С годами компания обычно доходит до того, что много справочников на одну тему (например, «Хобби» или «Пол») хранятся в совершенно невообразимых форматах в различных системах, препятствуя эффективной интеграции и обмену данными.
Традиционный подход для решения этой проблемы рекомендует создавать единую версию справочника «Хобби» и настраивать потоки обмена в него (и из него) для всех информационных систем. Мы же решили пойти другим путем и создать децентрализованную опенсорсную НСИ — Перекодер.
Хотите знать, что именно мы сделали, и какую роль в нашем продукте играют Lucene и Apache CXF?
Как обычно решается задача хранения справочников?
IT-директор решает прекратить видовое разнообразие справочников, и компания начинает заниматься построением единого справочника. Он будет призван объединить в себе все возможные виды корпоративных данных и наконец-то положить конец «лоскутной автоматизации» и «историческому наследию».
Если уж решать проблему, то сразу для всего, правда?
А вот и нет.
О страшных минусах централизации не напишут в презентациях крупных западных компаний, которым очень хочется продать вам многомиллионный софт, и не скажут в пресс-релизах. Но начав такой проект, вы влипнете в долгое нудное внедрение, которое будет идти годами. Потому что сущности, которые вы будете приводить к одному стандарту, имеют различную природу. А это делает бессмысленным объединение их в рамках единой системы.
Не верите — посмотрите сами на таблицу с типами данным, которые обычно встречаются в компании:
На практике самые быстрые и успешные внедрения происходят в тех компаниях, которые отдельно решают задачу ТМЦ, отдельно — задачу построения справочника контрагентов, и как-то по ходу разбираются с классификаторами.
Для ТМЦ обычно внедряется Product Information Management (PIM), для контрагентов — Customer Data Integration (CDI), а вот с классификаторами происходит интересное: для них часто отдельно внедряется НСИ (MDM) и формируется единая версия правды.
Правильно ли внедрять НСИ и создавать единую версию классификаторов? Или можно решить эту задачу по-другому?
Хорошо ли иметь единую версию правды для классификаторов?
При приведении классификаторов к единому виду обычно происходит один из сценариев:
В общем, единая версия правды обычно обходится дорого.
Кроме того, с единым стандартом всегда появляется проблема «серой зоны». Это разница между значениями в исходных системах и значениями вожделенной единой версии правды, которые собственноручно подтвердил специально назначенный эксперт. Наличие «серой зоны» и необходимости работы с ней приводит к появлению многочисленных воркфлоу и альтернативных потоков, что составляет значительную часть функционала (читай стоимости) НСИ.
А еще и бизнес не всегда готов ждать многочисленных согласований годами. Поэтому в итоге данные начинаются пробрасываться «под столом», с использованием «временных» перекодировок (что это такое, мы расскажем ниже).
Возникает закономерный вопрос: если единая версия правды так дорого обходится, можно ли обойтись без нее?
Можно — есть организации, в которых не внедрены НСИ. Внимательно посмотрев, вы обнаружите в этих организациях много маленьких таблиц соответствия между справочниками «Пол», «Образование» и пр. в разных системах. Храниться они будут то в Oracle, то на шине, а то и прямо в коде для загрузок-выгрузок и экспортов-импортов. Потому что таблицы соответствия — это самый естественный способ решения проблемы, когда одинаковый домен для разных людей или систем обозначается по-разному.
Иными словами, можно всех людей на земле заставить говорить на эсперанто (создать единую версию правды), а можно на переговоры китайского и немецкого врачей пригласить китайско-немецкого медицинского переводчика (сделать таблицу соответствия).
Поэтому мы решили сделать синхронный переводчик, понимающий язык любой системы, и позволяющий им договариваться об одних и тех же понятиях в рамках бизнес-процесса. Мы назвали таблицы соответствия перекодировками, а саму систему — Перекодером.
Основное назначение Перекодера — хранить в себе копии справочников исходных систем и перекодировки между ними.
Что можно делать с помощью Перекодера
Можно и нужно:
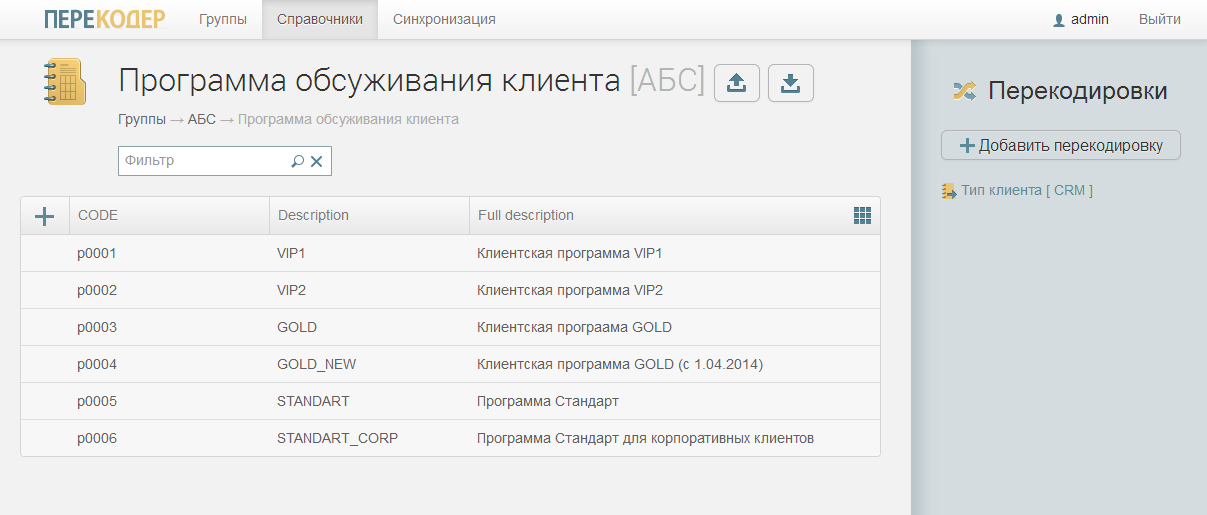
Классификатор «Программа обслуживания клиента», в котором атрибуты почему-то названы нерусскими словами Description и Full Description
Система разбита на модули, чтобы изолировать API, бизнес-логику и хранилище друг от друга. Связующим IoC контейнером между компонентами выступает Spring Framework.
Технологическую схему потоков данных можно представить так:

Как можно видеть, сервисы вообще не взаимодействуют напрямую с БД. Вместо этого вся работа (read / write) идет с индексом Lucene, а результаты write-операций дополнительно записываются в базу. Для чего так сделано? Все просто: основная задача системы — максимально быстро найти перекодировку (соответствие между записями в паре справочников), а такая архитектура наиболее эффективно справляется с этим на больших объемах данных. Плюс ко всему, получаем полнотекстовый поиск по всем данным «из коробки». Конечно, можно было бы использовать более высокоуровневые решения, например Elasticsearch или Solr, но у них есть свои недостатки, борьба с которыми выходит дороже, чем написать свой код.
Для того чтобы обеспечить целостность информации, модификация данных производится в одной транзакции в поисковом индексе и в базе. Причем интерфейсы спроектированы так, что бизнес-логика приложения знает только об индексе, а СУБД можно заменить на другое решение с минимальными модификациями. Фактически нужно реализовать пару классов и добавить их в classpath — все остальное сделает Spring и фабрики компиляции классов на лету (runtime code compiling).
Каркасом для SOAP и RESTfull интерфейсов выступает Apache CXF, который позволяет легко настроить версионность API (если вдруг понадобится изменить его) и вклиниться в любую фазу обработки входящего/исходящего сообщения.
github.com/hflabs/perecoder
rcd.hflabs.ru/rcd/admin/login
Логин: admin
Пароль: demo
confluence.hflabs.ru/x/RICSCg
Мы начали внедрение Перекодера у нескольких заказчиков.
Будем рады вашим комментариям по функциональности: что нравится, что нет, что непонятно.
Ну и если этот продукт будет вам полезен, значит, мы не зря потратили время на написание этой статьи ;)
Традиционный подход для решения этой проблемы рекомендует создавать единую версию справочника «Хобби» и настраивать потоки обмена в него (и из него) для всех информационных систем. Мы же решили пойти другим путем и создать децентрализованную опенсорсную НСИ — Перекодер.
Хотите знать, что именно мы сделали, и какую роль в нашем продукте играют Lucene и Apache CXF?
Как обычно решается задача хранения справочников?
IT-директор решает прекратить видовое разнообразие справочников, и компания начинает заниматься построением единого справочника. Он будет призван объединить в себе все возможные виды корпоративных данных и наконец-то положить конец «лоскутной автоматизации» и «историческому наследию».
Если уж решать проблему, то сразу для всего, правда?
А вот и нет.
О страшных минусах централизации не напишут в презентациях крупных западных компаний, которым очень хочется продать вам многомиллионный софт, и не скажут в пресс-релизах. Но начав такой проект, вы влипнете в долгое нудное внедрение, которое будет идти годами. Потому что сущности, которые вы будете приводить к одному стандарту, имеют различную природу. А это делает бессмысленным объединение их в рамках единой системы.
Не верите — посмотрите сами на таблицу с типами данным, которые обычно встречаются в компании:
| Что описывают | Стол, станок и т.д. | Физические, юридические лица, ЧП/ИП. | Атрибуты сущностей: образование, профессия и т.д. |
| Критерий истины атрибутов | Объективный (есть реальный станок, на который можно посмотреть) | Объективный (есть реальный человек или компания, у которого можно все спросить) | Субъективный (мнение эксперта, который может быть кагбе не совсем прав, или системы) |
| Размер | Средний (десятки тысяч единиц) | Средний или большой (сотни тысяч и миллионы записей) | Малый (тысячи единиц) |
| Количество атрибутов | Среднее (атрибуты ТМЦ) | Среднее (атрибуты клиента) | Малое (в большинстве случаев структура типа id — название) |
| Как существующие объекты меняются во времени? | Редко | Постоянно изменяются (смена адреса, семейного положения, пола...) | Непредсказуемо меняются в зависимости от потребностей информационной системы или бизнес-процесса |
На практике самые быстрые и успешные внедрения происходят в тех компаниях, которые отдельно решают задачу ТМЦ, отдельно — задачу построения справочника контрагентов, и как-то по ходу разбираются с классификаторами.
Для ТМЦ обычно внедряется Product Information Management (PIM), для контрагентов — Customer Data Integration (CDI), а вот с классификаторами происходит интересное: для них часто отдельно внедряется НСИ (MDM) и формируется единая версия правды.
Правильно ли внедрять НСИ и создавать единую версию классификаторов? Или можно решить эту задачу по-другому?
Хорошо ли иметь единую версию правды для классификаторов?
При приведении классификаторов к единому виду обычно происходит один из сценариев:
- Создается монстро-справочник, который учитывает все комбинации в исходных системах. Этот сложный справочник с трудом поддается модификации, требует длительных согласований, и со временем на него потихоньку все забивают
- Создается единый справочник, который содержит в себе урезанную версию правды, устраивающую всех. Кто работал в большой компании, тот знает, что поиск «правды, устраивающей лебедя, рака и щуку» редко заканчивается успешно, а если заканчивается, то требует много-много часов ожесточенных совещаний.
В общем, единая версия правды обычно обходится дорого.
Кроме того, с единым стандартом всегда появляется проблема «серой зоны». Это разница между значениями в исходных системах и значениями вожделенной единой версии правды, которые собственноручно подтвердил специально назначенный эксперт. Наличие «серой зоны» и необходимости работы с ней приводит к появлению многочисленных воркфлоу и альтернативных потоков, что составляет значительную часть функционала (читай стоимости) НСИ.
А еще и бизнес не всегда готов ждать многочисленных согласований годами. Поэтому в итоге данные начинаются пробрасываться «под столом», с использованием «временных» перекодировок (что это такое, мы расскажем ниже).
Можно ли не создавать единую версию правды?
Возникает закономерный вопрос: если единая версия правды так дорого обходится, можно ли обойтись без нее?
Можно — есть организации, в которых не внедрены НСИ. Внимательно посмотрев, вы обнаружите в этих организациях много маленьких таблиц соответствия между справочниками «Пол», «Образование» и пр. в разных системах. Храниться они будут то в Oracle, то на шине, а то и прямо в коде для загрузок-выгрузок и экспортов-импортов. Потому что таблицы соответствия — это самый естественный способ решения проблемы, когда одинаковый домен для разных людей или систем обозначается по-разному.
Иными словами, можно всех людей на земле заставить говорить на эсперанто (создать единую версию правды), а можно на переговоры китайского и немецкого врачей пригласить китайско-немецкого медицинского переводчика (сделать таблицу соответствия).
Поэтому мы решили сделать синхронный переводчик, понимающий язык любой системы, и позволяющий им договариваться об одних и тех же понятиях в рамках бизнес-процесса. Мы назвали таблицы соответствия перекодировками, а саму систему — Перекодером.
Основное назначение Перекодера — хранить в себе копии справочников исходных систем и перекодировки между ними.
Как это все работает
- В начале работы Перекодер считывает справочники из баз данных исходных систем и сохраняет их копии к себе в базу для последующей автоматической синхронизации. Мы работаем с Sybase, MariaDB, Vertica, MS SQL Server, MySQL, Oracle, PostgreSQL.
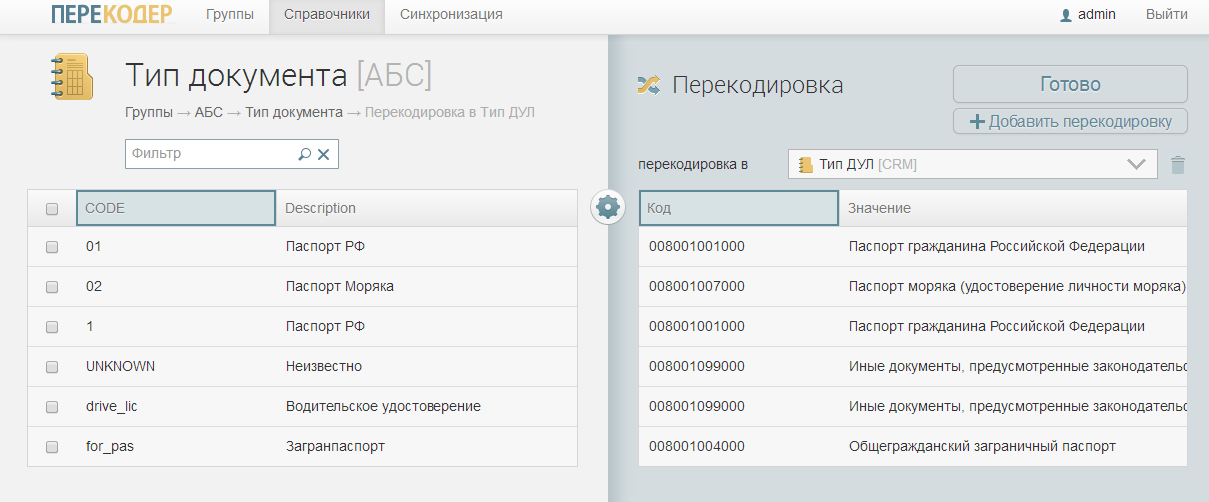
Пруфпик
- В интерфейсе Перекодера оператор настраивает таблицы соответствия записей справочников. Например, если мужской пол в одной системе заведён как «М», а в другой как «1», то оператор ставит в соответствие эти два значения, создавая перекодировку.
- Теперь любая система в процессе обмена информацией с другой системой может запросить у Перекодера через SOAP или REST интерфейс перевод значения из своего классификатора на язык целевой системы или перевести полученный данные на свой диалект.
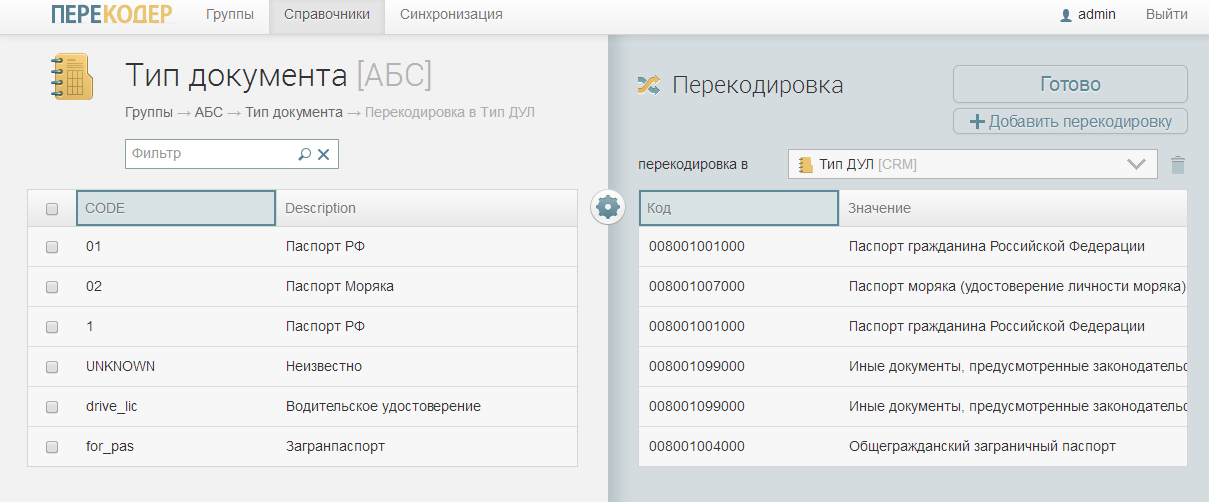
Перекодировка из справочника «Тип документа» некой банковской системы (АБС) в справочник «Тип ДУЛ» для CRM. Загранпаспорт соответствует общегражданскому заграничному паспорту, водительское удостоверение соответствует иным документам. АБС и CRM не нужно интегрировать с мастер-справочником, все довольны.
- Перекодер исходно спроектирован под нагрузку до тысячи перекодировок в секунду, чтобы удовлетворить всех участников информационного обмена: шину, ETL-скрипты, обслуживающие процедуры реального времени, макросы в Экселе, космическую станцию и пр.
Что можно делать с помощью Перекодера
Можно и нужно:
- Управлять справочниками, группами справочников и перекодировками (создавать, редактировать и удалять).
- Настраивать периодические синхронизации справочников Перекодера с исходными системами.
- Выполнять онлайн-перекодировки и получать значения исходных справочников через SOAP и REST интерфейсы.
- Получать автоматические оповещения об изменениях в исходных справочниках. Если вдруг появилось значение, для которого нет перекодировки, SOAP/REST вернут ошибку и оповестят всех заинтересованных лиц.

Классификатор «Программа обслуживания клиента», в котором атрибуты почему-то названы нерусскими словами Description и Full Description
Что под капотом?
Система разбита на модули, чтобы изолировать API, бизнес-логику и хранилище друг от друга. Связующим IoC контейнером между компонентами выступает Spring Framework.
Технологическую схему потоков данных можно представить так:
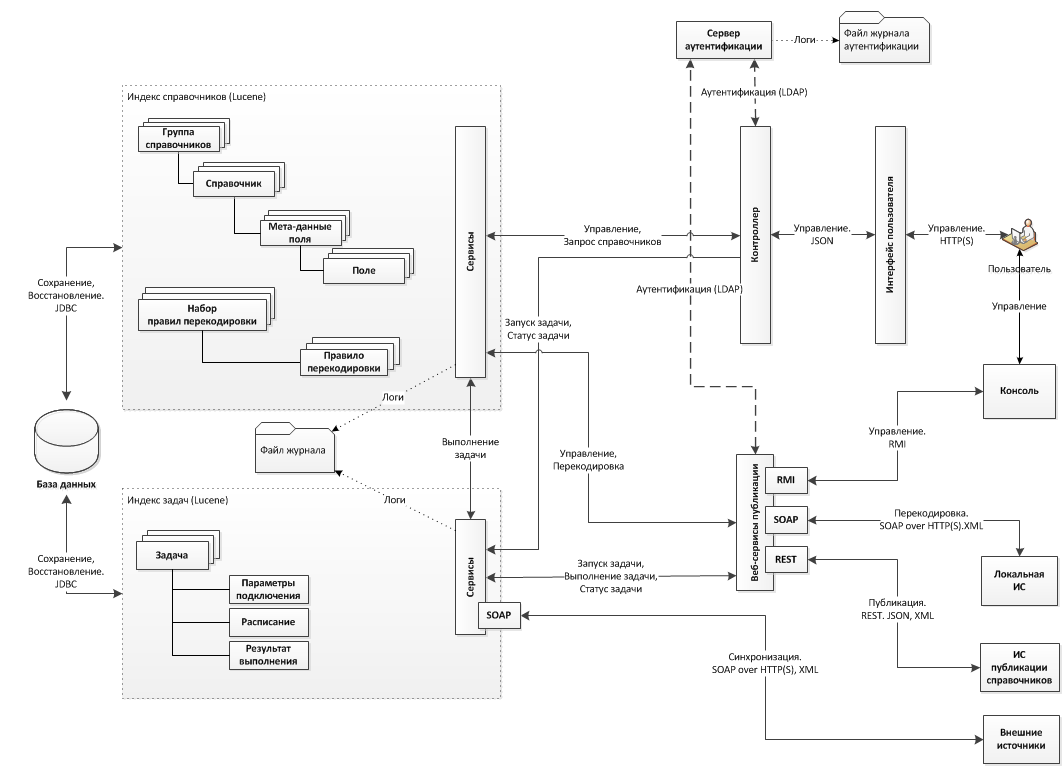
Как можно видеть, сервисы вообще не взаимодействуют напрямую с БД. Вместо этого вся работа (read / write) идет с индексом Lucene, а результаты write-операций дополнительно записываются в базу. Для чего так сделано? Все просто: основная задача системы — максимально быстро найти перекодировку (соответствие между записями в паре справочников), а такая архитектура наиболее эффективно справляется с этим на больших объемах данных. Плюс ко всему, получаем полнотекстовый поиск по всем данным «из коробки». Конечно, можно было бы использовать более высокоуровневые решения, например Elasticsearch или Solr, но у них есть свои недостатки, борьба с которыми выходит дороже, чем написать свой код.
Для того чтобы обеспечить целостность информации, модификация данных производится в одной транзакции в поисковом индексе и в базе. Причем интерфейсы спроектированы так, что бизнес-логика приложения знает только об индексе, а СУБД можно заменить на другое решение с минимальными модификациями. Фактически нужно реализовать пару классов и добавить их в classpath — все остальное сделает Spring и фабрики компиляции классов на лету (runtime code compiling).
Каркасом для SOAP и RESTfull интерфейсов выступает Apache CXF, который позволяет легко настроить версионность API (если вдруг понадобится изменить его) и вклиниться в любую фазу обработки входящего/исходящего сообщения.
Исходный код
github.com/hflabs/perecoder
Тестовый стенд
rcd.hflabs.ru/rcd/admin/login
Логин: admin
Пароль: demo
Документация
confluence.hflabs.ru/x/RICSCg
Что дальше
Мы начали внедрение Перекодера у нескольких заказчиков.
Будем рады вашим комментариям по функциональности: что нравится, что нет, что непонятно.
Ну и если этот продукт будет вам полезен, значит, мы не зря потратили время на написание этой статьи ;)
