

Однажды мы ставили новые дисковые полки для массива EMC у одного из наших крупных клиентов. Когда я уходил с объекта, то обратил внимание на людей в форме транспортной компании, которые вытаскивали из стоек и готовили к погрузке большое количество серверов. С сисадминами заказчиков общение идёт плотное, поэтому довольно быстро выяснилось, что это серверы — старые машинки, в которых мало памяти и процессорной мощности, хотя дисков стоит в избытке. Обновлять их не выгодно и железки будут отправлены на склад. И их спишут где-то через год, когда они покроются пылью.
Железо, в целом, неплохое, просто прошлого поколения. Выкидывать, естественно, было жалко. Тогда я и предложил протестировать EMС ScaleIO. Если коротко, работает это так:

ScaleIO — это софт, который ставится на серверы поверх операционной системы. ScaleIO состоит из серверной части, клиентской части и нод управления. Дисковые ресурсы объединяются в одну виртуальную одноуровневую систему.
Как это работает
Для работы системы нужно три управляющих ноды. Они содержат всю информацию о состояние массива, его компонентах и происходящих процессах. Это своего рода оркестраторы массива. Для полноценного функционирования ScaleIO должна быть жива хотя бы одна управляющая нода.
Серверная часть — это небольшие клиенты, объединяющие свободное место на серверах в единый пул. На этом пуле можно создавать луны (один лун будет распределен по всем серверам, входящим в пул) и отдавать их клиентам. ScaleIO может использовать оперативную память сервера в качестве кэша на чтение. Размер кэша задается для каждого сервера отдельно. Чем больше суммарный объем, тем быстрее будет работать массив.
Клиентская часть — это драйвер блочного устройства ввода-вывода, представляющий распределенный по разным серверам лун в виде локального диска. Вот так, например, лун ScaleIO выглядит на ОС Windows:
Требования для установки ScaleIO минимальны:
| Процессор |
Intel or AMD x86 |
| Память |
500 MB RAM для ноды управления 500 MB RAM на каждой ноде данных 50 MB RAM для каждого клиента |
| Поддерживаемые операционные системы |
Linux: CentOS Windows: 2008 R2, 2012, or 2012 R2 Hypervisors: · VMware ESXi OS: 5.0, 5.1, or 5.5, managed by vCenter 5.1 or 5.5 only · Hyper-V · XenServer 6.1 · RedHat KVM |
Разумеется, все данные передаются по сети Ethernet. Все операции ввода-вывода и пропускная способность доступны любому приложению в кластере. Каждый хост пишет на много нод одновременно, а значит, пропускная способность и количество операций ввода\вывода могут достигать очень больших значений. Дополнительное преимущество такого подхода в том, что ScaleIO не требует толстого интерконекта между нодами. Если в сервере стоит Ethernet 1Gb, решение подойдет для потоковой записи, архива или файловой помойки. Здесь же можно запустить тестовую среду или разработчиков. При использовании Ethernet 10Gb и SSD дисков, получим хорошее решение для баз данных. На SAS дисках можно поднять датасторы на VMware. При этом виртуальные машины могут работать на тех же серверах, с которых отдается место в общий лун, ведь под ESX есть и клиент, и серверная часть. Мне лично очень нравится такая вариативность.
При большом количестве дисков по теории вероятности растёт риск отказа любого из компонентов. Решение интересное: кроме RAID-групп на уровне контроллеров, используется зеркалирование данных по разным серверам. Все серверы делятся на fault-сеты — набор машинок с большой вероятностью одновременного отказа. Данные зеркалируются между fault-сетами таким образом, что потеря одного из них не приведет к недоступности данных. В один fault-сет могут входить серверы, размещенные в одной и той же стойке, или серверы с разными операционными системами. Последний вариант приятен тем, что можно выкатывать патчи на все машины с Linux или Windows одновременно, не опасаясь падения кластера из-за ошибок операционной системы.

Тесты
ScaleIO устанавливается с помощью installation manager. В него нужно загрузить пакеты программного обеспечения для разных операционных систем и csv-файл с желаемым результатом. Я взял 8 серверов, половину с Windows, половину с SLES. Установка на все 8 заняла 5 минут и несколько нажатий на кнопку «Далее».
Вот результат:

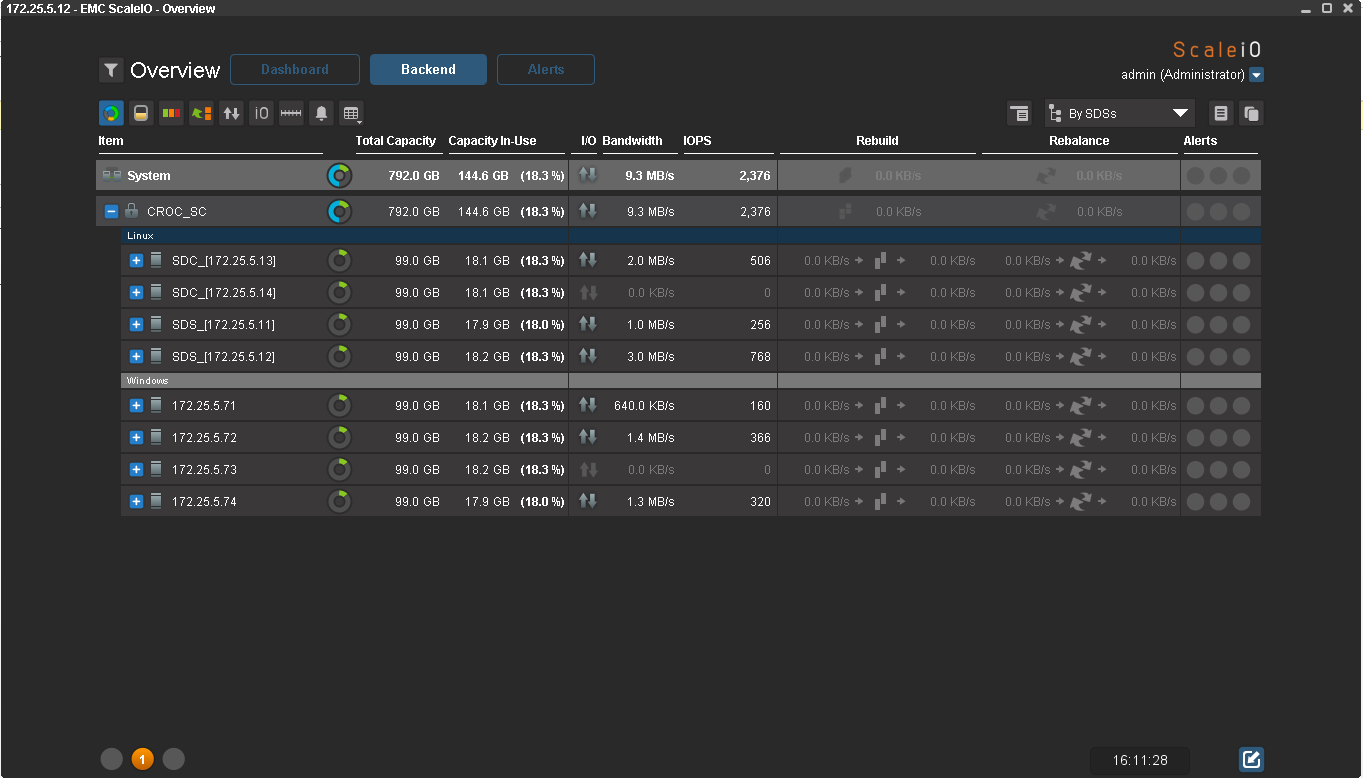
Это, кстати, GUI, через который можно управлять массивом. Для любителей консоли, есть подробный мануал по cli-командам. Консоль как всегда более функциональна.
Для тестов все ноды с данными я разделил на 2 Failover сета: с ОС Windows и с SLES. Мапим наш первый диск к хосту:

Объем диска небольшой, всего 56 Гб. Дальше по плану тесты на отказоустойчивость, а мне не хочется ждать окончание ребилда более 10 минут.
Для эмуляции нагрузки проще всего использовать IOmeter. Если диск отвалится хоть на секунду, я об этом обязательно узнаю. К сожалению, протестировать производительность в этом тесте не получится: серверы виртуальные, а датастор — EMC CX3. Нормальное оборудование занято в продакшне. Вот побежали первые байты:

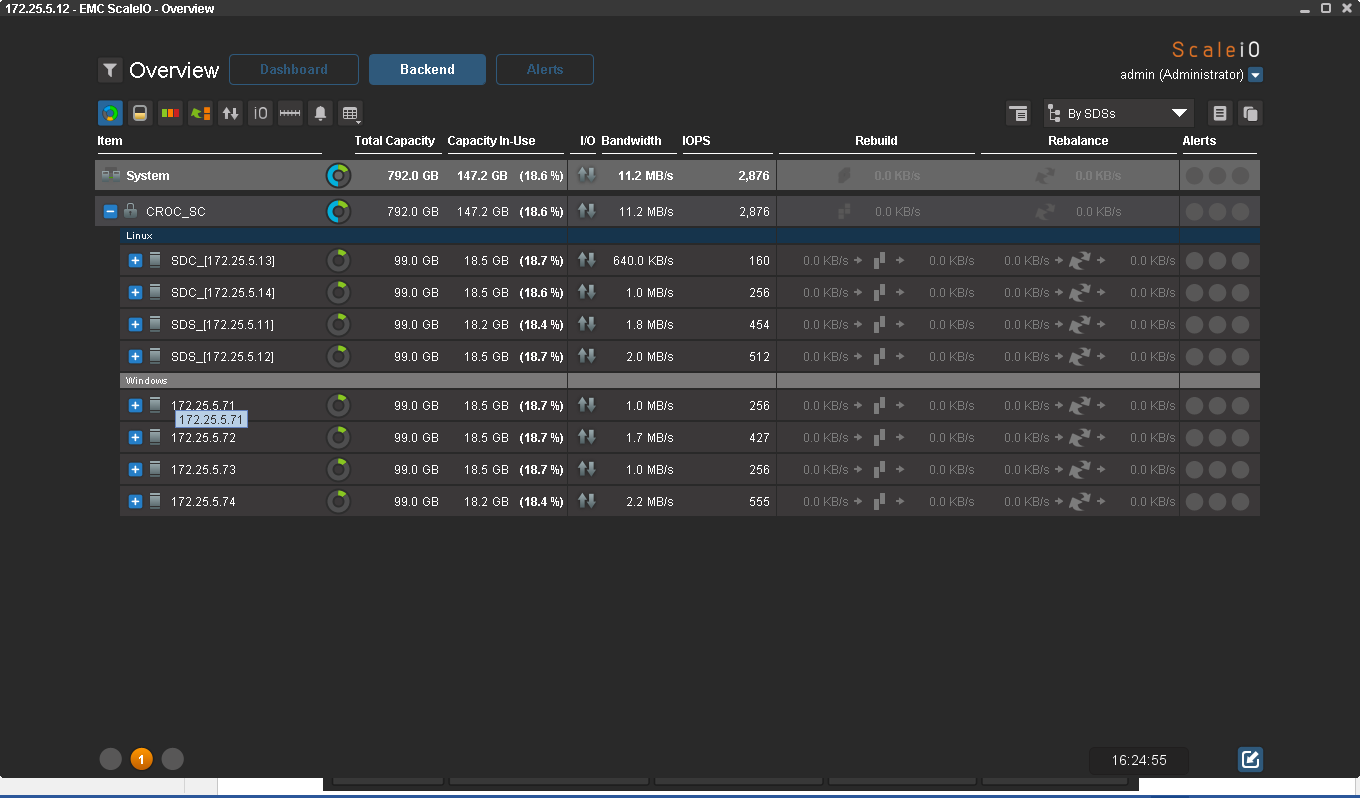
Как я писал раньше, один fail-сет можно выключить. Начинается самое интересное. Приятно знать, что с продуктивом клиента в экстренных ситуациях все будет нормально, поэтому в КРОК мы создаем такие ситуации в нашей лабе. Самый хороший способ убедить клиента в надежности решения для обеспечения высокой доступности — выключить одну из двух стоек с оборудованием. Здесь я делаю то же самое:
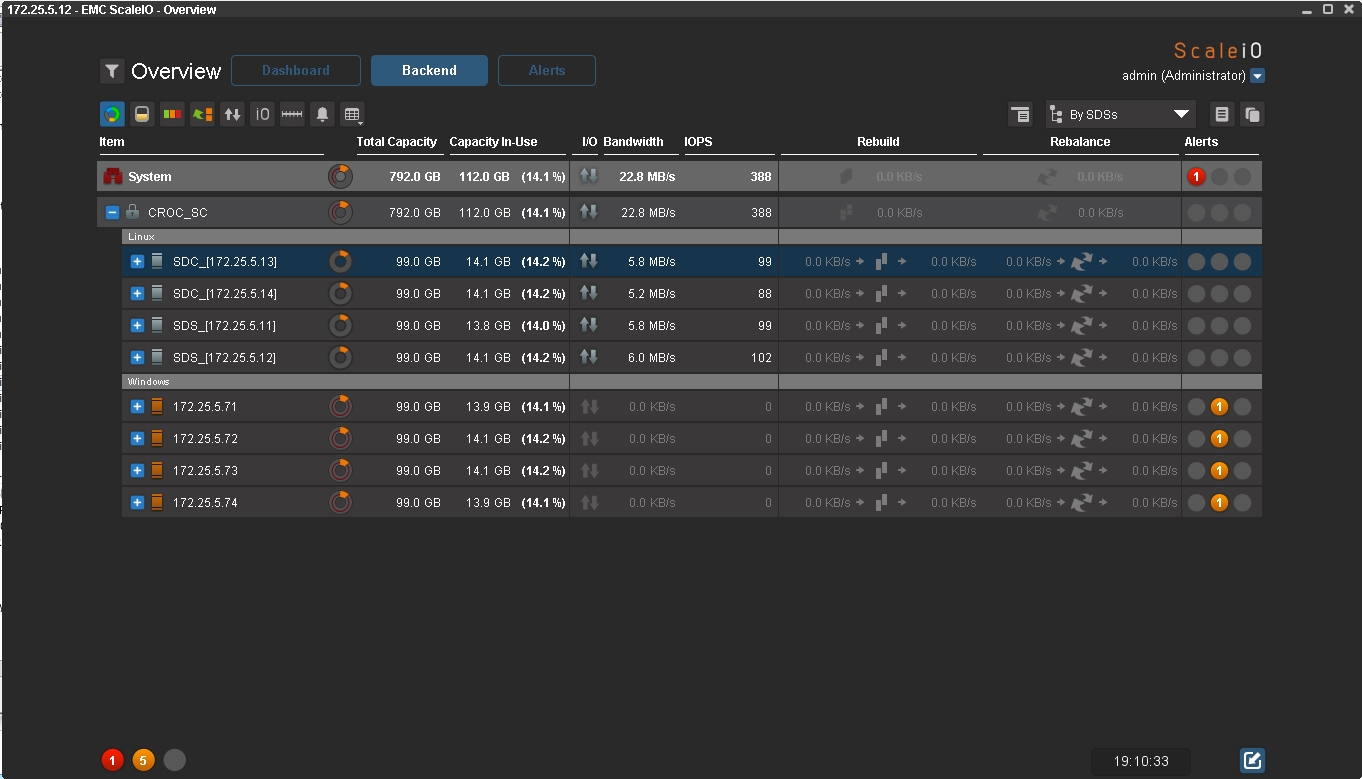
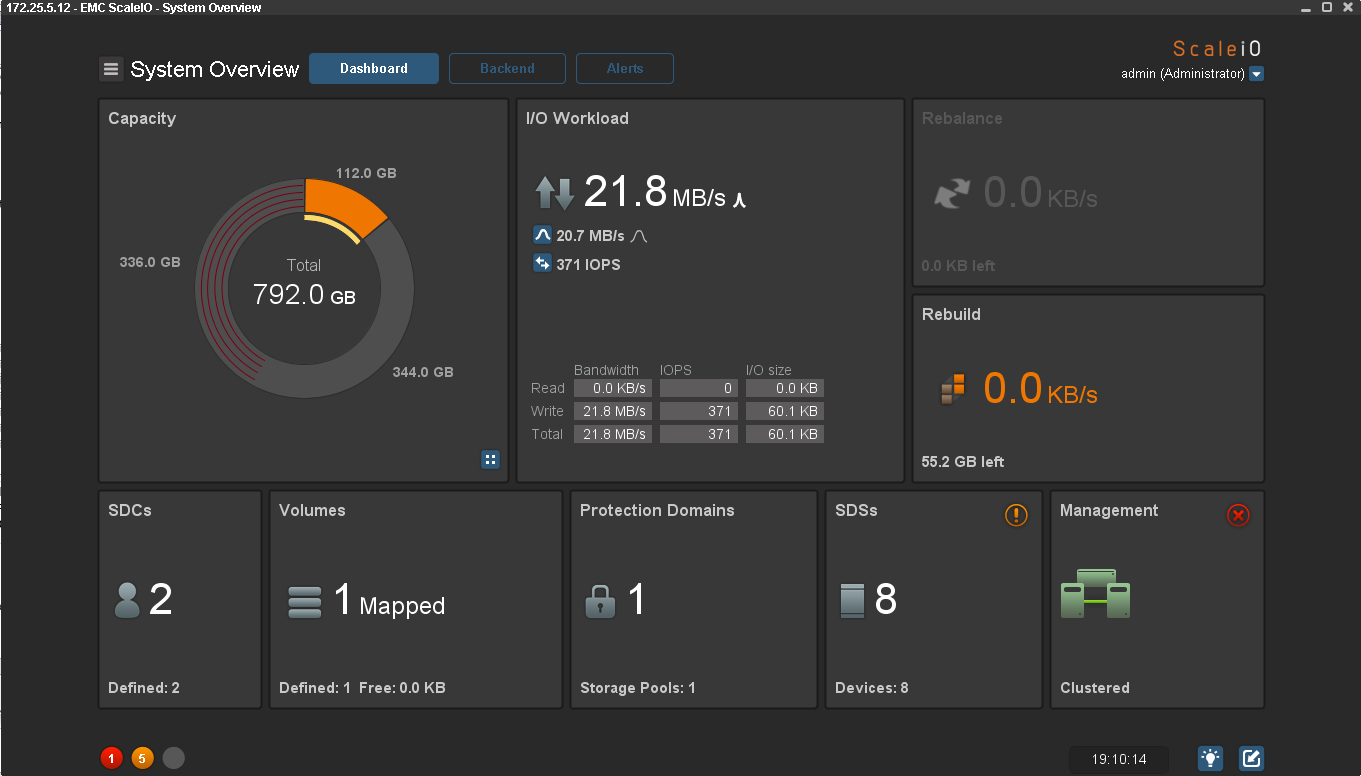
Из GUI видно, что все ноды с операционной системой Windows недоступны, а значит, данные больше не защищены избыточностью. Пул перешел в статус Degraded (рыжий цвет вместо зеленого), а IOmeter продолжает писать. Для хоста одновременный отказ половины нод прошел незаметно.
Попробуем включить 3 ноды из четырёх:
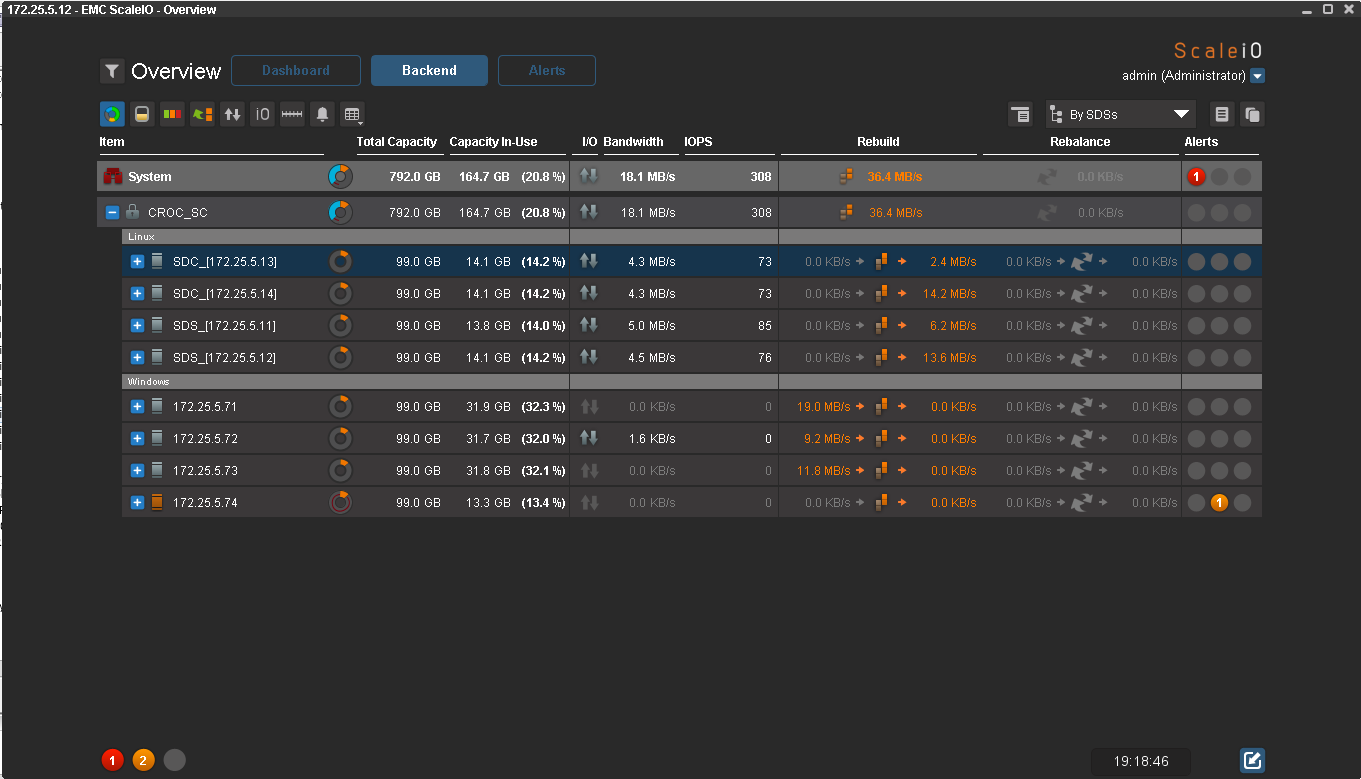
Автоматически начался ребилд, полет нормальный. Интересно, что избыточность данных будет восстановлена автоматически. Но так как сейчас нод с Windows на одну меньше, на них будет занято больше места. По мере восстановления избыточности данные будут окрашиваться в зеленый цвет.
Половина готова:
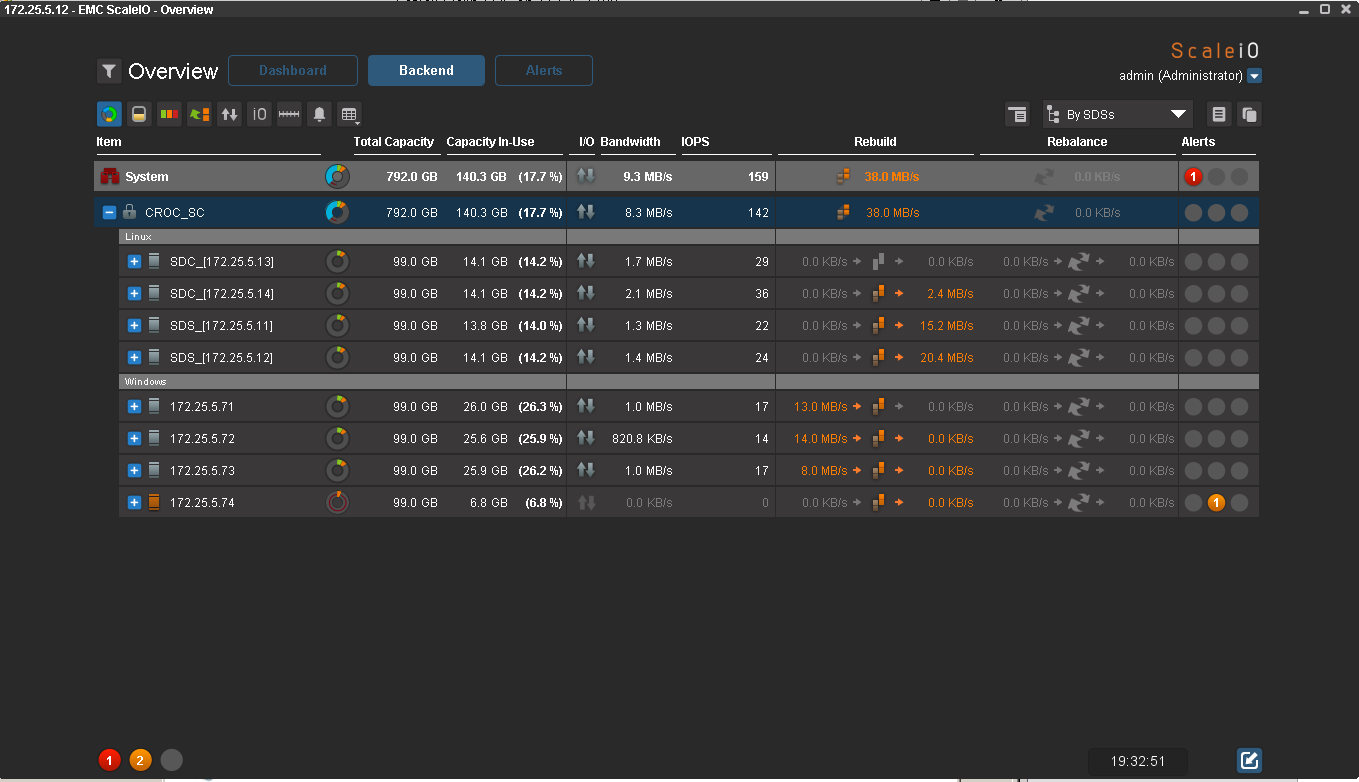
А вот теперь все:
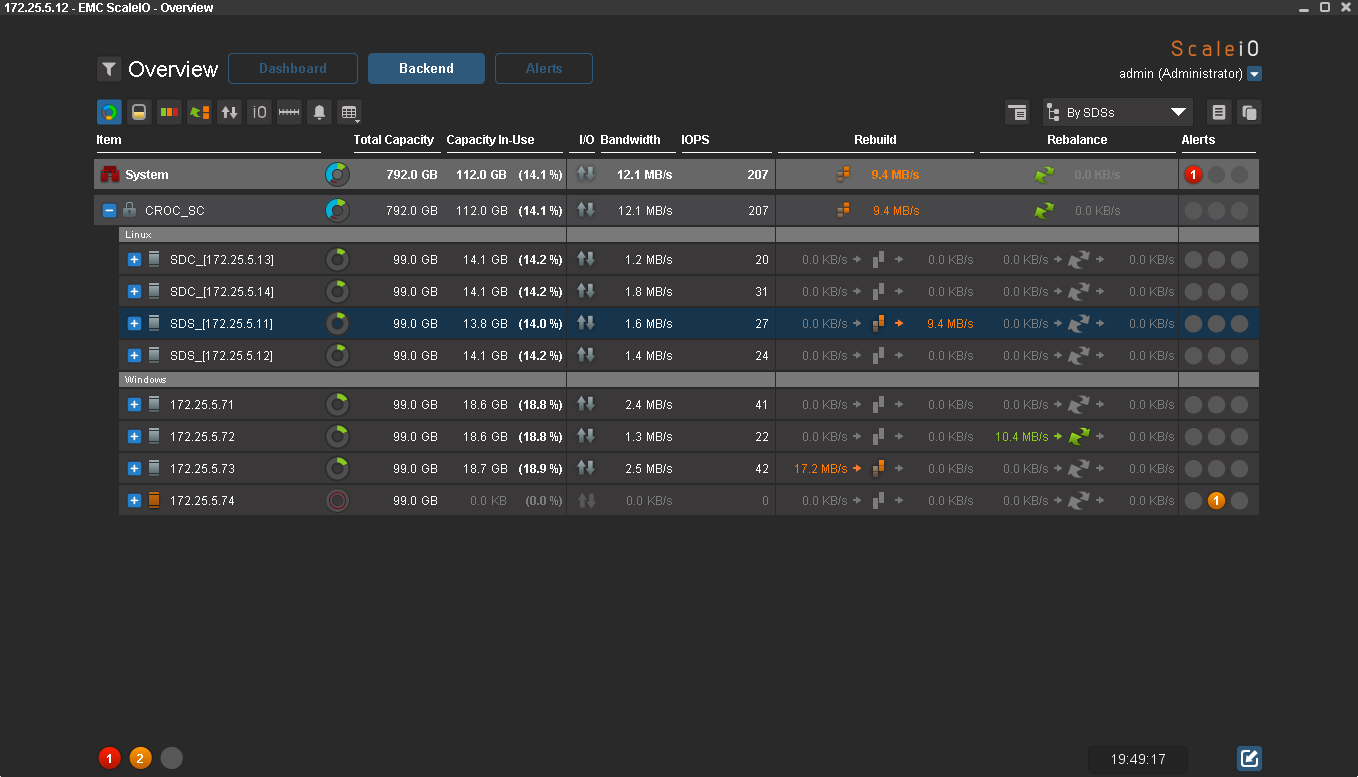
Данные полностью восстановили избыточность. На 4-й ноде сейчас ничего нет. Когда я ее включу, начнется балансировка внутри одного Failover set. То же самое происходит и при добавление новых нод.
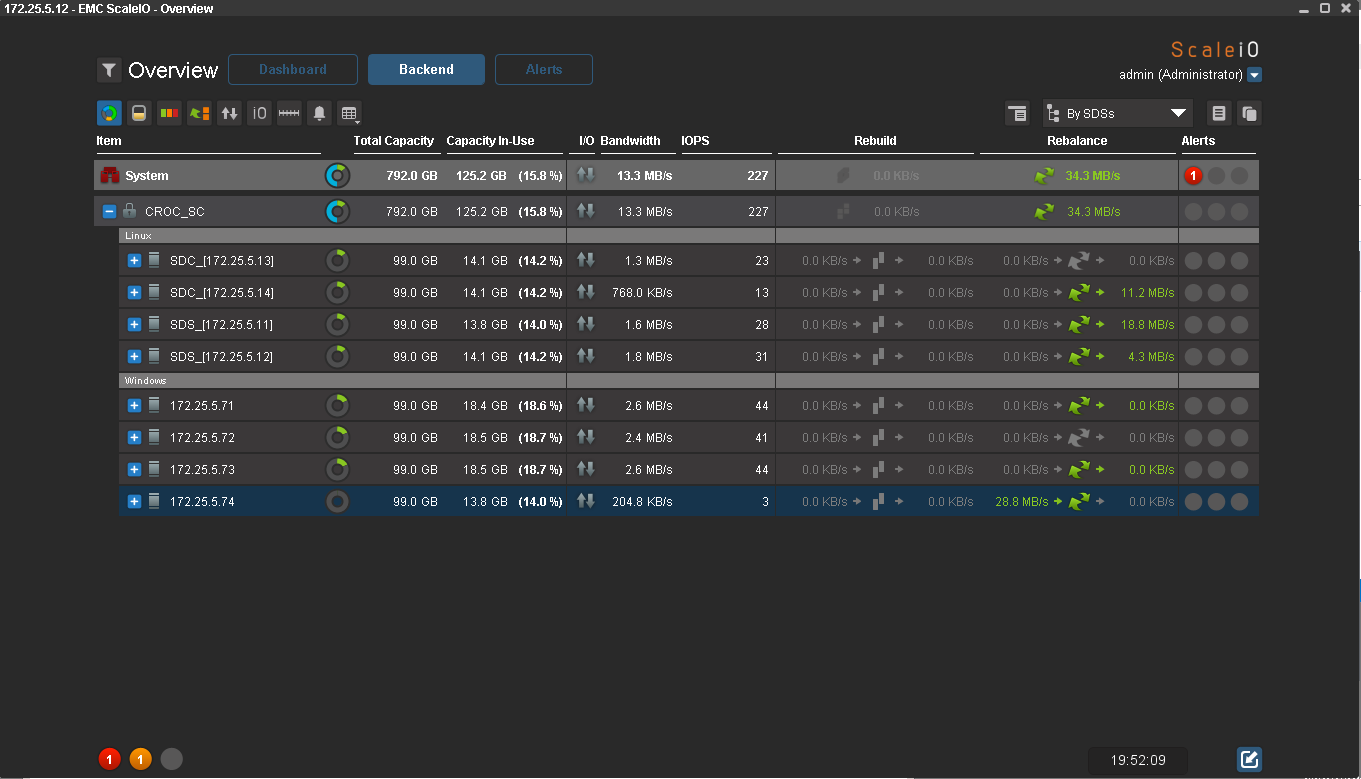
Ребаланс данных запустился. Интересно, что данные копируются со всех нод, а не только с нод того же файловер сета. После окончания ребаланса на всех нодах занято по 14% места. IOmeter по-прежнему пишет данные.
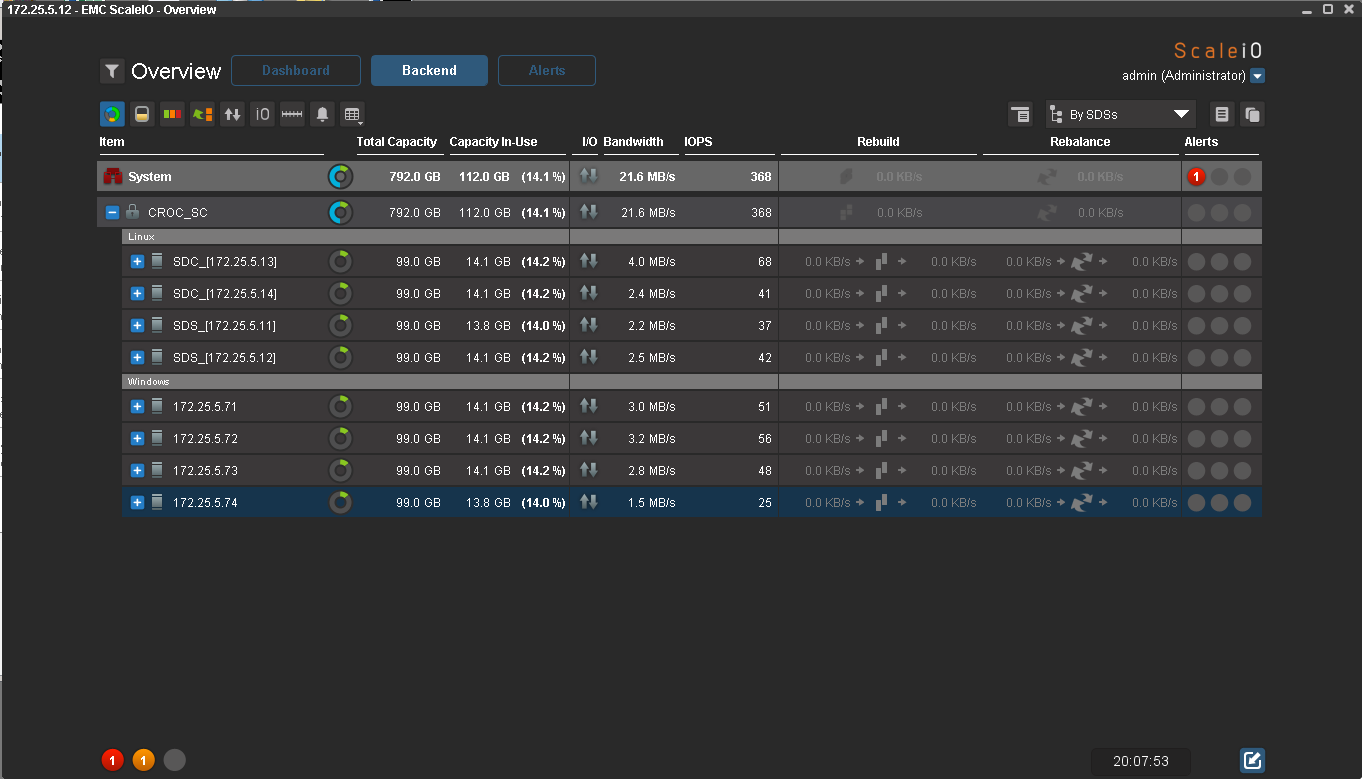
Первая итерация тестов закончилась, вторая будет на другом железе. Нужно протестировать производительность.
Цена
Политика лицензирования ScaleIO — оплата только за сырую ёмкость. Сами лицензии при этом никак не привязываются к железу. Это значит, что можно поставить ScaleIO на самое древнее железо, а через пару лет заменить его на современные серверы без докупки лицензий. Немного непривычно после стандартной политики лицензирования массивов, когда апгрейдные диски стоят дороже, чем те же самые диски при первоначальной покупке.
Прайсовая цена ScaleIO примерно 1572 долларов за терабайт сырого места. Скидки оговариваются отдельно (думаю, если вы дочитали до этого места, не надо объяснять, что такое «прайсовая» цена). У ScaleIO есть аналоги среди опенсорс-решений, и у других производителей. Но у ScaleIO важный плюс — круглосуточная поддержка EMC и огромный опыт внедрений.
Коллеги из EMC утверждают, что можно сэкономить до 60% затрат в пятилетней перспективе в сравнении с мидрейнджевой СХД. Это достигается как за счёт удешевления лицензий, так и за счёт снижения требований к железу, а также питанию, охлаждению и, соответственно, месту в дата-центре. В итоге решение получилось вполне «антикризисным». Думаю, в этом году оно много кому пригодится.
Что ещё можно сделать
- ScaleIO можно разделить на изолированные домены (это для облачных провайдеров).
- Софт умеет создавать мгновенные снимки и ограничивать скорость клиентов,
- Данные на ScaleIO можно шифровать и раскладывать по пулам с разной производительностью.
- Линейное масштабирование. С каждым новым хостом увеличивается пропускная способность, производительность и объем.
- Failover сеты позволяют терять серверы до тех пор, пока есть свободное место для восстановления избыточности данных.
- Вариативность. Можно собирать дешёвую файловую помойку на SATA-дисках, а можно быструю систему хранения с SSD-дисками.
- Вполне заменяет мидрейджевые СХД на некоторых проектах.
- Можно использовать неиспользуемое место на существующих серверах или подарить вторую жизнь старому железу.
Из минусов — требуется большое количество портов в сетевых коммутаторах и большое количество ip-адресов.
Типовые применения
- Самое очевидное — для построения публичного или частного облака компании. Решение легко расширять, ноды легко добавлять и менять.
- Для виртуализации инфраструктуры. Есть же клиенты для ESX, поэтому ничего не мешает нам сделать пул ScaleIO (можно даже на локальных дисках тех же серверов, на которых стоит ESX) и положить на него виртуальные машины. Таким образом можно обеспечить хорошую производительность и дополнительную отказоустойчивость при сравнительно небольших затратах.
- В конфигурации с SSD и Ethernet 10G, ScaleIO отлично подойдет для средних и малых баз данных.
- В конфигурации с ёмкими SATA-дисками можно сделать дешевое хранилище или архив, который, тем не менее, нельзя поместить на ленту.
- ScaleIO на SAS дисках будет отличным решением для девелоперов и тестировщиков.
- Подходит для некоторых задач видеомонтажа, когда нужно сочетание скорости надёжности и небольшой цены (нужно тестировать в прикладе под конкретику, конечно).Система может быть использована для хранения больших файлов вроде стриминга с HD-камер.
Итог
Тесты на отказоустойчивость прошли успешно. Всё идёт к тому, что старые серверы поедут обратно на тестирование производительности, а затем и в боевое использование. Если заказчик из истории в начале сделает, как задумано, кое-кто получит премию за сэкономленный некислый бюджет.
Если решение вас заинтересовало, есть желание протестировать его под конкретные задачи или просто обсудить — пишите на rpokruchin@croc.ru. На тестовом железе можно делать всё, как в том анекдоте про новую финскую бензопилу и сибирских мужиков.
