
Под напором появления новых асинхронных неблокирующихся фреймворков может показаться, что блокирующиеся вызовы — это пережиток прошлого, и все новые сервисы нужно писать на полностью асинхронной архитектуре. В этом посте я расскажу, как мы решили отказаться от неблокирующих асинхронных вызовов бэкендов в пользу обычных блокирующих.
В архитектуре HeadHunter есть сервис, который собирает данные с других сервисов. Например, чтобы показать вакансии по поисковому запросу, нужно:
- сходить в бэкенд поиска за “айдишками” вакансий;
- сходить в бэкенд вакансий за их описанием.
Это простейший пример. Часто в этом сервисе много всякой логики. Мы его даже назвали “logic”.
Изначально он был написан на python. За несколько лет существования logic в нем накопилось всякого тех. долга. Да и разработчики были не в восторге от необходимости копаться как в python, так и в java, на которой у нас написано большинство бэкендов. И мы подумали, почему бы не переписать logic на java.
Причем python logic у нас прогрессивный, построен на асинхронном неблокирующемся фреймворке tornado. Вопроса “блокироваться или не блокироваться при походе на бэкенды” даже не стояло: из-за GIL в python нет настоящего параллельного исполнения потоков, поэтому хочешь — не хочешь, а запросы надо обрабатывать в одном потоке и не блокироваться при походах в другие сервисы.
А вот при переходе на java мы решили еще раз оценить, хотим ли продолжать писать вывернутый коллбэчный код.
def search_vacancies(query):
def on_vacancies_ids_received(vacancies_ids):
get_vacancies(vacancies_ids, callback=reply_to_client)
search_vacancies_ids(query, callback=on_vacancies_ids_received)
Конечно callback hell можно сгладить. В java 8, например, появилась CompletableFuture. Еще можно посмотреть в сторону Akka, Vert.x, Quasar и т. д. Но, может быть, нам не нужны новые уровни абстракции, и мы можем вернуться к обычным синхронным блокирующимся вызовам?
def search_vacancies(query):
vacancies_ids = search_vacancies_ids(query)
return get_vacancies(vacancies_ids)
В этом случае мы будем выделять под обработку каждого запроса поток, который при походе на бэкенд будет блокироваться до тех пор, пока не получит результат, а затем продолжит исполнение. Обратите внимание, что я говорю про блокировку потока в момент вызова удаленного сервиса. Вычитывание запроса и запись результата в сокет будет по-прежнему осуществляться без блокировки. То есть, поток будет выделяться под готовый запрос, а не под соединение. Чем потенциально плоха блокировка потока?
- Потребуется много памяти, так как каждому потоку нужна память под стек.
- Все будет тормозить, так как переключение между контекстами потоков — не бесплатная операция.
- Если бэкенды затупят, то свободных потоков в пуле не останется.
Мы решили прикинуть, сколько нам понадобится потоков, а потом оценить, заметим ли мы эти проблемы.
Сколько нужно потоков?
Нижнюю границу оценить несложно.
Предположим, сейчас у python logic такие логи:
15:04:00 400 ms GET /vacancies
15:04:00 600 ms GET /resumes
15:04:01 500 ms GET /vacancies
15:04:01 600 ms GET /resumes
Вторая колонка — это время от поступления запроса до отдачи ответа. То есть logic обработал:
15:04:00 суммарная длительность запросов - 1000 ms
15:04:01 суммарная длительность запросов - 1100 ms
Если мы будем выделять под обработку каждого запроса поток, то:
- в 15:04:00 мы теоретически можем обойтись одним потоком, который вначале обработает запрос GET /vacancies, а потом обработает запрос GET /resumes;
- а вот в 15:04:01 уже придется выделять минимум 2 потока, так как один поток за одну секунду никак не сможет обработать больше секунды запросов.
На самом деле, в самое нагруженное время на python logic такая суммарная длительность запросов:
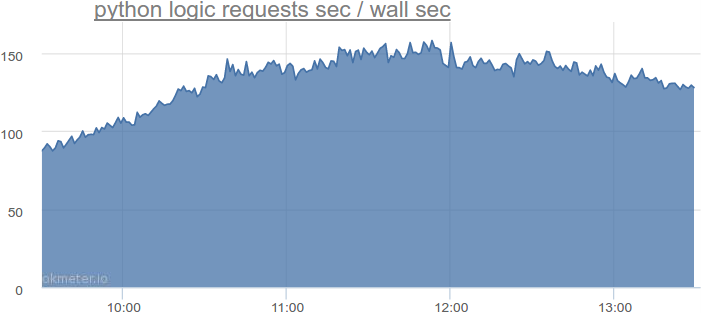
Больше 150 секунд запросов за секунду. То есть нам потребуется больше 150 потоков. Запомним это число. Но надо еще как-то учесть, что запросы приходят неравномерно, поток может быть возвращен в пул не сразу после обработки запроса, а чуть позже, и т. д.
Давайте возьмем другой сервис, который блокируется при походах в базу данных, посмотрим, сколько ему требуется потоков, и экстраполируем числа. Вот, например, сервис приглашений и откликов:
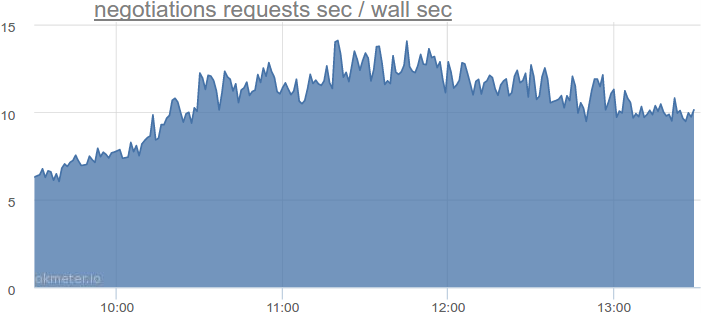
До 14 секунд запросов за секунду. А что с фактическим использованием потоков?
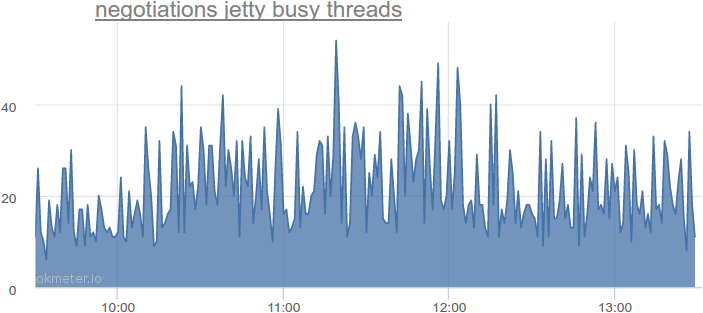
До 54-х одновременно используемых потоков, что в 2-4 раза больше по сравнению с теоретически минимальным количеством. Мы смотрели на другие сервисы — там похожая картина.
Тут уместно сделать небольшое отступление. В HeadHunter в качестве http сервера используется jetty, но в других http серверах похожая архитектура:
- каждый запрос — это задача;
- эта задача поступает в очередь перед пулом потоков;
- если в пуле есть свободный поток — он берет задачу из очереди и выполняет ее;
- если свободного потока нет — задача лежит в очереди, пока свободный поток не появится.
Если нам не страшно, что запрос будет некоторое время лежать в очереди — можно выделить потоков немногим больше, чем рассчитанный минимум. Но если мы хотим максимально сократить задержки, то потоков нужно выделить больше.
Давайте выделим в 4 раза больше потоков.
То есть, если мы сейчас переведем весь python logic на java logic с блокирующейся архитектурой, то нам потребуется 150 * 4 = 600 потоков.
Давайте представим, что нагрузка вырастет в 2 раза. Тогда, если мы не упремся в CPU, нам потребуется 1200 потоков.
Еще представим, что наши бэкенды тупят, и на обслуживание запросов уходит в 2 раза больше времени, но об этом позже, пока пусть будет 2400 потоков.
Сейчас python logic крутится на четырех серверах, то есть на каждом будет 2400 / 4 = 600 потоков.
600 потоков — это много или мало?
Несколько сотен тредов — это много или мало?
По-умолчанию, на 64-х битных машинах java выделяет под стек потока 1 МБ памяти.
То есть для 600 потоков потребуется 600 МБ памяти. Не катастрофа. К тому же это — 600 МБ виртуального адресного пространства. Физическая оперативная память будет задействована только тогда, когда эта память действительно потребуется. Нам почти никогда не требуется 1 МБ стека, мы часто зажимаем его до 512 КБ. В этом смысле ни 600, ни даже 1000 потоков для нас не проблема.
Что с затратами на переключение контекста между потоками?
Вот простенький тест на java:
- создаем пул потоков размером 1, 2, 4, 8… 4096;
- закидываем в него 16 384 задачи;
- каждая задача — это 600 000 итераций складывания случайных чисел;
- ждем выполнения всех задач;
- запускаем тест 2 раза для прогрева;
- запускаем тест еще 5 раз и берем среднее время.
static final int numOfWarmUps = 2;
static final int numOfTests = 5;
static final int numOfTasks = 16_384;
static final int numOfIterationsPerTask = 600_000;
public static void main(String[] args) throws Exception {
for (int numOfThreads : new int[] {1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096}) {
System.out.println(numOfThreads + " threads.");
ExecutorService executorService = Executors.newFixedThreadPool(numOfThreads);
System.out.println("Warming up...");
for (int i=0; i < numOfWarmUps; i++) {
test(executorService);
}
System.out.println("Testing...");
for (int i = 0; i < numOfTests; i++) {
long start = currentTimeMillis();
test(executorService);
System.out.println(currentTimeMillis() - start);
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.SECONDS);
System.out.println();
}
}
static void test(ExecutorService executorService) throws Exception {
List<Future<Integer>> resultsFutures = new ArrayList<>(numOfTasks);
for (int i = 0; i < numOfTasks; i++) {
resultsFutures.add(executorService.submit(new Task()));
}
for (Future<Integer> resultFuture : resultsFutures) {
resultFuture.get();
}
}
static class Task implements Callable<Integer> {
private final Random random = new Random();
@Override
public Integer call() throws InterruptedException {
int sum = 0;
for (int i = 0; i < numOfIterationsPerTask; i++) {
sum += random.nextInt();
}
return sum;
}
}
Вот результаты на 4-х ядерном i7-3820, HyperThreading отключен, Ubuntu Linux 64-bit. Ожидаем, что лучший результат покажет пул с четырьмя потоками (по количеству ядер), так что сравниваем остальные результаты с ним:
| Количество потоков | Среднее время, мс | Стандартное отклонение | Разница, % |
|---|---|---|---|
| 1 | 109152 | 9,6 | 287,70% |
| 2 | 55072 | 35,6 | 95,61% |
| 4 | 28153 | 3,8 | 0,00% |
| 8 | 28142 | 2,8 | -0,04% |
| 16 | 28141 | 3,6 | -0,04% |
| 32 | 28152 | 3,7 | 0,00% |
| 64 | 28149 | 6,6 | -0,01% |
| 128 | 28146 | 2,3 | -0,02% |
| 256 | 28146 | 4,1 | -0,03% |
| 512 | 28148 | 2,7 | -0,02% |
| 1024 | 28146 | 2,8 | -0,03% |
| 2048 | 28157 | 5,0 | 0,01% |
| 4096 | 28160 | 3,0 | 0,02% |
Разница между 4 и 4096 потоками сравнима с погрешностью. Так что и в смысле накладных расходов от переключения контекстов 600 потоков для нас не является проблемой.
А если бэкенды затупят?
Представим, что у нас затупил один из бэкендов, и теперь запросы к нему занимают в 2, 4, 10 раз больше времени. Это может привести к тому, что все потоки будут висеть заблокированными, и мы не сможем обрабатывать другие запросы, которым этот бэкенд не нужен. В этом случае мы можем сделать несколько вещей.
Во-первых, оставить про запас еще больше потоков.
Во-вторых, выставить жесткие таймауты. За таймаутами надо следить, это может быть проблемой. Стоит ли она того, чтобы писать асинхронный код? Вопрос открытый.
В-третьих, никто не заставляет нас писать все в синхронном стиле. Например, какие-то контроллеры мы вполне можем написать в асинхронном стиле, если ожидаем проблем с бэкендами.
Таким образом, для сервиса походов по бэкендам при наших нагрузках мы сделали выбор в пользу преимущественно блокирующейся архитектуры. Да, нам нужно следить за таймаутами, и мы не можем быстро отмасштабироваться в 100 раз. Но, с другой стороны, мы можем писать простой и понятный код, быстрее выпускать бизнес-фичи и тратить меньше времени на поддержку, что, на мой взгляд, тоже очень круто.
