

Нода кластера: сервер отечественного производства Etegro (2 AMD Opteron 6320, 16 GB RAM, 4 HDD)
Системы хранения данных, используемые сейчас на практике в России, условно делятся на три категории:
- Очень дорогие high-end СХД;
- Мидрейнжевые массивы (тиринг, HDD, гибридные решения);
- И экономичные кластеры на базе SSD-массивов и HDD-массивов из «бытовых» дисков, часто собранные своими руками.
И не факт, что последние решения медленнее или менее надёжные, чем хайэнд. Просто используется совершенно другой подход, который не всегда подходит для того же банка, например. Но зато отлично подходит для почти всего среднего бизнеса или облачных решений. Общий смысл — берём много дешёвого чуть ли не «бытового» железа и соединяем в отказоустойчивую конфигурацию, компенсируя проблемы правильным софтом виртуализации. Пример — отечественный RAIDIX, творение петербуржских коллег.
И вот на этот рынок пришла EMC, известная своими чертовски дорогими и надёжными железками с софтом, который позволяет без проблем поднять и VMware-ферму, и виртуальную СХД, и всякий приклад на одних и тех же х86 серверах. И ещё началась история с серверов русского производства.
Русские серверы
Изначальная идея была взять наше отечественное железо и поднять на нём недостающие для импортозамещения куски инфраструктуры. Например, те же рассадники виртуальных машин, VDI-серверы, системы хранения данных для приклада и аппликейшн-серверы.
Российский сервер — это такая чудо-железка, которая на 100% собирается в России и является по всем нормам 100% отечественной. На практике — возят отдельные детали из Китая и других стран, закупают отечественные провода и делают сборку на территории РФ.
Получается не так чтобы очень плохо. Работать можно, хотя надежность ниже тех же HP. Но это компенсируется ценой железа. Дальше мы приходим к ситуации, в которой не самое стабильное железо должно компенсироваться хорошим управляющим софтом. На этом этапе мы начали экспериментировать с EMC ScaleIO.
Опыт получился хороший, в ходе экспериментов выяснилось, что железо не сильно важно. То есть — можно заменить на проверенное, от известных брендов. Получится несколько дороже, но меньше проблем с сервисом.
В итоге концепция поменялась: теперь мы говорим просто про выгоду ScaleIO на различном железе, в том числе (и в первую очередь) — из нижнего ценового сегмента.
Но к делу: результаты тестов
Вот принцип работы ScaleIO (http://habrahabr.ru/company/croc/blog/248891/) — берём серваки, набиваем их под завязку дисками (например, теми же SSD-штуками, которые предназначались для замены HDD в своё время) и соединяем всё это в кластер:

Конфигурация, проверенная нами в лаборатории в этот раз — это интеграция EMC ScaleIO и VMware. Коллеги из Etegro любезно одолжили нам 4 сервера с 2 процессорами AMD Opteron(tm) Processor 6320 и 16 GB оперативной памяти в каждом. В каждом стояло по 4 диска. Не самая ёмкая конфигурация, я бы предпочел серверы на 25 дисков 2.5 дюйма, но работать приходится с тем, что есть, а не с тем, чего хочется.
Вот серверы в стойке:

Весь объём дисков в сервере я поделил на 3 части:
- 10 Gb для ESX. Этого вполне достаточно.
- 30 GB для внутренних нужд ScaleIO, но об этом позже.
- Все остальное место будет отдано через ScaleIO.
Первое, что нужно сделать — установить VMware. ESX ставить будем по сети, так быстрее. Задача это не новая, а виртуальная машина с PXE сервером давно заняла заслуженное место в моем ноутбуке.

Как видите, в нашей лабе много тестового оборудования. Справа стоят еще 4 стойки и еще 12 на первом этаже. Мы можем собрать практически любой стенд по просьбе заказчика.
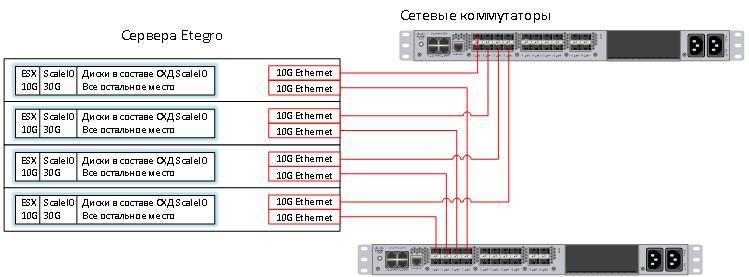
Технология работы Software Defined Storage такова, что каждая нода может запросить достаточно большое количество информации с других нод. Этот факт означает, что в таких решениях очень важны пропускная способность и время отклика BackEnd сети. 10G Ethernet хорошо подходит для решения этой задачи, а коммутаторы Nexus уже стоят в этой стойке.
Вот схема получившегося решения:
Установка ScaleIO на VMware очень проста. Фактически она состоит из 3 пунктов:
- Устанавливаем плагин для vSphere;
- Открываем плагин и запускаем инсталляцию, в этом же пункте нужно ответить на 15-20 вопросов визарда.
- Смотрим, как ScaleIO самостоятельно заползает на серверы.
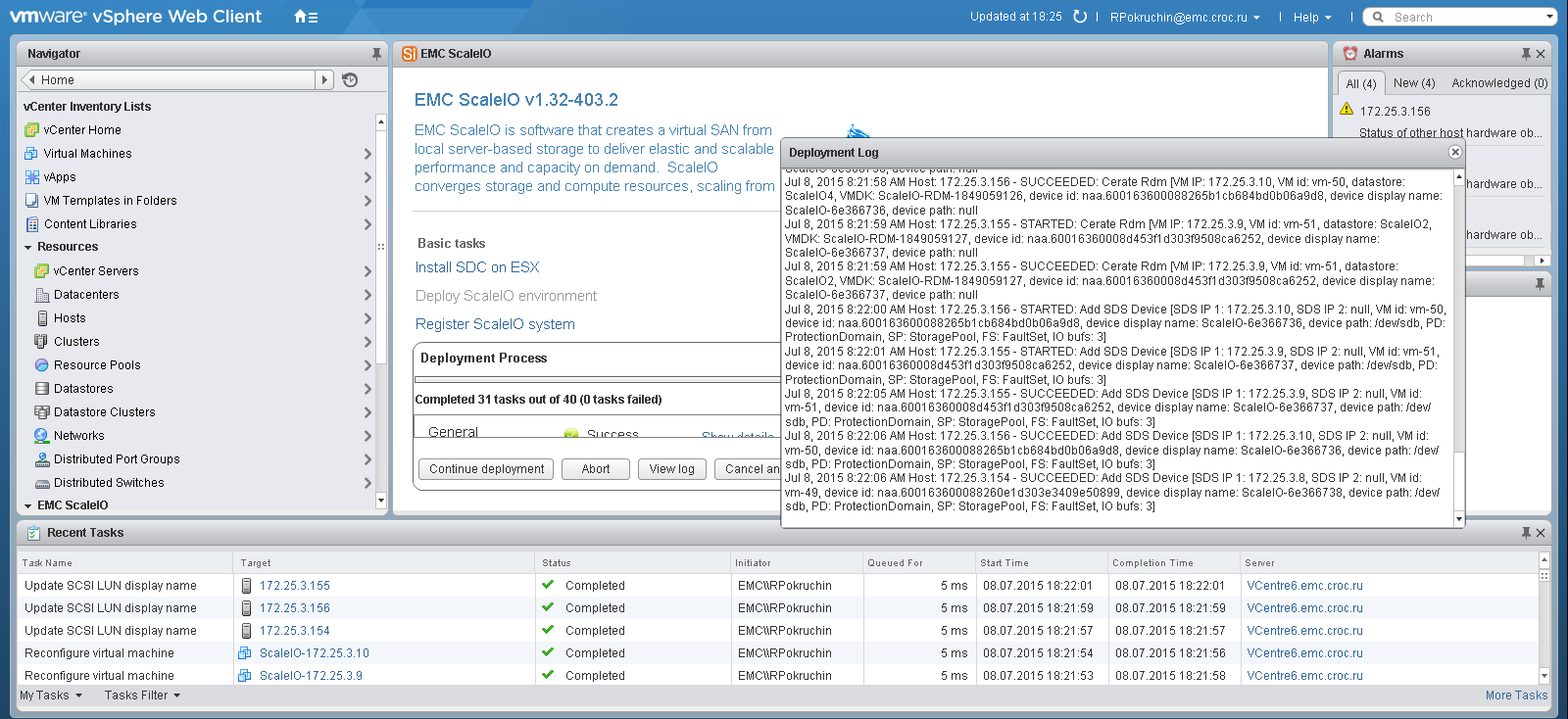
Если визард закончился без ошибок, в vSphere появится специальный раздел для ScaleIO, в котором можно создать луны и отдать их ESX серверам.
Или можно использовать стандартную консоль ScaleIO, установив ее на локальный компьютер.
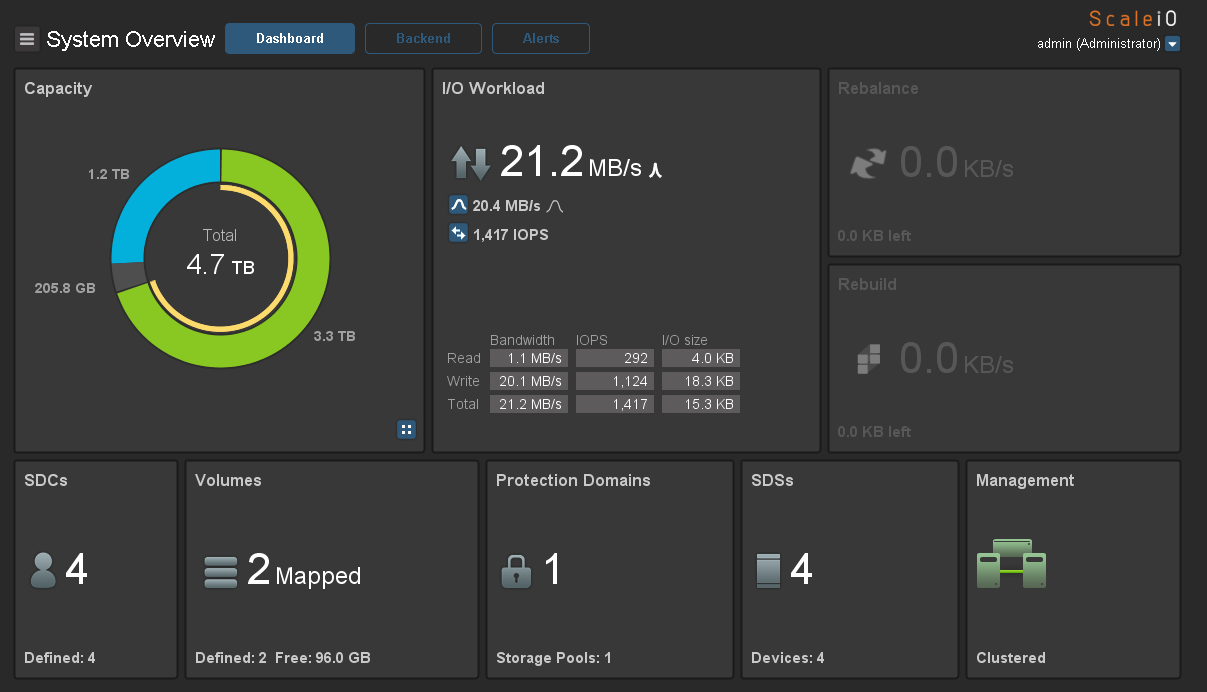
Теперь небольшой тест на производительность. Я создал на каждом хосте по виртуальной машине с 2 дисками по 50Gb и равномерно разделил их по датасторам. Нагрузку генерировал с помощью IOmeter. Вот максимальные результаты, которые мне удалось получить на нагрузке 100% random, 70% read, 2k.
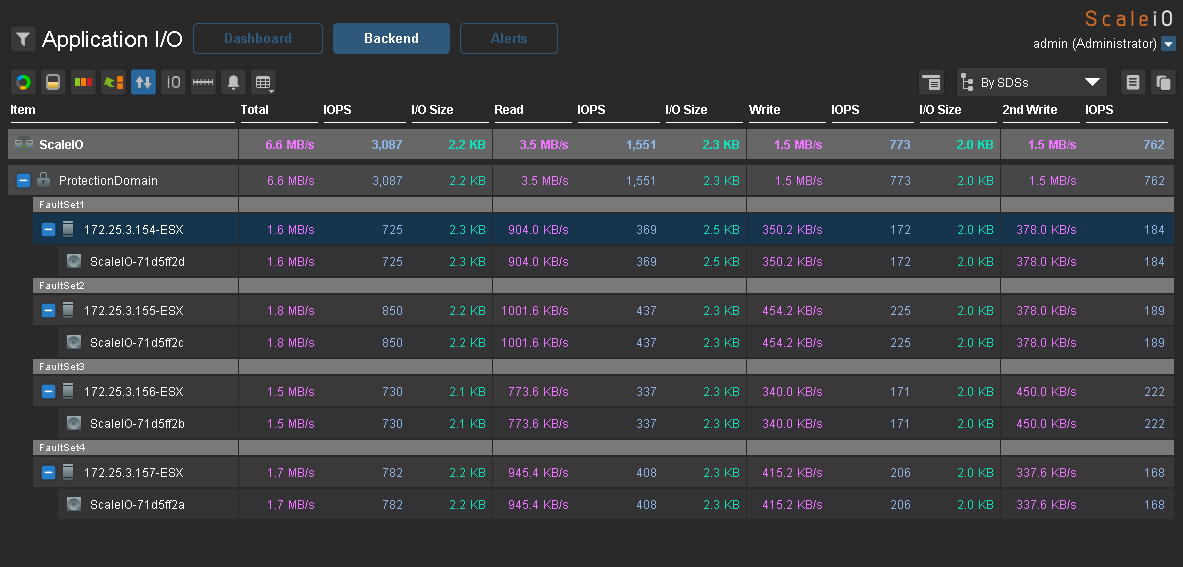
3000 application IO c 4-х серверов с SAS дисками — неплохой результат.
В качестве развлечения я попытался «завалить» систему, выдергивая ноды в разной последовательности и через разные промежутки времени. Если ноды выдергивать по одной и давать ScaleIO достаточно времени для ребилда, то виртуальные машины будут работать, даже если останется одна нода. Если отключить 3 ноды за минуту, например, доступ к общему пространству остановится до той поры, пока эти ноды не будут включены обратно. Данные становятся доступны, а массив выполняет проверку целостности данных и ребилд (если необходимо) в фоновом режиме. Таким образом, решение получается достаточно надежным для того, чтобы использовать его на боевых задачах.
Пожалуй, про виртуализацию все. Пора подвести итог.
Резюме
Плюсы:
- Цена решения (процессорные мощности + память + диски) конкурентоспособна и во многих случаях будет существенно ниже, чем серверы + СХД в аналогичных моновендорных предложениях.
- Можно использовать любое железо и получить замену «большой красивой» СХД для таких же задач. Если нужно, серверы можно заменить на более мощные без закупки каких-либо дополнительных лицензий для ScaleIO. Он лицензируется потерабайтно без привязки к железу.
- Решение конвергентное. Виртуальные машины и СХД на одном и том же сервере. Это очень удобно практически для любого среднего бизнеса. Флеш-СХД — уже не фантастика на этом уровне.
- Плюс требуется меньше места в стойках, меньше энергопотребление.
- Хорошая балансировка — равномерное распределение IO по всем дисковым ресурсам.
- Решение можно разнести на 2 разные площадки, настроив зеркалирование между ними на уровне одного кластера ScaleIO.
- Для синхронной и асинхронной репликации между кластерами можно использовать виртуальный RecoverPoint.
Минусы:
- Во-первых, придётся применить мозг. Дорогие решения, как правило, хороши тем, что внедряются очень быстро и не требуют почти никакого специального обучения. Учитывая, что ScaleIO — это, фактически, самосборное СХД, придётся разобраться в архитектуре, покурить пару форумов для оптимальной конфигурации, поставить эксперимент на своих данных для выбора оптимальной конфигурации.
- Во-вторых, за избыточность и отказоустойчивость вы платите местом на дисках. Коэффициент преобразования raw space в user space меняется в зависимости от конфигурации, и, возможно, вам потребуется больше дисков, чем вы думали изначально.
Напоминаю, вот здесь можно прочитать про софтверную часть подробно, а я же с удовольствием отвечу на вопросы в комментариях или почте RPokruchin@croc.ru. А ещё через месяц, 26 ноября, мы с коллегами будем делать открытый тест-драйв с Scale IO пылесосом Керхер, кувалдой и другими штуками, пока мужики не скажут: «Аааа, заррраза». Регистрация тут.
