
Представьте, что ваш дата-центр (или боевой сервер) сегодня упал. Просто взял и упал. Как показывает практика, готовы к этому далеко не все:
В предыдущих постах (раз и два) я писал про организационные меры, которые ускорят и облегчат восстановление ИТ-систем и связанных с ними процессов компании при чрезвычайной ситуации.

Сейчас поговорим про технические решения, которые в этом помогут. Их стоимость разнится от нескольких тысяч до сотен тысяч долларов.
Очень часто решения для высокой доступности (HA – High Availability) и аварийного восстановления (DR – Disaster Recovery) путают. Прежде всего, когда мы говорим о непрерывности бизнеса, мы имеем в виду резервную площадку. Применительно к ИТ – резервный ЦОД. Непрерывность бизнеса — это не про резервное копирование на библиотеку в соседней стойке (что тоже очень важно). Это про то, что основное здание компании сгорит, и мы через несколько часов или дней сможем возобновить работу, развернувшись на новом месте:
Значит, нужен резервный ЦОД. Какие есть варианты? Обычно выделяют три: горячий, теплый и холодный резервы.
Холодный резерв подразумевает, что есть некое серверное помещение, в которое можно завезти оборудование и развернуть его там. При восстановлении может планироваться закупка «железа», либо его хранение на складе. Нужно учитывать, что большинство систем поставляется под заказ, и быстро найти десятки единиц серверов, СХД, коммутаторов и проч. будет нетривиальной задачей. Как альтернативу складированию оборудования у себя, можно предусмотреть хранение наиболее важного или наиболее редкого оборудования на складе ваших поставщиков. При этом, телекоммуникационные каналы в помещении должны присутствовать, но заключение контракта с провайдером обычно происходит после принятия решения о запуске «холодного» ЦОДа. Восстановление работы в таком ЦОДе при катастрофическом сбое основной площадки вполне может занимать несколько недель. Убедитесь, что ваша компания сможет просуществовать эти несколько недель без ИТ и не лишиться бизнеса (по причине отзыва лицензии, либо невосполнимого кассового разрыва, например) – об этом я писал ранее. Честно говоря, я бы никому не рекомендовал этот вариант резервирования. Возможно, я преувеличиваю роль ИТ в бизнесе некоторых компаний.
Это значит, что у нас функционирует альтернативная площадка, в которой есть активные интернет и WAN-каналы, базовая телекоммуникационная и вычислительная инфраструктура. Она всегда «слабее» основной по вычислительным мощностям, некоторое оборудование там может отсутствовать. Самое важное – чтобы на площадке всегда была актуальная резервная копия данных. Действуя «по старинке» можно организовать регулярное перемещение туда резервных копий на лентах. Современный метод – репликация бэкапов по сети из основного ЦОДа. Использование бэкапа с дедупликацией позволит оперативно передавать резервные копии даже по «тонкому» каналу между ЦОДами.
Вот он, выбор крутых парней, поддерживающих ИТ-системы, простой которых даже на несколько часов приносит компании огромные убытки. Здесь имеется все необходимое оборудование для полноценной работы ИТ-систем. Обычно фундаментом такой площадки служит система хранения данных, на которую синхронно или асинхронно зеркалируются данные из основного ЦОДа. Для того, чтобы горячий резерв в час Икс смог отработать вложенные в него деньги, должны проводиться регулярные тестовые переводы систем, настройки и версия ОС серверов на основной и резервной площадке должны постоянно синхронизироваться – вручную либо автоматически.
Минус горячего и теплого резерва – дорогостоящее оборудование простаивает в ожидании катастрофы. Выходом из этой ситуации является стратегия распределенного ЦОДа. При таком варианте две (или более) площадки равноправны – большинство приложений могут работать как на одной, так и на другой. Это позволяет задействовать мощности всего оборудования и обеспечить балансировку нагрузки. С другой стороны, серьезно повышаются требования к автоматизации перевода ИТ-сервисов между ЦОДами. Если оба ЦОДа «боевые», бизнес вправе ожидать, что при ожидаемом пике нагрузки на одно из приложений, его можно быстро перевести в более свободный ЦОД. Чаще всего, в подобных ЦОДах присутствует синхронная репликация между СХД, но возможна и небольшая асинхронность (в пределах нескольких минут).
Перед тем, как перейти непосредственно к технологиям катастрофоустойчивости ИТ-сервисов, напомню три «волшебных» слова, которые определяют стоимость любого DR-решения: RTO, RPO, RCO.
Первое деление, которое мы можем провести между всем многообразием ИТ-решений для обеспечения катастрофоустойчивости – обеспечивают ли они нулевое RPO или нет. Отсутствие потери данных при сбое обеспечивается синхронной репликацией. Чаще всего, это делается на уровне СХД, но возможно реализовать и на уровне СУБД или сервера (при помощи продвинутого LVM). В первом случае сервер не получает от СХД, с которой он работает, подтверждения об успешности записи, пока СХД не передала эту транзакцию второй системе и не получила от нее подтверждение, что запись прошла успешно.
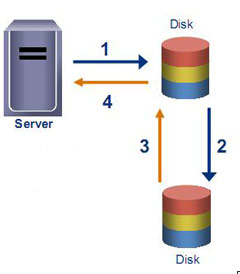
Синхронную репликацию умеют делать 100% СХД, относящихся к среднему ценовому сегменту и некоторые системы начального уровня от известных вендоров. Стоимость лицензий для синхронной репликации на «простых» СХД начинается от нескольких тысяч долларов. Примерно столько же стоит софт для репликации на уровне серверов на 2-3 сервера. Если у вас нет действующего резервного ЦОДа, не забудьте добавить стоимость закупки резервного оборудования.
RPO в несколько минут может обеспечить асинронная репликация на уровне СХД, ПО управления томами сервера (LVM – Logical volume manager), либо СУБД. До сих пор standby-копия базы данных остается одним из наиболее популярных решений для DR. Чаще всего функционал “log shipping”, как это называется у администраторов СУБД, не лицензируется производителем отдельно. Если у вас пролицензирована БД – реплицируйте на здоровье. Стоимость асинхронной репликации для серверов и СХД не отличается от синхронной, см. предыдущий пункт.
Если мы говорим об RPO в несколько часов, чаще это репликация резервных копий с одной площадки на другую. Большинство дисковых библиотек умеют делать это, часть ПО для резервного копирования – тоже. Как я уже говорил, при таком варианте здорово поможет дедупликация. Вы не только будете меньше загружать канал передачей резервных копий, но и сделаете это намного быстрее — каждый передаваемый бэкап будет занимать в десятки или сотни раз меньше времени, чем в реальности. С другой стороны, надо помнить, что первый бэкап при дедупликации все равно должен передать в систему массу уникальных данных. «Настоящую» дедупликацию вы увидите после недельного цикла резервного копирования. При синхронизации дисковых библиотек — то же самое. Если расчетное время передачи при вашей ширине канала между ЦОД составляет несколько дней и даже недель (что может и стоить немало), есть смысл сначала поставить вторую библиотеку рядом, выполнить синхронизацию и увезти ее в резервный ЦОД.

Синхронизация резервных копий между ЦОД
Когда стоит задача минимизации времени восстановления (RTO), процесс должен быть максимально документирован и автоматизирован. Одно из лучших и наиболее универсальных решений – HA-кластеры с территориально разнесенными узлами. Чаще всего, такие решения строятся на базе репликации СХД, но возможны и другие варианты. Лидирующие продукты в этой области, например, Symantec Veritas Cluster, имеют в своем составе модули по работе с СХД, переключающие направление репликации, когда необходимо перезапустить сервис на резервном узле. Для менее продвинутых кластеров (например Microsoft Cluster Services, встроенный в Windows) основные производители СХД (IBM, EMC, HP) предлагают надстройки, делая из обычного HA-кластера катастрофоустойчивый.
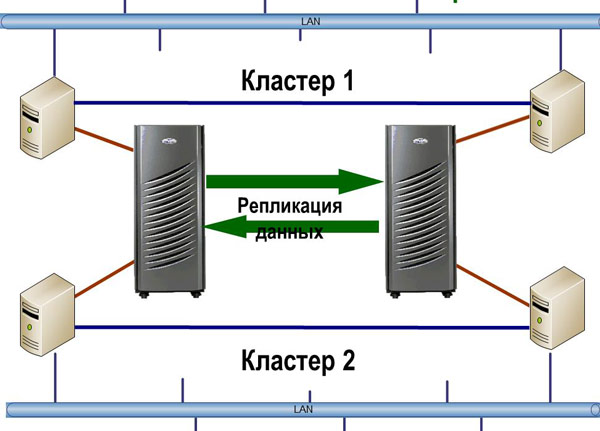
Географически распределенный кластер
Редко кто задумывается про интересную особенность подавляющего большинством решений по репликации данных – их «однозарядность». Вы можете получить на резервной площадке только одно состояние данных. Если система с этими данными по какой-то причине не стартовала – переходим к плану «Б». Чаще всего это восстановление из резервной копии с большой потерей данных. Из перечисленных мной технологий исключение составит только репликация тех же бэкапов. Ответом здесь является использование класса решений Continuous Data Protection. Их суть в том, что все записи, приходящие от сервера, помечаются и сохраняются в определенном журнальном томе на резервной площадке. При восстановлении системы можно выбрать любую точку из этого журнала и получить состояние не только на момент аварии, в которой данные были испорчены, но и за несколько секунд. Такие решения защищают от внутренней угрозы – удаления данных пользователями. В случае репликации СХД – ей все равно, что передавать – пустой том или вашу наиболее критичную БД. При использовании CDP можно выбрать момент прямо перед удалением информации и восстановиться на него. Стоимость систем CDP обычно – десятки тысяч долларов. Один из наиболее удачных примеров, на мой взгляд – EMC RecoverPoint.
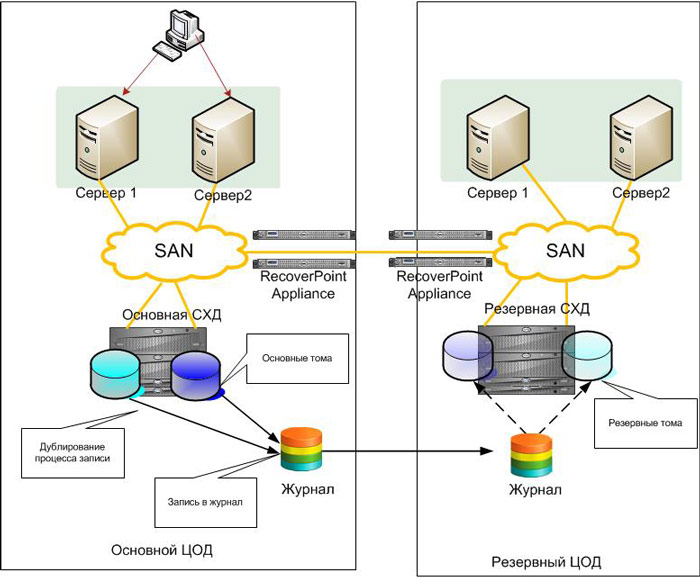
Схема решения на основе RecoverPoint
В последнее время набирают популярность системы виртуализации СХД. Помимо своей основной функции – объединения массивов разных вендоров в единый пул ресурсов – они могут сильно помочь и в организации распределенного ЦОДа. Суть виртуализации СХД в том, что между серверами и системами хранения появляется промежуточный слой контроллеров, пропускающих сквозь себя весь трафик. Тома с СХД презентуются не напрямую серверам, а этим виртуализаторам. Они, в свою очередь, раздают их хостам. В слое виртуализации можно делать репликацию данных между разными СХД, а зачастую есть и более продвинутые возможности — снэпшоты, многоуровневое хранение и т. д. При этом самая базовая функция виртуализаторов является самой нужной для целей DR. Если у нас есть две СХД в разных ЦОДах, соединенных оптической магистралью, мы берем тома с каждой из них и собираем «зеркало» на уровне виртуализатора. В итоге мы получаем один виртуальный том на два ЦОДа, который и видят серверы. Если эти серверы виртуальные – начинает работать Live Migration виртуальных машин и можете «на ходу» переводить задачи между ЦОДами – пользователи ничего не заметят.
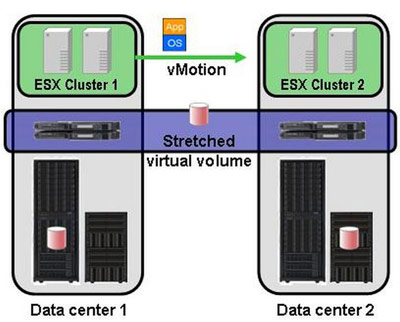
Полная потеря ЦОДа будет отработана обычным HA-кластером в автоматическом режиме за несколько минут. Пожалуй, виртуализация разнесенных СХД позволяет обеспечить минимальное время восстановления для большинства приложений. Для CУБД есть непревзойденный Oracle RAC и его аналоги, но стоимость заставляет задуматься. Виртуализация SAN пока тоже не дешева, для небольших объемов СХД стоимость решения может быть меньше $100К, но в большинстве случаев цена выше. На мой взгляд, наиболее проверенным решением является IBM SAN Volume Controller (SVC), наиболее технически совершенным – EMC VPLEX.
Кстати, если не все ваши приложения еще живут на виртуальной среде, стоит спроектировать резервный ЦОД для них на виртуальных машинах. Во-первых, выйдет намного дешевле, во вторых, сделав это для резерва, недалеко и до миграции основных систем под управление какого-нибудь гипервизора…
Конкуренция на рынке аутсорсинга ЦОД делает более выгодной аренду стойкомест в ЦОДе провайдера, по сравнению со строительством и эксплуатацией своего резервного центра. Если вы размещаете у него виртуальную инфраструктуру, выйдет серьезная экономия на арендных платежах. Но и аутсорсинговые ЦОДы уже не на вершине прогресса. Лучше строить резервную инфраструктуру сразу в «облаке». Синхронизацию данных с основными системами при этом можно обеспечить репликацией на уровне сервера (есть отличное семейство решений DoubleTake от Vision Solutions).
Последний, но очень важный момент, о котором нельзя забывать при проектировании катастрофоустойчивой ИТ-инфраструктуры – рабочие места пользователей. То, что поднялась база данных, не означает возобновления бизнес-процесса. Пользователь должен иметь возможность выполнять свою работу. Даже полноценный резервный офис, в котором стоят выключенные компьютеры для ключевых сотрудников – не идеальное решение. У человека на утраченном рабочем месте могут быть справочные материалы, макросы, и проч., полноценная работа без которых невозможна. Для наиболее важных для компании пользователей разумным выглядит переход на виртуальные рабочие места (VDI). Тогда на рабочем месте (будь то обычный ПК или модный «тонкий» клиент) не хранятся никакие данные, он используется только как терминал, чтобы достучаться до Windows XP или Windows 7, работающей на виртуальной машине в ЦОДе. Доступ к такому рабочему месту легко организовать из дома или из любого компьютера в филиальной сети. Например, если у вас несколько зданий и одно из них недоступно, ключевые пользователи могут приехать в соседний офис и сесть на рабочие места «менее ключевых». Затем они спокойно логинятся в систему, попадают в свою виртуальную машину и фирма оживает!
В завершение, вот основные вопросы, которые стоит задать при оценке DR-решения:
Катастрофоустойчивых решений бесчисленное множество – как коробочных, так и тех, которые можно сделать практически своими руками. Пожалуйста, поделитесь в комментариях что есть у вас и историями, как эти решения вас выручали. Если у вас работает что-то из описанных выше систем или их аналоги – оставляйте отзывы, насколько спокойно вы спите, когда ИТ-системы под их защитой.
- 93% компаний, которые теряли свой ЦОД на 10 и более дней из-за катастрофы, стали банкротами в течение года (National Archives & Records Administration in Washington)
- Каждую неделю в США выходит из строя 140 000 жестких дисков (Mozy Online Backup)
- У 75% компаний нет решений для аварийного восстановления (Forrester Research, Inc.)
- 34% компаний не тестируют резервные копии.
- 77% тех, кто тестируют, обнаруживали нечитаемые накопители в своих библиотеках.
В предыдущих постах (раз и два) я писал про организационные меры, которые ускорят и облегчат восстановление ИТ-систем и связанных с ними процессов компании при чрезвычайной ситуации.
Сейчас поговорим про технические решения, которые в этом помогут. Их стоимость разнится от нескольких тысяч до сотен тысяч долларов.
Высокая доступность и аварийное восстановление
Очень часто решения для высокой доступности (HA – High Availability) и аварийного восстановления (DR – Disaster Recovery) путают. Прежде всего, когда мы говорим о непрерывности бизнеса, мы имеем в виду резервную площадку. Применительно к ИТ – резервный ЦОД. Непрерывность бизнеса — это не про резервное копирование на библиотеку в соседней стойке (что тоже очень важно). Это про то, что основное здание компании сгорит, и мы через несколько часов или дней сможем возобновить работу, развернувшись на новом месте:
| Высокая доступность |
Аварийное восстановление |
| Решение в пределах одного ЦОД |
Включает в себя несколько удаленных ЦОД |
| Время восстановления < 30 минут |
Восстановление может занимать часы и даже дни |
| Нулевая или близкая к нулю потеря данных |
Потеря данных может достигать многих часов |
| Требует ежеквартального тестирования |
Требует ежегодного тестирования |
Холодный резерв
Холодный резерв подразумевает, что есть некое серверное помещение, в которое можно завезти оборудование и развернуть его там. При восстановлении может планироваться закупка «железа», либо его хранение на складе. Нужно учитывать, что большинство систем поставляется под заказ, и быстро найти десятки единиц серверов, СХД, коммутаторов и проч. будет нетривиальной задачей. Как альтернативу складированию оборудования у себя, можно предусмотреть хранение наиболее важного или наиболее редкого оборудования на складе ваших поставщиков. При этом, телекоммуникационные каналы в помещении должны присутствовать, но заключение контракта с провайдером обычно происходит после принятия решения о запуске «холодного» ЦОДа. Восстановление работы в таком ЦОДе при катастрофическом сбое основной площадки вполне может занимать несколько недель. Убедитесь, что ваша компания сможет просуществовать эти несколько недель без ИТ и не лишиться бизнеса (по причине отзыва лицензии, либо невосполнимого кассового разрыва, например) – об этом я писал ранее. Честно говоря, я бы никому не рекомендовал этот вариант резервирования. Возможно, я преувеличиваю роль ИТ в бизнесе некоторых компаний.
Теплый резерв
Это значит, что у нас функционирует альтернативная площадка, в которой есть активные интернет и WAN-каналы, базовая телекоммуникационная и вычислительная инфраструктура. Она всегда «слабее» основной по вычислительным мощностям, некоторое оборудование там может отсутствовать. Самое важное – чтобы на площадке всегда была актуальная резервная копия данных. Действуя «по старинке» можно организовать регулярное перемещение туда резервных копий на лентах. Современный метод – репликация бэкапов по сети из основного ЦОДа. Использование бэкапа с дедупликацией позволит оперативно передавать резервные копии даже по «тонкому» каналу между ЦОДами.
Горячий резерв
Вот он, выбор крутых парней, поддерживающих ИТ-системы, простой которых даже на несколько часов приносит компании огромные убытки. Здесь имеется все необходимое оборудование для полноценной работы ИТ-систем. Обычно фундаментом такой площадки служит система хранения данных, на которую синхронно или асинхронно зеркалируются данные из основного ЦОДа. Для того, чтобы горячий резерв в час Икс смог отработать вложенные в него деньги, должны проводиться регулярные тестовые переводы систем, настройки и версия ОС серверов на основной и резервной площадке должны постоянно синхронизироваться – вручную либо автоматически.
Минус горячего и теплого резерва – дорогостоящее оборудование простаивает в ожидании катастрофы. Выходом из этой ситуации является стратегия распределенного ЦОДа. При таком варианте две (или более) площадки равноправны – большинство приложений могут работать как на одной, так и на другой. Это позволяет задействовать мощности всего оборудования и обеспечить балансировку нагрузки. С другой стороны, серьезно повышаются требования к автоматизации перевода ИТ-сервисов между ЦОДами. Если оба ЦОДа «боевые», бизнес вправе ожидать, что при ожидаемом пике нагрузки на одно из приложений, его можно быстро перевести в более свободный ЦОД. Чаще всего, в подобных ЦОДах присутствует синхронная репликация между СХД, но возможна и небольшая асинхронность (в пределах нескольких минут).
Три волшебных слова
Перед тем, как перейти непосредственно к технологиям катастрофоустойчивости ИТ-сервисов, напомню три «волшебных» слова, которые определяют стоимость любого DR-решения: RTO, RPO, RCO.
- RTO (Recovery time objective) – время, за которое возможно восстановить ИТ-систему
- RPO (Recovery point objective) – сколько данных будет потеряно при аварийном восстановлении
- RCO (Recovery capacity objective) – какую часть нагрузки должна обеспечивать резервная система. Этот показатель может измеряться в процентах, транзакциях ИТ-систем и прочих величинах.
RPO
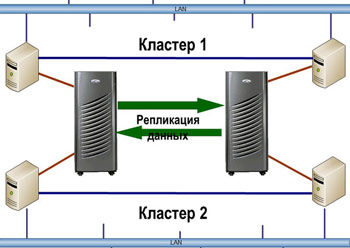
Первое деление, которое мы можем провести между всем многообразием ИТ-решений для обеспечения катастрофоустойчивости – обеспечивают ли они нулевое RPO или нет. Отсутствие потери данных при сбое обеспечивается синхронной репликацией. Чаще всего, это делается на уровне СХД, но возможно реализовать и на уровне СУБД или сервера (при помощи продвинутого LVM). В первом случае сервер не получает от СХД, с которой он работает, подтверждения об успешности записи, пока СХД не передала эту транзакцию второй системе и не получила от нее подтверждение, что запись прошла успешно.
Синхронную репликацию умеют делать 100% СХД, относящихся к среднему ценовому сегменту и некоторые системы начального уровня от известных вендоров. Стоимость лицензий для синхронной репликации на «простых» СХД начинается от нескольких тысяч долларов. Примерно столько же стоит софт для репликации на уровне серверов на 2-3 сервера. Если у вас нет действующего резервного ЦОДа, не забудьте добавить стоимость закупки резервного оборудования.
RPO в несколько минут может обеспечить асинронная репликация на уровне СХД, ПО управления томами сервера (LVM – Logical volume manager), либо СУБД. До сих пор standby-копия базы данных остается одним из наиболее популярных решений для DR. Чаще всего функционал “log shipping”, как это называется у администраторов СУБД, не лицензируется производителем отдельно. Если у вас пролицензирована БД – реплицируйте на здоровье. Стоимость асинхронной репликации для серверов и СХД не отличается от синхронной, см. предыдущий пункт.
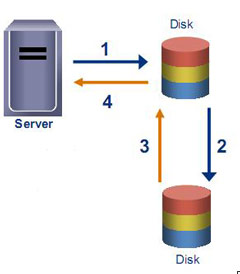
Если мы говорим об RPO в несколько часов, чаще это репликация резервных копий с одной площадки на другую. Большинство дисковых библиотек умеют делать это, часть ПО для резервного копирования – тоже. Как я уже говорил, при таком варианте здорово поможет дедупликация. Вы не только будете меньше загружать канал передачей резервных копий, но и сделаете это намного быстрее — каждый передаваемый бэкап будет занимать в десятки или сотни раз меньше времени, чем в реальности. С другой стороны, надо помнить, что первый бэкап при дедупликации все равно должен передать в систему массу уникальных данных. «Настоящую» дедупликацию вы увидите после недельного цикла резервного копирования. При синхронизации дисковых библиотек — то же самое. Если расчетное время передачи при вашей ширине канала между ЦОД составляет несколько дней и даже недель (что может и стоить немало), есть смысл сначала поставить вторую библиотеку рядом, выполнить синхронизацию и увезти ее в резервный ЦОД.
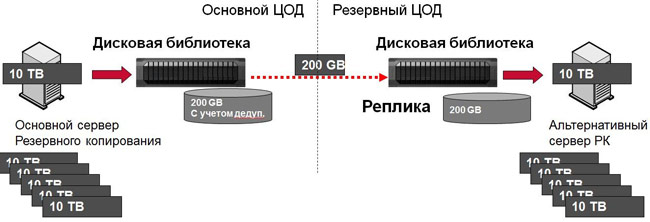
Синхронизация резервных копий между ЦОД
RTO
Когда стоит задача минимизации времени восстановления (RTO), процесс должен быть максимально документирован и автоматизирован. Одно из лучших и наиболее универсальных решений – HA-кластеры с территориально разнесенными узлами. Чаще всего, такие решения строятся на базе репликации СХД, но возможны и другие варианты. Лидирующие продукты в этой области, например, Symantec Veritas Cluster, имеют в своем составе модули по работе с СХД, переключающие направление репликации, когда необходимо перезапустить сервис на резервном узле. Для менее продвинутых кластеров (например Microsoft Cluster Services, встроенный в Windows) основные производители СХД (IBM, EMC, HP) предлагают надстройки, делая из обычного HA-кластера катастрофоустойчивый.
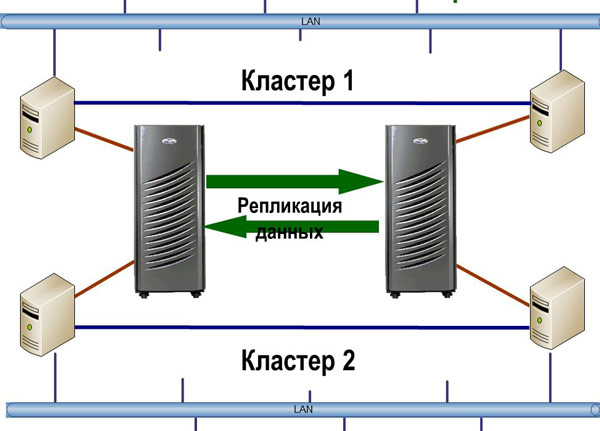
Географически распределенный кластер
Редко кто задумывается про интересную особенность подавляющего большинством решений по репликации данных – их «однозарядность». Вы можете получить на резервной площадке только одно состояние данных. Если система с этими данными по какой-то причине не стартовала – переходим к плану «Б». Чаще всего это восстановление из резервной копии с большой потерей данных. Из перечисленных мной технологий исключение составит только репликация тех же бэкапов. Ответом здесь является использование класса решений Continuous Data Protection. Их суть в том, что все записи, приходящие от сервера, помечаются и сохраняются в определенном журнальном томе на резервной площадке. При восстановлении системы можно выбрать любую точку из этого журнала и получить состояние не только на момент аварии, в которой данные были испорчены, но и за несколько секунд. Такие решения защищают от внутренней угрозы – удаления данных пользователями. В случае репликации СХД – ей все равно, что передавать – пустой том или вашу наиболее критичную БД. При использовании CDP можно выбрать момент прямо перед удалением информации и восстановиться на него. Стоимость систем CDP обычно – десятки тысяч долларов. Один из наиболее удачных примеров, на мой взгляд – EMC RecoverPoint.
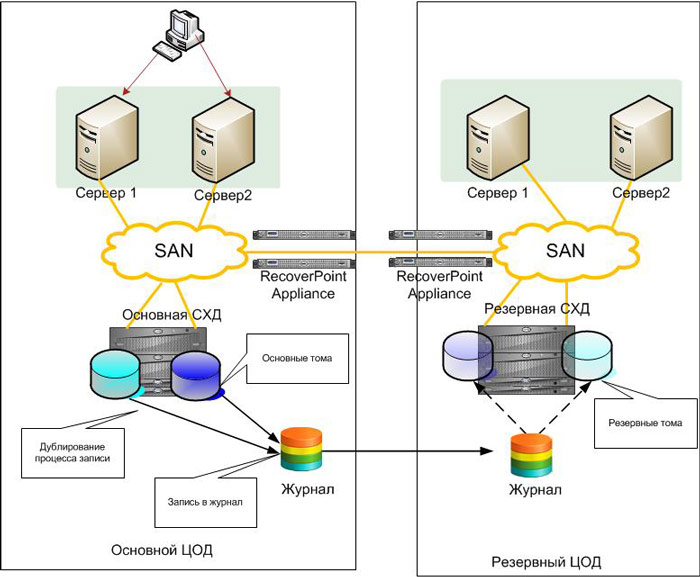
Схема решения на основе RecoverPoint
В последнее время набирают популярность системы виртуализации СХД. Помимо своей основной функции – объединения массивов разных вендоров в единый пул ресурсов – они могут сильно помочь и в организации распределенного ЦОДа. Суть виртуализации СХД в том, что между серверами и системами хранения появляется промежуточный слой контроллеров, пропускающих сквозь себя весь трафик. Тома с СХД презентуются не напрямую серверам, а этим виртуализаторам. Они, в свою очередь, раздают их хостам. В слое виртуализации можно делать репликацию данных между разными СХД, а зачастую есть и более продвинутые возможности — снэпшоты, многоуровневое хранение и т. д. При этом самая базовая функция виртуализаторов является самой нужной для целей DR. Если у нас есть две СХД в разных ЦОДах, соединенных оптической магистралью, мы берем тома с каждой из них и собираем «зеркало» на уровне виртуализатора. В итоге мы получаем один виртуальный том на два ЦОДа, который и видят серверы. Если эти серверы виртуальные – начинает работать Live Migration виртуальных машин и можете «на ходу» переводить задачи между ЦОДами – пользователи ничего не заметят.
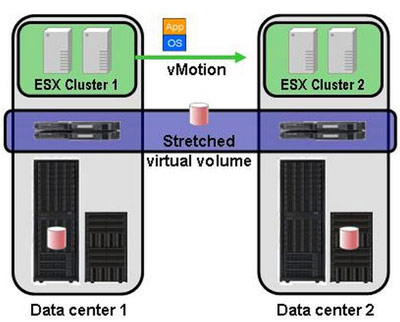
Полная потеря ЦОДа будет отработана обычным HA-кластером в автоматическом режиме за несколько минут. Пожалуй, виртуализация разнесенных СХД позволяет обеспечить минимальное время восстановления для большинства приложений. Для CУБД есть непревзойденный Oracle RAC и его аналоги, но стоимость заставляет задуматься. Виртуализация SAN пока тоже не дешева, для небольших объемов СХД стоимость решения может быть меньше $100К, но в большинстве случаев цена выше. На мой взгляд, наиболее проверенным решением является IBM SAN Volume Controller (SVC), наиболее технически совершенным – EMC VPLEX.
Кстати, если не все ваши приложения еще живут на виртуальной среде, стоит спроектировать резервный ЦОД для них на виртуальных машинах. Во-первых, выйдет намного дешевле, во вторых, сделав это для резерва, недалеко и до миграции основных систем под управление какого-нибудь гипервизора…
Конкуренция на рынке аутсорсинга ЦОД делает более выгодной аренду стойкомест в ЦОДе провайдера, по сравнению со строительством и эксплуатацией своего резервного центра. Если вы размещаете у него виртуальную инфраструктуру, выйдет серьезная экономия на арендных платежах. Но и аутсорсинговые ЦОДы уже не на вершине прогресса. Лучше строить резервную инфраструктуру сразу в «облаке». Синхронизацию данных с основными системами при этом можно обеспечить репликацией на уровне сервера (есть отличное семейство решений DoubleTake от Vision Solutions).
Последний, но очень важный момент, о котором нельзя забывать при проектировании катастрофоустойчивой ИТ-инфраструктуры – рабочие места пользователей. То, что поднялась база данных, не означает возобновления бизнес-процесса. Пользователь должен иметь возможность выполнять свою работу. Даже полноценный резервный офис, в котором стоят выключенные компьютеры для ключевых сотрудников – не идеальное решение. У человека на утраченном рабочем месте могут быть справочные материалы, макросы, и проч., полноценная работа без которых невозможна. Для наиболее важных для компании пользователей разумным выглядит переход на виртуальные рабочие места (VDI). Тогда на рабочем месте (будь то обычный ПК или модный «тонкий» клиент) не хранятся никакие данные, он используется только как терминал, чтобы достучаться до Windows XP или Windows 7, работающей на виртуальной машине в ЦОДе. Доступ к такому рабочему месту легко организовать из дома или из любого компьютера в филиальной сети. Например, если у вас несколько зданий и одно из них недоступно, ключевые пользователи могут приехать в соседний офис и сесть на рабочие места «менее ключевых». Затем они спокойно логинятся в систему, попадают в свою виртуальную машину и фирма оживает!
В завершение, вот основные вопросы, которые стоит задать при оценке DR-решения:
- От каких сбоев защищает?
- Какие RPO/RTO/RCO обеспечивает?
- Сколько стоит?
- Насколько сложна эксплуатация?
Катастрофоустойчивых решений бесчисленное множество – как коробочных, так и тех, которые можно сделать практически своими руками. Пожалуйста, поделитесь в комментариях что есть у вас и историями, как эти решения вас выручали. Если у вас работает что-то из описанных выше систем или их аналоги – оставляйте отзывы, насколько спокойно вы спите, когда ИТ-системы под их защитой.
