Во многих областях человеческой деятельности предъявляются повышенные требования к производительности и доступности сервисов, предлагаемых информационными технологиями. Примером таких областей является, например, банковское дело. Если у какого-нибудь крупного банка в стране на несколько часов откажет карточный процессинг, то это отразится на повседневных нуждах и заботах миллионов пользователей по всей стране, что приведет к снижению их лояльности вплоть до принятия решения отказаться от услуг такой кредитной организации. Аналогичным образом дело обстоит и с производительностью и доступностью многих других информационных систем.
Решение проблем с производительностью и доступностью в принципе известно: дублировать узлы, обеспечивающие обработку данных, и объединять их в кластеры. При этом для обеспечения максимальной загрузки имеющихся ресурсов и снижения времени простоя системы при выходе из строя одного из узлов кластер должен работать по схеме Active-Active. Также уровень доступности, обеспечиваемый кластером, размещенным целиком в одном центре обработки данных, может быть недостаточен (например, при отключении электричества в целых районах крупных городов). Тогда узлы кластера необходимо географически распределять.
В данной статье мы расскажем о проблемах построения отказоустойчивого географически разнесенного кластера и о решениях, предлагаемом корпорацией IBM на базе мейнфреймов, а также поделимся результатами выполненного нами тестирования производительности и высокой доступности реального банковского приложения в кластерной конфигурации, с узлами, разнесенными на расстояние до 70 км.
Условно проблемы при построении любого кластера Active-Active можно разделить на проблемы кластеризации прикладного приложения и проблемы кластеризации СУБД/подсистемы очередей сообщений. Например, для тестируемого нами приложения существовало требование строгого соблюдения порядка исполнения платежей от одного участника. Понятно, что обеспечение выполнения данного требования в кластерном режиме Active-Active привело к необходимости внесения существенных изменений в архитектуру приложения. Проблема усугублялась тем, что помимо производительности в режиме Active-Active, было необходимо обеспечить высокую доступность стандартными средствами программного обеспечения промежуточно слоя или операционной системы. Подробности того, как мы добились поставленных целей, достойны отдельной статьи.
Современные подходы к кластеризации СУБД обычно базируются на архитектуре shared disk. Основной задачей при таком подходе является обеспечение синхронизируемого доступа к разделяемым данным. Детали реализации сильно зависят от конкретной СУБД, но наиболее популярным является подход, основанный на обмене сообщениями между узлами кластера. Такое решение является чисто программным, прием и отправка сообщений требует прерывания работы приложений (обращения к сетевому стеку операционной системы), так же при активном доступе к разделяемым данным накладные расходы могу стать существенными, что особенно проявляется в случае увеличения расстояния между активными узлами. Как правило, коэффициент масштабируемости таких решений не превышает ¾ (кластер из четырех узлов, каждый из которых имеет производительность N, обеспечивает суммарную производительность ¾ N).
В случае удаленности друг от друга узлов кластера существенное влияние на производительность и допустимое время восстановления (RTO) решения оказывает расстояние. Как известно, скорость света в оптике составляет примерно 200 000 км/с, что соответствует задержке в 10 мкс на каждый километр оптоволокна.
В мейнфреймах IBM для кластеризации СУБД DB2 и менеджеров очередей WebSphere MQ применяется иной подход, не основанный на программном обмене сообщениями между узлами кластера. Решение называется Parallel Sysplex и позволяет объединять в кластер до 32 логических разделов (LPAR), работающих на одном или нескольких мейнфреймах под управлением операционной системы z/OS. Если учесть, что новый мейнфрейм z13 может иметь на борту более 140 процессоров, то максимальная достижимая производительность кластера не может не впечатлять.
Основой Parallel Sysplex является технология Coupling Facility, представляющая собой выделенные логические разделы (LPAR), использующие процессоры, которые могут выполнять специальное кластерное программное обеспечение – Coupling Facility Control Code (CFCC). Coupling Facility в своей памяти хранит структуры общих данных, совместно используемые узлами кластера Parallel Sysplex. Обмен данными между CF и подключенными системами организуется по принципу «память-память» (похоже на DMA), при этом процессоры, на которых работают приложения, не задействуются.
Для обеспечения высокой доступности структур CF используются механизмы синхронной и асинхронной репликации данных между ними средствами операционной системы z/OS и СУБД DB2.
Т.е. подход IBM основан не на программном, а на аппаратно-программном решении, обеспечивающем обмен данными между узлами кластера без прерывания работающих приложений. Тем самым достигается коэффициент масштабируемости близкий к единице, что подтверждается результатами нашего нагрузочного тестирования.
Для демонстрации масштабируемости системы и оценки влияния расстояния на показатели производительности мы провели ряд испытаний, результатами которых хотим с вами поделиться.
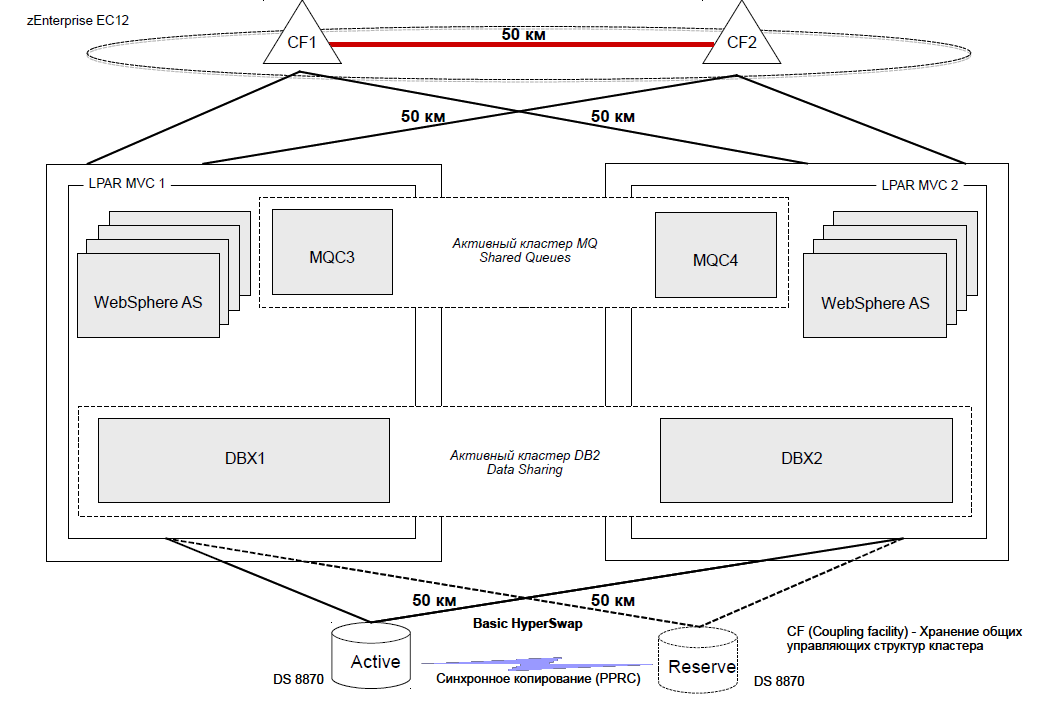
В качестве стенда для проведения испытаний использовался один физический сервер zEnterprise EC 12. На данном сервере было развёрнуто два логических раздела (LPAR) MVC1 и MVC2, каждый из которых работал под управлением операционной системы z/OS 2.1 и содержал по 5 процессоров общего назначения (CP) и 5 специализированных процессоров zIIP, предназначенных для исполнения кода СУБД DB2 и работы Java-приложений. Данные логические разделы были объединены в кластер с использованием механизма Parallel Sysplex.
Для работы механизма Coupling Facility использовались выделенные логические разделы (LPAR) CF1 и CF2, содержащие по 2 процессора ICF. Расстояние между CF1 и CF2 по каналам связи по сценарию тестирования дискретно менялось, находясь в пределах от 0 до 70 км.
Подключение MVC1 к CF1 осуществлялось посредством виртуальных каналов типа ICP, в то время как для доступа к CF2 использовались физические каналы типа Infiniband. Подключение MVC2 к CF1 и CF2 осуществлялось аналогично: посредством ICP каналов к CF2 и с помощью Infiniband к CF1.
Для хранения данных использовался дисковый массив IBM DS 8870, в котором были созданы два набора дисков и настроена синхронная репликация данных между ними с помощью технологии Metro Mirror. Расстояние между наборами дисков по каналам связи по сценарию тестирования дискретно менялось, находясь в пределах от 0 до 70 км. Необходимое расстояние между компонентами стенда обеспечивалось путем применения специализированных устройств DWDM (ADVA) и оптоволоконных кабелей необходимой длины.
Каждый из логических разделов MVC1 и MVC2 подключался к дисковым массивам с помощью двух каналов FICON, имеющих пропускную способность 8 GB/s.
Детальная схема стенда (в варианте с расстоянием между узлами кластера 50 км.) представлена на рисунке.

В качестве тестового приложения на узлах кластера была развернута банковская платежная система, использующая для своей работы следующее программное обеспечение IBM: СУБД DB2 z/OS, менеджеры очередей сообщений WebSphere MQ, сервер приложений WebSphere Application Server for z/OS.
Работы по настройке тестового стенда и установке платежной системы заняли примерно три недели.
Отдельно следует рассказать о принципе работы приложения и профиле нагрузки. Все обрабатываемые платежи можно разделить на два типа: срочные и несрочные. Срочные платежи проводятся сразу же после их считывания из входной очереди. В процессе же обработки несрочных платежей можно выделить три последовательные фазы. Первая фаза – фаза приема – платежи считываются из входной очереди системы и регистрируются в базе данных. Вторая фаза – фаза многостороннего взаимозачета – запускается по таймеру несколько раз в сутки и выполняется строго в однопоточном режиме. На данной фазе осуществляется проводка всех принятых до этого несрочных платежей, при этом учитываются взаимные обязательства участников системы (если Петя переводит 500 рублей Васе и 300 рублей Свете, а Вася – 300 рублей Свете, то есть смысл сразу увеличить значение счета Светы на 600 рублей, а Васи – на 200 рублей, чем выполнять реальные проводки). Третья фаза – фаза рассылки уведомлений – запускается автоматически после завершения второй фазы. На данной фазе осуществляется формирование и рассылка информационных сообщений (квитанций) для всех участвующих в многостороннем взаимозачете счетов. Каждая фаза представляет собой одну или нескольких глобальных транзакций, представляющих собой сложную последовательность действий, выполняемых менеджерами очередей WebSphere MQ и СУБД DB2. Каждая глобальная транзакция завершается двухфазной фиксацией (commit), т.к. в ней участвуют несколько ресурсов (очередь – база данных – очередь).
Важной особенностью платежной системы является способность проводить срочные платежи на фоне многостороннего взаимозачета.
Профиль нагрузки при проведении испытаний повторял профиль нагрузки реально работающей системы. На вход подавалось 2 млн. несрочных платежей, объединенных в пакеты по 500/1000/5000 платежей, каждому пакету соответствовало одно электронное сообщение. Данные пакеты подавались на вход системы с интервалом 4 мс между поступлением каждого следующего сообщения. Параллельно подавалось около 16 тыс. срочных платежей, каждому из которых соответствовало свое электронное сообщение. Данные электронные сообщения подавались с интервалом 10 мс. между поступлением каждого следующего сообщения.
При проведении нагрузочного тестирования расстояние по каналам связи между наборами дисков, а также между логическими разделами CF дискретно менялось, находясь в пределах от 0 до 70 км. При выполнении тестов были зафиксированы следующие результаты:

Интересно сравнить первые две строчки, показывающие масштабируемость системы. Видно, что время выполнения первой фазы при использовании кластера из двух узлов сокращается в 1.4 раза («нелинейность» масштабирования первой фазы объясняется особенностями реализации требования по соблюдению порядка платежей от одного участника), а время выполнения третьей фазы – практически в 2 раза. Многосторонний взаимозачет выполняется в один поток. Время его проведения в кластерном режиме увеличивается из-за необходимости пересылки блокировок DB2 в CF при выполнении массовых операций DML.
При включении механизма репликации данных на дисках (Metro Mirror) время выполнения каждой фазы увеличивается незначительно, на 3 – 4%. При дальнейшем росте расстояния по каналам связи между дисками и между логическими разделами CF время выполнения каждой фазы растет более интенсивно.
Интересно сравнить временные характеристики обработки срочных платежей в крайних случаях: без кластера и в кластере, узлы которого разнесены на расстояние 70 км.

Максимальное время обработки платежа выросло на 40%, при этом среднее изменилось всего на 7.6%. При этом утилизация процессорного ресурса изменяется незначительно за счет увеличения времени доступа к структурам CF.
В статье мы рассмотрели проблемы, возникающие при построении географически распределенного кластера, работающего в режиме Active-Active, и выяснили каким путем можно их избежать, построив кластер на основе мейнфреймов IBM. Утверждения о высокой масштабируемости решений на основе кластера Parallel Sysplex продемонстрированы результатами нагрузочного тестирования. При этом мы проверили поведение системы при различном расстоянии между узлами кластера: 0, 20, 50 и 70 км.
Наиболее интересными результатами является продемонстрированный близкий к единице коэффициент масштабируемости системы, а также выявленная зависимость времени обработки платежей от расстояния между узлами кластера. Чем меньше расстояние влияет на ключевые показатели производительности системы, тем дальше можно разнести узлы кластера друг от друга, тем самым обеспечив большую катастрофоустойчивость.
Если тема построения географически разнесенного кластера мейнфреймов вызовет интерес у хабражителей, то в следующей заметке мы подробно расскажем о проведенных испытаниях высокой доступности системы и полученных результатах. Если вам интересны другие вопросы, касающиеся мейнфреймов, или вы хотите просто поспорить, то добро пожаловать в комментарии. Так же будет полезно, если кто-нибудь поделится своим опытом построения отказоустойчивых решений.
Решение проблем с производительностью и доступностью в принципе известно: дублировать узлы, обеспечивающие обработку данных, и объединять их в кластеры. При этом для обеспечения максимальной загрузки имеющихся ресурсов и снижения времени простоя системы при выходе из строя одного из узлов кластер должен работать по схеме Active-Active. Также уровень доступности, обеспечиваемый кластером, размещенным целиком в одном центре обработки данных, может быть недостаточен (например, при отключении электричества в целых районах крупных городов). Тогда узлы кластера необходимо географически распределять.
В данной статье мы расскажем о проблемах построения отказоустойчивого географически разнесенного кластера и о решениях, предлагаемом корпорацией IBM на базе мейнфреймов, а также поделимся результатами выполненного нами тестирования производительности и высокой доступности реального банковского приложения в кластерной конфигурации, с узлами, разнесенными на расстояние до 70 км.
Проблемы при построении географически разнесенного кластера, работающего по схеме Active-Active
Условно проблемы при построении любого кластера Active-Active можно разделить на проблемы кластеризации прикладного приложения и проблемы кластеризации СУБД/подсистемы очередей сообщений. Например, для тестируемого нами приложения существовало требование строгого соблюдения порядка исполнения платежей от одного участника. Понятно, что обеспечение выполнения данного требования в кластерном режиме Active-Active привело к необходимости внесения существенных изменений в архитектуру приложения. Проблема усугублялась тем, что помимо производительности в режиме Active-Active, было необходимо обеспечить высокую доступность стандартными средствами программного обеспечения промежуточно слоя или операционной системы. Подробности того, как мы добились поставленных целей, достойны отдельной статьи.
Современные подходы к кластеризации СУБД обычно базируются на архитектуре shared disk. Основной задачей при таком подходе является обеспечение синхронизируемого доступа к разделяемым данным. Детали реализации сильно зависят от конкретной СУБД, но наиболее популярным является подход, основанный на обмене сообщениями между узлами кластера. Такое решение является чисто программным, прием и отправка сообщений требует прерывания работы приложений (обращения к сетевому стеку операционной системы), так же при активном доступе к разделяемым данным накладные расходы могу стать существенными, что особенно проявляется в случае увеличения расстояния между активными узлами. Как правило, коэффициент масштабируемости таких решений не превышает ¾ (кластер из четырех узлов, каждый из которых имеет производительность N, обеспечивает суммарную производительность ¾ N).
В случае удаленности друг от друга узлов кластера существенное влияние на производительность и допустимое время восстановления (RTO) решения оказывает расстояние. Как известно, скорость света в оптике составляет примерно 200 000 км/с, что соответствует задержке в 10 мкс на каждый километр оптоволокна.
Подход, применяемый в мейнфреймах IBM
В мейнфреймах IBM для кластеризации СУБД DB2 и менеджеров очередей WebSphere MQ применяется иной подход, не основанный на программном обмене сообщениями между узлами кластера. Решение называется Parallel Sysplex и позволяет объединять в кластер до 32 логических разделов (LPAR), работающих на одном или нескольких мейнфреймах под управлением операционной системы z/OS. Если учесть, что новый мейнфрейм z13 может иметь на борту более 140 процессоров, то максимальная достижимая производительность кластера не может не впечатлять.
Основой Parallel Sysplex является технология Coupling Facility, представляющая собой выделенные логические разделы (LPAR), использующие процессоры, которые могут выполнять специальное кластерное программное обеспечение – Coupling Facility Control Code (CFCC). Coupling Facility в своей памяти хранит структуры общих данных, совместно используемые узлами кластера Parallel Sysplex. Обмен данными между CF и подключенными системами организуется по принципу «память-память» (похоже на DMA), при этом процессоры, на которых работают приложения, не задействуются.
Для обеспечения высокой доступности структур CF используются механизмы синхронной и асинхронной репликации данных между ними средствами операционной системы z/OS и СУБД DB2.
Т.е. подход IBM основан не на программном, а на аппаратно-программном решении, обеспечивающем обмен данными между узлами кластера без прерывания работающих приложений. Тем самым достигается коэффициент масштабируемости близкий к единице, что подтверждается результатами нашего нагрузочного тестирования.
Нагрузочное тестирование кластера
Для демонстрации масштабируемости системы и оценки влияния расстояния на показатели производительности мы провели ряд испытаний, результатами которых хотим с вами поделиться.
В качестве стенда для проведения испытаний использовался один физический сервер zEnterprise EC 12. На данном сервере было развёрнуто два логических раздела (LPAR) MVC1 и MVC2, каждый из которых работал под управлением операционной системы z/OS 2.1 и содержал по 5 процессоров общего назначения (CP) и 5 специализированных процессоров zIIP, предназначенных для исполнения кода СУБД DB2 и работы Java-приложений. Данные логические разделы были объединены в кластер с использованием механизма Parallel Sysplex.
Для работы механизма Coupling Facility использовались выделенные логические разделы (LPAR) CF1 и CF2, содержащие по 2 процессора ICF. Расстояние между CF1 и CF2 по каналам связи по сценарию тестирования дискретно менялось, находясь в пределах от 0 до 70 км.
Подключение MVC1 к CF1 осуществлялось посредством виртуальных каналов типа ICP, в то время как для доступа к CF2 использовались физические каналы типа Infiniband. Подключение MVC2 к CF1 и CF2 осуществлялось аналогично: посредством ICP каналов к CF2 и с помощью Infiniband к CF1.
Для хранения данных использовался дисковый массив IBM DS 8870, в котором были созданы два набора дисков и настроена синхронная репликация данных между ними с помощью технологии Metro Mirror. Расстояние между наборами дисков по каналам связи по сценарию тестирования дискретно менялось, находясь в пределах от 0 до 70 км. Необходимое расстояние между компонентами стенда обеспечивалось путем применения специализированных устройств DWDM (ADVA) и оптоволоконных кабелей необходимой длины.
Каждый из логических разделов MVC1 и MVC2 подключался к дисковым массивам с помощью двух каналов FICON, имеющих пропускную способность 8 GB/s.
Детальная схема стенда (в варианте с расстоянием между узлами кластера 50 км.) представлена на рисунке.
В качестве тестового приложения на узлах кластера была развернута банковская платежная система, использующая для своей работы следующее программное обеспечение IBM: СУБД DB2 z/OS, менеджеры очередей сообщений WebSphere MQ, сервер приложений WebSphere Application Server for z/OS.
Работы по настройке тестового стенда и установке платежной системы заняли примерно три недели.
Отдельно следует рассказать о принципе работы приложения и профиле нагрузки. Все обрабатываемые платежи можно разделить на два типа: срочные и несрочные. Срочные платежи проводятся сразу же после их считывания из входной очереди. В процессе же обработки несрочных платежей можно выделить три последовательные фазы. Первая фаза – фаза приема – платежи считываются из входной очереди системы и регистрируются в базе данных. Вторая фаза – фаза многостороннего взаимозачета – запускается по таймеру несколько раз в сутки и выполняется строго в однопоточном режиме. На данной фазе осуществляется проводка всех принятых до этого несрочных платежей, при этом учитываются взаимные обязательства участников системы (если Петя переводит 500 рублей Васе и 300 рублей Свете, а Вася – 300 рублей Свете, то есть смысл сразу увеличить значение счета Светы на 600 рублей, а Васи – на 200 рублей, чем выполнять реальные проводки). Третья фаза – фаза рассылки уведомлений – запускается автоматически после завершения второй фазы. На данной фазе осуществляется формирование и рассылка информационных сообщений (квитанций) для всех участвующих в многостороннем взаимозачете счетов. Каждая фаза представляет собой одну или нескольких глобальных транзакций, представляющих собой сложную последовательность действий, выполняемых менеджерами очередей WebSphere MQ и СУБД DB2. Каждая глобальная транзакция завершается двухфазной фиксацией (commit), т.к. в ней участвуют несколько ресурсов (очередь – база данных – очередь).
Важной особенностью платежной системы является способность проводить срочные платежи на фоне многостороннего взаимозачета.
Профиль нагрузки при проведении испытаний повторял профиль нагрузки реально работающей системы. На вход подавалось 2 млн. несрочных платежей, объединенных в пакеты по 500/1000/5000 платежей, каждому пакету соответствовало одно электронное сообщение. Данные пакеты подавались на вход системы с интервалом 4 мс между поступлением каждого следующего сообщения. Параллельно подавалось около 16 тыс. срочных платежей, каждому из которых соответствовало свое электронное сообщение. Данные электронные сообщения подавались с интервалом 10 мс. между поступлением каждого следующего сообщения.
Результаты нагрузочного тестирования
При проведении нагрузочного тестирования расстояние по каналам связи между наборами дисков, а также между логическими разделами CF дискретно менялось, находясь в пределах от 0 до 70 км. При выполнении тестов были зафиксированы следующие результаты:
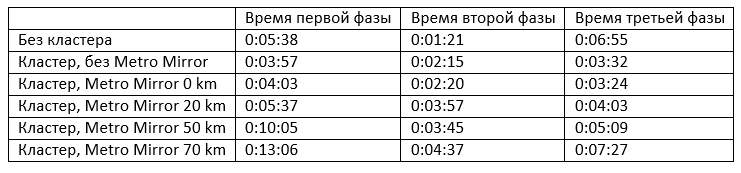
Интересно сравнить первые две строчки, показывающие масштабируемость системы. Видно, что время выполнения первой фазы при использовании кластера из двух узлов сокращается в 1.4 раза («нелинейность» масштабирования первой фазы объясняется особенностями реализации требования по соблюдению порядка платежей от одного участника), а время выполнения третьей фазы – практически в 2 раза. Многосторонний взаимозачет выполняется в один поток. Время его проведения в кластерном режиме увеличивается из-за необходимости пересылки блокировок DB2 в CF при выполнении массовых операций DML.
При включении механизма репликации данных на дисках (Metro Mirror) время выполнения каждой фазы увеличивается незначительно, на 3 – 4%. При дальнейшем росте расстояния по каналам связи между дисками и между логическими разделами CF время выполнения каждой фазы растет более интенсивно.
Интересно сравнить временные характеристики обработки срочных платежей в крайних случаях: без кластера и в кластере, узлы которого разнесены на расстояние 70 км.

Максимальное время обработки платежа выросло на 40%, при этом среднее изменилось всего на 7.6%. При этом утилизация процессорного ресурса изменяется незначительно за счет увеличения времени доступа к структурам CF.
Выводы
В статье мы рассмотрели проблемы, возникающие при построении географически распределенного кластера, работающего в режиме Active-Active, и выяснили каким путем можно их избежать, построив кластер на основе мейнфреймов IBM. Утверждения о высокой масштабируемости решений на основе кластера Parallel Sysplex продемонстрированы результатами нагрузочного тестирования. При этом мы проверили поведение системы при различном расстоянии между узлами кластера: 0, 20, 50 и 70 км.
Наиболее интересными результатами является продемонстрированный близкий к единице коэффициент масштабируемости системы, а также выявленная зависимость времени обработки платежей от расстояния между узлами кластера. Чем меньше расстояние влияет на ключевые показатели производительности системы, тем дальше можно разнести узлы кластера друг от друга, тем самым обеспечив большую катастрофоустойчивость.
Если тема построения географически разнесенного кластера мейнфреймов вызовет интерес у хабражителей, то в следующей заметке мы подробно расскажем о проведенных испытаниях высокой доступности системы и полученных результатах. Если вам интересны другие вопросы, касающиеся мейнфреймов, или вы хотите просто поспорить, то добро пожаловать в комментарии. Так же будет полезно, если кто-нибудь поделится своим опытом построения отказоустойчивых решений.
