Представляем гостевой пост от компании Surf Studio (Certified Google Developer Agency).
Привет, Хабр. Меня зовут Александр Ольферук (@olferuk), я занимаюсь машинным обучением в Surf. С 2011 года мы разрабатываем мобильные приложения для крупного бизнеса, а теперь готовим к релизу B2B-продукт с TensorFlow. Спасибо коллегам из Google за возможность рассказать немного о нашем опыте.
В современном машинном обучении много энтузиастов, но критически не хватает профессионалов. В нашей команде я вживую наблюдал превращение таких энтузиастов в специалистов с боевым опытом. Разрабатывая первый для нас коммерческий продукт, связанный с машинным обучением, команда столкнулась с кучей нюансов. Всеми любимые соревнования на Kaggle оказались очень далеки от решения задач реального бизнеса. Сейчас хочу поделиться опытом, показать примеры и рассказать немного о том, через что мы прошли.
Задача
Задача нашей системы — предсказывать оптимальную наценку на товары розничной сети, имея трехлетнюю историю продаж. Цель — сделать бизнес клиента более прибыльным, конечно же. Данные агрегированы по неделям: известны технические характеристики товаров, сколько единиц товара было продано, в скольких магазинах товар есть в наличии, цены закупки и розницы, а также прибыль, полученная в итоге. Это сырые данные, на продажи влияет еще множество факторов. Все остальные признаки, начиная от инфляции и цен на сырье, и заканчивая погодой, мы собрали самостоятельно. Перед нами был каталог с более чем 20 000 товаров. Из-за различия в их типах мы пришли к построению не одной, а сразу семейства моделей. Каждая из них тренируется на истории о товарах, с точки зрения продаж ведущих себя одинаково.
В соревнованиях по машинному обучению величина для предсказания обычно определена заранее. В реальном же бизнес-проекте мы вправе выбирать ее самостоятельно. Что лучше: пытаться предсказать прибыль, наценку, или, может, количество продаваемых товаров? Отталкиваемся от того, что мы можем предсказать эффективно, и что позволит клиенту зарабатывать больше денег.
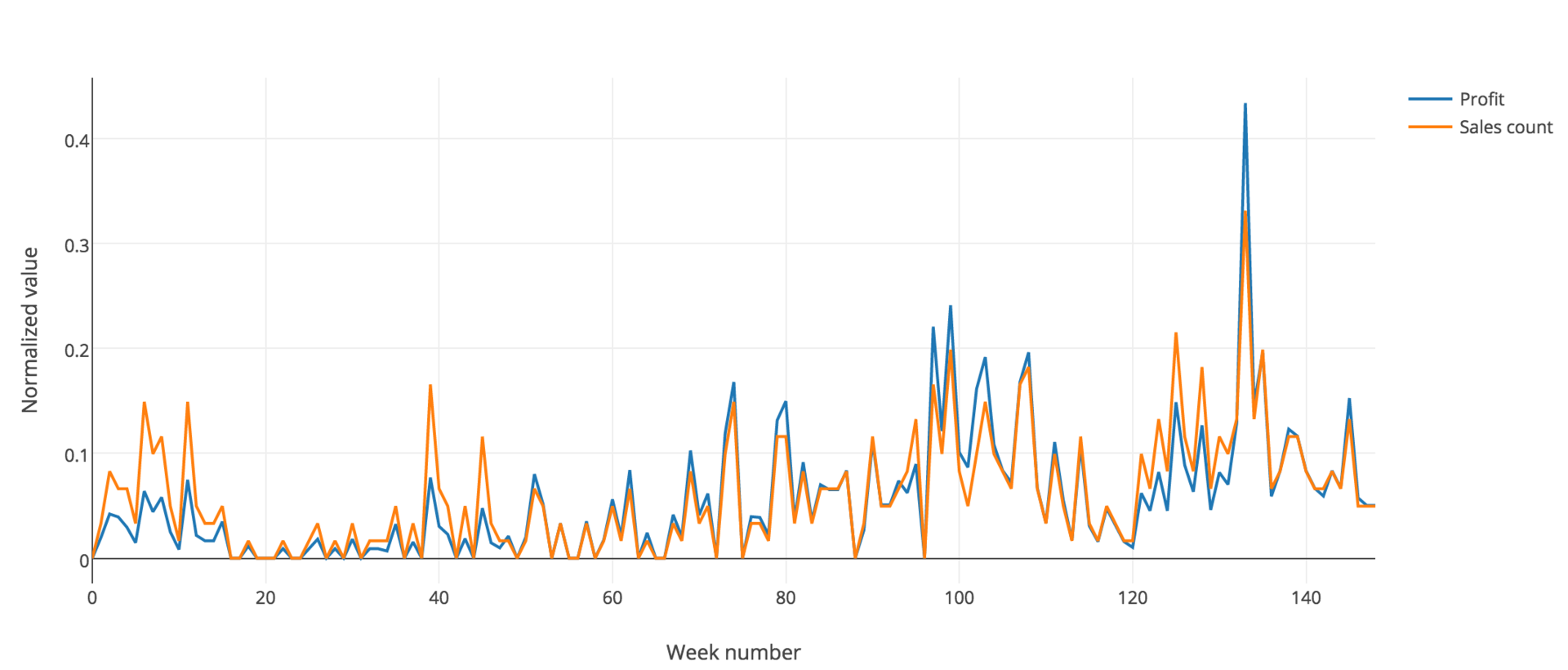
Ось X здесь — время, разбитое по неделям. Y — нормированная величина, включающая прибыль (синяя линия) и количества продаж (оранжевая линия) Поскольку они почти совпадают, в нашей задаче мы можем опираться или на любую из них.
Есть и другое, не менее важное отличие. Реальный мир не так совершенен, как искусственные модели. Если в соревнованиях единственным важным критерием является точность, то в реальном бизнес-проекте жизненно-важно соблюсти хрупкий баланс между точностью и здравым смыслом.
Как начать проект?
Первым делом нужно выбрать подходящую метрику. Она должна не только отражать точность решения, но и соответствовать логике предметной области. Очевидно, что при выборе наценки для товара для максимизации прибыли, бессмысленно выбирать ее нулевой или крайне большой. Это невыгодно либо покупателю, либо магазину. А значит решение нужно искать в доверительном интервале, основываясь на разумных ценовых пределах для конкретного товара, а также на его старой цене.
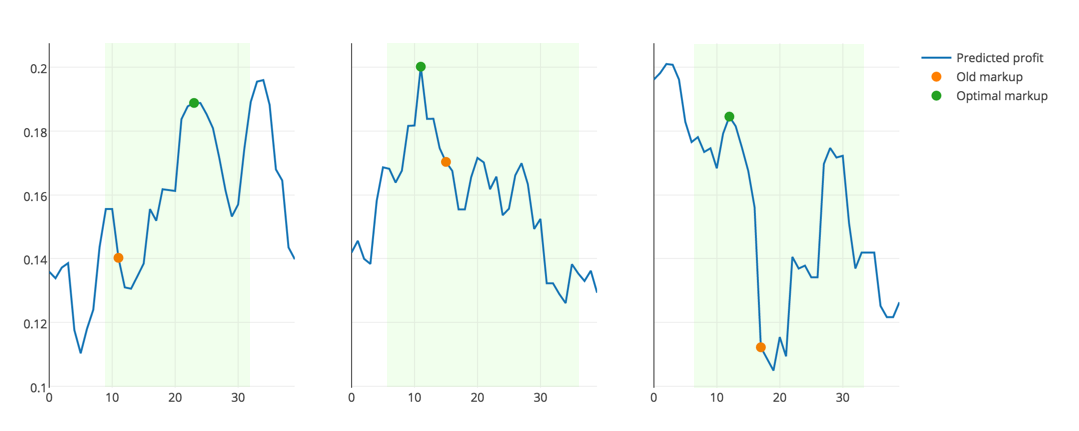
Про кросс-валидацию сказано уже много, описано множество техник. Наша же задача связана с историческими данными, то есть меняющимися во времени. Поэтому разбивать выборку на случайные фолды нельзя, можно лишь предсказывать будущие значения уровня прибыли, обучаясь на прошлом.
Однако не все данные одинаково полезны. Как я уже говорил, при построении моделей мы учитываем реальную жизнь. Аномальные данные могут исказить общую картину и существенно сказаться на эффективности модели. Поэтому данные, собранные в период кризиса конца 2015 — начала 2016, мы решили не учитывать.
Pipeline
После выбора метрики и кросс-валидации усилия команды должны быть брошены на то, чтобы как можно раньше реализовать end-to-end структуру.

Структура на схеме постоянна и не должна меняться с развитием проекта. На первых порах лучше ограничить очистку данных хотя бы борьбой с отсутствующими значениями: для большинства классификаторов критично отсутствие NaN-значений в данных. Отложить следует также трансформацию признаков и добавление новых.
После этого нужно выбрать baseline-модель, например решающий лес. Используйте ее для формирования первой отчетности. Ответьте на два вопроса: «Что хотел бы видеть заказчик?», «Какого рода результаты будут понятны и полезны экспертам предметной области?». Отчеты и необходимые графики формируйте исходя из ответов на эти вопросы. В ходе дальнейшей разработки стоит возвращаться к этому шагу, заново отвечать, сохранять ответы, анализировать прогресс.
Мы же на практике получили систему с формируемой отчетностью достаточно поздно. Поэтому наглядно посмотреть положительную динамику в развитии модели весьма затруднительно.
В роли архитектуры для решения подобных задач себя отлично зарекомендовали пайплайны — абстракции, представляющие цепочку преобразований или композицию функций.
В изначальной реализации каждый из этапов в этой цепочке — трансформер, принимающий на вход объект класса ndarray (является numpy-объектом).
Мы решили улучшить это решение. На каждом этапе хотелось получать новый Pandas dataframe. В таком случае классификаторы получат из финальной таблицы все необходимые для обучения признаки, а визуализации упростится, ведь все поясняющие метки под рукой.
От таких библиотек, как sklearn-pandas или luigi, мы отказались. Фактически мы написали собственный велосипед. Это небольшой и очень сырой хелпер, который мы сделали исключительно для себя. В ближайшее время причешем, но пользоваться можно уже сейчас. Мы постарались сделать прозрачный и емкий интерфейс с учетом перечисленных выше особенностей.
Вот несколько примеров-этапов из нашего пайплайна.
Добавляем цены на металл, а также цены с лагом в 1 и 2 месяца:
('add_metal', DFFeatureUnion([
('metal', DFPipeline([
('load_metal', MetalAppender()),
('metal_lag', Lagger([4, 8]))
]))
]))И еще один:
('lags', Lagger(columns_strategies={
'Z': { 'lags': [1, 2], 'groupby': 'name' },
'X': { 'lags': [1], 'groupby': 'name' },
'Y': { 'lags': [1], 'groupby': 'name' },
'markup': { 'lags': [1], 'groupby': 'name' }
}))Здесь логика несколько сложнее, чем просто сдвинуть колонку оператором shift из коробки Pandas. Мы должны учесть, что каждый из признаков сдвигается только для конкретного товара, а не во всей таблице разом. Для того, чтобы решить эту проблему, и был создан класс Lagger.
Модель разработки
Дальнейшее развитие проекта идет по спиралевидной модели разработки. Если у вас есть новые идеи: подключение новых признаков или другой способ обработки имеющихся — проверяйте. С выстроенной архитектурой проверка каждой вашей гипотезы будет выглядеть так:
- Модифицируем пайплайн обработки данных, вносим необходимые изменения;
- переучиваем estimator, подбираем оптимальные гиперпараметры;
- вычисляем новый score для полученного классификатора;
- визуализируем результаты, формируем отчетность, сравниваем, делаем выводы.
Небольшое уточнение по третьему пункту. Стоит обратить внимание не на абсолютные значения метрики, а только на ее изменение. Мало того: нельзя доверять этой разнице, если в масштабах вашей выборки все укладывается в рамки случайного отклонения.
Есть хорошие гайдлайны по организации проекта. Можете ознакомиться с этим и этим, например.
Если открыть папку проекта, то вот, что мы увидим внутри:
project/
├── data/ <- исходные предоставленные клиентом данные
├── cache/ <- pickle-файлы со всякой всячиной
├── notebooks/ <- тетрадки
├── scripts/ <- *.py-скрипты с протестированным кодом
├── logs/ <- логи
├── out/ <- все обработанные данные, в том числе:
└─ reports/ <- отчеты, в нашем случае xls-файлы
└─ plots/ <- графики, в нашем случае сделанные в plotly
├── requirements <- список всех зависимостей проекта
└── README.mdКак разделить таски между членами команды, чтобы работать, не мешая друг другу? Мы пришли к такой схеме: в рабочей директории есть набор Jupyter-тетрадок, Python-скрипты и сами данные: кэш, отчеты, графики. Каждый работает в отдельной тетрадке. Думаю, не нужно говорить, что тетрадь должна быть хорошо прокомментирована, а все вычисления в них воспроизводимы.
Сколько нужно таких тетрадок и насколько большими они должны быть? Из нашего опыта — отдельная тетрадь для каждого эксперимента. Пример: «Проверка необходимости внедрения доверительного интервала для предсказаний». Это включает в себя как необходимый код логики, так и визуализацию. Опять же, хорошо и посмотреть, что советуют другие.
Как только эксперимент завершен и гипотеза проверена — все необходимые функции тестируются и отправляются в Python-скрипты. Если эксперимент себя оправдал, конечно.
Визуализируй это
Прежде чем подавать данные на вход в классификатор и оценивать результат, следует разобраться, с чем же имеем дело. Вот, какие инструменты нам помогли нам в работе:
• Для визуализации отсутствующих значений пользовались библиотекой MissingNo.
• Для того, чтобы оценить характер распределения признака, мы пользовались гистограммами: violin plot (его предоставляет, например, библиотека seaborn), box plot. Зачем это нужно?
- Характер распределения подсказывает, как поступить с отсутствующим значением: для скошенных вполне подойдет заполнение модой, но в случае нормального распределения следует воспользоваться матожиданием.
- Скошенные данные данные нужно обрабатывать соответственно. Например, использование логарифмирования или нахождение корня N-й степени делает распределение признака более похожим на нормальное. Обычно это помогает увеличить точность.
• Для оценки важности признака использовали factor plot.
• Для оценки попарной корреляции признаков использовали correlation matrix и scatterplot matrix. Цель — найти сильно коррелированные признаки и исключить схожие, если такие имеются. Явно значимой пользы для классификатора они не несут, лишь увеличивают дисперсию предсказаний.

Вот как мы проверили влияние инфляции. На графике синим показано изменение уровня розничной цены на товар во времени. Однако стоит лишь вычесть инфляцию (оранжевые точки), становится видно, что розничная цена колеблется в районе определенного уровня (если считать все в ценах января 2014 года, то есть нулевой недели). Значит, мы правильно учли влияние внешнеэкономического фактора.
Переезжаем в облака с Google
Итак, у нас построен пайплайн, делающий все необходимое: от загрузки и обработки данных до формирования финального предсказания. Теперь следует задуматься о том, как сделать модели точнее.
Для этого мы можем:
- выбирать лучшие признаки;
- добавлять новые;
- искать лучшие гиперпараметры моделей.
Если же требуется модифицировать готовый пайплайн, например, изменить MinMaxScaler на StandardScaler — придется обработать данные и настраивать параметры моделей заново. Много ли у вас данных или мало, на домашних и рабочих компьютерах пробегать десятки циклов grid search для поиска лучших гиперпараметров — удел терпеливых. Это очень долго. Очень.
У нас решение созрело сразу: переезжаем в Google Cloud. От DataLab нам, однако, пришлось отказаться: поддерживается только Python версии 2.7. В рамках задачи нам не требовалась богатая инфраструктура, нам нужна была очень мощная виртуальная машина, а JupyterHub мы можем развернуть и сами.
На удаленной машине создали несколько директорий: общую и отдельные для каждого члена команды. Это позволило каждому не только работать в общей среде, но и при желании организовать собственный git flow в отдельном разделе. Безопасности ради все ходили исключительно по https, ssh-сертификат тоже сделали.
Из интересного: скрипты Google для старта виртуальных машин написаны на Python 3.5 и не хотели дружить с нашим Python 3.6. К счастью, все оказалось решаемо.
Стоила ли игра свеч? Безусловно! Чтобы перебрать все гиперпараметры для пайплайна простым рабочим компьютерам требовалась пара дней. В облаке Google все оказалось гораздо быстрее. Уходишь с работы домой? Пришел утром и все уже готово.
Что в итоге?
Из ERP-системы клиента (1С, SAP, Oracle и другие) по требованию можно выгружать исторические данные о продажах. Группа товаров, для которой нужно сформировать прогнозы, обозначена отдельно. Добавляем дополнительные данные, собранные из открытых источников.
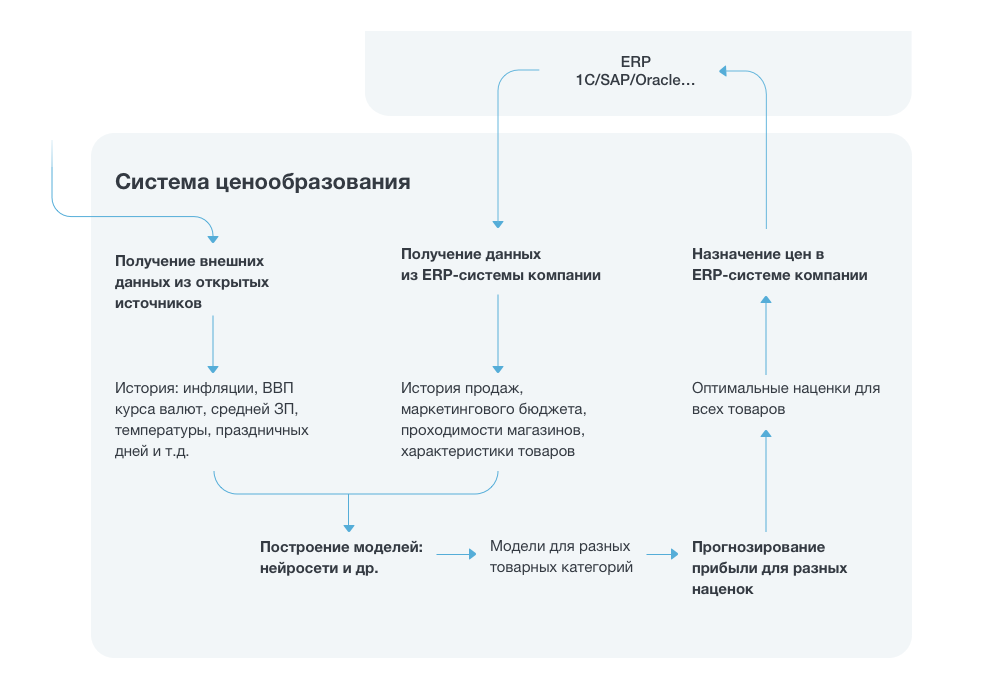
Так как оптимальные параметры модели найдены и закэшированы, остается немного: обучить модель, и с ее помощью генерировать новые отчеты. В отчетах для клиента собирается как агрегированная статистика по имеющимся данным, так и прогнозы: по компании, по категориям товаров, по отдельным товарам.
Клиент может корректировать ценовую политику на основе полученных прогнозов.
А/B-тест по-хардкору
Чтобы показать бизнесу, что умные машины могут не только распознавать картинки с арбузами и писать забавные стихи, нужны результаты. Пока в индустрии широко известных результатов нет, все будут с большим опасением смотреть на подобные решения.
Нам очень повезло с клиентом. Они поверили в новую для них технологию и дали нам важный шанс — провести хардкорнейший A/B-тест. Нашему коду доверили формировать рекомендации по ценам на все товары сети в целом регионе. Итоговые данные сравним с данными по регионам, где цены формируются по старинке. Если все будет хорошо — будем гордиться тем, что немножко изменили мир, сделали свой скромный вклад в индустрию и проникновение машинного обучения в бизнес. Скрестите за нас пальцы?
В завершении
Помните, что простые решения часто оказываются лучшими, а лучший код — чистый.
Чистите зубы дважды в день.
Перечитайте МакКонелла.
Кроссфит и ставки на спорт не стоят потраченного времени.
Проводите больше времени с семьей.
Удачи, счастья, здоровья!
