

Kubernetes стал для нас той технологией, которая в полной мере позволяет соответствовать строгим требованиям к отказоустойчивости, масштабируемости и качественному обслуживанию проекта. Несмотря на то, что сегодня K8s больше распространен в крупных организациях и проектах, мы научились применять его и в небольших приложениях. Снижение себестоимости обслуживания стало возможным для нас благодаря унификации и обобщению всех компонентов, которые встречаются практически у каждого клиента. Эта статья — взгляд на полученный опыт со стороны бизнес-потребностей и их технической реализации, которая позволяет нам предлагать клиентам качественное решение и поддержку за разумные деньги.
«Rocket science» как норма
Начну с общих слов о том, как мы вообще к этому пришли, а обзор технических деталей по предлагаемой инфраструктуре читайте ниже.
Около 10 официальных лет «Флант» занимается системным администрированием GNU/Linux и бесчисленного множества сопутствующих технологий и программного обеспечения. Все это время мы улучшали свои рабочие процессы, часто сравнивая компанию с заводом, который переходит от ручного труда (необходимости «вручную» заходить на сервер при возникновении множества однообразных проблем) к потоковому производству (типовым конфигурациям, централизованному управлению, автоматическому деплою и т.п.). Даже несмотря на то, что многие обслуживаемые нами проекты сильно отличаются (в стеке применяемых технологий, требованиях к производительности и масштабированию…), у них есть фундамент, который подлежит систематизации. Этот факт позволяет превратить качественное обслуживание в типовое, обеспечивая клиента дополнительными преимуществами за разумные деньги.
Взращивая внутри компании лучшие практики на основе опыта работы с разными проектами, обобщая и по возможности «программируя» их, мы распространяем эти результаты на другие имеющиеся инсталляции. Раньше ключевым инструментом для этого служила система управления конфигурациями (мы предпочитали Chef). Постепенно внедряя в инфраструктуру Docker-контейнеры, мы пошли на логичный шаг по интеграции их настройки с возможностями Chef (реализовали это в рамках своего инструмента dapp)…
Но с появлением Kubernetes многое изменилось. Теперь мы описываем конфигурации в Kubernetes и получаем (предлагаем клиентам) инфраструктуру, которая:
- централизованно управляется,
- быстро разворачивается,
- легко дополняется новыми сервисами,
- не зависит от поставщика ресурсов (облачного провайдера, дата-центра),
- масштабируется в случаях усложнения проекта или растущих нагрузок,
- просто интегрируется с современными процессами и технологиями непрерывной интеграции и доставки приложений (CI/CD).
Такой подход к инфраструктуре — результат наших продолжительных поисков оптимального решения, бесчисленных проб и ошибок, по-настоящему многогранного опыта обслуживания ИТ-систем. Это наше текущее видение разумной «нормы» для проектов разных масштабов.
Частое ощущение, которое после этого возникает у владельцев бизнеса: «Ну, звучит классно, но это какой-то rocket science, и он не для нас, потому что слишком сложен и дорог». Однако наш опыт показывает, что этот «rocket science» идеально подходит даже для тех, кто думает, что ещё «не на том уровне» для внедрения Kubernetes:
- Выгода — инфраструктура, которая не только просто работает, чинится в случае аварий и постепенно (по мере запросов) улучшается… Это инфраструктура, которая по своей «природе» закрывает все потребности по отказоустойчивости, масштабируемости и сопровождению разработки (любые тестовые контуры, деплой, CI/CD). Она построена на лучших практиках DevOps и Open Source-компонентах, являющихся стандартом индустрии.
- Сложность — зона нашей ответственности, которая как раз и заключается ровно в том, чтобы, наоборот, сделать результат максимально простым для пользователей, т.е. разработчиков.
- Стоимость — обычная ежемесячная абонентская плата за обслуживание такой типовой инфраструктуры для небольшого проекта составляет от 80 до 120 тыс. рублей, что сопоставимо с наймом одного «условно среднего» Linux-инженера.
О том, что мы понимаем под небольшим проектом и какие у него потребности, написано в следующем абзаце, с которого и начинается рассказ об устройстве типовой инфраструктуры.
Технические подробности
Что за «небольшой проект»?
Рассматриваемая в статье архитектура уже реализована во множестве проектов различной направленности: это СМИ, интернет-магазины, онлайн-игры, социальные сети, блокчейн-платформы и т.п.
Что такое небольшой проект, на который она рассчитана? Критерии не являются очень строгими, но обозначают основные тенденции и требования:
- Это проект, у которого уже больше 1 сервера (верхнюю границу называть неправильно, так как архитектура может быть развернута на множестве серверов).
- Проекту уже требуется отказоустойчивость, так как он является инструментом бизнеса и приносит прибыль.
- Проект должен быть готов к высоким нагрузкам, и существует реальная потребность в возможности быстрого масштабирования (например, интернет-магазин должен временно увеличить серверные мощности перед Black Friday).
- Проекту уже требуется системный администратор, потому что без него ничего не получается.
Если очень кратко описать архитектуру в целом, то можно сказать, что это «отказоустойчивое и масштабируемое облако Docker-контейнеров, которое находится под управлением Kubernetes». И вот что в неё входит…
Приложение в Kubernetes
Здесь и далее я возьму в качестве примера типовой интернет-магазин. Представим себе, что есть 3 сервера, на которых развернут кластер Kubernetes. Kubernetes — это главная составляющая архитектуры, это компонент, который занимается оркестровкой Docker-контейнеров и их управлением. Он отвечает за надежную, отказоустойчивую и масштабируемую работу контейнеров, внутри которых работает приложение клиента. Т.е. по сути это облако из контейнеров, работающее на трех серверах. Если один из серверов, на которых работает облако, выходит из строя, то Kubernetes автоматически перекидывает упавшие контейнеры (работавшие на упавшем сервер) на оставшиеся два сервера — это происходит очень быстро, в течение нескольких секунд.
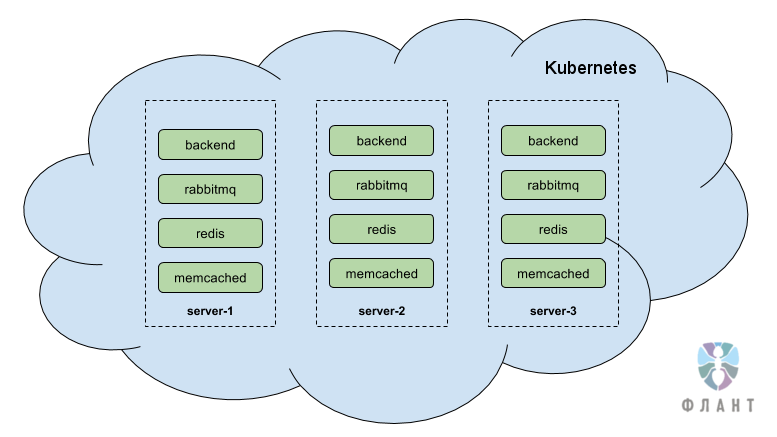
Наша цель — падение одного сервера или даже двух серверов в облаке должно быть незаметным событием. Это достигается за счет того, что каждый компонент как минимум однократно продублирован и внутри облака экземпляры одного компонента расположены на разных серверах. При этом резервный компонент готов мгновенно принять нагрузку на себя. Если приложение поддерживает, то возможен вариант, когда все экземпляры компонента работают одновременно, а не в режиме «главный-резерв». Также есть возможность по нажатию кнопки «отмасштабироваться» и получить еще один-два-три и более дополнительных экземпляров этого компонента.
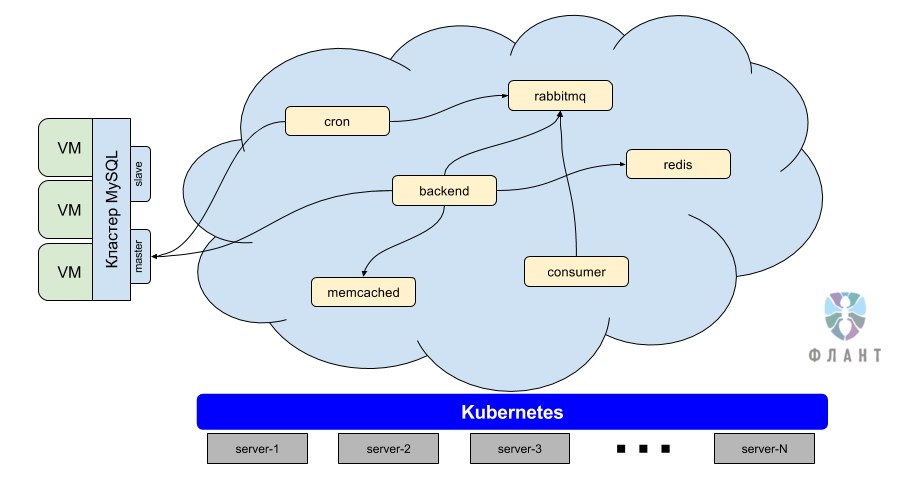
Представим себе, что интернет-магазин написан на PHP и у него есть следующие компоненты*:
- база данных MySQL;
- PHP-бэкенд;
- кеширование в memcached;
- очередь RabbitMQ;
- хранение заказов в Redis;
- консьюмер;
- cron-задачи.
* В действительности же не так важно, интернет-магазин это или сайт СМИ, и даже сами компоненты могут быть совсем иными, но суть останется прежней.
Как вы уже могли догадаться, часть нашей работы состоит в том, чтобы упаковать приложение (в данном случае — интернет-магазин) в Docker-контейнеры, а затем запустить эти контейнеры в облаке Kubernetes. Помимо самого приложения (PHP-бэкенда) в облаке работают и остальные компоненты: memcached, RabbitMQ и т.п.
Примечание: Мы до сих пор не устанавливаем РСУБД в production внутрь облака Kubernetes по некоторым технологическим причинам. Однако начали делать первые такие инсталляции для маленьких проектов и приложений не в production (dev-контуры и т.п.).
Все проекты зачастую имеют примерно одинаковый стек компонентов, а различия скорее заключаются в языках программирования и базах данных. Внедрение Kubernetes дало нам хорошую возможность реализовать типовую конфигурацию каждого из этих компонентов, которая подойдет любому проекту. При этом такой типовой компонент сам по себе отказоустойчив, легко масштабируется, а также ставится в любой кластер Kubernetes в течение 5 минут. Для примера рассмотрю каждый из компонентов отдельно.
Базы данных
СУБД выделены в отдельную сущность, так как они в большинстве случаев находятся за пределами Kubernetes и обычно представляют собой 2 или 3 сервера, которые работают в режиме master-slave (MySQL, PostgreSQL, ...) или master-master (Percona XtraDB), с автоматическим или ручным failover на случай аварийной ситуации.
PHP-бэкенд
Бэкенд представляет собой код приложения, упакованный в Docker-контейнер. В этом контейнере установлены необходимые приложению библиотеки и софт (например, PHP 7). Тот же самый контейнер используется для запуска консьюмеров и cron-задач. В Kubernetes мы запускаем несколько экземпляров бэкенда, один крон и несколько консьюмеров.
Memcached
С memcached у нас исторически сложилось два варианта реализации, которые применяются в различных ситуациях:
- N отдельных экземпляров memcached (обычно 3). Приложение знает о всех трех memcached и пишет во все три, само обеспечивает failover.
- Mcrouter — универсальный вариант, который подойдет любому приложению. Логика распределенной записи и failover вынесена из приложения на сторону mcrouter.
RabbitMQ
Мы используем штатный кластер RabbitMQ из трех и более узлов с автоматическим failover’ом на уровне Kubernetes.
Redis
В основе этого компонента мы используем штатный кластер Redis Sentinel, имеющий некоторую обвязку, которая избавляет приложение от необходимости реализации протокола sentinel.
Другие сервисы приложения
Аналогичным образом у нас в арсенале есть такие готовые и протестированные компоненты, как minio, sphinxsearch, elasticsearch и многие другие. Практически любой софт может быть установлен внутри Kubernetes — главное, подходить к этому процессу с умом.
Служебные компоненты
Каждый проект имеет также следующие служебные компоненты Kubernetes:
- Панель управления (dashboard), которая дает разработчикам возможность управления компонентами. Также через нее можно попадать внутрь контейнеров — практически как по SSH.
- Централизованное хранилище логов. Сбор логов производится в режиме реального времени со всех компонентов во всех контурах, логи пишутся в единую базу данных. Доступен веб-интерфейс с возможностью просмотра всех логов в реальном времени, поиска и фильтрации по различным параметрам. Для этого используется собственное Open Source-решение loghouse, подробнее о котором читайте в этом анонсе.
- Мониторинг на Prometheus + Okmeter. Prometheus установлен внутри Kubernetes и собирает статистические данные со всех компонентов. Помимо стандартных параметров (память, диск, CPU) также снимаются метрики с Apache/php-fpm, RabbitMQ, Redis и т.п. — каждый компонент отдельно мониторится. Okmeter стоит снаружи Kubernetes и занимается мониторингом самих серверов извне.
Консалтинг по архитектуре и stateless
Как правило, проекты, которые к нам приходят, изначально имеют проблемы с архитектурой — в первую очередь, с масштабированием из-за хранения файлов или промежуточных данных на диске, локального хранения сессий и многих других причин. Самая большая и сложная часть работы заключается в том, чтобы помочь разработчикам переделать приложение так, чтобы оно стало stateless.
Если совсем «на пальцах», то это значит, что каждый компонент приложения не хранит промежуточных данных, либо эти данные мало важны и их можно безболезненно потерять. Это нужно для того, чтобы можно было запустить несколько бэкендов и при внезапном отказе одного из них ничего бы не сломалось, никакие загруженные пользователями файлы бы не удалились и т.д.
Самые частые причины, которые мешают сделать приложение stateless, — это:
- Локальное хранение сессий на бэкенде (в файлах). Это вопрос практически всегда решается простым вынесением сессий в отказоустойчивый memcached (либо через настройки PHP, либо через настройки приложения).
- Локальное хранение файлов загрузки на бэкенде. Вопрос решается с помощью использования выделенного хранилища файлов (например, Amazon S3 или хранилища файлов от Selectel) или вариантами с хранилищем на серверах клиента, реализованным на minio или Ceph (S3/Swift API).
Ответ на возникающие опасения касательного такого stateless-будущего (да, действительно придётся потратить ресурсы разработчиков на изменения в приложении для этого) заключается в том, что оно всё равно неизбежно (для приложений, которым нужно масштабирование) и что приближаться к нему можно поэтапно.
Другие проблемы и особенности
CI/CD
Наконец, возникает логичный вопрос, как же происходит деплой кода приложения в такую инфраструктуру. Устроено это следующим образом:
- Код находится под управлением системы версионирования (Git).
- Мы используем GitLab*, чтобы после коммита кода вызывать сборку Docker-контейнера.
- После стадии сборки в GitLab появляется кнопка «выкатить на production».
- Нажимаем эту кнопку — новая версия приложения выкатывается и запускается, старая версия останавливается, выкат происходит бесшовно и незаметно для пользователя сайта. Также во время выката выполняются миграции БД.
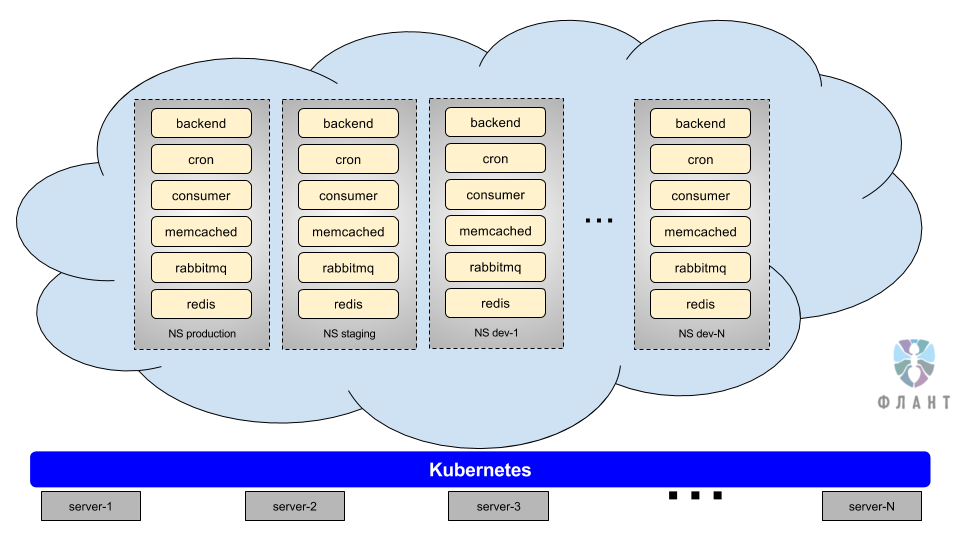
В Kubernetes есть пространства имен (namespaces). Их можно представить себе как отдельные изолированные контуры или окружения, которые запускаются в одном кластере. То есть у нас появляется возможность сделать отдельный контур для staging, для master-ветки… или вообще на каждую ветку делать свой отдельный контур. Контур представляет собой полную копию production: там стоят все те же самые компоненты (MySQL, бэкенды, Redis, RabbitMQ и т.д.). Это достигается за счет того, что вся конфигурация инфраструктуры (конфигурация всех компонентов) описана в специальных YAML-файлах и лежит в репозитории, то есть мы получаем возможность быстро и полностью воссоздать production-среду в любом другом namespace.
* С примером нашего пайплайна в GitLab CI и техническими подробностями его реализации можно ознакомиться в этой статье.
Серверы
Самая типовая инсталляция — это 3 сервера-гипервизора, имеющие примерно такую конфигурацию: E5-1650v4, 128G RAM, 2×500 ГБ SSD. Серверы объединены между собой локальной сетью. Ресурсы каждого сервера разделены с помощью виртуальных машин (Linux KVM + QEMU) на такие части:
- production-контур;
- dev-контуры;
- служебные сервисы Kubernetes (мастеры и фронты);
- база данных.
Резервное копирование
Мы бэкапим все, что требуется в проекте: базы данных, upload-файлы и т.п. Никаких простоев при бэкапе не возникает (для СУБД данные снимаются со slave-сервера и т.п.). План бэкапа и его ежемесячного тестирования согласуется с клиентом — за это отвечает персональный менеджер проекта.
Мониторинг и взаимодействие
Это уже не всегда технические вопросы, но они важны для понимания полной картины осуществляемой поддержки:
- Благодаря имеющимся у нас средствам мониторинга, все алерты стекаются в централизованный интерфейс для дежурных инженеров. Каждый инцидент должен быть обработан, по каждому должно быть резюме. Мы гарантируем реакцию на алерты в течение 15 минут, при этом наше среднее время реакции на алерт — 1 минута (и 10 минут на триаж). Дежурные инженеры круглосуточно на связи по телефону, Slack, почте, системе тикетов (Redmine).
- У каждого нашего проекта есть выделенный менеджер, а также выделенная команда инженеров, в составе которой есть и ведущий инженер, и рядовые инженеры, и младшие инженеры. Эти люди не меняются — они «живут» с проектом с самого его начала и полностью понимают, как он устроен.
- Мы предлагаем гарантии по SLA, подразумевающие штрафы за простой критичной для бизнеса инфраструктуры.
Резюмируя
Мы верим, что современные инфраструктурные решения категории cloud native могут работать во благо уже сейчас и для всех, а стоимость их применения не должна быть сопоставима с ценой космического корабля. Можно провести аналогию с мобильной связью: если раньше сотовая связь была доступна только избранным, то сегодня это обыденность и данность, а цена за связь невелика.
Пройдя путь от «ручного» администрирования «всего на Linux» до поддержки современной инфраструктуры на базе Kubernetes, мы стремимся к тому, чтобы сервис, который мы считаем разумной «нормой», был доступным для клиентов с любым бюджетом. Поэтому предлагаем выделенную команду специалистов для внедрения/обслуживания такой инфраструктуры по принципам DevOps (в тесном взаимодействии с разработчиками) с круглосуточной поддержкой и гарантиями по SLA в рамках бюджета на уровне зарплаты системного администратора/DevOps-инженера, нанятого в штат.
Многие технические аспекты вкратце рассмотренной здесь инфраструктуры (и связанных с ней лучших практик) подлежат значительной детализации, но это история для отдельных статей: и если некоторые из них уже опубликованы в нашем блоге, то запросы на новые — приветствуются в комментариях. Будем рады и вопросам не по технологиям, а процессам, используемым нами в работе и/или предлагаемым клиентам в рамках обслуживания.
P.S.
Читайте также в нашем блоге:
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- Цикл про истории успеха Kubernetes в production: «№1: 4200 подов и TessMaster у eBay», «№2: Concur и SAP», «№3: GitHub», «№4: SoundCloud (авторы Prometheus)»;
- «Статистика The New Stack о трудностях внедрения Kubernetes»;
- «Зачем нужен Kubernetes и почему он больше, чем PaaS?»
