
Основное направление деятельности нашей компании — это разработка корпоративных информационных систем. Помимо систем под заказ мы делаем два тиражируемых продукта. Конечно, мы стараемся, чтобы наши продукты были максимально удобными и функциональными. Однако в реальной жизни каждый бизнес имеет свои особенности и не всегда готов мириться со стандартными возможностями системы. Возникает задача доработки решения под конкретного клиента и его дальнейшей поддержки. Какие существуют подходы к организации архитектуры расширяемых продуктов? Какие проблемы могут возникнуть при разработке? Как поступили мы? Обо всем этом ниже.
Возможные подходы
Для начала уточним, что «проектом-расширением» или просто «расширением» мы называем продукт с внесенными модификациями для конкретного заказчика. А теперь рассмотрим некоторые из возможных подходов к расширению продукта:
Отдельный бранч в репозитории под каждый проект-расширение
Пожалуй, эта мысль — первая, которая приходит в голову, ведь ответвиться от основного продукта и внести изменения в новый бранч — самый быстрый способ достичь желаемого результата. Вопрос лишь в цене, которую придется заплатить за эту быстроту.
После разработки и внедрения информационной системы начинается самая долгая и часто самая болезненная фаза жизненного цикла — поддержка. В случае с проектом-расширением эта фаза может стать вдвойне неприятнее, ведь придется поставлять заказчику не только новые “фичи”, которые реализованы специально для него, но и новые версии продукта, на котором основано расширение. Для того, чтобы в проект попали изменения из новой версии продукта, видится один способ — merge изменений из основной ветки в бранч расширения. Но представьте, насколько это окажется трудоемко, и сколько потенциальных ошибок может проявиться, если один и тот же участок кода сильно изменялся в обеих ветках.
Можно, конечно, сразу думать о будущих переводах на новую версию продукта и организовывать код таким образом, что все специфичные изменения будут располагаться максимально в стороне от кода основного продукта. В идеальном мире это бы сработало, но мы с вами живем в суровой реальности, где часто срок выполнения задачи может быть объявлен как “вчера”, и работает над проектом отнюдь не компактная команда классных профессионалов, а батальон вчерашних студентов. В таких ситуациях люди редко задумываются об архитектуре и идут по пути наименьшего сопротивления — нашел место, где надо поправить, удалил старое, написал новое. Это, кстати, ведет к еще одной большой проблеме — логика расширения перемешивается с логикой продукта.
Итог: данный подход является самым гибким, так как позволяет изменить абсолютно любую часть продукта, но радоваться гибкости придется только первые пару обновлений. Впоследствии огромные сложности доставят поддержка расширения и перевод его на новые версии продукта. Причем чем дольше будет жить информационная система, тем более и более трудоемкой будет становиться поддержка.
После разработки и внедрения информационной системы начинается самая долгая и часто самая болезненная фаза жизненного цикла — поддержка. В случае с проектом-расширением эта фаза может стать вдвойне неприятнее, ведь придется поставлять заказчику не только новые “фичи”, которые реализованы специально для него, но и новые версии продукта, на котором основано расширение. Для того, чтобы в проект попали изменения из новой версии продукта, видится один способ — merge изменений из основной ветки в бранч расширения. Но представьте, насколько это окажется трудоемко, и сколько потенциальных ошибок может проявиться, если один и тот же участок кода сильно изменялся в обеих ветках.
Можно, конечно, сразу думать о будущих переводах на новую версию продукта и организовывать код таким образом, что все специфичные изменения будут располагаться максимально в стороне от кода основного продукта. В идеальном мире это бы сработало, но мы с вами живем в суровой реальности, где часто срок выполнения задачи может быть объявлен как “вчера”, и работает над проектом отнюдь не компактная команда классных профессионалов, а батальон вчерашних студентов. В таких ситуациях люди редко задумываются об архитектуре и идут по пути наименьшего сопротивления — нашел место, где надо поправить, удалил старое, написал новое. Это, кстати, ведет к еще одной большой проблеме — логика расширения перемешивается с логикой продукта.
Итог: данный подход является самым гибким, так как позволяет изменить абсолютно любую часть продукта, но радоваться гибкости придется только первые пару обновлений. Впоследствии огромные сложности доставят поддержка расширения и перевод его на новые версии продукта. Причем чем дольше будет жить информационная система, тем более и более трудоемкой будет становиться поддержка.
Использование динамических атрибутов (модель Entity-Attribute-Value)
Модель Entity-Attribute-Value (или Open Schema) может использоваться вместе со стандартной реляционной моделью для динамического определения и хранения значений новых атрибутов сущностей. При использовании модели EAV значения атрибутов обычно пишутся в одну таблицу из трех колонок. Как несложно догадаться, их имена Entity, Attribute и Value:
Обязательным компонентом схемы является также таблица, которая хранит описание метаданных для атрибутов:
Для использования этой модели в продукте необходимо сделать 2 вещи:
Самое главное достоинство подхода — это отсутствие необходимости создавать проект-расширение. Заказчику поставляется базовый продукт и на этапе настройки или даже эксплуатации заводится любое количество динамических атрибутов в сущностях.
Далее о недостатках. Во-первых, это ограниченность применения. Модель EAV позволит лишь добавить атрибуты в сущность и отобразить их в заранее определенном месте на экране. Не более того. Об изменении функциональности, хитрых UI-компонентах здесь речи не идет.
Во-вторых, EAV модель создает большую дополнительную нагрузку на сервер БД. Для загрузки одного экземпляра сущности без связей потребуется чтение вместо одной нескольких строк таблицы. Для загрузки списка экземпляров, например в таблицу на UI, вообще потребуется N+1 запросов, либо джойны по числу колонок таблицы. Учитывая, что база данных в корпоративных системах и так чаще всего является самым медленным и плохо масштабируемым элементом, такая дополнительная нагрузка может просто убить систему.
В-третьих, опять же из-за структуры базы будет довольно сложно делать выборки данных для отчетов — вместо написания обычного SQL для реляционных данных потребуются гораздо более сложные запросы.
- Entity — хранит ссылку на объект, поле которого мы описываем. Обычно это идентификатор сущности;
- Attribute — ссылка на определение атрибута (об этом ниже);
- Value — собственно значение атрибута.
Обязательным компонентом схемы является также таблица, которая хранит описание метаданных для атрибутов:
- тип атрибута;
- ограничения (длина поля, регулярное выражение, которому должно соответствовать значение и пр.);
- компонент для отображения в UI;
- порядок отображения компонента в UI.
Для использования этой модели в продукте необходимо сделать 2 вещи:
- Реализовать механизм задания метаданных, с помощью которого мы сможем, например, указать, что к сущностям типа “Договор” добавится новый атрибут «Дата расторжения», тип поля — «Дата», компонент для отображения — DateField.
- Реализовать механизмы отображения и ввода значений динамических атрибутов на необходимых экранах продукта. Механизм должен находить возможный набор атрибутов для данной сущности в таблице с описанием метаданных, отображать компоненты для их редактирования, а затем в таблице с данными искать и отображать их значения, сохраняя их при закрытии экрана.
Самое главное достоинство подхода — это отсутствие необходимости создавать проект-расширение. Заказчику поставляется базовый продукт и на этапе настройки или даже эксплуатации заводится любое количество динамических атрибутов в сущностях.
Далее о недостатках. Во-первых, это ограниченность применения. Модель EAV позволит лишь добавить атрибуты в сущность и отобразить их в заранее определенном месте на экране. Не более того. Об изменении функциональности, хитрых UI-компонентах здесь речи не идет.
Во-вторых, EAV модель создает большую дополнительную нагрузку на сервер БД. Для загрузки одного экземпляра сущности без связей потребуется чтение вместо одной нескольких строк таблицы. Для загрузки списка экземпляров, например в таблицу на UI, вообще потребуется N+1 запросов, либо джойны по числу колонок таблицы. Учитывая, что база данных в корпоративных системах и так чаще всего является самым медленным и плохо масштабируемым элементом, такая дополнительная нагрузка может просто убить систему.
В-третьих, опять же из-за структуры базы будет довольно сложно делать выборки данных для отчетов — вместо написания обычного SQL для реляционных данных потребуются гораздо более сложные запросы.
Плагинная архитектура
Данная архитектура позволяет хранить дополнительную функциональность в отдельных артефактах — плагинах. Если ваш заказчик хочет какой-то новой специфики, то вы ставите ему базовый продукт, пишете плагин, подключаете его и готово. Для использования плагинов в продукте должны быть объявлены точки расширения. Что это такое? Если просто, то это определенные места в коде. В этих местах перебираются загруженные плагины, анализируется, есть ли в плагинах логика, предназначенная для данной точки расширения, и если такая логика находится, она выполняется. Примеры точек расширения: пункт меню, обрабочик команды, кнопка на тулбаре, новый экран.
Такой часто используемый вариант расширения функциональности, как описание логики и обработчиков событий во внешних скриптах, также можно отнести к вариациям плагинов, т.к. скрипты вызываются и исполняются определенными точками программы.
Плагинная архитектура позволяет хранить всю новую функциональность отдельно от продукта, что является немаловажным её достоинством. Полное физическое разделение продукта и плагинов делает процесс обновления версии продукта или плагина очень простым — достаточно лишь заменить обновленный компонент.
Но и здесь, к сожалению, есть недостатки. Для каких-то продуктов они окажутся несущественными, для каких-то могут стать причиной невозможности использования плагинной архитектуры. Дело в том, что плагин может расширить систему лишь в том месте, где определена точка расширения. Бесспорно, существует класс продуктов, где таких мест в принципе немного и все они заранее определены, но есть также и огромная группа, для которой предугадать, что потребуется расширить завтра, практически невозможно. Анализ потенциальных расширяемых мест может стать очень ресурсоемким занятием, а в результате все равно оказаться не совсем точным. Кроме того, точки расширения — это усложнение основного кода, что всегда чревато ошибками и сложностью сопровождения. Подходить к определению точек расширения в основном продукте надо очень вдумчиво.
Такой часто используемый вариант расширения функциональности, как описание логики и обработчиков событий во внешних скриптах, также можно отнести к вариациям плагинов, т.к. скрипты вызываются и исполняются определенными точками программы.
Плагинная архитектура позволяет хранить всю новую функциональность отдельно от продукта, что является немаловажным её достоинством. Полное физическое разделение продукта и плагинов делает процесс обновления версии продукта или плагина очень простым — достаточно лишь заменить обновленный компонент.
Но и здесь, к сожалению, есть недостатки. Для каких-то продуктов они окажутся несущественными, для каких-то могут стать причиной невозможности использования плагинной архитектуры. Дело в том, что плагин может расширить систему лишь в том месте, где определена точка расширения. Бесспорно, существует класс продуктов, где таких мест в принципе немного и все они заранее определены, но есть также и огромная группа, для которой предугадать, что потребуется расширить завтра, практически невозможно. Анализ потенциальных расширяемых мест может стать очень ресурсоемким занятием, а в результате все равно оказаться не совсем точным. Кроме того, точки расширения — это усложнение основного кода, что всегда чревато ошибками и сложностью сопровождения. Подходить к определению точек расширения в основном продукте надо очень вдумчиво.
Как это делаем мы
Мы выпустили на рынок два тиражируемых продукта: ECM (или в более привычных терминах, систему электронного документооборота, СЭД) ТЕЗИС и систему для автоматизации бизнеса такси Sherlock. С самого начала было очевидно: для того, чтобы поставить конкретному клиенту максимально удобную систему, потребуются доработки продукта, и следовательно в основе продукта должна лежать легко расширяемая архитектура.
Начиная работу над новым расширением, часто мы даже не предполагали, в какого «монстра» (в хорошем смысле слова) этот проект может перерасти. Обычное явление — когда то, что начиналось как небольшая кастомизация, заканчивается практически полностью переписанными бизнес-процессами и дополнительной логикой на доброй половине экранов. Вдобавок продукт может расшириться новой функциональностью, вполне достаточной для самостоятельной системы. Как пример — в проекте-расширении ТЕЗИС для крупной распределенной компании появилась автоматизация деятельности казначейства, оценки эффективности работы сотрудников и еще несколько непростых модулей.
Разнообразие требований, их объем и непредсказуемость не позволяли использовать ни один из способов, описанных выше. Вдобавок ко всему, версии продуктов выходят довольно регулярно. Это делает обязательным требованием максимальную легкость перевода проекта-расширения на новую версию продукта.
Как же мы решаем проблему создания и поддержки расширений?
Наш проект-расширение
Большинство проектов нашей компании созданы с помощью платформы CUBA. Мы уже писали о ней в одной из прошлых статей. Для того, чтобы понять, как организованы проекты-расширения, сначала нужно разобраться с устройством самой платформы.
Если коротко, то CUBA — это набор модулей, каждый из которых предоставляет определенную функциональность:
- cuba — ядро приложения, содержит в себе всю инфраструктуру, средства для организации бизнес-логики, библиотеку визуальных компонентов, подсистему безопасности и пр.
- reports — подсистема генерации отчетов
- fts — подсистема полнотекстового поиска
- charts — подсистема вывода диаграмм
- workflow — подсистема управления бизнес-процессами
- ccpayments — подсистема работы с кредитными картами
Каждая подсистема может содержать в себе персистентные сущности, экраны и сервисы с бизнес-логикой.
При создании нового проекта, в его скрипте сборки прописываются зависимости от тех базовых модулей платформы, функциональность которых необходима. После этого, используя сущности, экраны и сервисы подключенных модулей, мы начинаем реализовывать проект. Физически модули платформы — это jar файлы, а установленный на сервере проект — обычное Java веб-приложение.
Когда нужно расширить существующий продукт на платформе, мы поступаем так: создаем новый проект, но в его скрипте сборки указываем зависимость уже не от модулей платформы, а от расширяемого продукта. Продукт сам фактически выступает в роли платформы для разработки.

Теперь внутри проекта-расширения можно создавать новые объекты доменной модели, описывать новый пользовательский интерфейс как в самом обычном проекте на платформе CUBA. Весь функционал ниже-лежащих модулей разработчику по прежнему доступен.
Самое очевидное достоинство — вся новая логика хранится в отдельном проекте-расширении. Всегда можно увидеть, что именно и когда вы написали в рамках текущего расширения. Подход никак не ограничивает разработчика в типе новой функциональности, как это делают плагинная архитектура и EAV.
Процесс перевода расширения на новую версию продукта заключается в следующем:
- вы указываете новую версию продукта в скриптах сборки и пересобираете расширение;
- если в расширении использовался только стабильный API продукта, то на этом все — запускаете свой расширенный продукт и вперед;
- если в продукте произошли значительные изменения в тех точках, которые вы расширяли, то может потребоваться изменение кода расширения. Как правило, это происходит нечасто, и локализовать проблему просто. Багфикс-релизы продуктов всегда сохраняют совместимость с расширениями.
Понятно, что в расширении легко можно создавать новые сущности, бизнес-логику и экраны для них. Но как изменить то, что уже имеется в продукте? Например добавить поле в продуктовую сущность и отобразить его в имеющихся экранах?
Добавление нового атрибута в сущность базового продукта
Определим для себя задачу: в сущность
User базового продукта необходимо добавить поле для хранения адреса. Подобные требования, пожалуй, самые распространенные среди наших заказчиков. Сразу скажем, что платформа поддерживает модель динамических атрибутов, о которых писалось выше, но на практике этот вариант используется редко — скорость выборки данных и легкость построения отчетов практически всегда оказываются важным требованием.Собственно об альтернативном способе добавления атрибута. В качестве ORM платформой используется OpenJPA. Объявление сущности в продукте выглядит следующим образом:
@Entity(name = "product$User")
@Table(name = "PRODUCT_USER")
public class User extends StandardEntity {
@Column(name = "LOGIN")
protected String login;
@Column(name = "PASSWORD")
protected String password;
//getters and setters
}
Как видите, это стандартное для JPA описание сущности и маппинга на таблицу и колонки БД.
Создаем наследника сущности в проекте-расширении:
@Entity(name = "ext$User")
@Extends(User.class)
public class ExtUser extends User {
@Column(name = "ADDRESS", length = 100)
private String address;
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
Механизм наследования стандартен для OpenJPA за исключением аннотации
@Extends, которая и представляет наибольший интерес. Именно она объявляет, что класс ExtUser будет повсеместно использоваться вместо класса User. Теперь все операции создания сущности
User будут создавать экземпляр расширенной сущности:User user = metadata.create(User.class); //создает класс ExtUser
Операции извлечения данных из БД также вернут экземпляры новой сущности. Например, в базовом продукте объявлен сервис поиска пользователей по имени, возвращающий результат следующего JPQL запроса:
select u from product$User u where u.name = :name
Без аннотации
@Extends мы имели бы на выходе коллекцию объектов User, и для получения адреса из ExtUser пришлось бы повторно перечитать из базы результат предыдущего запроса. Но используя информацию о переопределении, которую предоставляет аннотация @Extends, механизмы платформы произведут предварительную трансформацию запроса и вернут нам коллекцию объектов расширенной сущности ExtUser. Более того, если какие-то другие сущности имели ссылки на User, то при подключении расширения эти ссылки будут возвращать объекты типа ExtUser, без какого-либо изменения исходного кода.Сущность переопределена. Теперь хорошо бы отобразить новое поле пользователю.
Экран платформы представляет собой связку XML + Java. XML декларативно описывает UI, Java-контроллер определяет реакцию на события. Понятно, что с переопределением Java-контроллера особых проблем не возникнет, а вот с расширением XML чуть сложнее. Вернемся к предыдущему примеру с добавлением поля
address в сущность User. Описание разметки простейшего экрана выглядит так:
<window
datasource="userDs"
caption="msg://caption"
class="com.haulmont.cuba.gui.app.security.user.edit.UserEditor"
messagesPack="com.haulmont.cuba.gui.app.security.user.edit"
>
<dsContext>
<datasource
id="userDs"
class="com.haulmont.cuba.security.entity.User"
view="user.edit">
</datasource>
</dsContext>
<layout spacing="true">
<fieldGroup id="fieldGroup" datasource="userDs">
<column width="250px">
<field id="login"/>
<field id="password"/>
</column>
</fieldGroup>
<iframe id="windowActions" screen="editWindowActions"/>
</layout>
</window>
Видим ссылку на контроллер экрана UserEditor, объявление источника данных (datasource), компонента fieldGroup, отображающего поля сущности, и фрейм со стандартными действиями “ОК” и “Отмена” (windowActions).
Совсем не хочется дублировать код базового экрана в проекте-расширении, поэтому мы добавили в платформу возможность наследования XML-дескрипторов экранов. Вот так выглядит наследник экрана из базового проекта:
<window extends="/com/haulmont/cuba/gui/app/security/user/edit/user-edit.xml">
<layout>
<fieldGroup id="fieldGroup">
<column>
<field id="address"/>
</column>
</fieldGroup>
</layout>
</window>
В экране-наследнике указывается предок (атрибут extends) и описываются лишь те компоненты, которые должны быть добавлены в базовый экран либо переопределены в нем. Остается лишь объявить экран в конфигурационном файле с идентификатором базового экрана:
<screen id="sec$User.edit" template="com/sample/sales/gui/extuser/extuser-edit.xml"/>
Результат:
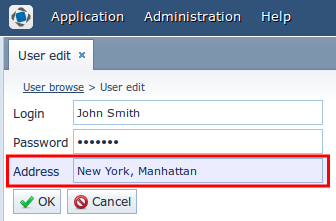
Переопределение бизнес-логики
Что касается переопределения функциональности, то здесь все достаточно тривиально. Инфраструктура платформы реализована на Spring. Соответственно и слой сервисов с бизнес логикой — это управляемые спрингом бины. Возможностей расширения, предоставляемых фреймворком, оказывается более чем достаточно для переопределения нужной бизнес-логики. Чтобы наглядно это продемонстрировать, снова небольшой пример. Допустим, на среднем слое в базовом продукте имеется компонент, выполняющий расчет цены:
@ManagedBean("product_PriceCalculator")
public class PriceCalculator {
public void BigDecimal calculatePrice() {
//price calculation
}
}
Для того, чтобы в проекте-расширении заменить алгоритм расчета цены мы делаем 2 простых шага:
Создаем наследника переопределяемого компонента:
public class ExtPriceCalculator extends PriceCalcuator {
@Override
public void BigDecimal calculatePrice() {
//modified logic goes here
}
}
Регистрируем класс в конфигурационном файле Spring с идентификатором бина из базового продукта:
<bean id="product_PriceCalculator" class="com.sample.extension.core.ExtPriceCalculator"/>
Теперь контейнер Spring будет всегда возвращать нам экземпляр ExtPriceCalculator.
Переопределение темы
С модификацией сущностей, компонентов экранов и бизнес-логики мы разобрались. Следующая на очереди визуальная тема.
Экраны, созданные с помощью платформы, работают в веб и десктоп клиентах. На текущий момент у нас преобладает использование веб-клиентов, поэтому говоря о кастомизации темы, рассмотрим именно их.
Для реализации веб-UI нами был выбран популярный фреймворк Vaadin. Vaadin позволяет описывать темы на SCSS. Описание стилей для новой темы на SCSS само по себе в разы приятнее, чем на чистом CSS. Мы сделали процесс создания темы еще менее трудоемким, вынеся множество параметров в переменные.
Заготовка для новой темы создается в 2 клика с помощью нашей студии разработки. Новая тема импортирует стили базовой темы платформы, разработчику остается переопределить лишь нужные стили и переменные. Многие клиенты желают видеть информационную систему в корпоративных цветах своей компании. Используемый нами подход к расширению тем позволяет им легко этого добиться.
В проекте расширении разработчику доступна возможность подключения новых визуальных компонентов. Большое количество готовых компонентов имеется в репозитории аддонов Vaadin. Если нужного компонента там не нашлось, то можно написать его самому.
Примеры различных визуальных тем:

Заключение
Если наш подход показался вам интересным, то можете попробовать платформу CUBA сами. Создавая продукт на платформе, вы автоматически получаете возможность кастомизировать его описанным способом. Всегда рады отзывам и комментариям!
P.S. Автор заглавного фото — Илья Варламов. Еще больше шикарных пакистанских грузовиков вы можете найти в его блоге.
