В первой статье мы говорили о том, как работала старая система доставки сообщений и тех уроках, которые мы вынесли из ее работы. Во этой (второй) статье мы расскажем об архитектуре новой системы и том, почему мы выбрали Google Cloud Pub/Sub в качестве транспортного механизма для всех событий.
Наш опыт в эксплуатации и поддержке старой системы доставки событий дал нам массу вводной информации для создания новой и улучшенной. Наша текущая платформа была построена на основе еще более старой системы, работающей с почасовыми логами. Эта конструкция создавала сложности, например, с распространением и подтверждение маркеров конца файла на каждой машине, выдающей события. Кроме того, текущая реализация могла войти в такое состояние сбоя, из которого автоматически она выйти не могла. Существование части программного обеспечения, которое требует ручного вмешательства в случае некоторых сбоев и работающее на каждой машине, «производящей» логи, выливается в значительные эксплуатационные расходы. В новой системе мы хотели упростить работу машин с логами, обрабатывая события меньшим количеством компьютеров, расположенных ближе в сети дальнейшей обработки.
Здесь недостающая часть – система доставки событий или очередь, реализующая надежную транспортировку событий и сохранение недоставленных сообщений в очереди. С помощью такой системы мы могли бы приблизить и значительно ускорить передачу данных Продюсерами, получать подтверждения с низкой задержкой и переложить ответственность за запись событий в HDFS на остальную систему.
Еще одно изменение, которое мы запланировали, состояло в том, чтобы у каждого типа события был свой канал, или топик, и события конвертировались в более структурированный формат на ранних стадиях процесса. Больше работы на Продюсерах означает меньше времени на конвертирование данных в Extract, Transform, Load (ETL) работе на поздних этапах. Разделение событий по топикам — это ключевое требование для построения эффективной системы реального времени.
Так как доставка сообщений должна работать все время, мы создавали новую систему таким образом, чтобы она работала параллельно с текущей. Интерфейсы и на Продюсере, и на Потребителях соответствовали текущей системе, и мы могли проверить производительность и корректность работы новой прежде, чем переключиться на нее.
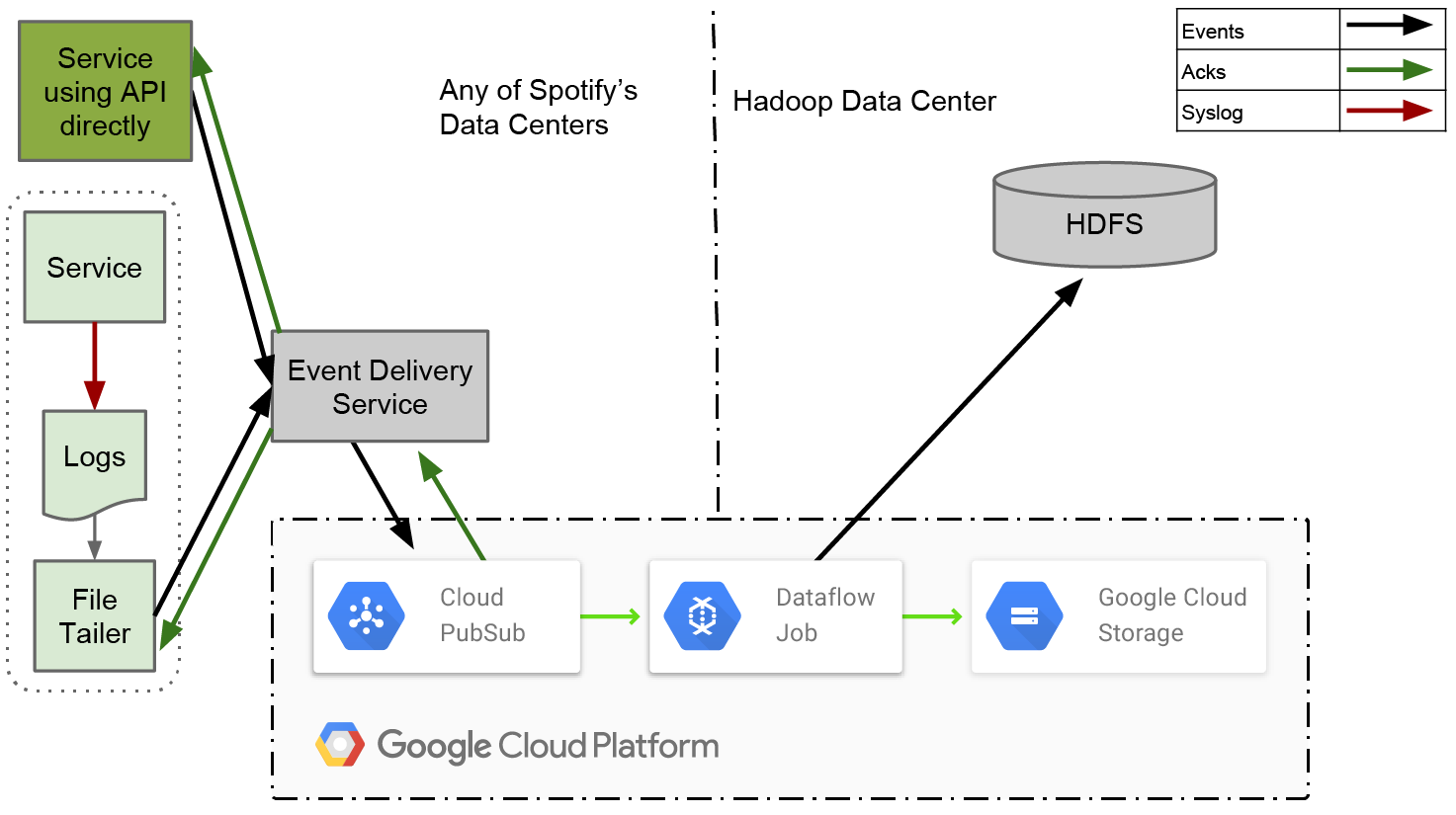
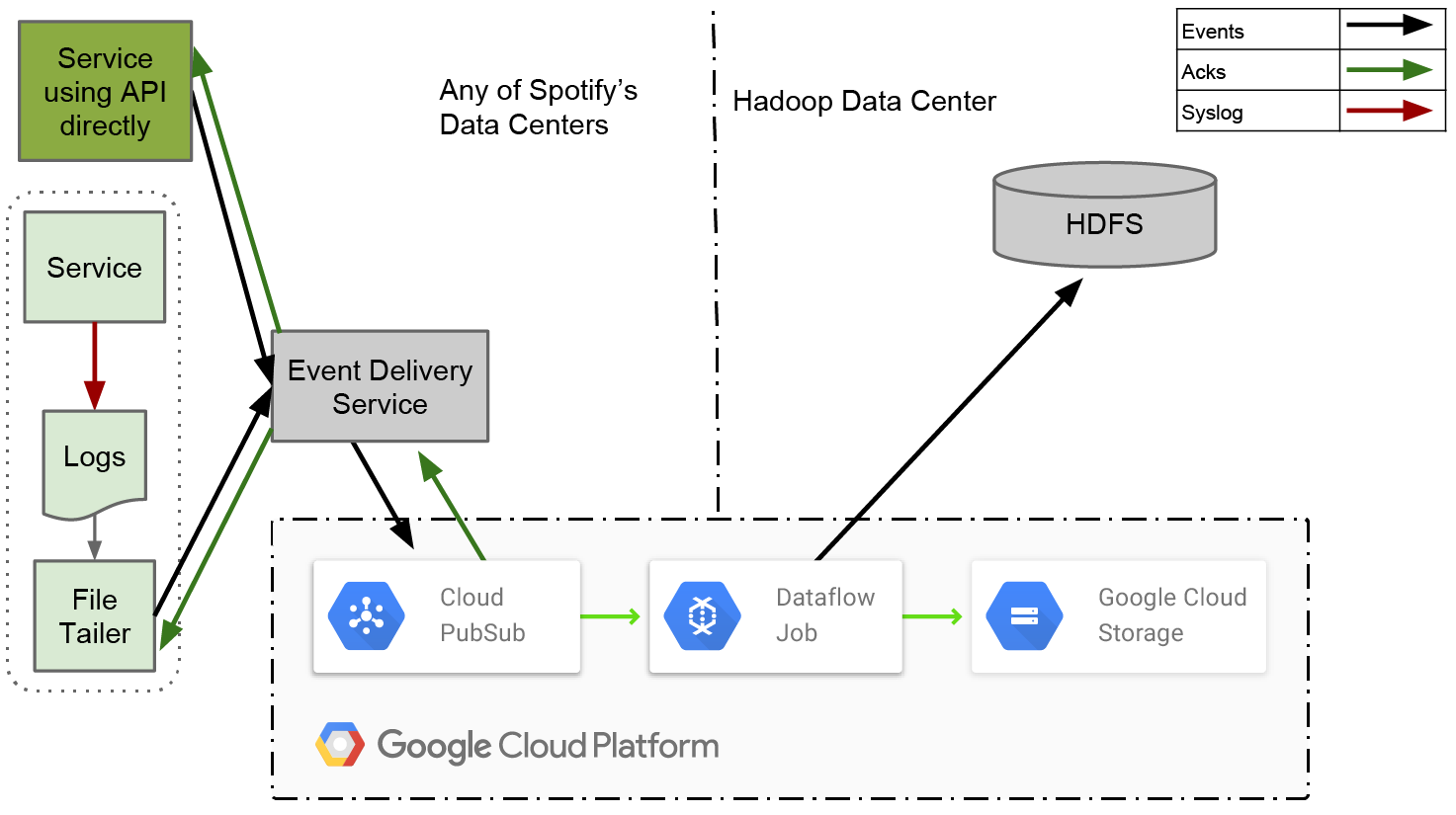
Четыре основных компонента новой системы – Файловый агент (File Tailer), Сервис доставки событий (Event Delivery Service), Очередь надежной доставки (Reliable Persistent Queue) и ETL сервис.
В этой конструкции, у Файлового Агента гораздо более узкий круг обязанностей, чем у Продюсера в нашей старой системе. Он формирует лог-файлы из новых событий и пересылает их в Службу доставки событий. Как только он получает подтверждение, что события получены, на этом его работа заканчивается. Нет больше сложной обработки маркеров конца файла или удостоверения, что данные достигли конечной точки в HDFS.
Система доставки событий принимает их от Агента, переводит в конечный структурированный формат и отправляет в Очередь. Сервис построен как RESTful микросервис при помощи фреймворка Apollo и развернут с помощью Helios оркестратора, что является общей схемой для Spotify. Это позволяет отвязать клиентов от определенной единой технологии, а также позволяет перейти на любую другую базовую технологию, не прерывая обслуживания.
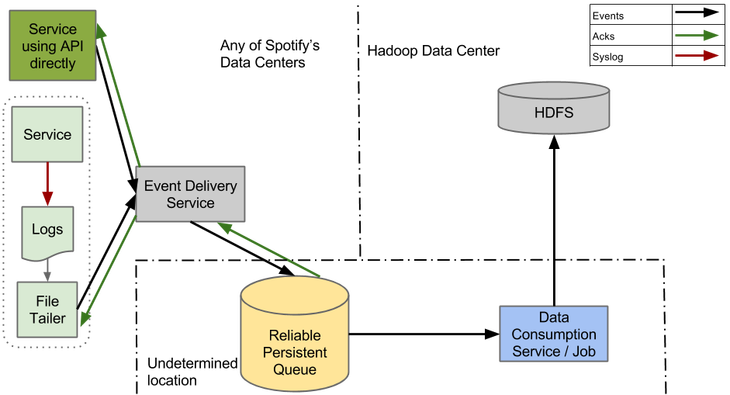
Очередь является ядром нашей системы и в таком виде важна для масштабирования в соответствии с ростом потока данных. Чтобы справиться с простоем Hadoop, она должна надежно сохранять сообщения в течение нескольких дней.
ETL сервис должен надежно предотвращать дублирование и экспортировать данные из Очереди в ежечасные сборки в HDFS. До того, как он откроет такой пакет нижележащим пользователям, он должен с высокой степенью вероятности убедиться, что все данные для пакета получены.
В рисунке выше вы можете видеть блок, на котором написано «Сервис использует API напрямую». Мы уже некоторое время ощущаем, что syslog неидеальный API для Продюсера событий. Когда новая система вступит в строй, а старая полностью сойдет со сцены, будет логично отказаться от syslog и начать работать с библиотеками, которые напрямую смогут общаться с Сервисом доставки событий.
Создание Очереди надежной доставки, которая надежно обрабатывала бы огромные объемы событий Spotify, является сложной задачей. Наша цель состояла в том, чтобы использовать существующие инструменты для самой тяжелой работы. Так как доставка событий — это основа нашей инфраструктуры, мы бы хотели сделать систему удобной и стабильной. Первым выбором стала Kafka 0.8.
Есть множество сообщений, что Kafka 0.8 успешно используется в больших компаниях по всему миру и Kafka 0.8 это значительно улучшенная версия по сравнению с той, что используется у нас сейчас. В частности, в ней улучшенные брокеры Kafka обеспечивают надежное постоянное хранилище. Проект Mirror Maker представил зеркалирование между дата-центрами, а Camus можно использовать для экспортирования структурированных Avro событий в ежечасные сборки.
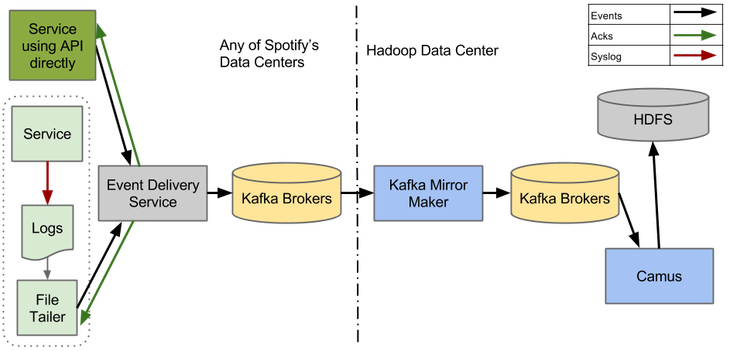
Чтобы убедиться, что доставка событий может правильно работать на Kafka 0.8, мы развернули тестовую систему, которая показана на рисунке выше. Встроить простой Kafka Продюсер в Сервис доставки событий оказалось легко. Чтобы удостовериться, что система работает корректно от начала и до конца – от Сервиса доставки событий до HDFS – мы внедрили разнообразные интеграционные тесты в наши процессы непрерывной интеграции и доставки.
К сожалению, как только эта система начала обрабатывать реальный трафик, она начала распадаться на части. Единственным компонентом, который оказался стабильным, стал Camus (но так как мы не пропускали слишком много трафика через систему, мы все еще не знаем, как Camus повел бы себя под нагрузкой).
Mirror Maker доставил нам больше всего головной боли. Мы предполагали, что он надежно будет зеркалировать данные между дата-центрами, но это оказалось просто не так. Он работает только в идеальных условиях (точнее best effort basis). Как только в целевом кластере случается проблема, Mirror Maker просто теряет данные, хотя, при этом и сообщает исходному кластеру, что данные успешно зеркалированы (обратите внимание, что это должно быть исправлено в Kafka 0.9).
Mirror Maker-ы иногда путались в том, кто был лидером в кластере. Лидер иногда забывал, что он был лидером, в то время как остальные Mirror Maker-ы из кластера могли радостно пытаться за ним следовать. Когда это случалось, зеркалирование между дата-центрами останавливалось.
У Kafka Producer также серьезные проблемы со стабильностью. Если один или больше брокеров из кластера удалялись, или даже просто перезапускались, с определенной вероятностью Продюсер входил в состояние, из которого уже не мог выйти сам. В таком состоянии он не мог производить никаких событий. Единственным выходом был полный рестарт сервиса.
Даже не касаясь решения этих вопросов, мы поняли, что на приведение системы в рабочее состояние понадобится много сил. Нам необходимо будет определить стратегию развертывания для Kafka Broker-ов и Mirror Maker-ов, смоделировать требуемые мощности и распланировать все системные компоненты, а также задать метрики производительности для системы мониторинга Spotify.
Мы оказались на перепутье. Должны ли мы сделать значительные инвестиции и попытаться заставить Kafka работать на нас? Или стоит попробовать что-то еще?
Пока мы боролись с Kafka, другие члены команды Spotify начали экспериментировать с Google Cloud. Особенно нас интересовал Cloud Pub/Sub. Казалось, что Cloud Pub/Sub сможет удовлетворить нашу потребность в надежной очереди: он может хранить недоставленные данные в течение 7 дней, обеспечивает надежность за счет подтверждений на уровне приложения и имеет «at-least-once» семантику доставки.
Помимо удовлетворения наших основных потребностей, у Cloud Pub/Sub есть и дополнительные преимущества:
Звучит прекрасно на бумаге… но слишком хорошо, чтобы быть правдой? Решения, который мы создали на Apache Kafka, хотя и не были идеальными, все же нормально нам служили. У нас было много опыта в борьбе с различными отказами, доступ к железу и исходникам, и – теоретически – мы могли найти источник любой проблемы. Переход к управляемому сервису означал, что мы должны были доверить ведение операций другой организации. И при этом Cloud Pub/Sub рекламировался как бета-версия – мы не знали о какой-либо другой организации, кроме Google, которая использовала бы его в таком масштабе, который был нужен нам.
Имея все это ввиду, мы решили, что нам нужен подробный план тестирования, чтобы быть абсолютно уверенными в том, что если мы перейдем на Cloud Pub/Sub, то он будет соответствовать всем нашим требованиям.
Первым пунктом в нашем плане было тестирование Cloud Pub/Sub на то, сможет ли он выдержать нашу нагрузку. В настоящее время наша рабочая нагрузка достигает в пике 700К событий в секунду. Если учесть будущий рост и возможные сценарии аварийного восстановления, мы остановились на тестовой нагрузке в 2М событий в секунду. Чтобы совсем добить Pub/Sub, мы решили опубликовать весь этот объем трафика в одном дата-центре, так чтобы все эти запросы попали в машины Pub/Sub в одной зоне. Мы сделали предположение, что Google распланировал зоны как независимые домены, и что каждая зона может обрабатывать равные объемы трафика. В теории, если бы мы смогли пропихнуть 2М сообщений в одну зону, то смогли бы и передать и количество_зон*2М сообщений во всех зонах. Наша надежда была на то, что система сможет обрабатывать этот трафик как на стороне производителя, так и на стороне потребителя в течение длительного времени без деградации сервиса.
В самом начале мы наткнулись на камень преткновения: Java клиент Cloud Pub/Sub работал недостаточно хорошо. Этот клиент, как и многие другие Google Cloud API клиенты, автоматически сгенерирован из спецификаций API. Это хорошо, если вы хотите, чтобы клиенты поддерживали широкий набор языков, но не слишком, если вы хотите получить быстродействующий клиент для одного языка.
К счастью, у Pub/Sub есть REST API, так что для нас было просто написать собственную библиотеку. Мы создали нового клиента, думая в первую очередь о его быстродействии. Чтобы более эффективно использовать ресурсы, мы использовали асинхронную Java. Мы также добавили в клиент очереди и пакетную обработку. (Это не первый раз, когда нам пришлось засучить рукава и переписать клиента Google Cloud API – в другом проекте мы разработали быстродействующий клиент для Datastore API.)
C новым клиентом мы были готовы начать нагружать Pub/Sub по-взрослому. Мы использовали простой генератор для отправки фиктивного трафика от Сервиса событий к Pub/Sub. Сформированный трафик перенаправлялся через два Pub/Sub топика в соотношении 7:3. Чтобы сгенерировать 2М сообщений в секунду, мы запустили Сервис событий на 29 машинах.
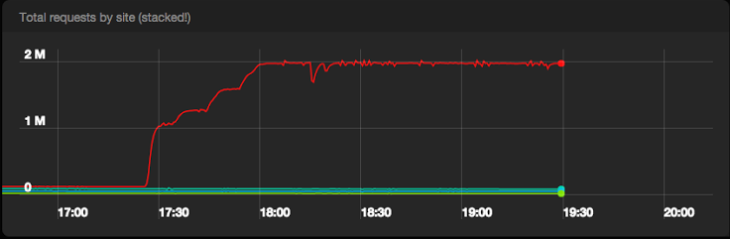
Количество успешных запросов в секунду к Pub/Sub из всех дата-центров
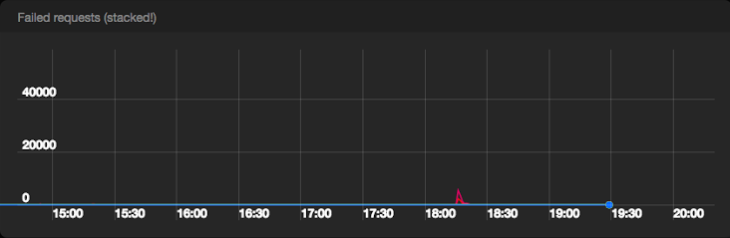
Количество неуспешных запросов в секунду к Pub/Sub из всех дата-центров
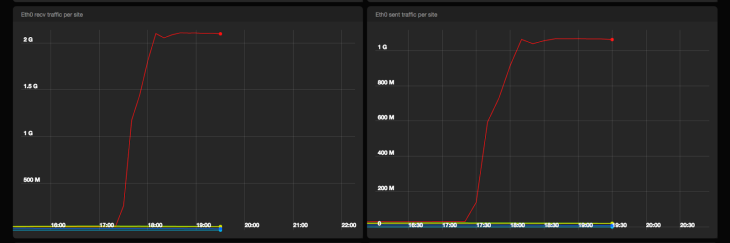
Входящий и исходящий сетевой трафик от машин Сервиса событий в bps
Pub/Sub прошел испытание с честью. Мы опубликовали 2М сообщений без какого-либо нарушения качества и почти не получили серверных ошибок от Pub/Sub бэкенда. Включение пакетной обработки и сжатия на машинах Сервиса событий привело к получению примерно в 1 Gpbs трафика к Pub/Sub.
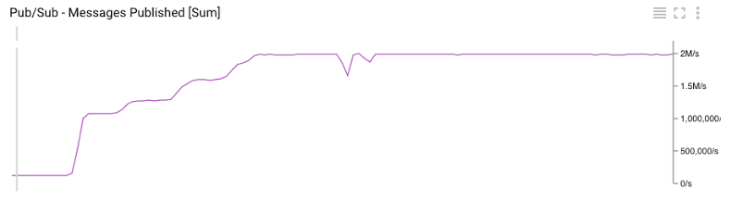
График Google Cloud Monitoring для общего количества опубликованных сообщений в Pub/Sub
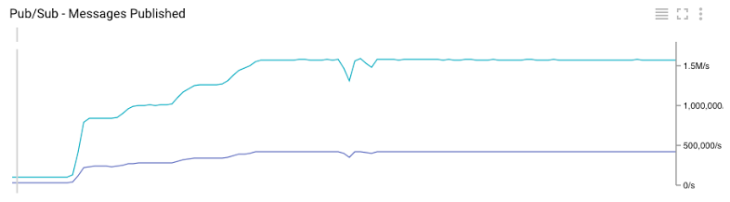
График Google Cloud Monitoring для количества опубликованных сообщений в топиках Pub/Sub
Полезный побочный эффект нашего теста – мы смогли сравнить наши внутренние метрики с метриками, предоставленными Google. Как показано на Графиках 3 и 6, они идеально совпадают.
Наш второй важный тест был посвящен потреблению. В течение 5 дней мы измеряли end-to-end задержки под большой нагрузкой. На время теста мы публиковали, в среднем, около 800К сообщений в секунду. Для имитации реальных нагрузок, скорость публикации менялась в течение дня. Чтобы удостовериться, что мы можем использовать несколько топиков одновременно, все данные публиковались для двух топиков в соотношении 7:3.
Слегка удивило в поведении Cloud Pub/Sub то, что необходимо создать подписки до сохранения сообщений – пока подписки не существует, никакие данные не сохраняются. Каждая подписка хранит данные независимо, и нет ограничений тому, сколько подписок может быть у потребителя. Потребители координируются на стороне сервера, и сервер ответственен за достаточное выделение сообщений для всех потребителей, запрашивающих данные. Это очень отличается от Kafka, где данные сохраняются в созданном топике и количество потребителей в топике ограничено количеством разделов в топике.
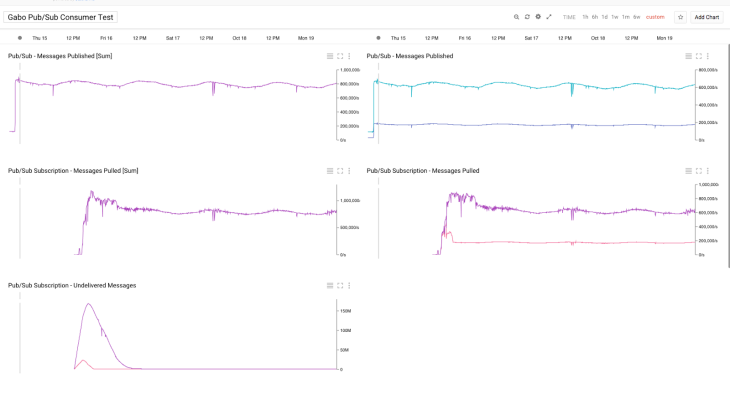
В нашем тесте мы создали подписку, часом спустя мы начали потреблять данные. Мы потребляли их пакетами по 1000 сообщений. Так как мы не пытались достичь предела в потреблении, мы хотели просто слегка превысить текущий пиковый уровень. Это заняло 8 часов. После того как мы достигли его, Потребители продолжили работать на том же уровне, который соответствовал скорости публикации.
Средняя end-to-end задержка, которую мы измеряли в ходе тестового периода – включая восстановление backlog – была в районе 20 секунд. Мы не наблюдали потерь сообщений в течение всего тестового периода.
На этих тестах мы убедились, что Cloud Pub/Sub это правильный выбор для нас. Задержки были малы и постоянны, и единственное ограничение в емкости, с которым мы столкнулись, была установленная квота. Короче говоря, выбор Cloud Pub/Sub вместо Kafka 0.8 для нашей новой платформы доставки сообщений, был очевидным решением.
После того как события надежно сохранены в Pub/Sub, настало время экспортировать их в HDFS. Чтобы в полной мере использовать возможности Google Cloud, мы решили попробовать Dataflow.
В последней статье из этой серии мы расскажем о том, как использовали Dataflow для наших целей. Оставайтесь с нами!

Как создавалась новая система доставки событий для Spotify
Наш опыт в эксплуатации и поддержке старой системы доставки событий дал нам массу вводной информации для создания новой и улучшенной. Наша текущая платформа была построена на основе еще более старой системы, работающей с почасовыми логами. Эта конструкция создавала сложности, например, с распространением и подтверждение маркеров конца файла на каждой машине, выдающей события. Кроме того, текущая реализация могла войти в такое состояние сбоя, из которого автоматически она выйти не могла. Существование части программного обеспечения, которое требует ручного вмешательства в случае некоторых сбоев и работающее на каждой машине, «производящей» логи, выливается в значительные эксплуатационные расходы. В новой системе мы хотели упростить работу машин с логами, обрабатывая события меньшим количеством компьютеров, расположенных ближе в сети дальнейшей обработки.
Здесь недостающая часть – система доставки событий или очередь, реализующая надежную транспортировку событий и сохранение недоставленных сообщений в очереди. С помощью такой системы мы могли бы приблизить и значительно ускорить передачу данных Продюсерами, получать подтверждения с низкой задержкой и переложить ответственность за запись событий в HDFS на остальную систему.
Еще одно изменение, которое мы запланировали, состояло в том, чтобы у каждого типа события был свой канал, или топик, и события конвертировались в более структурированный формат на ранних стадиях процесса. Больше работы на Продюсерах означает меньше времени на конвертирование данных в Extract, Transform, Load (ETL) работе на поздних этапах. Разделение событий по топикам — это ключевое требование для построения эффективной системы реального времени.
Так как доставка сообщений должна работать все время, мы создавали новую систему таким образом, чтобы она работала параллельно с текущей. Интерфейсы и на Продюсере, и на Потребителях соответствовали текущей системе, и мы могли проверить производительность и корректность работы новой прежде, чем переключиться на нее.
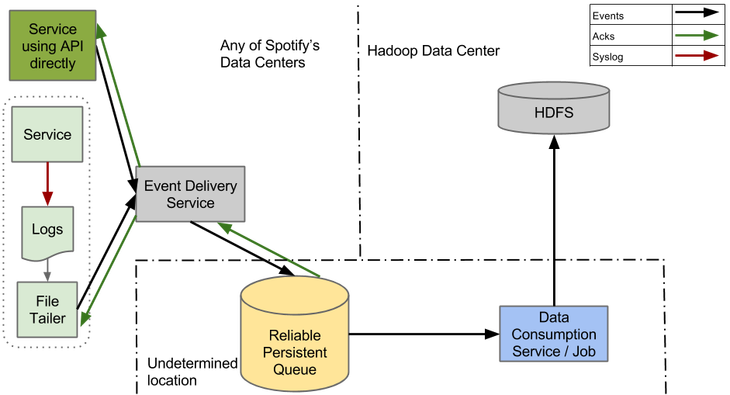
Четыре основных компонента новой системы – Файловый агент (File Tailer), Сервис доставки событий (Event Delivery Service), Очередь надежной доставки (Reliable Persistent Queue) и ETL сервис.
В этой конструкции, у Файлового Агента гораздо более узкий круг обязанностей, чем у Продюсера в нашей старой системе. Он формирует лог-файлы из новых событий и пересылает их в Службу доставки событий. Как только он получает подтверждение, что события получены, на этом его работа заканчивается. Нет больше сложной обработки маркеров конца файла или удостоверения, что данные достигли конечной точки в HDFS.
Система доставки событий принимает их от Агента, переводит в конечный структурированный формат и отправляет в Очередь. Сервис построен как RESTful микросервис при помощи фреймворка Apollo и развернут с помощью Helios оркестратора, что является общей схемой для Spotify. Это позволяет отвязать клиентов от определенной единой технологии, а также позволяет перейти на любую другую базовую технологию, не прерывая обслуживания.
Очередь является ядром нашей системы и в таком виде важна для масштабирования в соответствии с ростом потока данных. Чтобы справиться с простоем Hadoop, она должна надежно сохранять сообщения в течение нескольких дней.
ETL сервис должен надежно предотвращать дублирование и экспортировать данные из Очереди в ежечасные сборки в HDFS. До того, как он откроет такой пакет нижележащим пользователям, он должен с высокой степенью вероятности убедиться, что все данные для пакета получены.
В рисунке выше вы можете видеть блок, на котором написано «Сервис использует API напрямую». Мы уже некоторое время ощущаем, что syslog неидеальный API для Продюсера событий. Когда новая система вступит в строй, а старая полностью сойдет со сцены, будет логично отказаться от syslog и начать работать с библиотеками, которые напрямую смогут общаться с Сервисом доставки событий.
Выбор Очереди надежной доставки
Kafka 0.8
Создание Очереди надежной доставки, которая надежно обрабатывала бы огромные объемы событий Spotify, является сложной задачей. Наша цель состояла в том, чтобы использовать существующие инструменты для самой тяжелой работы. Так как доставка событий — это основа нашей инфраструктуры, мы бы хотели сделать систему удобной и стабильной. Первым выбором стала Kafka 0.8.
Есть множество сообщений, что Kafka 0.8 успешно используется в больших компаниях по всему миру и Kafka 0.8 это значительно улучшенная версия по сравнению с той, что используется у нас сейчас. В частности, в ней улучшенные брокеры Kafka обеспечивают надежное постоянное хранилище. Проект Mirror Maker представил зеркалирование между дата-центрами, а Camus можно использовать для экспортирования структурированных Avro событий в ежечасные сборки.
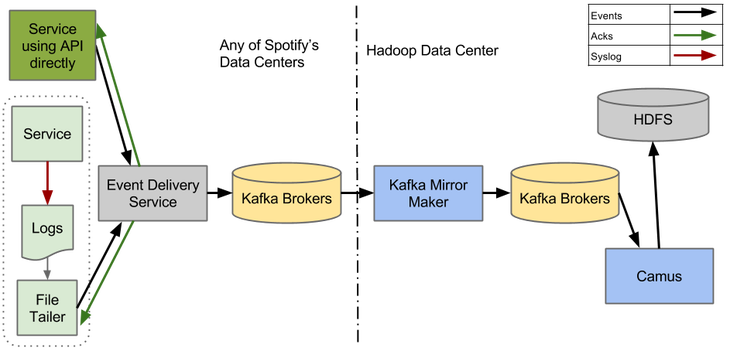
Чтобы убедиться, что доставка событий может правильно работать на Kafka 0.8, мы развернули тестовую систему, которая показана на рисунке выше. Встроить простой Kafka Продюсер в Сервис доставки событий оказалось легко. Чтобы удостовериться, что система работает корректно от начала и до конца – от Сервиса доставки событий до HDFS – мы внедрили разнообразные интеграционные тесты в наши процессы непрерывной интеграции и доставки.
К сожалению, как только эта система начала обрабатывать реальный трафик, она начала распадаться на части. Единственным компонентом, который оказался стабильным, стал Camus (но так как мы не пропускали слишком много трафика через систему, мы все еще не знаем, как Camus повел бы себя под нагрузкой).
Mirror Maker доставил нам больше всего головной боли. Мы предполагали, что он надежно будет зеркалировать данные между дата-центрами, но это оказалось просто не так. Он работает только в идеальных условиях (точнее best effort basis). Как только в целевом кластере случается проблема, Mirror Maker просто теряет данные, хотя, при этом и сообщает исходному кластеру, что данные успешно зеркалированы (обратите внимание, что это должно быть исправлено в Kafka 0.9).
Mirror Maker-ы иногда путались в том, кто был лидером в кластере. Лидер иногда забывал, что он был лидером, в то время как остальные Mirror Maker-ы из кластера могли радостно пытаться за ним следовать. Когда это случалось, зеркалирование между дата-центрами останавливалось.
У Kafka Producer также серьезные проблемы со стабильностью. Если один или больше брокеров из кластера удалялись, или даже просто перезапускались, с определенной вероятностью Продюсер входил в состояние, из которого уже не мог выйти сам. В таком состоянии он не мог производить никаких событий. Единственным выходом был полный рестарт сервиса.
Даже не касаясь решения этих вопросов, мы поняли, что на приведение системы в рабочее состояние понадобится много сил. Нам необходимо будет определить стратегию развертывания для Kafka Broker-ов и Mirror Maker-ов, смоделировать требуемые мощности и распланировать все системные компоненты, а также задать метрики производительности для системы мониторинга Spotify.
Мы оказались на перепутье. Должны ли мы сделать значительные инвестиции и попытаться заставить Kafka работать на нас? Или стоит попробовать что-то еще?
Google Cloud Pub/Sub
Пока мы боролись с Kafka, другие члены команды Spotify начали экспериментировать с Google Cloud. Особенно нас интересовал Cloud Pub/Sub. Казалось, что Cloud Pub/Sub сможет удовлетворить нашу потребность в надежной очереди: он может хранить недоставленные данные в течение 7 дней, обеспечивает надежность за счет подтверждений на уровне приложения и имеет «at-least-once» семантику доставки.
Помимо удовлетворения наших основных потребностей, у Cloud Pub/Sub есть и дополнительные преимущества:
- Доступность – как глобальный сервис, Pub/Sub доступен во всех зонах Google Cloud. Передача данных между нашими дата-центрами будет идти не через нашего нормального интернет провайдера, а будет использоваться базовая сеть Google.
- Простой REST API – если бы нам не понравилась клиентская библиотека, которую предоставляет Google, то мы легко могли бы написать собственную.
- Операционная ответственность лежала на ком-то еще – нет нужды создавать модель просчета ресурсов или стратегию развертывания, настраивать мониторинг и предупреждения.
Звучит прекрасно на бумаге… но слишком хорошо, чтобы быть правдой? Решения, который мы создали на Apache Kafka, хотя и не были идеальными, все же нормально нам служили. У нас было много опыта в борьбе с различными отказами, доступ к железу и исходникам, и – теоретически – мы могли найти источник любой проблемы. Переход к управляемому сервису означал, что мы должны были доверить ведение операций другой организации. И при этом Cloud Pub/Sub рекламировался как бета-версия – мы не знали о какой-либо другой организации, кроме Google, которая использовала бы его в таком масштабе, который был нужен нам.
Имея все это ввиду, мы решили, что нам нужен подробный план тестирования, чтобы быть абсолютно уверенными в том, что если мы перейдем на Cloud Pub/Sub, то он будет соответствовать всем нашим требованиям.
Тестовая нагрузка Продюсера
Первым пунктом в нашем плане было тестирование Cloud Pub/Sub на то, сможет ли он выдержать нашу нагрузку. В настоящее время наша рабочая нагрузка достигает в пике 700К событий в секунду. Если учесть будущий рост и возможные сценарии аварийного восстановления, мы остановились на тестовой нагрузке в 2М событий в секунду. Чтобы совсем добить Pub/Sub, мы решили опубликовать весь этот объем трафика в одном дата-центре, так чтобы все эти запросы попали в машины Pub/Sub в одной зоне. Мы сделали предположение, что Google распланировал зоны как независимые домены, и что каждая зона может обрабатывать равные объемы трафика. В теории, если бы мы смогли пропихнуть 2М сообщений в одну зону, то смогли бы и передать и количество_зон*2М сообщений во всех зонах. Наша надежда была на то, что система сможет обрабатывать этот трафик как на стороне производителя, так и на стороне потребителя в течение длительного времени без деградации сервиса.
В самом начале мы наткнулись на камень преткновения: Java клиент Cloud Pub/Sub работал недостаточно хорошо. Этот клиент, как и многие другие Google Cloud API клиенты, автоматически сгенерирован из спецификаций API. Это хорошо, если вы хотите, чтобы клиенты поддерживали широкий набор языков, но не слишком, если вы хотите получить быстродействующий клиент для одного языка.
К счастью, у Pub/Sub есть REST API, так что для нас было просто написать собственную библиотеку. Мы создали нового клиента, думая в первую очередь о его быстродействии. Чтобы более эффективно использовать ресурсы, мы использовали асинхронную Java. Мы также добавили в клиент очереди и пакетную обработку. (Это не первый раз, когда нам пришлось засучить рукава и переписать клиента Google Cloud API – в другом проекте мы разработали быстродействующий клиент для Datastore API.)
C новым клиентом мы были готовы начать нагружать Pub/Sub по-взрослому. Мы использовали простой генератор для отправки фиктивного трафика от Сервиса событий к Pub/Sub. Сформированный трафик перенаправлялся через два Pub/Sub топика в соотношении 7:3. Чтобы сгенерировать 2М сообщений в секунду, мы запустили Сервис событий на 29 машинах.
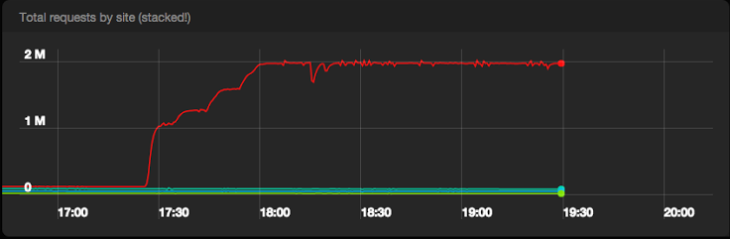
Количество успешных запросов в секунду к Pub/Sub из всех дата-центров
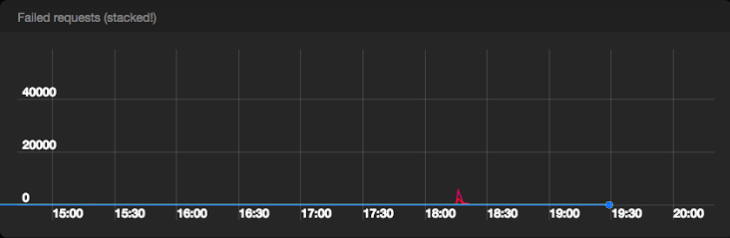
Количество неуспешных запросов в секунду к Pub/Sub из всех дата-центров
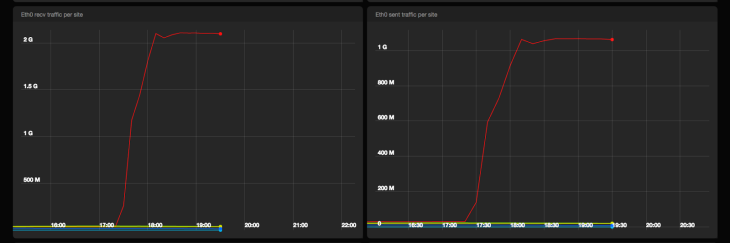
Входящий и исходящий сетевой трафик от машин Сервиса событий в bps
Pub/Sub прошел испытание с честью. Мы опубликовали 2М сообщений без какого-либо нарушения качества и почти не получили серверных ошибок от Pub/Sub бэкенда. Включение пакетной обработки и сжатия на машинах Сервиса событий привело к получению примерно в 1 Gpbs трафика к Pub/Sub.

График Google Cloud Monitoring для общего количества опубликованных сообщений в Pub/Sub
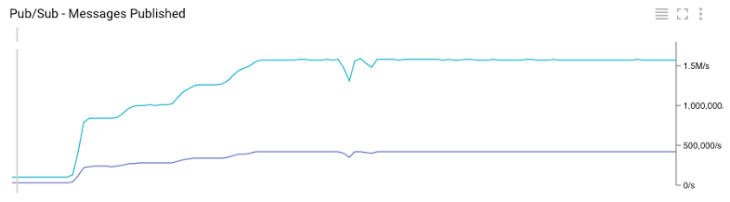
График Google Cloud Monitoring для количества опубликованных сообщений в топиках Pub/Sub
Полезный побочный эффект нашего теста – мы смогли сравнить наши внутренние метрики с метриками, предоставленными Google. Как показано на Графиках 3 и 6, они идеально совпадают.
Тест на стабильность Потребителей
Наш второй важный тест был посвящен потреблению. В течение 5 дней мы измеряли end-to-end задержки под большой нагрузкой. На время теста мы публиковали, в среднем, около 800К сообщений в секунду. Для имитации реальных нагрузок, скорость публикации менялась в течение дня. Чтобы удостовериться, что мы можем использовать несколько топиков одновременно, все данные публиковались для двух топиков в соотношении 7:3.
Слегка удивило в поведении Cloud Pub/Sub то, что необходимо создать подписки до сохранения сообщений – пока подписки не существует, никакие данные не сохраняются. Каждая подписка хранит данные независимо, и нет ограничений тому, сколько подписок может быть у потребителя. Потребители координируются на стороне сервера, и сервер ответственен за достаточное выделение сообщений для всех потребителей, запрашивающих данные. Это очень отличается от Kafka, где данные сохраняются в созданном топике и количество потребителей в топике ограничено количеством разделов в топике.

В нашем тесте мы создали подписку, часом спустя мы начали потреблять данные. Мы потребляли их пакетами по 1000 сообщений. Так как мы не пытались достичь предела в потреблении, мы хотели просто слегка превысить текущий пиковый уровень. Это заняло 8 часов. После того как мы достигли его, Потребители продолжили работать на том же уровне, который соответствовал скорости публикации.
Средняя end-to-end задержка, которую мы измеряли в ходе тестового периода – включая восстановление backlog – была в районе 20 секунд. Мы не наблюдали потерь сообщений в течение всего тестового периода.
Решение
На этих тестах мы убедились, что Cloud Pub/Sub это правильный выбор для нас. Задержки были малы и постоянны, и единственное ограничение в емкости, с которым мы столкнулись, была установленная квота. Короче говоря, выбор Cloud Pub/Sub вместо Kafka 0.8 для нашей новой платформы доставки сообщений, был очевидным решением.
Следующий шаг
После того как события надежно сохранены в Pub/Sub, настало время экспортировать их в HDFS. Чтобы в полной мере использовать возможности Google Cloud, мы решили попробовать Dataflow.
В последней статье из этой серии мы расскажем о том, как использовали Dataflow для наших целей. Оставайтесь с нами!
