В конце июля компания Fujitsu представила новый функционал своих дисковых массивов ETERNUS DX S3. Эти усовершенствования СХД реализуют дополнительный уровень защиты данных от сбоев дисков и крупных аварий и упрощают контроль времени отклика для приложений с разным приоритетом.
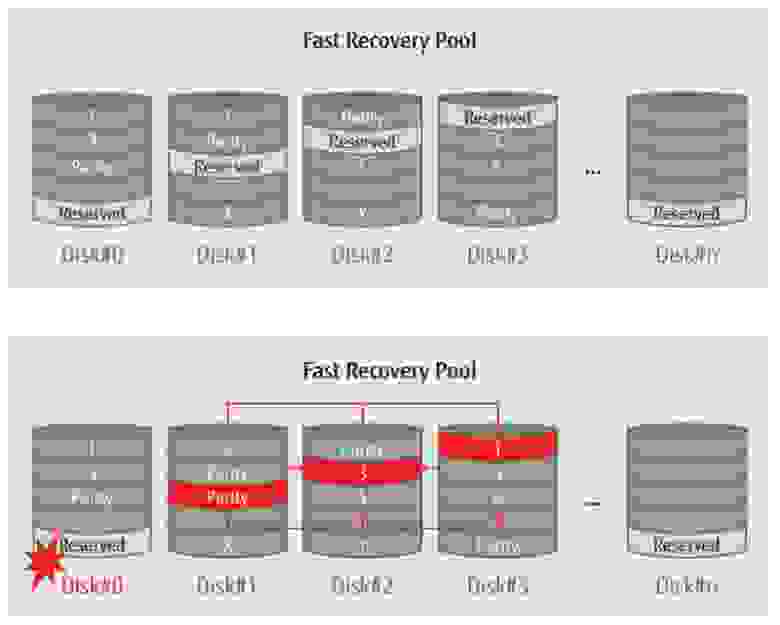
При традиционном подходе к отказоустойчивости в RAID-массиве шестого уровня в ETERNUS DX используется выделение одного из дисков массива в «горячий резерв» (hot spare). Основное предназначение этого резервного диска – запись на него восстановленного с помощью механизмов RAID содержания сбойного диска. После завершения записи сбойный диск можно заменить на новый и переписать на него восстановленные данные с диска горячего резерва. После выполнения всех этих операций восстановления данных и их записи сначала на диск горячего резерва, а затем на новый диск, RAID-массив снова будет защищен от аппаратных сбоев за счет избыточности RAID.
Проблема состоит в том, что по мере роста емкости современных жестких дисков возрастает и время, необходимое для перезаписи всех данных со сбойного диска на диск hot spare, поэтому при использовании терабайтных накопителей эта операция может растянуться на много часов. В результате при восстановлении данных сбойного диска снижается отказоустойчивость массива, поскольку если до окончания записи восстановленных данных на диск hot spare в массиве выйдет из строя еще один диск, то часть или даже все хранящиеся на массиве данные могут быть безвозвратно потеряны.
Представленная в конце июля функция ETERNUS Fast Recovery вместо отдельного диска горячего резерва использует выделение пространства Fast Hot Spare (FHS) для горячего резервирования на всех дисках RAID-массива. За счет такого распределения горячего резерва по дискам массива при восстановлении содержимого сбойного диска операции записи выполняются параллельно на десятки и даже сотни накопителей, поэтому процедура происходит намного быстрее. Например, при использовании массива RAID-6 с однотерабайтными дисками она ускоряется в шесть раз – с девяти до полутора часов.
Таким образом, при использовании Fast Recovery длительность процедуры восстановления сбойного диска значительно сокращается, а вместе с нею и риск потери данных при выходе из строя еще одного диска.
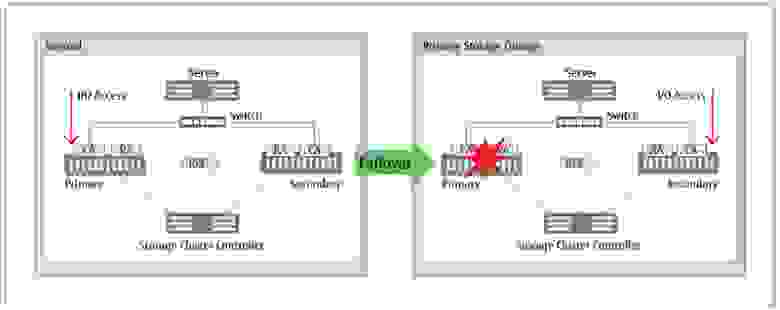
Вторая новая функция систем хранения ETERNUS – ETERNUS Storage Cluster – обеспечивает непрерывную доступность информации, хранящейся на массиве, и даже в случае крупной аварии, которая может вывести из строя не только сам массив, но и весь дата-центр, данные останутся неповрежденными. Технология ETERNUS Storage Cluster, использующая хорошо известный владельцам СХД семейства ETERNUS DX механизм синхронного удаленного «эквивалентного» копирования REC (Remote Equivalent Copy), реализует прозрачную для бизнес-приложений процедуру обработки отказов с переключением (failover) на другую систему хранения при сбое в работе основной СХД или ее отключения для планового обслуживания.
Системный администратор может настроить автоматический запуск переключения на резервную систему при сбое или вручную запускать его перед проведением обслуживания массива (например, при обновлении микрокода) или в случае таких мелких сбоев, как плановое отключение электричества. Благодаря зеркалированию в режиме реального времени между основным и резервным массивом и прозрачному переключению практически полностью устраняются простои бизнес-процессов из-за временной недоступностью системы хранения. Эта технология поддерживается во всей линейке ETERNUS DX S3, включая и младшие модели DX100 S3 и DX200 S3.
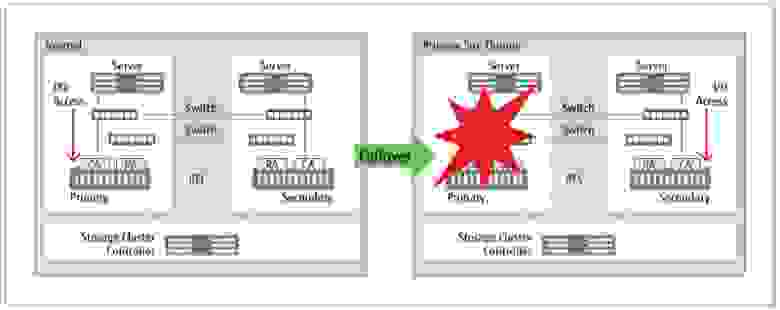
Для построения Storage Cluster помимо соединенных по Fibre Channel двух массивов требуется сервер, выполняющий функции контроллера кластера Storage Cluster Controller. В обычном режиме работы кластера данные с основного массива непрерывно копируются на резервный с помощью синхронной REC, а контроллер постоянно отслеживает состояние основного массива. Если контроллер обнаружит сбой на основном массиве, то он запустит процедуру переключения (failover) с передачей на резервный массив базовых параметров основного массива (номеров LUN, адресов WWN и т.д.), поэтому переключение будет прозрачным для серверов приложений, хранящих свои данные на основном массиве.
Storage Cluster может применяться по двум сценариям – кластер может состоять из массивов, установленных в одном дата-центре, так и массивов, разнесенных на расстояние до 100 километров для защиты от крупных катастроф. В отличие от аналогичных катастрофоустойчивых решений, для зеркалирования данных между массивами в Storage Cluster не используется виртуализирующая приставка, усложняющая управление и обслуживание.
Консолидированное хранение на одной системе больших объемов данных может приводить к конкуренции за ресурсы ввода-вывода СХД между различными серверами и их бизнес-приложениями. Функция Auto QoS (автоматическое обеспечение качества обслуживания), реализованная в новой версии управляющего ПО ETERNUS SF V16.1, позволяет добиться гарантированного времени отклика для самых важных бизнес-приложений даже в тех ситуациях, когда СХД из-за высокой нагрузки работает на пределе своей мощности. С помощью Auto QoS системный администратор может выбрать для каждого приложения один из трех уровней приоритета (высокий, средний или низкий) и установить целевое время отклика (Target Response Time) для томов данных, выделенных определенным приложениям.
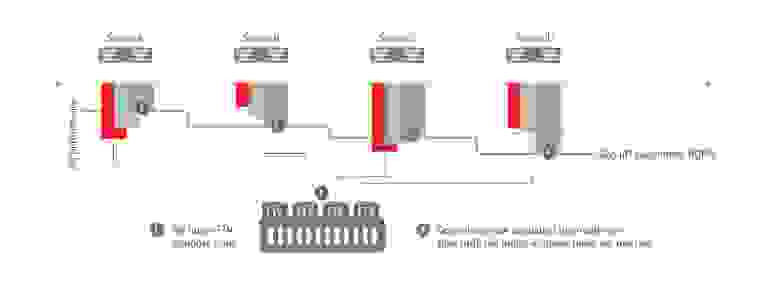
ETERNUS SF отслеживает производительность ввода/вывода томов и в динамическом режиме подстраивает их для обеспечения соблюдения Target Response Time. Если время отклика превышает целевое значение, то тому данных автоматически выделяются дополнительные ресурсы подсистемы ввода/вывода либо он перемещается на уровень хранения с более высокой скоростью доступа к данным, например, на твердотельные диски SSD. Auto QoS, в отличие от традиционных механизмов QoS, не требует от системного администратора выполнять сложные расчеты производительности ввода/вывода (IOPS-ов) для обеспечения требуемого качества сервиса СХД.
Новый функционал ETENUS DX S3 будет особенно востребован ИТ-директорами бизнеса, для которого необходим максимально возможный уровень готовности данных и эффективное управление качеством сервисов хранения массивов важнейших бизнес-данных.

При традиционном подходе к отказоустойчивости в RAID-массиве шестого уровня в ETERNUS DX используется выделение одного из дисков массива в «горячий резерв» (hot spare). Основное предназначение этого резервного диска – запись на него восстановленного с помощью механизмов RAID содержания сбойного диска. После завершения записи сбойный диск можно заменить на новый и переписать на него восстановленные данные с диска горячего резерва. После выполнения всех этих операций восстановления данных и их записи сначала на диск горячего резерва, а затем на новый диск, RAID-массив снова будет защищен от аппаратных сбоев за счет избыточности RAID.
Проблема состоит в том, что по мере роста емкости современных жестких дисков возрастает и время, необходимое для перезаписи всех данных со сбойного диска на диск hot spare, поэтому при использовании терабайтных накопителей эта операция может растянуться на много часов. В результате при восстановлении данных сбойного диска снижается отказоустойчивость массива, поскольку если до окончания записи восстановленных данных на диск hot spare в массиве выйдет из строя еще один диск, то часть или даже все хранящиеся на массиве данные могут быть безвозвратно потеряны.
Представленная в конце июля функция ETERNUS Fast Recovery вместо отдельного диска горячего резерва использует выделение пространства Fast Hot Spare (FHS) для горячего резервирования на всех дисках RAID-массива. За счет такого распределения горячего резерва по дискам массива при восстановлении содержимого сбойного диска операции записи выполняются параллельно на десятки и даже сотни накопителей, поэтому процедура происходит намного быстрее. Например, при использовании массива RAID-6 с однотерабайтными дисками она ускоряется в шесть раз – с девяти до полутора часов.
Таким образом, при использовании Fast Recovery длительность процедуры восстановления сбойного диска значительно сокращается, а вместе с нею и риск потери данных при выходе из строя еще одного диска.

Вторая новая функция систем хранения ETERNUS – ETERNUS Storage Cluster – обеспечивает непрерывную доступность информации, хранящейся на массиве, и даже в случае крупной аварии, которая может вывести из строя не только сам массив, но и весь дата-центр, данные останутся неповрежденными. Технология ETERNUS Storage Cluster, использующая хорошо известный владельцам СХД семейства ETERNUS DX механизм синхронного удаленного «эквивалентного» копирования REC (Remote Equivalent Copy), реализует прозрачную для бизнес-приложений процедуру обработки отказов с переключением (failover) на другую систему хранения при сбое в работе основной СХД или ее отключения для планового обслуживания.
Системный администратор может настроить автоматический запуск переключения на резервную систему при сбое или вручную запускать его перед проведением обслуживания массива (например, при обновлении микрокода) или в случае таких мелких сбоев, как плановое отключение электричества. Благодаря зеркалированию в режиме реального времени между основным и резервным массивом и прозрачному переключению практически полностью устраняются простои бизнес-процессов из-за временной недоступностью системы хранения. Эта технология поддерживается во всей линейке ETERNUS DX S3, включая и младшие модели DX100 S3 и DX200 S3.

Для построения Storage Cluster помимо соединенных по Fibre Channel двух массивов требуется сервер, выполняющий функции контроллера кластера Storage Cluster Controller. В обычном режиме работы кластера данные с основного массива непрерывно копируются на резервный с помощью синхронной REC, а контроллер постоянно отслеживает состояние основного массива. Если контроллер обнаружит сбой на основном массиве, то он запустит процедуру переключения (failover) с передачей на резервный массив базовых параметров основного массива (номеров LUN, адресов WWN и т.д.), поэтому переключение будет прозрачным для серверов приложений, хранящих свои данные на основном массиве.

Storage Cluster может применяться по двум сценариям – кластер может состоять из массивов, установленных в одном дата-центре, так и массивов, разнесенных на расстояние до 100 километров для защиты от крупных катастроф. В отличие от аналогичных катастрофоустойчивых решений, для зеркалирования данных между массивами в Storage Cluster не используется виртуализирующая приставка, усложняющая управление и обслуживание.
Консолидированное хранение на одной системе больших объемов данных может приводить к конкуренции за ресурсы ввода-вывода СХД между различными серверами и их бизнес-приложениями. Функция Auto QoS (автоматическое обеспечение качества обслуживания), реализованная в новой версии управляющего ПО ETERNUS SF V16.1, позволяет добиться гарантированного времени отклика для самых важных бизнес-приложений даже в тех ситуациях, когда СХД из-за высокой нагрузки работает на пределе своей мощности. С помощью Auto QoS системный администратор может выбрать для каждого приложения один из трех уровней приоритета (высокий, средний или низкий) и установить целевое время отклика (Target Response Time) для томов данных, выделенных определенным приложениям.

ETERNUS SF отслеживает производительность ввода/вывода томов и в динамическом режиме подстраивает их для обеспечения соблюдения Target Response Time. Если время отклика превышает целевое значение, то тому данных автоматически выделяются дополнительные ресурсы подсистемы ввода/вывода либо он перемещается на уровень хранения с более высокой скоростью доступа к данным, например, на твердотельные диски SSD. Auto QoS, в отличие от традиционных механизмов QoS, не требует от системного администратора выполнять сложные расчеты производительности ввода/вывода (IOPS-ов) для обеспечения требуемого качества сервиса СХД.
Новый функционал ETENUS DX S3 будет особенно востребован ИТ-директорами бизнеса, для которого необходим максимально возможный уровень готовности данных и эффективное управление качеством сервисов хранения массивов важнейших бизнес-данных.
