 Система хранения данных P6000 EVA разработана и оптимизированадля работы в среде виртуализации и с приложениями баз данных. Технологические и эксплуатационные достоинства дисковых массивов HP EVA обеспечены прежде всего тем, что в них реализована одна из трех возможных схем виртуализации — виртуализация на уровне систем хранения. Совместно с двумя другими схемами — на уровне серверов и на уровне сети она обеспечивает абстрагирование логических и физических ресурсов хранения. Виртуализация на уровне систем хранения реализуется с помощью контроллеров дисковых массивов, обеспечивающих независимость от серверов. Данный тип виртуализации позволяет рассматривать все физически диски, входящие в состав накопителя, как единый пул ресурсов хранения, доступный для всех подключаемых к нему серверов. Виртуализация обеспечивает эффективное использование пространства хранения, упрощает процесс управления и, как следствие, снижает расходы на хранение данных.
Система хранения данных P6000 EVA разработана и оптимизированадля работы в среде виртуализации и с приложениями баз данных. Технологические и эксплуатационные достоинства дисковых массивов HP EVA обеспечены прежде всего тем, что в них реализована одна из трех возможных схем виртуализации — виртуализация на уровне систем хранения. Совместно с двумя другими схемами — на уровне серверов и на уровне сети она обеспечивает абстрагирование логических и физических ресурсов хранения. Виртуализация на уровне систем хранения реализуется с помощью контроллеров дисковых массивов, обеспечивающих независимость от серверов. Данный тип виртуализации позволяет рассматривать все физически диски, входящие в состав накопителя, как единый пул ресурсов хранения, доступный для всех подключаемых к нему серверов. Виртуализация обеспечивает эффективное использование пространства хранения, упрощает процесс управления и, как следствие, снижает расходы на хранение данных. Несколько простых советов, описанных в этой статье позволят правильно оптимизировать работу СХД и позволят в дальнейшем быстрее адаптироваться к изменениям, возникающим в бизнесе.
Массивы HP EVA представляют собой пример того, как эти качества реализованы в недорогих дисковых массивах, предназначенных как для предприятий малого и среднего бизнеса, так и для корпоративных клиентов. Одно из главных преимуществ виртуализации, реализованное в накопителях семейства HP EVA, — высокая производительность и балансировка нагрузки, позволяющая равномерно распределить обращения к физическим дискам.
Как видно из рисунка, при традиционном использовании RAID вся нагрузка сосредоточена на физических дисках, которые входят в соответствующие RAID-массивы. В этой ситуации нагрузка может быть больше или меньше в зависимости от режима работы приложений, в то время как при поддержке виртуализации все диски нагружаются равномерно, следовательно, общая производительность становится выше.

Начнем с описания внутреннего устройства систем EVA. Данное описание относится в практически неизменном виде ко всем поколениям EVA.
В предыдущих статьях было написано про основные понятия СХД EVA такие, как дисковая группа, виртальный диск (LUN).
Каждая дисковая группа делится управляющим ПО Virtual Controller Software (VCS/XCS) на Redundant Storage Sets (RSS) для повышения характеристик отказоустойчивости этой дисковой группы. Можно рассматривать это как множество мини-RAID групп, образующие одну большую общую дисковую группу.
Если необходимо записать информацию в эту дисковую группу, то в каждый RSS записывается равный объем (например, 30MB информации в 3 RSS записывается по 10MB в RSS).
Рассмотрим наглядно как происходит процесс разделения.
Для традиционных массивов хранения данных характерно то, что определенные диски используются для хранения данных одного уровня RAID.

Для виртуализированных систем EVA все диски могут использоваться для хранения данных в различных уровнях RAID.
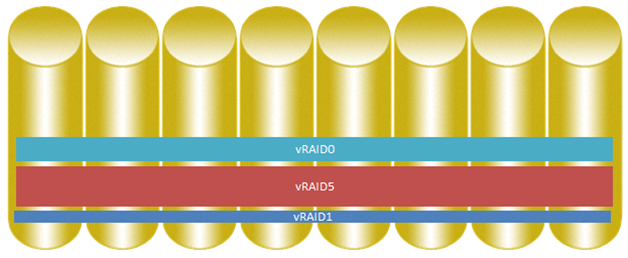
Каждый том на EVA, таким образом, получает IOPS от всех дисков, которые образуют virtual disk, что дает прирост в производительности.
1. Управляющее ПО XCS делит каждый диск на равные по размеру блоки. Размер блока зависит от версии массива, версии управляющего ПО, размер сегмента варьируется 2 / 8 MB.
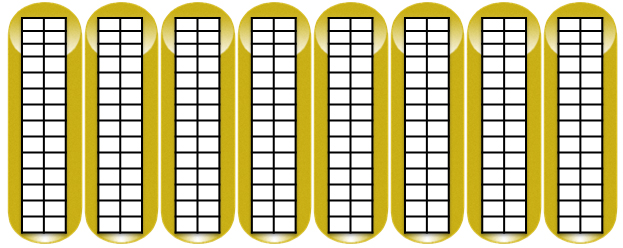
2. Далее формируются в группы по 8 дисков (RSS), в каждой RSS резервируется объем необходимый для защиты данных от выхода из строя дисков в зависимости от предпочитаемого уровня RAID.
3. EVA следует определенным алгоритмам для выбора участников RSS для обеспечения максимальной доступности и лучшей утилизации дискового пространства:
— участники RSS выбираются вертикально между разными дисковыми полками
— пары RAID выбираются между разными дисковыми полками
Для наглядности диски из разных полок поставлены в ряд. Схематически показан пример записи двух блоков данных по 8 МБ в RAID5 (4 блока данных и 1 блок четности) на примере EVA 4400.
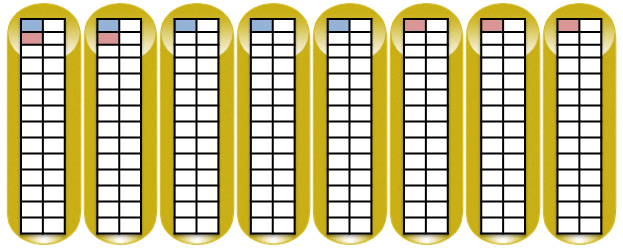
При добавлении дисков или при выходе из строя дисков начинается процесс перемещения триггеров и перестройки RSS, только если произошедшие изменения могут принести потерю информации (при выходе из строя диска, содержащего участников пар vRAID1 процесс перестройки получает наивысший приоритет, при выходе из строя диска, состоящего только из участников vRAID5 приоритет перестройки ниже). Приоритет процесса перестройки RSS выбирается исходя из оценки приоритетов остальных процессов в массиве. Этот процесс проходит в фоновом режиме и не влияет на производительность.
В ходе эксплуатации системы хранения может возникнуть также необходимость установить дополнительные диски без перерывов в обслуживании — в условиях виртуализации это делается чрезвычайно просто.
При распределенном резервировании, поддерживаемом средствами виртуализации, восстановление данных после выхода из строя одного из физических дисков происходит существенно быстрее, чем в традиционных схемах, где необходимо держать какое-то количество отдельно стоящих дисков в режиме горячего резервирования. Ускорение достигается за счет того, что резервные диски включены в общий пул на равных основаниях. Собственно говоря, никаких специальных резервных дисков нет, а есть некоторый запас емкости. Если из строя выходит один диск, то обычными средствами администрирования производится изменение балансировки между дисками и восстанавливается структура VRaid. Это весьма быстрая процедура, а ее следствием является лишь уменьшение резерва, который может быть восстановлен без перерывов в обслуживании.
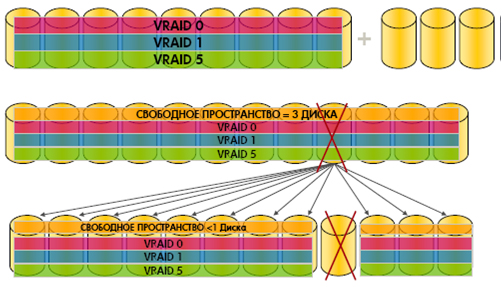
В массиве для оптимизации нагрузки на диски и контроллеры существую процессы равномерного распределения:
1. Процесс равномерного распределение RSS в дисковой группе
2. Процесс равномерного распределения данных внутри каждой RSS.
Процесс реконструкции дисков обладает более высоким приоритетом, по сравнению с процессом равномерного распределения. Отказоустойчивость данных при этом сохраняется.
При выходе из строя диска существуют наилучшие рекомендации:
1. Заменить вышедший из строя диск до изменения конфигурации дисковой группы
2. Заменить вышедший из строя диск аналогичным по объему и скорости
3. Новый диск должен быть помещен в ту же локацию, что и вышедший из строя.
Например, в конфигурации с 50-ю дисками на массив возможен одновременный выход из строя до 6 дисков, чтобы данные в VRAID5 оставались доступны или одновременный выход из строя 25 дисков для VRAID1 (но с таким количеством вышедших из строя дисков существует высокая вероятность повреждения метаданных).
Из-за того, что данные каждого LUN распределены по разным RSS, которые, в свою очередь состоят из дисков в разных дисковых полках это обеспечивает высокую производительность всего массива. Каждый драйв прибавляет IOPS’ы, которые может выдать LUN для приложения хоста.
Исходя из документа по Best Practices существует несколько важный рекомендаций, которые позволят повысить производительность дискового массива:
1. Использовать самую последнюю версию firmware контроллеров, дисков, устройств, к которым подключается массив.
2. Использовать число полок, кратное 8 – это позволит оптимизировать распределение дисков внутри RSS.
3. Добавлять диски в дисковую группу числом, кратным 8.
4. Использовать диски одного объема и скорости в дисковой группе. При использовании дисков разного объема и скорости затраты на поддержку массива возрастают. Например, если поместить диск большого объема в дисковую группу, состоящую из дисков небольшого объема – результирующий полезный объем этого диска будет равен объему наименьшего диска в группе.
5. Создавать как можно меньше дисковых групп – это позволит данным использовать максимальное число дисков, следственно выдавать лучшие параметры производительности.
6. Производительность максимальна, когда массив распределяет данные по максимально возможному числу дисков.
7. Для большинства инсталляций уровень защиты protection level of one предоставляет адекватную доступность данных.
8. Отделять данные с логами баз данных от остальных данных.
9. Для параметров максимальной производительности использовать Solid State Drives.
10.Позволить контроллерам EVA самим балансировать нагрузку.
11. Все best practices для центров обработки данных базируются на регулярном копировании данных на внешние устройства бэкапа или на отдельную дисковую группу на MDL SAS дисках большого объема.
12. Использовать Inside Remote Support для автоматического оповещения о проблемах с массивом в HP Support центр.
Отдельным пунктом можно описать процесс перемещения LUN и изменения уровня vRAID виртуального диска. Эти операции используют зеркальные копии для копирования данных в группы с новыми параметрами. Как только зеркальная копия будет синхронизирована роли копии и главного тома меняются. Данные хоста автоматически обращаются к новому тому. Этот функционал доступен после приобретиния лицензии HP Business Copy. После копирования оба тома остаются, том со старыми параметрами становится копией, по желанию его можно удалить.
Материалы:
1. HP P6000 Best Practices
2. HP with VMware best practices
3. HP P6000 QuickSpecs
P.S. В данном топике приведены лишь некоторые материалы об устройстве массивов P6000, доступные для публикации.
