
В высоконагруженных проектах всегда повышенные требования к избыточности и надежности. Одним из важнейших звеньев инфраструктуры является маршрутизатор, потому что от его устойчивости зависит доступность сети в целом. Именно на таких узлах мы используем одну из схем реализации отказоустойчивого виртуального роутера на базе GNU/Linux с использованием iproute2, NetGWM, keepalived, ISC DHCPD, PowerDNS. Как мы всё это настраиваем, читайте в этой статье.
Компоненты
В идеальной схеме отказоустойчивого роутера мы резервируем все элементы, которые могут привести к недоступности сети, то есть:
- каналы связи,
- коммутаторы,
- маршрутизаторы.
В общем виде схема (на уровне L2) выглядит так:
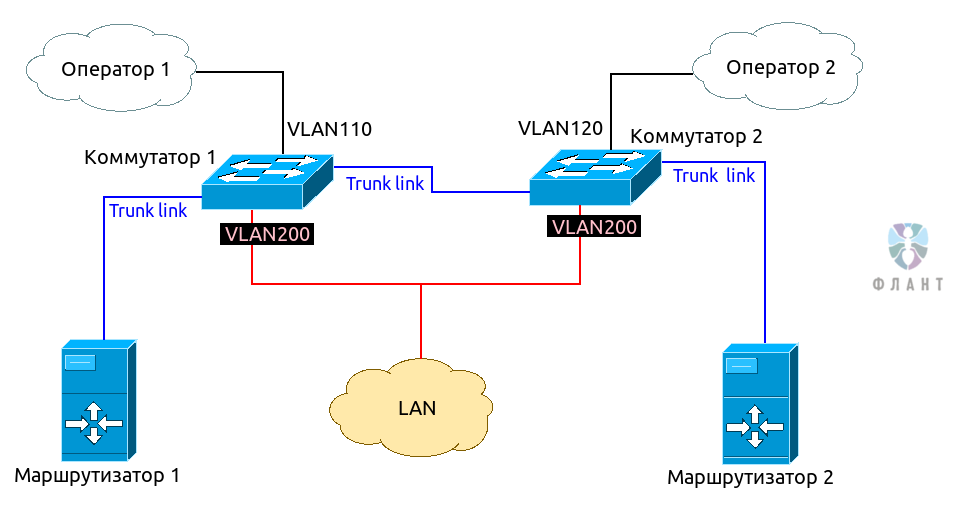
Как видно из схемы, нам нужны 2 коммутатора с поддержкой 802.1Q VLAN. Оператор 1 коммутируется в Коммутатор 1 и ему выделяется отдельный VLAN (например, 110). Оператор 2 коммутируется в Коммутатор 2, в другой VLAN (например, 120). Отдельный VLAN (в нашем случае — 200), выделяется под локальную сеть. Между коммутаторами организуется транк, и транком же линкуем оба маршрутизатора, которые и будут «сердцем» нашего виртуального роутера (схема router-on-a-stick).
Такая компоновка позволяет оставлять работоспособной сеть при выходе из строя любого компонента: роутера, коммутатора или оператора.
Стек базовых компонентов, которые мы используем в работе роутеров:
- Ubuntu Linux;
- NetGWM — утилита приоритезации основного шлюза в решении. Это наша Open Source-разработка, о которой мы готовим отдельную статью (пока предлагаю ознакомиться с базовой документацией) [Обновлено 08.08.2017: статья опубликована как «Настройка основного и двух резервных операторов на Linux-роутере с NetGWM»];
- iproute2 — для создания нескольких таблиц маршрутизации;
- keepalived — для реализации протокола VRRP в Linux;
- ISC DHCPD — как горизонтально масштабируемый DHCP-сервер;
- PowerDNS — как DNS-сервер для локальной сети.
Маршрутизаторы настраиваются примерно одинаково, за исключением конфигурации IP-адресов и keepalived.
Настройка интерфейсов
Настраиваем VLAN. Конфигурация
/etc/network/interfaces будет выглядеть примерно так:auto lo
iface lo inet loopback
post-up bash /etc/network/iprules.sh
post-up ip route add blackhole 192.168.0.0/16
dns-nameservers 127.0.0.1
dns-search dz
# lan, wan: trunk dot1q
auto eth0
iface eth0 inet manual
# lan
auto vlan200
iface vlan200 inet static
vlan_raw_device eth0
address 192.168.1.2
netmask 255.255.255.0
# Operator1
auto vlan110
iface vlan110 inet static
vlan_raw_device eth0
address 1.1.1.2
netmask 255.255.255.252
post-up ip route add default via 1.1.1.1 table oper1
post-up sysctl net.ipv4.conf.$IFACE.rp_filter=0
post-down ip route flush table oper1
# Operator2
auto vlan120
iface vlan120 inet static
vlan_raw_device eth0
address 2.2.2.2
netmask 255.255.255.252
post-up ip route add default via 2.2.2.1 table oper2
post-up sysctl net.ipv4.conf.$IFACE.rp_filter=0
post-down ip route flush table oper2
Основные моменты:
- настраиваем blackhole — хорошая практика для того, чтобы локальные пакеты не улетали по маршруту по умолчанию в сторону провайдера;
-
net.ipv4.conf.$IFACE.rp_filter=0— необходим для корректной работы multi-wan; - для каждого провайдера настраиваем отдельную таблицу маршрутизации с единственным маршрутом по умолчанию.
Настроим маркинг пакетов для направления в определенные таблицы — добавим в iptables правила:
iptables -t mangle -A PREROUTING -i vlan110 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A PREROUTING -i vlan120 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff
iptables -t mangle -A OUTPUT -o vlan110 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A OUTPUT -o vlan120 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff
iptables -t mangle -A POSTROUTING -o vlan110 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A POSTROUTING -o vlan120 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
И настроим правила маршрутизации для промаркированных пакетов — мы это делаем вызовом скрипта
iprules.sh при выполнении ifup lo (смотри выше в /etc/network/interfaces). Внутри скрипта:#!/bin/bash
/sbin/ip rule flush
#operator 1
/sbin/ip rule add priority 8001 iif vlan110 lookup main
/sbin/ip rule add priority 10001 fwmark 0x1/0x3 lookup oper1
/sbin/ip rule add from 1.1.1.2 lookup oper1
#operator 2
/sbin/ip rule add priority 8002 iif vlan120 lookup main
/sbin/ip rule add priority 10002 fwmark 0x2/0x3 lookup operator2
/sbin/ip rule add from 2.2.2.2 lookup operator2
Эти таблицы маршрутизации необходимо объявить в
/etc/iproute2/rt_tables:# reserved values
255 local
254 main
253 default
0 unspec
# local
110 oper1
120 oper2
Балансировщик основного шлюза
Настроим NetGWM — утилиту для приоритезации основного шлюза. Она будет устанавливать маршрут по умолчанию, выбирая операторов в соответствии с двумя правилами: а) установленным нами приоритетом, б) статусом оператора (жив или нет).
Чтобы установить NetGWM, можно воспользоваться исходниками на GitHub или нашим репозиторием для Ubuntu. Второй способ в случае Ubuntu 14.04 LTS выглядит так:
# Установим репозиторий
$ sudo wget https://apt.flant.ru/apt/flant.trusty.common.list -O /etc/apt/sources.list.d/flant.common.list
# Импортируем ключ
$ wget https://apt.flant.ru/apt/archive.key -O- | sudo apt-key add -
# Понадобится HTTPS-транспорт — установите его, если не сделали это раньше
$ sudo apt-get install apt-transport-https
# Обновим пакетную базу и установим netgwm
$ sudo apt-get update && sudo apt-get install netgwmУкажем в конфиге
/etc/netgwm/netgwm.yml, что у нас 2 оператора, маршруты по умолчанию для каждого из них, приоритезацию и настройки для контроля доступности:# Описываем маршруты по умолчанию для каждого оператора и приоритеты
# Меньшее значение (число) имеет больший приоритет
gateways:
oper1: {ip: 1.1.1.1, priority: 1}
oper2: {ip: 2.2.2.1, priority: 2}
# В ситуации, когда более приоритетного оператора начинает «штормить»
# и он то online, то offline, хочется избежать постоянных переключений
# туда-сюда. Этот параметр определяет время (в секундах), после которого
# netgwm будет считать, что связь стабильна
min_uptime: 900
# Массив удаленных хостов, которые будут использоваться netgwm для
# проверки работоспособности каждого оператора
check_sites:
- 192.5.5.241
- 198.41.0.4Обратите внимание на имена
oper1 и oper2 — это названия таблиц маршрутизации из /etc/iproute2/ip_tables. Рестартнем сервис netgwm, чтобы он начал управлять шлюзом по умолчанию для системы:$ sudo service netgwm restartНастройка keepalived
Keepalived — реализация протокола VRRP для Linux. Этот протокол позволяет реализовать схему с отказоустойчивой маршрутизацией, создавая виртуальный IP, который будет использоваться в качестве маршрута по умолчанию для обслуживаемой сети. Виртуальный IP автоматически передается резервному серверу при выходе из строя основного сервера.
На этом этапе мы определяемся, что Маршрутизатор 2 будет играть роль Backup, а Маршрутизатор 1 — роль Master. Настраиваем keepalived, изменяя конфигурационный файл
/etc/keepalived/keepalived.conf:! Глобальный блок можно настраивать под себя
! Configuration File for keepalived
global_defs {
notification_email {
admin@fromhabr.ru
}
notification_email_from keepalived@example.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MY_ROUTER
}
vrrp_instance VI_1 {
interface vlan200 # VRRP обслуживает VLAN локальной сети
virtual_router_id 17 # поставьте любое число, но одинаковое на Master и Backup
nopreempt # важный параметр, подробнее см. ниже
state MASTER # на резервном сервере установите state BACKUP
priority 200 # на резервном сервере число должно быть ниже, например 100
advert_int 1 # интервал рассылки сообщения “Я жив”
garp_master_delay 1
garp_master_refresh 60
authentication {
auth_type PASS
auth_pass qwerty # не забудьте поменять пароль
}
virtual_ipaddress {
# Виртуальный адрес, который будет шлюзом по умолчанию в локальной сети и
# заодно широковещательный адрес, в который будут рассылаться VRRP-анонсы
192.168.1.1/24 broadcast 192.168.1.255 dev vlan200
}
# Скрипты вызываются при переходе в соответствующее состояние Master, Backup, Fault и
# при остановке keepalived; используются нами для передачи уведомлений
notify_master /etc/keepalived/scripts/master.sh
notify_backup /etc/keepalived/scripts/backup.sh
notify_stop /etc/keepalived/scripts/stop.sh
notify_fault /etc/keepalived/scripts/fault.sh
}Так как наш отказоустойчивый роутер — многокомпонентный, мы решили использовать режим, в котором переключение keepalived режимов Backup → Master происходит только в случае отказа Master-сервера. За это как раз отвечает параметр
nopreempt. Настройка ISC DHCPD
ISC DHCPD был выбран нами, так как позволяет масштабировать DHCP на несколько серверов. Он прост в конфигурировании и хорошо зарекомендовал себя на практике. Кроме того, нам понравилось, что разработчики этого DHCP-сервера придумали изящное решение для организации реплики между серверами. Для основного и второстепенного серверов выделяются разные пулы адресов и на запросы отвечает сервер, который успел сделать это первым, выдавая адрес из своего пула. При этом база арендованных IP синхронизируется. В случае, если один из серверов отказывает, второй как ни в чем не бывало продолжает выдачу адресов из своего пула. При возврате отказавшего сервера он начинает выдачу из своего пула, при этом не возникает коллизий.
Правим конфиг
/etc/dhcp/dhcpd.conf:# Настраиваем DDNS для локальных адресов
ddns-updates on;
ddns-update-style interim;
do-forward-updates on;
update-static-leases on;
deny client-updates; # ignore, deny, allow
update-conflict-detection false;
update-optimization false;
key "update-key" {
algorithm hmac-md5;
secret "КЛЮЧ"; # про генерацию ключа см. ниже
};
zone 1.168.192.in-addr.arpa. {
primary 192.168.1.1;
key "update-key";
}
zone mynet. {
primary 192.168.1.1;
key "update-key";
# Настраиваем масштабирование
failover peer "failover-partner" {
primary; # на резервном сервере укажите здесь secondary
address 192.168.1.3; # адрес резервного сервера
port 519;
peer address 192.168.1.2; # адрес основного сервера
peer port 520;
max-response-delay 60;
max-unacked-updates 10;
load balance max seconds 3;
}
default-lease-time 2400;
max-lease-time 36000;
log-facility local7;
authoritative;
option ntp-servers 192.168.1.1, ru.pool.ntp.org;
# Настраиваем пул для нашего сервера
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.51 192.168.1.150; # на 100 адресов, например
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.1.255;
option domain-name-servers 192.168.1.1;
option routers 192.168.1.1;
ddns-domainname "mynet.";
# … и пул для резервного. Они не должны пересекаться
pool {
failover peer "failover-partner";
range 192.168.1.151 192.168.1.250;
}
# … и статические leases
host printer { hardware ethernet 00:26:73:47:94:d8; fixed-address 192.168.1.8; }
}
Нам понадобится сгенерировать ключ
update_key, с помощью которого мы будем обновлять зону mynet. Сгенерируем его и выведем на экран:$ dnssec-keygen -r /dev/urandom -a HMAC-MD5 -b 64 -n HOST secret_key
Ksecret_key.+157+64663
$ cat Ksecret_key.+*.private | grep ^Key | awk '{print $2}'
bdvkG1HcHCM=Скопируйте сгенерированный ключ и вставьте в конфигурационный файл вместо слова КЛЮЧ.
Настройка PowerDNS
В качестве DNS-сервера мы предпочли PowerDNS, так как он имеет возможность хранить зоны в СУБД MySQL, которую удобно реплицировать между первым и вторым сервером. Кроме того, PoweDNS — это производительное решение, хорошо функционирующее в высоконагруженном роутере.
Настройку PowerDNS начнем с подготовки базы данных.
# Заходим в MySQL CLI
$ mysql -u root -p
# Создаем БД и назначаем права для пользователя, которым будем к ней подключаться
mysql> CREATE DATABASE IF NOT EXIST powerdns;
mysql> GRANT ALL ON powerdns.* TO 'pdns_admin'@'localhost' IDENTIFIED BY 'pdns_password';
mysql> GRANT ALL ON powerdns.* TO 'pdns_admin'@'localhost.localdomain' IDENTIFIED BY 'pdns_password';
mysql> FLUSH PRIVILEGES;
# Переходим в только что созданную БД и создаем структуру данных
mysql> USE powerdns;
mysql> CREATE TABLE IF NOT EXIST `domains` (
id INT auto_increment,
name VARCHAR(255) NOT NULL,
master VARCHAR(128) DEFAULT NULL,
last_check INT DEFAULT NULL,
type VARCHAR(6) NOT NULL,
notified_serial INT DEFAULT NULL,
account VARCHAR(40) DEFAULT NULL,
primary key (id)
);
mysql> CREATE TABLE `records` (
id INT auto_increment,
domain_id INT DEFAULT NULL,
name VARCHAR(255) DEFAULT NULL,
type VARCHAR(6) DEFAULT NULL,
content VARCHAR(255) DEFAULT NULL,
ttl INT DEFAULT NULL,
prio INT DEFAULT NULL,
change_date INT DEFAULT NULL,
primary key(id)
);
mysql> CREATE TABLE `supermasters` (
ip VARCHAR(25) NOT NULL,
nameserver VARCHAR(255) NOT NULL,
account VARCHAR(40) DEFAULT NULL
);
mysql> CREATE INDEX `domain_id` ON `records`(`domain_id`);
mysql> CREATE INDEX `rec_name_index` ON `records`(`name`);
mysql> CREATE INDEX `nametype_index` ON `records`(`name`,`type`);
mysql> CREATE UNIQUE INDEX name_index` ON `domains`(`name`);
quit;Теперь нужно настроить PowerDNS и научить его работать с БД. Для этого требуется установить пакет
pdns-backend-mysql и изменить конфиг /etc/powerdns/pdns.conf:# Настраиваем доверенные сети
allow-axfr-ips=127.0.0.0/8,192.168.1.0/24
allow-dnsupdate-from=127.0.0.0/8,192.168.1.0/24
allow-recursion=127.0.0.0/8,192.168.1.0/24
# Базовые настройки демона
config-dir=/etc/powerdns
daemon=yes
disable-axfr=no
dnsupdate=yes
guardian=yes
local-address=0.0.0.0
local-address-nonexist-fail=no
local-port=53
local-ipv6=::1
# На втором маршрутизаторе такие же значения этих параметров
master=yes
slave=no
recursor=127.0.0.1:5353
setgid=pdns
setuid=pdns
socket-dir=/var/run
version-string=powerdns
webserver=no
# Настраиваем MySQL
launch=gmysql
# Хост с БД - тот самый, которым управляет keepalived
gmysql-host=192.168.1.1
gmysql-port=3306
# Имя и пароль пользователя, которого мы создавали в БД
gmysql-user=pdns_admin
gmysql-password=pdns_password
gmysql-dnssec=yesНа этом базовая конфигурация PowerDNS закончена. Нам же ещё потребуется настроить рекурсор — обработчик рекурсивных DNS-запросов, который позволяет значительно повысить производительность DNS-сервера. Правим файл
/etc/powerdns/recursor.conf:daemon=yes
forward-zones-file=/etc/powerdns/forward_zones
local-address=127.0.0.1
local-port=5353
quiet=yes
setgid=pdns
setuid=pdns
В файл
forward_zones вносим зоны intranet, которые обслуживают соседние серверы:piter_filial.local=192.168.2.1
2.168.192.in-addr.arpa=192.168.2.1По окончании настройки перезапускаем сервисы
pdns и pdns-recursor.После запуска настраиваем реплику MySQL между серверами.
Заключение
Мы используем данное решение не только в чистом виде. В большинстве случаев оно усложняется добавлением туннелей VTun, OpenVPN или IPSec через основного и резервного оператора связи и динамической маршрутизацией, которая реализуется с помощью Quagga. Поэтому схему, предложенную в статье, предлагаю воспринимать как фундамент для создания более сложных решений.
Будем рады, если вы зададите свои вопросы в комментариях или укажете на места в схеме, которые можно улучшить. И, конечно, подписывайтесь на наш хаб, чтобы не пропускать новые полезные материалы! )
