Дана битовая матрица, содержащая закрашенное изображение круга, квадрата или треугольника.
Изображение может быть немного искажено и может содержать помехи.
Необходимо написать алгоритм для определения типа нарисованной фигуры по матрице.

Эта простая с первого взгляда задача встретилась мне на вступительном экзамене в DM Labs.
На первом занятии мы обсудили решение, а преподаватель (Александр Шлемов; он руководил и дальнейшей реализацией) показал, почему для решения лучше использовать машинное обучение.
В процессе дискуссии мы обнаружили, что наше решение производится в два этапа. Первый этап — фильтрация помех, второй этап — вычисление метрики, по которой будет проходить классификация. Здесь возникает проблема определения границ: необходимо знать, какие значения может принимать метрика для каждой фигуры. Можно проложить эти границы вручную “на глазок”, но лучше поручить это дело математически обоснованному алгоритму.
Эта учебная задачка стала для меня введением в Machine Learning, и я хотел бы поделиться с вами этим опытом.
Сначала мы создаем множество случайных изображений кругов, треугольников и четырехугольников. Далее пропускаем картинки через фильтры для ликвидации помех и вычисляем набор метрик, которые будут использованы для классификации фигур. Граничные значения для метрик определим с помощью дерева решений (Decision tree), а точнее с помощью его разновидности CART (подробнее можно прочитать тут). Реализация алгоритма проста и лучше интерпретируется в терминах границ.
Пропустив неизвестное изображение через фильтры и вычислив метрики, по дереву решений мы сможем сказать, к какому классу относится фигура на картинке.
Генератор должен не только создавать картинки, но и уметь накладывать помехи на них. При генерации мы должны отбрасывать фигуры с сторонами меньше некой величины (например, 15 пикселей) и с тупыми углами (больше 150 градусов) — даже человеку сложно их классифицировать.
Скрипт заботливо предоставил Виктор Евстратов.
bitbucket.org/rampeer/image-classifier/src/HEAD/picture_generator.py
В процессе дискуссии с коллегами мы нашли хорошие идеи для фильтров. Примем пиксели черного цвета, окруженные пикселями противоположного цвета за помехи (эта идея легла в основу медианного фильтра), а за искомый контур примем большое скопление черных пикселей, то есть используем бикомпонентный фильтр.
Медианный фильтр: для каждого черного пикселя определяем количество «черных» соседей в окрестности радиуса R. Если это число меньше некого T, то отбрасываем этот пиксель, то есть закрашиваем его в белый цвет. В «оригинальном» медианном фильтре мы отбрасываем пиксель, если у него меньше половины черных соседей, а мы определили свой порог T, так что, на самом деле — это квантильный фильтр.

Я написал медианный фильтр честно и «в лоб», поэтому он работает за
Получается, что вычислить матрицу с количеством соседей можно как
Этот алгоритм работает за
bitbucket.org/rampeer/image-classifier/src/HEAD/filter_median.py
Однако, я обнаружил у этого фильтра нехорошее свойство: он скругляет острые углы треугольников. Из-за этого приходится брать радиус окна R довольно маленьким и проходиться по изображению фильтром только несколько (N) раз. Хотя поначалу казалось, что можно применять медианный фильтр до тех пор, пока он удаляет какие-то пиксели.
Бикомпонентный фильтр: берем произвольный черный пиксель, назначаем ему какое-то число Q. Назначаем это же число «черным» соседям этого пикселя в окрестности с радиусом R и повторим для соседей соседей. Будем повторять до тех пор, пока не дойдем до границы изображения (это напоминает действие инструмента «Заливка» в Paint, а красим в цвет Q). Затем увеличим число Q на единицу, выберем очередной «неокрашенный» пиксель и повторим процесс.
После выполнения этого алгоритма получится набор несоприкасающихся островов. Мы можем с высокой достоверностью сказать, что самый большой остров – это и есть фигура, а остальные острова – помехи.

<filter_bicomp.py>
В отличие от предыдущего, этот фильтр не портит изображение. Он может нанести ущерб, только если фигуру пересечет линия из помех шириной больше T, что маловероятно.
У медианного фильтра я обнаружил ещё одно свойство, на этот раз положительное. Он разбивает пространство, заполненное помехами, на “островки”. Значит, применив потом бикомпонентный фильтр, мы получим контур с прилепившимися помехами. После обработки бикомпонентным фильтром стоит ещё раз пройтись медианным, чтобы убрать оставшиеся неровности. Затем нужно построить вокруг оставшихся точек выпуклый контур, заполнить его и вычислять метрики уже для нового изображения.
bitbucket.org/rampeer/image-classifier/src/HEAD/process.py
Работа фильтров:
Параметры фильтров подбираются исходя из размеров изображений в выборке и их зашумленности. Для хитрого четырехугольника, изображенного выше:
В нашей выборке изображения будут менее зашумлены, и настройки будут более щадящие.
В ходе всё той же дискуссии с коллегами мы придумали еще много разных интересных метрик.
Подсчет углов. Это самое первое, что приходит в голову после прочтения задачи. Но из-за помех могут появиться дополнительные углы, близкие к 0 градусам. Я безуспешно пытался бороться с этим, «склеивая» почти коллинеарные вектора и устанавливая пороги. Такие методы тяжело настроить, и они все равно могут дать некорректный результат, так как при фильтрации фигурка сглаживается. Лучше просуммировать квадраты синусов углов, а если углы больше некого порога T – округлять квадрат вверх до единицы. Это дает достаточно хороший результат: острые углы прибавляют к счетчику единичку, а углы, близкие к 0, почти ничего не прибавляют. Кстати, мне показалось забавным, что в таком случае количество углов у треугольника может варьироваться от 2,5 до 4.
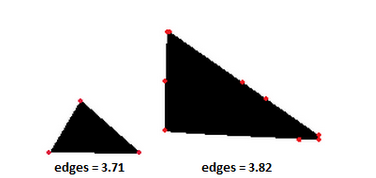
bitbucket.org/rampeer/image-classifier/src/HEAD/feature_edges.py
Зеркалирование. Смысл этой метрики – посчитать, насколько фигура будет совпадать с перевернутой копией себя при отражении по горизонтали/вертикали/вдоль обоих осей. То есть эта метрика — своеобразная мера симметрии. Круг, как ни крути, всегда будет полностью совпадать сам с собой. Также, я интуитивно предположил, что квадрат будет больше совпадать сам с собой, чем треугольник.

bitbucket.org/rampeer/image-classifier/src/HEAD/feature_mirror.py
Отношение площади к квадрату периметра. Периметр необходимо возводить в квадрат, чтобы метрика не имела размерности и не зависела от размера изображения. Периметр и площадь будем брать от выпуклого контура. Круг имеет наибольшее значение метрики среди фигур:

bitbucket.org/rampeer/image-classifier/src/HEAD/feature_perimeter.py
Метрики на описывающем прямоугольнике. Предыдущие метрики не очень хорошо разделяли четырех- и треугольник, и я решил придумать новую метрику. Построим ограничивающий прямоугольник вокруг фигуры. Для каждой стороны прямоугольника найдем первое (“минимальное”) и последнее (“максимальное”) пересечение с фигурой. У нас получится “восьмиугольник”, для которого можно вычислять разные метрики.
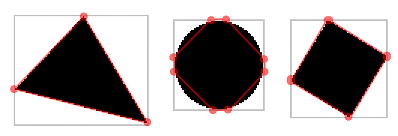
Например, отношение площади фигуры к площади описывающего квадрата (sbound).
bitbucket.org/rampeer/image-classifier/src/HEAD/feature_sbound.py
Также многообещающей метрикой кажется отношение площади фигуры к площади этого восьмиугольника (sbound2):
bitbucket.org/rampeer/image-classifier/src/HEAD/feature_sbound2.py
Применив полученные знания, я сгенерировал изображения и собрал статистику. В этот набор изображений я добавил фигуры, представляющие собой потенциальные “плохие случаи” для метрик:
Этим случаям я дал большой вес при построении дерева. Дело в том, что вероятность случайной генерации таких картинок мала, а эти случаи являются граничными для некоторых метрик. Следовательно, для корректной классификации надо их добавить в выборку с большим весом.
Процедуру фильтрации изображения и сбора метрик я вынес в отдельный файл, она понадобится для анализа. Кстати, в дереве решений наши метрики называются “входными параметрами” или “фичами” (feature).
bitbucket.org/rampeer/image-classifier/src/HEAD/process.py
bitbucket.org/rampeer/image-classifier/src/HEAD/stats.py
Затем я построил график, чтобы убедиться, что метрики достаточно хорошо различают фигурки. Для этого подойдет график типа “коробки с усиками”:
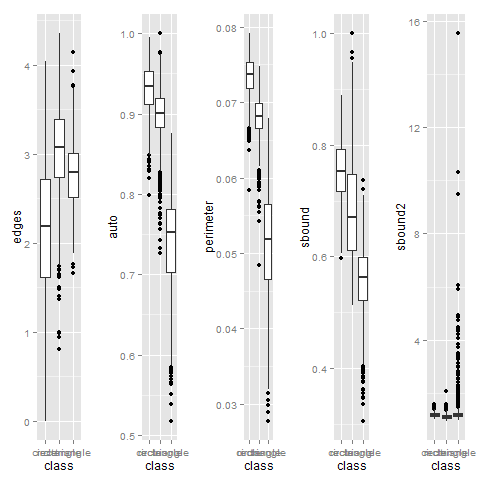
“Усики” пересекаются, а это означает, что возможны неточности при анализе. Как было написано выше, именно для точности нам нужны несколько метрик, а не одна. Дальше я попробовал убедиться, что «плохие случаи» метрик не пересекаются. Для этого я построил зависимость одной метрики от другой. Если получится, что они монотонно зависят друг от друга, то их “плохие случаи” также совпадут.
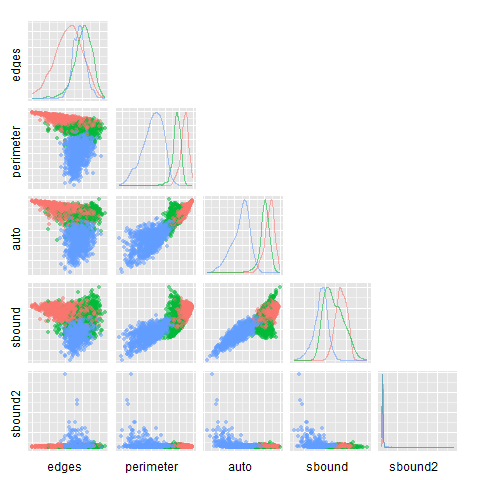
*Как мы видим по графикам, “облака” точек сильно пересекаются. Следовательно, при классификации возможна большая ошибка. К тому же, метрики не зависимы монотонно друг от друга.
По собранным данным можно построить дерево решений:
bitbucket.org/rampeer/image-classifier/src/HEAD/analyze.py
Я попробовал визуализировать дерево. Получилось вот такая схема:
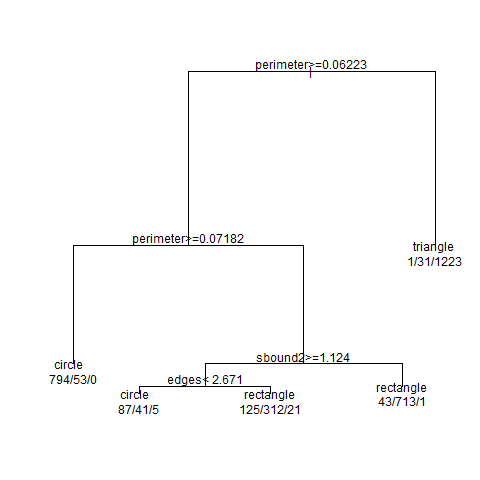
Из неё следует, что некоторые метрики остались неиспользованными. Мы не могли с самого начала предсказать, какие метрики окажутся “лучше” других.
Точность предсказания составляет примерно 91 процент, что неплохо, учитывая искажения квадратов и помехи в выборке:

Попробуем нарисовать изображения самостоятельно и проанализировать их:
Попробуем повысить напряжение.
Будем искажать фигуры до тех пор, пока они не станут неправильно определяться.
Вот и всё.
В последнем изображении углы треугольника сильно скруглены, edges не может верно работать, а perimeter дает слишком большую погрешность. Треугольник неудачно повернут: при построении ограничивающего прямоугольника только две вершины будут его касаться, и sbound и sbound2 не выдадут ничего разумного. Только mirror мог бы выдать корректный результат, но он не включен в дерево. Да и если из 5 метрик только одна укажет на треугольник, то можно трактовать этот вывод как ошибочный.
Методы машинного обучения позволили построить систему, которая хорошо справляется с поставленной задачей – она достаточно хорошо распознает фигурки на изображении.
Графики были построены в R:
bitbucket.org/rampeer/image-classifier/src/HEAD/charts.R
Изображение может быть немного искажено и может содержать помехи.
Необходимо написать алгоритм для определения типа нарисованной фигуры по матрице.

Эта простая с первого взгляда задача встретилась мне на вступительном экзамене в DM Labs.
На первом занятии мы обсудили решение, а преподаватель (Александр Шлемов; он руководил и дальнейшей реализацией) показал, почему для решения лучше использовать машинное обучение.
В процессе дискуссии мы обнаружили, что наше решение производится в два этапа. Первый этап — фильтрация помех, второй этап — вычисление метрики, по которой будет проходить классификация. Здесь возникает проблема определения границ: необходимо знать, какие значения может принимать метрика для каждой фигуры. Можно проложить эти границы вручную “на глазок”, но лучше поручить это дело математически обоснованному алгоритму.
Эта учебная задачка стала для меня введением в Machine Learning, и я хотел бы поделиться с вами этим опытом.
Основная идея
Сначала мы создаем множество случайных изображений кругов, треугольников и четырехугольников. Далее пропускаем картинки через фильтры для ликвидации помех и вычисляем набор метрик, которые будут использованы для классификации фигур. Граничные значения для метрик определим с помощью дерева решений (Decision tree), а точнее с помощью его разновидности CART (подробнее можно прочитать тут). Реализация алгоритма проста и лучше интерпретируется в терминах границ.
Пропустив неизвестное изображение через фильтры и вычислив метрики, по дереву решений мы сможем сказать, к какому классу относится фигура на картинке.
Генерация
Генератор должен не только создавать картинки, но и уметь накладывать помехи на них. При генерации мы должны отбрасывать фигуры с сторонами меньше некой величины (например, 15 пикселей) и с тупыми углами (больше 150 градусов) — даже человеку сложно их классифицировать.
Скрипт заботливо предоставил Виктор Евстратов.
bitbucket.org/rampeer/image-classifier/src/HEAD/picture_generator.py
Фильтры
В процессе дискуссии с коллегами мы нашли хорошие идеи для фильтров. Примем пиксели черного цвета, окруженные пикселями противоположного цвета за помехи (эта идея легла в основу медианного фильтра), а за искомый контур примем большое скопление черных пикселей, то есть используем бикомпонентный фильтр.
Медианный фильтр: для каждого черного пикселя определяем количество «черных» соседей в окрестности радиуса R. Если это число меньше некого T, то отбрасываем этот пиксель, то есть закрашиваем его в белый цвет. В «оригинальном» медианном фильтре мы отбрасываем пиксель, если у него меньше половины черных соседей, а мы определили свой порог T, так что, на самом деле — это квантильный фильтр.

Я написал медианный фильтр честно и «в лоб», поэтому он работает за
O(WHR2), где W и H – размеры картинки. Преподаватель рассказал, что можно ускорить алгоритм, используя преобразование Фурье. Действительно, медианный фильтр можно выразить через свертку, а свертку можно быстро вычислить с помощью быстрого преобразования Фурье. Получается, что вычислить матрицу с количеством соседей можно как
result = FFT-1 (FFT(data) FFT(window))Этот алгоритм работает за
O(WHlog(W+H)), то есть намного быстрее наивной реализации, и не зависит от размеров окна. Из-за цикличности свертки возникает артефакт на границах: при обработке крайних левых пикселей соседями будут считаться крайние правые. Это можно исправить, добавив рамку из чистых пикселей по краям изображения, а можно оставить так, что я и сделал — всё равно этот эффект не наносит ущерба работоспособности. bitbucket.org/rampeer/image-classifier/src/HEAD/filter_median.py
Однако, я обнаружил у этого фильтра нехорошее свойство: он скругляет острые углы треугольников. Из-за этого приходится брать радиус окна R довольно маленьким и проходиться по изображению фильтром только несколько (N) раз. Хотя поначалу казалось, что можно применять медианный фильтр до тех пор, пока он удаляет какие-то пиксели.
Бикомпонентный фильтр: берем произвольный черный пиксель, назначаем ему какое-то число Q. Назначаем это же число «черным» соседям этого пикселя в окрестности с радиусом R и повторим для соседей соседей. Будем повторять до тех пор, пока не дойдем до границы изображения (это напоминает действие инструмента «Заливка» в Paint, а красим в цвет Q). Затем увеличим число Q на единицу, выберем очередной «неокрашенный» пиксель и повторим процесс.
После выполнения этого алгоритма получится набор несоприкасающихся островов. Мы можем с высокой достоверностью сказать, что самый большой остров – это и есть фигура, а остальные острова – помехи.

<filter_bicomp.py>
В отличие от предыдущего, этот фильтр не портит изображение. Он может нанести ущерб, только если фигуру пересечет линия из помех шириной больше T, что маловероятно.
У медианного фильтра я обнаружил ещё одно свойство, на этот раз положительное. Он разбивает пространство, заполненное помехами, на “островки”. Значит, применив потом бикомпонентный фильтр, мы получим контур с прилепившимися помехами. После обработки бикомпонентным фильтром стоит ещё раз пройтись медианным, чтобы убрать оставшиеся неровности. Затем нужно построить вокруг оставшихся точек выпуклый контур, заполнить его и вычислять метрики уже для нового изображения.
bitbucket.org/rampeer/image-classifier/src/HEAD/process.py
Работа фильтров:
| Исходное изображение | Медианный фильтр | Медианный, бикомпонентный | Медианный, бикомпонентный, медианный, заливка |
 |
 |
 |
 |
Параметры фильтров подбираются исходя из размеров изображений в выборке и их зашумленности. Для хитрого четырехугольника, изображенного выше:
median.filter(img, 2, 6, 1)
bicomp.filter(img, 2)
median.filter(img, 2, 5, 2)
В нашей выборке изображения будут менее зашумлены, и настройки будут более щадящие.
Метрики
В ходе всё той же дискуссии с коллегами мы придумали еще много разных интересных метрик.
Подсчет углов. Это самое первое, что приходит в голову после прочтения задачи. Но из-за помех могут появиться дополнительные углы, близкие к 0 градусам. Я безуспешно пытался бороться с этим, «склеивая» почти коллинеарные вектора и устанавливая пороги. Такие методы тяжело настроить, и они все равно могут дать некорректный результат, так как при фильтрации фигурка сглаживается. Лучше просуммировать квадраты синусов углов, а если углы больше некого порога T – округлять квадрат вверх до единицы. Это дает достаточно хороший результат: острые углы прибавляют к счетчику единичку, а углы, близкие к 0, почти ничего не прибавляют. Кстати, мне показалось забавным, что в таком случае количество углов у треугольника может варьироваться от 2,5 до 4.

bitbucket.org/rampeer/image-classifier/src/HEAD/feature_edges.py
Зеркалирование. Смысл этой метрики – посчитать, насколько фигура будет совпадать с перевернутой копией себя при отражении по горизонтали/вертикали/вдоль обоих осей. То есть эта метрика — своеобразная мера симметрии. Круг, как ни крути, всегда будет полностью совпадать сам с собой. Также, я интуитивно предположил, что квадрат будет больше совпадать сам с собой, чем треугольник.

bitbucket.org/rampeer/image-classifier/src/HEAD/feature_mirror.py
Отношение площади к квадрату периметра. Периметр необходимо возводить в квадрат, чтобы метрика не имела размерности и не зависела от размера изображения. Периметр и площадь будем брать от выпуклого контура. Круг имеет наибольшее значение метрики среди фигур:
s/p^2 =(πr^2)/(4π^2 r^2 )=1/4π. Для равностороннего треугольника (у него это соотношение самое большое среди треугольников): s/p^2 =(4√3 a^2)/(3*9a^2 )=(4√3)/27. Для квадрата: s/p^2 =(a^2)/(16*a^2 )=1/16.
bitbucket.org/rampeer/image-classifier/src/HEAD/feature_perimeter.py
Метрики на описывающем прямоугольнике. Предыдущие метрики не очень хорошо разделяли четырех- и треугольник, и я решил придумать новую метрику. Построим ограничивающий прямоугольник вокруг фигуры. Для каждой стороны прямоугольника найдем первое (“минимальное”) и последнее (“максимальное”) пересечение с фигурой. У нас получится “восьмиугольник”, для которого можно вычислять разные метрики.

Например, отношение площади фигуры к площади описывающего квадрата (sbound).
bitbucket.org/rampeer/image-classifier/src/HEAD/feature_sbound.py
Также многообещающей метрикой кажется отношение площади фигуры к площади этого восьмиугольника (sbound2):
bitbucket.org/rampeer/image-classifier/src/HEAD/feature_sbound2.py
Сбор данных
Применив полученные знания, я сгенерировал изображения и собрал статистику. В этот набор изображений я добавил фигуры, представляющие собой потенциальные “плохие случаи” для метрик:
- равносторонний треугольник
- прямоугольный треугольник с двумя сторонами, параллельными осями
- квадрат со сторонами, параллельными осям.
Этим случаям я дал большой вес при построении дерева. Дело в том, что вероятность случайной генерации таких картинок мала, а эти случаи являются граничными для некоторых метрик. Следовательно, для корректной классификации надо их добавить в выборку с большим весом.
Процедуру фильтрации изображения и сбора метрик я вынес в отдельный файл, она понадобится для анализа. Кстати, в дереве решений наши метрики называются “входными параметрами” или “фичами” (feature).
bitbucket.org/rampeer/image-classifier/src/HEAD/process.py
bitbucket.org/rampeer/image-classifier/src/HEAD/stats.py
Затем я построил график, чтобы убедиться, что метрики достаточно хорошо различают фигурки. Для этого подойдет график типа “коробки с усиками”:

“Усики” пересекаются, а это означает, что возможны неточности при анализе. Как было написано выше, именно для точности нам нужны несколько метрик, а не одна. Дальше я попробовал убедиться, что «плохие случаи» метрик не пересекаются. Для этого я построил зависимость одной метрики от другой. Если получится, что они монотонно зависят друг от друга, то их “плохие случаи” также совпадут.

*Как мы видим по графикам, “облака” точек сильно пересекаются. Следовательно, при классификации возможна большая ошибка. К тому же, метрики не зависимы монотонно друг от друга.
Анализ
По собранным данным можно построить дерево решений:
bitbucket.org/rampeer/image-classifier/src/HEAD/analyze.py
Я попробовал визуализировать дерево. Получилось вот такая схема:

Из неё следует, что некоторые метрики остались неиспользованными. Мы не могли с самого начала предсказать, какие метрики окажутся “лучше” других.
Точность предсказания составляет примерно 91 процент, что неплохо, учитывая искажения квадратов и помехи в выборке:

Попробуем нарисовать изображения самостоятельно и проанализировать их:
 Circle |
 Rectangle |
 Triangle |
Попробуем повысить напряжение.
Будем искажать фигуры до тех пор, пока они не станут неправильно определяться.
 Rectangle |
 Rectangle |
 Triangle |
 Rectangle |
Вот и всё.
В последнем изображении углы треугольника сильно скруглены, edges не может верно работать, а perimeter дает слишком большую погрешность. Треугольник неудачно повернут: при построении ограничивающего прямоугольника только две вершины будут его касаться, и sbound и sbound2 не выдадут ничего разумного. Только mirror мог бы выдать корректный результат, но он не включен в дерево. Да и если из 5 метрик только одна укажет на треугольник, то можно трактовать этот вывод как ошибочный.
Вывод
Методы машинного обучения позволили построить систему, которая хорошо справляется с поставленной задачей – она достаточно хорошо распознает фигурки на изображении.
Графики были построены в R:
bitbucket.org/rampeer/image-classifier/src/HEAD/charts.R
