Последнее время большое внимание в Программе «Единая Фронтальная Система» (ЕФС) уделяется автоматизации тестовых сценариев. Причины объективны и связаны с повышением уровня зрелости отдельных подсистем Программы и объемом регрессионного тестирования.
Постоянный рост объема функционала приводит к лавинообразному росту количества автотестов, а вместе с этим растет время на анализ результатов прогонов и поиск причин ошибок. О том, как мы сократили время и ушли от ручного разбора логов, читайте под катом.

Объем данных результатов прогонов достигает критических для инженеров величин, влечет повышение рисков пропуска дефектов, ухудшение качества анализа данных и снижение скорости принятия решений.
Практика показывает, что реальное количество уникальных проблем в десятки раз меньше зарегистрированных в ходе тестов ошибок.
Инженеру сложно быстро принять решение по набору однотипных ошибок: нужно вручную найти похожие решения, зайдя в систему баг-трекинга, прочесть переписку в почте, заглянуть в Confluence, найти нужные отрывки лог-файлов аппликативной части системы (БД журналирования, файлы сервера приложений WebSphere), найти и изучить нужные скриншоты, посмотреть видео шагов тест. Можно, конечно, не искать похожие решения, но тогда возникает риск завести дублирующий открытый дефект. С целью экономии времени инженер может завести дефект с указанием неполной информации, что в свою очередь приведет к увеличению времени исправления и ухудшению качества доработки.
Именно в этот момент мы в Программе ЕФС пришли к необходимости создания автоматизированной системы — назовем ее Unified Logfile Analyzer или коротко ULA — которая бы помогла достичь двух целей:
Проектирование и разработка системы легла целиком на плечи автоматизаторов. По сути ребята делали систему для самих себя, для своего удобства, но продукт решили сделать универсальным, с возможностью применения в будущем не только в рамках текущих задач Программы.
В качестве технологического стека были выбраны:
В ULA используются данные от самих автотестов: XML, CSV, снимки экрана, видео, а также от аппликативной части тестируемых подсистем: лог-файлы WebSphere, данные из БД журналирования.

Система распределенная и состоит из нескольких модулей:
На текущий момент разработаны агенты для Allure v.1.4,v. 1.5 и Serenity. Агенты обращаются в открытый API и работают под управлением Windows или Linux.
Управляет агентами по передаче логов-автотестов к Агенту;
Альтернативное решение Jenkins plugin: результаты выполнения можно загружать в обход Дженкинса, используя maven;
API для приема результатов открыт — системой можно пользоваться без Jenkins и разработанных агентов. В этом случае автотесты либо другое вспомогательное ПО должны сами, при соблюдении спецификации загрузки данных, отправлять сообщения в ходе тестирования.
Сервис приема сообщений работает асинхронно: сначала сообщения попадают в очередь обработки, что позволяет сократить до минимума влияние системы на длительность запусков автотестов.
На данный момент реализованы и проходят тестирование ряд подсистем, рассмотрим их подробнее.
Данная подсистема обладает следующими функциями:
В данной подсистеме пользователю предоставляется возможность обогатить информацию об ошибках, полученных в ходе работы автотестов различными данными.
После запуска скриншоты тестов UI хранятся в директориях несколько дней. Считается, что в течение этого времени, запуск точно будет проанализирован. Если запуск не был проанализирован, то он был не нужен. После анализа файлы снимков экрана копируются на сервер обработки и хранятся там неограниченное время.
Видеозаписи создаются по желанию тестировщика и только для тестов, проверяющих графический интерфейс. Логика работы с ними аналогична логике работы со скриншотами.
Каждая из подсистем ЕФС логирует данные в специальную БД. В ходе анализа шага автотеста на основе маркера (сессия пользователя) записи из БД Журналирование копируются в БД ULA.
Логика их получения сложнее: кроме сессии пользователя, добавляются граничные значения времени для поиска определенных файлов и сегментов в них.
Вся информация собирается системой на одном экране, пользователю предлагается принять решение. Там же можно посмотреть данные истории принятия схожих решений, отсортированные по релевантности, привязать ошибки к существующему решению или создать новое. При создании нового решения, имеется возможность завести дефект. Основные поля дефекта заполняются автоматически, исходя из имеющихся в ULA данных. Файлы со скриншотами и логами прикрепляются автоматически.
Специально для администраторов тестовых сред была разработана подсистема оповещений о критических ошибках, которые подпадают под определенные значения в фильтре.
К примеру, недоступность сервисов на уровне TCP, ошибки HTTP (404, 500) и прочие проблемы, требующие быстрой реакции администратора. Сейчас прорабатывается задача автоматического заведения инцидентов на тестовой среде.
Опишем в упрощенном виде реализованные в системе шаги алгоритма поиска дубликатов и агрегации.
Входящее в систему сообщение (обычно это stack trace) при помощи регулярных выражений очищается от «лишних символов», таких как знаки препинания, все виды скобок, служебные символы. На выходе получается строка из слов, разделенных пробелами.
Пример канонизированного текста:
«сумма на счете не изменилась на указанную сумму ожидаемая сумма на счете 173,40 euro баланс после пополнения 173,40 euro»
Разделение проводится с шагом в одно слово. Количество слов в словосочетании называется длиной shingle.
Набор shingles с длиной 5:
«сумма на счете не изменилась»; «на счете не изменилась на»; «счете не изменилась на указанную»; «не изменилась на указанную сумму»; «изменилась на указанную сумму ожидаемая»; «на указанную сумму ожидаемая сумма»; «указанную сумму ожидаемая сумма на»; «сумму ожидаемая сумма на счете».
Полученный набор хэшей текста хранится во временной таблице до окончания сравнения с хэшами shingles всех шаблонов ошибок, заведенных в системе.
Для каждого набора shingles шаблонов ошибок вычисляется степень схожести по набору хэшей.
SIMILARITY(i) = SIMCNT * 2 / (TSCNT + THCNT(i)),
где SIMCNT – количество совпавших уникальных хэшей в двух наборах, TSCNT – количество уникальных хэшей анализируемого текста, THCNT(i) – количество уникальных хэшей шаблона i.
Ищется SIMILARITY = MAX(SIMILARITY(i)).
Если SIMILARITY больше или равно заданному порогу схожести, то тексту проставляется существующий идентификатор шаблона.
Если SIMILARITY меньше порога схожести, то канонизированный текст сам становится шаблоном, а набор хэшей shingles записывается в БД.
Справедливый вопрос – зачем вы писали систему сами, когда на рынке уже имеется аналогичный продукт, например, Report Portal от компании EPAM.
Зрелое, качественное и красивое решение, на разработку которого ребята потратили более четырех лет, и которое с некоторых пор распространяется свободно.
Однако есть разница в подходах, для удобства сравнения мы представили это в таблице.
Unified Logfile Analyzer – система, которую мы собрали с нуля, разработали ее, учитывая свой опыт, опыт коллег, проанализировав существующие на рынке решения. Система самообучаемаемая, помогает нам быстрее находить и точно исправлять баги — куда без них.
Сейчас мы запускаем ULA в продуктив, будем раскатывать на продуктах и сервисах Программы ЕФС. В следующем посте расскажем о первых результатах и поделимся кейсами.
Будем рады обсудить решение и поспорить о подходах, поделитесь опытом и кейсами в комментариях!
Постоянный рост объема функционала приводит к лавинообразному росту количества автотестов, а вместе с этим растет время на анализ результатов прогонов и поиск причин ошибок. О том, как мы сократили время и ушли от ручного разбора логов, читайте под катом.

Объем данных результатов прогонов достигает критических для инженеров величин, влечет повышение рисков пропуска дефектов, ухудшение качества анализа данных и снижение скорости принятия решений.
Практика показывает, что реальное количество уникальных проблем в десятки раз меньше зарегистрированных в ходе тестов ошибок.
Инженеру сложно быстро принять решение по набору однотипных ошибок: нужно вручную найти похожие решения, зайдя в систему баг-трекинга, прочесть переписку в почте, заглянуть в Confluence, найти нужные отрывки лог-файлов аппликативной части системы (БД журналирования, файлы сервера приложений WebSphere), найти и изучить нужные скриншоты, посмотреть видео шагов тест. Можно, конечно, не искать похожие решения, но тогда возникает риск завести дублирующий открытый дефект. С целью экономии времени инженер может завести дефект с указанием неполной информации, что в свою очередь приведет к увеличению времени исправления и ухудшению качества доработки.
Именно в этот момент мы в Программе ЕФС пришли к необходимости создания автоматизированной системы — назовем ее Unified Logfile Analyzer или коротко ULA — которая бы помогла достичь двух целей:
- минимизация времени анализа результатов автотестов;
- минимизация количества дублирующих дефектов.
С чего начинали?
Проектирование и разработка системы легла целиком на плечи автоматизаторов. По сути ребята делали систему для самих себя, для своего удобства, но продукт решили сделать универсальным, с возможностью применения в будущем не только в рамках текущих задач Программы.
В качестве технологического стека были выбраны:
- СУБД Oracle 11g для хранения справочных данных, истории;
- Oracle TimesTen In-Memory Database 11g для хранения хэшей shingles;
- Jersey для микросервисов;
- React JS для FrontEnd.
В ULA используются данные от самих автотестов: XML, CSV, снимки экрана, видео, а также от аппликативной части тестируемых подсистем: лог-файлы WebSphere, данные из БД журналирования.
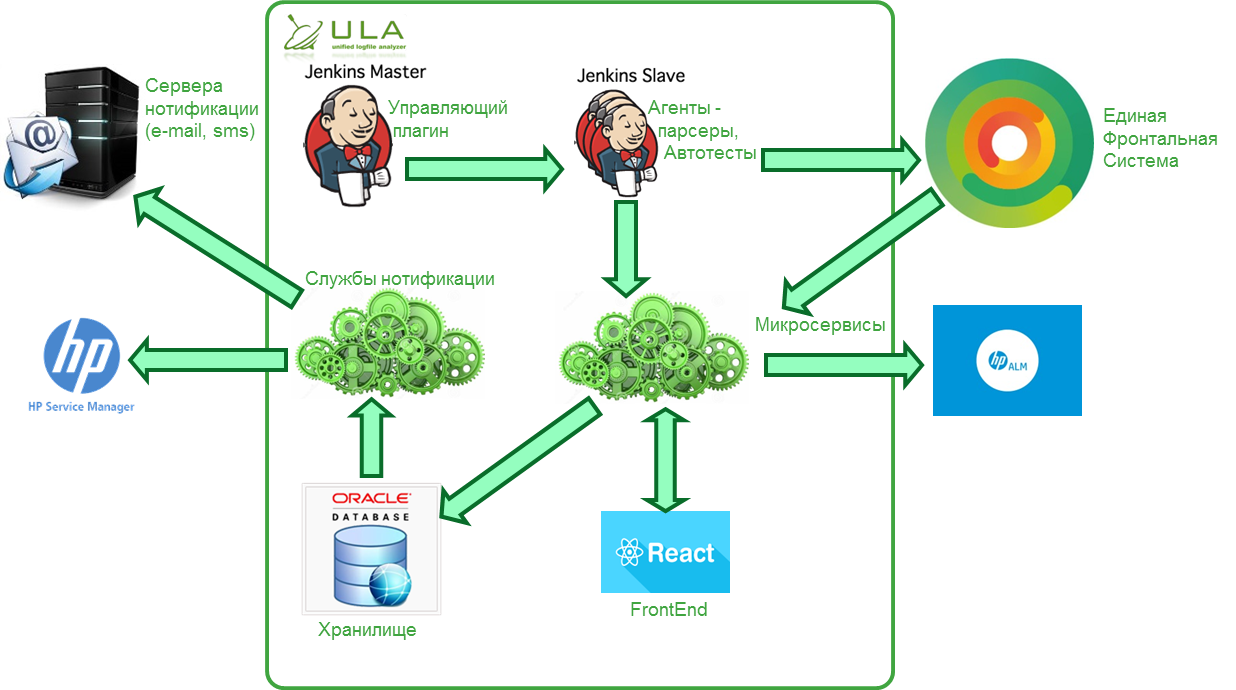
Система распределенная и состоит из нескольких модулей:
- Агенты по разбору логов автотестов;
На текущий момент разработаны агенты для Allure v.1.4,v. 1.5 и Serenity. Агенты обращаются в открытый API и работают под управлением Windows или Linux.
- Plugin Jenkins;
Управляет агентами по передаче логов-автотестов к Агенту;
- Maven Plugin;
Альтернативное решение Jenkins plugin: результаты выполнения можно загружать в обход Дженкинса, используя maven;
- Набор микросервисов с функциями приема новых сообщений, принятия событий о завершении запусков, для функционирования Frontend части;
- Frontend на базе React JS;
- База данных под управлением Oracle 11g;
- Службы нотификации для рассылки результатов тестов по определенным каналам.
API для приема результатов открыт — системой можно пользоваться без Jenkins и разработанных агентов. В этом случае автотесты либо другое вспомогательное ПО должны сами, при соблюдении спецификации загрузки данных, отправлять сообщения в ходе тестирования.
Сервис приема сообщений работает асинхронно: сначала сообщения попадают в очередь обработки, что позволяет сократить до минимума влияние системы на длительность запусков автотестов.
На данный момент реализованы и проходят тестирование ряд подсистем, рассмотрим их подробнее.
Подсистема агрегации сообщений об ошибках
Данная подсистема обладает следующими функциями:
- прием сообщений от автотестов;
- парсинг стандартных отчетов: Allure для API-тестов и Serenity для UI-тестов;
- агрегация сообщений методом нечеткого поиска. В качестве основы был выбран алгоритм поиска нечетких дубликатов текстов (shingles);
- автоматическое заведение шаблонов ошибок (обучение без учителя).
Подсистема принятия решений
В данной подсистеме пользователю предоставляется возможность обогатить информацию об ошибках, полученных в ходе работы автотестов различными данными.
Скриншоты
После запуска скриншоты тестов UI хранятся в директориях несколько дней. Считается, что в течение этого времени, запуск точно будет проанализирован. Если запуск не был проанализирован, то он был не нужен. После анализа файлы снимков экрана копируются на сервер обработки и хранятся там неограниченное время.
Видеозаписи прохождения тестов
Видеозаписи создаются по желанию тестировщика и только для тестов, проверяющих графический интерфейс. Логика работы с ними аналогична логике работы со скриншотами.
БД
Каждая из подсистем ЕФС логирует данные в специальную БД. В ходе анализа шага автотеста на основе маркера (сессия пользователя) записи из БД Журналирование копируются в БД ULA.
Плоские текстовые файлы с системными логами
Логика их получения сложнее: кроме сессии пользователя, добавляются граничные значения времени для поиска определенных файлов и сегментов в них.
Вся информация собирается системой на одном экране, пользователю предлагается принять решение. Там же можно посмотреть данные истории принятия схожих решений, отсортированные по релевантности, привязать ошибки к существующему решению или создать новое. При создании нового решения, имеется возможность завести дефект. Основные поля дефекта заполняются автоматически, исходя из имеющихся в ULA данных. Файлы со скриншотами и логами прикрепляются автоматически.
Подсистема оповещений
Специально для администраторов тестовых сред была разработана подсистема оповещений о критических ошибках, которые подпадают под определенные значения в фильтре.
К примеру, недоступность сервисов на уровне TCP, ошибки HTTP (404, 500) и прочие проблемы, требующие быстрой реакции администратора. Сейчас прорабатывается задача автоматического заведения инцидентов на тестовой среде.
Опишем в упрощенном виде реализованные в системе шаги алгоритма поиска дубликатов и агрегации.
- Шаг 1. Канонизация текста.
Входящее в систему сообщение (обычно это stack trace) при помощи регулярных выражений очищается от «лишних символов», таких как знаки препинания, все виды скобок, служебные символы. На выходе получается строка из слов, разделенных пробелами.
Пример канонизированного текста:
«сумма на счете не изменилась на указанную сумму ожидаемая сумма на счете 173,40 euro баланс после пополнения 173,40 euro»
- Шаг 2. Разделение на словосочетания (shingles).
Разделение проводится с шагом в одно слово. Количество слов в словосочетании называется длиной shingle.
Набор shingles с длиной 5:
«сумма на счете не изменилась»; «на счете не изменилась на»; «счете не изменилась на указанную»; «не изменилась на указанную сумму»; «изменилась на указанную сумму ожидаемая»; «на указанную сумму ожидаемая сумма»; «указанную сумму ожидаемая сумма на»; «сумму ожидаемая сумма на счете».
- Шаг 3. Вычисление хэшей shingles по алгоритму MD5.
Полученный набор хэшей текста хранится во временной таблице до окончания сравнения с хэшами shingles всех шаблонов ошибок, заведенных в системе.
Для каждого набора shingles шаблонов ошибок вычисляется степень схожести по набору хэшей.
SIMILARITY(i) = SIMCNT * 2 / (TSCNT + THCNT(i)),
где SIMCNT – количество совпавших уникальных хэшей в двух наборах, TSCNT – количество уникальных хэшей анализируемого текста, THCNT(i) – количество уникальных хэшей шаблона i.
- Шаг 4. Выбирается подходящий шаблон ошибки.
Ищется SIMILARITY = MAX(SIMILARITY(i)).
Если SIMILARITY больше или равно заданному порогу схожести, то тексту проставляется существующий идентификатор шаблона.
Если SIMILARITY меньше порога схожести, то канонизированный текст сам становится шаблоном, а набор хэшей shingles записывается в БД.
- Заключительный этап.
Поговорим об аналогах
Справедливый вопрос – зачем вы писали систему сами, когда на рынке уже имеется аналогичный продукт, например, Report Portal от компании EPAM.
Зрелое, качественное и красивое решение, на разработку которого ребята потратили более четырех лет, и которое с некоторых пор распространяется свободно.
Однако есть разница в подходах, для удобства сравнения мы представили это в таблице.
| ReportPortal |
Unified Logfile Analyzer |
| Акцент на анализе логов самих автотестов, в которых также могут быть дефекты, включая дефекты логирования |
Указывает пользователю на подозрительные автотесты, когда тест помечен как успешно пройденный, но по нему имеются ошибки, или, наоборот, когда тест провален, но никаких ошибок не зарегистрировано |
| В основе алгоритма определения схожести используется расстояние Левенштейна |
Нам не подходит данный алгоритм, так как на длинных словах расстояние получается существенным В своем решении используем алгоритм Shingles (http://ethen8181.github.io/machine-learning/clustering_old/text_similarity/text_similarity.html) |
| В Report Portal мы пока не увидели этой возможности. Возможно, в будущем появится. |
Информация от автотестов (тексты ошибок, скриншоты, видеозапись теста) обогащается информацией из аппликативной части самих систем (файлы, БД), что улучшает качество анализа |
| Большое внимание уделено отчетности: графики, разнообразная статистика |
Функционал отчетности планируем реализовать отдельно |
| Не предусмотрена интеграция с HP ALM |
Есть интеграция с HP ALM, для нас это важно |
| Используется нереляционная база данных MongoDB. Спорить на эту тему можно долго |
По нашему мнению, решение на Oracle 11g будет вести себя более предсказуемо в части потребления ресурсов |
Unified Logfile Analyzer – система, которую мы собрали с нуля, разработали ее, учитывая свой опыт, опыт коллег, проанализировав существующие на рынке решения. Система самообучаемаемая, помогает нам быстрее находить и точно исправлять баги — куда без них.
Сейчас мы запускаем ULA в продуктив, будем раскатывать на продуктах и сервисах Программы ЕФС. В следующем посте расскажем о первых результатах и поделимся кейсами.
Будем рады обсудить решение и поспорить о подходах, поделитесь опытом и кейсами в комментариях!
