
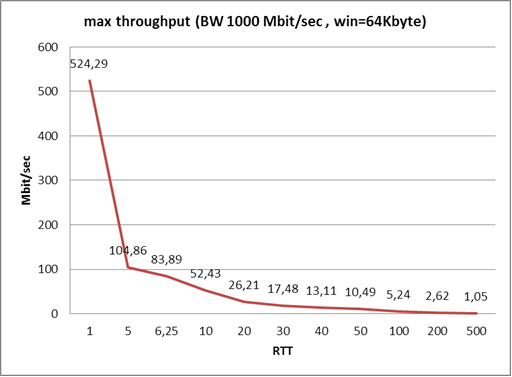
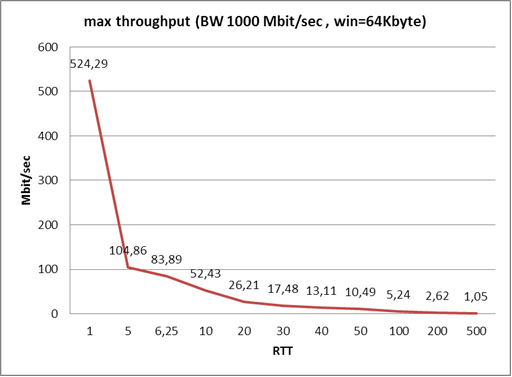
Вот этот график показывает, как сетевая задержка влияет на максимальную скорость при использовании TCP. Проще говоря, если у вас пинг 500 миллисекунд, то при доступной полосе пропускания 6, 10, 100, 500 и т. д. мегабит трафик между двумя хостами у вас не разгонится выше одного мегабита.
Моя команда занимается оптимизацией каналов связи. Иногда удаётся поправить всё буквально парой кликов вручную, но чаще нужно устанавливать специальные устройства, которые существенно ужимают обмен и превращают протоколы в более «оптимистичные» или «предиктивные».
Что такое «оптимистичный» протокол? Очень примерно — это когда удалённый сервер ещё не ответил, что можно отправлять следующий фрейм, а железка уже говорит «посылай», потому что знает, что шанс успеха — 97%. Если вдруг что-то пойдёт не так, она уже сама дошлёт нужный пакет, не беспокоя отправляющий сервер.
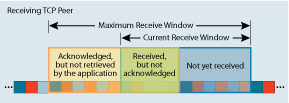
Есть такое понятие, как RWIN (https://en.wikipedia.org/wiki/TCP_tuning). Это размер окна.
Раньше, когда транзисторы были большими (это 2004–2005 год), ограничение было 64К. Соответственно и скорости, и задержки, и приложения были другими. И проблем на этом этапе не было. Они начали возникать, когда сети стали шустрее, а приложения прожорливее (в смысле стали больше есть трафика). У компаний возникла потребность в расширении полосы, чтобы всё быстро функционировало. Однако работало всё хорошо только до определённых моментов, которые можно на нижеуказанном графике и поймать. Причём современные ОС в корпоративных сетях научились бороться с так называемой проблемой «потолка» в автоматическом режиме и прозрачно для пользователей. Но ведь есть и старые ОС, а ещё целые зоопарки различных ОС и стеков…
Изначально TCP Receive Window ограничено 64K (времена WinXP). В современных версиях протокола поддерживаются и большие размеры фрейма (а это часто нужно), но обмен начинается именно с малых.
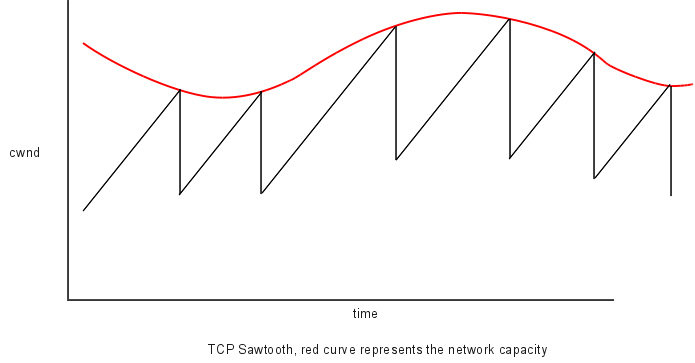
Есть такое понятие, как «TCP пила». Значит это следующее: при обмене данными в TCP каждый раз, когда рассылается несколько фреймов, передающая сторона увеличивает их количество, переданных за один раз. На диаграмме видно, что до определённого момента мы можем увеличивать это количество, но один раз мы всё-таки упрёмся в потолок и начнутся потери.
Когда произойдут потери, RWIN будет автоматически снижен в два раза. Так, если пользователь скачивал какой-либо файл, можно увидеть, что он вроде как разгоняется, но потом падает. Такое поведение должно быть многим знакомо.
Очень хорошего эффекта для сети со старыми роутерами и большим количеством беспроводных хопов можно добиться, меняя размер окна: надо стараться получить максимальный unscaled RWIN (до 65535 байт) и использовать минимальный фактор масштаба (RFC 1323, scale factor). Новые Windows выбирают размер фрейма самостоятельно, и делают это хорошо.
Пока всё просто: очень упрощая, мы передаём 64K, затем ждём ответа, затем передаём 64K. Если ответ приходит с нефтедобывающего комплекса через полпланеты и геостационарную орбиту — угадайте, какая будет эффективная скорость. На самом деле всё чуть сложнее, но проблема та же. Поэтому нужны пакеты больше.
Работа с RWIN — самое простое, что можно сделать уже сейчас на спутниковом канале (одна настройка решает очень много проблем). Пример: если ваши пакеты летят до спутника, потом обратно на землю, ждут ответа сервера, потом летят на спутник и обратно к вам. Для геостационарного спутника и приёмных станций по нормали к нему это означает задержку в 500 мс. Если прыжок длиннее (станции образуют треугольник), можно получить и пару секунд. В моей практике были случаи с ретрансляторами, отправляющими информацию снова через спутник (уже другой, который не видит за планетой первый телепорт в точке отправления), — там можно поймать 3–4 секунды, но это уже отдельная разновидность коммуникационного ада.

Теперь самое весёлое. Для протоколов, работающих с окнами-фреймами, максимальная пропускная способность определяется шириной канала и задержкой. Соответственно, оптимальный размер пакета (или сборки пакетов в одном фрейме, если используется промежуточная оптимизация) должен быть тем больше, чем шире канал, чтобы максимально использовать его возможности. Прикладное значение проще: нужно знать отношение RWIN/BDP (Bandwidth Delay Product) — интегральный показатель задержки передачи. Вот тут его можно посчитать для пакета unscaled 64k.
Следующий логический шаг — определить оптимальное TCP Receive Window — вот тест, посмотрите.
Определение максимального размера сегмента (MSS) и выставление его потом в настройках обмена сильно ускоряет процесс. Точнее, доводит его до теоретического максимума при вашей задержке. Win7 и 2008 Server умеют следующее: начинают с очень маленького окна (около 17520 байт), затем повышают его автоматически, если инфраструктура между узлами позволяет. Затем включается автонастройка RWIN, но она довольно ограничена. В Win10 границы автонастройки чуть раздвинуты.
Вы можете вручную управлять RWIN, и это может поменять ситуацию на медленных сетях. По крайней мере пару раз мы так спасали заказчика от покупки дорогого оборудования. Если окно репликации 24 часа, а получается только за 26, то, вполне возможно, настройка канала и тюнинг собственного сжатия разных узлов позволит упасть до 18–19, чего достаточно. С оптимизатором можно и до 6–7 при болтливом обмене, но иногда задача уже решается. Или откладывается на пару лет.
Оптимизаторы (дальше мы говорим про семейство Riverbed Steelhead — я их поставил уже сотни на разных месторождениях полезных ископаемых, и потому буду опираться на практику) — так вот, они умеют «избавлять» TCP от присущих ему недостатков фреймового протокола за счёт трансляции в свой транспортный протокол. Если обмен идёт между двумя узлами Ривербеда, то трансляция выглядит так:

Теперь давайте посмотрим на то, как эти милые устройства работают с оптимизацией уровнями повыше. У Steelhead вообще есть 3 техники оптимизации: data streamlining (дедупликация), transport streamlining (оптимизация транспорта, про это говорили выше) и application streamlining (это ниже).
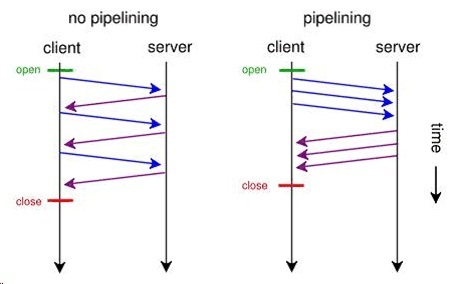
HTTP — старый добрый протокол для работы с сайтами. Старый — не то слово, и оптимизировать там есть что. Например, открывать дополнительные соединения в тот момент, когда становится понятно, какие ещё объекты грузить. Современные браузеры умеют делать это «из коробки»:
У него очень муторная аутентификация:

Которую в оптимистичном случае можно ужать до двух пакетов — надо просто спросить у отправляющего узла всё это за один раз, затем отдать Ривербеду на принимающем узле, а он уже «поговорит» с кем надо. Очень круто для корпоративных порталов.
При нескольких открытых соединениях есть проблемы повторных авторизаций при так называемом connection jumping, когда одно из соединений отдаёт 401 и часть запросов хендшейка падает в первое, уже аутентифицированное.
Основные типы оптимизации следующие:
Есть возможность оптимизировать HTTPS и SSL-приложения, в том числе на нестандартных портах. На нашей практике такое встречалось не раз. В современных версиях софта для Steelhead можно оптимизировать интернет-трафик, если пользователи постоянно ходят на какие-то защищённые порталы (весь интернет-трафик загонять в оптимизацию нецелесообразно), и в том числе, если для доступа в интернет используется прокси-сервер.
Есть оптимизация Office365. Можно также работать и с корпоративным прокси.
CIFS/SMB — протокол 1990 года для обмена файлами между узлами сети. Используется также для сетевой печати. Ривербед слушает оба его стандартных TCP-порта (445 и 139). Точные методы оптимизации не раскрываются, но речь идёт о сборке пакетов в оптимальные по размеру для канала, излишние блокировки на быстром узле, поддержание часто возникающих сессий (удержание их открытыми до фактической необходимости), перекладывание части защиты на пару устройств Steelhead вместо собственной нагрузки на узлы. В Win10 и Server16 для SMB 3.1.1 есть механизм pre-authentication integrity — некий его аналог реализуется на старых версиях протокола Стилхедами. Аналогичные методы используются для других файловых протоколов. Устройства поддерживают все версии SMB до 3.1.1, в т. ч. Signed-SMB.
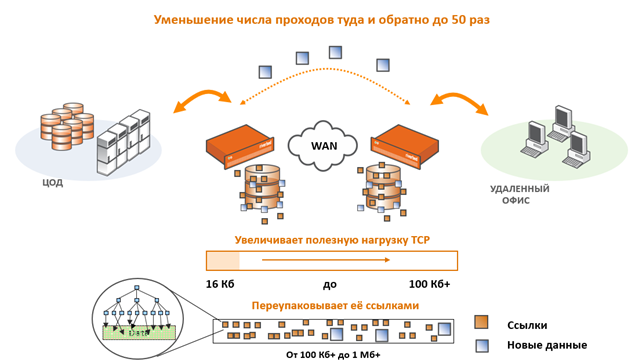
Вот здесь описано, как происходит сжатие и увеличивается полезная нагрузка TCP. Очень актуально для передачи файлов.
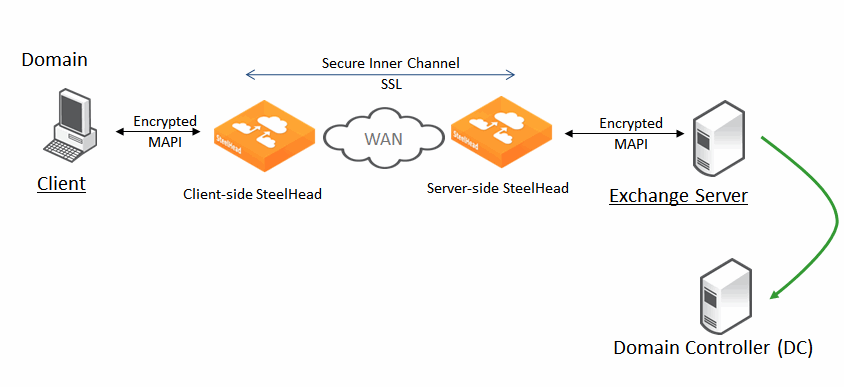
MAPI (over HTTP, Signed-MAPI и Office365) — обмен почтой между Outlook-клиентами и Exchange-серверами. У него довольно долгая процедура хендшейка:

Оптимизация достигается за счёт поддержания этой сессии открытой (Ривербед её перехватывает и удерживает 96 часов), эффективного обмена подтверждениями, потоковым чтением почты и вложений (фактически кешированием того, что клиент ещё не начал получать по факту).
Сам трафик хорошо сжимается/дедуплицируется и избавляется от избыточности:

В кластерных инсталляциях также очень помогает метод предопределения портов.
У меня был случай, когда HR-спец по праздникам ронял всю сеть очень далёкого офиса банка. Расследование показало, что его пожилая коллега слала почтой BMP-открытку под 10 Мегабайт. Стилхед «понял», что сотрудники в 10 утра открывают почту, и стал по ночам собирать почту на себя. И заодно сжимать эти чёртовы открытки, фактически обеспечивая дедупликацию от 10 писем до одного и сжатие этого эталонного образца. Раньше люди приходили в 10, а работать начинали в 10:30, как всё «пролезет». Сейчас же поводов для грусти не стало, начало работы строго по расписанию.
В банках используется много систем дистанционного обучения, это очень удобно для сотрудников. На удалённых филиалах почти вся полоса забивается обучающими видео. Ривербед с http-потоком может делать вот такую штуку, как на картинке. В результате каналы не «страдают» от такого трафика. Но это предиктивная механика, видео в реальном времени (видео-конференц-связь, например), можно только приоритизировать.
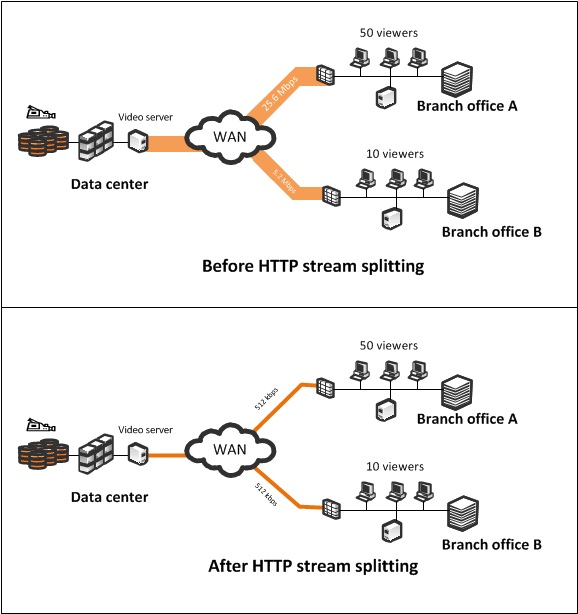
Речь про HTTP-поток, а не RTP/RSTP
Следующая механика — Prepopulation. Если мы знаем заранее — вот есть офис, и у него имеются сетевые диски, и при этом маркетинг работает со своей одной папкой, а оптимизация и контроль сети — со своей. Если мы также знаем, что в каком-то филиале сидят определённые отделы, которые пользуются конкретными сетевыми папками, то можно научить Ривербед самостоятельно на них ходить (указать ему эти пути). Он поймет, что там за файлы лежат, насколько быстро они запрашиваются. Таким образом, много сессий не будет открываться, Ривербед сам «притворится» клиентом и сходит по сетевым шарам, соберёт всё, что там есть, и самый часто используемый контент заберёт на себя. Итого: на следующий день сотрудник приходит в офис, и он может уже воспользоваться без задержек доступом к дальней стороне. Соответственно, получит обновлённую информацию.
Прочие протоколы разбираются по схеме оптимизации протокола низкого уровня (чаще всего речь о размере фрейма и выставлении оптимального времени жизни пакета под канал) — даже если каналу нужны большие фреймы, а протокол хочет отправлять маленькими, Стилхеды умеют перебирать всё это в свой формат, дедуплицировать и отправлять как надо. Затем поток дедуплицируется-сжимается-кешируется-предугадывается. «Болтливые» последовательности выявляются и переводятся на оптимистичные ответы.
Ещё есть connection pooling — когда Стилхед держит 20лишних сессий уже открытыми под текущие нужды. Это очень актуально на спутнике.
На стандартном окне в 64K ещё много кто работает — и это сильно бьёт по обмену. Например, между ЦОДами в Хабаровске и Москве на канале 100 Мбит/с при задержке 80мс скорость репликации на стандартных средствах — 5 Мегабит/c. Сюрприз! Надо менять размер окна и потом делать всё остальное. Опять же, тот же Офис365 имеет ближайшие Azure-ЦОД в Амстердаме и Дублине. С помощью линейки и калькулятора по ссылке выше можно прикинуть задержку. Ещё трафик из того же Хабаровска идёт через Москву (хотя через азиатский Azure-ЦОД ближе).
А ещё есть потери. На спутнике — это 5% от погоды запросто. Какие-то пакеты застревают в тумане, некоторые не проходят через снежинки, а большой и толстый пакет может обогатить информацией голубя. Или ворону, прилетевшую склёвывать плёнку с транспондера (правда, к счастью, на больших телепортах они быстро закипают и соскальзывают с зеркала). Кстати, поддержка SCPS помогает.
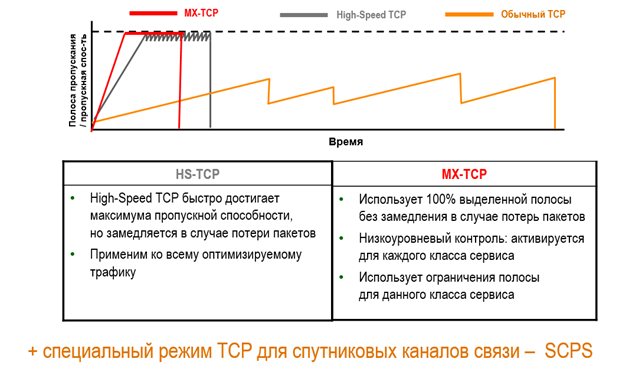
Кроме манипуляций с размерами фрейма, Riverbed SteelHead умеет использовать оптимальные механизмы контроля перегрузок (congestion avoidance). От NewReno до специфических MX-TCP и HSTCP. Последние помогают избежать проблемы с высоким BDP и проблемой TCP slow start, то есть, зная ширину канала, мы можем давать определённому трафику сразу всю полосу.
С выходом нового софта появляются новые фичи. Начиная с версии 9.0 появился полноценный DPI и можно классифицировать трафик по приложениям. Встроенные возможности Стилхедов по приоритизации и разбору трафика ещё хорошо использовать для задания сетевых политик. Например, на нефтебуровых часто используется следующая механика: сначала технический трафик, потом видеопакеты ВКС руководства, потом офис, потом личный трафик сотрудников. Теперь бурильщик Вася, качающий новую 20-мегабайтную гифку с котом, не перебьёт трафик руководству.
Или вот был объект под Ленском. Там очень прошаренные админы, они выжали из канала всё, что могли. Почитали наши прошлые посты, попросили железку на тест. Главная проблема — не самые быстрые RDP-подобные соединения, люди бесятся. А это у них основной способ доступа к бизнес-приложениям. Во время высокой загрузки канала (а он ещё и несимметричный) пользователи бизнес-приложений начали испытывать проблемы в доступе по RDP. Оптимизация у них уже была встроенная в спутниковые модемы, но только на уровне транспорта, поэтому искали другое решение. Поставили риверы — волосы стали мягкими и шелковистыми, нагрузка спала в 3 раза. Потом натолкнулись на костыль спутникового модема, — при выключении встроенной оптимизации по дефолту устанавливались катастрофически маленькие размеры очереди TCP (TCP queue length). Это очень сильно вредило Ривербедам. Тоже подобрали оптимальные параметры. В итоге RPD-подобия стабильно работают, файлы качаются быстрее — люди вахтами сидят и делают что-то круглосуточно. Ситуация такая же, как и у бурильщика Васи: он качает 20мб гиф с котом быстрее, никому не вредит, и все счастливы.
Вот ещё один пример. В открытых водах есть большие суда — фабрики на траулерах. И там
свежепойманная рыба сразу же закатывается в консервы. Производство там управляется через сеть, в рамках процесса осуществляется обмен данными.
Но как раз двойные спутниковые прыжки или неприятные переходы «спутник — 2G — оптика». Им поставили оптимизаторы — там наступило всем счастье. И компании в плане контроля бизнес-процессов, и сотрудникам в плане улучшений условий труда, т. к. у них появилась возможность коммуницировать с семьями, обмениваться фото/видео.
Набор Стилхедов преимущественно берут в следующих случаях:
На самом деле сценариев гораздо больше, но чаще всего все они рождаются вследствие одной проблемы – медленной работы пользователей с бизнес-приложениями. Я перечислил наиболее встречаемые.
Магия Ривербед начинает работать на 3G-каналах, спутниковых каналах, 3G-радиорелейных хопов, двойных спутниковых прыжков, 2G-4G-хопов, а также на широких каналах 10G и c задержкой в 2–5 мс. Лучше всего это окупается в России при использовании спутниковых каналов, которые шире физически не сделать, а надо.
Раньше каналы стоили нереальных денег, но сейчас они дешевеют в большей части страны. Чаще всего к нам обращаются в основном банки и добывающий сектор.
Для многих это всё ещё откровение, что расширение каналов связи не приводит к повышению эффективности их работы, что задержка влияет на пропускную способность канала и бесконечно расширять канал нельзя. Часто, когда сталкиваются с такой проблемой, например, медленной репликации, медленных приложений, начинают расширять каналы. И чаще всего это не помогает. Вот, собственно, об этом я и хотел рассказать. Надеюсь, получилось.
Моя команда занимается оптимизацией каналов связи. Иногда удаётся поправить всё буквально парой кликов вручную, но чаще нужно устанавливать специальные устройства, которые существенно ужимают обмен и превращают протоколы в более «оптимистичные» или «предиктивные».
Что такое «оптимистичный» протокол? Очень примерно — это когда удалённый сервер ещё не ответил, что можно отправлять следующий фрейм, а железка уже говорит «посылай», потому что знает, что шанс успеха — 97%. Если вдруг что-то пойдёт не так, она уже сама дошлёт нужный пакет, не беспокоя отправляющий сервер.
Окна и задержки
Есть такое понятие, как RWIN (https://en.wikipedia.org/wiki/TCP_tuning). Это размер окна.
Раньше, когда транзисторы были большими (это 2004–2005 год), ограничение было 64К. Соответственно и скорости, и задержки, и приложения были другими. И проблем на этом этапе не было. Они начали возникать, когда сети стали шустрее, а приложения прожорливее (в смысле стали больше есть трафика). У компаний возникла потребность в расширении полосы, чтобы всё быстро функционировало. Однако работало всё хорошо только до определённых моментов, которые можно на нижеуказанном графике и поймать. Причём современные ОС в корпоративных сетях научились бороться с так называемой проблемой «потолка» в автоматическом режиме и прозрачно для пользователей. Но ведь есть и старые ОС, а ещё целые зоопарки различных ОС и стеков…
Изначально TCP Receive Window ограничено 64K (времена WinXP). В современных версиях протокола поддерживаются и большие размеры фрейма (а это часто нужно), но обмен начинается именно с малых.

Есть такое понятие, как «TCP пила». Значит это следующее: при обмене данными в TCP каждый раз, когда рассылается несколько фреймов, передающая сторона увеличивает их количество, переданных за один раз. На диаграмме видно, что до определённого момента мы можем увеличивать это количество, но один раз мы всё-таки упрёмся в потолок и начнутся потери.
Когда произойдут потери, RWIN будет автоматически снижен в два раза. Так, если пользователь скачивал какой-либо файл, можно увидеть, что он вроде как разгоняется, но потом падает. Такое поведение должно быть многим знакомо.
Очень хорошего эффекта для сети со старыми роутерами и большим количеством беспроводных хопов можно добиться, меняя размер окна: надо стараться получить максимальный unscaled RWIN (до 65535 байт) и использовать минимальный фактор масштаба (RFC 1323, scale factor). Новые Windows выбирают размер фрейма самостоятельно, и делают это хорошо.
Пока всё просто: очень упрощая, мы передаём 64K, затем ждём ответа, затем передаём 64K. Если ответ приходит с нефтедобывающего комплекса через полпланеты и геостационарную орбиту — угадайте, какая будет эффективная скорость. На самом деле всё чуть сложнее, но проблема та же. Поэтому нужны пакеты больше.
Работа с RWIN — самое простое, что можно сделать уже сейчас на спутниковом канале (одна настройка решает очень много проблем). Пример: если ваши пакеты летят до спутника, потом обратно на землю, ждут ответа сервера, потом летят на спутник и обратно к вам. Для геостационарного спутника и приёмных станций по нормали к нему это означает задержку в 500 мс. Если прыжок длиннее (станции образуют треугольник), можно получить и пару секунд. В моей практике были случаи с ретрансляторами, отправляющими информацию снова через спутник (уже другой, который не видит за планетой первый телепорт в точке отправления), — там можно поймать 3–4 секунды, но это уже отдельная разновидность коммуникационного ада.
Теперь самое весёлое. Для протоколов, работающих с окнами-фреймами, максимальная пропускная способность определяется шириной канала и задержкой. Соответственно, оптимальный размер пакета (или сборки пакетов в одном фрейме, если используется промежуточная оптимизация) должен быть тем больше, чем шире канал, чтобы максимально использовать его возможности. Прикладное значение проще: нужно знать отношение RWIN/BDP (Bandwidth Delay Product) — интегральный показатель задержки передачи. Вот тут его можно посчитать для пакета unscaled 64k.
Следующий логический шаг — определить оптимальное TCP Receive Window — вот тест, посмотрите.
Определение максимального размера сегмента (MSS) и выставление его потом в настройках обмена сильно ускоряет процесс. Точнее, доводит его до теоретического максимума при вашей задержке. Win7 и 2008 Server умеют следующее: начинают с очень маленького окна (около 17520 байт), затем повышают его автоматически, если инфраструктура между узлами позволяет. Затем включается автонастройка RWIN, но она довольно ограничена. В Win10 границы автонастройки чуть раздвинуты.
Вы можете вручную управлять RWIN, и это может поменять ситуацию на медленных сетях. По крайней мере пару раз мы так спасали заказчика от покупки дорогого оборудования. Если окно репликации 24 часа, а получается только за 26, то, вполне возможно, настройка канала и тюнинг собственного сжатия разных узлов позволит упасть до 18–19, чего достаточно. С оптимизатором можно и до 6–7 при болтливом обмене, но иногда задача уже решается. Или откладывается на пару лет.
Оптимизаторы (дальше мы говорим про семейство Riverbed Steelhead — я их поставил уже сотни на разных месторождениях полезных ископаемых, и потому буду опираться на практику) — так вот, они умеют «избавлять» TCP от присущих ему недостатков фреймового протокола за счёт трансляции в свой транспортный протокол. Если обмен идёт между двумя узлами Ривербеда, то трансляция выглядит так:

Теперь давайте посмотрим на то, как эти милые устройства работают с оптимизацией уровнями повыше. У Steelhead вообще есть 3 техники оптимизации: data streamlining (дедупликация), transport streamlining (оптимизация транспорта, про это говорили выше) и application streamlining (это ниже).
HTTP — старый добрый протокол для работы с сайтами. Старый — не то слово, и оптимизировать там есть что. Например, открывать дополнительные соединения в тот момент, когда становится понятно, какие ещё объекты грузить. Современные браузеры умеют делать это «из коробки»:

У него очень муторная аутентификация:

Которую в оптимистичном случае можно ужать до двух пакетов — надо просто спросить у отправляющего узла всё это за один раз, затем отдать Ривербеду на принимающем узле, а он уже «поговорит» с кем надо. Очень круто для корпоративных порталов.
При нескольких открытых соединениях есть проблемы повторных авторизаций при так называемом connection jumping, когда одно из соединений отдаёт 401 и часть запросов хендшейка падает в первое, уже аутентифицированное.
Основные типы оптимизации следующие:
- Отключение компрессии передающего и принимающего узла и сборка пакетов в пачки. Если отключить сжатие каждого отдельного пакета, то можно отлично дедуплицировать множественные повторяющиеся. По факту это будет означать, что для однажды переданного пакета, похожего на следующий передающийся, можно отправлять только номер ближайшего похожего и разницу. Это существенно меньше, чем два сжатых пакета.
- Вставка куков. Некоторые сервера требуют хранения определённых технических данных, которые примерно одинаковы для всех пользователей и редко меняются. Их можно положить в кеш. Кроме того, если ваш узел не поддерживает cookie, эта поддержка может быть включена на оптимизаторе трафика.
- Поддержка соединений — тут всё просто: если не отпускать сессию, то не придётся авторизовываться заново.
- URL-обучение. Пользователи ходят одними и теми же дорожками, поэтому оптимизатор может довольно быстро выучить повадки офиса и часть кешировать, часть положить в быстрый доступ на предзапросе и так далее.
- Предсказание запросов. Например, если через Стилхед проходит страница с тегом img, логично предположить, что через несколько миллисекунд принимающий сервер запросит и саму картинку. Ривербед использует оптимистичный подход и не ждёт этого, а просто запрашивает сразу. Когда ваш сервер посылает запрос, Ривербед его перехватывает и отдаёт то, что уже получил.
- Префетчингу также отлично поддаются открываемые сессии.
- Принудительный NTLM, если возможно (это быстрее).
- Стандартные методы избавления от лишних заголовков.
- «Gratuitos 401» — браузеры часто делают лишний GET, которого можно избежать.
Есть возможность оптимизировать HTTPS и SSL-приложения, в том числе на нестандартных портах. На нашей практике такое встречалось не раз. В современных версиях софта для Steelhead можно оптимизировать интернет-трафик, если пользователи постоянно ходят на какие-то защищённые порталы (весь интернет-трафик загонять в оптимизацию нецелесообразно), и в том числе, если для доступа в интернет используется прокси-сервер.
Есть оптимизация Office365. Можно также работать и с корпоративным прокси.

CIFS/SMB — протокол 1990 года для обмена файлами между узлами сети. Используется также для сетевой печати. Ривербед слушает оба его стандартных TCP-порта (445 и 139). Точные методы оптимизации не раскрываются, но речь идёт о сборке пакетов в оптимальные по размеру для канала, излишние блокировки на быстром узле, поддержание часто возникающих сессий (удержание их открытыми до фактической необходимости), перекладывание части защиты на пару устройств Steelhead вместо собственной нагрузки на узлы. В Win10 и Server16 для SMB 3.1.1 есть механизм pre-authentication integrity — некий его аналог реализуется на старых версиях протокола Стилхедами. Аналогичные методы используются для других файловых протоколов. Устройства поддерживают все версии SMB до 3.1.1, в т. ч. Signed-SMB.
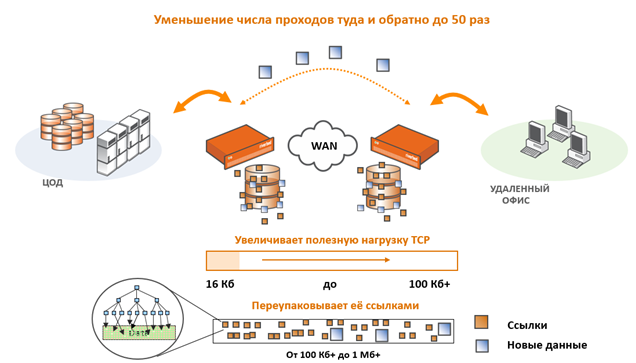
Вот здесь описано, как происходит сжатие и увеличивается полезная нагрузка TCP. Очень актуально для передачи файлов.
MAPI (over HTTP, Signed-MAPI и Office365) — обмен почтой между Outlook-клиентами и Exchange-серверами. У него довольно долгая процедура хендшейка:
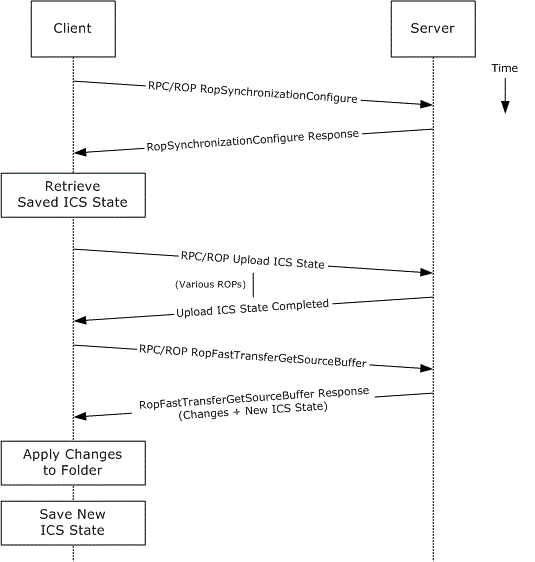
Оптимизация достигается за счёт поддержания этой сессии открытой (Ривербед её перехватывает и удерживает 96 часов), эффективного обмена подтверждениями, потоковым чтением почты и вложений (фактически кешированием того, что клиент ещё не начал получать по факту).
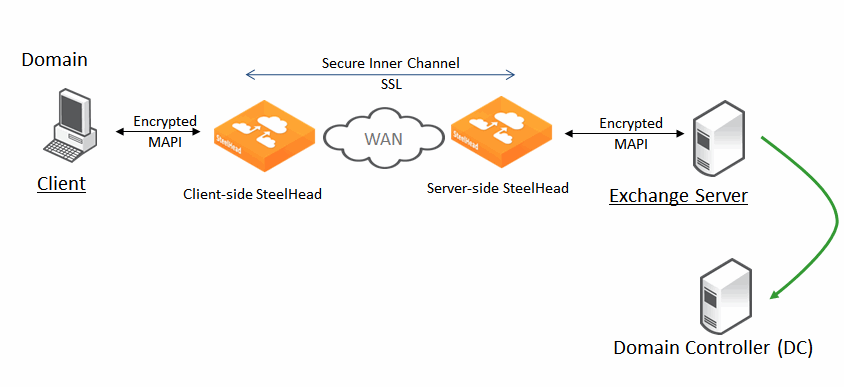
Сам трафик хорошо сжимается/дедуплицируется и избавляется от избыточности:

В кластерных инсталляциях также очень помогает метод предопределения портов.
У меня был случай, когда HR-спец по праздникам ронял всю сеть очень далёкого офиса банка. Расследование показало, что его пожилая коллега слала почтой BMP-открытку под 10 Мегабайт. Стилхед «понял», что сотрудники в 10 утра открывают почту, и стал по ночам собирать почту на себя. И заодно сжимать эти чёртовы открытки, фактически обеспечивая дедупликацию от 10 писем до одного и сжатие этого эталонного образца. Раньше люди приходили в 10, а работать начинали в 10:30, как всё «пролезет». Сейчас же поводов для грусти не стало, начало работы строго по расписанию.
В банках используется много систем дистанционного обучения, это очень удобно для сотрудников. На удалённых филиалах почти вся полоса забивается обучающими видео. Ривербед с http-потоком может делать вот такую штуку, как на картинке. В результате каналы не «страдают» от такого трафика. Но это предиктивная механика, видео в реальном времени (видео-конференц-связь, например), можно только приоритизировать.
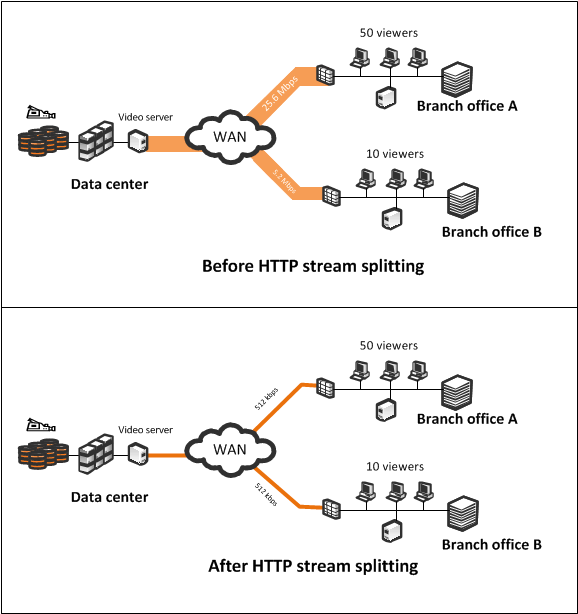
Речь про HTTP-поток, а не RTP/RSTP
Подобные методы используются и в других протоколах.
Следующая механика — Prepopulation. Если мы знаем заранее — вот есть офис, и у него имеются сетевые диски, и при этом маркетинг работает со своей одной папкой, а оптимизация и контроль сети — со своей. Если мы также знаем, что в каком-то филиале сидят определённые отделы, которые пользуются конкретными сетевыми папками, то можно научить Ривербед самостоятельно на них ходить (указать ему эти пути). Он поймет, что там за файлы лежат, насколько быстро они запрашиваются. Таким образом, много сессий не будет открываться, Ривербед сам «притворится» клиентом и сходит по сетевым шарам, соберёт всё, что там есть, и самый часто используемый контент заберёт на себя. Итого: на следующий день сотрудник приходит в офис, и он может уже воспользоваться без задержек доступом к дальней стороне. Соответственно, получит обновлённую информацию.
Прочие протоколы разбираются по схеме оптимизации протокола низкого уровня (чаще всего речь о размере фрейма и выставлении оптимального времени жизни пакета под канал) — даже если каналу нужны большие фреймы, а протокол хочет отправлять маленькими, Стилхеды умеют перебирать всё это в свой формат, дедуплицировать и отправлять как надо. Затем поток дедуплицируется-сжимается-кешируется-предугадывается. «Болтливые» последовательности выявляются и переводятся на оптимистичные ответы.
Ещё есть connection pooling — когда Стилхед держит 20лишних сессий уже открытыми под текущие нужды. Это очень актуально на спутнике.
Ещё практика
На стандартном окне в 64K ещё много кто работает — и это сильно бьёт по обмену. Например, между ЦОДами в Хабаровске и Москве на канале 100 Мбит/с при задержке 80мс скорость репликации на стандартных средствах — 5 Мегабит/c. Сюрприз! Надо менять размер окна и потом делать всё остальное. Опять же, тот же Офис365 имеет ближайшие Azure-ЦОД в Амстердаме и Дублине. С помощью линейки и калькулятора по ссылке выше можно прикинуть задержку. Ещё трафик из того же Хабаровска идёт через Москву (хотя через азиатский Azure-ЦОД ближе).
А ещё есть потери. На спутнике — это 5% от погоды запросто. Какие-то пакеты застревают в тумане, некоторые не проходят через снежинки, а большой и толстый пакет может обогатить информацией голубя. Или ворону, прилетевшую склёвывать плёнку с транспондера (правда, к счастью, на больших телепортах они быстро закипают и соскальзывают с зеркала). Кстати, поддержка SCPS помогает.
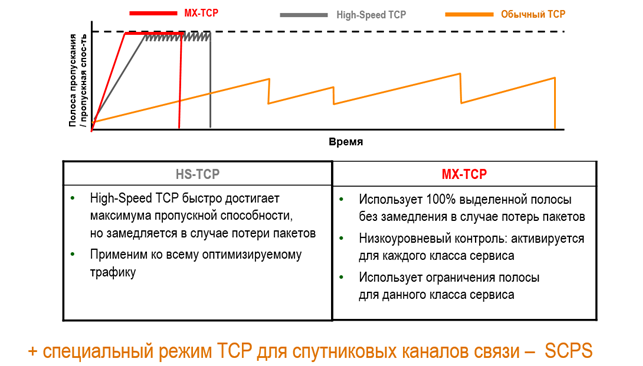
Кроме манипуляций с размерами фрейма, Riverbed SteelHead умеет использовать оптимальные механизмы контроля перегрузок (congestion avoidance). От NewReno до специфических MX-TCP и HSTCP. Последние помогают избежать проблемы с высоким BDP и проблемой TCP slow start, то есть, зная ширину канала, мы можем давать определённому трафику сразу всю полосу.
С выходом нового софта появляются новые фичи. Начиная с версии 9.0 появился полноценный DPI и можно классифицировать трафик по приложениям. Встроенные возможности Стилхедов по приоритизации и разбору трафика ещё хорошо использовать для задания сетевых политик. Например, на нефтебуровых часто используется следующая механика: сначала технический трафик, потом видеопакеты ВКС руководства, потом офис, потом личный трафик сотрудников. Теперь бурильщик Вася, качающий новую 20-мегабайтную гифку с котом, не перебьёт трафик руководству.
Или вот был объект под Ленском. Там очень прошаренные админы, они выжали из канала всё, что могли. Почитали наши прошлые посты, попросили железку на тест. Главная проблема — не самые быстрые RDP-подобные соединения, люди бесятся. А это у них основной способ доступа к бизнес-приложениям. Во время высокой загрузки канала (а он ещё и несимметричный) пользователи бизнес-приложений начали испытывать проблемы в доступе по RDP. Оптимизация у них уже была встроенная в спутниковые модемы, но только на уровне транспорта, поэтому искали другое решение. Поставили риверы — волосы стали мягкими и шелковистыми, нагрузка спала в 3 раза. Потом натолкнулись на костыль спутникового модема, — при выключении встроенной оптимизации по дефолту устанавливались катастрофически маленькие размеры очереди TCP (TCP queue length). Это очень сильно вредило Ривербедам. Тоже подобрали оптимальные параметры. В итоге RPD-подобия стабильно работают, файлы качаются быстрее — люди вахтами сидят и делают что-то круглосуточно. Ситуация такая же, как и у бурильщика Васи: он качает 20мб гиф с котом быстрее, никому не вредит, и все счастливы.
Вот ещё один пример. В открытых водах есть большие суда — фабрики на траулерах. И там
свежепойманная рыба сразу же закатывается в консервы. Производство там управляется через сеть, в рамках процесса осуществляется обмен данными.
Но как раз двойные спутниковые прыжки или неприятные переходы «спутник — 2G — оптика». Им поставили оптимизаторы — там наступило всем счастье. И компании в плане контроля бизнес-процессов, и сотрудникам в плане улучшений условий труда, т. к. у них появилась возможность коммуницировать с семьями, обмениваться фото/видео.
Где применяется на практике
Набор Стилхедов преимущественно берут в следующих случаях:
- Где нельзя технически увеличить пропускную способность канала.
- Где на широком канале имеется очень высокая задержка (например, для спутников).
- LFN (длинная толстая сеть, например, труба между двумя дата-центрами или географически удалёнными офисами, например, Москва — Кипр).
На самом деле сценариев гораздо больше, но чаще всего все они рождаются вследствие одной проблемы – медленной работы пользователей с бизнес-приложениями. Я перечислил наиболее встречаемые.
Магия Ривербед начинает работать на 3G-каналах, спутниковых каналах, 3G-радиорелейных хопов, двойных спутниковых прыжков, 2G-4G-хопов, а также на широких каналах 10G и c задержкой в 2–5 мс. Лучше всего это окупается в России при использовании спутниковых каналов, которые шире физически не сделать, а надо.
Раньше каналы стоили нереальных денег, но сейчас они дешевеют в большей части страны. Чаще всего к нам обращаются в основном банки и добывающий сектор.
Для многих это всё ещё откровение, что расширение каналов связи не приводит к повышению эффективности их работы, что задержка влияет на пропускную способность канала и бесконечно расширять канал нельзя. Часто, когда сталкиваются с такой проблемой, например, медленной репликации, медленных приложений, начинают расширять каналы. И чаще всего это не помогает. Вот, собственно, об этом я и хотел рассказать. Надеюсь, получилось.
