 С развитием компьютерных мощностей и появлением множества технологий обработки изображений всё чаще стал возникать вопрос: а можно ли научить машину видеть и распознавать образы? Например, отличать кошку от собаки или даже бладхаунда от бассета? О точности распознавания говорить не приходится: наш мозг несравнимо быстрее может понять, что перед нами, при условии, что раньше мы получили достаточно сведений об объекте. Т.е. даже видя только часть собаки, мы можем с уверенностью сказать, что это собака. А если ты — собаковод, то легко определишь и породу собаки. Но как научить машину различать их? Какие существуют алгоритмы? А можно ли обмануть машину? (Спойлер: конечно можно! Точно так же, как и наш мозг.) Попробуем осмыслить все эти вопросы и по возможности ответить на них. Итак, приступим.
С развитием компьютерных мощностей и появлением множества технологий обработки изображений всё чаще стал возникать вопрос: а можно ли научить машину видеть и распознавать образы? Например, отличать кошку от собаки или даже бладхаунда от бассета? О точности распознавания говорить не приходится: наш мозг несравнимо быстрее может понять, что перед нами, при условии, что раньше мы получили достаточно сведений об объекте. Т.е. даже видя только часть собаки, мы можем с уверенностью сказать, что это собака. А если ты — собаковод, то легко определишь и породу собаки. Но как научить машину различать их? Какие существуют алгоритмы? А можно ли обмануть машину? (Спойлер: конечно можно! Точно так же, как и наш мозг.) Попробуем осмыслить все эти вопросы и по возможности ответить на них. Итак, приступим.Как научить машину видеть?
Машинное зрение относится к Machine Learning, куда входят и семантические анализаторы, и распознаватели звуков, и прочее. Это сложная предметная область, и она требует глубоких знаний математики (в том числе, бррррр, тензорной математики). Существует множество алгоритмов, которые применяются при распознавании образов: VGG16, VGG32, VGG29, ResNet, DenseNet, Inception (V1, V2, V3, V… их сотни!). Наиболее популярными считаются VGG16 и Inception V3 и V4. Самый простой, популярный и больше всего подходящий для быстрого старта — VGG16, поэтому выбираем и ковыряем его. Начнем с названия VGG16 и выясним, что же в нём сакрального и как оно расшифровывается. И тут К.О. подсказывает, что всё просто: VGG — это Visual Geometry Group c факультета инженерных наук Оксфордского университета. Ну а 16 откуда? Тут чуть сложнее и уже напрямую связано с алгоритмом. 16 — число слоёв нейронной сети, которое используется для распознавания образов (наконец-то приступили к интересному, а то всё вокруг да около). И уже пора врубаться в самую суть матана. Сами они используют от 16 до 19 слоев и фильтры 3х3 на каждом уровне нейронной сети. Собственно, причин несколько: наибольшая производительность именно при таком количестве слоёв, точность распознавания (вполне достаточно и этого, ссылки на статьи, раз и два). Следует отметить, что нейронная сеть используется не простая, а улучшенная свёрточная нейронная сеть (Convolutional Neural Network (CNN) и Convolutional Neural Network with Refinement (CNN-R)).
А теперь разберёмся в принципах работы этого самого алгоритма, зачем нужна свёрточная нейронная сеть и с какими параметрами она работает. Ну и, конечно же, лучше сразу делать это на практике. Ассистента в студию!

Вот эта замечательная хаски станет нашим ассистентом, над ней мы и будем ставить эксперименты. Она уже светится от счастья и желает поскорее вникнуть в детали.
Итак, простыми словами: свёрточная нейронная сеть работает с двумя «командами» (сильно утрирую, но так будет понятнее). Первая — выдели фрагмент, вторая — попытайся найти объект целиком. Почему целиком? Имея в наличии набор мельчайших паттернов с контурами целых объектов, нейросети проще в дальнейшем получать характерные признаки и сравнивать их с изображением, которое требуется распознать. И тут нам поможет изображение алгоритма в конечном виде. Кто хочет изучить подробно, с тоннами матана — вот пруфлинк. А мы идём дальше.
Объяснить следующий алгоритм не так сложно. Это полный алгоритм работы свёрточной нейронной сети с модулем улучшения (вот тот самый, который обведён пунктиром и присутствует после каждого шага свёртки).
Первый шаг: пилим изображением пополам (с хаски проделано, но не так эффектно выглядит, как со слонами на рисунке). Потом ещё пополам, потом ещё и ещё, и так доходим до тараканов, в смысле до блока 14х14 и меньше (минимальный размер, как уже было сказано, 3х3). Между шагами — основная магия. А именно — получение маски целого объекта и вероятности нахождения целого объекта на отпиленном куске. После всех этих манипуляций получаем набор кусочков и набор масок к ним. Что теперь с ними делать? Ответ прост: при уменьшении изображения мы получаем деградацию соседних пикселей, что упростит построение маски в упрощённом виде и даст возможность увеличить вероятность различения переходов между объектами.
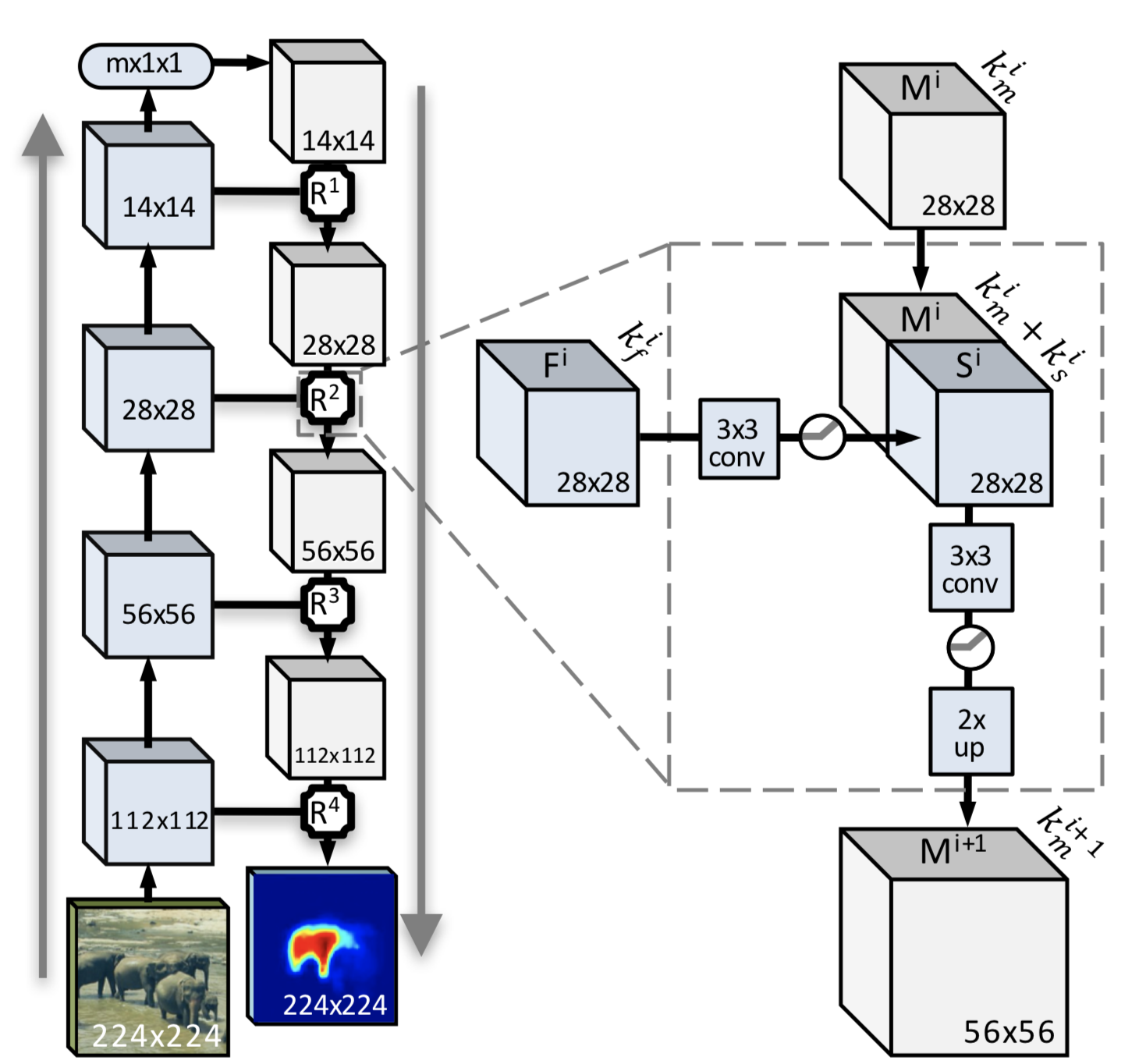
На основе анализа уменьшенных изображений строятся независимые исходные описания и затем результат усредняется для всех масок. Но следует отметить, что данный вариант не самый лучший при сегментации объекта. Усреднённая маска не всегда может быть применима при небольших различиях цвета между объектами и фоном (вот почему именно такое тестовое изображение было выбрано).
Предложенный подход более-менее работоспособен, но для объектов, которые целиком находятся на изображении и контрастируют с фоном, в то же время разделение двух одинаковых или схожих объектов (далеко за примером ходить не будем: стадо овец, у всех белая шерсть) вызовет значительные затруднения.
Для получения адекватной пиксельной маски и разделения объектов необходимо доводить алгоритм до ума.
И вот теперь настал момент спросить: а зачем нам этот «модуль-улучшайзер» вообще нужен, если вроде как всё и так неплохо?
Мы добавляем на каждом шаге не только построение маски, но и использование всей информации, полученной из низкоуровневых функций совместно со знаниями о высокоуровневых объектах, которые распознаны в верхних слоях нейронной сети. Наряду с получением независимых результатов на каждом шаге производится генерация и грубое распознавание, результатом является семантически полная функциональная мультиканальная карта, в которую интегрируется только положительная информация из ранних слоев.
В чём отличие классической свёрточной нейронной сети и улучшенной свёрточной нейронной сети?
Каждый этап уменьшения исходного изображения позволяет получить кодированную маску, сгенерированную при прохождении от общего изображения к уменьшенному. Вместе с этим в усовершенствованной свёрточной нейронной сети происходит движение от меньшего изображения к большему с получением характерных функций (точек). Итогом является маска, полученная в результате двунаправленного слияния функций и характерных точек.
Звучит достаточно запутанно. Попробуем применить к нашему изображению.

Эффектно. Это называется DeepMask — грубые границы объектов на изображении. Попробуем разобраться, почему так. Начнём с простого — с носа. При деградации изображения контраст очевиден, поэтому нос и выделен как самостоятельный объект. То же самое и с ноздрями: на определённых уровнях свёртки они стали самостоятельными объектами за счёт того, что находились полностью на фрагменте. Кроме того, отдельно обведена морда второй собаки (как, не видите? Да вот же она, прямо перед вами!). Кусок руки был признан фоном. Ну что поделать? С основной частью фона по цвету не контрастирует. Зато переход «рука-футболка» выделен. И погрешность в виде пятна «рука-сетка», и большое пятно, захватывающее фон и голову хаски.
Что ж, результат интересный! Как же можно помочь алгоритму справиться с задачей лучше? Только если поиздеваться над нашим помощником. Для начала попробуем сделать его в градациях серого. Мда… Фото хуже, чем в паспорте. После этого лаборанту уже нечего терять, я только включил один фильтр, и всё завертелось… Сепия, а за ней соляризация, накладывание и вычитание слоёв, размытие фона со сложением изображений — в общем, что видел, то и применял; главное, чтобы объекты становились заметнее на изображении. Как говорится, картинка в фотошопе всё стерпит. Поиздевались, пора бы и посмотреть, как теперь будет распознано изображение.

Нейросеть сказала: «Здесь нет того, кого можно хоть как-то классифицировать». Логично, контрастные только нос и глаза. Не слишком характерно при небольшом наборе для обучения.

Ух, жуть какая (прости, друг)! Но здесь мы серьёзно прибавили контраста объектам на изображении. Как? Берём и дублируем изображение (можно несколько раз). На одном выкручиваем контраст, на другом — яркость, на третьем — пережигаем цвета (делаем их неестественно яркими) и потом всё это складываем. И напоследок попробуем запихнуть многострадальную хаски в обработку.

Надо сказать, что стало лучше. Не прям «ух, как круто», но получше. Уменьшилось число неполных объектов, появился контраст между объектами. Дальнейшие эксперименты с предварительной обработкой дадут больший контраст: объект — объект, объект — фон. Получим 4 сегмента вместо 8. С точки зрения обработки большого потока картинок (150 изображений в минуту) лучше вообще не заморачиваться с предварительной обработкой. Она — так, поиграться на домашнем компьютере.
Идём дальше. SharpMask практически отличаться не будет. А SharpMask — это построение уточнённой маски объектов. Алгоритм с улучшением тот же.
Главная проблема DeepMask в том, что эта модель использует простую сеть прямого распространения, которая успешно создаёт «грубые» маски, но не выполняет сегментацию с точностью до пикселя. Пропускаем пример для этого шага, так как хаски и так нелегко живётся.
Последний шаг — попытка распознать то, что получилось после уточнения маски.

Запускаем быстро собранное демо и получаем результат — целых 70%, что это собака. Неплохо.
Но как машина поняла, что это собака? Вот мы напилили кусков, получили красивые маски, матрицы к ним и наборы признаков. Что дальше-то? А дальше всё просто: у нас есть обученная сеть, у которой есть эталонные наборы признаков, масок и прочее, прочее, прочее. Ну, есть они, и что дальше-то? Вот наша хаски с набором признаков, вот эталонная сферическая собака в вакууме с набором признаков. Тупое сравнение в лоб делать нельзя, потому как недостаток признаков у изображения, которое мы распознаём, приведёт к ошибке. И что же делать? Для этого придумали такой замечательный параметр, как dropout, или рандомный сброс параметров сети. Это значит следующее: берутся оба набора и из каждого из них рандомно удаляются признаки (проще говоря, есть наборы по 10 признаков, dropout = 0.1; по одному признаку отбрасываем, далее сравниваем). А в результате? А в результате — PROFIT.
Cразу отвечу на вопрос, почему вторая собака — не собака, а рука — не человек. Тестовая выборка была всего на 1000 изображений котов и собак. Обучалась всего в два шага эволюции.
Вместо выводов
Итак, мы получили картинку и результат, что это собака (нам очевидно, а для нейросети было не очень). Обучение проводилось всего в два шага и не было эволюции модели (что очень важно). Изображение грузилось как есть, без обработки. В дальнейшем планируется проверить, сможет ли нейросеть распознать собак по минимальному набору признаков.
Из плюсов:
- Провели обучение на одной машине. Если надо, файлы можно раскидывать сразу же на другие машины, и они (машины) уже будут уметь то же самое.
- Высокая точность определения при обучении и эволюции сети (это оооочень долго).
- Можно эволюционировать под разные алгоритмы распознавания и «дообучать» сеть.
- Огромная база изображений COCO и VOC (обновляется ежегодно).
Из минусов: танцы с бубном с каждым фреймворком.
P.S. При проведении экспериментов ни одна хаски не пострадала. О том, как собирали, что собирали, сколько граблей, в какие места и прочее — в следующей статье нашего цикла «Машинное зрение для домохозяек».
P.P.S. И совсем-совсем резюмируя: серебряной пули не существует, но есть фауст-патрон, который можно обточить напильником. А для быстрого старта были использованы следующие фреймворки:
Keras
Caffe
Tensorflow
