

В конце 2008 года на тогда ещё небольшую петербуржскую компанию вышел один западный медиахолдинг примерно так:
— Это вы там упоролись по хардкору и приспособили SSE-инструкции для реализации кода Рида-Соломона?
— Да, только мы не…
— Да мне пофиг. Хотите заказ?
Проблема была в том, что видеомонтаж требовал адовой производительности, и тогда использовались RAID-5 массивы. Чем больше дисков в RAID-5 — тем выше была вероятность отказа прямо во время монтажа (для 12 дисков — 6%, а для 36 дисков — уже 17-18%). Дроп диска при монтаже недопустим: даже если диск падает в хайэндовой СХД, скорость резко деградирует. Медиахолдигу надоело с криком биться головой о стену каждый раз, и поэтому кто-то посоветовал им сумрачного русского гения.
Много позже, когда наши соотечественники подросли, возникла вторая интересная задача — Silent Data Corruption. Это такой тип ошибок хранения, когда на блине одновременно меняется и бит в основных данных, и контрольный бит. Если речь о видео или фотографии — в целом, никто даже не заметит. А если речь про медицинские данные, то это становится диагностической проблемой. Так появился специальный продукт под этот рынок.
Ниже — история того, что они делали, немного математики и результат — ОС для highload-СХД. Серьёзно, первая русская ОС, доведённая до ума и выпущенная. Хоть и для СХД.
Медиахолдинг
История началась в 2008-2009 как проект для американского заказчика. Требовалось разработать такую систему хранения данных, которая обеспечивала бы высокую производительности и при этом стоила бы меньше кластера из готовых хайэндовых СХД. У холдинга было много стандартного железа по типу Амазон-ферм — x86-архитектура, типовые полки с дисками. Предполагалось, что «эти русские» смогут написать такой управляющий софт, который будет объединять устройства в кластеры и обеспечивать тем самым надёжность.
Проблема, конечно, в том, что RAID-6 требовал очень большой вычислительной мощности для работы с полиномами, что было непростой задачей для x86 CPU. Именно поэтому производители СХД использовали и используют свои варианты и поставляют в итоге стойку как своего рода «чёрный ящик».
Но вернёмся в 2009 год. Основной задачей в начале проекта было быстрое декодирование данных. Вообще, высокой производительностью декодирования компания RAIDIX (так стали звать наших героев намного позже) занималась всегда.
Вторая задача — чтобы при выходе из строя диска не просаживалась скорость чтения-записи. Третья задача немного похожа на вторую — бороться с проблемами ошибок на HDD, которые происходят неизвестно когда и на каком носителе. Фактически, открылось новое поле работы — обнаружение скрытых дефектов данных на чтение и их исправление.
Проблемы эти были актуальны тогда только для больших, очень больших хранилищ и реально быстрых данных. По большому счёту, архитектура «обычных» СХД устраивала всех, кроме тех, кто постоянно использовал реально большие объёмы данных на чтение-запись (а не работал 80% времени с «горячим» набором данных, составляющим 5-10% СУБД).
Тогда не было как таковых стандартов end-to-end data protection (точнее, не было вменяемой реализации), да и сейчас они поддерживаются далеко не всеми дисками и контроллерми.
Решение первых задач
Начался проект. Андрей Рюрикович Фёдоров — математик и основатель компании, начал с оптимизации восстановления данных, используя типовую архитектуру процессоров Intel. Как раз тогда первая проектная группа нашла простой, но реально действенный подход к векторизации умножения на примитивный элемент поля Галу. При использовании SSE-регистров одновременно умножаются 128 элементов поля на x за несколько XOR. А как вы знаете, умножение любых полиномов в конечных полях можно свести к умножению на примитивный элемент за счет факторизации умножения. Вообще было множество идей с использованием расширенных возможностей процессоров Intel.
Когда стало понятно, что идеи, в целом, имеют успех, но требуется написание продукта уровня ОС для работы на самом низком уровне, сначала был выделен департамент, а потом была основана отдельная компания RAIDIX.
Идей было много, для проработки и проверки были найдены сотрудники университета СПБГУ. Началась работа на стыке науки и технологии — попытки создания новых алгоритмов. Например, очень много работали с обращением матриц (это алгоритмически сложная задача, но очень важная для декодирования). Ковыряли Рида-Соломона, пробовали увеличить размерность поля двух в шестнадцатой, двух в двухсот пятьдесят шестой степени, искали быстрые способы обнаружения Silent Data Corruption. Проводили опыты до прототипов на ассемблере, оценивали алгоритмическую сложность каждого варианта. В большинстве своём опыты давали отрицательный результат, но примерно на 30-40 попыток одна была положительной по производительности. Например, то же увеличение размерности поля пришлось убрать — в теории это было замечательно, но на практике вызвало ухудшение декодирования, потому что сильно увеличивался cache miss (непопадание в кэш).
Дальше шла планомерная работа по расширению RAID 7.N. Проверяли, что будет при увеличении количества дисков, разбиений на диск и так далее. Intel добавил набор инструкций AES для безопасности, среди которых обнаружилась очень удобная инструкция для умножения полиномов (pclmulqdq). Думали, что её можно использовать для кода — но после проверки преимуществ в сравнении с уже имеющейся производительностью не нашли.
Компания выросла до 60 человек, занимающихся исключительно вопросами хранения данных.
Параллельно начали работать над отказоустойчивой конфигурацией. Сначала предполагалось, что отказоустойчивый кластер будет на базе открытого ПО. Столкнулись с тем, что качество кода и его универсальность были недостаточными для решения конкретных практических задач. В это время стали появляться новые проблемы: например, при падении интерфейса традиционно на контроллере проходили перевыборы и переключение мастера. Это в совокупности занимало астрономическое время — до минуты-двух. Потребовалась новая система хостов: начали присваивать каждому очки за сессии (чем больше открытых сессий — тем больше очков), а новые хосты делали discover. В третьем поколении обнаружилось, что даже при синхронной репликации из-за особенностей реализации ПО и железа, сессия на одном контроллере могла появиться раньше, чем на другом — и возникал нежелательный хендовер с переключением. Потребовалось четвёртое поколение — свой собственный кластер-менеджер именно на работу СХД, в котором отказы хост-интерфейсов и бекэнд интерфейсов обрабатывалось правильно, с учётом всех особенностей аппаратного обеспечения. Потребовалось очень существенно доделать ПО на низком уровне, но результат того стоил — сейчас пара секунд на переключение максимум, плюс Active-Active стал куда более правильным. Добавилось автоконфигурирование корзин с дисками.
В конечном счёте сделали очень хорошую оптимизация SATA с переходом на RAID 7.3 — поддержка восстановления данных без потери производительности.
Реализация
Используется решение это вендорами СХД, а также владельцами больших хранилищ из США, Китая и Кореи. Вторая категория — непотоковые задачи интеграторов, чаще всего медиа, суперкомпьютеры, здравоохранение. Во время Олимпийских игр конечным потребителем была студия спортивного вещания «Панорама», они как раз делали картинку с олимпиады. Есть пользователи RAIDIX в Германии, Индии, Египте, России, США.
Получилось вот что:
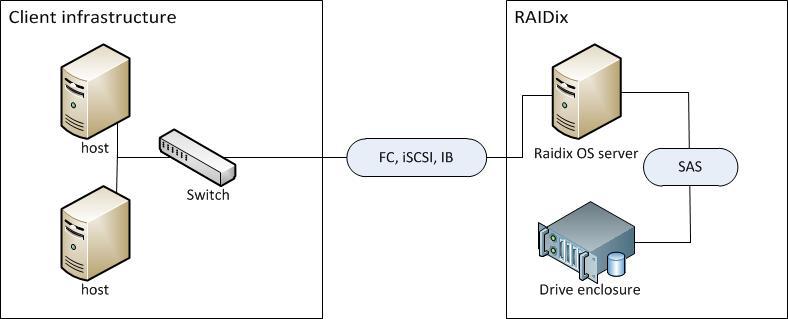
На одном контроллере: обычное x86 железо + ОС = быстрое и очень, очень дешёвое хранилище.
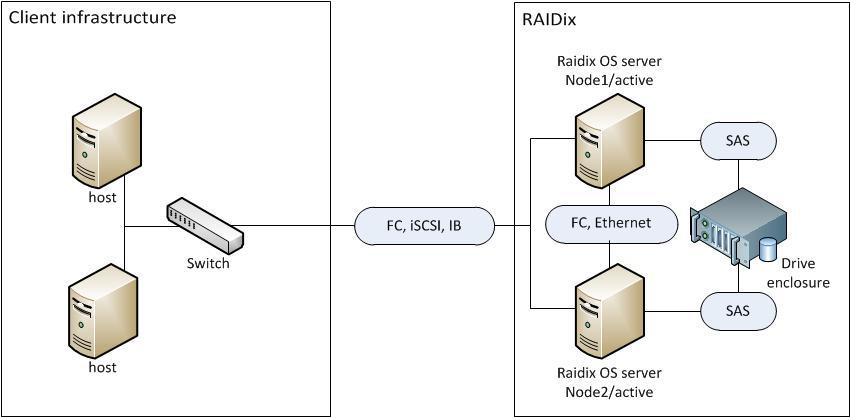
Два контроллера: получается система с резервированием (но дороже).
Важная фишка — частичное восстановление тома. Есть по три контрольных суммы на каждый страйп:

Благодаря собственному алгоритму расчета RAID-массива есть возможность восстанавливать только отдельную область диска, содержащую поврежденные данные, уменьшая время восстановления массива. Это очень эффективно для массивов больших объемов.
Вторая вещь — реализован механизм упреждающей реконструкции, исключающей из процесса до двух (RAID 6) или до трех (RAID 7.3) дисков, скорость чтения с которых ниже, чем у остальных. Когда быстрее восстановить, чем прочитать — естественно, используется первый вариант.
Работает это так: из K стрипов получается K-N, необходимое для сборки участка данных. Если данные целые, чтение остальных стрипов останавливается.
Это означает, что в RAID 7.3 имея 24 диска при 3 отказах — 12 Гб/с на ядро (4 ядра) — скорость восстановления превышает скорость чтения бекапа и даже обращения к RAM — несмотря на выпадение диска, чтение сохраняется.
Следующая проблема низкого уровня — попытка выполнить чтение битого участка. Даже на энтерпрайз-системах задержка может составить 8 секунд — наверняка вы видели такие «подвисания» HDD-СХД. С учётом этого алгоритма неотдача данных с трёх дисков из 24 означает просто замедление чтение на несколько миллисекунд.
Более того, система запоминает диски с наибольшим временем отклика и перестает отправлять им запросы в течение одной секунды. Это позволяет снизить нагрузку на ресурсы системы. Дискам с наибольшим временем отклика присваивается статус «медленный» и делается уведомление о том, что стоит их заменить.
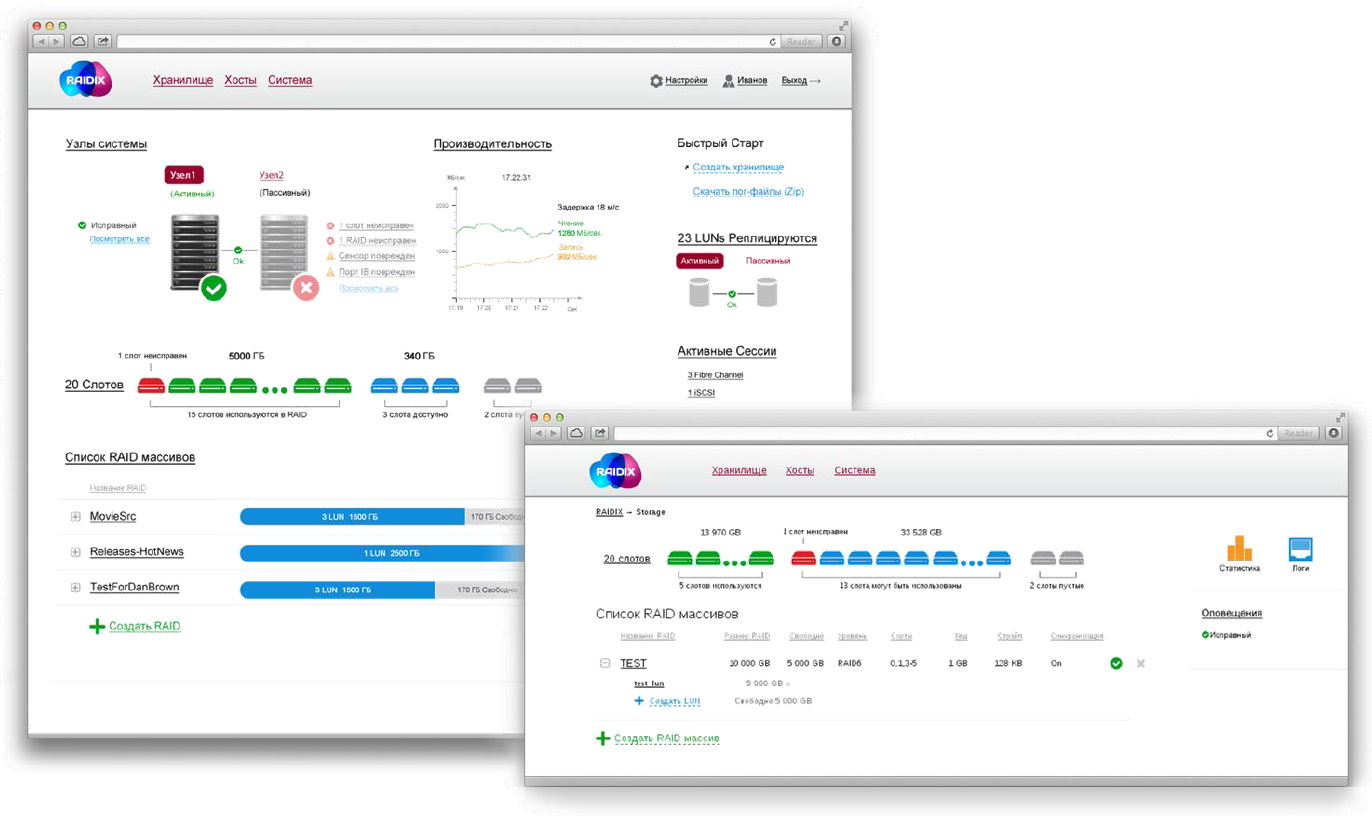
Скриншоты интерфейса
Учитывая преимущества ОС RAIDIX, многие заказчики решили мигрировать на неё. Здесь сказался недостаток размера компании — сложно петербуржскому разработчику учесть все особенности зеркалирования СУБД и других специфических данных. В последней версии были сделаны большие подвижки в сторону плавной миграции, но всё равно гладко и ровно как у хайэнд-СХД с зеркальным подключением Active-Active не получится, скорее всего потребуется отключение.
Детали
В России лично я вижу возможность получать за минимальные деньги вполне интересные варианты СХД. Мы будем собирать на нормальном стабильном железе решения, которые будут ставиться готовыми к заказчикам. Главное преимущество, конечно, рубль на Гб/с. Очень дёшево.
Например, вот конфигурация:
- Сервер HP DL 380p gen8 (Intel Xeon E5-2660v2, 24 Гб памяти + контроллеры LSI SAS HBA 9207-8i).
- На 2 диска разливаем ОС RAIDIX 4.2, оставшиеся 10 – 2Тб SATA.
- Внешний интерфейс – 10 Гбит/с Ethernet.
- 20 Тб пространства, которое можно использовать.
- + Лицензии на 1 год (включающая ТП и обновления).
- Цена на продажу по прайсу: 30 000$.
Полка расширения, подключенная по SAS с 12 дисками по 2Тб по прайсу – 20 000$. В цену входит предустановка ОС. Под данные на дисках с данными уходит 97% места. LUN неограниченного размера. Поддерживаются Fibre Channel; InfiniBand (FDR, QDR, DDR); iSCSI. Есть SMB, NFS, FTP, AFP, есть Hot Spare, есть ИБП, 64 диска в массиве RAID 0/ 6/ 10/ 7.3 (с тройной четностью). 8 Гб/с на RAID 6. Есть QoS. В результате — оптимальное решение для постпродашна, в частности, цветокоррекции и монтажа, для ТВ-вещания, складывания данных с HD-камер. При семействе узлов можно получить 150 Гб/с без существенного снижения надёжности и даже под Lustre — это область highload.
Вот по ссылке спека и ещё детали (PDF).
Тесты
1. Одноконтроллерная конфигурация. Сервер SuperMicro SSG-6027R-E1R12L 2 юнита. 12 дисков по 4 Тб Sata 3,5”. Внешний интерфейс 8Гбит/с FC. 48 Тб неразмеченного пространства за 12 000$
2. Двухконтроллерная конфигурация. Сервер SuperServer 6027TR-DTRF, в нем 2 платы (как блейды). Добавляем полку с 45 дисками по 4 Тб. Внешний интерфейс 8Гбит/с FC. 180 Тб неразмеченного пространства за 30 000$.
Конфигурация а — RAID 7.3 на 12 дисков. 36 Тб полезной емкости, 0,33$/Гб.
Конфигурация б — три RAID 7.3 по 15 дисков. 0,166$/Гб
| FC 8G Performance |
||||
| Sequential Read/Write |
||||
| Operation type |
Block Size |
|
||
| IOps |
MBps |
|
||
| read |
4K |
80360,8 |
329,1 |
55,8 |
| 128K |
11946,7 |
1565,8 |
54,3 |
|
| 1M |
1553,5 |
1628,9 |
98,3 |
|
| write |
4K |
18910,8 |
77,4 |
44,8 |
| 128K |
9552,2 |
1252,0 |
54,9 |
|
| 1M |
1555,7 |
1631,2 |
100,4 |
|
Здесь — остальные результаты.
В целом
Я очень рад, что у нас «под боком» внезапно нашёлся такой производитель, решающий очень специфические задачи. Своих комплектующих компания не выпускает и других бизнес-сервисов у них нет, системной интеграцией заниматься тоже не планируют — так мы и договорились до сотрудничества. В итоге мой отдел теперь занимается, в частности, решениями на базе ОС RAIDIX. Первые внедрения в России, естественно, пойдут строго вместе с производителями.
Мы обкатали на демо-стенде некоторые конфигурации, и, в целом, довольны, хоть и нашли пару подводных камней (что нормально для новых версий ПО). Если интересны детали по внедрению — пишите на atishchenko@croc.ru, расскажу подробнее, стоит или нет.
