
Автор: Игорь Литвиненко, Senior Mobile Developer.
В этой статье я расскажу о функциональном программировании. А точнее, мы рассмотрим проблемы императивного и объектно-ориентированного программирования, затем рассмотрим функциональное программирование и попробуем найти в нем решение этих проблем. Также мы увидим, когда надо использовать функционально программирование и когда не надо.
Экскурс в историю
Немного истории. Так уж сложилось, что все методологии разработки пришли к нам из академических источников. Затем должно было пройти где-то от двух до нескольких десятков лет, чтобы методология стала популярной. Отчасти так происходило, потому что нам, разработчикам, нужно время, чтобы изменить свое видение, чтобы изменить наши способы решения задач.
Мне очень понравился пример из книги «Думаем функционально» (или «Функциональное мышление»). Представьте, что вы лесоруб, и у вас есть самый большой топор в лесу, который позволяет вам быть самым лучшим и успешным лесорубом. Но потом вы читаете в каком-нибудь журнале заметку маркетолога о том, что сейчас придумали новую крайне эффективную и современную концепцию валки леса — при помощи бензопилы. Тогда вы заказываете себе бензопилу — вам ее доставляют, вы ее распаковываете, но не знаете, как она включается. Зато вы прекрасно знаете, как рубить лес топором. И вы берете бензопилу и пытаетесь ей рубить деревья так же, как обычно рубите топором. И, конечно же, у вас ничего не получается — вам ничего не остается, как снова вернуться к топору. Но потом к вам приходит сосед и объясняет, как заводить бензопилу — и вы наконец начинаете эффективно валить лес бензопилой.
Это я говорю к тому, что идея, концепция или методология у нас не взлетит, пока не обрастет сопутствующими материалами (например, руководствами, лучшими практиками), и пока ясно не выделится пласт задач, которые мы можем отлично решать при помощи новой методологии.
Если мы заглянем в историю, увидим, что процедурное программирование отлично справлялось со своими задачами, — оно было очень быстрым. И когда придумали первый объектно-ориентированный язык (Simula 67) в 1967 г., никто не понимал, зачем этот язык нужен, — — все обращали внимание лишь на потери в производительности, связанные с тем, что нужно найти правильную реализацию метода, либо же правильного наследника и т. д. Но затем программы стали выполнять больший пласт задач: они стали сложнее, команды разработки стали больше, и оказалось, что при этом не хватало именно объектно-ориентированного подхода. В итоге императивный объектно-ориентированный подход к разработке ПО стал популярным с введением C++, представленного в 1983 г.
Та же история — с кроссплатформенными языками вроде Java и .NET. Концепция зародилась еще в 1980 г.: среда позволяла запускать код на «Паскале» на двух машинах: Apple 2 и IBM PC. Но тогда совсем не хватало мощностей для перегона в байт-код и последующей его трансляции в машинный код. А в 90-х Sun представила Java. Сейчас специалисты кроссплатформенных языков Java и .NET намного более востребованы, чем специалисты разных машинных языков. Ведь уже в 90-е стало понятно, что лучше поставить более дорогое мощное железо на сервер, где весь нужный код будет выполняться во время производства, но сэкономить при этом на разработке. После знакомства с Java, в которой есть очень хорошая объектно-ориентированная модель и сборщик мусора, большинство людей больше не хочет, конечно, переходить к ручному управлению памятью.
Проблемы императивного (и объектно-ориентированного) подхода
Однако императивный, объектно-ориентированный подход имеет свои недостатки.
- Порог вхождения. Во-первых, нам нужно разобраться с терминологией: например, нужно знать, что такое наследование и как его использовать и, что еще более важно, когда его не использовать, а использовать обыкновенную композицию. Во-вторых, есть порог вхождения в проект. Например, когда вы приходите в проект на стадии активной разработки, вам придется разбираться с объектами и их взаимодействиями.
- Нетривиальное разбиение на абстракции. Не всегда имеет смысл напрямую переносить физические объекты в объекты программирования — всё равно придется как-то дробить эти объекты, вводить дополнительные, создавать разные уровни абстракции. При этом нельзя научиться делать это правильно по какой-нибудь книге — это всё равно придет с опытом. Из книг вы можете узнать только о шаблонах проектирования, но тут есть очередная проблема:
- Неправильное понимание шаблонов — антишаблоны. Шаблоны проектирования направлены на то, чтобы часть кода, которая потенциально может изменяться, перенести как можно глубже, то есть на то, чтобы как можно ниже спуститься к конкретной реализации, — но общая логика при этом останется неизменной. Это, конечно, очень удобно, но люди ленятся и не всегда понимают, что делают. Из-за этого появились антишаблоны проектирования. Например, появился «божественный объект», который всё «знает» про всех и лишает нас большей части гибкости. Также появился класс «полтергейст»: вы видите, что делает этот класс, но не понимаете, зачем он здесь. Так что в императивном программировании у нас очень много такого рода побочных эффектов, которые может вызвать какой-нибудь класс.
- Неочевидны побочные эффекты по интерфейсу.
Конечно, некоторые проблемы можно решить путем привлечения опытных ребят, которые могут сделать рефакторинг. Но когда мы говорим о многопоточности, концепция императивного программирования перестает работать. Ведь следить за изменениями состояния объектов в разных потоках и синхронизировать их, делать какие-то атомарные операции довольно трудно. Нельзя просто взять программу из коробки и распараллелить ее на несколько процессоров. Более того, если внутри программы нераспаралеленный код составляет более 30 %, вы не сможете получить никаких преимуществ от многопроцессорных систем: слишком много времени у вас уйдёт на синхронизацию и атомарные действия. Отсюда следующие недостатки:
- Сама концепция изменения состояния перестает работать.
Когда концепция не работает, люди начинают искать другие. И тогда мы увидим, что, так или иначе, функциональное программирование начало пролезать в наши любимые языки. У нас появились блоки в Objective-C, у нас есть замыкания в Swift, у нас есть поддержка лямбда-функций в C++ начиная с 11-го стандарта, и даже Java стала обзаводиться лямбда-выражениями. На слуху теперь такие языки, как Clojure и Scala. Поэтому давайте теперь разберемся, что такое функциональное программирование.
Функционально программирование (ФП) и его основные принципы
Если вы подумали, что функциональное программирование — это программирование с помощью функций, вы правы. В этом случае мы пишем в более математическом стиле. У нас всегда есть входные и выходные данные, и мы пишем функции, как бы составляя из них трубу, внутри которой пролетают данные.
Основные столпы ФП:
Основные столпы ФП:
● Неизменность входных данных.
• Никаких побочных эффектов.
• Многопоточность.
● Изменение уровня абстракции за счет функций высших порядков
• Больше повторно используемого кода.
• Лучше читаемость кода.
• Сохранение контекста.
Неизменность входных данных обеспечивает отсечение всех побочных эффектов. Это значит, что можно больше не переживать о многопоточных системах: ничего не меняется и никакие синхронизации не нужны.
Использование функций высших порядков. Это значит, что вы можете писать функции, которые принимают другие функции как параметры, что позволяет выходить на следующий уровень абстракции, когда вы пишете более общую логику, а способ конкретной реализации того или иного действия передается в виде параметра вашей функций.
Неизменность входных данных
Давайте теперь подробнее остановимся на неизменности входных данных. Когда вы приходите в проект и просите коллегу помочь во всем разобраться, всегда приходится рисовать диаграмму: объекты, методы, сообщения, в какое состояние что должно перейти и т. д. А затем вы начинаете смотреть функцию. И когда вы смотрите функцию, вам нужно:
- Понять, что делает эта функция.
- Понять, как она будет вызвана — внутри данного объекта или снаружи, либо вызвана по таймеру, либо по нотификации, либо еще как-то.
- Вы смотрите интерфейс какого-либо объекта. Сколько других объектов задевает этот интерфейс?
Конечно, вы не можете ответить на этот вопрос. Вы даже не можете сказать, что произойдет в глобальном смысле, если вы вызовете какой-то определенный метод. Это и есть основная проблема.
Вот немного кода для примера:

Допустим, у нас есть класс “User”, есть “ViewController”, который хранит этого “User”, и у нас есть класс “NetworkOperation” — то есть, грубо говоря, запрос. Так как тип “User” — ссылочный, то есть передается по ссылке, вы, изменив что-то во “ViewController”, поменяете что-то и в “NetworkOperation”, очень далеко, и тогда, как говорится, веселого дебага!
Что с этим делать? В Swift есть два типа данных: ссылочный (reference type) и значимый (value type). Ссылочный тип данных — нечто живое, то, что как-то реагирует и может изменять свое состояние. Значимый тип — нечто мертвое и не реагирующее, простые данные. Сама концепция говорит, что нам нужно отказаться от использования активных объектов, то есть от ссылочного типа, и перейти к использованию только значений. Таким образом, уже на уровне языка вы избавитесь от побочных эффектов: есть только простые данные, которые никак себя внутри не меняют и не создают никаких дополнительных ссылок. И это уже намного проще.
Допустим, у нас есть массив “a”, включающий в себя элементы “1”, “2”, “3”. Массив “b” — это ссылка на “a”:
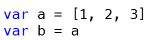
И допустим, вы хотите добавить какой-либо элемент к массиву “b”. Тогда, если бы “b” был объектом, он бы изменился. Здесь же у вас “a” остается неизменным, то есть нет побочных эффектов на уровне значения:

Если же мы будем работать с “View”, который работает как ссылочный тип, при изменении “alpha” в переменной “beta”, у нас меняется “alpha” в переменной “a”:

Конечно, можно подумать, что значимый тип как бы немного обрезан — это простые данные, с которыми, казалось бы, ничего нельзя сделать. Но на самом деле, это не так: в Swift перечисляемые типы (enum) и структуры (struct) — значимые типы. А структуры умеют реализовывать протоколы, хранить методы, делать какие-то вычисления — по сути, они уже начинают понемногу выходить на один уровень с объектами. При этом у них есть три основных преимущества:
- Во-первых, структура всегда постоянная и не может изменяться со временем
- Во-вторых, изолированность: значимые типы — всегда изолированны. Когда мы, например, используем ссылочный тип “User”, создаем внутри зависимости между компонентами. Если же мы используем структуру, то есть значимый тип, у нас нет никаких зависимостей, и все данные изолированны. Вот, вкратце, про значимые типы.
- В-третьих, это взаимозаменяемость. Нет понятия “instance-структура”, как в случае с объектами — другими словами, у нас нет ID. По большому счету, значимый тип характеризуется только темы данными, которые у него внутри — это значит, что они могут быть внутризаменяемыми. Например, когда вы говорите a = [1, 2, 3], мне неважно, где физически, в памяти лежит этот объект. То есть, если я обращусь к “а”, там будет массив с этими данными. Откуда они у меня взялись — уже другой вопрос.
Изменение уровня абстракции за счет функций высших порядков
Изменение уровня абстракции за счет функций высших порядков значит, что мы можем принимать функцию внутри своей функции и выполнять ее как аргумент. Это также говорит о том, что в Swift функции стали переменными 1-го класса — мы можем обращаться с ними точно так же, как с обычными переменными (кэшировать, принимать внутри функции, возвращать как результаты другой функции). На уровне языка Swift у нас уже реализованы базовые функции из ФП, такие как “map”, “filter” и “reduce”. Пример использования этих функций:

“Map” просто перегоняет коллекцию объектов одного типа в коллекцию объектов другого типа. Пример из жизни. У меня в предыдущем проекте модель всей системы была написана на значимых типах. Но некоторые значения было необходимо сохранять в базу данных. Когда мы сохраняем в базу данных, можем оперировать на уровне объектов классом “NSManagedObject” (это ссылочный тип данных). И тут мне функция “map” очень сильно помогла: допустим, когда вы делаете какой-то запрос в базу данных, вам возвращаются эти объекты, и вы возвращаете не ту коллекцию, которая к вам вернулась, а вы пишете “map” («перевести в значимый тип»), и к вам возвращаются данные значимого типа.
Чтобы сделать код еще более читабельным и красивым, Swift предоставляет сокращенное обозначение (shorthand notation), позволяющее организовать очень быстрый доступ к переменным. Когда вы пишете “$0”, “$1”, “$2”, вы обращаетесь к номеру параметра, который вошел внутрь вашего замыкания.
И еще одна добавка. Если ваше замыкание возвращает какое-то значение, результат выполнения последней строчки, если вы не написали “return”, вернется как результат вашего выполнения операции. Из-за этого в данном случае функция “map” просто возвращает квадраты этих чисел.
Следующая функция — “filter”. Сюда мы просто передаем замыкание, которое должно обязательно вернуть bool, чтобы мы могли определить, включать ли то или иное выражение в результирующую выборку.
Функция “reduce” сжимает нашу коллекцию до одного значения. Например, выше, приводится пример, как посчитать количество глав в первом акте «Ромео и Джульетты».
Так как функции ничего не изменяют и не имеют никакого глобального эффекта, уже на этом этапе, когда мы скомпилировали приложение, функции типа “map”, “filter” и “reduce” автоматически работают на всех процессорах. То есть, мы ничего не меняем снаружи и точно знаем, что сделать с каждым отдельным элементом, — мы всё это разбросали по всем процессорам и вернули наш результат. Всё работает очень хорошо!
Опциональные типы данных и сахар Swift
Давайте теперь посмотрим на другие возможности, которые присутствуют в Swift, но не являются обязательными для функционального языка.
- Обобщенные типы (generics) — всегда круто. Мы пишем более абстрактный код.
- Статическая типизация позволяет легче разбираться в написанном коде и упрощает тестирование.
- Перегрузка операторов позволяет нам писать четкий и интуитивно понятный код.
- Опциональные типы очень сильно изменили API, который предоставляет сам SDK. Допустим, в Objective C у нас есть “indexOfObject” — он всегда возвращает значение, но вам нужно сравнить результирующее значение с константой “NSNotFound”, и, если они не равны, — мы что-то нашли: “(NSUInteger)indexOfObject:(ObjectType)anObject”. В Swift всё намного проще: у нас возвращается опциональный “index” элемента: если этот элемент есть в коллекции — вернулся “index”, если нет — “index” нет:
public func indexOf(element: Self.Generator.Element) -> Self.Index?
Разбираемся на примерах
А теперь перейдём от теории к практике.
Пример 1. Валидация локального файла
Сначала мы рассмотрим императивное решение задачи, а затем перейдем к функциональному.
Допустим, у нас есть функция, которой мы передаем URL на локальный файл, и она определяет, является ли файл устаревшим:

При использовании императивного объектно-ориентированного подхода решение было бы примерно следующим: мы бы взяли ссылку на файл, проверили бы, существует ли он. Затем, если он существует, взяли бы у него атрибуты. Если атрибуты существуют, попробовали бы вытащить из атрибутов дату и проверить, является ли файл устаревшим или нет. То есть у нас есть чёткая последовательность действий, чтобы мы могли получить ответ. Если мы не смогли развернуть какие-то опциональные типы, то у нас, понятное дело, возвращается “false”.
ФП же предлагает начать с разбиения на маленькие функции:

Первая функция будет просто определять, существует ли файл: принимаем строку, возвращаем опционально строку (делаем одну операцию — если файл существует, возвращаем). Следующая — получение атрибутов, где получаем на вход строку на уже точно существующий файл, и возвращаем возможные атрибуты, которые нам удалось получить. Следующая функция будет вытягивать дату из полученных ранее атрибутов — тут мы используем сокращенное обозначение (“$0”). Получается, что весь путь, то есть труба, составленная из функций, будет вот такая: получаем путь, проверяем существование файла, достаем атрибуты и проверяем дату создания.
Чтобы решение было еще более красивым, определим функцию “bind”, которая будет связывать две функции, и определим оператор, который просто будет ссылаться на эту функцию. Функция “bind” принимает опциональное значение и опциональную функцию (то нужно сделать с этим значением) и возвращает тоже опциональное значение. Если значение есть, функция выполняется, а если нет, так нет.

В итоге у нас получается вот такой вот очень наглядный метод:
return filePath >>= fileExists >>= retrieveFileAttributes >>= extractCreationDate >>= checkExpired ?? false
Не знаю, как вас, а меня очень сильно напрягает работа с соцсетями. Допустим, для записи в Facebook нужно: проверить, залогинен пользователь или нет (если не залогинен, залогинить); если залогинен, проверить, есть ли право на публикацию записей, если нет, запрашиваем его, если есть, собираем запись. А теперь представьте, как это всё превратилось бы в такую вот небольшую цепочку вызовов: вы сразу видите, что она делает, если возникают ошибки, точно знаете, какой функцией это вызвано.
Пример 2
Второй пример показывает, как легко понять программу на функциональном языке:

Тут у нас есть какой-то массив имен. Что мы с ним делаем? Во-первых, “filter” — отсекаем все имена, у которых есть один символ. Затем делаем первую букву заглавной и объединяем всё это с сепаратором с запятой. Получается, что мы берем входной массив, убираем имена с одним символом, и превращаем его в строку. А теперь подумайте, сколько времени у вас ушло бы на написание такого кода на императивном языке, и сколько у вас времени ушло бы, если бы вы увидели такой код в чьем-то проекте.
Когда не надо применять ФП
Но не всегда функциональное решение — наилучшее. Допустим, нам нужно посчитать количество вхождений каждого слова во входную строку. Для этого мы бы сделали что-то такое:

То есть мы бы создали результат, который был был dictionary. Мы бы по регулярке разбили строку и для всех совпадений проверили бы, является ли данное слово предлогом: если нет, увеличили бы значение его индекса.
А на функциональном языке это выглядело бы так:
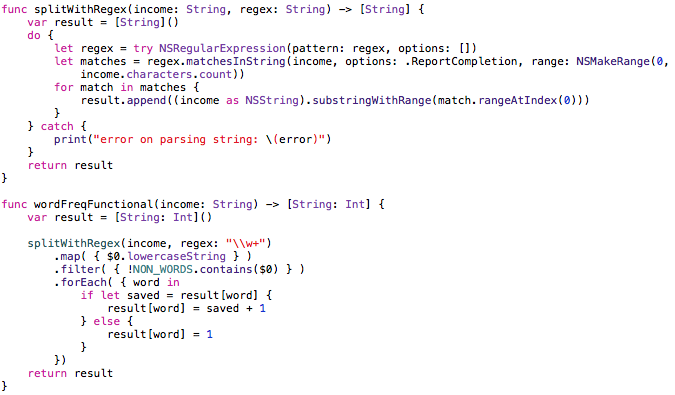
Тут мы откололи отдельно функцию, которая принимает входную строку, и регулярное выражение — она разбивает и возвращает результат. А далее начинается самое интересное. Наша главная функция сначала делает “map”, что переводит входные данные в нижний регистр. Следующий шаг: мы проверяем, самостоятельное ли это слово или просто предлог. И дальше у нас начинается “forEach”, который говорит, что для каждого элемента выполнен вот этот кусочек.
Да, наши функции типа “map”, “filter” и “forEach” оптимизированы и всё такое. Но вы только подумайте, сколько будет сделано итераций! Ведь сначала мы зайдем и сделаем “map” для всех элементов, затем сделаем фильтрацию лишних слов, и только потом применим это для всех из них. В первом же случае всё это решалось одним циклом.
Такой вот пример неудачного переноса функционального стиля.
Заключение
Я не хочу сказать, что нам всем нужно перейти с нашего любимого объектно-ориентированного программирования на функциональное. Будем честны — время повсеместного применения функционального программирования прошло. Я говорю, что мы должны использовать объектно-ориентированный подход там, где он нужен: там, где у нас есть UI-компоненты, где важно иметь наследование, где важно, чтобы какие-то методы были определены в предке, где мы определим всю эту логику. Но у нас также есть огромный пласт задач (например, обработка данных, фильтрация списков и т. д.), которые очень хорошо решаются при помощи ФП.
Поэтому я призываю писать UI объектно-ориентированным методом, а модель делать на значимых типах. Тогда мы получим выигрыш в производительности и читаемости, избавимся от нежелательных эффектов. Более того, наш код станет тестируемым.
Ведь как происходит тестирование написанного на императивном языке? Мы создаем вселенную, совершаем какие-то действия и смотрим, что поменялось во вселенной.
Если же мы хотим протестировать что-то, что находится глубоко, в тестах нам нужно сделать цепочку вызовов. В ФП же всё просто: мы знаем, что функция всегда возвращает одно и то же значение для одних и тех же входных данных, что позволяет писать для тестов короткие данные.
