может отсортировать рекомендации по цене или наличию; подмешать в выдачу другие товары.
Возникает главный вопрос: насколько эффективно работает всё вышеописанное? Как вообще измерить эффективность?
Использование A/B тестов для работы с персональными рекомендациями в ближайшем будущем будет доступно владельцам интернет-магазинов, можно будет прямо в админке выбрать и настроить нужные метрики, пособирать данные в течение какого-то времени и оценить разницу, сравнив конверсии разных аудиторий.
По нашим данным, рост конверсии у нас составляет от 10 до 35%. Даже 10% — это огромный показатель для интернет-магазина с точки зрения инвестирования. Вместо того, чтобы вбухивать больше денег в рекламу и привлечение, пользователи эффективнее работают со своей аудиторией.
Но почему такой большой разброс по росту конверсии? Это зависит от:
В каталоге, где мало позиций и мало аксессуаров, рост будет меньше. В магазинах, предлагающих много дополнительных позиций, рост будет выше.
Где еще можно применять подобный инструментарий, помимо интернет-магазинов? Практически в любом интернет-проекте, который хочет увеличить аудиторию. Ведь товарной единицей может быть не только нечто материальное. Товаром может быть статья, любой текстовый материал, цифровой продукт, услуга, что угодно.
По тем же моделям можно оценивать аудиторию и ее готовность к переходу, например, от бесплатных тарифов к платным, и наоборот. Либо можно оценить вероятность ухода пользователей к конкурентам. Это можно предотвратить какой-то дополнительной скидкой, маркетинговой акцией. Или если клиент вот-вот готов купить товар или услугу, то можно сделать какое-то интересное предложение, тем самым повысив лояльность аудитории. Естественно, максимально гибко всё это можно использовать с триггерными ссылками. Например, пользователю, который посмотрел какой-то товар, положил его в корзину, но не разместил заказ, можно сделать персональное предложение.
На данный момент на нашей платформе работает 17 тыс. магазинов, система обсчитывает порядка 440 млн событий в месяц. Общий товарный каталог содержит около 18 млн наименований. Доля заказов по рекомендации от общего количества заказов: 9–37%.
Как видите, данных очень много, и они не лежат мертвым грузом, а работают и приносят пользу. Для работающих на нашей платформе магазинов этот сервис сейчас бесплатен. У нас открытый API, который можно модифицировать на стороне Backend’a и выдавать более гибкие рекомендации конкретным посетителям.
Сейчас очень многие интернет-магазины осознали, что одной из главных задач для них является повышение собственной эффективности. Возьмем два магазина, каждый из которых привлек по 10 тыс. посетителей, но один сделал 100 продаж, а другой 200. Вроде бы, аудитория одинаковая, но второй магазин работает в два раза эффективнее.
Тема обработки данных, обработки моделей посетителей магазинов актуальна и важна. Как вообще работают традиционные модели, в которых все связи устанавливаются вручную? Мы составляем соответствие товаров в каталоге, составляем связки с аксессуарами, и так далее. Но, как говорит расхожая шутка:

Невозможно предусмотреть подобную связь и продать покупателю что-то совершенно несвязанное с искомым. Но зато следующей женщине, которая ищет зеленое пальто, мы можем порекомендовать ту самую красную сумку на основании похожей модели поведения предыдущего посетителя.
Такой подход очень ярко иллюстрирует случай, связанный с ритейлинговой сетью Target. Однажды к ним пришел разъяренный посетитель и позвал менеджера. Оказалось, что интернет-магазин в своей рассылке несовершеннолетней дочери этого самого посетителя прислал предложение для беременных. Отец был крайне возмущен этим фактом: «Что вы вытворяете? Она несовершеннолетняя, какая она беременная?». Поругался и ушел. Через пару недель выяснилось, что девушка на самом деле беременна. Причем интернет-магазин узнал об этом раньше ее самой на основе анализа ее предпочтений: заказанные ею товары были сопоставлены с моделями других посетительниц, которые действовали примерно по тем же сценариям.
Результат работы аналитических алгоритмов для многих выглядит как магия. Естественно, многие проекты хотят внедрить у себя подобную аналитику. Но на рынке мало игроков с достаточно большой аудиторией, чтобы можно было действительно что-то посчитать и спрогнозировать. В основном, это поисковики, соцсети, крупные порталы и интернет-магазины.
Наши первые шаги в использовании больших данных
Когда мы задумались о внедрении анализа больших данных в наши продукты, то задали себе три ключевых вопроса:
- Наберется ли у нас достаточно данных?
- Как мы их будем обрабатывать? У нас нет в штате математиков, мы не обладаем достаточной компетенцией по работе с «большими данными».
- Как это всё внедрять в существующие продукты?
Больших интернет-магазинов с миллионными аудиториями вообще очень мало, в том числе и на нашей платформе. Однако общее количество магазинов, использующих «1С-Битрикс: Управление сайтом», очень велико, и все вместе они охватывают внушительную аудиторию в самых разных сегментах рынка.
В итоге мы организовали в рамках проекта внутренний стартап. Поскольку мы не знали, с какого конца браться, решили начать с решения мелкой задачи: как собирать и хранить данные. Этот маленький прототип был нарисован за 30-40 минут:
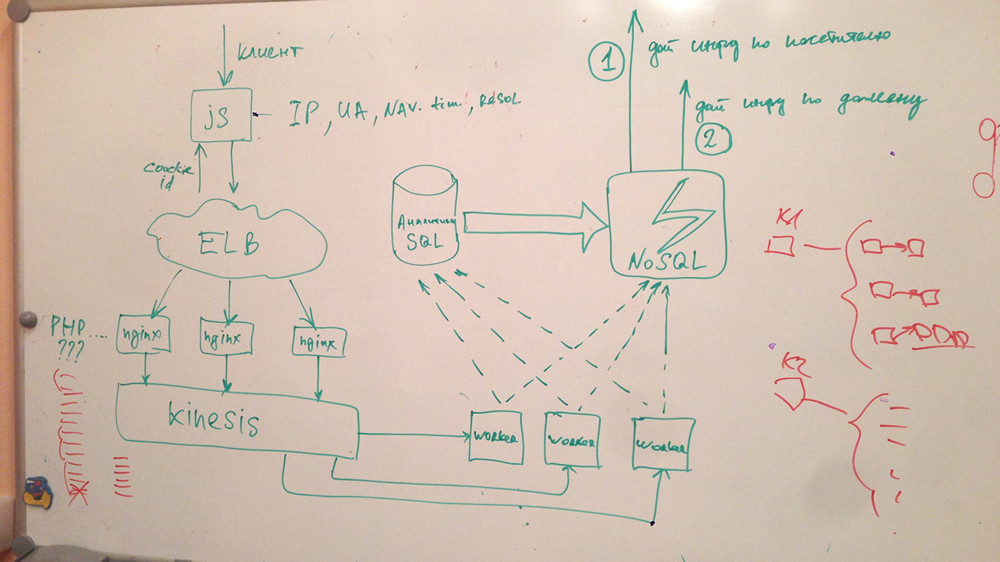
Существует термин MVP — minimum viable product, продукт с минимальным функционалом. Мы решили начать собирать технические метрики, скорость загрузки страниц у посетителей, и предоставлять пользователям аналитику по скорости работы их проекта. Это еще не имело отношения ни к персонализации, ни к BigData, но позволяло нам научиться обрабатывать всю аудиторию всех посетителей.
В JavaScript существует инструмент под названием Navigation Timing API, который позволяет собирать на стороне клиента данные по скорости страницы, продолжительности DNS resolve, передачи данных по сети, работы на Backend’е, отрисовки страницы. Всё это можно разбивать на самые разные метрики и потом выдавать аналитику.

Мы прикинули, сколько примерно магазинов работает на нашей платформе, сколько данных нам надо будет собирать. Потенциально это десятки тысяч сайтов, десятки миллионов хитов в день, 1000-1500 запросов на запись данных в секунду. Информации очень много, куда ее сохранять, чтобы потом с ней работать? И как обеспечить для пользователя максимальную скорость работы аналитического сервиса? То есть наш JS-счетчик не только обязан очень быстро давать ответ, но и не должен замедлять скорость загрузки страницы.
Запись и хранение данных
Наши продукты в основном построены на PHP и MySQL. Первым желанием было просто сохранять всю статистику в MySQL или в любой другой реляционной базе данных. Но даже без тестов и экспериментов мы поняли, что это тупиковый вариант. В какой-то момент нам просто не хватит производительности либо при записи, либо при выборке данных. А любой сбой на стороне этой базы приведет к тому, что, либо сервис будет работать крайне медленно, либо вообще окажется неработоспособен.

Рассмотрели разные NoSQL-решения. Поскольку у нас большая инфраструктура развернута в Amazon, то в первую очередь обратили внимание на DynamoDB. У этого продукта есть некоторое количество преимуществ и недостатков по сравнению с реляционными базами. При записи и масштабировании DynamoDB работает лучше и быстрее, но какие-то сложные выборки делать будет гораздо сложнее. Также есть вопросы с консистентностью данных. Да, она обеспечивается, но, когда вам надо будет постоянно выбирать какие-то данные, не факт, что вы всегда выберете актуальные.
В итоге мы стали использовать DynamoDB для агрегации и последующей выдачи информации пользователям, но не как хранилище для сырых данных.
Рассматривали колоночные базы данных, которые работают уже не со строками, а с колонками. Но из-за низкой производительности при записи пришлось их отвергнуть.
Выбирая походящее решение, мы обсудили самые разные подходы, начиная с записи текстового лога :) и заканчивая сервисами очередей ZeroMQ, Rabbit MQ и т.п. Однако в итоге выбрали совсем другой вариант.
Kinesis
Так совпало, что к тому моменту Amazon разработал сервис Kinesis, который как нельзя лучше подошел для первичного сбора данных. Он представляет собой своеобразный большой высокопроизводительный буфер, куда можно писать всё, что угодно. Он очень быстро принимает данные и рапортует об успешной записи. Затем можно в фоновом режиме спокойно работать с информацией: делать выборки, фильтровать, агрегировать и т.д.
Судя по представленным Amazon данным, Kinesis должен был легко справиться с нашей нагрузкой. Но оставался ряд вопросов. Например, конечный пользователь — посетитель сайта — не мог писать данные напрямую в Kinesis; для работы с сервисом необходимо «подписывать» запросы, используя относительно сложный механизм авторизации в Amazon Web Services v. 4. Поэтому необходимо было решить, как сделать так, чтобы Frontend отправлял данные в Kinesis.
Рассматривали следующие варианты:
- Написать на чистом nginx некую конфигурацию, которая будет проксировать в Kinesis. Не получалось, логика слишком сложная.
- Nginx в виде Frontend + PHP-Backend. Выходило сложно и дорого по ресурсам, потому что при таком количестве запросов любой Backend рано или поздно перестанет справляться, его надо будет горизонтально масштабировать. А мы еще не знаем, взлетит ли проект.
- Nginx + свой модуль на С/С++. Долго и сложно с точки зрения разработки.
- Nginx + ngx_http_perl_module. Вариант с модулем, блокирующим запросы. То есть запрос, который пришел в этом треде блокирует обработку других запросов. Здесь те же недостатки, что и с использованием какого-либо Backend’a. К тому же в документации к nginx было прямо сказано: «Модуль экспериментальный, поэтому возможно все».
- Nginx + ngx_lua. На тот момент мы еще не сталкивались с Lua, но этот модуль показался любопытным. Нужный вам кусок кода, пишется прямо в конфиг nginx на языке, чем-то похожем на JavaScript, либо выносится в отдельный файл. Таким образом можно реализовать самую странную, неординарную логику, которая вам нужна.
В результате мы решили сделать ставку на Lua.
Lua
Язык очень гибкий, позволяет обрабатывать и запрос, и ответ. Может встраиваться во все фазы обработки запроса в nginx на уровне рерайта, логирования. На нем можно писать любые подзапросы, причем неблокирующие, с помощью некоторых методов. Существует куча дополнительных модулей для работы с MySQL, с криптующими библиотеками, и так далее.
За два-три дня мы изучили функции Lua, нашли нужные библиотеки и написали прототип.
На первом нагрузочном тесте, конечно же… всё упало. Пришлось настроить Linux под большие нагрузки — оптимизировать сетевой стек. Эта процедура описана во многих документах, но почему-то не делается по умолчанию. Основной проблемой оказалась нехватка портов для исходящих соединений с Kinesis.
/etc/sysctl.conf (man sysctl)
# диапазон портов исходящих коннектов
net.ipv4.ip_local_port_range=1024 65535
# повторное использование TIME_WAIT сокетов
net.ipv4.tcp_tw_reuse=1
# время пребывания сокета в FIN_WAIT_2
net.ipv4.tcp_fin_timeout=15
# размер таблиц файрволла
net.netfilter.nf_conntrack_max=1048576
# длина очереди входящих пакетов на интерфейсе
net.core.netdev_max_backlog=50000
# количество возможных подключений к сокету
net.core.somaxconn=81920
# не посылать syncookies на SYN запросы
net.ipv4.tcp_syncookies=0
Мы расширили диапазон, настроили тайм-ауты. Если вы используете встроенный firewall, типа Iptables, то нужно увеличить для него размер таблиц, иначе они очень быстро переполнятся при таком количестве запросов. Заодно надо скорректировать размеры всяких бэклогов для сетевого интерфейса и для TCP-стека в самой системе.
После этого всё успешно заработало. Система стала исправно обрабатывать 1000 запросов в секунду, и для этого нам хватило одной виртуальной машины.
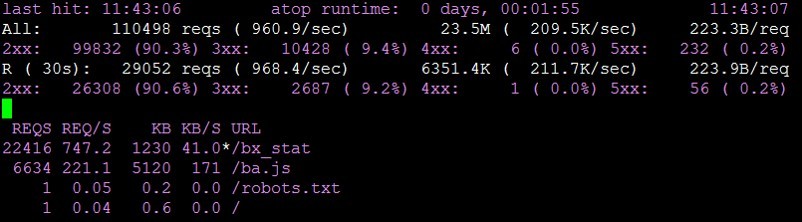
В какой-то момент мы всё-таки уперлись в потолок и стали получать ошибки “
connect() to [...] failed (99: Cannot assign requested address) while connecting to upstream”, хотя ресурсы системы еще не были исчерпаны. По LA нагрузка была близка к нулю, памяти достаточно, процессор далек от перегрузки, но во что-то уперлись. 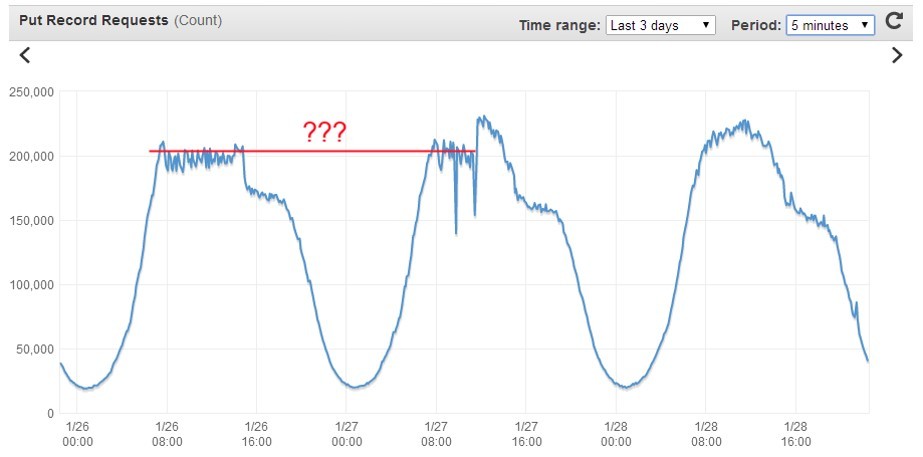
Решить проблему удалось путем настройки в nginx keepalive-соединений.
upstream kinesis {
server kinesis.eu-west-1.amazonaws.com:443;
keepalive 1024;
}
proxy_pass https://kinesis/;
proxy_http_version 1.1;
proxy_set_header Connection "";
Машина с двумя виртуальными ядрами и четырьмя гигабайтами памяти легко обрабатывает 1000 запросов в секунду. Если нам надо больше, то либо добавляем ресурсов этой машине, либо масштабируем горизонтально и ставим за любым балансировщиком 2, 3, 5 таких машин. Решение получается простое и дешевое. Но главное, что мы можем собирать и сохранять любые данные и в любом количестве.
На создание прототипа, собирающего до 70 млн хитов в сутки, ушла примерно неделя. Готовый сервис «Скорость сайтов» для всех клиентов «1С-Битрикс: Управление сайтом» был создан за один месяц усилиями трёх человек. Система не влияет на скорость отображения сайтов, имеет внутреннее администрирование. Стоимость услуг Kinesis — 250 долларов в месяц. Если бы мы делали всё на собственном железе, писали полностью свое решение на любом хранилище, то получилось бы гораздо дороже с точки зрения обслуживания и администрирования. И гораздо менее надежно.

Рекомендации и персонализации
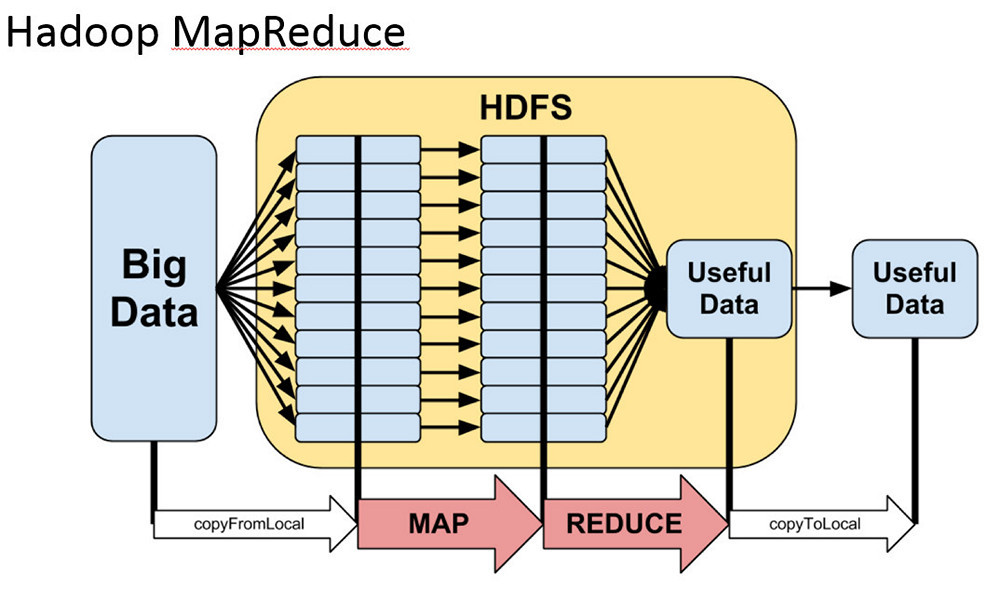
Общую схему системы можно представить следующим образом:
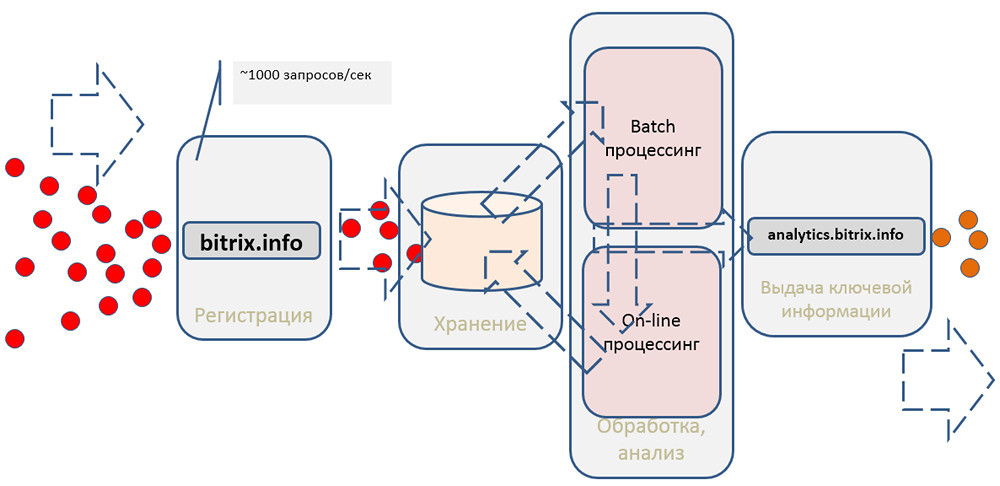
Она должна регистрировать события, сохранять, выполнять какую-то обработку и что-то отдавать клиентам.
Мы создали прототип, теперь надо перейти от технических метрик к оценке бизнес-процессов. По сути, нам неважно, что мы собираем. Можно передавать что угодно:
- Куки
- Хэш-лицензии
- Домен
- Категорию, ID и название товара
- ID рекомендации
и так далее.
Хиты можно классифицировать по видам событий. Что нам интересно с точки зрения магазина?
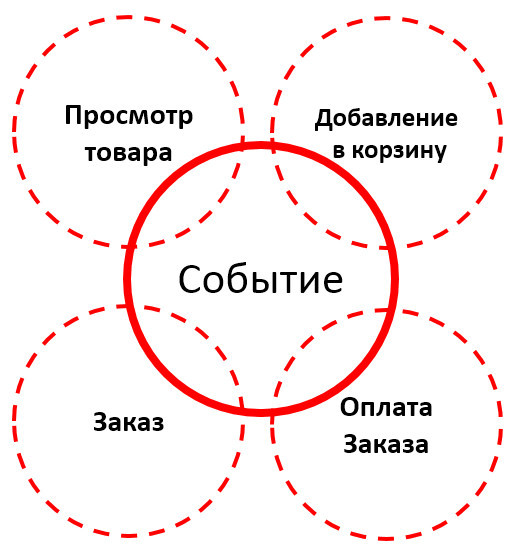
Все технические метрики мы можем собирать и привязывать уже к бизнес-метрикам и последующей аналитике, которая нам потребуется. Но что делать с этим данными, как их обрабатывать?
Пара слов о том, как работают системы рекомендации.
Ключевой механизм, который позволяет рекомендовать посетителям какие-то товары, это механизм коллаборативной фильтрации. Существует несколько алгоритмов. Самый простой — соответствие user-user. Мы сопоставляем профили двух пользователей, и на основании действий первого из них можем прогнозировать для другого пользователя, который выполняет похожие действия, что в следующий момент ему понадобится тот же товар, который заказывал первый пользователь. Это наиболее простая и логически понятная модель. Но она имеет некоторые минусы.
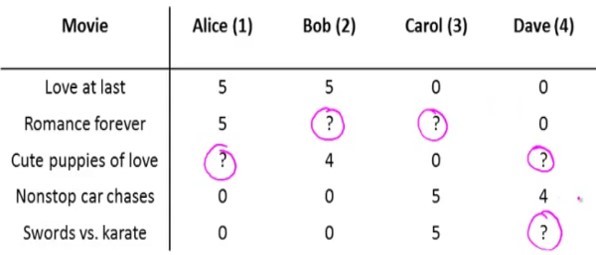
- Во-первых, очень мало пользователей с одинаковыми профилями.
- Во-вторых, модель не очень устойчивая. Пользователи смотрят самые разные товары, матрицы соответствий постоянно меняются.
- Если мы охватываем всю аудиторию наших интернет-магазинов, то это десятки миллионов посетителей. И чтобы найти соответствия по всем пользователям, нам нужно перемножить эту матрицу саму на себя. А перемножение таких миллионных матриц — это нетривиальная задача с точки зрения алгоритмов и инструментов, которые мы будем использовать.
Компания Amazon для своего интернет-магазина придумала другой алгоритм — item-item: соответствия устанавливаются не по пользователям, а по конкретным товарам, в том числе и тем, которые покупают вместе с «основными». Это актуальнее всего для увеличения продаж аксессуаров: купившему телефон человеку можно порекомендовать чехол, зарядку, еще что-то. Эта модель гораздо устойчивее, потому что соответствия товаров меняются редко. Сам алгоритм работает гораздо быстрее.
Есть еще один подход — content based-рекомендации. Анализируются разделы и товары, которыми интересовался пользователь, и его поисковые запросы, после чего выстраивается вектор пользователя. И в качестве подсказок предлагаются те товары, чьи векторы оказываются ближе всего к вектору пользователя.

Можно не выбирать какой-то один алгоритм, а использовать их все, комбинируя друг с другом. Какие есть для этого инструменты:
- • MapReduce. Если до конца в нем разобраться, то использование не вызовет затруднений. Но если вы будете «плавать» в теории, то сложности гарантированы.


- • Spark. Работает гораздо быстрее по сравнению с традиционным MapReduce, потому что все структуры хранит в памяти, и может использовать их повторно. Также он гораздо гибче, в нем удобнее делать сложные выборки и агрегации.
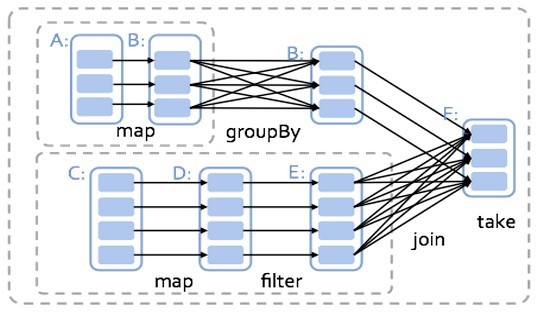
Если вы программируете на Java, то работа со Spark не вызовет особых затруднений. Здесь используется реляционная алгебра, распределенные коллекции, цепочки обработки.


В своем проекте мы сделали выбор в пользу Spark.
Архитектура нашего проекта
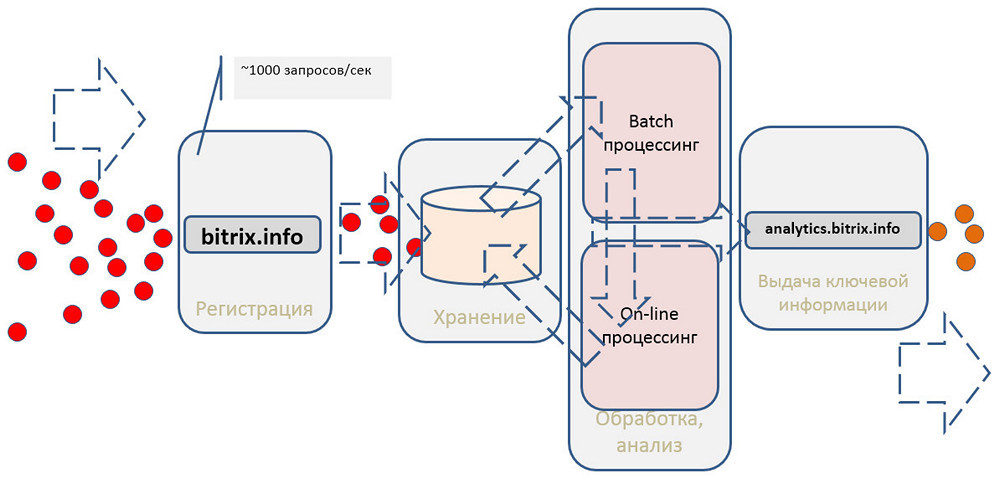
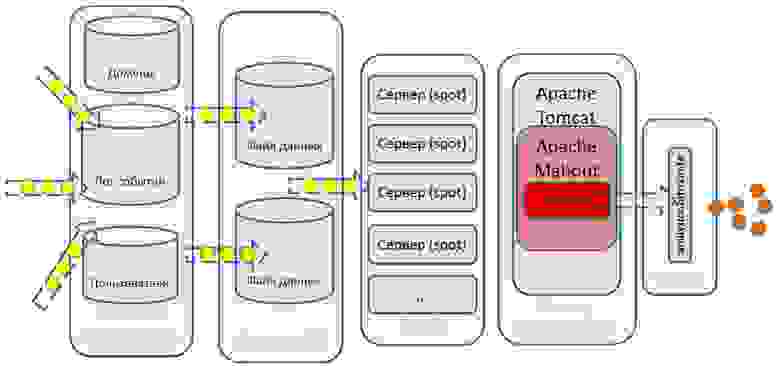
Мы считываем данные из Kinesis с помощью простых воркеров, написанных на PHP. Почему PHP? Просто потому, что он нам привычнее, и нам так удобнее. Хотя у Amazon есть SDK для работы с их сервисами практически для всех популярных языков. Затем делаем первичную фильтрацию хитов: убираем многочисленные хиты поисковых ботов и т.п. Далее отправляем ту статистику, которую можем сразу отдавать в онлайне, в Dynamo DB.
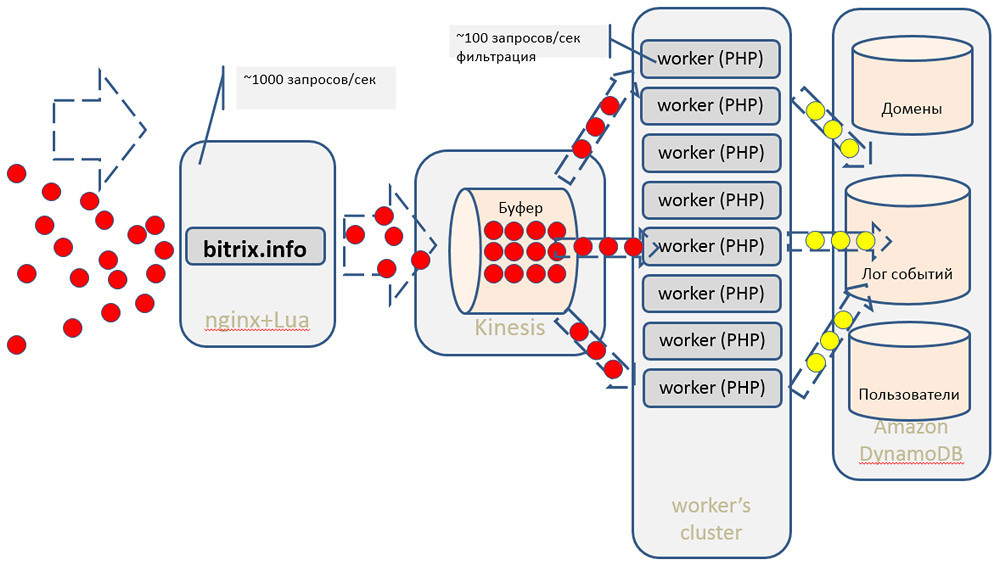
Основной массив данных для последующей обработки, для построения моделей в Spark'е и т.д. мы сохраняем в S3 (вместо традиционного HDFS мы используем хранилище Амазона). Последующей математикой, алгоритмами коллаборативной фильтрации и машинного обучения занимается наш кластер рекомендаций, построенный на базе Apache Mahout.
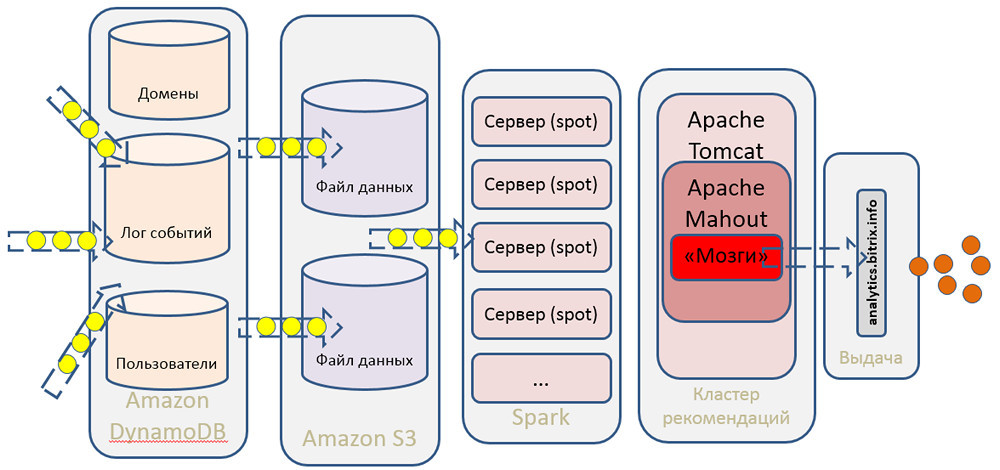
- Для обработки данных мы используем Apache Hadoop/MapReduce, Apache Spark, Dynamo DB (NoSQL).
- Для математических расчетов задействуется Apache Mahout, а масштабная обработка умножения матриц делается с использованием парадигмы MapReduce.
- Данные обрабатываются на динамических вычислительных кластерах в облаке Amazon.
- Хранение осуществляется в объектном Amazon S3 и частично — в NoSQL DynamoDB.
Использование облачной инфраструктуры и готовых сервисов Amazon AWS экономит нам кучу сил, ресурсов и времени. Нам не нужен большой штат админов для обслуживания этой системы, не нужна многочисленная команда разработчиков. Использование всех вышеперечисленных компонентов позволяет обходиться очень небольшим количеством специалистов.
К тому же вся система получается гораздо дешевле. Все наши терабайты данных выгоднее положить в S3, чем поднять отдельные сервера с дисковыми хранилищами, заботиться о бэкапе и т.д. Гораздо проще и дешевле поднять Kinesis как готовый сервис, начать его использовать буквально в считанные минуты или часы, чем настраивать инфраструктуру, администрировать ее, и решать какие-то низкоуровневые задачи по обслуживанию.
Для разработчика интернет-магазина, который работает на нашей платформе, всё это выглядит как некий сервис. Для работы с этим сервисом используется набор API, с помощью которых можно получить полезную статистику и персональные рекомендации для каждого посетителя.
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=recommend&uid=#кука#&count=3&aid=#хэш_лицензии#- uid — кука пользователя.
- aid — хэш лицензии.
- сount — число рекомендаций.
{
"id":"24aace52dc0284950bcff7b7f1b7a7f0de66aca9",
"items":["1651384","1652041","1651556"]
}
Мы можем помочь порекомендовать похожие товары, что удобно для продаж аксессуаров и каких-то дополнительных компонентов:
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=simitems&aid=#хэш_лицензии#&eid=#id_товара#&count=3&type=combined&uid=#кука#- uid – кука пользователя.
- aid – хэш лицензии.
- eid – ID товара
- type — view|order|combined
- сount – размер выдачи.
Другой полезный механизм — топ товаров по объему продаж. Вы можете возразить, что всё это можно сделать без возни с большими данными. В самом магазине — да, можно. Но использование нашей статистики позволяет снять немалую долю нагрузки с базы магазина.
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=sim_domain_items&aid=#хэш_лицензии#&domain=#домен#&count=50&type=combined&uid=#кука#- uid – кука пользователя.
- aid – хэш лицензии.
- domain – домен сайта.
- type — view|order|combined
- сount – размер выдачи.
Клиент может использовать все эти инструменты в любой комбинации. Облачный сервис персональных рекомендаций максимально полно интегрирован с самой платформой «1С-Битрикс: Управление сайтом», разработчик магазина может очень гибко управлять блоком выдаваемых рекомендаций: «подмешивать» нужные позиции товаров, которые всегда надо показать; использовать сортировку по цене или по каким-то другим критериям и т.п.
При построении модели пользователя учитывается вся статистика его просмотров, а не только текущая сессия. Причем все модели деперсонализированы, то есть каждый посетитель существует в системе только в виде безликого ID. Это позволяет сохранить конфиденциальность.
Мы не делим посетителей в зависимости от магазинов, которые они посещают. У нас единая база данных, и каждому посетителю присваивается единый идентификатор, по каким бы магазинам он ни ходил. В этом одно из главных преимуществ нашего сервиса, потому что маленькие магазины не имеют достаточно большой статистики, позволяющей достоверно прогнозировать поведение пользователей. А благодаря нашей единой базе данных даже магазин с 10 посещениями в день получает возможность с высокой вероятностью успеха порекомендовать товары, которые будут интересны именно этому посетителю.
Данные могут устаревать, так что при построении пользовательской модели мы не будем учитывать статистику годовой давности, например. Учитываются только данные за последний месяц.
Практические примеры
Как выглядят на сайте предлагаемые нами инструменты?
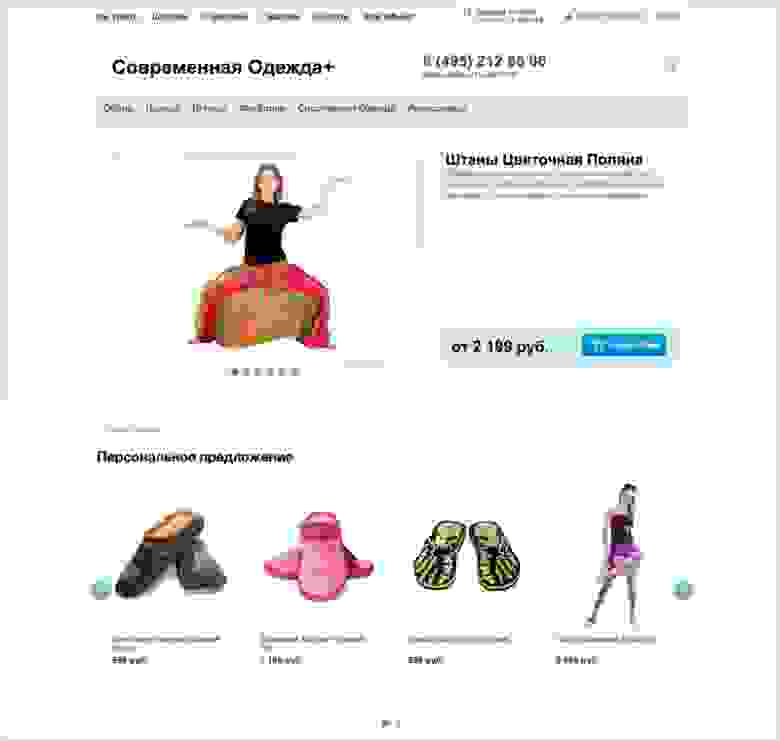
Блок персональных рекомендаций, который может быть на главной странице. Он индивидуален для каждого посетителя сайта.
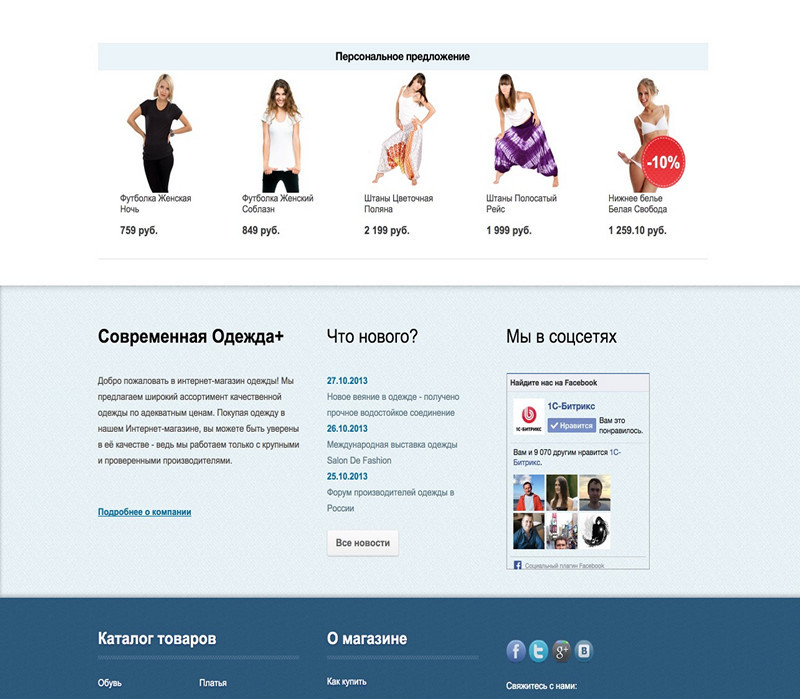
Его можно отображать и в карточке конкретного товара:
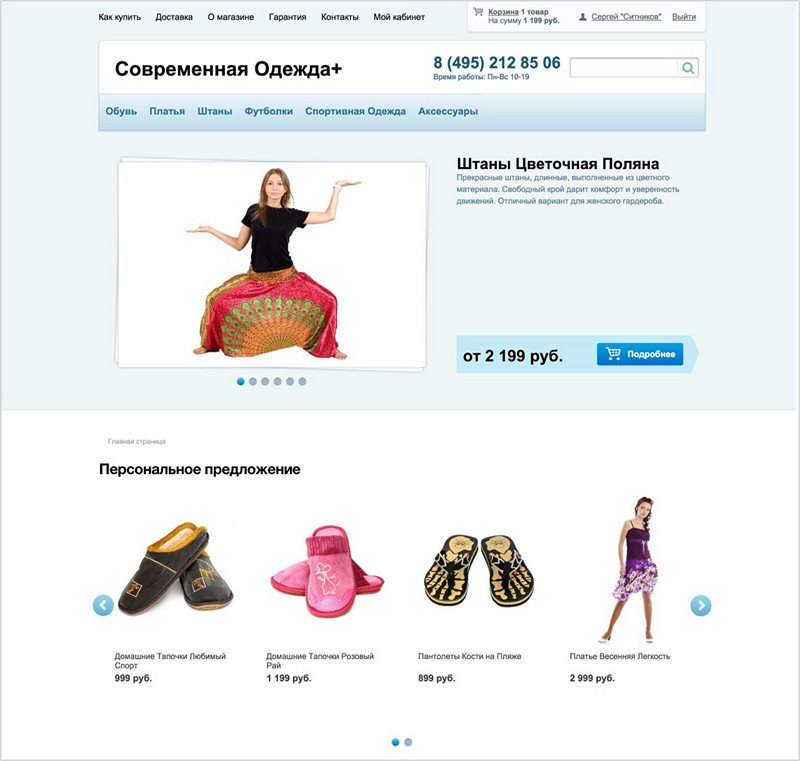
Пример блока рекомендуемых товаров:
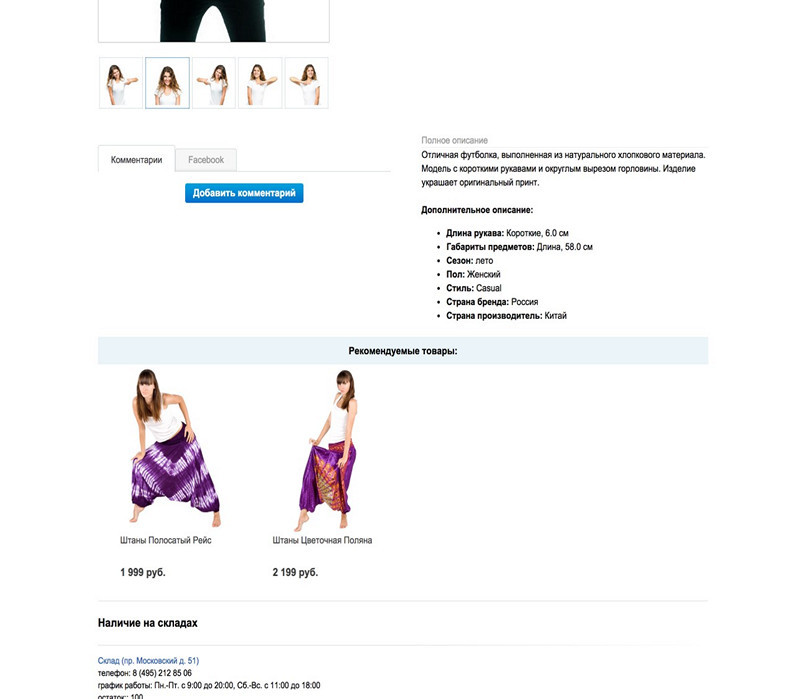
Блоки можно комбинировать, ища наиболее эффективно сочетание.
Заказы, проданные по персональной рекомендации, отмечаются в админке.
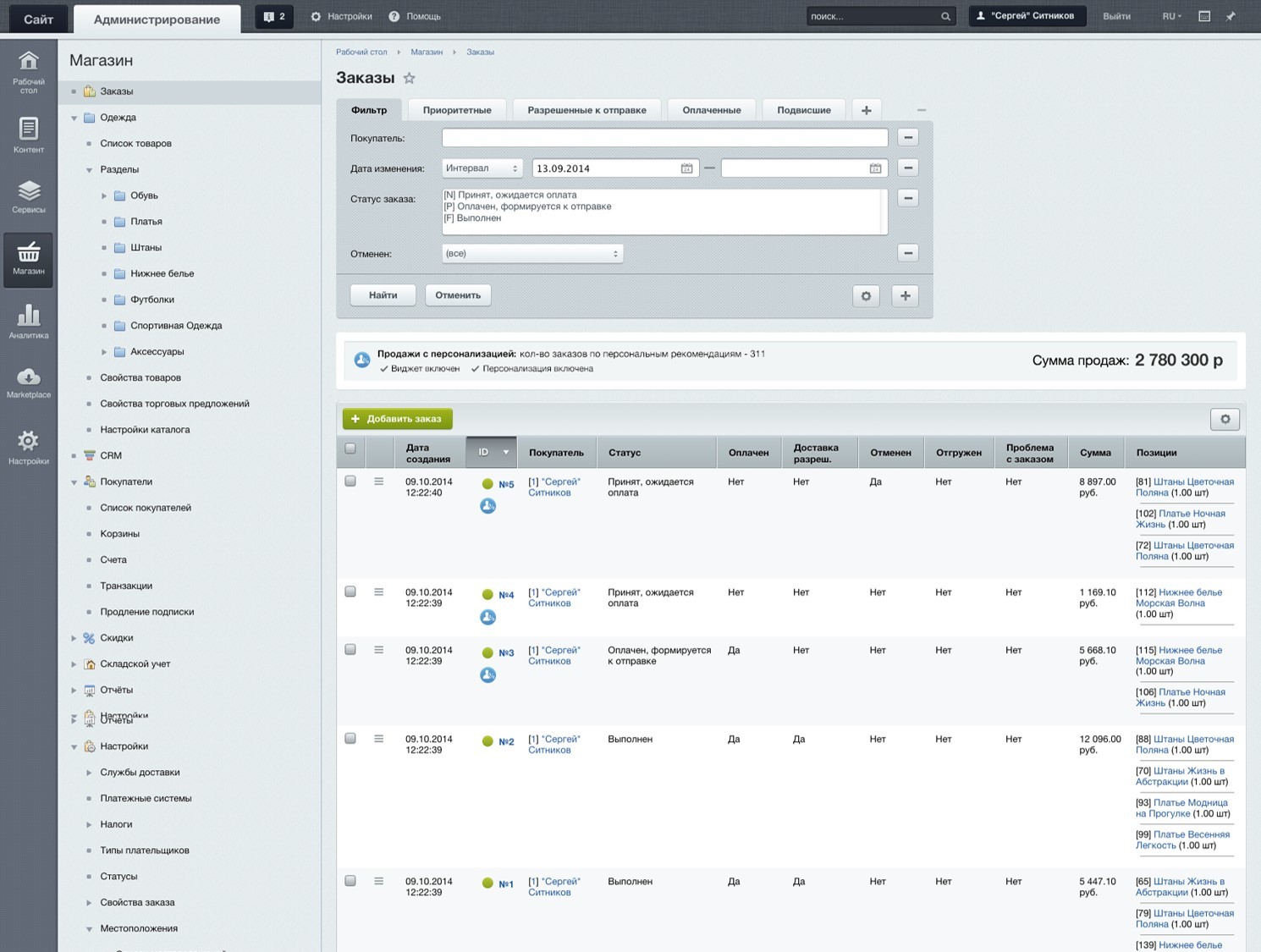
Сотруднику, обрабатывающему заказы, можно в админке сразу выводить список товаров, которые можно порекомендовать покупателю при оформлении.
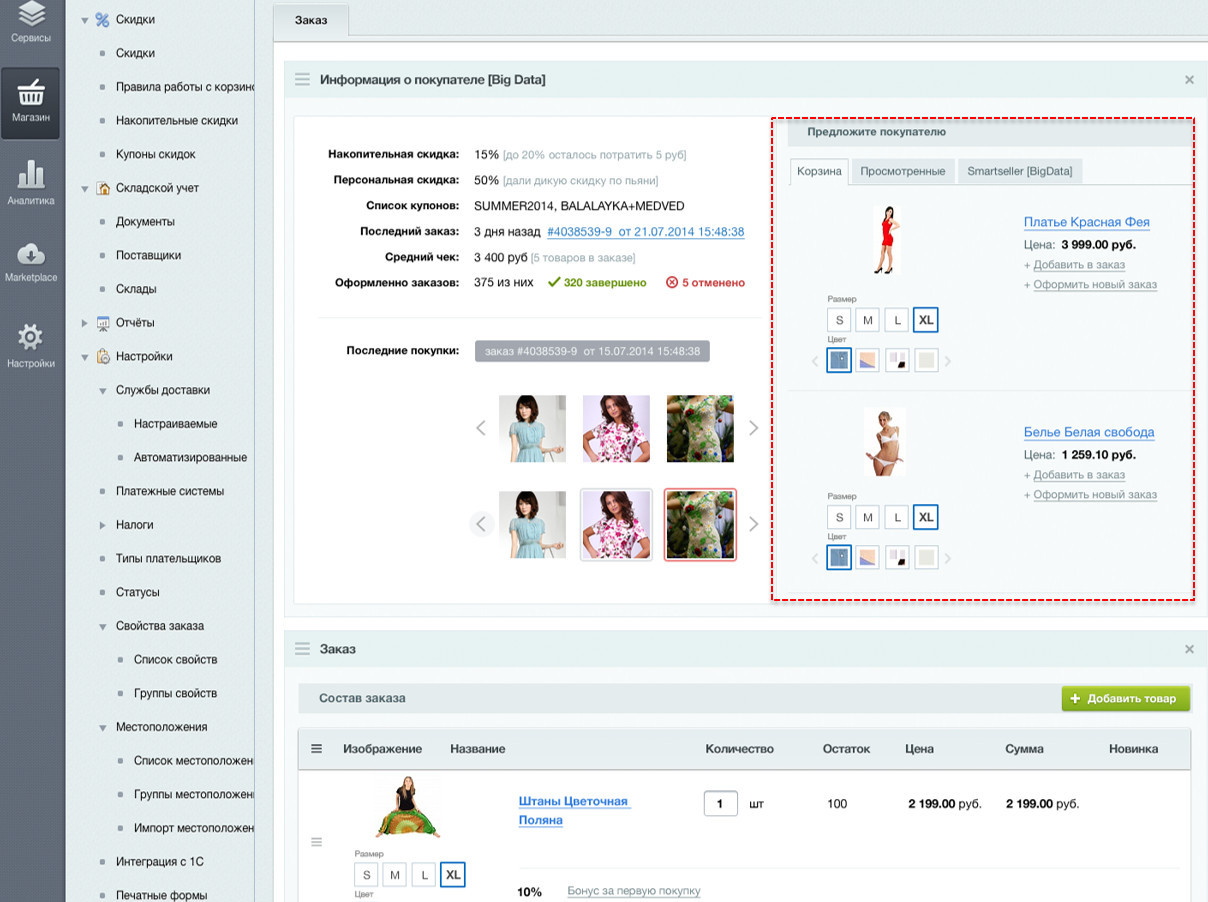
В отличие от наших инструментов, у сторонних сервисов рекомендаций есть важный недостаток — достаточно маленькая аудитория. Для использования этих сервисов нужно вставить счетчик и виджет для отображения рекомендаций. В то время как наш инструментарий очень тесно интегрирован с платформой, и позволяет дорабатывать выдаваемые посетителям рекомендации. Например, владелец магазина может отсортировать рекомендации по цене или наличию; подмешать в выдачу другие товары.
Метрики качества
Возникает главный вопрос: насколько эффективно работает всё вышеописанное? Как вообще измерить эффективность?
- Мы вычисляем отношение просмотров по рекомендациям к общему количеству просмотров.
- Также измеряем количество заказов, сделанных по рекомендации, и общее количество заказов.
- Проводим измерения по state-машинам пользователей. У нас есть матрица с моделями поведения за период в три недели, мы даем по ним какие-то рекомендации. Затем оцениваем состояние, например, через неделю, и сравниваем размещенные заказы с теми рекомендациями, которые мы могли бы дать в будущем. Если они совпадают, то мы рекомендуем правильно. Если не совпадают, надо подкручивать или совсем менять алгоритмы.
- А/В тесты. Можно просто разделить посетителей интернет-магазина на группы: одной показать товары без персональных рекомендаций, другой — с рекомендациями, и оценить разницу в продажах.
Использование A/B тестов для работы с персональными рекомендациями в ближайшем будущем будет доступно владельцам интернет-магазинов, можно будет прямо в админке выбрать и настроить нужные метрики, пособирать данные в течение какого-то времени и оценить разницу, сравнив конверсии разных аудиторий.
По нашим данным, рост конверсии у нас составляет от 10 до 35%. Даже 10% — это огромный показатель для интернет-магазина с точки зрения инвестирования. Вместо того, чтобы вбухивать больше денег в рекламу и привлечение, пользователи эффективнее работают со своей аудиторией.
Но почему такой большой разброс по росту конверсии? Это зависит от:
- разнообразия ассортимента,
- тематики,
- общего количества товаров на сайте,
- специфики аудитории,
- связок товаров.
В каталоге, где мало позиций и мало аксессуаров, рост будет меньше. В магазинах, предлагающих много дополнительных позиций, рост будет выше.
Другие сферы применения
Где еще можно применять подобный инструментарий, помимо интернет-магазинов? Практически в любом интернет-проекте, который хочет увеличить аудиторию. Ведь товарной единицей может быть не только нечто материальное. Товаром может быть статья, любой текстовый материал, цифровой продукт, услуга, что угодно.
- Мобильные операторы, сервис-провайдеры: выявление клиентов, готовых уйти.
- Банковский сектор: продажа допуслуг.
- Контентные проекты.
- CRM.
- Триггерные рассылки.
По тем же моделям можно оценивать аудиторию и ее готовность к переходу, например, от бесплатных тарифов к платным, и наоборот. Либо можно оценить вероятность ухода пользователей к конкурентам. Это можно предотвратить какой-то дополнительной скидкой, маркетинговой акцией. Или если клиент вот-вот готов купить товар или услугу, то можно сделать какое-то интересное предложение, тем самым повысив лояльность аудитории. Естественно, максимально гибко всё это можно использовать с триггерными ссылками. Например, пользователю, который посмотрел какой-то товар, положил его в корзину, но не разместил заказ, можно сделать персональное предложение.
Статистика проекта BigData: Персонализация
На данный момент на нашей платформе работает 17 тыс. магазинов, система обсчитывает порядка 440 млн событий в месяц. Общий товарный каталог содержит около 18 млн наименований. Доля заказов по рекомендации от общего количества заказов: 9–37%.
Как видите, данных очень много, и они не лежат мертвым грузом, а работают и приносят пользу. Для работающих на нашей платформе магазинов этот сервис сейчас бесплатен. У нас открытый API, который можно модифицировать на стороне Backend’a и выдавать более гибкие рекомендации конкретным посетителям.
